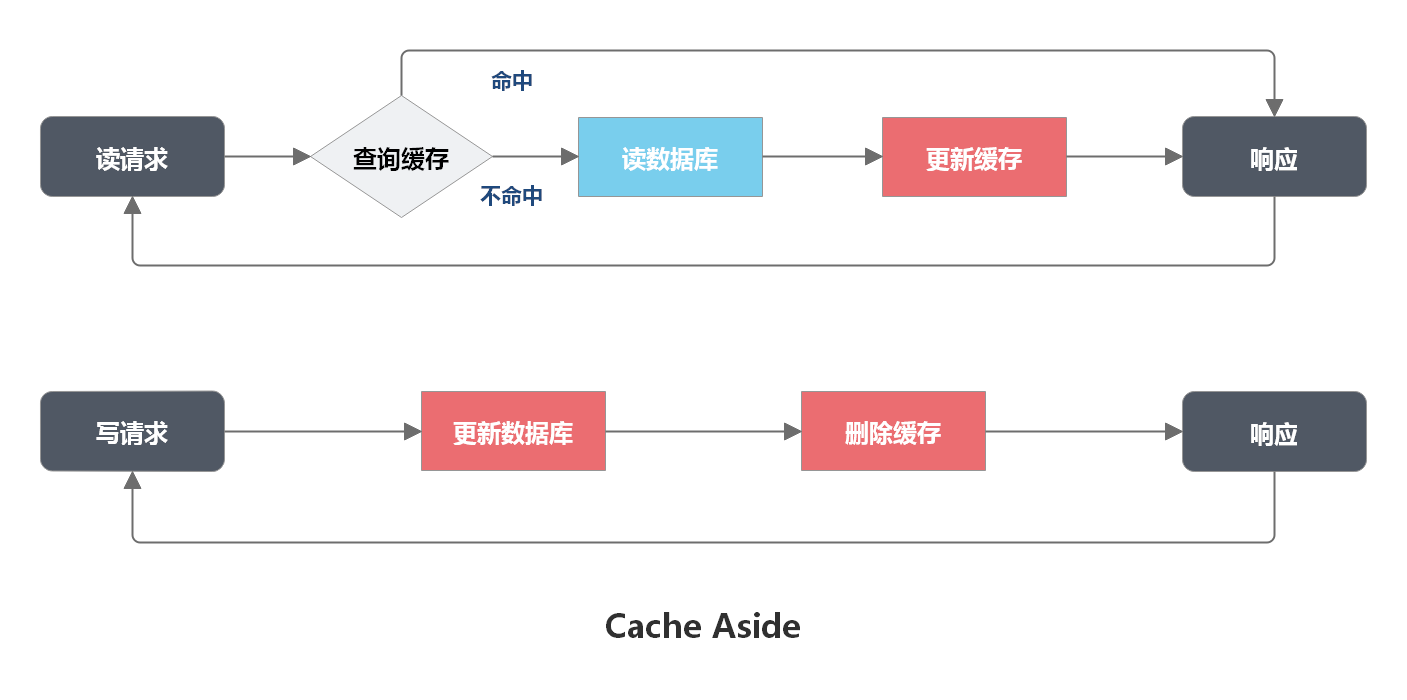
读写分离基本原理
读写分离基本原理
读写分离的基本原理是:主服务器用来处理写操作以及实时性要求比较高的读操作,而从服务器用来处理读操作。
为何要读写分离
- 有效减少锁竞争 - 主服务器只负责写,从服务器只负责读,能够有效的避免由数据更新导致的行锁竞争,使得整个系统的查询性能得到极大的改善。
- 提高查询吞吐量 - 通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
- 提升数据库可用性 - 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升数据库的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
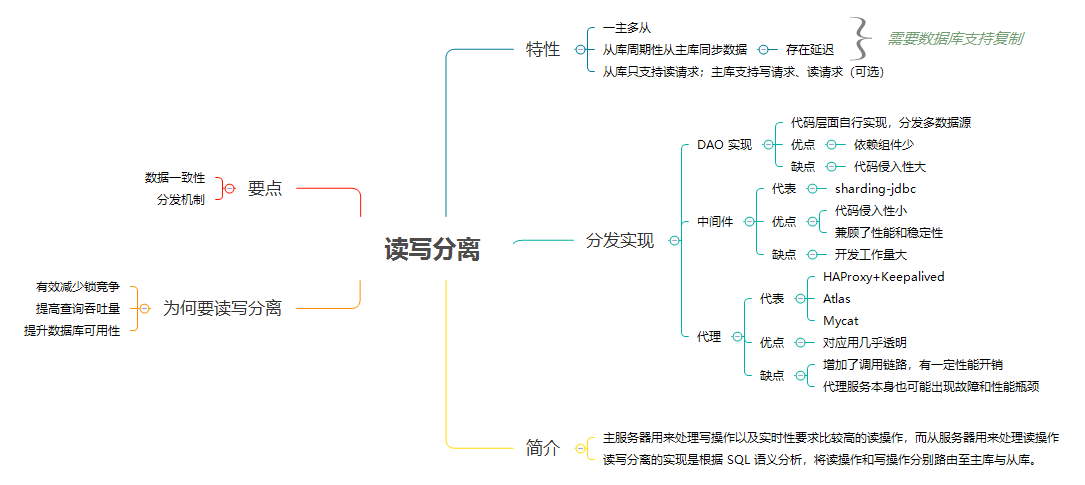
读写分离的原理
读写分离的实现是根据 SQL 语义分析,将读操作和写操作分别路由至主库与从库。

读写分离的基本实现是:
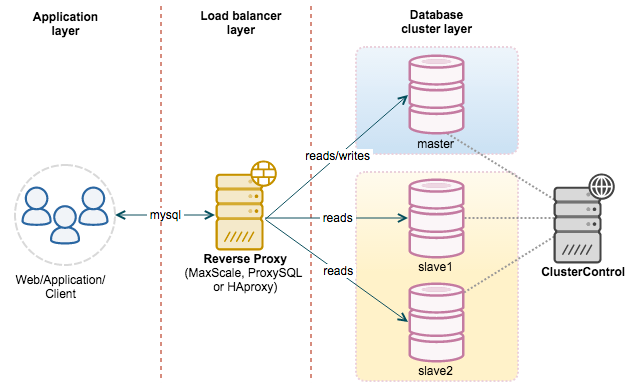
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了全量数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
- 主机会记录请求的二进制日志,然后推送给从库,从库解析并执行日志中的请求,完成主从复制。这意味着:复制过程存在时延,这段时间内,主从数据可能不一致。
读写分离的问题
读写分离存在两个问题:数据一致性和分发机制。
数据一致性
读写分离产生了主库与从库之间的数据一致性的问题。

分发机制
数据库读写分离后,一个 SQL 请求具体分发到哪个数据库节点?一般有两种分发方式:客户端分发和中间件代理分发。
客户端分发,是基于程序代码,自行控制数据分发到哪个数据库节点。更细一点来说,一般程序中建立多个数据库的连接,根据一定的算法,选择合适的连接去发起 SQL 请求。这种方式也被称为客户端中间件,代表有:jdbc-sharding。
中间件代理分发,指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。代表有:Mycat。
参考资料
JavaAgent
JavaAgent
Javaagent 是什么?
Javaagent 是 java 命令的一个参数。参数 javaagent 可以用于指定一个 jar 包,它利用 JVM 提供的 Instrumentation API 来更改加载 JVM 中的现有字节码。
- 这个 jar 包的 MANIFEST.MF 文件必须指定 Premain-Class 项。
- Premain-Class 指定的那个类必须实现 premain() 方法。
premain 方法,从字面上理解,就是运行在 main 函数之前的的类。当 Java 虚拟机启动时,在执行 main 函数之前,JVM 会先运行-javaagent所指定 jar 包内 Premain-Class 这个类的 premain 方法 。
在命令行输入 java可以看到相应的参数,其中有 和 java agent 相关的:
1 | -agentlib:<libname>[=<选项>] |
Java Agent 技术简介
Java Agent 直译为 Java 代理,也常常被称为 Java 探针技术。
Java Agent 是在 JDK1.5 引入的,是一种可以动态修改 Java 字节码的技术。Java 中的类编译后形成字节码被 JVM 执行,在 JVM 在执行这些字节码之前获取这些字节码的信息,并且通过字节码转换器对这些字节码进行修改,以此来完成一些额外的功能。
Java Agent 是一个不能独立运行 jar 包,它通过依附于目标程序的 JVM 进程,进行工作。启动时只需要在目标程序的启动参数中添加-javaagent 参数添加 ClassFileTransformer 字节码转换器,相当于在 main 方法前加了一个拦截器。
Java Agent 功能介绍
Java Agent 主要有以下功能
- Java Agent 能够在加载 Java 字节码之前拦截并对字节码进行修改;
- Java Agent 能够在 Jvm 运行期间修改已经加载的字节码;
Java Agent 的应用场景
- IDE 的调试功能,例如 Eclipse、IntelliJ IDEA ;
- 热部署功能,例如 JRebel、XRebel、spring-loaded;
- 各种线上诊断工具,例如 Btrace、Greys,还有阿里的 Arthas;
- 各种性能分析工具,例如 Visual VM、JConsole 等;
- 全链路性能检测工具,例如 Skywalking、Pinpoint 等;
Java Agent 实现原理
在了解 Java Agent 的实现原理之前,需要对 Java 类加载机制有一个较为清晰的认知。一种是在 man 方法执行之前,通过 premain 来执行,另一种是程序运行中修改,需通过 JVM 中的 Attach 实现,Attach 的实现原理是基于 JVMTI。
主要是在类加载之前,进行拦截,对字节码修改
下面我们分别介绍一下这些关键术语:
JVMTI 就是 JVM Tool Interface,是 JVM 暴露出来给用户扩展使用的接口集合,JVMTI 是基于事件驱动的,JVM 每执行一定的逻辑就会触发一些事件的回调接口,通过这些回调接口,用户可以自行扩展
JVMTI 是实现 Debugger、Profiler、Monitor、Thread Analyser 等工具的统一基础,在主流 Java 虚拟机中都有实现
JVMTIAgent是一个动态库,利用 JVMTI 暴露出来的一些接口来干一些我们想做、但是正常情况下又做不到的事情,不过为了和普通的动态库进行区分,它一般会实现如下的一个或者多个函数:
- Agent_OnLoad 函数,如果 agent 是在启动时加载的,通过 JVM 参数设置
- Agent_OnAttach 函数,如果 agent 不是在启动时加载的,而是我们先 attach 到目标进程上,然后给对应的目标进程发送 load 命令来加载,则在加载过程中会调用 Agent_OnAttach 函数
- Agent_OnUnload 函数,在 agent 卸载时调用
javaagent 依赖于 instrument 的 JVMTIAgent(Linux 下对应的动态库是 libinstrument.so),还有个别名叫 JPLISAgent(Java Programming Language Instrumentation Services Agent),专门为 Java 语言编写的插桩服务提供支持的
instrument 实现了 Agent_OnLoad 和 Agent_OnAttach 两方法,也就是说在使用时,agent 既可以在启动时加载,也可以在运行时动态加载。其中启动时加载还可以通过类似-javaagent:jar 包路径的方式来间接加载 instrument agent,运行时动态加载依赖的是 JVM 的 attach 机制,通过发送 load 命令来加载 agent
JVM Attach 是指 JVM 提供的一种进程间通信的功能,能让一个进程传命令给另一个进程,并进行一些内部的操作,比如进行线程 dump,那么就需要执行 jstack 进行,然后把 pid 等参数传递给需要 dump 的线程来执行
Java Agent 案例
加载 Java 字节码之前拦截
App 项目
(1)创建一个名为 javacore-javaagent-app 的 maven 工程
1 |
|
(2)创建一个应用启动类
1 | public class AppMain { |
(3)创建一个模拟应用初始化的类
1 | public class AppInit { |
(4)输出
1 | APP 启动!!! |
Agent 项目
(1)创建一个名为 javacore-javaagent-agent 的 maven 工程
1 | <?xml version="1.0" encoding="UTF-8"?> |
(2)创建一个 Agent 启动类
1 | public class RunTimeAgent { |
这里每个类加载的时候都会走这个方法,我们可以通过 className 进行指定类的拦截,然后借助 javassist 这个工具,进行对 Class 的处理,这里的思想和反射类似,但是要比反射功能更加强大,可以动态修改字节码。
(3)使用 javassist 拦截指定类,并进行代码增强
1 | package io.github.dunwu.javacore.javaagent; |
(4)输出
指定 VM 参数 -javaagent:F:\code\myCode\agent-test\runtime-agent\target\runtime-agent-1.0-SNAPSHOT.jar=hello,运行 AppMain
1 | 探针启动!!! |
运行时拦截(JDK 1.6 及以上)
如何实现在程序运行时去完成动态修改字节码呢?
