Spring MVC 之 DispatcherServlet 简介 DispatcherServlet 是 Spring MVC 框架的核心组件,负责将客户端请求映射到相应的控制器,然后调用控制器处理请求并返回响应结果 。
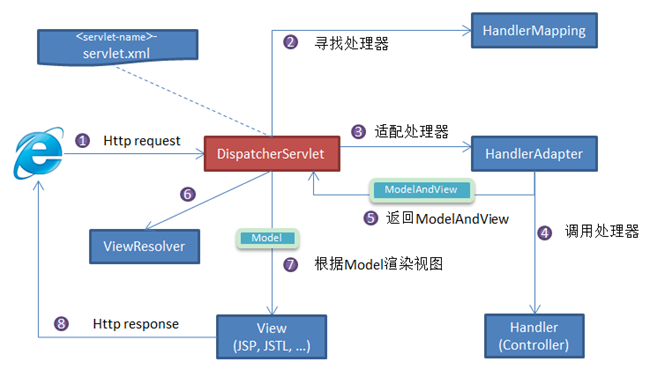
DispatcherServlet 工作原理 DispatcherServlet 工作流程 DispatcherServlet 的工作流程大致如下图所示:
接收 Http 请求 :当客户端发送 HTTP 请求时,DispatcherServlet 接收该请求并将其传递给 Spring MVC 框架。**选择 Handler**:DispatcherServlet 会根据请求的 URL 找到对应的处理器映射器 HandlerMapping,该映射器会根据配置文件中的 URL 映射规则找到合适的处理器 Handler。
绑定属性 :DispatcherServlet 会根据程序的 web 初始化策略关联各种 Resolver,如:LocaleResolver、ThemeResolver 等。DispatcherServlet 根据 <servlet-name>-servlet.xml 中的配置对请求的 URL 进行解析,得到请求资源标识符(URI)。然后根据该 URI,调用 HandlerMapping 获得该 Handler 配置的所有相关的对象(包括 Handler 对象以及 Handler 对象对应的拦截器),最后以HandlerExecutionChain 对象的形式返回。
将请求映射到处理程序以及用于预处理和后处理的拦截器列表。映射基于一些标准,其细节因 HandlerMapping 实现而异。
两个主要的 HandlerMapping 实现是 RequestMappingHandlerMapping(支持 @RequestMapping 注释方法)和 SimpleUrlHandlerMapping(维护 URI 路径模式到处理程序的显式注册)。
**选择 HandlerAdapter**: DispatcherServlet 根据获得的 Handler,选择一个合适的 HandlerAdapter。
HandlerAdapter 帮助 DispatcherServlet 调用映射到请求的 Handler,而不管实际调用 Handler 的方式如何。例如,调用带注解的控制器需要解析注解。HandlerAdapter 的主要目的是保护 DispatcherServlet 免受此类细节的影响。
Handler 处理请求DispatcherServlet 提取 Request 中的模型数据,填充 Handler 入参,由 HandlerAdapter 负责调用 Handler(Controller)。 在填充 Handler 的入参过程中,根据你的配置,Spring 将帮你做一些额外的工作:
HttpMessageConverter: 将请求消息(如 Json、xml 等数据)转换成一个对象,将对象转换为指定的响应信息。数据转换:对请求消息进行数据转换。如 String 转换成 Integer、Double 等。
数据格式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等。
数据验证: 验证数据的有效性(长度、格式等),验证结果存储到 BindingResult 或 Error 中。
返回 ModelAndView 对象 :Handler 处理完请求后,会返回一个 ModelAndView 对象,其中包含了处理结果(Model)和视图(View)信息。**选择 ViewResolver 渲染 ModelAndView**:根据返回的 ModelAndView,选择一个适合的 ViewResolver,并将 ModelAndView 传递给 ViewResolver 进行渲染,最后将渲染后的结果返回给客户端。
DispatcherServlet 源码解读 前面介绍了 DispatcherServlet 的工作流程,下面通过核心源码解读,来加深对 DispatcherServlet 工作原理的理解
(1)onRefresh 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override protected void onRefresh (ApplicationContext context) { initStrategies(context); } protected void initStrategies (ApplicationContext context) { initMultipartResolver(context); initLocaleResolver(context); initThemeResolver(context); initHandlerMappings(context); initHandlerAdapters(context); initHandlerExceptionResolvers(context); initRequestToViewNameTranslator(context); initViewResolvers(context); initFlashMapManager(context); }
(2)doService 方法
DispatcherServlet 的核心方法 doService 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @Override protected void doService (HttpServletRequest request, HttpServletResponse response) throws Exception { logRequest(request); Map<String, Object> attributesSnapshot = null ; if (WebUtils.isIncludeRequest(request)) { attributesSnapshot = new HashMap <>(); Enumeration<?