# Kafka 生产者
# 1. 生产者简介
不管是把 Kafka 作为消息队列系统、还是数据存储平台,总是需要一个可以向 Kafka 写入数据的生产者和一个可以从 Kafka 读取数据的消费者,或者是一个兼具两种角色的应用程序。
使用 Kafka 的场景很多,诉求也各有不同,主要有:是否允许丢失消息?是否接受重复消息?是否有严格的延迟和吞吐量要求?
不同的场景对于 Kafka 生产者 API 的使用和配置会有直接的影响。
# 1.1. 生产者传输实体
Kafka Producer 发送的数据对象叫做 ProducerRecord ,它有 4 个关键参数:
Topic- 主题Partition- 分区(非必填)Key- 键(非必填)Value- 值
# 1.2. 生产者发送流程
Kafka 生产者发送消息流程:
(1)序列化 - 发送前,生产者要先把键和值序列化。
(2)分区 - 数据被传给分区器。如果在 ProducerRecord 中已经指定了分区,那么分区器什么也不会做;否则,分区器会根据 ProducerRecord 的键来选择一个分区。选定分区后,生产者就知道该把消息发送给哪个主题的哪个分区。
(3)批次传输 - 接着,这条记录会被添加到一个记录批次中。这个批次中的所有消息都会被发送到相同的主题和分区上。有一个独立的线程负责将这些记录批次发送到相应 Broker 上。
- 批次,就是一组消息,这些消息属于同一个主题和分区。
- 发送时,会把消息分成批次传输,如果每次只发送一个消息,会占用大量的网路开销。
(4)响应 - 服务器收到消息会返回一个响应。
- 如果成功,则返回一个
RecordMetaData对象,它包含了主题、分区、偏移量; - 如果失败,则返回一个错误。生产者在收到错误后,可以进行重试,重试次数可以在配置中指定。失败一定次数后,就返回错误消息。
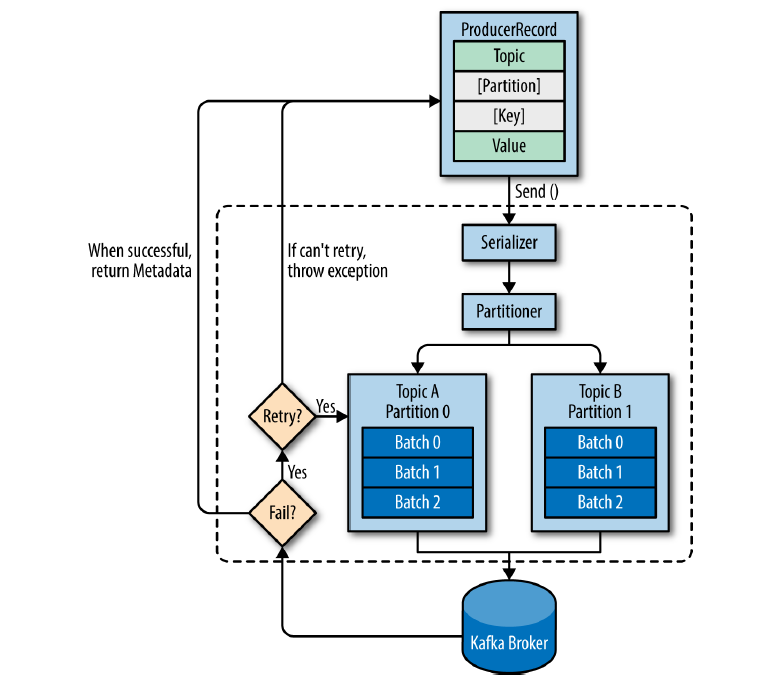
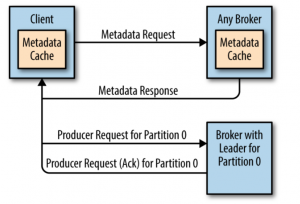
生产者向 Broker 发送消息时是怎么确定向哪一个 Broker 发送消息?