动态修改字节码需要依赖于 JDK 为我们提供的 JVM 工具,也就是上边我们提到的 Attach,通过它去加载我们的代理程序。
首先我们在代理程序中需要定义一个名字为 agentmain 的方法,它可以和上边我们提到的 premain 是一样的内容,也可根据 agentmain 的特性进行自己逻辑的开发。
1 | /** |
然后就是我们需要将配置中设置,让其知道我们的探针需要加载这个类,在 maven 中设置如下,如果是 META-INF/MANIFEST.MF 文件同理。
1 | <!--<Premain-Class>com.zhj.agent.agentmain.RunTimeAgent</Premain-Class>--> |
这样其实我们的探针就已经改造好了,然后我们需要在目标程序的 main 方法中植入一些代码,使其可以读取到我们的代理程序,这样我们也无需去配置 JVM 的参数,就可以加载探针程序。
1 | public class APPMain { |
其中 VirtualMachine 是 JDK 工具包下的类,如果系统环境变量没有配置,需要自己在 Maven 中引入本地文件。
1 | <dependency> |
这样我们在程序启动后再去动态修改字节码文件的简单案例就完成了。
参考资料
《后端存储实战课》笔记
《后端存储实战课》笔记
课前加餐丨电商系统是如何设计的?
创建和更新订单时,如何保证数据准确无误?
流量大、数据多的商品详情页系统该如何设计?
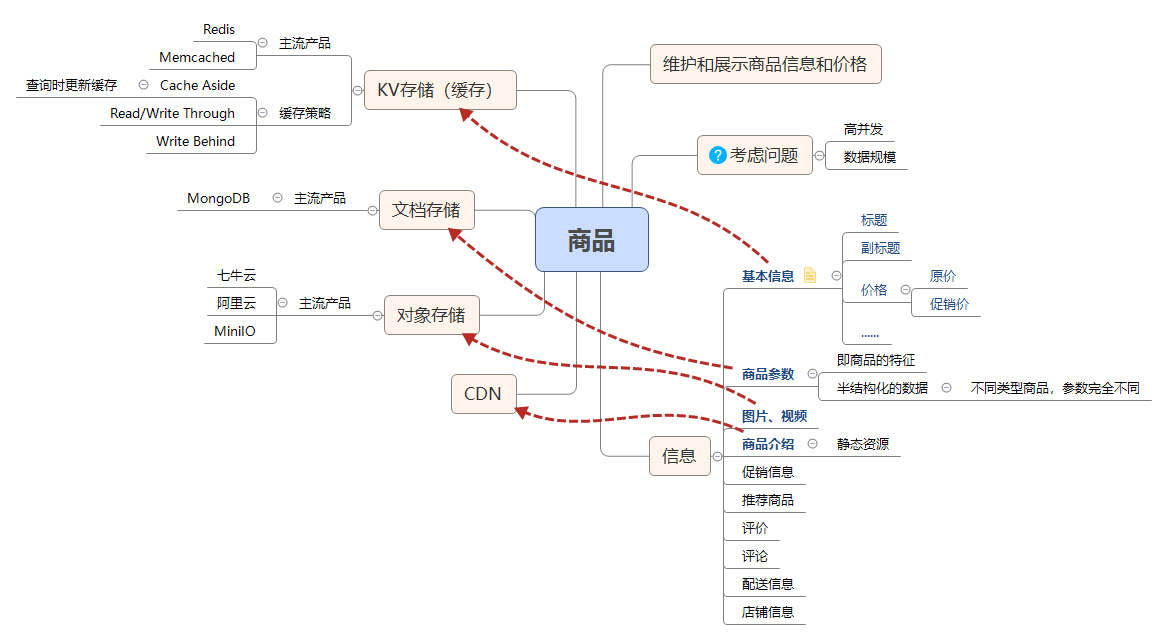
复杂而又重要的购物车系统,应该如何设计?
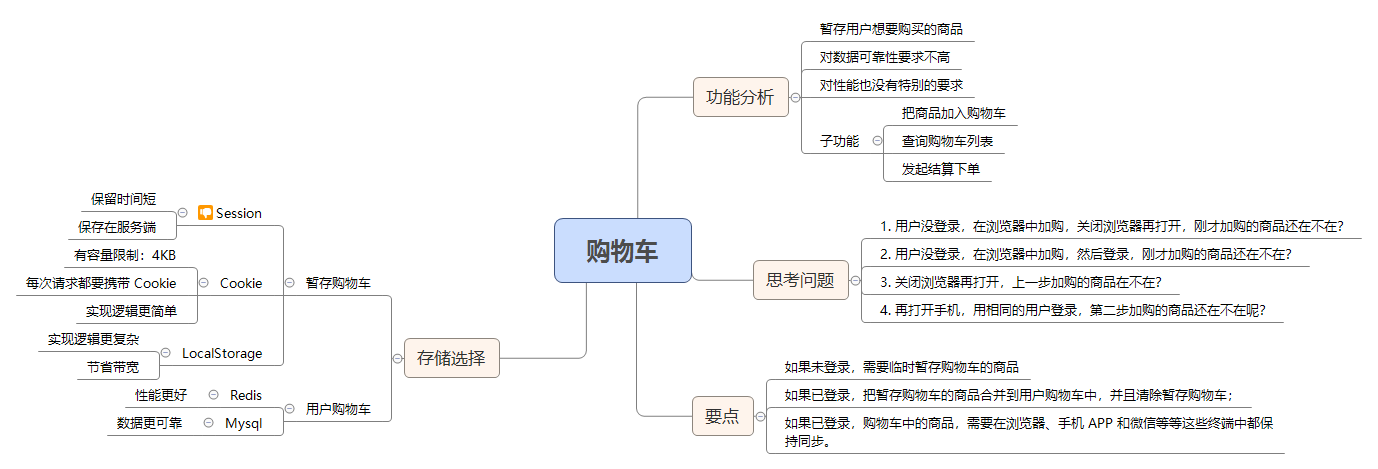
事务:账户余额总是对不上账,怎么办?
分布式事务:如何保证多个系统间的数据是一致的?
分布式事务常见解决方案:
- 2PC
- 3PC
- TCC
- Saga
- 本地消息表
个人以前总结:分布式事务
如何用 Elasticsearch 构建商品搜索系统?
搜索领域的核心问题是进行全文匹配。一般的关系型数据库,如 Mysql 的索引(InnoDB 为 B 树索引)不适用于全文检索,导致查询时只能全表扫描,性能很差。
搜索引擎(典型代表:Elasticsearch)通过倒排索引技术,很好的支持了全文检索。但是,倒排索引的写入和更新性能相较于 B 树索引较差,因此不适用于更新频繁的数据。
MySQL HA:如何将“删库跑路”的损失降到最低?
Mysql 复制(略)
一个几乎每个系统必踩的坑儿:访问数据库超时
数据库超时分析经验:
- 根据故障时段在系统忙时,推断出故障是跟支持用户访问的功能有关。
- 根据系统能在流量峰值过后自动恢复这一现象,排除后台服务被大量请求打死的可能性。
- 根据 CPU 利用率的变化曲线,如果满足一定的周期性波动,可推断出大概率和定时任务有关。这些定时任务负责刷新数据缓存。如果确实是因为刷新缓存定时任务导致的,需要针对性优化。
- 如果 Mysql CPU 过高,大概率是慢 SQL 导致的,优先排查慢 SQL 日志,找出查询特别慢的表。看看该表是不是需要加缓存。
避免访问数据库超时的注意点:
- 开发时,考虑 SQL 相关表的数据规模,查询性能,是否匹配索引等等,避免出现慢 SQL
- 设计上,考虑减少查询次数,如使用缓存
- 系统支持自动杀慢 SQL
- 支持熔断、降级,减少故障影响范围
怎么能避免写出慢 SQL?
数据表不宜过大,一般不要超过千万条数据。
根据实际情况,尽量设计好索引,以提高查询、排序效率。
如果出现慢 SQL,需要改造索引时,可以通过执行计划进行分析。
走进黑盒:SQL 是如何在数据库中执行的?
MySQL 如何应对高并发(一):使用缓存保护 MySQL
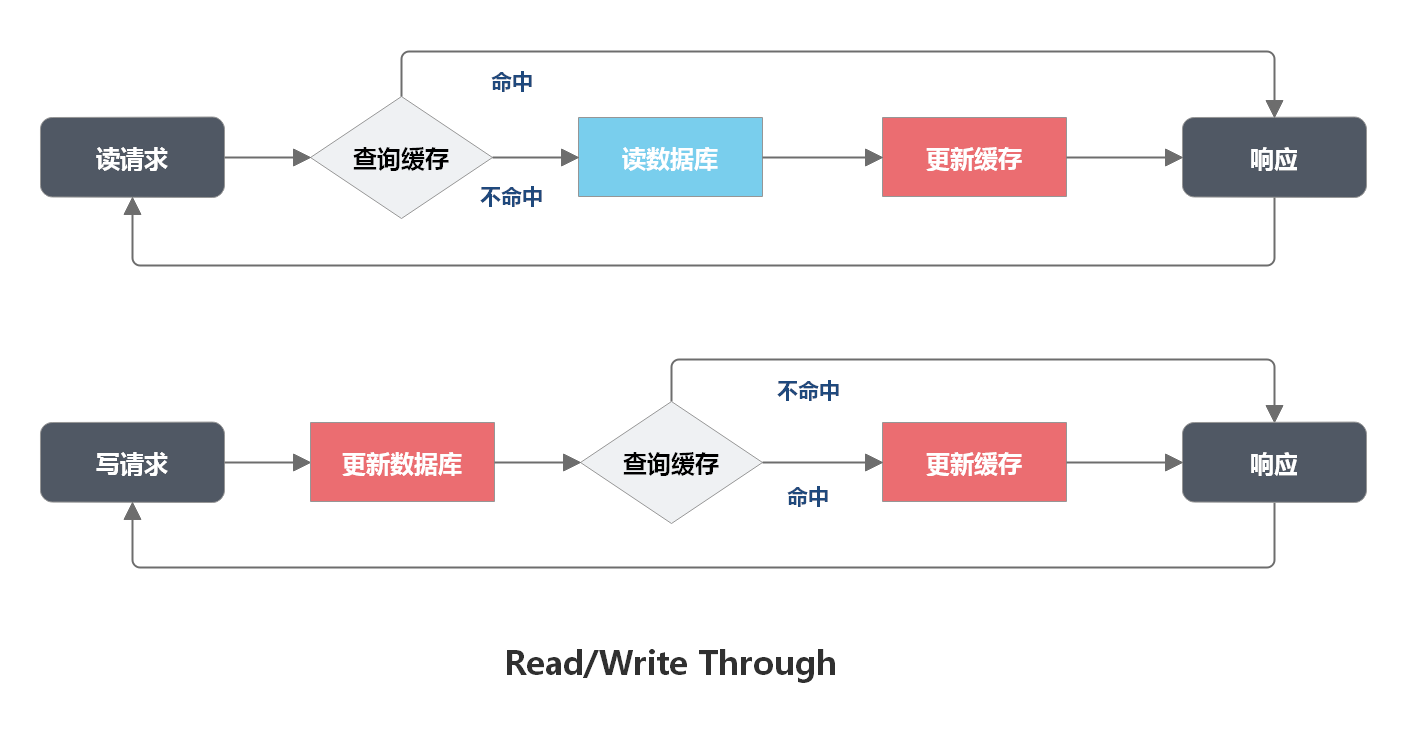
MySQL 如何应对高并发(二):读写分离
MySQL 主从数据库同步是如何实现的?