> attrNames = request.getAttributeNames(); while (attrNames.hasMoreElements()) { String attrName = (String) attrNames.nextElement(); if (this .cleanupAfterInclude || attrName.startsWith(DEFAULT_STRATEGIES_PREFIX)) { attributesSnapshot.put(attrName, request.getAttribute(attrName)); } } } request.setAttribute(WEB_APPLICATION_CONTEXT_ATTRIBUTE, getWebApplicationContext()); request.setAttribute(LOCALE_RESOLVER_ATTRIBUTE, this .localeResolver); request.setAttribute(THEME_RESOLVER_ATTRIBUTE, this .themeResolver); request.setAttribute(THEME_SOURCE_ATTRIBUTE, getThemeSource()); if (this .flashMapManager != null ) { FlashMap inputFlashMap = this .flashMapManager.retrieveAndUpdate(request, response); if (inputFlashMap != null ) { request.setAttribute(INPUT_FLASH_MAP_ATTRIBUTE, Collections.unmodifiableMap(inputFlashMap)); } request.setAttribute(OUTPUT_FLASH_MAP_ATTRIBUTE, new FlashMap ()); request.setAttribute(FLASH_MAP_MANAGER_ATTRIBUTE, this .flashMapManager); } RequestPath previousRequestPath = null ; if (this .parseRequestPath) { previousRequestPath = (RequestPath) request.getAttribute(ServletRequestPathUtils.PATH_ATTRIBUTE); ServletRequestPathUtils.parseAndCache(request); } try { doDispatch(request, response); } finally { if (!WebAsyncUtils.getAsyncManager(request).isConcurrentHandlingStarted()) { if (attributesSnapshot != null ) { restoreAttributesAfterInclude(request, attributesSnapshot); } } if (this .parseRequestPath) { ServletRequestPathUtils.setParsedRequestPath(previousRequestPath, request); } } }
(3)doDispatch 方法
doService 中的核心方法是 doDispatch,负责分发请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 protected void doDispatch (HttpServletRequest request, HttpServletResponse response) throws Exception { HttpServletRequest processedRequest = request; HandlerExecutionChain mappedHandler = null ; boolean multipartRequestParsed = false ; WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request); try { ModelAndView mv = null ; Exception dispatchException = null ; try { processedRequest = checkMultipart(request); multipartRequestParsed = (processedRequest != request); mappedHandler = getHandler(processedRequest); if (mappedHandler == null ) { noHandlerFound(processedRequest, response); return ; } HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler()); String method = request.getMethod(); boolean isGet = HttpMethod.GET.matches(method); if (isGet || HttpMethod.HEAD.matches(method)) { long lastModified = ha.getLastModified(request, mappedHandler.getHandler()); if (new ServletWebRequest (request, response).checkNotModified(lastModified) && isGet) { return ; } } if (!mappedHandler.applyPreHandle(processedRequest, response)) { return ; } mv = ha.handle(processedRequest, response, mappedHandler.getHandler()); if (asyncManager.isConcurrentHandlingStarted()) { return ; } applyDefaultViewName(processedRequest, mv); mappedHandler.applyPostHandle(processedRequest, response, mv); } catch (Exception ex) { dispatchException = ex; } catch (Throwable err) { dispatchException = new NestedServletException ("Handler dispatch failed" , err); } processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException); } catch (Exception ex) { triggerAfterCompletion(processedRequest, response, mappedHandler, ex); } catch (Throwable err) { triggerAfterCompletion(processedRequest, response, mappedHandler, new NestedServletException ("Handler processing failed" , err)); } finally { if (asyncManager.isConcurrentHandlingStarted()) { if (mappedHandler != null ) { mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response); } } else { if (multipartRequestParsed) { cleanupMultipart(processedRequest); } } } }
