# Kafka 存储
Kafka 是 Apache 的开源项目。Kafka 既可以作为一个消息队列中间件,也可以作为一个分布式流处理平台。
Kafka 用于构建实时数据管道和流应用。它具有水平可伸缩性,容错性,快速快速性。
# 1. 逻辑存储
# 2. 持久化
持久化是 Kafka 的一个重要特性。
Kafka 集群持久化保存(使用可配置的保留期限)所有发布记录——无论它们是否被消费。但是,Kafka 不会一直保留数据,也不会等待所有的消费者读取了消息才删除消息。只要数据量达到上限(比如 1G)或者数据达到过期时间(比如 7 天),Kafka 就会删除旧消息。Kafka 的性能和数据大小无关,所以长时间存储数据没有什么问题。
Kafka 对消息的存储和缓存严重依赖于文件系统。
顺序磁盘访问在某些情况下比随机内存访问还要快!在 Kafka 中,所有数据一开始就被写入到文件系统的持久化日志中,而不用在 cache 空间不足的时候 flush 到磁盘。实际上,这表明数据被转移到了内核的 pagecache 中。所以,虽然 Kafka 数据存储在磁盘中,但其访问性能也不低。
Kafka 的协议是建立在一个 “消息块” 的抽象基础上,合理将消息分组。 这使得网络请求将多个消息打包成一组,而不是每次发送一条消息,从而使整组消息分担网络中往返的开销。Consumer 每次获取多个大型有序的消息块,并由服务端依次将消息块一次加载到它的日志中。这可以有效减少大量的小型 I/O 操作。
由于 Kafka 在 Producer、Broker 和 Consumer 都共享标准化的二进制消息格式,这样数据块不用修改就能在他们之间传递。这可以避免字节拷贝带来的开销。
Kafka 以高效的批处理格式支持一批消息可以压缩在一起发送到服务器。这批消息将以压缩格式写入,并且在日志中保持压缩,只会在 Consumer 消费时解压缩。压缩传输数据,可以有效减少网络带宽开销。
- Kafka 支持 GZIP,Snappy 和 LZ4 压缩协议。
所有这些优化都允许 Kafka 以接近网络速度传递消息。
# 3. 物理存储
# 3.1. Log
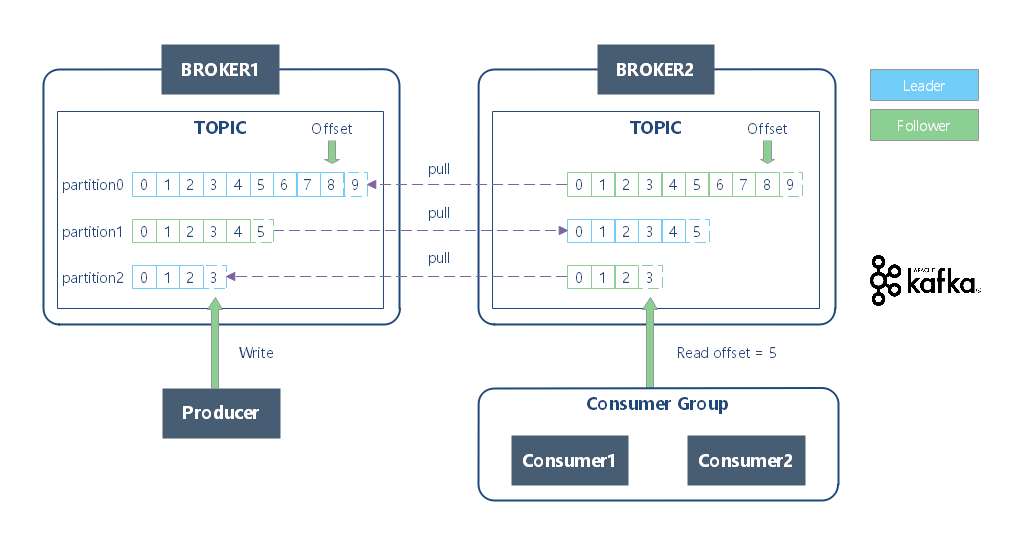
Kafka 的数据结构采用三级结构,即:主题(Topic)、分区(Partition)、消息(Record)。
在 Kafka 中,任意一个 Topic 维护了一组 Partition 日志,如下所示:
请注意:这里的主题只是一个逻辑上的抽象概念,实际上,Kafka 的基本存储单元是 Partition。Partition 无法在多个 Broker 间进行再细分,也无法在同一个 Broker 的多个磁盘上进行再细分。所以,分区的大小受到单个挂载点可用空间的限制。
Partiton 命名规则为 Topic 名称 + 有序序号,第一个 Partiton 序号从 0 开始,序号最大值为 Partition 数量减 1。
Log 是 Kafka 用于表示日志文件的组件。每个 Partiton 对应一个 Log 对象,在物理磁盘上则对应一个目录。如:创建一个双分区的主题 test,那么,Kafka 会在磁盘上创建两个子目录:test-0 和 test-1;而在服务器端,这就对应两个 Log 对象。
# 3.2. Log Segment
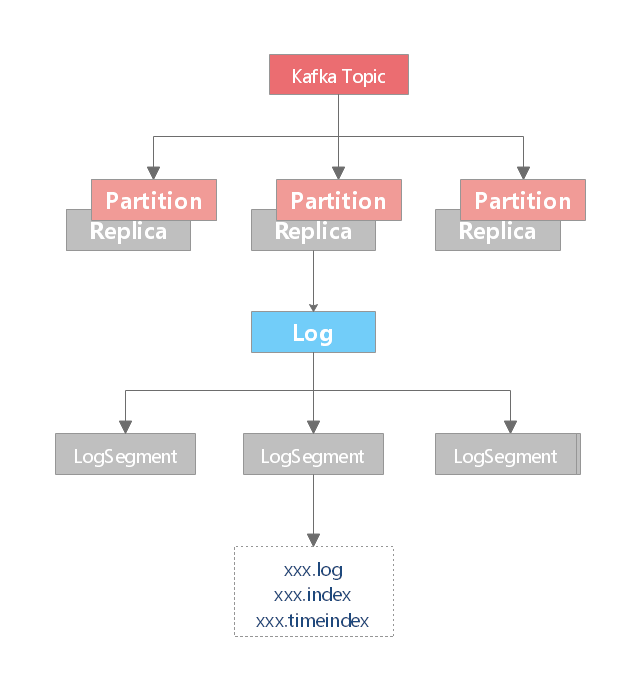
因为在一个大文件中查找和删除消息是非常耗时且容易出错的。所以,Kafka 将每个 Partition 切割成若干个片段,即日志段(Log Segment)。默认每个 Segment 大小不超过 1G,且只包含 7 天的数据。如果 Segment 的消息量达到 1G,那么该 Segment 会关闭,同时打开一个新的 Segment 进行写入。
Broker 会为 Partition 里的每个 Segment 打开一个文件句柄(包括不活跃的 Segment),因此打开的文件句柄数通常会比较多,这个需要适度调整系统的进程文件句柄参数。正在写入的分片称为活跃片段(active segment),活跃片段永远不会被删除。
Segment 文件命名规则:Partition 全局的第一个 segment 从 0 开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用 0 填充。
Segment 文件可以分为两类:
- 索引文件
- 偏移量索引文件(
.index) - 时间戳索引文件(
.timeindex) - 已终止事务的索引文件(
.txnindex):如果没有使用 Kafka 事务,则不会创建该文件
- 偏移量索引文件(
- 日志数据文件(
.log)
# 4. 文件格式
Kafka 的消息和偏移量保存在文件里。保存在磁盘上的数据格式和从生产者发送过来或消费者读取的数据格式是一样的。因为使用了相同的数据格式,使得 Kafka 可以进行零拷贝技术给消费者发送消息,同时避免了压缩和解压。