基于 binlog 进行数据同步
订单数据越来越多,数据库越来越慢该怎么办?
针对大表,为了优化其查询性能,可以将历史数据归档。一般可以考虑归档到列式数据库,如:Hive
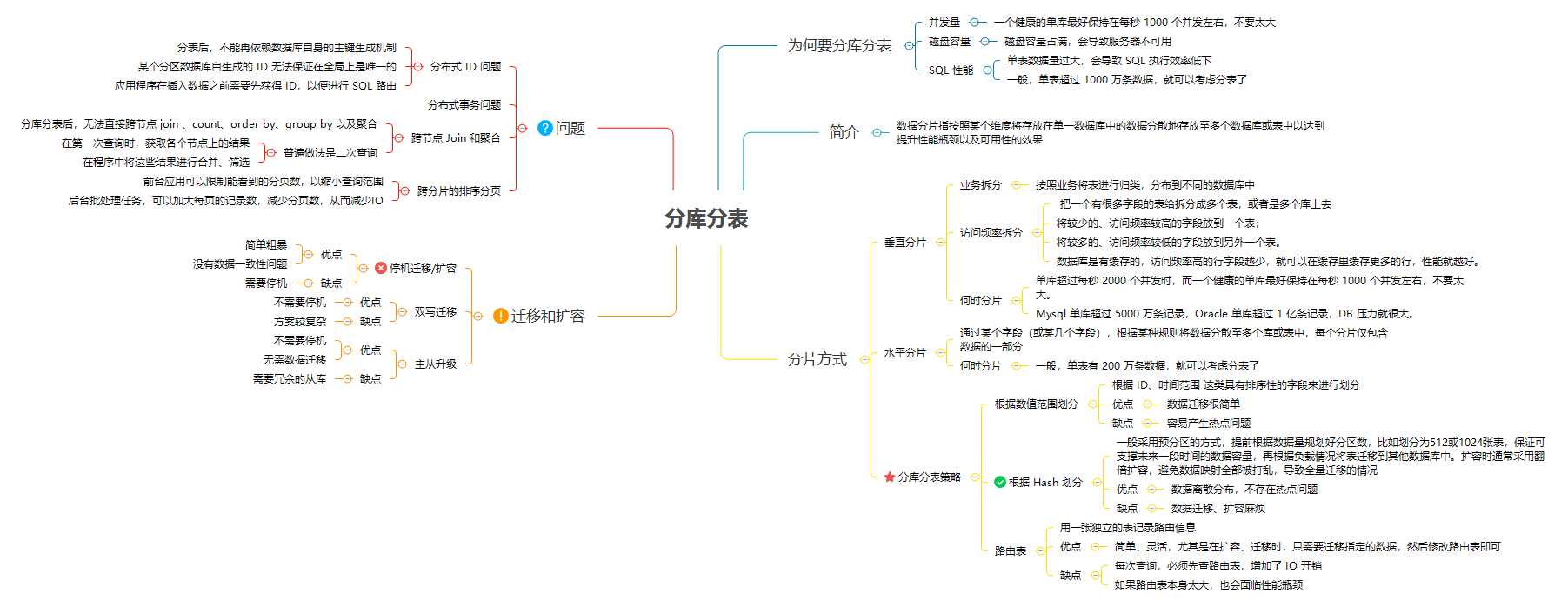
MySQL 存储海量数据的最后一招:分库分表
分库分表
用 Redis 构建缓存集群的最佳实践有哪些
Redis 3.0 后,官方提供 Redis Cluster 来解决数据量大、高可用和高并发问题。
相关文章:Redis 集群
大厂都是怎么做 MySQL to Redis 同步的?
缓存穿透:把全量数据都放在 Redis 集群,服务通过接受 MQ 消息,去触发更新缓存数据。
使用 Binlog 实时更新 Redis 缓存,如 Canal
分布式存储:你知道对象存储是如何保存图片文件的吗?
保存图片、音频、视频这种相对较大的文件,一般使用对象存储。如:HDFS 等。
元数据管理:ZooKeeper、etcd、Nacos
对象如何拆分和保存:将大文件分块(block),提升 IO 效率并方便维护。
跨系统实时同步数据,分布式事务是唯一的解决方案吗?
跨系统实时同步数据:
- 早期方案:使用 ETL 定时同步数据,在 T+1 时刻去同步上一周期的数据,然后进行计算和分析。
- 使用 Binlog 和 MQ 构建实时数据同步系统
如何保证数据同步的实时性
- 为了能够支撑众多下游数据库实时同步的需求,可以通过 MQ 解耦上下游,Binlog 先发送到 MQ 中,下游各业务方可以消费 MQ 中的消息再写入各自的数据库。
- 如果下游处理能力不能满足要求,可以增加 MQ 中的分区数量实现并发同步,但需要结合同步的业务数据特点,把具有因果关系的数据哈希到相同分区上,才能避免因为并发乱序而出现数据同步错误的问题。
如何在不停机的情况下,安全地更换数据库?
- 停机迁移/扩容
- 优点:简单粗暴;没有数据一致性问题
- 缺点:需要停机
- 双写迁移
- 优点:不需要停机
- 缺点:方案较复杂
- 主从升级
- 优点:不需要停机;无需数据迁移
- 缺点:需要冗余的从库
类似“点击流”这样的海量数据应该如何存储?
使用 Kafka 暂存海量原始数据,然后再使用大数据计算框架(Spark、Flink)进行计算。
其他方案:
分布式流数据存储,如:Pravega、Pulsar 的存储引擎 BookKeeper
时序数据库,如:InfluxDB、OpenTSDB 等。
面对海量数据,如何才能查得更快
实时计算:Flink、Storm
批处理计算:Map-Reduce、Spark
海量数据存储:
- 列式数据库(在正确使用的前提下,10GB 量级的数据查询基本上可以做到秒级返回):HBase、Cassandra
- 搜索引擎(对于 TB 量级以下的数据,如果可以接受相对比较贵的硬件成本):Elasticsearch
MySQL 经常遇到的高可用、分片问题,NewSQL 是如何解决的?
安利 CockroachDB、RocksDB、OceanBase
RocksDB:不丢数据的高性能 KV 存储、
越来越多的新生代数据库,都选择 RocksDB 作为它们的存储引擎。
Redis 是一个内存数据库,所以它很快。
RocksDB 是一个持久化的 KV 存储,它需要保证每条数据都要安全地写到磁盘上。磁盘的读写性能和内
存读写性能差着一两个数量级,读写磁盘的 RocksDB,能和读写内存的 Redis 做到相近的性能,这就是 RocksDB 的价值所在了。
RocksDB 性能好,是由于使用了 LSM 树结构。
LSM-Tree 的全称是:The Log-Structured Merge-Tree,是一种非常复杂的复合数据结构,它包含了 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table)。
参考资料
- 后端存储实战课 - 极客教程【入门】:讲解存储在电商领域的种种应用和一些基本特性
数据结构与数据库索引
数据结构与数据库索引
关键词:链表、数组、散列表、红黑树、B+ 树、LSM 树、跳表
引言
数据库是“按照 数据结构 来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
——上面这句定义对数据库的定义来自百度百科。通过这个定义,我们也能明显看出数据结构是实现数据库的基石。
从本质来看,数据库只负责两件事:读数据、写数据;而数据结构研究的是如何合理组织数据,尽可能提升读、写数据的效率,这恰好是数据库的核心问题。因此,数据结构与数据库这两个领域有非常多的交集。其中,数据库索引最能体现二者的紧密关联。
索引是数据库为了提高查找效率的一种数据结构。索引基于原始数据衍生而来,它的主要作用是缩小检索的数据范围,提升查询性能。通俗来说,索引在数据库中的作用就像是一本书的目录索引。索引对于良好的性能非常关键,在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,索引优化应该是查询性能优化的最有效手段。
很多数据库允许单独添加和删除索引,而不影响数据库的内容,它只会影响查询性能。维护额外的结构势必会引入开销,特别是在新数据写入时。对于写入,它很难超过简单地追加文件方式的性能,因为那已经是最简单的写操作了。由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
本文以一些常见的数据库为例,分析它们的索引采用了什么样的数据结构,有什么利弊,为何如此设计。
数组和链表
数组和链表分别代表了连续空间和不连续空间的存储方式,它们是线性表(Linear List)的典型代表。其他所有的数据结构,比如栈、队列、二叉树、B+ 树等,实际上都是这两者的结合和变化。
数组用连续的内存空间来存储数据。数组**支持随机访问,根据下标随机访问的时间复杂度为 O(1)**。但这并不代表数组的查找时间复杂度也是 O(1)。
- **对于无序数组,只能顺序查找,其时间复杂度为
O(n)**。 - **对于有序数组,可以应用二分查找法,其时间复杂度为
O(log n)**。
在有序数组上应用二分查找法如此高效,为什么几乎没有数据库直接使用数组作为索引?这是因为它的限制条件:数据有序——为了保证数据有序,每次添加、删除数组数据时,都必须要进行数据调整,来保证其有序,而 **数组的插入/删除操作,时间复杂度为 O(n)**。此外,由于数组空间大小固定,每次扩容只能采用复制数组的方式。数组的这些特性,决定了它不适合用于数据频繁变化的应用场景。
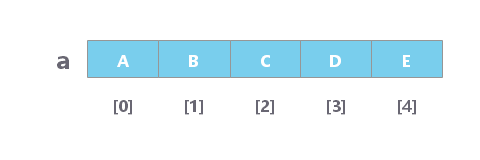
链表用不连续的内存空间来存储数据;并通过一个指针按顺序将这些空间串起来,形成一条链。
区别于数组,链表中的元素不是存储在内存中连续的一片区域,链表中的数据存储在每一个称之为“结点”复合区域里,在每一个结点除了存储数据以外,还保存了到下一个节点的指针(Pointer)。由于不必按顺序存储,**链表的插入/删除操作,时间复杂度为 O(1)**,但是,链表只支持顺序访问,其 **查找时间复杂度为 O(n)**。其低效的查找方式,决定了链表不适合作为索引。
哈希索引
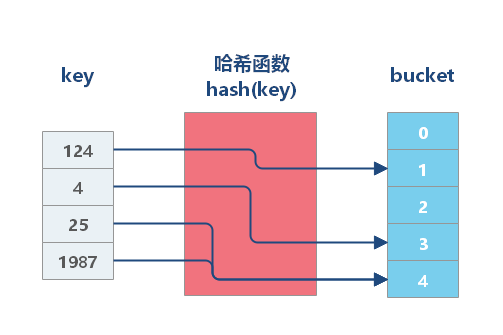
哈希表是一种以键 - 值(key-value)对形式存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。
哈希表 使用 哈希函数 组织数据,以支持快速插入和搜索的数据结构。哈希表的本质是一个数组,其思路是:使用 Hash 函数将 Key 转换为数组下标,利用数组的随机访问特性,使得我们能在 O(1) 的时间代价内完成检索。
有两种不同类型的哈希表:哈希集合 和 哈希映射。
- 哈希集合 是集合数据结构的实现之一,用于存储非重复值。
- 哈希映射 是映射 数据结构的实现之一,用于存储键值对。
哈希索引基于哈希表实现,只适用于等值查询。对于每一行数据,哈希索引都会将所有的索引列计算一个哈希码(hashcode),哈希码是一个较小的值。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
✔️️️ 哈希索引的优点:
- 因为索引数据结构紧凑,所以查询速度非常快。
❌ 哈希索引的缺点:
- 哈希索引值包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响不大。
- 哈希索引数据不是按照索引值顺序存储的,所以无法用于排序。
- 哈希索引不支持部分索引匹配查找,因为哈希索引时使用索引列的全部内容来进行哈希计算的。如,在数据列 (A,B) 上建立哈希索引,如果查询只有数据列 A,无法使用该索引。
- 哈希索引只支持等值比较查询,包括
=、IN()、<=>;不支持任何范围查询,如WHERE price > 100。 - 哈希索引有可能出现哈希冲突
- 出现哈希冲突时,必须遍历链表中所有的行指针,逐行比较,直到找到符合条件的行。
- 如果哈希冲突多的话,维护索引的代价会很高。
因为种种限制,所以哈希索引只适用于特定的场合。而一旦使用哈希索引,则它带来的性能提升会非常显著。例如,Mysql 中的 Memory 存储引擎就显示的支持哈希索引。
B-Tree 索引
通常我们所说的 B 树索引是指 B-Tree 索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。使用 B-Tree 这个术语,是因为 MySQL 在 CREATE TABLE 或其它语句中使用了这个关键字,但实际上不同的存储引擎可能使用不同的数据结构,比如 InnoDB 使用的是 B+Tree索引;而 MyISAM 使用的是 B-Tree索引。
B-Tree 索引中的 B 是指 balance,意为平衡。需要注意的是,B-Tree 索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
二叉搜索树
二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。其查询时间复杂度是 O(log n)。
当然为了维持 O(log n) 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是 O(log n)。
随着数据库中数据的增加,索引本身大小随之增加,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘 I/O 消耗,相对于内存存取,I/O 存取的消耗要高几个数量级。可以想象一下一棵几百万节点的二叉树的深度是多少?如果将这么大深度的一颗二叉树放磁盘上,每读取一个节点,需要一次磁盘的 I/O 读取,整个查找的耗时显然是不能够接受的。那么如何减少查找过程中的 I/O 存取次数?