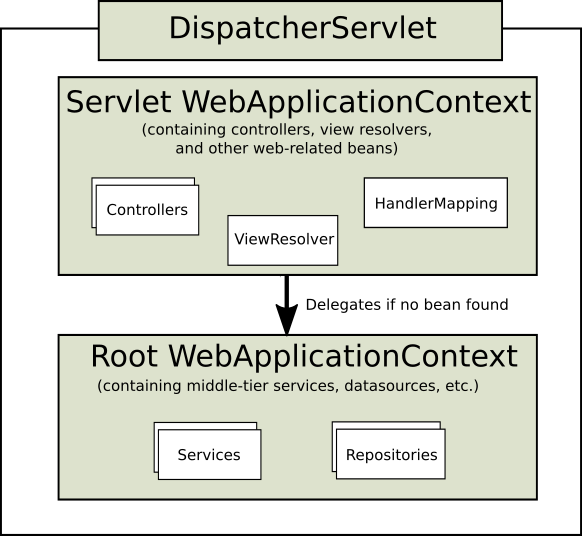
上下文层次结构 DispatcherServlet 需要一个 WebApplicationContext(ApplicationContext 的扩展类)用于它自己的配置。WebApplicationContext 有一个指向 ServletContext 和与之关联的 Servlet 的链接。它还绑定到 ServletContext,以便应用程序可以在 RequestContextUtils 上使用静态方法来查找 WebApplicationContext。
对于多数应用程序来说,拥有一个 WebApplicationContext 单例就足够。也可以有一个上下文层次结构,其中有一个根 WebApplicationContext 在多个 DispatcherServlet(或其他 Servlet)实例之间共享,每个实例都有自己的子 WebApplicationContext 配置。
根 WebApplicationContext 通常包含基础结构 bean,例如需要跨多个 Servlet 实例共享的数据存储和业务服务。这些 bean 是有效继承的,并且可以在特定 Servlet 的子 WebApplicationContext 中被覆盖(即重新声明),它通常包含指定 Servlet 的本地 bean。下图显示了这种关系:
【示例】配置 WebApplicationContext 层次结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MyWebAppInitializer extends AbstractAnnotationConfigDispatcherServletInitializer { @Override protected Class<?>[] getRootConfigClasses() { return new Class <?>[] { RootConfig.class }; } @Override protected Class<?>[] getServletConfigClasses() { return new Class <?>[] { App1Config.class }; } @Override protected String[] getServletMappings() { return new String [] { "/app1/*" }; } }
【示例】web.xml 方式配置 WebApplicationContext 层次结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <web-app > <listener > <listener-class > org.springframework.web.context.ContextLoaderListener</listener-class > </listener > <context-param > <param-name > contextConfigLocation</param-name > <param-value > /WEB-INF/root-context.xml</param-value > </context-param > <servlet > <servlet-name > app1</servlet-name > <servlet-class > org.springframework.web.servlet.DispatcherServlet</servlet-class > <init-param > <param-name > contextConfigLocation</param-name > <param-value > /WEB-INF/app1-context.xml</param-value > </init-param > <load-on-startup > 1</load-on-startup > </servlet > <servlet-mapping > <servlet-name > app1</servlet-name > <url-pattern > /app1/*</url-pattern > </servlet-mapping > </web-app >
配置 DispatcherServlet 与其他 Servlet 一样,需要使用 Java 配置或在 web.xml 中根据 Servlet 规范进行声明和映射。也就是说,DispatcherServlet 使用 Spring 配置来发现请求映射、视图解析、异常处理等所需的委托组件。
可以通过将 Servlet 初始化参数(init-param 元素)添加到 web.xml 文件中的 Servlet 声明来自定义各个 DispatcherServlet 实例。下表列出了支持的参数:
参数
说明
contextClass实现 ConfigurableWebApplicationContext 的类,将由此 Servlet 实例化和本地配置。默认情况下,使用 XmlWebApplicationContext。
contextConfigLocation传递给上下文实例(由 contextClass 指定)以指示可以在何处找到上下文的字符串。该字符串可能包含多个字符串(使用逗号作为分隔符)以支持多个上下文。在具有两次定义的 bean 的多个上下文位置的情况下,最新的位置优先。
namespaceWebApplicationContext 的命名空间。默认为 [servlet-name]-servlet。
throwExceptionIfNoHandlerFound当找不到请求的处理程序时是否抛出 NoHandlerFoundException。然后可以使用 HandlerExceptionResolver(例如,通过使用 @ExceptionHandler 控制器方法)捕获异常并像其他任何方法一样处理。默认情况下,它设置为 false,在这种情况下,DispatcherServlet 设置响应状态为 404 (NOT_FOUND) 而不会引发异常。请注意,如果 [默认 servlet 处理](https://docs.spring.io/spring-framework/docs/current/reference/html/web.html#mvc -default-servlet-handler) 也被配置,未解决的请求总是转发到默认的 servlet 并且永远不会引发 404。
应用程序可以声明处理请求所需的特殊 Bean 类型中列出的基础结构 bean。DispatcherServlet 检查每个特殊 bean 的 WebApplicationContext。如果没有匹配的 bean 类型,它将回退到 DispatcherServlet.properties 中列出的默认类型。
在大多数情况下,MVC 配置是最好的起点。它以 Java 或 XML 声明所需的 bean,并提供更高级别的配置回调 API 来对其进行自定义。
注意:Spring Boot 依赖于 MVC Java 配置来配置 Spring MVC,并提供了许多额外的方便选项。