除了键、值和偏移量外,消息里还包含了消息大小、校验和(检测数据损坏)、魔数(标识消息格式版本)、压缩算法(Snappy、GZip 或者 LZ4)和时间戳(0.10.0 新增)。时间戳可以是生产者发送消息的时间,也可以是消息到达 Broker 的时间,这个是可配的。
如果生产者发送的是压缩的消息,那么批量发送的消息会压缩在一起,以“包装消息”(wrapper message)来发送,如下所示:
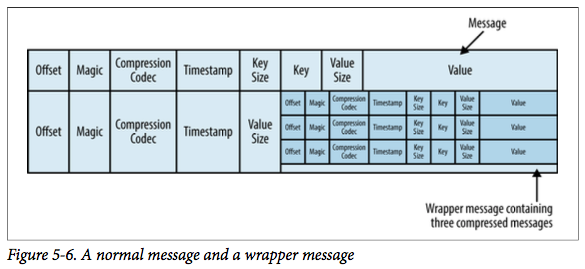
如果生产者使用了压缩功能,发送的批次越大,就意味着能获得更好的网络传输效率,并且节省磁盘存储空间。
Kafka 附带了一个叫 DumpLogSegment 的工具,可以用它查看片段的内容。它可以显示每个消息的偏移量、校验和、魔术数字节、消息大小和压缩算法。
# 5. 索引
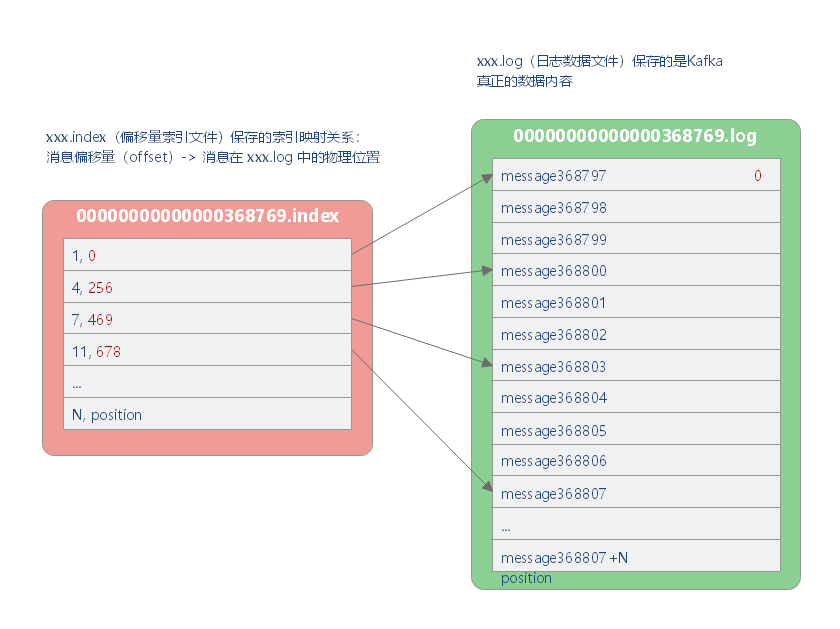
Kafka 允许消费者从任意有效的偏移量位置开始读取消息。Kafka 为每个 Partition 都维护了一个索引(即 .index 文件),该索引将偏移量映射到片段文件以及偏移量在文件里的位置。
索引也被分成片段,所以在删除消息时,也可以删除相应的索引。Kafka 不维护索引的校验和。如果索引出现损坏,Kafka 会通过重读消息并录制偏移量和位置来重新生成索引。如果有必要,管理员可以删除索引,这样做是绝对安全的,Kafka 会自动重新生成这些索引。
索引文件用于将偏移量映射成为消息在日志数据文件中的实际物理位置,每个索引条目由 offset 和 position 组成,每个索引条目可以唯一确定在各个分区数据文件的一条消息。其中,Kafka 采用稀疏索引存储的方式,每隔一定的字节数建立了一条索引,可以通过**“index.interval.bytes”**设置索引的跨度;
有了偏移量索引文件,通过它,Kafka 就能够根据指定的偏移量快速定位到消息的实际物理位置。具体的做法是,根据指定的偏移量,使用二分法查询定位出该偏移量对应的消息所在的分段索引文件和日志数据文件。然后通过二分查找法,继续查找出小于等于指定偏移量的最大偏移量,同时也得出了对应的 position(实际物理位置),根据该物理位置在分段的日志数据文件中顺序扫描查找偏移量与指定偏移量相等的消息。下面是 Kafka 中分段的日志数据文件和偏移量索引文件的对应映射关系图(其中也说明了如何按照起始偏移量来定位到日志数据文件中的具体消息)。
