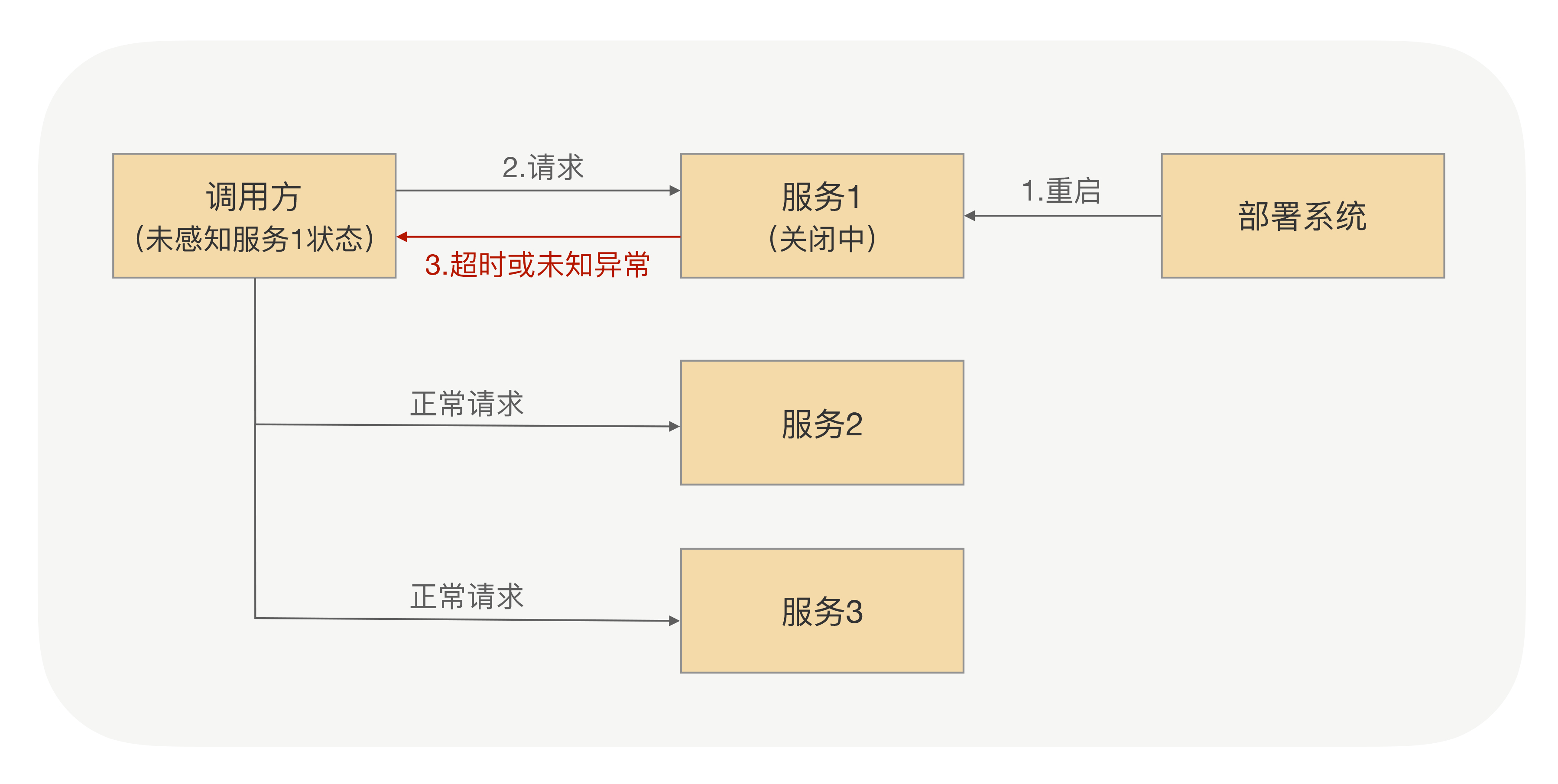
org.apache.rocketmq.remoting.exception.RemotingConnectException: connect to <172.17.0.1:10909> failed at org.apache.rocketmq.remoting.netty.NettyRemotingClient.invokeSync(NettyRemotingClient.java:357) at org.apache.rocketmq.client.impl.MQClientAPIImpl.sendMessageSync(MQClientAPIImpl.java:343) at org.apache.rocketmq.client.impl.MQClientAPIImpl.sendMessage(MQClientAPIImpl.java:327) at org.apache.rocketmq.client.impl.MQClientAPIImpl.sendMessage(MQClientAPIImpl.java:290) at org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl.sendKernelImpl(DefaultMQProducerImpl.java:688) at