Spring 校验
Java API 规范(JSR303)定义了Bean校验的标准validation-api,但没有提供实现。hibernate validation是对这个规范的实现,并增加了校验注解如@Email、@Length等。Spring Validation是对hibernate validation的二次封装,用于支持spring mvc参数自动校验。
快速入门
引入依赖
如果 spring-boot 版本小于 2.3.x,spring-boot-starter-web 会自动传入 hibernate-validator 依赖。如果 spring-boot 版本大于 2.3.x,则需要手动引入依赖:
1
2
3
4
5
| <dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator-parent</artifactId>
<version>6.2.5.Final</version>
</dependency>
|
对于 web 服务来说,为防止非法参数对业务造成影响,在 Controller 层一定要做参数校验的!大部分情况下,请求参数分为如下两种形式:
- POST、PUT 请求,使用 requestBody 传递参数;
- GET 请求,使用 requestParam/PathVariable 传递参数。
实际上,不管是 requestBody 参数校验还是方法级别的校验,最终都是调用 Hibernate Validator 执行校验,Spring Validation 只是做了一层封装。
校验示例
(1)在实体上标记校验注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
@NotNull
private Long id;
@NotBlank
@Size(min = 2, max = 10)
private String name;
@Min(value = 1)
@Max(value = 100)
private Integer age;
}
|
(2)在方法参数上声明校验注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| @Slf4j
@Validated
@RestController
@RequestMapping("validate1")
public class ValidatorController {
@PostMapping(value = "save")
public DataResult<Boolean> save(@Valid @RequestBody User entity) {
log.info("保存一条记录:{}", JSONUtil.toJsonStr(entity));
return DataResult.ok(true);
}
@GetMapping(value = "queryByName")
public DataResult<User> queryByName(
@RequestParam("username")
@NotBlank
@Size(min = 2, max = 10)
String name
) {
User user = new User(1L, name, 18);
return DataResult.ok(user);
}
@GetMapping(value = "detail/{id}")
public DataResult<User> detail(@PathVariable("id") @Min(1L) Long id) {
User user = new User(id, "李四", 18);
return DataResult.ok(user);
}
}
|
(3)如果请求参数不满足校验规则,则会抛出 ConstraintViolationException 或 MethodArgumentNotValidException 异常。
统一异常处理
在实际项目开发中,通常会用统一异常处理来返回一个更友好的提示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| @Slf4j
@ControllerAdvice
public class GlobalExceptionHandler {
@ResponseBody
@ResponseStatus(HttpStatus.OK)
@ExceptionHandler(Throwable.class)
public Result handleException(Throwable e) {
log.error("未知异常", e);
return new Result(ResultStatus.HTTP_SERVER_ERROR.getCode(), e.getMessage());
}
@ResponseBody
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler({ ConstraintViolationException.class })
public Result handleConstraintViolationException(final ConstraintViolationException e) {
log.error("ConstraintViolationException", e);
List<String> errors = new ArrayList<>();
for (ConstraintViolation<?> violation : e.getConstraintViolations()) {
Path path = violation.getPropertyPath();
List<String> pathArr = StrUtil.split(path.toString(), ',');
errors.add(pathArr.get(0) + " " + violation.getMessage());
}
return new Result(ResultStatus.REQUEST_ERROR.getCode(), CollectionUtil.join(errors, ","));
}
@ResponseBody
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler({ MethodArgumentNotValidException.class })