在 Servlet 环境中,您可以选择以编程方式配置 Servlet 容器作为替代方案或与 web.xml 文件结合使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import org.springframework.web.WebApplicationInitializer;public class MyWebApplicationInitializer implements WebApplicationInitializer { @Override public void onStartup (ServletContext container) { XmlWebApplicationContext appContext = new XmlWebApplicationContext (); appContext.setConfigLocation("/WEB-INF/spring/dispatcher-config.xml" ); ServletRegistration.Dynamic registration = container.addServlet("dispatcher" , new DispatcherServlet (appContext)); registration.setLoadOnStartup(1 ); registration.addMapping("/" ); } }
WebApplicationInitializer 是 Spring MVC 提供的接口,可确保检测到自定义的实现并自动用于初始化任何 Servlet 3 容器。名为 AbstractDispatcherServletInitializer 的 WebApplicationInitializer 的抽象基类实现通过覆盖方法来指定 servlet 映射和 DispatcherServlet 配置的位置,使得注册 DispatcherServlet 变得更加容易。
对于使用基于 Java 的 Spring 配置的应用程序,建议这样做,如以下示例所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MyWebAppInitializer extends AbstractAnnotationConfigDispatcherServletInitializer { @Override protected Class<?>[] getRootConfigClasses() { return null ; } @Override protected Class<?>[] getServletConfigClasses() { return new Class <?>[] { MyWebConfig.class }; } @Override protected String[] getServletMappings() { return new String [] { "/" }; } }
如果使用基于 XML 的 Spring 配置,则应直接从 AbstractDispatcherServletInitializer 扩展,如以下示例所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class MyWebAppInitializer extends AbstractDispatcherServletInitializer { @Override protected WebApplicationContext createRootApplicationContext () { return null ; } @Override protected WebApplicationContext createServletApplicationContext () { XmlWebApplicationContext cxt = new XmlWebApplicationContext (); cxt.setConfigLocation("/WEB-INF/spring/dispatcher-config.xml" ); return cxt; } @Override protected String[] getServletMappings() { return new String [] { "/" }; } }
AbstractDispatcherServletInitializer 还提供了一种方便的方法来添加 Filter 实例并将它们自动映射到 DispatcherServlet,如以下示例所示:
1 2 3 4 5 6 7 8 9 10 public class MyWebAppInitializer extends AbstractDispatcherServletInitializer { @Override protected Filter[] getServletFilters() { return new Filter [] { new HiddenHttpMethodFilter (), new CharacterEncodingFilter () }; } }
每个过滤器都根据其具体类型添加一个默认名称,并自动映射到 DispatcherServlet。
AbstractDispatcherServletInitializer 的 isAsyncSupported 保护方法提供了一个单独的位置来启用 DispatcherServlet 和映射到它的所有过滤器的异步支持。默认情况下,此标志设置为 true。
最后,如果需要进一步自定义 DispatcherServlet 本身,可以重写 createDispatcherServlet 方法。
【示例】Java 方式注册并初始化 DispatcherServlet,它由 Servlet 容器自动检测(请参阅 Servlet Config):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class MyWebApplicationInitializer implements WebApplicationInitializer { @Override public void onStartup (ServletContext servletContext) { AnnotationConfigWebApplicationContext context = new AnnotationConfigWebApplicationContext (); context.register(AppConfig.class); DispatcherServlet servlet = new DispatcherServlet (context); ServletRegistration.Dynamic registration = servletContext.addServlet("app" , servlet); registration.setLoadOnStartup(1 ); registration.addMapping("/app/*" ); } }