- 生产者会向任意 broker 发送一个元数据请求(
MetadataRequest),获取到每一个分区对应的 Leader 信息,并缓存到本地。 - 生产者在发送消息时,会指定 Partition 或者通过 key 得到到一个 Partition,然后根据 Partition 从缓存中获取相应的 Leader 信息。
# 2. 生产者 API
Kafka 的 Java 生产者 API 主要的对象就是 KafkaProducer。通常我们开发一个生产者的步骤有 4 步。
- 构造生产者对象所需的参数对象。
- 利用第 1 步的参数对象,创建
KafkaProducer对象实例。 - 使用
KafkaProducer的send方法发送消息。 - 调用
KafkaProducer的close方法关闭生产者并释放各种系统资源。
# 2.1. 创建生产者
Kafka 生产者核心配置:
bootstrap.servers- 指定了 Producer 启动时要连接的 Broker 地址。注:如果你指定了 1000 个 Broker 连接信息,那么,Producer 启动时就会首先创建与这 1000 个 Broker 的 TCP 连接。在实际使用过程中,并不建议把集群中所有的 Broker 信息都配置到bootstrap.servers中,通常你指定 3 ~ 4 台就足以了。因为 Producer 一旦连接到集群中的任一台 Broker,就能拿到整个集群的 Broker 信息,故没必要为bootstrap.servers指定所有的 Broker。key.serializer- 键的序列化器。value.serializer- 值的序列化器。
// 指定生产者的配置
final Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
// 设置 key 的序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置 value 的序列化器
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 使用配置初始化 Kafka 生产者
Producer<String, String> producer = new KafkaProducer<>(properties);
# 2.2. 异步发送
直接发送消息,不关心消息是否到达。
这种方式吞吐量最高,但有小概率会丢失消息。
【示例】异步发送
ProducerRecord<String, String> record =
new ProducerRecord<>("CustomerCountry", "Precision Products", "France");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
# 2.3. 同步发送
返回一个 Future 对象,调用 get() 方法,会一直阻塞等待 Broker 返回结果。
这是一种可靠传输方式,但吞吐量最差。
【示例】同步发送
ProducerRecord<String, String> record =
new ProducerRecord<>("CustomerCountry", "Precision Products", "France");
try {
producer.send(record).get();
} catch (Exception e) {
e.printStackTrace();
}
# 2.4. 异步响应发送
代码如下,异步方式相对于“发送并忽略返回”的方式的不同在于:在异步返回时可以执行一些操作,如:抛出异常、记录错误日志。
这是一个折中的方案,即兼顾吞吐量,也保证消息不丢失。
【示例】异步响应发送
首先,定义一个 callback:
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
}
}
}
然后,使用这个 callback:
ProducerRecord<String, String> record =
new ProducerRecord<>("CustomerCountry", "Biomedical Materials", "USA");
producer.send(record, new DemoProducerCallback());
# 2.5. 关闭连接
调用 producer.close() 方法可以关闭 Kafka 生产者连接。
Producer<String, String> producer = new KafkaProducer<>(properties);
try {
producer.send(new ProducerRecord<>(topic, msg));
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭连接
producer.close();
}
# 3. 生产者的连接
Apache Kafka 的所有通信都是基于 TCP 的。无论是生产者、消费者,还是 Broker 之间的通信都是如此。
选用 TCP 连接是由于 TCP 本身提供的一些高级功能,如多路复用请求以及同时轮询多个连接的能力。
# 3.1. 何时创建 TCP 连接
Kafka 生产者创建连接有三个时机:
(1)在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender 线程开始运行时,首先会创建与 bootstrap.servers 中所有 Broker 的 TCP 连接。
(2)当 Producer 更新集群的元数据信息之后,如果发现与某些 Broker 当前没有连接,那么它就会创建一个 TCP 连接。
- 场景一:当 Producer 尝试给一个不存在的主题发送消息时,Broker 会告诉 Producer 说这个主题不存在。此时 Producer 会发送 METADATA 请求给 Kafka 集群,去尝试获取最新的元数据信息。
- 场景二:Producer 通过
metadata.max.age.ms参数定期地去更新元数据信息。该参数的默认值是 300000,即 5 分钟,也就是说不管集群那边是否有变化,Producer 每 5 分钟都会强制刷新一次元数据以保证它是最及时的数据。
(3)当要发送消息时,Producer 发现尚不存在与目标 Broker 的连接,会创建一个 TCP 连接。
# 3.2. 何时关闭 TCP 连接
Producer 端关闭 TCP 连接的方式有两种:一种是用户主动关闭;一种是 Kafka 自动关闭。
主动关闭是指调用 producer.close() 方法来关闭生产者连接;甚至包括用户调用 kill -9 主动“杀掉”Producer 应用。
如果设置 Producer 端 connections.max.idle.ms 参数大于 0(默认为 9 分钟),意味着,在 connections.max.idle.ms 指定时间内,如果没有任何请求“流过”某个 TCP 连接,那么 Kafka 会主动帮你把该 TCP 连接关闭。如果设置该参数为 -1,TCP 连接将成为永久长连接。
值得注意的是,在第二种方式中,TCP 连接是在 Broker 端被关闭的,但其实这个 TCP 连接的发起方是客户端,因此在 TCP 看来,这属于被动关闭的场景,即 passive close。被动关闭的后果就是会产生大量的 CLOSE_WAIT 连接,因此 Producer 端或 Client 端没有机会显式地观测到此连接已被中断。
# 4. 序列化
Kafka 内置了常用 Java 基础类型的序列化器,如:StringSerializer、IntegerSerializer、DoubleSerializer 等。
但如果要传输较为复杂的对象,推荐使用序列化性能更高的工具,如:Avro、Thrift、Protobuf 等。
使用方式是通过实现 org.apache.kafka.common.serialization.Serializer 接口来引入自定义的序列化器。
# 5. 分区
# 5.1. 什么是分区
Kafka 的数据结构采用三级结构,即:主题(Topic)、分区(Partition)、消息(Record)。
在 Kafka 中,任意一个 Topic 维护了一组 Partition 日志,如下所示:
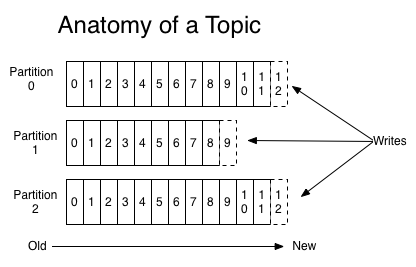
每个 Partition 都是一个单调递增的、不可变的日志记录,以不断追加的方式写入数据。Partition 中的每条记录会被分配一个单调递增的 id 号,称为偏移量(Offset),用于唯一标识 Partition 内的每条记录。
# 5.2. 为什么要分区
为什么 Kafka 的数据结构采用三级结构?
分区的作用就是提供负载均衡的能力,以实现系统的高伸缩性(Scalability)。
不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的机器节点来增加整体系统的吞吐量。
# 5.3. 分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法,也就是负载均衡算法。
前文中已经提到,Kafka 生产者发送消息使用的对象 ProducerRecord ,可以选填 Partition 和 Key。不过,大多数应用会用到 key。key 有两个作用:作为消息的附加信息;也可以用来决定消息该被写到 Topic 的哪个 Partition,拥有相同 key 的消息将被写入同一个 Partition。
如果 ProducerRecord 指定了 Partition,则分区器什么也不做,否则分区器会根据 key 选择一个 Partition 。
- 没有 key 时的分发逻辑:每隔
topic.metadata.refresh.interval.ms的时间,随机选择一个 partition。这个时间窗口内的所有记录发送到这个 partition。发送数据出错后会重新选择一个 partition。 - 根据 key 分发:Kafka 的选择分区策略是:根据 key 求 hash 值,然后将 hash 值对 partition 数量求模。这里的关键点在于,同一个 key 总是被映射到同一个 Partition 上。所以,在选择分区时,Kafka 会使用 Topic 的所有 Partition ,而不仅仅是可用的 Partition。这意味着,如果写入数据的 Partition 是不可用的,那么就会出错。
# 5.4. 自定义分区策略
如果 Kafka 的默认分区策略无法满足实际需要,可以自定义分区策略。需要显式地配置生产者端的参数 partitioner.class。这个参数该怎么设定呢?