一种行之有效的解决方法是减少树的深度,将二叉树变为 N 叉树(多路搜索树),而 B+ 树就是一种多路搜索树。
B+Tree 索引
B+ 树索引适用于全键值查找、键值范围查找和键前缀查找,其中键前缀查找只适用于最左前缀查找。
理解 B+Tree,只需要理解其最重要的两个特征即可:
- 第一,所有的关键字(可以理解为数据)都存储在叶子节点,非叶子节点并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。
- 其次,所有的叶子节点由指针连接。如下图为简化了的
B+Tree。
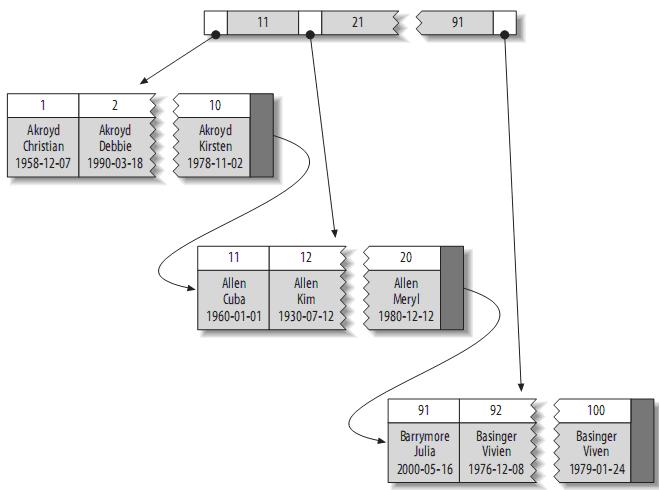
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 聚簇索引(clustered):又称为主键索引,其叶子节点存的是整行数据。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。InnoDB 的聚簇索引实际是在同一个结构中保存了 B 树的索引和数据行。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary)。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于 249 个。
聚簇表示数据行和相邻的键值紧凑地存储在一起,因为数据紧凑,所以访问快。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
聚簇索引和非聚簇索引的查询有什么区别
- 如果语句是
select * from T where ID=500,即聚簇索引查询方式,则只需要搜索 ID 这棵 B+ 树; - 如果语句是
select * from T where k=5,即非聚簇索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非聚簇索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
显然,主键长度越小,非聚簇索引的叶子节点就越小,非聚簇索引占用的空间也就越小。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。从性能和存储空间方面考量,自增主键往往是更合理的选择。有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
内存是半导体元件。对于内存而言,只要给出了内存地址,我们就可以直接访问该地址取出数据。这个过程具有高效的随机访问特性,因此内存也叫随机访问存储器(Random Access Memory,即 RAM)。内存的访问速度很快,但是价格相对较昂贵,因此一般的计算机内存空间都相对较小。
而磁盘是机械器件。磁盘访问数据时,需要等磁盘盘片旋转到磁头下,才能读取相应的数据。尽管磁盘的旋转速度很快,但是和内存的随机访问相比,性能差距非常大。一般来说,如果是随机读写,会有 10 万到 100 万倍左右的差距。但如果是顺序访问大批量数据的话,磁盘的性能和内存就是一个数量级的。
磁盘的最小读写单位是扇区,较早期的磁盘一个扇区是 512 字节。随着磁盘技术的发展,目前常见的磁盘扇区是 4K 个字节。操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block),也叫作簇(Cluster)。当我们要从磁盘中读取一个数据时,操作系统会一次性将整个块都读出来。因此,对于大批量的顺序读写来说,磁盘的效率会比随机读写高许多。
假设有一个有序数组存储在硬盘中,如果它足够大,那么它会存储在多个块中。当我们要对这个数组使用二分查找时,需要先找到中间元素所在的块,将这个块从磁盘中读到内存里,然后在内存中进行二分查找。如果下一步要读的元素在其他块中,则需要再将相应块从磁盘中读入内存。直到查询结束,这个过程可能会多次访问磁盘。我们可以看到,这样的检索性能非常低。
由于磁盘相对于内存而言访问速度实在太慢,因此,对于磁盘上数据的高效检索,我们有一个极其重要的原则:对磁盘的访问次数要尽可能的少!
将索引和数据分离就是一种常见的设计思路。在数据频繁变化的场景中,有序数组并不是一个最好的选择,二叉检索树或者哈希表往往更有普适性。但是,哈希表由于缺乏范围检索的能力,在一些场合也不适用。因此,二叉检索树这种树形结构是许多常见检索系统的实施方案。
随着索引数据越来越大,直到无法完全加载到内存中,这是需要将索引数据也存入磁盘中。B+ 树给出了将树形索引的所有节点都存在磁盘上的高效检索方案。操作系统对磁盘数据的访问是以块为单位的。因此,如果我们想将树型索引的一个节点从磁盘中读出,即使该节点的数据量很小(比如说只有几个字节),但磁盘依然会将整个块的数据全部读出来,而不是只读这一小部分数据,这会让有效读取效率很低。B+ 树的一个关键设计,就是让一个节点的大小等于一个块的大小。节点内存储的数据,不是一个元素,而是一个可以装 m 个元素的有序数组。这样一来,我们就可以将磁盘一次读取的数据全部利用起来,使得读取效率最大化。
B+ 树还有另一个设计,就是将所有的节点分为内部节点和叶子节点。内部节点仅存储 key 和维持树形结构的指针,并不存储 key 对应的数据(无论是具体数据还是文件位置信息)。这样内部节点就能存储更多的索引数据,我们也就可以使用最少的内部节点,将所有数据组织起来了。而叶子节点仅存储 key 和对应数据,不存储维持树形结构的指针。通过这样的设计,B+ 树就能做到节点的空间利用率最大化。此外,B+ 树还将同一层的所有节点串成了有序的双向链表,这样一来,B+ 树就同时具备了良好的范围查询能力和灵活调整的能力了。
因此,B+ 树是一棵完全平衡的 m 阶多叉树。所谓的 m 阶,指的是每个节点最多有 m 个子节点,并且每个节点里都存了一个紧凑的可包含 m 个元素的数组。
即使是复杂的 B+ 树,我们将它拆解开来,其实也是由简单的数组、链表和树组成的,而且 B+ 树的检索过程其实也是二分查找。因此,如果 B+ 树完全加载在内存中的话,它的检索效率其实并不会比有序数组或者二叉检索树更
高,也还是二分查找的 log(n) 的效率。并且,它还比数组和二叉检索树更加复杂,还会带来额外的开销。
另外,这一节还有一个很重要的设计思想需要你掌握,那就是将索引和数据分离。通过这样的方式,我们能将索引的数组大小保持在一个较小的范围内,让它能加载在内存中。在许多大规模系统中,都是使用这个设计思想来精简索引的。而且,B+ 树的内部节点和叶子节点的区分,其实也是索引和数据分离的一次实践。
MySQL 中的 B+ 树实现其实有两种,一种是 MyISAM 引擎,另一种是 InnoDB 引擎。它们的核心区别就在于,数据和索引是否是分离的。
在 MyISAM 引擎中,B+ 树的叶子节点仅存储了数据的位置指针,这是一种索引和数据分离的设计方案,叫作非聚集索引。如果要保证 MyISAM 的数据一致性,那我们需要在表级别上进行加锁处理。
在 InnoDB 中,B+ 树的叶子节点直接存储了具体数据,这是一种索引和数据一体的方案。叫作聚集索引。由于数据直接就存在索引的叶子节点中,因此 InnoDB 不需要给全表加锁来保证一致性,它只需要支持行级的锁就可以了。
LSM 树
B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。因此,每次插入的新数据都需要随机写入磁盘,而随机写入的性能非常慢。如果是一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
操作系统对磁盘的读写是以块为单位的,我们能否以块为单位写入,而不是每次插入一个数据都要随机写入磁盘呢?这样是不是就可以大幅度减少写入操作了呢?解决方案就是:LSM 树(Log Structured Merge Trees)。
LSM 树就是根据这个思路设计了这样一个机制:当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。因此,LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。
LSM 树具有以下 3 个特点:
- 将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并(Merge Trees);
- 用批量写入代替随机写入,并且用预写日志 WAL 技术(Write AheadLog,预写日志技术)保证内存数据,在系统崩溃后可以被恢复;
- 数据采取类似日志追加写的方式写入(Log Structured)磁盘,以顺序写的方式提高写
入效率。
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
倒排索引
倒排索引的核心其实并不复杂,它的具体实现其实是哈希表,只是它不是将文档 ID 或者题目作为 key,而是反过来,通过将内容或者属性作为 key 来存储对应的文档列表,使得我们能在 O(1) 的时间代价内完成查询。
尽管原理并不复杂,但是倒排索引是许多检索引擎的核心。比如说,数据库的全文索引功能、搜索引擎的索引、广告引擎和推荐引擎,都使用了倒排索引技术来实现检索功能。
索引的维护
创建索引
- 数据压缩:一个是尽可能地将数据加载到内存中,因为内存的检索效率大大高于磁盘。那为了将数据更多地加载到内存中,索引压缩是一个重要的研究方向。
- 分支处理:另一个是将大数据集合拆成多个小数据集合来处理。这其实就是分布式系统的核心思想。
更新索引
(1)Double Buffer(双缓冲)机制
就是在内存中同时保存两份一样的索引,一个是索引 A,一个是索引 B。两个索引保持一个读、一个写,并且来回切换,最终完成高性能的索引更新。
优点:简单高效
缺点:达到一定数据量级后,会带来翻倍的内存开销,甚至有些索引存储在磁盘上的情况下,更是无法使用此机制。
(2)全量索引和增量索引
将新接收到的数据单独建立一个可以存在内存中的倒排索引,也就是增量索引。当查询发生的时候,我们会同时查询全量索引和增量索引,将合并的结果作为总的结果输出。
因为增量索引相对全量索引而言会小很多,内存资源消耗在可承受范围,所以我们可以使用 Double Buffer 机制
对增量索引进行索引更新。这样一来,增量索引就可以做到无锁访问。而全量索引本身就是只读的,也不需要加锁。因此,整个检索过程都可以做到无锁访问,也就提高了系统的检索效率。
参考资料
复杂度分析
复杂度分析
为什么需要复杂度分析
衡量算法的优劣,有两种评估方式:事前估计和后期测试。
后期测试有性能测试、基准测试(Benchmark)等手段。
但是,后期测试有以下限制:
- 测试结果非常依赖测试环境。如:不同机型、不同编译器版本、不同硬件配置等等,都会影响测试结果。
- 测试结果受数据规模的影响很大。
所以,需要一种方法,可以不受环境或数据规模的影响,粗略地估计算法的执行效率。这种方法就是复杂度分析。
时间复杂度分析
大 O 表示法
假设问题的规模为 n,则程序的时间复杂度表示为 T(n)。代码的执行时间 T(n) 与每行代码的执行次数 n 成正比。
当 n 增大时,T(n) 也随之增大,想要准确估计其变化比较困难。所以,可以采用大 O 时间复杂度来粗略估计其复杂度,其表达式为:**T(n) = O(f(n))**。
大 O 表示法实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
时间复杂度分析的要点
- 只关注循环执行次数最多的一段代码
- 加法法则:总复杂度等于量级最大的那段代码的复杂度
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
最好、最坏和平均情况
- 最好情况时间复杂度(best case time complexity):在最理想的情况下,执行代码的时间复杂度。例如:在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,此时最好情况时间复杂度为 1。
- 最坏情况时间复杂度(worst case time complexity):在最糟糕的情况下,执行代码的时间复杂度。例如:在最理想的情况下,要查找的变量 x 正好是数组的最后个元素,此时最好情况时间复杂度为 n。
- 平均情况时间复杂度(average case time complexity):平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
时间复杂度分析示例
【示例】从 1 累加到 100 的时间复杂度是多少?