org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl.sendSelectImpl(DefaultMQProducerImpl.java:901) at org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl.send(DefaultMQProducerImpl.java:878) at org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl.send(DefaultMQProducerImpl.java:873) at org.apache.rocketmq.client.producer.DefaultMQProducer.send(DefaultMQProducer.java:369) at com.emrubik.uc.mdm.sync.utils.MdmInit.sendMessage(MdmInit.java:62) at com.emrubik.uc.mdm.sync.utils.MdmInit.main(MdmInit.java:2149)
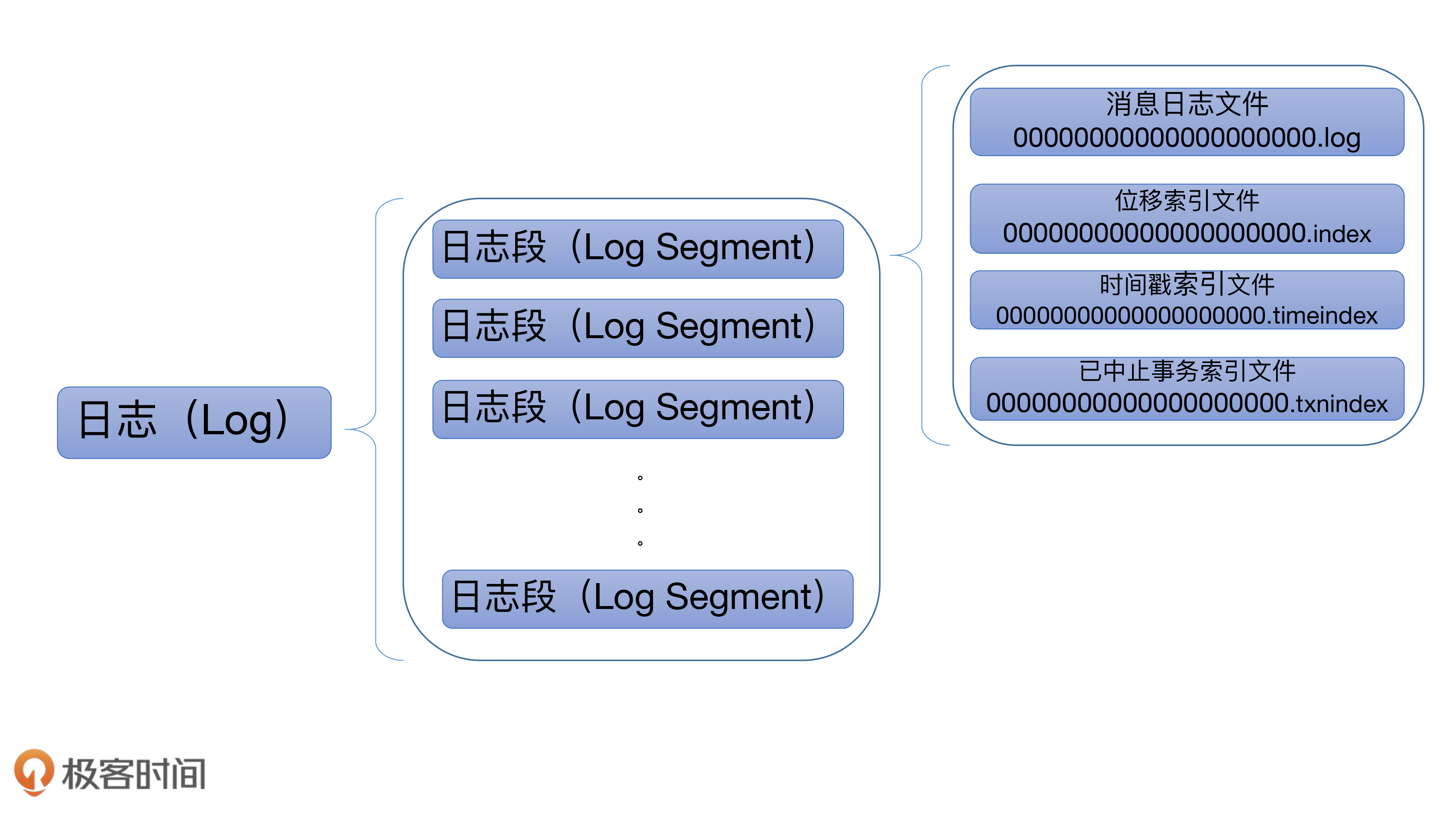
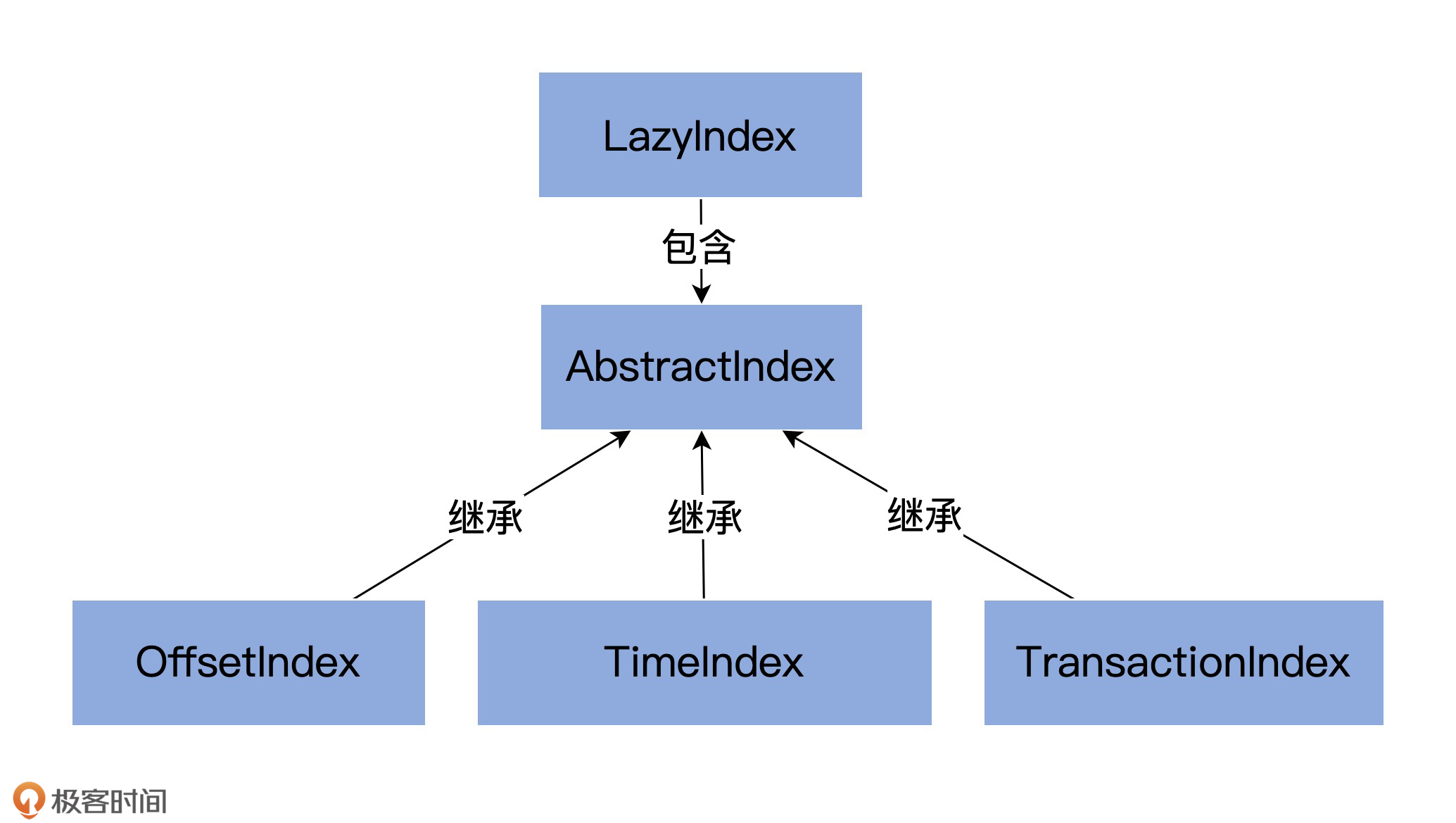
LogSegment object:保存静态变量或静态方法。相当于 LogSegment class 的工具类。