首先,要实现 org.apache.kafka.clients.producer.Partitioner 接口。这个接口定义了两个方法:partition 和 close,通常只需要实现最重要的 partition 方法。我们来看看这个方法的方法签名:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
这里的 topic、key、keyBytes、value和 valueBytes 都属于消息数据,cluster 则是集群信息(比如当前 Kafka 集群共有多少主题、多少 Broker 等)。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。
接着,设置 partitioner.class 参数为自定义类的全限定名,那么生产者程序就会按照你的代码逻辑对消息进行分区。
负载均衡算法常见的有:
- 随机算法
- 轮询算法
- 最小活跃数算法
- 源地址哈希算法
可以根据实际需要去实现。
# 6. 压缩
# 6.1. Kafka 的消息格式
目前,Kafka 共有两大类消息格式,社区分别称之为 V1 版本和 V2 版本。V2 版本是 Kafka 0.11.0.0 中正式引入的。
不论是哪个版本,Kafka 的消息层次都分为两层:消息集合(message set)以及消息(message)。一个消息集合中包含若干条日志项(record item),而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
那么社区引入 V2 版本的目的是什么呢?V2 版本主要是针对 V1 版本的一些弊端做了修正。
在 V1 版本中,每条消息都需要执行 CRC 校验。但有些情况下消息的 CRC 值是会发生变化的。比如在 Broker 端可能会对消息时间戳字段进行更新,那么重新计算之后的 CRC 值也会相应更新;再比如 Broker 端在执行消息格式转换时(主要是为了兼容老版本客户端程序),也会带来 CRC 值的变化。鉴于这些情况,再对每条消息都执行 CRC 校验就有点没必要了,不仅浪费空间还耽误 CPU 时间。
因此,在 V2 版本中,只对消息集合执行 CRC 校验。V2 版本还有一个和压缩息息相关的改进,就是保存压缩消息的方法发生了变化。之前 V1 版本中保存压缩消息的方法是把多条消息进行压缩然后保存到外层消息的消息体字段中;而 V2 版本的做法是对整个消息集合进行压缩。显然后者应该比前者有更好的压缩效果。
# 6.2. Kafka 的压缩流程
Kafka 的压缩流程,一言以概之——Producer 端压缩、Broker 端保持、Consumer 端解压缩。
# 压缩过程
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。
生产者程序中配置 compression.type 参数即表示启用指定类型的压缩算法。
【示例】开启 GZIP 的 Producer 对象
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启 GZIP 压缩
props.put("compression.type", "gzip");
Producer<String, String> producer = new KafkaProducer<>(props);
通常,Broker 从 Producer 端接收到消息后,不做任何处理。以下两种情况除外:
情况一:Broker 端指定了和 Producer 端不同的压缩算法。显然,应该尽量避免这种情况。
情况二:Broker 端发生了消息格式转换。所谓的消息格式转换,主要是为了兼容老版本的消费者程序。在一个生产环境中,Kafka 集群中同时保存多种版本的消息格式非常常见。为了兼容老版本的格式,Broker 端会对新版本消息执行向老版本格式的转换。这个过程中会涉及消息的解压缩和重新压缩。一般情况下这种消息格式转换对性能是有很大影响的,除了这里的压缩之外,它还让 Kafka 丧失了引以为豪的 Zero Copy 特性。
所谓零拷贝,说的是当数据在磁盘和网络进行传输时避免昂贵的内核态数据拷贝,从而实现快速的数据传输。因此如果 Kafka 享受不到这个特性的话,性能必然有所损失,所以尽量保证消息格式的统一吧,这样不仅可以避免不必要的解压缩 / 重新压缩,对提升其他方面的性能也大有裨益。
# 解压缩的过程
通常来说解压缩发生在消费者程序中,也就是说 Producer 发送压缩消息到 Broker 后,Broker 照单全收并原样保存起来。当 Consumer 程序请求这部分消息时,Broker 依然原样发送出去,当消息到达 Consumer 端后,由 Consumer 自行解压缩还原成之前的消息。
那么现在问题来了,Consumer 怎么知道这些消息是用何种压缩算法压缩的呢?其实答案就在消息中。Kafka 会将启用了哪种压缩算法封装进消息集合中,这样当 Consumer 读取到消息集合时,它自然就知道了这些消息使用的是哪种压缩算法。
# 压缩算法
在 Kafka 2.1.0 版本之前,Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。从 2.1.0 开始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。
在实际使用中,GZIP、Snappy、LZ4 甚至是 zstd 的表现各有千秋。但对于 Kafka 而言,它们的性能测试结果却出奇得一致,即在吞吐量方面:LZ4 > Snappy > zstd 和 GZIP;而在压缩比方面,zstd > LZ4 > GZIP > Snappy。
如果客户端机器 CPU 资源有很多富余,强烈建议开启 zstd 压缩,这样能极大地节省网络资源消耗。
# 6.3. 何时启用压缩
何时启用压缩是比较合适的时机呢?