1 | int sum = 0; |
时间复杂度计算:显然,这段代码执行了 100 次加法,其时间复杂度和 N 的大小完全一致
1 | T(n) = O(n) |
【示例】嵌套循环的时间复杂度是多少?
1 | int M = 10; |
时间复杂度计算:
1 | T(n) = (M-1)(N-1) = O(M*N) ≈ O(N^2) |
【示例】递归函数的时间复杂度是多少?思考一下斐波那契数列 f(n) = f(n-1) + f(n-2) 的时间复杂度是多少?
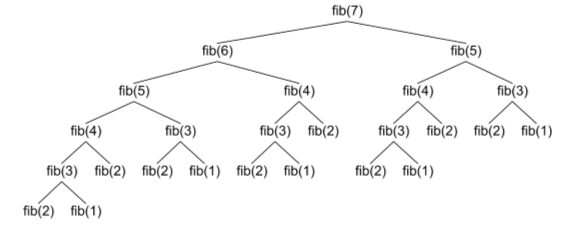
1 | T(n) = O(2^N) |
空间复杂度分析
时间复杂度的全称是渐进时间复杂度,表示算法的执行时间与数据规模之间的增长关系。
类比一下,空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
复杂度量级
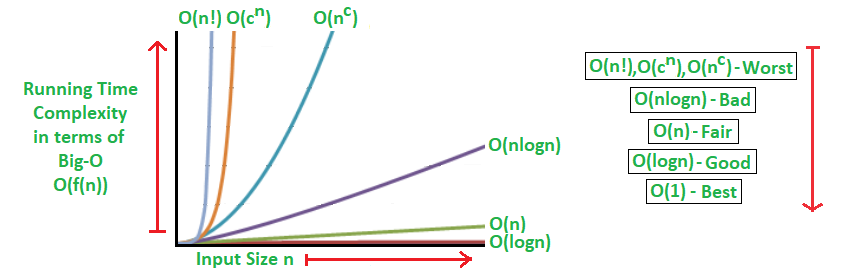
复杂度有以下量级:
- **
O(1)**:常数复杂度 - **
O(log n)**:对数复杂度 - **
O(n)**:线性复杂度 - **
O(nlog n)**:线性对数阶复杂度 - **
O(n^2)**:平方复杂度 - **
O(n^3)**:立方复杂度 - **
O(n^k)**:K 次方复杂度 - **
O(2^n)**:指数复杂度 - **
O(n!)**:阶乘复杂度
在数据量比较小的时候,复杂度量级差异并不明显;但是,随着数据规模大小的变化,差异会逐渐突出。
O(1) 复杂度示例:
1 | int num = 100; |
O(log n) 对数复杂度示例:
1 | int max = 100; |
O(n) 复杂度示例:
1 | int max = 100; |
O(n^2) 复杂度示例:
1 | int M = 10; |
O(k^n) 复杂度示例:
1 | int max = 10; |
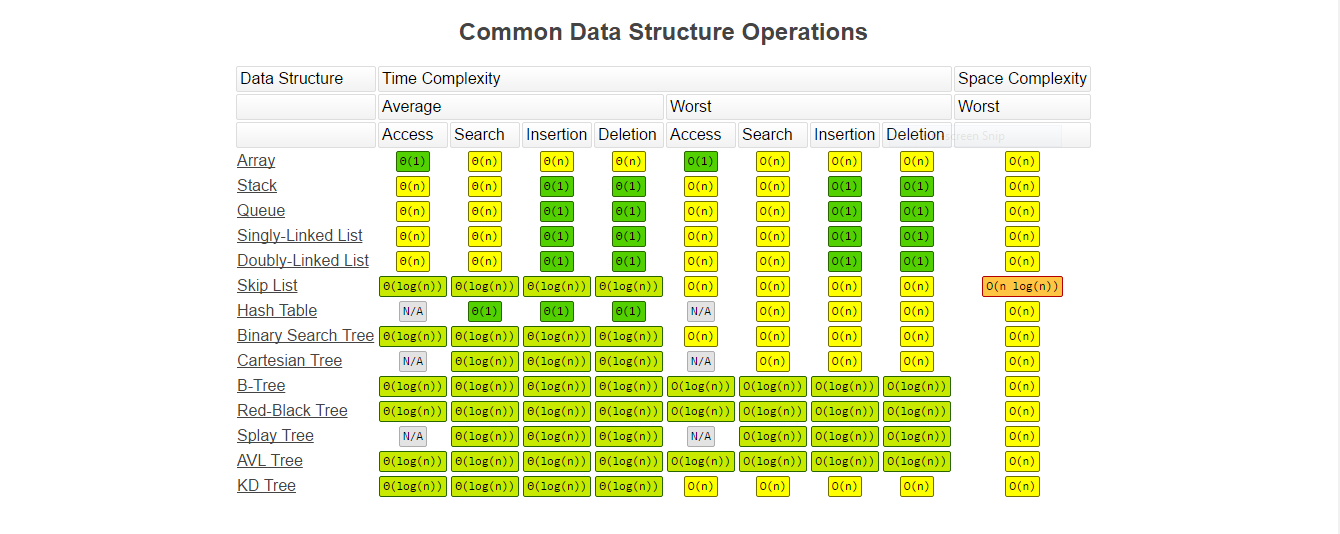
常见数据结构的复杂度
参考资料
Flink Table API & SQL
Flink Table API & SQL
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。Table API 是用于 Scala 和 Java 语言的查询 API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输入是连续的(流式)还是有界的(批处理),在两个接口中指定的查询都具有相同的语义,并指定相同的结果。
Table API 和 SQL 两种 API 是紧密集成的,以及 DataStream API。你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。比如,你可以先用 CEP 从 DataStream 中做模式匹配,然后用 Table API 来分析匹配的结果;或者你可以用 SQL 来扫描、过滤、聚合一个批式的表,然后再跑一个 Gelly 图算法 来处理已经预处理好的数据。
jar 依赖
必要依赖:
1 | <dependency> |
除此之外,如果你想在 IDE 本地运行你的程序,你需要添加下面的模块,具体用哪个取决于你使用哪个 Planner:
1 | <dependency> |
如果你想实现自定义格式或连接器 用于(反)序列化行或一组用户定义的函数,下面的依赖就足够了,编译出来的 jar 文件可以直接给 SQL Client 使用:
1 | <dependency> |
概念与通用 API
Table API 和 SQL 集成在同一套 API 中。 这套 API 的核心概念是Table,用作查询的输入和输出。
Table API 和 SQL 程序的结构
所有用于批处理和流处理的 Table API 和 SQL 程序都遵循相同的模式。
1 | import org.apache.flink.table.api.*; |
创建 TableEnvironment
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
- 在内部的 catalog 中注册
Table - 注册外部的 catalog
- 加载可插拔模块
- 执行 SQL 查询
- 注册自定义函数 (scalar、table 或 aggregation)
DataStream和Table之间的转换(面向StreamTableEnvironment)
在 Catalog 中创建表
TableEnvironment 维护着一个由标识符(identifier)创建的表 catalog 的映射。标识符由三个部分组成:catalog 名称、数据库名称以及对象名称。
Table 可以是虚拟的(视图 VIEWS)也可以是常规的(表 TABLES)。视图 VIEWS可以从已经存在的Table中创建,一般是 Table API 或者 SQL 的查询结果。 表TABLES描述的是外部数据,例如文件、数据库表或者消息队列。
查询表
Table API 示例
1 | // get a TableEnvironment |
SQL 示例
1 | // get a TableEnvironment |
输出表