private Result handleMethodArgumentNotValidException(final MethodArgumentNotValidException e) {
log.error("MethodArgumentNotValidException", e);
List<String> errors = new ArrayList<>();
for (ObjectError error : e.getBindingResult().getAllErrors()) {
errors.add(((FieldError) error).getField() + " " + error.getDefaultMessage());
}
return new Result(ResultStatus.REQUEST_ERROR.getCode(), CollectionUtil.join(errors, ","));
}
}
|
进阶使用
分组校验
在实际项目中,可能多个方法需要使用同一个 DTO 类来接收参数,而不同方法的校验规则很可能是不一样的。这个时候,简单地在 DTO 类的字段上加约束注解无法解决这个问题。因此,spring-validation 支持了分组校验的功能,专门用来解决这类问题。
(1)定义分组
1
2
3
4
5
6
7
| @Target({ ElementType.FIELD, ElementType.PARAMETER })
@Retention(RetentionPolicy.RUNTIME)
public @interface AddCheck { }
@Target({ ElementType.FIELD, ElementType.PARAMETER })
@Retention(RetentionPolicy.RUNTIME)
public @interface EditCheck { }
|
(2)在实体上标记校验注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Data
public class User2 {
@NotNull(groups = EditCheck.class)
private Long id;
@NotNull(groups = { AddCheck.class, EditCheck.class })
@Size(min = 2, max = 10, groups = { AddCheck.class, EditCheck.class })
private String name;
@IsMobile(message = "不是有效手机号", groups = { AddCheck.class, EditCheck.class })
private String mobile;
}
|
(3)在方法上根据不同场景进行校验分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Slf4j
@Validated
@RestController
@RequestMapping("validate2")
public class ValidatorController2 {
@PostMapping(value = "add")
public DataResult<Boolean> add(@Validated(AddCheck.class) @RequestBody User2 entity) {
log.info("添加一条记录:{}", JSONUtil.toJsonStr(entity));
return DataResult.ok(true);
}
@PostMapping(value = "edit")
public DataResult<Boolean> edit(@Validated(EditCheck.class) @RequestBody User2 entity) {
log.info("编辑一条记录:{}", JSONUtil.toJsonStr(entity));
return DataResult.ok(true);
}
}
|
嵌套校验
前面的示例中,DTO 类里面的字段都是基本数据类型和 String 类型。但是实际场景中,有可能某个字段也是一个对象,这种情况先,可以使用嵌套校验。
post
比如,上面保存 User 信息的时候同时还带有 Job 信息。需要注意的是,此时 DTO 类的对应字段必须标记@Valid 注解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| @Data
public class UserDTO {
@Min(value = 10000000000000000L, groups = Update.class)
private Long userId;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String userName;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String account;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String password;
@NotNull(groups = {Save.class, Update.class})
@Valid
private Job job;
@Data
public static class Job {
@Min(value = 1, groups = Update.class)
private Long jobId;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String jobName;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String position;
}
public interface Save {
}
public interface Update {
}
}
复制代码
|
嵌套校验可以结合分组校验一起使用。还有就是嵌套集合校验会对集合里面的每一项都进行校验,例如List<Job>字段会对这个 list 里面的每一个 Job 对象都进行校验
自定义校验注解
(1)自定义校验注解 @IsMobile
1
2