LogFlushStats object:尾部有个 stats,用于统计,负责为日志落盘进行计时。
LogSegment class 声明
1 2 3 4 5 6 7 8
classLogSegmentprivate[log] (val log: FileRecords, val lazyOffsetIndex: LazyIndex[OffsetIndex], val lazyTimeIndex: LazyIndex[TimeIndex], val txnIndex: TransactionIndex, val baseOffset: Long, val indexIntervalBytes: Int, val rollJitterMs: Long, val time: Time) extendsLogging{ ... }
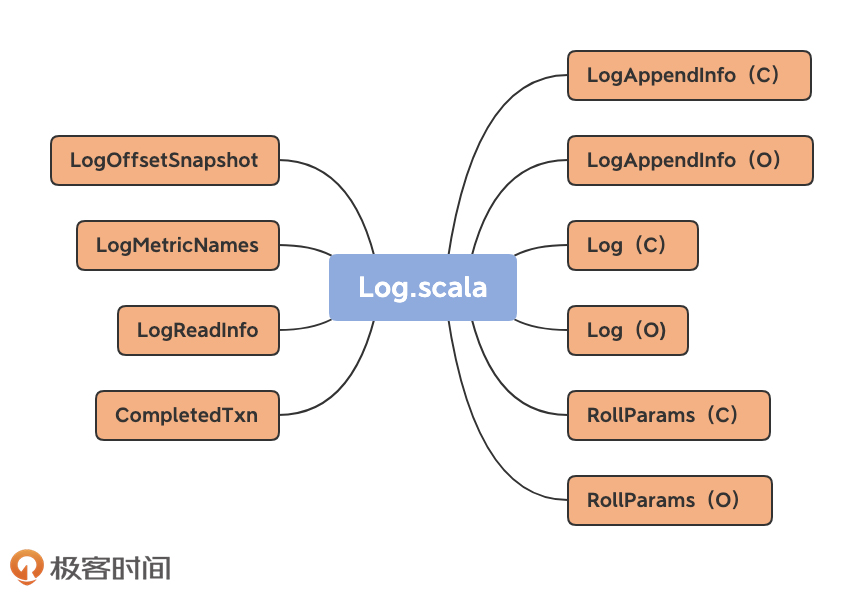
// UnifiedLog 定义 classUnifiedLog(@volatile var logStartOffset: Long, private val localLog: LocalLog, brokerTopicStats: BrokerTopicStats, val producerIdExpirationCheckIntervalMs: Int, @volatile var leaderEpochCache: Option[LeaderEpochFileCache], val