Table 通过写入 TableSink 输出。TableSink 是一个通用接口,用于支持多种文件格式(如 CSV、Apache Parquet、Apache Avro)、存储系统(如 JDBC、Apache HBase、Apache Cassandra、Elasticsearch)或消息队列系统(如 Apache Kafka、RabbitMQ)。
批处理 Table 只能写入 BatchTableSink,而流处理 Table 需要指定写入 AppendStreamTableSink,RetractStreamTableSink 或者 UpsertStreamTableSink。
数据类型
通用类型与(嵌套的)复合类型 (如:POJO、tuples、rows、Scala case 类) 都可以作为行的字段。
复合类型的字段任意的嵌套可被 值访问函数 访问。
通用类型将会被视为一个黑箱,且可以被 用户自定义函数 传递或引用。
SQL
Flink 支持以下语句:
- SELECT (Queries)
- CREATE TABLE, DATABASE, VIEW, FUNCTION
- DROP TABLE, DATABASE, VIEW, FUNCTION
- ALTER TABLE, DATABASE, FUNCTION
- INSERT
- SQL HINTS
- DESCRIBE
- EXPLAIN
- USE
- SHOW
- LOAD
- UNLOAD
参考资料
LSM树
LSM 树
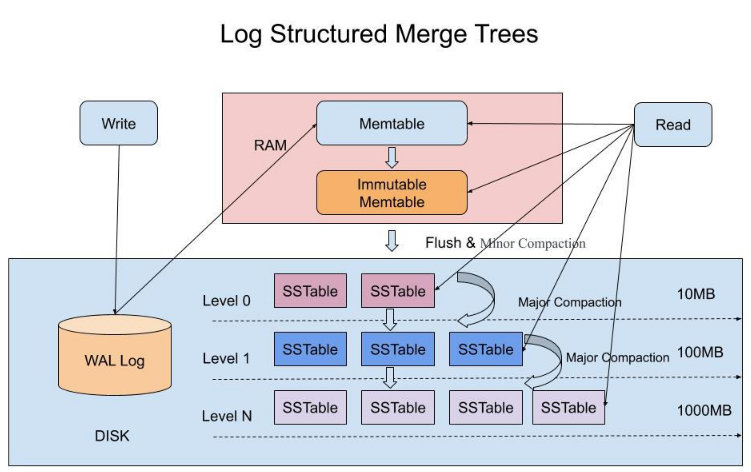
什么是 LSM 树
LSM 树具有以下 3 个特点:
- 将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并(Merge Trees);
- 用批量写入代替随机写入,并且用预写日志 WAL 技术(Write AheadLog,预写日志技术)保证内存数据,在系统崩溃后可以被恢复;
- 数据采取类似日志追加写的方式写入(Log Structured)磁盘,以顺序写的方式提高写
入效率。
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
LSM 树就是根据这个思路设计了这样一个机制:当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。因此,LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。
如何将内存数据与磁盘数据合并
可以参考两个有序链表归并排序的过程,将 C0 树和 C1 树的所有叶子节点中存储的数据,看作是两个有序链表,那滚动合并问题就变成了我们熟悉的两个有序链表的归并问题。不过由于涉及磁盘操作,那为了提高写入效率和检索效率,我们还需要针对磁盘的特性,在一些归并细节上进行优化。
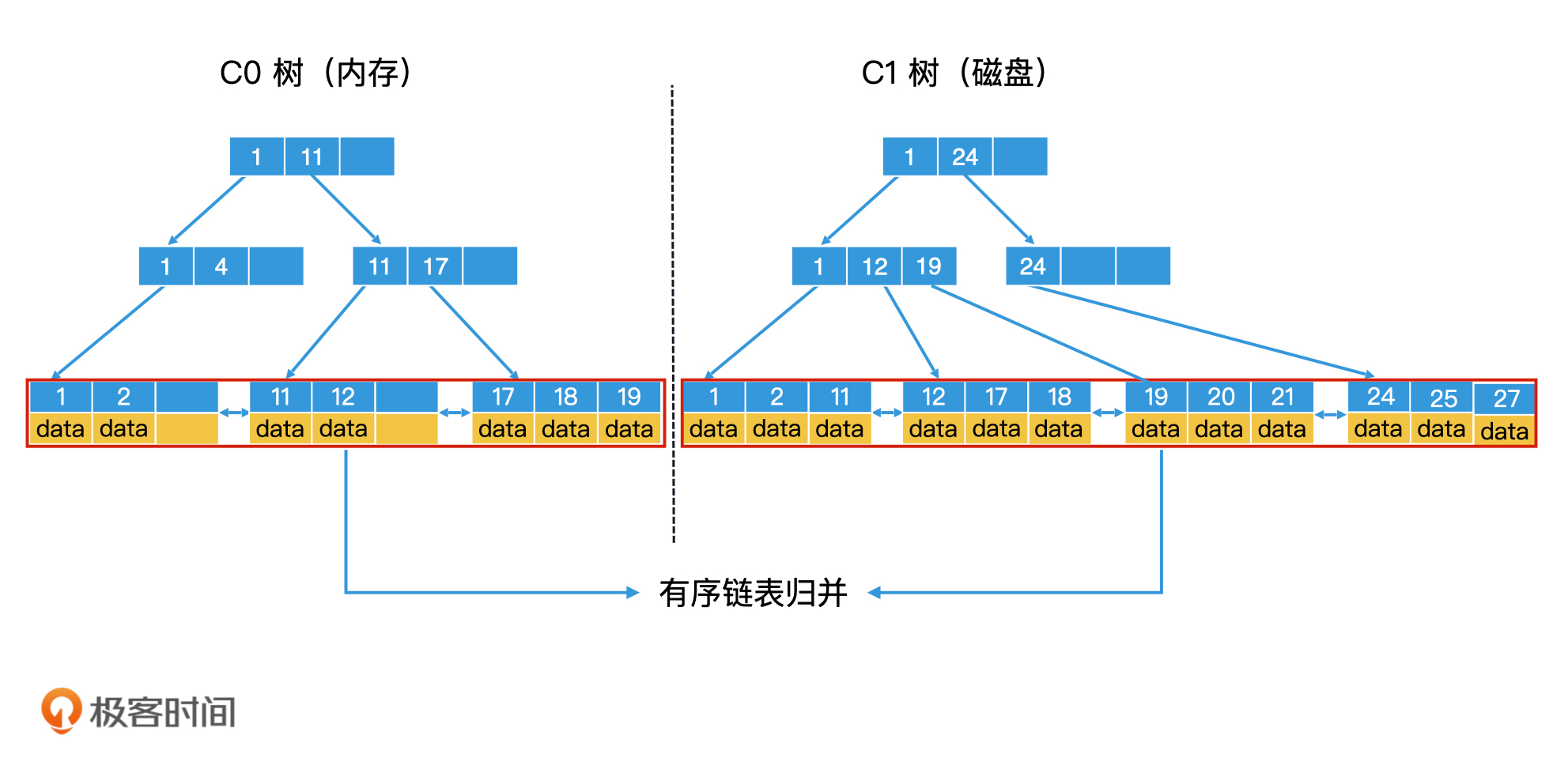
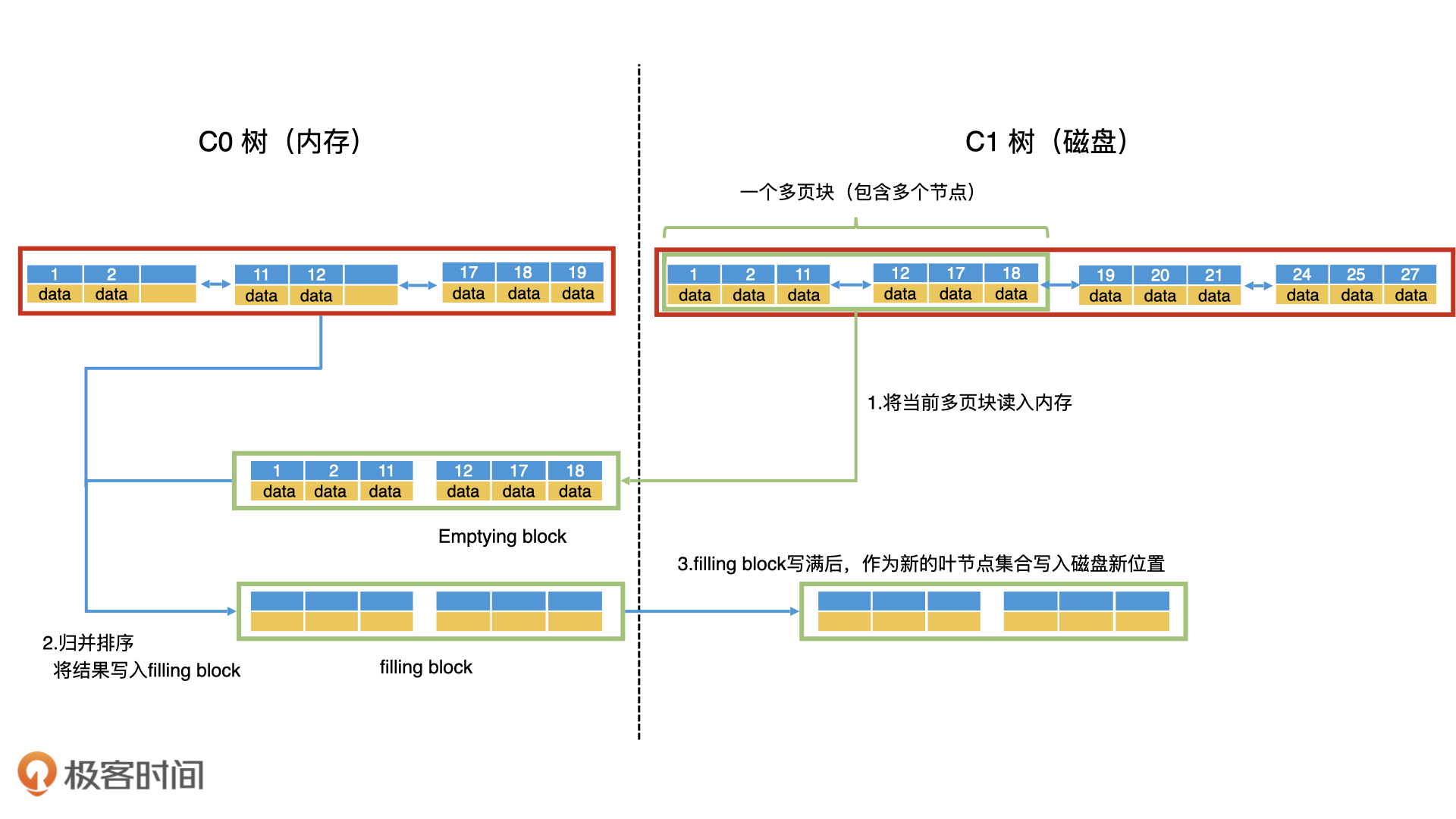
由于磁盘具有顺序读写效率高的特性,因此,为了提高 C1 树中节点的读写性能,除了根节点以外的节点都要尽可能地存放到连续的块中,让它们能作为一个整体单位来读写。这种包含多个节点的块就叫作多页块(Multi-Pages Block)。
第一步,以多页块为单位,将 C1 树的当前叶子节点从前往后读入内存。读入内存的多页块,叫作清空块(Emptying Block),意思是处理完以后会被清空。
第二步,将 C0 树的叶子节点和清空块中的数据进行归并排序,把归并的结果写入内存的一个新块中,叫作填充块(Filling Block)。
第三步,如果填充块写满了,我们就要将填充块作为新的叶节点集合顺序写入磁盘。这个时候,如果 C0 树的叶子节点和清空块都没有遍历完,我们就继续遍历归并,将数据写入新的填充块。如果清空块遍历完了,我们就去 C1 树中顺序读取新的多页块,加载到清空块中。
第四步,重复第三步,直到遍历完 C0 树和 C1 树的所有叶子节点,并将所有的归并结果写入到磁盘。这个时候,我们就可以同时删除 C0 树和 C1 树中被处理过的叶子节点。这样就完成了滚动归并的过程。
LSM 树是如何检索
因为同时存在 C0 和 C1 树,所以要查询一个 key 时,我们会先到 C0 树中查询。如果查询到了则直接返回;如过没有查询到,则查询 C1 树。
需要注意一种特殊情况:删除操作。假设某数据在 C0 树中被删除了,但是在 C1 树中仍存在。这此时查询时,可以在 C1 树中查到这个 key,这其实是过期数据了,如何应对这种情况呢?对于被删除的数据,可以将这些数据的 key 插入到 C0 树中,并标记一个删除标志。如果查到了一个带着删除标志的 key,就直接返回查询失败。
为什么需要 LSM 树
在关系型数据库中,通常使用 B+ 树作为索引。B+ 树的数据都存储在叶子节点中,而叶子节点一般都存储在磁盘中。因此,每次插入的新数据都需要随机写入磁盘,而随机写入的性能非常慢。如果是一个日志系统,每秒钟要写入上千条甚至上万条数据,这样的磁盘操作代价会使得系统性能急剧下降,甚至无法使用。
操作系统对磁盘的读写是以块为单位的,我们能否以块为单位写入,而不是每次插入一个数据都要随机写入磁盘呢?这样是不是就可以大幅度减少写入操作了呢?解决方案就是:LSM 树(Log Structured Merge Trees)。
WAL 技术
LSM 树至少需要由两棵树组成,一棵是存储在内存中较小的 C0 树,另一棵是存储在磁盘中较大的 C1 树。
如果机器断电或系统崩溃了,那内存中还未写入磁盘的数据岂不就永远丢失了?这种情况我们该如何解决呢?