【示例】web.xml 方式注册并初始化 DispatcherServlet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <web-app > <listener > <listener-class > org.springframework.web.context.ContextLoaderListener</listener-class > </listener > <context-param > <param-name > contextConfigLocation</param-name > <param-value > /WEB-INF/app-context.xml</param-value > </context-param > <servlet > <servlet-name > app</servlet-name > <servlet-class > org.springframework.web.servlet.DispatcherServlet</servlet-class > <init-param > <param-name > contextConfigLocation</param-name > <param-value > </param-value > </init-param > <load-on-startup > 1</load-on-startup > </servlet > <servlet-mapping > <servlet-name > app</servlet-name > <url-pattern > /app/*</url-pattern > </servlet-mapping > </web-app >
路径匹配 Servlet API 将完整的请求路径公开为 requestURI,并将其进一步细分为 contextPath、servletPath 和 pathInfo,它们的值因 Servlet 的映射方式而异。从这些输入中,Spring MVC 需要确定用于映射处理程序的查找路径,如果适用,它应该排除 contextPath 和任何 servletMapping 前缀。
servletPath 和 pathInfo 已解码,这使得它们无法直接与完整的 requestURI 进行比较以派生 lookupPath,因此有必要对 requestURI 进行解码。然而,这引入了它自己的问题,因为路径可能包含编码的保留字符,例如 "/" 或 ";" 这反过来又会在解码后改变路径的结构,这也可能导致安全问题。此外,Servlet 容器可能会在不同程度上规范化 servletPath,这使得进一步无法对 requestURI 执行 startsWith 比较。
这就是为什么最好避免依赖基于前缀的 servletPath 映射类型附带的 servletPath。如果 DispatcherServlet 被映射为带有 "/" 的默认 Servlet,或者没有带 "/*" 的前缀,并且 Servlet 容器是 4.0+,则 Spring MVC 能够检测 Servlet 映射类型,并避免使用 servletPath 和 pathInfo。在 3.1 Servlet 容器上,假设相同的 Servlet 映射类型,可以通过在 MVC 配置中通过路径匹配提供一个带有 alwaysUseFullPath=true 的 UrlPathHelper 来实现等效。
幸运的是,默认的 Servlet 映射 "/" 是一个不错的选择。但是,仍然存在一个问题,即需要对 requestURI 进行解码才能与控制器映射进行比较。这也是不可取的,因为可能会解码改变路径结构的保留字。如果不需要这样的字符,那么您可以拒绝它们(如 Spring Security HTTP 防火墙),或者您可以使用 urlDecode=false 配置 UrlPathHelper,但控制器映射需要与编码路径匹配,这可能并不总是有效。此外,有时 DispatcherServlet 需要与另一个 Servlet 共享 URL 空间,并且可能需要通过前缀进行映射。
在使用 PathPatternParser 和解析模式时解决了上述问题,作为使用 AntPathMatcher 进行字符串路径匹配的替代方法。PathPatternParser 从 5.3 版本开始就可以在 Spring MVC 中使用,并且从 6.0 版本开始默认启用。与需要解码查找路径或编码控制器映射的 AntPathMatcher 不同,解析的 PathPattern 与称为 RequestPath 的路径的解析表示匹配,一次一个路径段。这允许单独解码和清理路径段值,而没有改变路径结构的风险。解析的 PathPattern 也支持使用 servletPath 前缀映射,只要使用 Servlet 路径映射并且前缀保持简单,即它没有编码字符。
拦截器 所有 HandlerMapping 实现都支持处理拦截器,当想要将特定功能应用于某些请求时,这些拦截器很有用——例如,检查主体。拦截器必须使用 org.springframework.web.servlet 包中的三个方法实现 HandlerInterceptor,这三个方法应该提供足够的灵活性来进行各种预处理和后处理:
preHandle(..):在实际 handler 之前执行postHandle(..):handler 之后执行afterCompletion(..):完成请求后执行
preHandle(..) 方法返回一个布尔值。可以使用此方法中断或继续执行链的处理。当此方法返回 true 时,处理程序执行链将继续。当它返回 false 时,DispatcherServlet 假定拦截器本身已经处理请求(并且,例如,呈现适当的视图)并且不会继续执行其他拦截器和执行链中的实际处理程序。
有关如何配置拦截器的示例,请参阅 MVC 配置部分中的拦截器 。还可以通过在各个 HandlerMapping 实现上使用 setter 来直接注册它们。
postHandle 方法对于 @ResponseBody 和 ResponseEntity 的方法不太有用,它们的响应是在 HandlerAdapter 中和 postHandle 之前编写和提交的。这意味着对响应进行任何更改都为时已晚,例如添加额外的标头。对于此类场景,您可以实现 ResponseBodyAdvice 并将其声明为 Controller Advice bean 或直接在 RequestMappingHandlerAdapter 上进行配置。
解析器 DispatcherServlet 会加载多种解析器来处理请求,比较常见的有以下几个:
HandlerExceptionResolver 在 WebApplicationContext 中声明的 HandlerExceptionResolver 用于解决请求处理期间抛出的异常。这些异常解析器允许自定义逻辑来解决异常。
对于 HTTP 缓存支持,处理程序可以使用 WebRequest 的 checkNotModified 方法,以及用于控制器的 HTTP 缓存中所述的带注释控制器的更多选项。
如果在请求映射期间发生异常或从请求处理程序(例如 @Controller)抛出异常,则 DispatcherServlet 委托 HandlerExceptionResolver 链来解决异常并提供替代处理,这通常是错误响应。