# 6. 清理
每个日志片段可以分为以下两个部分:
- 干净的部分:这部分消息之前已经被清理过,每个键只存在一个值。
- 污浊的部分:在上一次清理后写入的新消息。
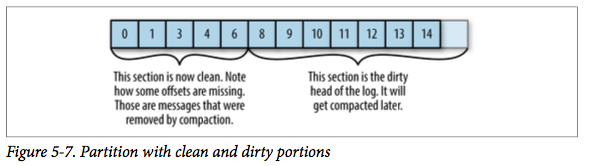
如果在 Kafka 启动时启用了清理功能(通过 log.cleaner.enabled 配置),每个 Broker 会启动一个清理管理器线程和若干个清理线程,每个线程负责一个 Partition。
清理线程会读取污浊的部分,并在内存里创建一个 map。map 的 key 是消息键的哈希吗,value 是消息的偏移量。对于相同的键,只保留最新的位移。其中 key 的哈希大小为 16 字节,位移大小为 8 个字节。也就是说,一个映射只有 24 字节,假设消息大小为 1KB,那么 1GB 的段有 1 百万条消息,建立这个段的映射只需要 24MB 的内存,映射的内存效率是非常高效的。
在配置 Kafka 时,管理员需要设置这些清理线程可以使用的总内存。如果设置 1GB 的总内存同时有 5 个清理线程,那么每个线程只有 200MB 的内存可用。在清理线程工作时,它不需要把所有脏的段文件都一起在内存中建立上述映射,但需要保证至少能够建立一个段的映射。如果不能同时处理所有脏的段,Kafka 会一次清理最老的几个脏段,然后在下一次再处理其他的脏段。
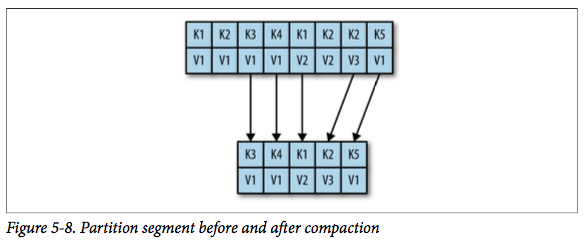
一旦建立完脏段的键与位移的映射后,清理线程会从最老的干净的段开始处理。如果发现段中的消息的键没有在映射中出现,那么可以知道这个消息是最新的,然后简单的复制到一个新的干净的段中;否则如果消息的键在映射中出现,这条消息需要抛弃,因为对于这个键,已经有新的消息写入。处理完会将产生的新段替代原始段,并处理下一个段。
对于一个段,清理前后的效果如下:
# 7. 删除事件
对于只保留最新消息的清理策略来说,Kafka 还支持删除相应键的消息操作(而不仅仅是保留最新的消息内容)。这是通过生产者发送一条特殊的消息来实现的,该消息包含一个键以及一个 null 的消息内容。当清理线程发现这条消息时,它首先仍然进行一个正常的清理并且保留这个包含 null 的特殊消息一段时间,在这段时间内消费者消费者可以获取到这条消息并且知道消息内容已经被删除。过了这段时间,清理线程会删除这条消息,这个键会从 Partition 中消失。这段时间是必须的,因为它可以使得消费者有一定的时间余地来收到这条消息。