为了保证内存中的数据在系统崩溃后能恢复,可以使用 WAL 技术(Write Ahead Log,预写日志技术)将数据第一时间高效写入磁盘进行备份。
WAL 技术保存和恢复数据的具体步骤如下:
- 内存中的程序在处理数据时,会先将对数据的修改作为一条记录,顺序写入磁盘的 log 文件作为备份。由于磁盘文件的顺序追加写入效率很高,因此许多应用场景都可以接受这种备份处理。
- 在数据写入 log 文件后,备份就成功了。接下来,该数据就可以长期驻留在内存中了。
- 系统会周期性地检查内存中的数据是否都被处理完了(比如,被删除或者写入磁盘),并且生成对应的检查点(Check Point)记录在磁盘中。然后,我们就可以随时删除被处理完的数据了。这样一来,log 文件就不会无限增长了。
- 系统崩溃重启,我们只需要从磁盘中读取检查点,就能知道最后一次成功处理的数据在 log 文件中的位置。接下来,我们就可以把这个位置之后未被处理的数据,从 log 文件中读出,然后重新加载到内存中。
参考资料
B+树
B+树
什么是 B+树
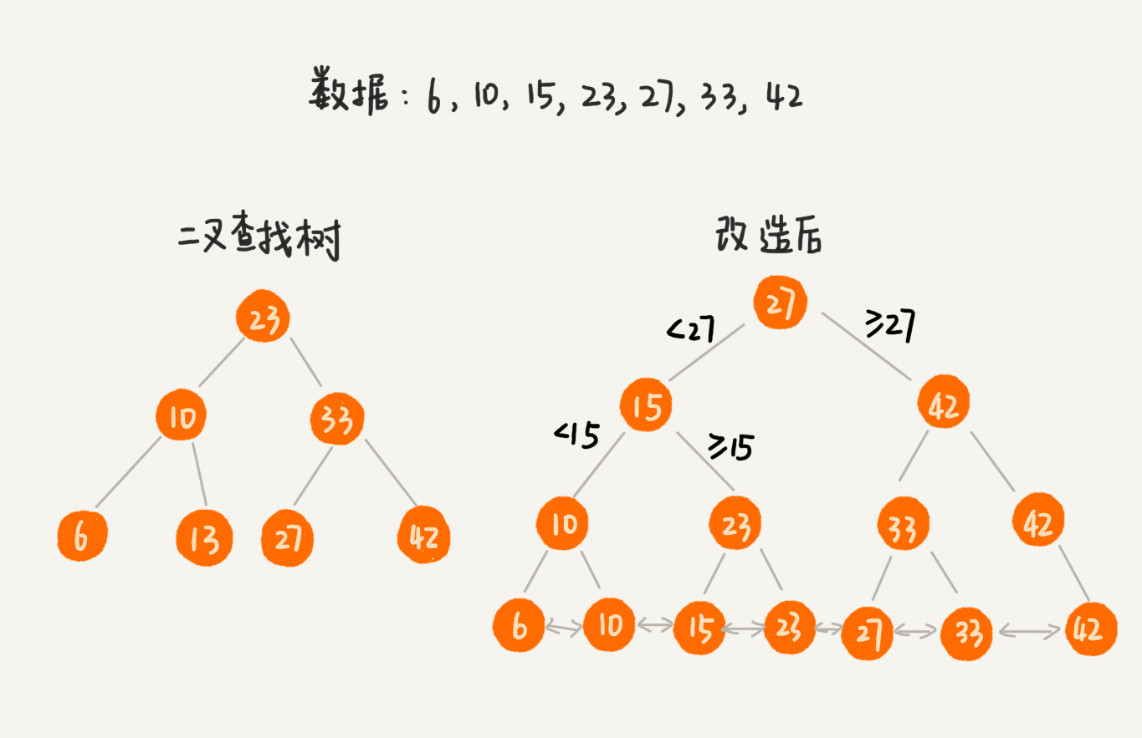
B+树是在二叉查找树的基础上进行了改造:树中的节点并不存储数据本身,而是只是作为索引。每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。
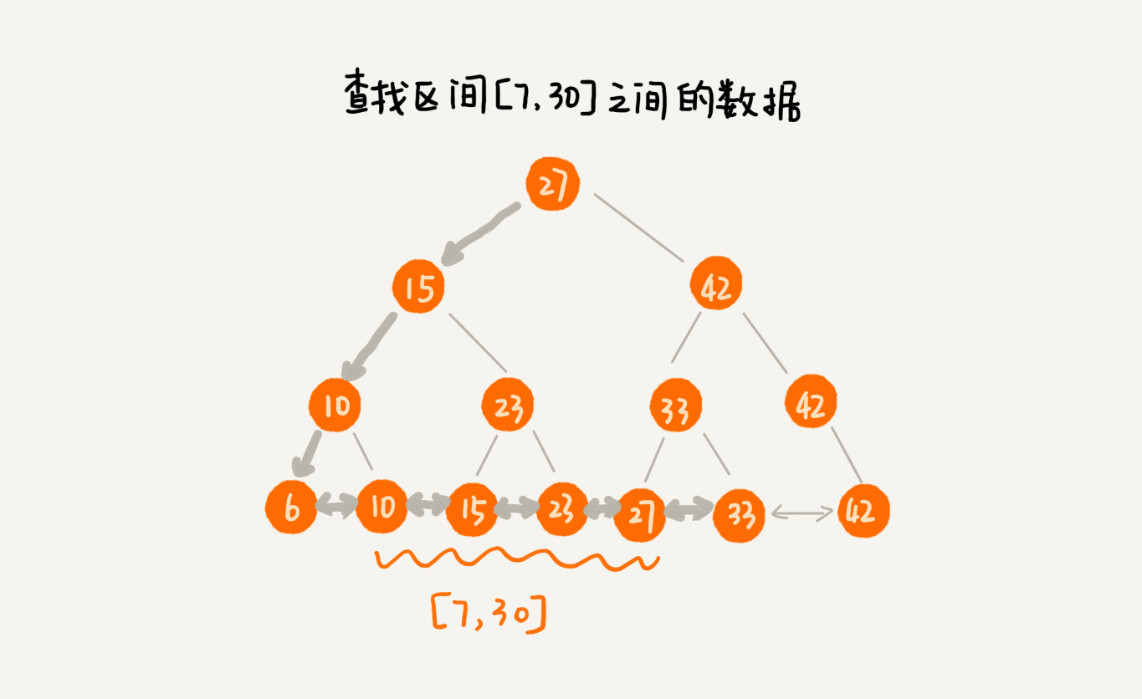
改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
但是,我们要为几千万、上亿的数据构建索引,如果将索引存储在内存中,尽管内存访问的速度非常快,查询的效率非常高,但是,占用的内存会非常多。
比如,我们给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,那就需要大约 1GB 的内存空间。给一张表建立索引,我们需要 1GB 的内存空间。如果我们要给 10 张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题呢?
我们可以借助时间换空间的思路,把索引存储在硬盘中,而非内存中。我们都知道,硬盘是一个非常慢速的存储设备。通常内存的访问速度是纳秒级别的,而磁盘访问的速度是毫秒级别的。读取同样大小的数据,从磁盘中读取花费的时间,是从内存中读取所花费时间的上万倍,甚至几十万倍。
这种将索引存储在硬盘中的方案,尽管减少了内存消耗,但是在数据查找的过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
二叉查找树,经过改造之后,支持区间查找的功能就实现了。不过,为了节省内存,如果把树存储在硬盘中,那么每个节点的读取(或者访问),都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。
我们前面讲到,比起内存读写操作,磁盘 IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作,也就是,尽量降低树的高度。那如何降低树的高度呢?
我们来看下,如果我们把索引构建成 m 叉树,高度是不是比二叉树要小呢?如图所示,给 16 个数据构建二叉树索引,树的高度是 4,查找一个数据,就需要 4 个磁盘 IO 操作(如果根节点存储在内存中,其他结点存储在磁盘中),如果对 16 个数据构建五叉树索引,那高度只有 2,查找一个数据,对应只需要 2 次磁盘操作。如果 m 叉树中的 m 是 100,那对一亿个数据构建索引,树的高度也只是 3,最多只要 3 次磁盘 IO 就能获取到数据。磁盘 IO 变少了,查找数据的效率也就提高了。
为什么需要 B+树
关系型数据库中常用 B+ 树作为索引,这是为什么呢?
思考以下经典应用场景
- 根据某个值查找数据,比如
select * from user where id=1234。 - 根据区间值来查找某些数据,比如
select * from user where id > 1234 and id < 2345。
为了提高查询效率,需要使用索引。而对于索引的性能要求,主要考察执行效率和存储空间。如果让你选择一种数据结构去存储索引,你会如何考虑?