压缩是在 Producer 端完成的工作,那么启用压缩的一个条件就是 Producer 程序运行机器上的 CPU 资源要很充足。如果 Producer 运行机器本身 CPU 已经消耗殆尽了,那么启用消息压缩无疑是雪上加霜,只会适得其反。
如果环境中带宽资源有限,那么也建议开启压缩。
# 7. 幂等性
# 7.1. 什么是幂等性
幂等(idempotent、idempotence)是一个数学与计算机学概念,指的是:一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
# 7.2. Kafka Producer 的幂等性
在 Kafka 中,Producer 默认不是幂等性的,但我们可以创建幂等性 Producer。它其实是 0.11.0.0 版本引入的新功能。在此之前,Kafka 向分区发送数据时,可能会出现同一条消息被发送了多次,导致消息重复的情况。在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即 props.put(“enable.idempotence”, ture),或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
enable.idempotence 被设置成 true 后,Producer 自动升级成幂等性 Producer,其他所有的代码逻辑都不需要改变。Kafka 自动帮你做消息的去重。底层具体的原理很简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉。当然,实际的实现原理并没有这么简单,但你大致可以这么理解。
我们必须要了解幂等性 Producer 的作用范围:
- 首先,
enable.idempotence只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。 - 其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
如果想实现多分区以及多会话上的消息无重复,应该怎么做呢?答案就是事务(transaction)或者依赖事务型 Producer。这也是幂等性 Producer 和事务型 Producer 的最大区别!
# 7.3. PID 和 Sequence Number
为了实现 Producer 的幂等性,Kafka 引入了 Producer ID(即 PID)和 Sequence Number。
- PID。每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个 PID 对用户是不可见的。
- Sequence Numbler。对于每个 PID,该 Producer 发送数据的每个
<Topic, Partition>都对应一个从 0 开始单调递增的 Sequence Number。
Broker 端在缓存中保存了这 seq number,对于接收的每条消息,如果其序号比 Broker 缓存中序号大于 1 则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个 Producer 对于同一个 <Topic, Partition> 的 Exactly Once 语义。不能保证同一个 Producer 一个 topic 不同的 partion 幂等。
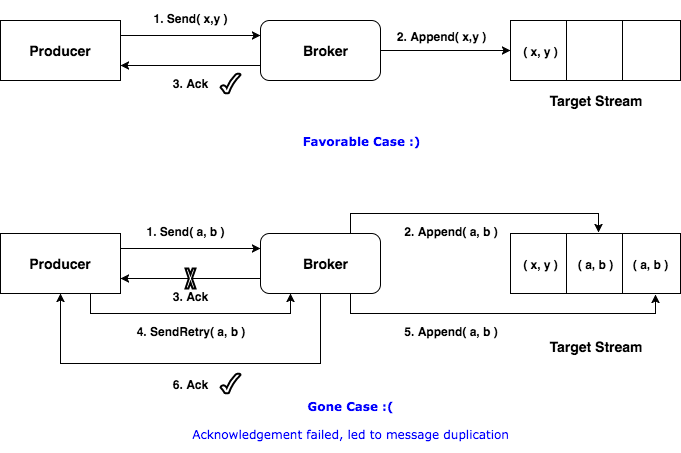 实现幂等之后:
实现幂等之后:
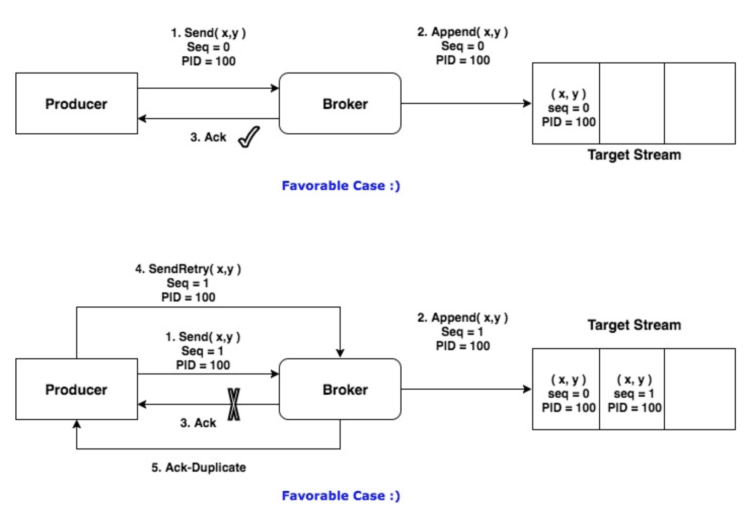
# 7.4. 生成 PID 的流程
在执行创建事务时,如下:
Producer<String, String> producer = new KafkaProducer<String, String>(props);
会创建一个 Sender,并启动线程,执行如下 run 方法,在 maybeWaitForProducerId()中生成一个 producerId,如下:
====================================
类名:Sender
====================================
void run(long now) {
if (transactionManager != null) {
try {
........
if (!transactionManager.isTransactional()) {
// 为idempotent producer生成一个producer id
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
........
# 7.5. 幂等性的应用实例
(1)配置属性
需要设置:
enable.idempotence,需要设置为 ture,此时就会默认把 acks 设置为 all,所以不需要再设置 acks 属性了。
// 指定生产者的配置
final Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
// 设置 key 的序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置 value 的序列化器