3
4
5
6
7
8
9
10
11
12
| @Target({ METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER, TYPE_USE })
@Retention(RUNTIME)
@Constraint(validatedBy = MobileValidator.class)
public @interface IsMobile {
String message();
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
}
|
(2)实现 ConstraintValidator 接口,编写 @IsMobile 校验注解的解析器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import cn.hutool.core.util.StrUtil;
import io.github.dunwu.spring.core.validation.annotation.IsMobile;
import io.github.dunwu.tool.util.ValidatorUtil;
import javax.validation.ConstraintValidator;
import javax.validation.ConstraintValidatorContext;
public class MobileValidator implements ConstraintValidator<IsMobile, String> {
@Override
public void initialize(IsMobile isMobile) { }
@Override
public boolean isValid(String s, ConstraintValidatorContext constraintValidatorContext) {
if (StrUtil.isBlank(s)) {
return false;
} else {
return ValidatorUtil.isMobile(s);
}
}
}
|
自定义校验
可以通过实现 org.springframework.validation.Validator 接口来自定义校验。
有以下要点
- 实现
supports 方法
- 实现
validate 方法
- 通过
Errors 对象收集错误
ObjectError:对象(Bean)错误:FieldError:对象(Bean)属性(Property)错误
- 通过
ObjectError 和 FieldError 关联 MessageSource 实现获取最终的错误文案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| package io.github.dunwu.spring.core.validation;
import io.github.dunwu.spring.core.validation.annotation.Valid;
import io.github.dunwu.spring.core.validation.config.CustomValidatorConfig;
import io.github.dunwu.spring.core.validation.entity.Person;
import org.springframework.stereotype.Component;
import org.springframework.validation.Errors;
import org.springframework.validation.ValidationUtils;
import org.springframework.validation.Validator;
import java.lang.annotation.Annotation;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Component
public class CustomValidator implements Validator {
private final CustomValidatorConfig validatorConfig;
public CustomValidator(CustomValidatorConfig validatorConfig) {
this.validatorConfig = validatorConfig;
}
@Override
public boolean supports(Class<?> clazz) {
return Person.class.equals(clazz);
}
@Override
public void validate(Object target, Errors errors) {
ValidationUtils.rejectIfEmpty(errors, "name", "name.empty");
List<Field> fields = getFields(target.getClass());
for (Field field : fields) {
Annotation[] annotations = field.getAnnotations();
for (Annotation annotation : annotations) {
if (annotation.annotationType().getAnnotation(Valid.class) != null) {
try {
ValidatorRule validatorRule = validatorConfig.findRule(annotation);
if (validatorRule != null) {
validatorRule.valid(annotation, target, field, errors);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
private List<Field> getFields(Class<?> clazz) {
List<Field> fields = new ArrayList<>();
while (clazz != null) {