以一些常见数据结构为例:
- 哈希表:哈希表的查询性能很好,时间复杂度是
O(1)。但是,哈希表不能支持按照区间快速查找数据。所以,哈希表不能满足我们的需求。 - 平衡二叉查找树:尽管平衡二叉查找树查询的性能也很高,时间复杂度是
O(logn)。而且,对树进行中序遍历,我们还可以得到一个从小到大有序的数据序列,但这仍然不足以支持按照区间快速查找数据。 - 跳表:跳表是在链表之上加上多层索引构成的。它支持快速地插入、查找、删除数据,对应的时间复杂度是
O(logn)。并且,跳表也支持按照区间快速地查找数据。我们只需要定位到区间起点值对应在链表中的结点,然后从这个结点开始,顺序遍历链表,直到区间终点对应的结点为止,这期间遍历得到的数据就是满足区间值的数据。
实际上,数据库索引所用到的数据结构跟跳表非常相似,叫作 B+ 树。不过,它是通过二叉查找树演化过来的,而非跳表。B+树的应用场景
参考资料
字典树
字典树
什么是字典树
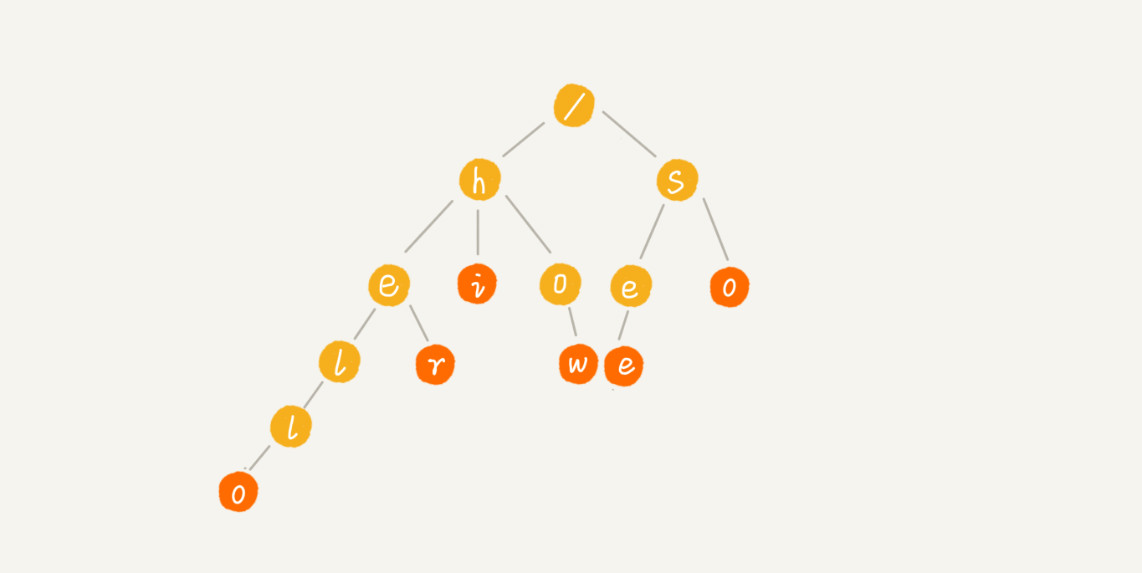
Trie 树(又叫“前缀树”或“字典树”)是一种用于快速查询“某个字符串/字符前缀”是否存在的数据结构。
- 根节点(Root)不包含字符,除根节点外的每一个节点都仅包含一个字符;
- 从根节点到某一节点路径上所经过的字符连接起来,即为该节点对应的字符串;
- 任意节点的所有子节点所包含的字符都不相同;
字典树的构造
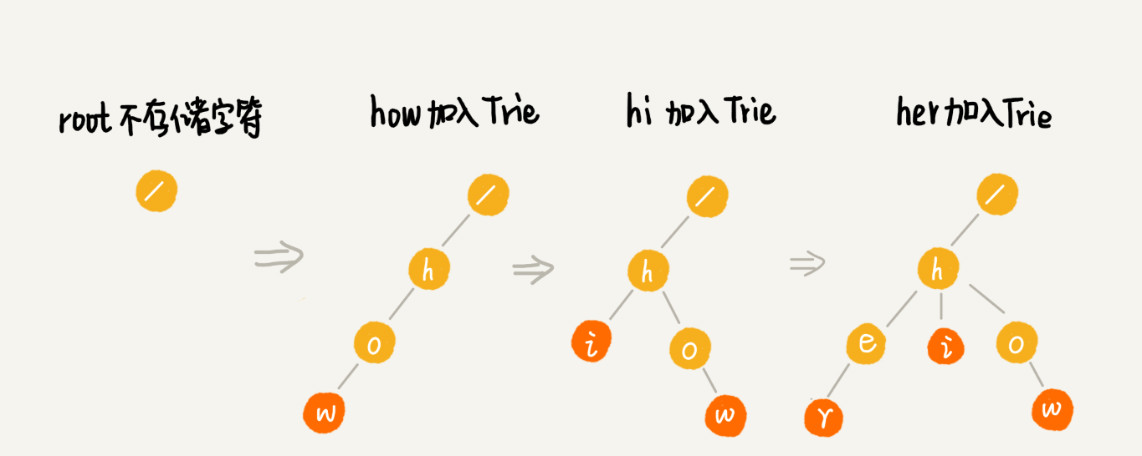
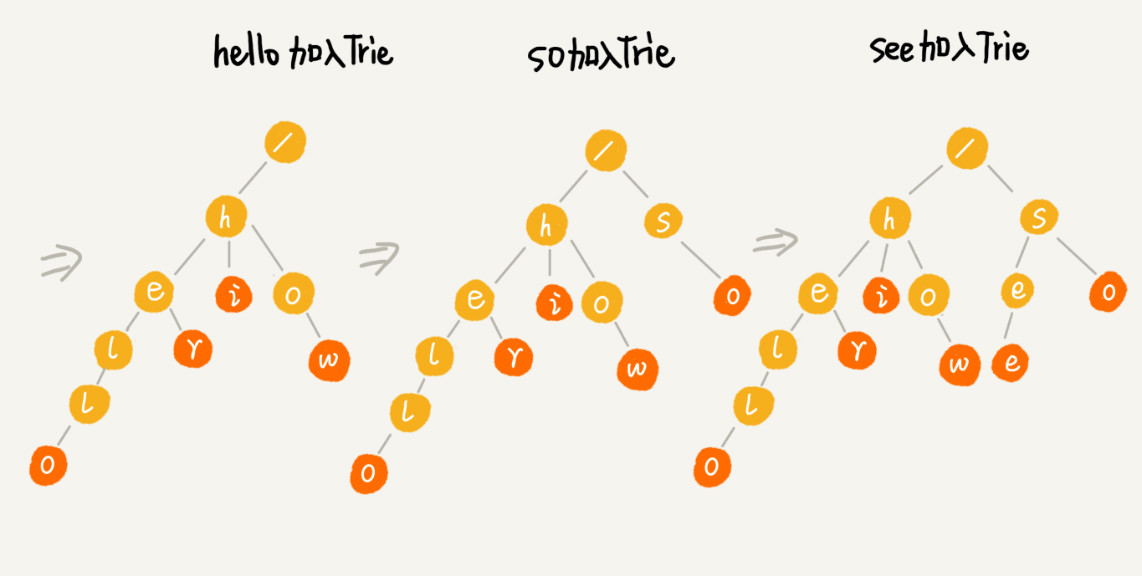
构建 Trie 树的过程,需要扫描所有的字符串,时间复杂度是 O(n)(n 表示所有字符串的长度和)。
字典树非常耗费内存。
用数组来存储一个节点的子节点的指针。如果字符串中包含从 a 到 z 这 26 个字符,那每个节点都要存储一个长度为 26 的数组,并且每个数组存储一个 8 字节指针(或者是 4 字节,这个大小跟 CPU、操作系统、编译器等有关)。而且,即便一个节点只有很少的子节点,远小于 26 个,比如 3、4 个,我们也要维护一个长度为 26 的数组。
用数组来存储一个节点的子节点的指针。如果字符串中包含从 a 到 z 这 26 个字符,那每个节点都要存储一个长度为 26 的数组,并且每个数组存储一个 8 字节指针(或者是 4 字节,这个大小跟 CPU、操作系统、编译器等有关)。而且,即便一个节点只有很少的子节点,远小于 26 个,比如 3、4 个,我们也要维护一个长度为 26 的数组。
用数组来存储一个节点的子节点的指针。如果字符串中包含从 a 到 z 这 26 个字符,那每个节点都要存储一个长度为 26 的数组,并且每个数组存储一个 8 字节指针(或者是 4 字节,这个大小跟 CPU、操作系统、编译器等有关)。而且,即便一个节点只有很少的子节点,远小于 26 个,比如 3、4 个,我们也要维护一个长度为 26 的数组。
字典树的查找
- 每次从根结点开始搜索;
- 获取关键词的第一个字符,根据该字符选择对应的子节点,转到该子节点继续检索;
- 在相应的子节点上,获取关键词的第二个字符,进一步选择对应的子节点进行检索;
- 以此类推,进行迭代过程;
- 在某个节点处,关键词的所有字母已被取出,则读取附在该节点上的信息,查找完成。
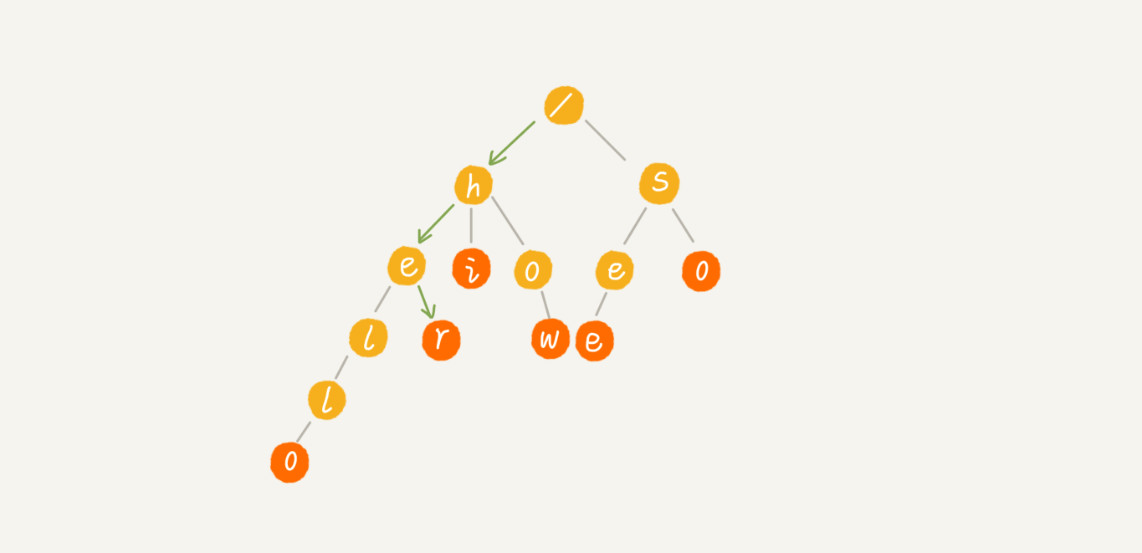
每次查询时,如果要查询的字符串长度是 k,那我们只需要比对大约 k 个节点,就能完成查询操作。跟原本那组字符串的长度和个数没有任何关系。所以说,构建好 Trie 树后,在其中查找字符串的时间复杂度是 O(k),k 表示要查找的字符串的长度。
字典树的应用场景
在一组字符串中查找字符串,Trie 树实际上表现得并不好。它对要处理的字符串有及其严苛的要求。
第一,字符串中包含的字符集不能太大。我们前面讲到,如果字符集太大,那存储空间可能就会浪费很多。即便可以优化,但也要付出牺牲查询、插入效率的代价。
第二,要求字符串的前缀重合比较多,不然空间消耗会变大很多。
第三,如果要用 Trie 树解决问题,那我们就要自己从零开始实现一个 Trie 树,还要保证没有 bug,这个在工程上是将简单问题复杂化,除非必须,一般不建议这样做。
第四,我们知道,通过指针串起来的数据块是不连续的,而 Trie 树中用到了指针,所以,对缓存并不友好,性能上会打个折扣。
在一组字符串中查找字符串,Trie 树实际上表现得并不好。它对要处理的字符串有及其严苛的要求。
在一组字符串中查找字符串,Trie 树实际上表现得并不好。它对要处理的字符串有及其严苛的要求。
(1)自动补全

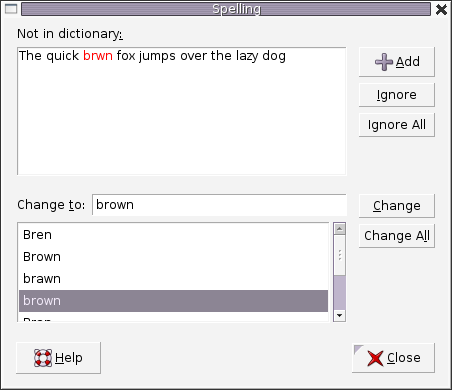
(2)拼写检查
(3)IP 路由 (最长前缀匹配)
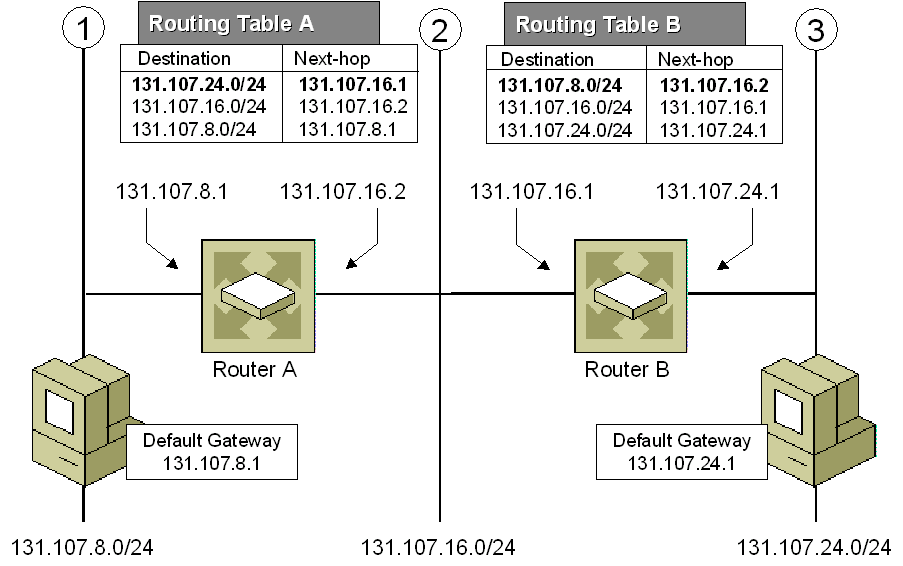
图 3. 使用 Trie 树的最长前缀匹配算法,Internet 协议(IP)路由中利用转发表选择路径。
(4)T9 (九宫格) 打字预测
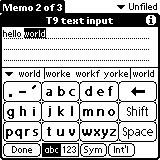
(5)单词游戏

Trie 树可通过剪枝搜索空间来高效解决 Boggle 单词游戏