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启幂等性
properties.put("enable.idempotence", true);
// 设置重试次数
properties.put("retries", 3);
//Reduce the no of requests less than 0
properties.put("linger.ms", 1);
// buffer.memory 控制生产者可用于缓冲的内存总量
properties.put("buffer.memory", 33554432);
// 使用配置初始化 Kafka 生产者
producer = new KafkaProducer<>(properties);
(2)发送消息
跟一般生产者一样,如下
public void produceIdempotMessage(String topic, String message) {
// 创建Producer
Producer producer = buildIdempotProducer();
// 发送消息
producer.send(new ProducerRecord<String, String>(topic, message));
producer.flush();
}
此时,因为我们并没有配置 transaction.id 属性,所以不能使用事务相关 API,如下
producer.initTransactions();
否则会出现如下错误:
Exception in thread “main” java.lang.IllegalStateException: Transactional method invoked on a non-transactional producer.
at org.apache.kafka.clients.producer.internals.TransactionManager.ensureTransactional(TransactionManager.java:777)
at org.apache.kafka.clients.producer.internals.TransactionManager.initializeTransactions(TransactionManager.java:202)
at org.apache.kafka.clients.producer.KafkaProducer.initTransactions(KafkaProducer.java:544)
# 8. Kafka 事务
Kafka 的事务概念是指一系列的生产者生产消息和消费者提交偏移量的操作在一个事务,或者说是是一个原子操作),同时成功或者失败。
消息可靠性保障,由低到高为:
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
Kafka 支持事务功能主要是为了实现精确一次处理语义的,而精确一次处理是实现流处理的基石。
# 8.1. 事务
Kafka 自 0.11 版本开始提供了对事务的支持,目前主要是在 read committed 隔离级别上做事情。它能保证多条消息原子性地写入到目标分区,同时也能保证 Consumer 只能看到事务成功提交的消息。
# 8.2. 事务型 Producer
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
事务属性实现前提是幂等性,即在配置事务属性 transaction.id 时,必须还得配置幂等性;但是幂等性是可以独立使用的,不需要依赖事务属性。
在事务属性之前先引入了生产者幂等性,它的作用为:
- 生产者多次发送消息可以封装成一个原子操作,要么都成功,要么失败。
- consumer-transform-producer 模式下,因为消费者提交偏移量出现问题,导致重复消费。需要将这个模式下消费者提交偏移量操作和生产者一系列生成消息的操作封装成一个原子操作。
消费者提交偏移量导致重复消费消息的场景:消费者在消费消息完成提交便宜量 o2 之前挂掉了(假设它最近提交的偏移量是 o1),此时执行再均衡时,其它消费者会重复消费消息(o1 到 o2 之间的消息)。
# 8.3. 事务操作的 API
Producer 提供了 initTransactions, beginTransaction, sendOffsets, commitTransaction, abortTransaction 五个事务方法。
/**
* 初始化事务。需要注意的有:
* 1、前提
* 需要保证transation.id属性被配置。
* 2、这个方法执行逻辑是:
* (1)Ensures any transactions initiated by previous instances of the producer with the same
* transactional.id are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion,
* but not yet finished, this method awaits its completion.