Collections.addAll(fields, clazz.getDeclaredFields());
clazz = clazz.getSuperclass();
}
return fields;
}
}
|
快速失败(Fail Fast)
Spring Validation 默认会校验完所有字段,然后才抛出异常。可以通过一些简单的配置,开启 Fali Fast 模式,一旦校验失败就立即返回。
1
2
3
4
5
6
7
8
9
| @Bean
public Validator validator() {
ValidatorFactory validatorFactory = Validation.byProvider(HibernateValidator.class)
.configure()
.failFast(true)
.buildValidatorFactory();
return validatorFactory.getValidator();
}
|
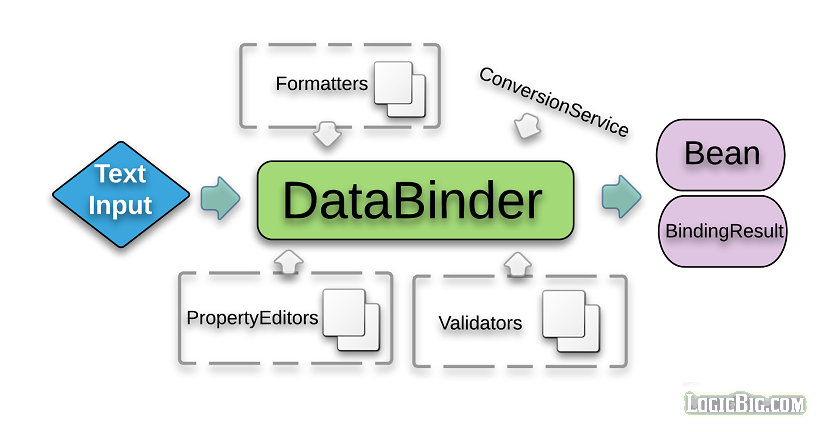
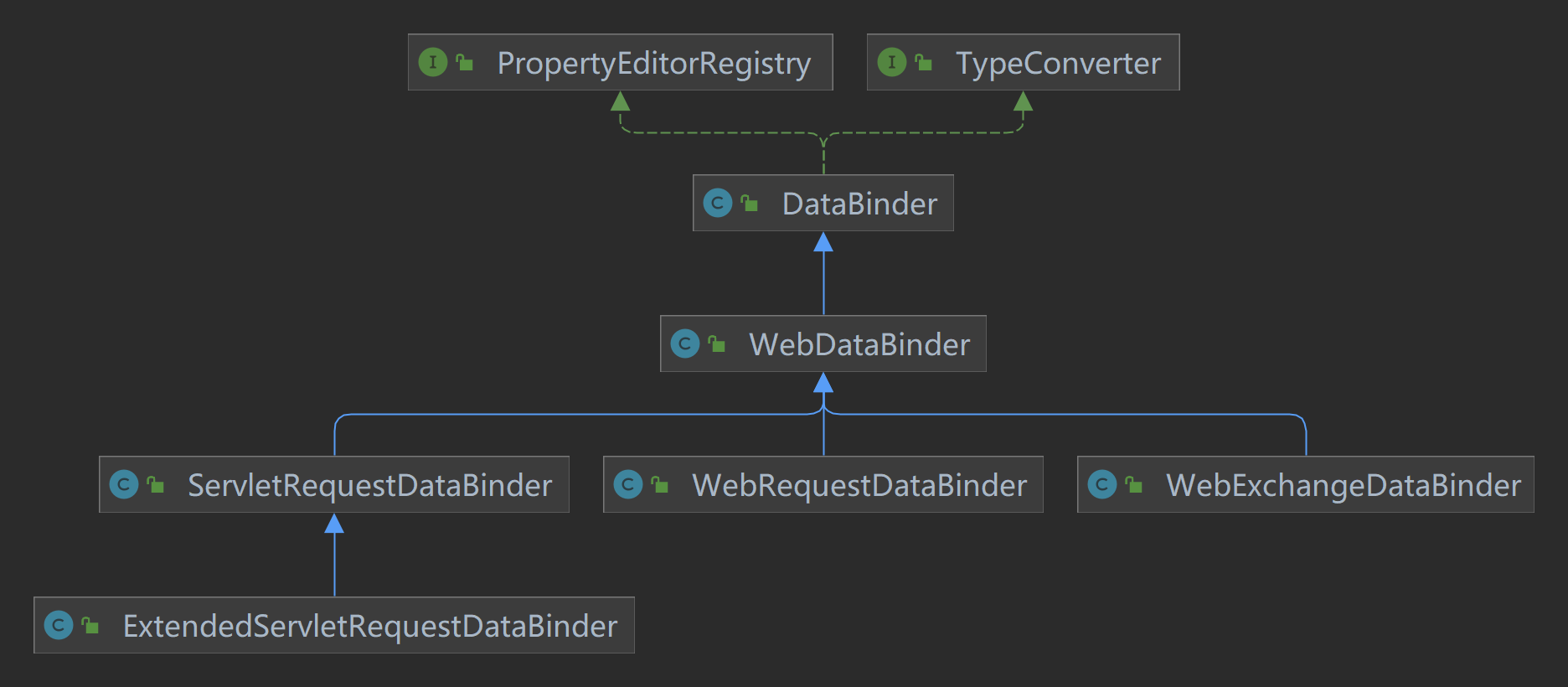
Spring 校验原理
Spring 校验使用场景
- Spring 常规校验(Validator)
- Spring 数据绑定(DataBinder)
- Spring Web 参数绑定(WebDataBinder)
- Spring WebMVC/WebFlux 处理方法参数校验
Validator 接口设计
- 接口职责
- Spring 内部校验器接口,通过编程的方式校验目标对象
- 核心方法
supports(Class):校验目标类能否校验validate(Object,Errors):校验目标对象,并将校验失败的内容输出至 Errors 对象
- 配套组件
- 错误收集器:
org.springframework.validation.Errors
- Validator 工具类:
org.springframework.validation.ValidationUtils
Errors 接口设计
- 接口职责
- 数据绑定和校验错误收集接口,与 Java Bean 和其属性有强关联性
- 核心方法
reject 方法(重载):收集错误文案rejectValue 方法(重载):收集对象字段中的错误文案
- 配套组件
- Java Bean 错误描述:
org.springframework.validation.ObjectError
- Java Bean 属性错误描述:
org.springframework.validation.FieldError
Errors 文案来源
Errors 文案生成步骤
- 选择 Errors 实现(如:
org.springframework.validation.BeanPropertyBindingResult)
- 调用 reject 或 rejectValue 方法
- 获取 Errors 对象中 ObjectError 或 FieldError
- 将 ObjectError 或 FieldError 中的 code 和 args,关联 MessageSource 实现(如:
ResourceBundleMessageSource)
spring web 校验原理
RequestBody 参数校验实现原理
在 spring-mvc 中,RequestResponseBodyMethodProcessor 是用于解析 @RequestBody 标注的参数以及处理@ResponseBody 标注方法的返回值的。其中,执行参数校验的逻辑肯定就在解析参数的方法 resolveArgument() 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
parameter = parameter.nestedIfOptional();
Object arg = readWithMessageConverters(webRequest, parameter, parameter.getNestedGenericParameterType());
String name = Conventions.getVariableNameForParameter(parameter);
if (binderFactory != null) {
WebDataBinder binder = binderFactory.createBinder(webRequest, arg, name);
if (arg != null) {
validateIfApplicable(binder, parameter);
if (binder.getBindingResult().hasErrors() && isBindExceptionRequired(binder, parameter)) {
throw new MethodArgumentNotValidException(parameter, binder.getBindingResult());
}
}
if (mavContainer != null) {
mavContainer.addAttribute(BindingResult.MODEL_KEY_PREFIX + name, binder.getBindingResult());
}
}
return adaptArgumentIfNecessary(arg, parameter);
}
|
可以看到,resolveArgument()调用了 validateIfApplicable()进行参数校验。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| protected void validateIfApplicable(WebDataBinder binder, MethodParameter parameter) {
Annotation[] annotations = parameter.getParameterAnnotations();
for (Annotation ann : annotations) {
Validated validatedAnn = AnnotationUtils.getAnnotation(ann, Validated.class);
if (validatedAnn != null || ann.annotationType().getSimpleName().startsWith("Valid")) {