producerStateManager: ProducerStateManager, @volatile private var _topicId: Option[Uuid], val keepPartitionMetadataFile: Boolean) extendsLoggingwithKafkaMetricsGroup{ ... }
// LocalLog 定义 classLocalLog(@volatile private var _dir: File, @volatile private[log] var config: LogConfig, private[log] val segments: LogSegments, @volatile private[log] var recoveryPoint: Long, @volatile private var nextOffsetMetadata: LogOffsetMetadata, private[log] val scheduler: Scheduler, private[log] val time: Time, private[log] val topicPartition: TopicPartition, private[log] val logDirFailureChannel: LogDirFailureChannel) extendsLoggingwithKafkaMetricsGroup{ ... }
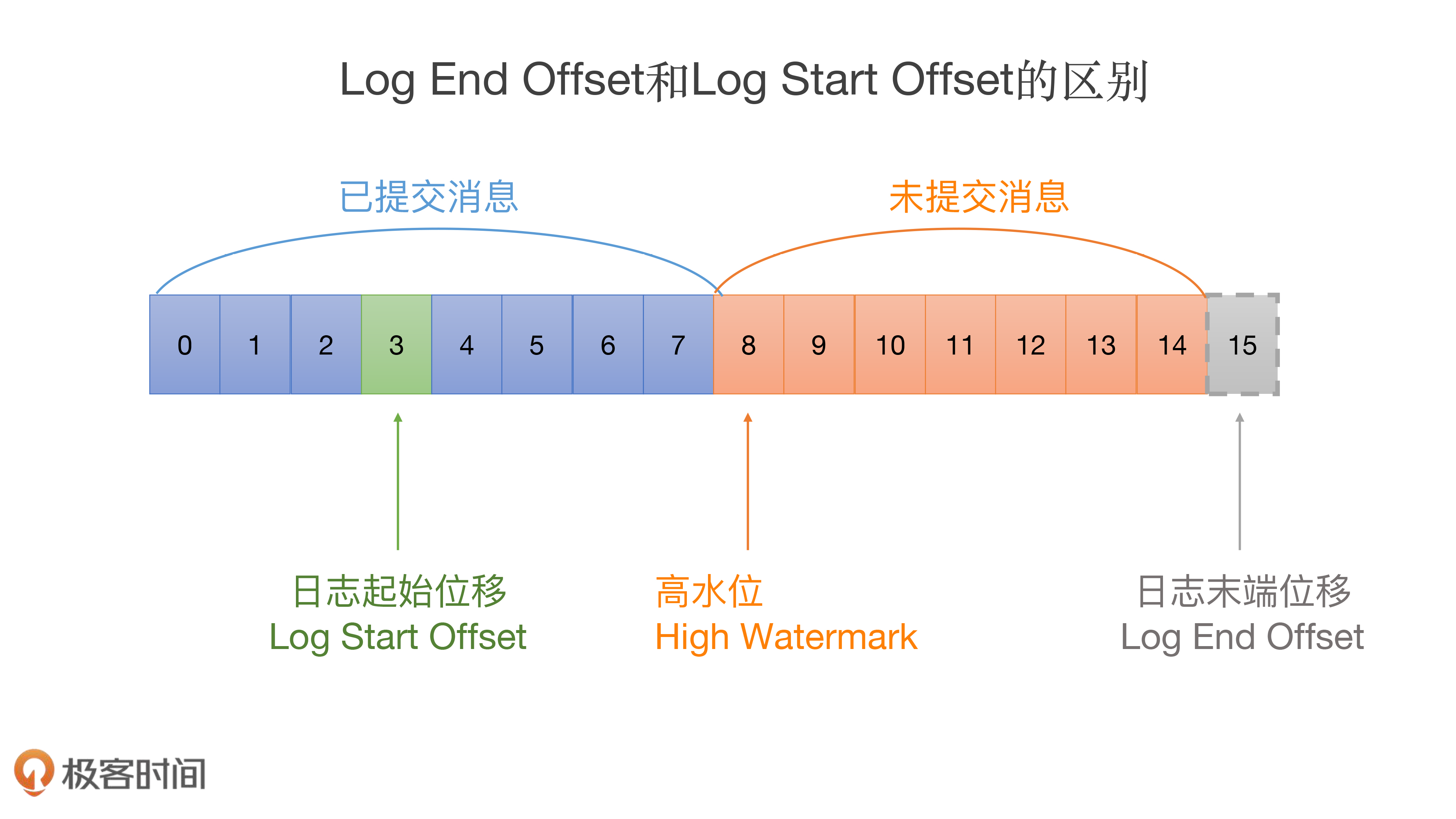
上面属性中最重要的两个属性是:_dir 和 logStartOffset。_dir 就是这个日志所在的文件夹路径,也就是主题分区的路径。logStartOffset,表示日志的当前最早位移。_dir 和 logStartOffset 都是 volatile var 类型,表示它们的值是变动的,而且可能被多个线程更新。
Log End Offset(LEO),是表示日志下一条待插入消息的位移值,而这个 Log Start Offset 是跟它相反的,它表示日志当前对外可见的最早一条消息的位移值。
privatedefupdateHighWatermarkMetadata(newHighWatermark: LogOffsetMetadata): Unit = { if (newHighWatermark.messageOffset < 0) // 高水位值不能是负数 thrownewIllegalArgumentException("High watermark offset should be non-negative")
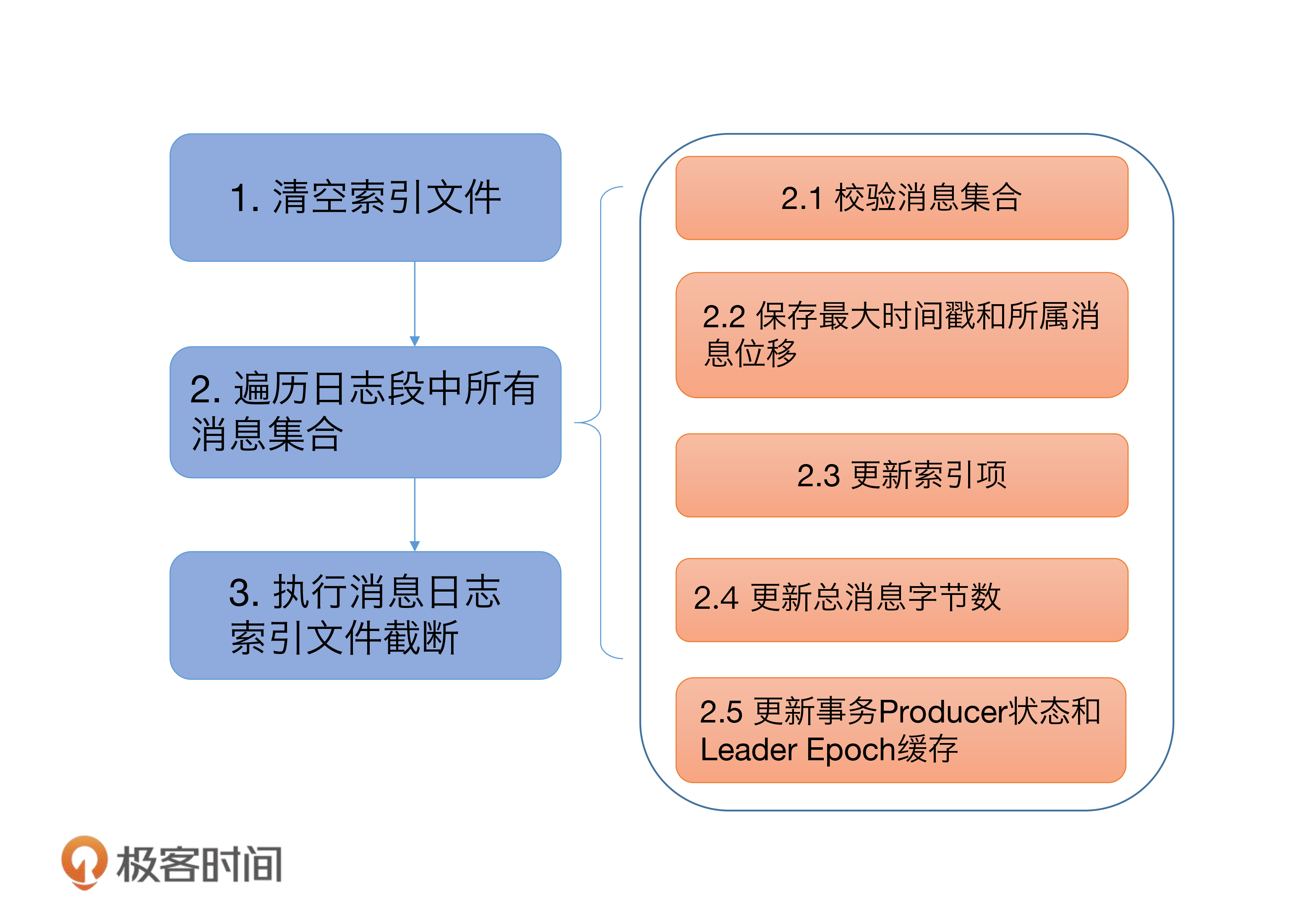