下表列出了可用的 HandlerExceptionResolver 实现:
HandlerExceptionResolver说明
SimpleMappingExceptionResolver异常类名称和错误视图名称之间的映射。用于在浏览器应用程序中呈现错误页面。
DefaultHandlerExceptionResolver解决由 Spring MVC 引发的异常并将它们映射到 HTTP 状态代码。
ResponseStatusExceptionResolver使用 @ResponseStatus 注解解决异常,并根据注解中的值将它们映射到 HTTP 状态代码。
ExceptionHandlerExceptionResolver通过在 @Controller 或 @ControllerAdvice 类中调用 @ExceptionHandler 方法来解决异常。
解析器链 您可以通过在 Spring 配置中声明多个 HandlerExceptionResolver bean 并根据需要设置它们的顺序属性来构成异常解析器链。order 属性越高,异常解析器的位置就越靠后。
HandlerExceptionResolver 的约定使它可以返回以下内容:
MVC Config 自动为默认的 Spring MVC 异常、@ResponseStatus 注释的异常和对 @ExceptionHandler 方法的支持声明内置解析器。您可以自定义该列表或替换它。
错误页面 如果异常仍未被任何 HandlerExceptionResolver 处理并因此继续传播,或者如果响应状态设置为错误状态(即 4xx、5xx),Servlet 容器可以在 HTML 中呈现默认错误页面。要自定义容器的默认错误页面,您可以在 web.xml 中声明一个错误页面映射。以下示例显示了如何执行此操作:
1 2 3 <error-page > <location > /error</location > </error-page >
在前面的示例中,当出现异常或响应具有错误状态时,Servlet 容器会在容器内将 ERROR 分派到配置的 URL(例如,/error)。然后由 DispatcherServlet 处理,可能将其映射到 @Controller,后者可以返回带有模型的错误视图名称或呈现 JSON 响应,如以下示例所示:
1 2 3 4 5 6 7 8 9 10 11 @RestController public class ErrorController { @RequestMapping(path = "/error") public Map<String, Object> handle (HttpServletRequest request) { Map<String, Object> map = new HashMap <String, Object>(); map.put("status" , request.getAttribute("jakarta.servlet.error.status_code" )); map.put("reason" , request.getAttribute("jakarta.servlet.error.message" )); return map; } }
提示:Servlet API 不提供在 Java 中创建错误页面映射的方法。但是,您可以同时使用 WebApplicationInitializer 和最小的 web.xml。
ViewResolver Spring MVC 定义了 ViewResolver 和 View 接口,让用户可以在浏览器中渲染模型,而无需限定于特定的视图技术。ViewResolver 提供视图名称和实际视图之间的映射。View 解决了在移交给特定视图技术之前准备数据的问题。
下表提供了有关 ViewResolver 一些子类:
ViewResolver
Description
AbstractCachingViewResolverAbstractCachingViewResolver 的子类缓存它们解析的视图实例。缓存提高了某些视图技术的性能。您可以通过将 cache 属性设置为 false 来关闭缓存。此外,如果您必须在运行时刷新某个视图(例如,修改 FreeMarker 模板时),您可以使用 removeFromCache(String viewName, Locale loc) 方法。
UrlBasedViewResolverViewResolver 接口的简单实现,无需显式映射定义即可将逻辑视图名称直接解析为 URL。如果您的逻辑名称以直接的方式匹配您的视图资源的名称,而不需要任意映射,那么这是合适的。
InternalResourceViewResolverUrlBasedViewResolver 的子类,支持 InternalResourceView(实际上是 Servlet 和 JSP)以及 JstlView 和 TilesView 等子类。可以使用 setViewClass(..) 为该解析器生成的所有视图指定视图类。
FreeMarkerViewResolverUrlBasedViewResolver 的子类,支持 FreeMarkerView 和它们的自定义子类。
ContentNegotiatingViewResolverViewResolver 接口的实现,该接口根据请求文件名或 Accept 标头解析视图。
BeanNameViewResolver将视图名称解释为当前应用程序上下文中的 bean 名称的 ViewResolver 接口的实现。这是一个非常灵活的变体,允许根据不同的视图名称混合和匹配不同的视图类型。每个这样的“视图”都可以定义为一个 bean,例如 在 XML 或配置类中。
处理 可以通过声明多个解析器来构成视图解析器链,如果需要,还可以通过设置 order 属性来指定顺序。顺序属性越高,视图解析器在链中的位置就越靠后。
ViewResolver 的约定指定它可以返回 null 以指示找不到视图。但是,对于 JSP 和 InternalResourceViewResolver,确定 JSP 是否存在的唯一方法是通过 RequestDispatcher 执行分派。因此,您必须始终将 InternalResourceViewResolver 配置为在视图解析器的整体顺序中排在最后。
配置视图解析就像将 ViewResolver 添加到 Spring 配置中一样简单。MVC Config 为视图解析器和添加无逻辑视图控制器提供了专用的配置 API,这对于没有控制器逻辑的 HTML 模板渲染很有用。
重定向 视图名称中的特殊前缀 redirect: 可以实现一个重定向。UrlBasedViewResolver(及其子类)将此识别为需要重定向的指令。视图名称的其余部分是重定向 URL。
最终效果与控制器返回 RedirectView 相同,但现在控制器本身可以根据逻辑视图名称进行操作。逻辑视图名称(例如 redirect:/myapp/some/resource)相对于当前 Servlet 上下文重定向,而名称(例如 redirect:https://myhost.com/some/arbitrary/path)重定向到绝对 URL。
请注意,如果使用 @ResponseStatus 注解标记控制器方法,则注解值优先于 RedirectView 设置的响应状态。