Object hints = (validatedAnn != null ? validatedAnn.value() : AnnotationUtils.getValue(ann));
Object[] validationHints = (hints instanceof Object[] ? (Object[]) hints : new Object[] {hints});
binder.validate(validationHints);
break;
}
}
}
|
以上代码,就解释了 Spring 为什么能同时支持 @Validated、@Valid 两个注解。
接下来,看一下 WebDataBinder.validate() 的实现:
1
2
3
4
5
6
7
8
| @Override
public void validate(Object target, Errors errors, Object... validationHints) {
if (this.targetValidator != null) {
processConstraintViolations(
this.targetValidator.validate(target, asValidationGroups(validationHints)), errors);
}
}
|
通过上面代码,可以看出 Spring 校验实际上是基于 Hibernate Validator 的封装。
方法级别的参数校验实现原理
Spring 支持根据方法去进行拦截、校验,原理就在于应用了 AOP 技术。具体来说,是通过 MethodValidationPostProcessor 动态注册 AOP 切面,然后使用 MethodValidationInterceptor 对切点方法织入增强。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class MethodValidationPostProcessor extends AbstractBeanFactoryAwareAdvisingPostProcessorimplements InitializingBean {
@Override
public void afterPropertiesSet() {
Pointcut pointcut = new AnnotationMatchingPointcut(this.validatedAnnotationType, true);
this.advisor = new DefaultPointcutAdvisor(pointcut, createMethodValidationAdvice(this.validator));
}
protected Advice createMethodValidationAdvice(@Nullable Validator validator) {
return (validator != null ? new MethodValidationInterceptor(validator) : new MethodValidationInterceptor());
}
}
|
接着看一下 MethodValidationInterceptor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class MethodValidationInterceptor implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
if (isFactoryBeanMetadataMethod(invocation.getMethod())) {
return invocation.proceed();
}
Class<?>[] groups = determineValidationGroups(invocation);
ExecutableValidator execVal = this.validator.forExecutables();
Method methodToValidate = invocation.getMethod();
Set<ConstraintViolation<Object>> result;
try {
result = execVal.validateParameters(
invocation.getThis(), methodToValidate, invocation.getArguments(), groups);
}
catch (IllegalArgumentException ex) {
...
}
if (!result.isEmpty()) {
throw new ConstraintViolationException(result);
}
Object returnValue = invocation.proceed();
result = execVal.validateReturnValue(invocation.getThis(), methodToValidate, returnValue, groups);
if (!result.isEmpty()) {
throw new ConstraintViolationException(result);
}
return returnValue;
}
}
|
实际上,不管是 requestBody 参数校验还是方法级别的校验,最终都是调用 Hibernate Validator 执行校验,Spring Validation 只是做了一层封装。
问题
Spring 有哪些校验核心组件?
- 检验器:
org.springframework.validation.Validator
- 错误收集器:
org.springframework.validation.Errors
- Java Bean 错误描述:
org.springframework.validation.ObjectError
- Java Bean 属性错误描述:
org.springframework.validation.FieldError
- Bean Validation 适配:
org.springframework.validation.beanvalidation.LocalValidatorFactoryBean
参考资料