defdeleteOldSegments(): Int = { if (config.delete) { deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments() } else { deleteLogStartOffsetBreachedSegments() } }
privatedefdeleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean, reason: String): Int = { lock synchronized { val deletable = deletableSegments(predicate) if (deletable.nonEmpty) info(s"Found deletable segments with base offsets [${deletable.map(_.baseOffset).mkString(",")}] due to $reason") deleteSegments(deletable) } }
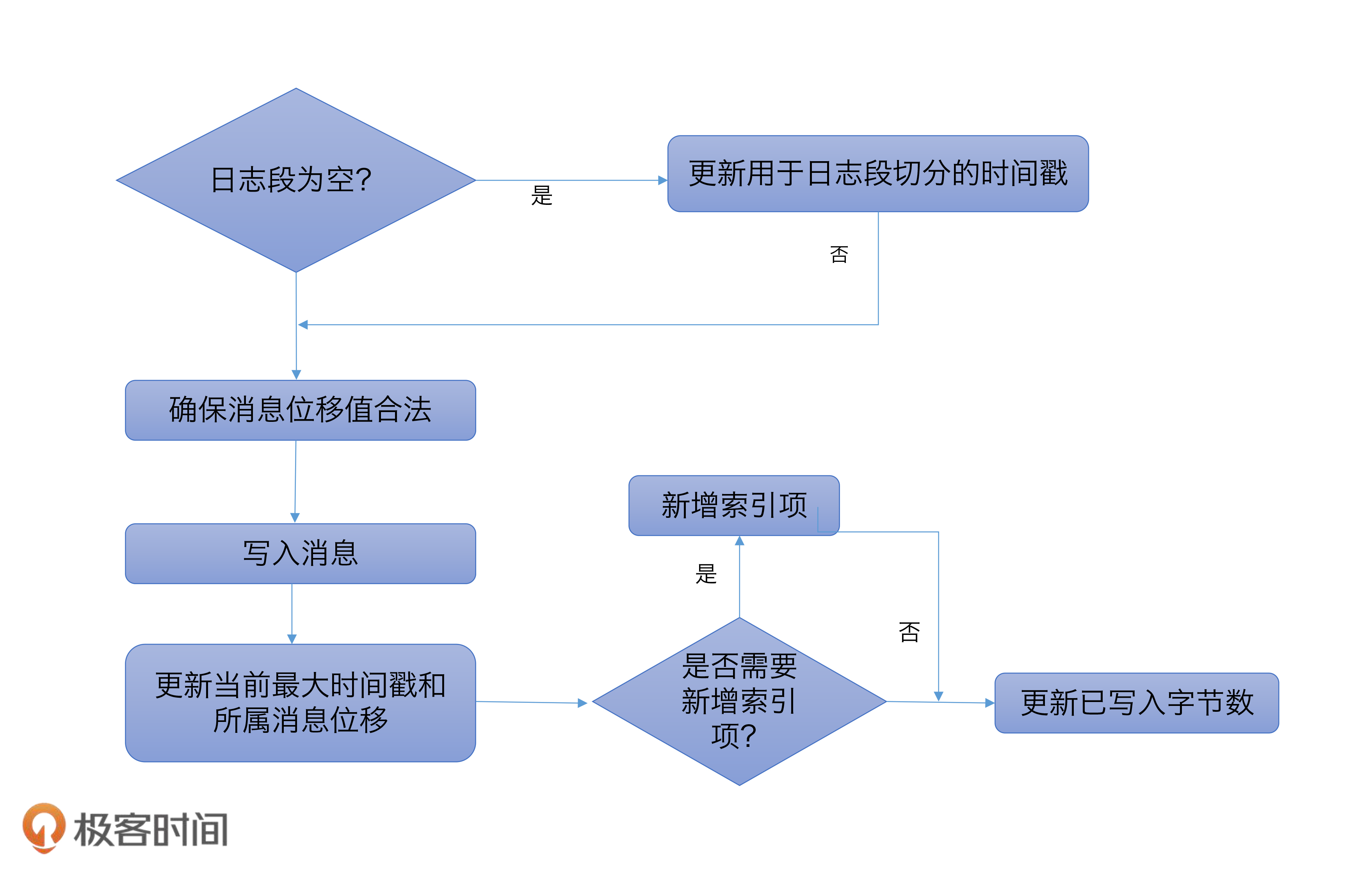
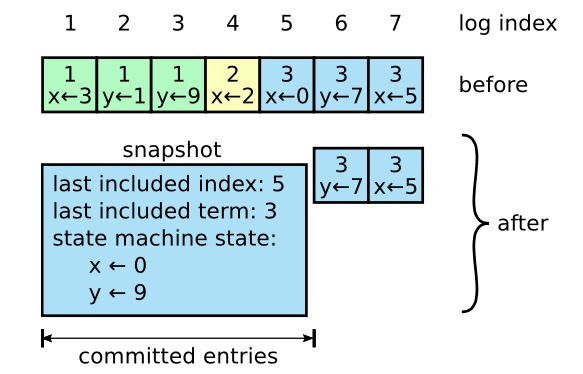
Log 对象发生日志切分(Log Roll)时:日志切分是啥呢?其实就是创建一个全新的日志段对象,并且关闭当前写入的日志段对象。这通常发生在当前日志段对象已满的时候。一旦发生日志切分,说明 Log 对象切换了 Active Segment,那么,LEO 中的起始位移值和段大小数据都要被更新,因此,在进行这一步操作时,我们必须要更新 LEO 对象。