* (2)Gets the internal producer id and epoch, used in all future transactional
* messages issued by the producer.
*
*/
public void initTransactions();
/**
* 开启事务
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* 为消费者提供的在事务内提交偏移量的操作
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException ;
/**
* 提交事务
*/
public void commitTransaction() throws ProducerFencedException;
/**
* 放弃事务,类似回滚事务的操作
*/
public void abortTransaction() throws ProducerFencedException ;
# 8.4. Kafka 事务相关配置
使用 kafka 的事务 api 时的一些注意事项:
- 需要消费者的自动模式设置为 false,并且不能子再手动的进行执行
consumer#commitSync或者consumer#commitAsyc - 设置 Producer 端参数
transctional.id。最好为其设置一个有意义的名字。 - 和幂等性 Producer 一样,开启
enable.idempotence = true。如果配置了transaction.id,则此时enable.idempotence会被设置为 true - 消费者需要配置事务隔离级别
isolation.level。在consume-trnasform-produce模式下使用事务时,必须设置为READ_COMMITTED。read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
# 8.5. Kafka 事务应用示例
# 只有生成操作
创建一个事务,在这个事务操作中,只有生成消息操作。代码如下:
/**
* 在一个事务只有生产消息操作
*/
public void onlyProduceInTransaction() {
Producer producer = buildProducer();
// 1.初始化事务
producer.initTransactions();
// 2.开启事务
producer.beginTransaction();
try {
// 3.kafka写操作集合
// 3.1 do业务逻辑
// 3.2 发送消息
producer.send(new ProducerRecord<String, String>("test", "transaction-data-1"));
producer.send(new ProducerRecord<String, String>("test", "transaction-data-2"));
// 3.3 do其他业务逻辑,还可以发送其他topic的消息。
// 4.事务提交
producer.commitTransaction();
} catch (Exception e) {
// 5.放弃事务
producer.abortTransaction();
}
}
创建生产者,代码如下,需要:
- 配置
transactional.id属性 - 配置
enable.idempotence属性
/**
* 需要:
* 1、设置transactional.id
* 2、设置enable.idempotence
* @return
*/
private Producer buildProducer() {
// create instance for properties to access producer configs
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", "localhost:9092");
// 设置事务id
props.put("transactional.id", "first-transactional");
// 设置幂等性
props.put("enable.idempotence",true);
//Set acknowledgements for producer requests.