转发 视图名称中的特殊前缀 forward: 可以实现一个转发。这将创建一个 InternalResourceView,它执行 RequestDispatcher.forward()。因此,此前缀对 InternalResourceViewResolver 和 InternalResourceView(对于 JSP)没有用,但如果您使用另一种视图技术但仍想强制转发由 Servlet/JSP 引擎处理的资源,它可能会有所帮助。
内容协商 ContentNegotiatingViewResolver 本身不解析视图,而是委托给其他视图解析器并选择类似于客户端请求的表示的视图。可以从 Accept 头或查询参数(例如,"/path?format=pdf")确定表示形式。
ContentNegotiatingViewResolver 通过将请求媒体类型与其每个 ViewResolver 关联的 View 支持的媒体类型(也称为 Content-Type)进行比较,来选择合适的 View 来处理请求。列表中第一个具有兼容 Content-Type 的视图将处理结果返回给客户端。如果 ViewResolver 链无法提供兼容的视图,则会查阅通过 DefaultViews 属性指定的视图列表。后一个选项适用于单例视图,它可以呈现当前资源的适当表示,而不管逻辑视图名称如何。Accept 标头可以包含通配符(例如 text/*),在这种情况下,Content-Type 为 text/xml 的 View 是兼容的匹配项。
LocaleResolver 大部分的 Spring 架构都支持国际化,就像 Spring web MVC 框架所做的那样。DispatcherServlet 允许您使用客户端的语言环境自动解析消息。这是通过 LocaleResolver 对象完成的。
当收到请求时,DispatcherServlet 会寻找语言环境解析器,如果找到,它会尝试使用它来设置 Locale 环境。通过使用 RequestContext.getLocale() 方法,您始终可以检索由 Locale 解析器解析的语言环境。
除了自动识别 Locale 环境之外,您还可以为 handle 映射附加拦截器,在特定情况下更改 Locale 环境设置(例如,基于请求中的参数)。
Locale 解析器和拦截器在 org.springframework.web.servlet.i18n 包中定义,并以正常方式在您的应用程序上下文中配置。Spring 中有以下 Locale 解析器可供选择。
LocaleResolver 除了获取客户端的区域设置外,了解其时区通常也很有用。LocaleContextResolver 接口提供了 LocaleResolver 的扩展,让解析器提供更丰富的 LocaleContext,其中可能包括时区信息。
如果可用,可以使用 RequestContext.getTimeZone() 方法获取用户的 TimeZone。在 Spring 的 ConversionService 中注册的任何日期/时间 Converter 和 Formatter 对象会自动使用时区信息。
标头解析器 此 Locale 解析器检查客户端(例如网络浏览器)发送的请求中的 accept-language 头。通常,此头字段包含客户端操作系统的区域信息。请注意,此解析器不支持时区信息。
CookieLocaleResolver This locale resolver inspects a Cookie that might exist on the client to see if a Locale or TimeZone is specified. If so, it uses the specified details. By using the properties of this locale resolver, you can specify the name of the cookie as well as the maximum age. The following example defines a CookieLocaleResolver:
此 Locale 解析器检查客户端上是否存在 Cookie,以查看是否指定了 Locale 或 TimeZone。如果是,它会使用指定的详细信息。通过使用此 Locale 解析器的属性,可以指定 cookie 的名称以及最长期限。以下示例定义了 CookieLocaleResolver:
1 2 3 4 5 6 7 8 <bean id ="localeResolver" class ="org.springframework.web.servlet.i18n.CookieLocaleResolver" > <property name ="cookieName" value ="clientlanguage" /> <property name ="cookieMaxAge" value ="100000" /> </bean >
下表描述了 CookieLocaleResolver 的属性:
属性
默认值
Description
cookieName类名 + LOCALE
cookie 名
cookieMaxAgeServlet container default
cookie 在客户端上保留的最长时间。如果指定了“-1”,则不会保留 cookie。它仅在客户端关闭浏览器之前可用。
cookiePath/
将 cookie 的可见性限制在您网站的特定部分。当指定 cookiePath 时,cookie 仅对该路径及其下方的路径可见。
SessionLocaleResolver SessionLocaleResolver 允许您从可能与用户请求相关联的会话中检索 Locale 和 TimeZone。与 CookieLocaleResolver 相比,此策略将本地选择的 locale 设置存储在 Servlet 容器的 HttpSession 中。因此,这些设置对于每个会话都是临时的,因此会在每个会话结束时丢失。
注意,这与外部会话管理机制(例如 Spring Session 项目)没有直接关系。此 SessionLocaleResolver 根据当前 HttpServletRequest 评估和修改相应的 HttpSession 属性。