日志截断(Log Truncation)时:这个也是显而易见的。日志中的部分消息被删除了,自然可能导致 LEO 值发生变化,从而要更新 LEO 对象。
Log Start Offset 被更新的时机:
Log 对象初始化时:和 LEO 类似,Log 对象初始化时要给 Log Start Offset 赋值,一般是将第一个日志段的起始位移值赋值给它。
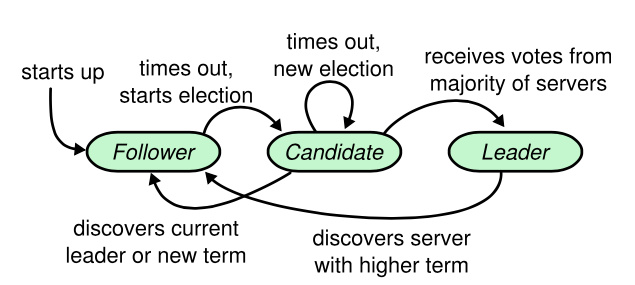
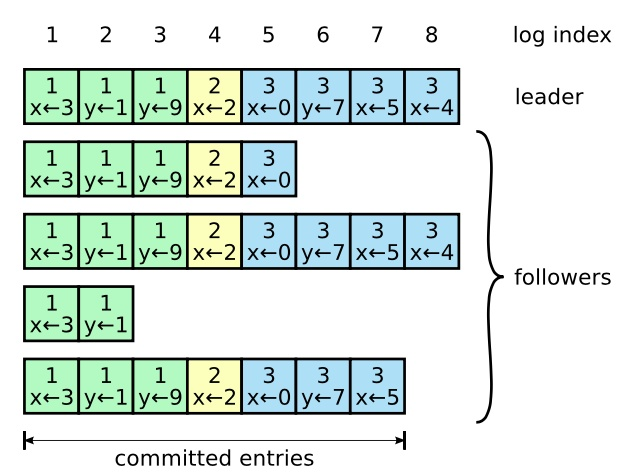
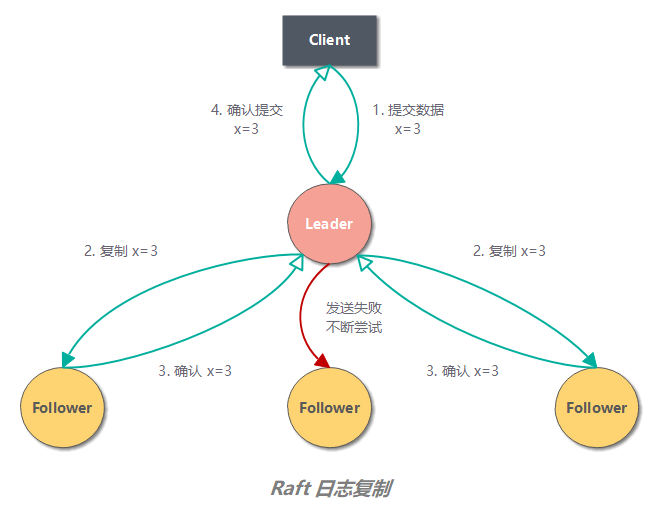
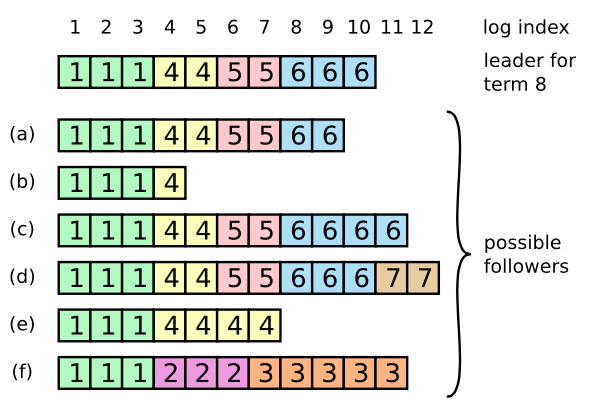
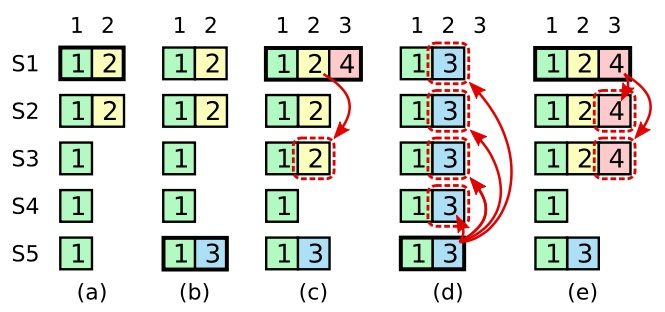
当一个 Candidate 从整个集群半数以上的服务器节点获得了针对同一个 Term 的选票,那么它就赢得了这次选举并成为 Leader。每个服务器最多会对一个 Term 投出一张选票,按照先来先服务(FIFO)的原则。_要求半数以上选票的规则确保了最多只会有一个 Candidate 赢得此次选举_。
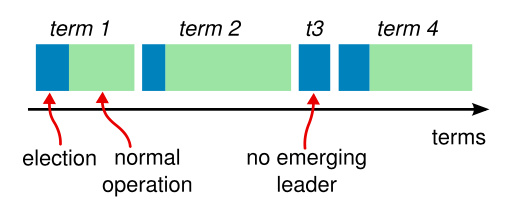