props.put("acks", "all");
//If the request fails, the producer can automatically retry,
props.put("retries", 1);
//Specify buffer size in config,这里不进行设置这个属性,如果设置了,还需要执行producer.flush()来把缓存中消息发送出去
//props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
// Kafka消息是以键值对的形式发送,需要设置key和value类型序列化器
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
return producer;
}
# 消费-生产并存(consume-transform-produce)
在一个事务中,既有生产消息操作又有消费消息操作,即常说的 Consume-tansform-produce 模式。如下实例代码
/**
* 在一个事务内,即有生产消息又有消费消息
*/
public void consumeTransferProduce() {
// 1.构建上产者
Producer producer = buildProducer();
// 2.初始化事务(生成productId),对于一个生产者,只能执行一次初始化事务操作
producer.initTransactions();
// 3.构建消费者和订阅主题
Consumer consumer = buildConsumer();
consumer.subscribe(Arrays.asList("test"));
while (true) {
// 4.开启事务
producer.beginTransaction();
// 5.1 接受消息
ConsumerRecords<String, String> records = consumer.poll(500);
try {
// 5.2 do业务逻辑;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = Maps.newHashMap();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 读取消息,并处理消息。print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 5.2.2 记录提交的偏移量
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
// 6.生产新的消息。比如外卖订单状态的消息,如果订单成功,则需要发送跟商家结转消息或者派送员的提成消息
producer.send(new ProducerRecord<String, String>("test", "data2"));
}
// 7.提交偏移量
producer.sendOffsetsToTransaction(commits, "group0323");
// 8.事务提交
producer.commitTransaction();
} catch (Exception e) {
// 7.放弃事务
producer.abortTransaction();
}
}
}
创建消费者代码,需要:
- 将配置中的自动提交属性(auto.commit)进行关闭
- 而且在代码里面也不能使用手动提交 commitSync( )或者 commitAsync( )
- 设置 isolation.level
/**
* 需要:
* 1、关闭自动提交 enable.auto.commit
* 2、isolation.level为
* @return
*/
public Consumer buildConsumer() {
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", "localhost:9092");
// 消费者群组
props.put("group.id", "group0323");
// 设置隔离级别
props.put("isolation.level","read_committed");
// 关闭自动提交
props.put("enable.auto.commit", "false");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
return consumer;
}
# 只有消费操作
创建一个事务,在这个事务操作中,只有生成消息操作,如下代码。这种操作其实没有什么意义,跟使用手动提交效果一样,无法保证消费消息操作和提交偏移量操作在一个事务。
/**
* 在一个事务只有消息操作
*/
public void onlyConsumeInTransaction() {
Producer producer = buildProducer();
// 1.初始化事务
producer.initTransactions();
// 2.开启事务
producer.beginTransaction();
// 3.kafka读消息的操作集合
Consumer consumer = buildConsumer();
while (true) {
// 3.1 接受消息
ConsumerRecords<String, String> records = consumer.poll(500);
try {
// 3.2 do业务逻辑;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = Maps.newHashMap();
for (ConsumerRecord<String, String> record : records) {
// 3.2.1 处理消息 print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 3.2.2 记录提交偏移量
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
}
// 4.提交偏移量
producer.sendOffsetsToTransaction(commits, "group0323");
// 5.事务提交
producer.commitTransaction();
} catch (Exception e) {
// 6.放弃事务
producer.abortTransaction();
}
}
}
# 9. 生产者的配置
更详尽的生产者配置可以参考:Kafka 生产者官方配置说明 (opens new window)
以下为生产者主要配置参数清单:
acks:指定了必须有多少个分区副本收到消息,生产者才会认为消息写入是成功的。默认为acks=1acks=0如果设置为 0,则 Producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。acks=1如果设置为 1,leader 节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。acks=all如果设置为 all,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1 与 acks=all 是等效的。
buffer.memory:用来设置 Producer 缓冲区大小。compression.type:Producer 生成数据时可使用的压缩类型。默认值是 none(即不压缩)。可配置的压缩类型包括:none、gzip、snappy、lz4或zstd。压缩是针对批处理的所有数据,所以批处理的效果也会影响压缩比(更多的批处理意味着更好的压缩)。retries:用来设置发送失败的重试次数。batch.size:用来设置一个批次可占用的内存大小。linger.ms:用来设置 Producer 在发送批次前的等待时间。client.id:Kafka 服务器用它来识别消息源,可以是任意字符串。max.in.flight.requests.per.connection:用来设置 Producer 在收到服务器响应前可以发送多少个消息。timeout.ms:用来设置 Broker 等待同步副本返回消息确认的时间,与acks的配置相匹配。request.timeout.ms:Producer 在发送数据时等待服务器返回响应的时间。metadata.fetch.timeout.ms:Producer 在获取元数据时(如:分区的 Leader 是谁)等待服务器返回响应的时间。max.block.ms:该配置控制KafkaProducer.send()和KafkaProducer.partitionsFor()允许被阻塞的时长。这些方法可能因为缓冲区满了或者元数据不可用而被阻塞。用户提供的序列化程序或分区程序的阻塞将不会被计算到这个超时。max.request.size:请求的最大字节数。receieve.buffer.bytes:TCP 接收缓冲区的大小。send.buffer.bytes:TCP 发送缓冲区的大小。
# 10. 参考资料
- 官方
- 书籍
- 教程
- 文章