LocaleChangeInterceptor 可以通过将 LocaleChangeInterceptor 添加到一个 HandlerMapping 定义来启用区域设置更改。它检测请求中的参数并相应地更改 Locale 环境,在调度程序的应用程序上下文中调用 LocaleResolver 上的 setLocale 方法。下面的示例显示调用所有包含名为 siteLanguage 的参数的 *.view 资源,以更改语言环境。因此,例如,对 URL https://www.sf.net/home.view?siteLanguage=nl 的请求将站点语言更改为荷兰语。以下示例显示了如何拦截语言环境:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <bean id ="localeChangeInterceptor" class ="org.springframework.web.servlet.i18n.LocaleChangeInterceptor" > <property name ="paramName" value ="siteLanguage" /> </bean > <bean id ="localeResolver" class ="org.springframework.web.servlet.i18n.CookieLocaleResolver" /> <bean id ="urlMapping" class ="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping" > <property name ="interceptors" > <list > <ref bean ="localeChangeInterceptor" /> </list > </property > <property name ="mappings" > <value > /**/*.view=someController</value > </property > </bean >
ThemeResolver 您可以应用 Spring Web MVC 框架主题来设置应用程序的整体外观,从而增强用户体验。主题是静态资源的集合,通常是样式表和图像,它们会影响应用程序的视觉风格。
要在 Web 应用程序中使用主题,必须设置 org.springframework.ui.context.ThemeSource 接口的实现。WebApplicationContext 接口扩展了 ThemeSource 但将其职责委托给了专门的实现。默认情况下,委托是 org.springframework.ui.context.support.ResourceBundleThemeSource ,它从类的根路径加载属性文件。要使用自定义的 ThemeSource 实现或配置 ResourceBundleThemeSource 的基本名称前缀,您可以在应用程序上下文中使用保留名称 themeSource 注册一个 bean。Web 应用程序上下文自动检测具有该名称的 bean 并使用它。
当使用 ResourceBundleThemeSource 时,主题是在一个简单的属性文件中定义的。属性文件列出了构成主题的资源,如以下示例所示:
1 2 styleSheet =/themes/cool/style.css background =/themes/cool/img/coolBg.jpg
属性的键是从视图代码中引用主题元素的名称。对于 JSP,通常使用 spring:theme 自定义标签来执行此操作,它与 spring:message 标签非常相似。以下 JSP 片段使用前面示例中定义的主题来自定义外观:
1 2 3 4 5 6 7 8 9 <%@ taglib prefix="spring" uri="http://www.springframework.org/tags"%> <html > <head > <link rel ="stylesheet" href ="<spring:theme code='styleSheet'/>" type ="text/css" /> </head > <body style ="background=<spring:theme code='background'/>" > ... </body > </html >
默认情况下, ResourceBundleThemeSource 使用空的基本名称前缀。因此,属性文件是从类路径的根加载的。因此,可以将 cool.properties 主题定义放在类路径根目录中(例如,在 /WEB-INF/classes 中)。ResourceBundleThemeSource 使用标准的 Java 资源包加载机制,允许主题完全国际化。例如,我们可以有一个 /WEB-INF/classes/cool_nl.properties,它引用一个带有荷兰语文本的特殊背景图像。
定义主题后,可以决定使用哪个要使用的主题。DispatcherServlet 查找名为 themeResolver 的 bean 以找出要使用的 ThemeResolver 实现。主题解析器的工作方式与 LocaleResolver 大致相同。它检测用于特定请求的主题,也可以更改请求的主题。下表描述了 Spring 提供的主题解析器:
Class
Description
FixedThemeResolver选择一个固定的主题,使用 defaultThemeName 属性设置。
SessionThemeResolver主题在用户的 HTTP 会话中维护。 它只需要为每个会话设置一次,但不会在会话之间持续存在。
CookieThemeResolver所选主题存储在客户端的 cookie 中。
Spring 还提供了一个 ThemeChangeInterceptor,它允许使用一个简单的请求参数在每个请求上更改主题。
MultipartResolver org.springframework.web.multipart 包中的 MultipartResolver 是一种解析 multipart 请求(包括文件上传)的策略。 有一个基于容器的 StandardServletMultipartResolver 实现,用于 Servlet 多部分请求解析。 请注意,从具有新 Servlet 5.0+ 基线的 Spring Framework 6.0 开始,基于 Apache Commons FileUpload 的过时的 CommonsMultipartResolver 不再可用。
要启用 multipart 处理,需要在 DispatcherServlet Spring 配置中声明一个名为 multipartResolver 的 MultipartResolver。 DispatcherServlet 检测到它并将其应用于传入请求。 当接收到内容类型为 multipart/form-data 的 POST 时,解析器解析将当前 HttpServletRequest 包装为 MultipartHttpServletRequest 的内容,以提供对已解析文件的访问以及将部分作为请求参数公开。
Servlet 多部分解析需要通过 Servlet 容器配置启用。 为此:
以下示例显示如何在 Servlet 注册上设置 MultipartConfigElement:
1 2 3 4 5 6 7 8 9 10 11 12 public class AppInitializer extends AbstractAnnotationConfigDispatcherServletInitializer { @Override protected void customizeRegistration (ServletRegistration.Dynamic registration) { registration.setMultipartConfig(new MultipartConfigElement ("/tmp" )); } }
一旦 Servlet multipart 配置好,就可以添加一个名为 multipartResolver 的 StandardServletMultipartResolver 类型的 bean。
参考资料