_例如,场景 f 可能会这样发生,某服务器在 Term2 的时候是 Leader,已附加了一些日志条目到自己的日志中,但在提交之前就崩溃了;很快这个机器就被重启了,在 Term3 重新被选为 Leader,并且又增加了一些日志条目到自己的日志中;在 Term 2 和 Term 3 的日志被提交之前,这个服务器又宕机了,并且在接下来的几个任期里一直处于宕机状态_。
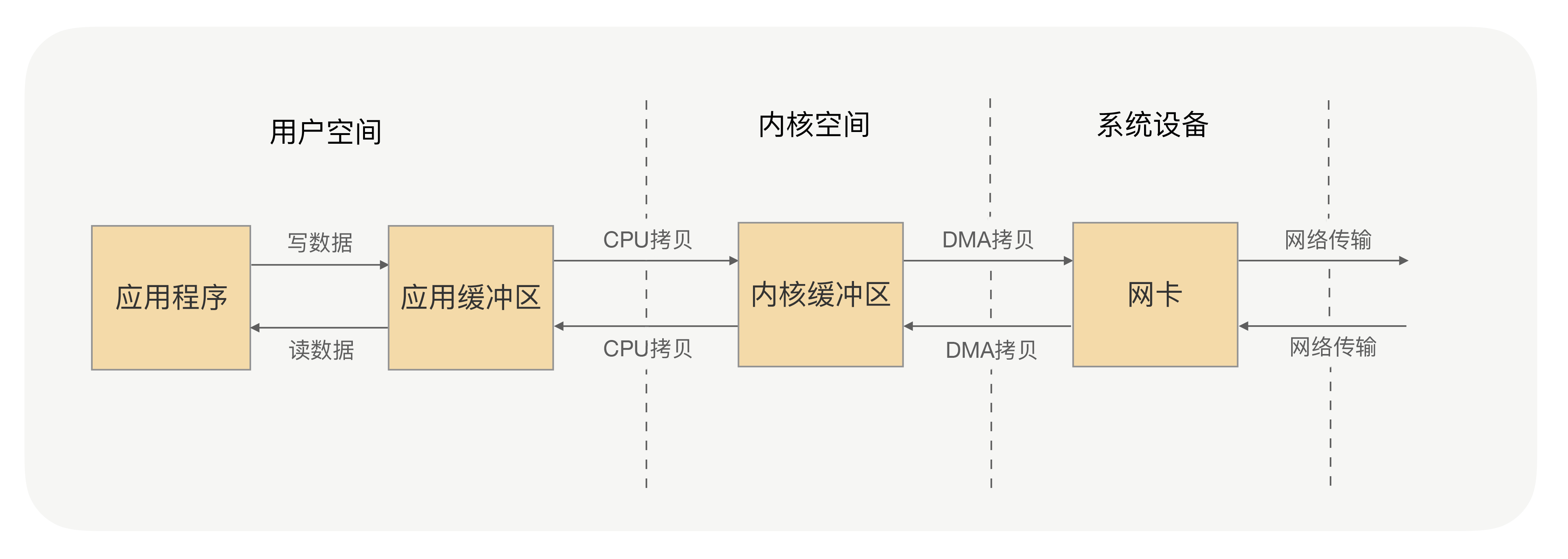
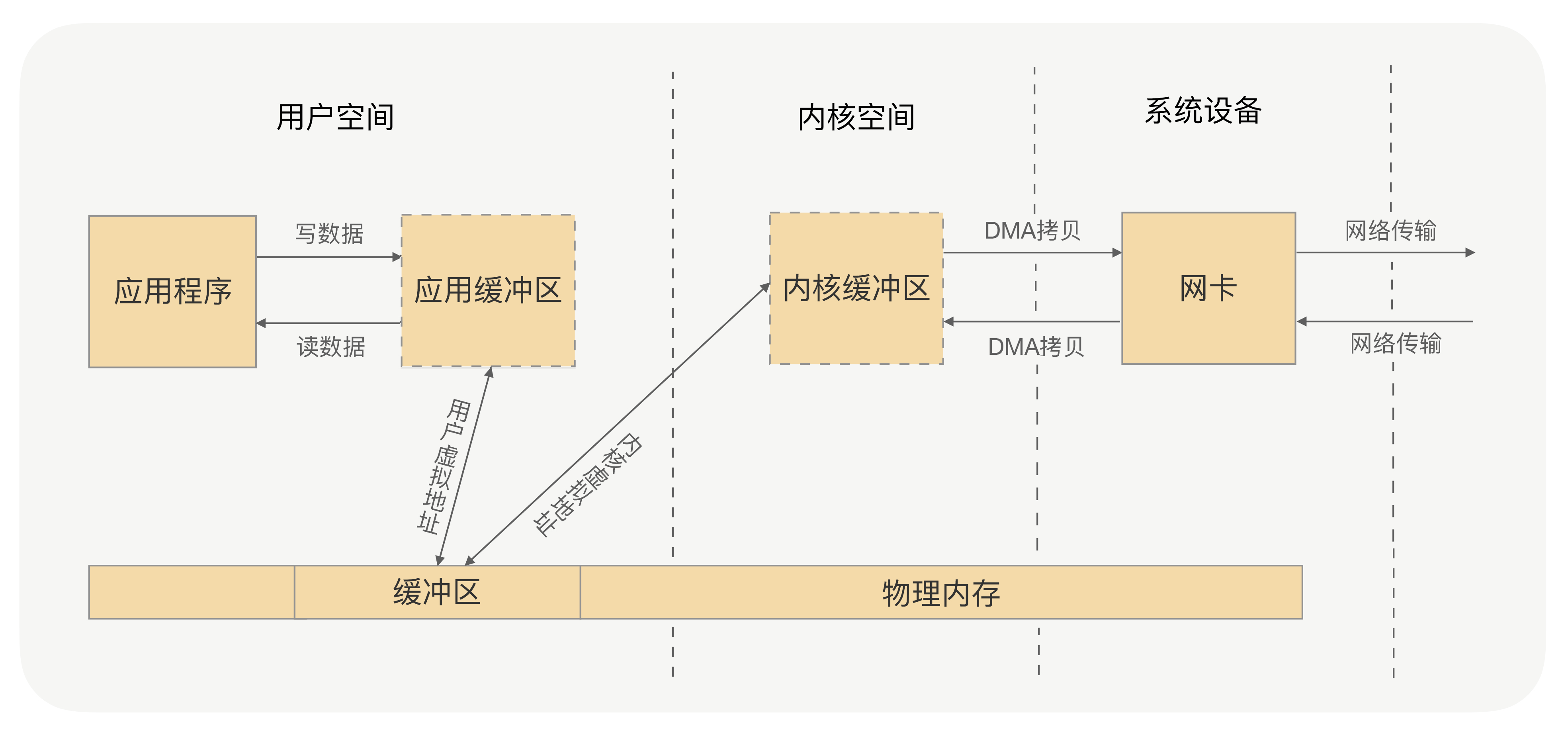
应用进程的每一次写操作,都会把数据写到用户空间的缓冲区中,再由 CPU 将数据拷贝到系统内核的缓冲区中,之后再由 DMA 将这份数据拷贝到网卡中,最后由网卡发送出去。这里我们可以看到,一次写操作数据要拷贝两次才能通过网卡发送出去,而用户进程的读操作则是将整个流程反过来,数据同样会拷贝两次才能让应用程序读取到数据。
应用进程的一次完整的读写操作,都需要在用户空间与内核空间中来回拷贝,并且每一次拷贝,都需要 CPU 进行一次上下文切换(由用户进程切换到系统内核,或由系统内核切换到用户进程),这样很浪费 CPU 和性能。
为了保障应用升级后,我们的业务行为还能保持和升级前一样,我们在大多数情况下都是依靠已有的 TestCase 去验证,但这种方式在一定程度上并不是完全可靠的。最可靠的方式就是引入线上 Case 去验证改造后的应用,把线上的真实流量在改造后的应用里面进行回放,这样不仅节省整个上线时间,还能弥补手动维护 Case 存在的缺陷。