Memcached 简洁而强大。它的简洁设计便于快速开发,减轻开发难度,解决了大数据量缓存的很多问题。它的 API 兼容大部分流行的开发语言。本质上,它是一个简洁的 key-value 存储系统。
Memcached 特性
memcached 作为高速运行的分布式缓存服务器,具有以下的特点。
协议简单
基于 libevent 的事件处理
内置内存存储方式
memcached 不互相通信的分布式
Memcached 命令
可以通过 telnet 命令并指定主机 ip 和端口来连接 Memcached 服务。
1 2 3 4 5 6 7 8 9 10 11 12 13
telnet 127.0.0.111211
Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. set foo 0 0 3 保存命令 bar 数据 STORED 结果 get foo 取得命令 VALUE foo 0 3 数据 bar 数据 END 结束行 quit 退出
Java 连接 Memcached
使用 Java 程序连接 Memcached,需要在你的 classpath 中添加 Memcached jar 包。
<!-- Add an EnvEntry only valid for this webapp --> <Newid="gargle"class="org.eclipse.jetty.plus.jndi.EnvEntry"> <Arg>gargle</Arg> <Argtype="java.lang.Double">100</Arg> <Argtype="boolean">true</Arg> </New>
<!-- Add an override for a global EnvEntry --> <Newid="wiggle"class="org.eclipse.jetty.plus.jndi.EnvEntry"> <Arg>wiggle</Arg> <Argtype="java.lang.Double">55.0</Arg> <Argtype="boolean">true</Arg> </New>
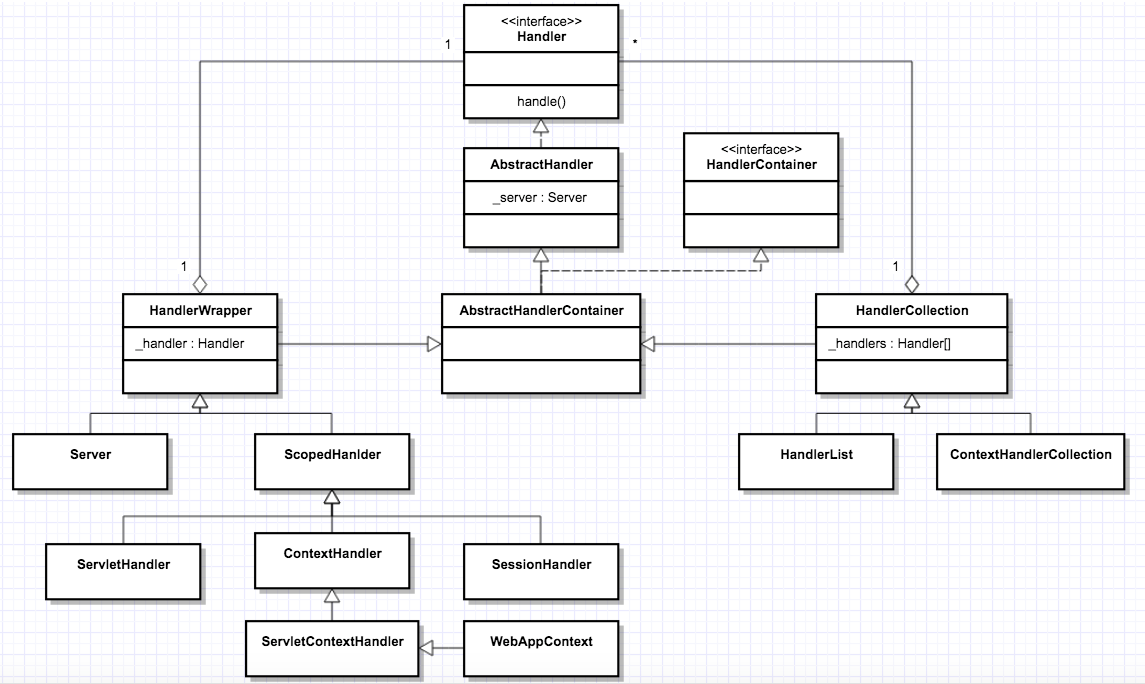
HandlerCollection 其实维护了一个 Handler 数组。这是为了同时支持多个 Web 应用,如果每个 Web 应用有一个 Handler 入口,那么多个 Web 应用的 Handler 就成了一个数组,比如 Server 中就有一个 HandlerCollection,Server 会根据用户请求的 URL 从数组中选取相应的 Handler 来处理,就是选择特定的 Web 应用来处理请求。
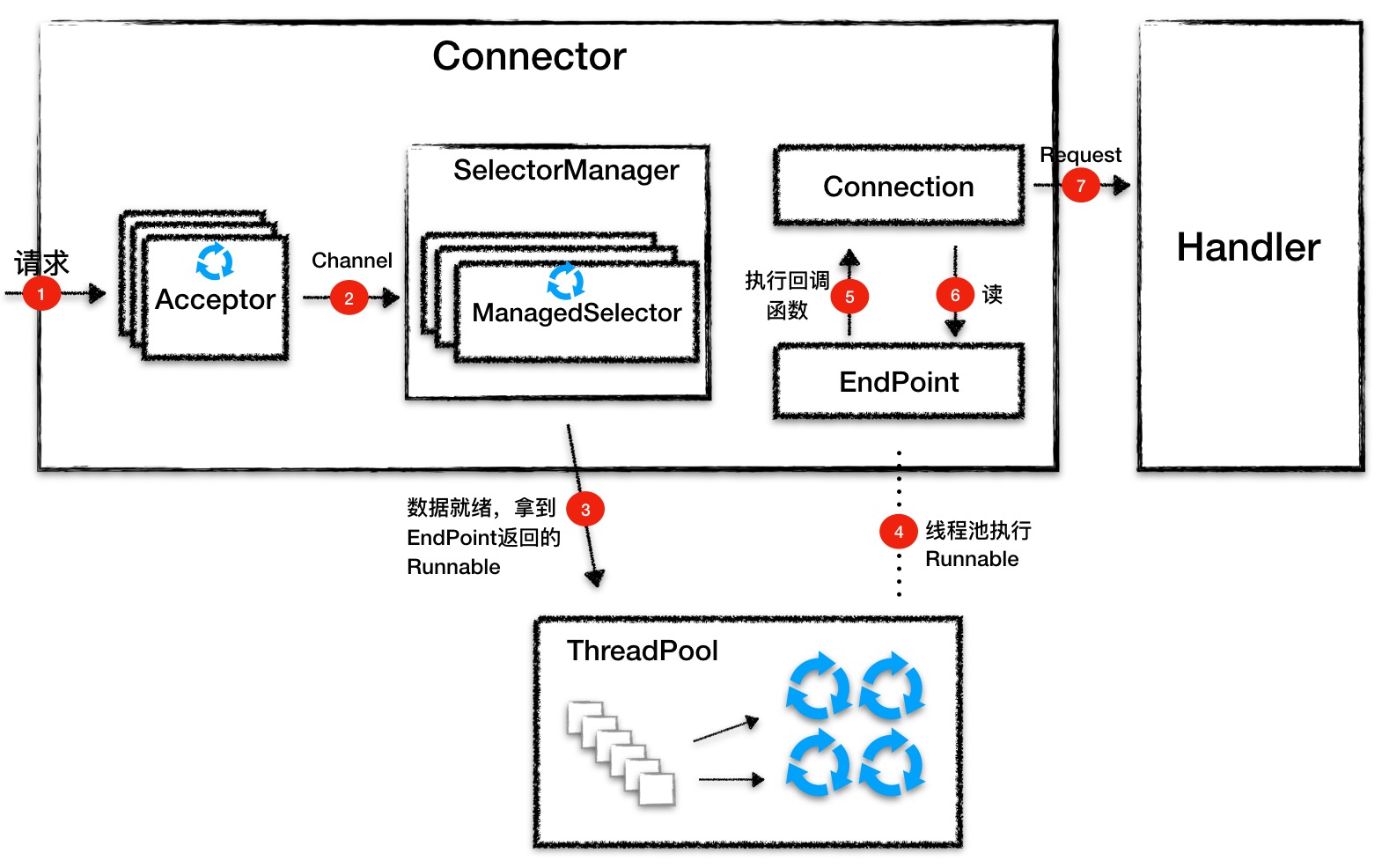
将 I/O 事件检测和业务处理这两种工作分开的思路也有缺点:当 Selector 检测读就绪事件时,数据已经被拷贝到内核中的缓存了,同时 CPU 的缓存中也有这些数据了,我们知道 CPU 本身的缓存比内存快多了,这时当应用程序去读取这些数据时,如果用另一个线程去读,很有可能这个读线程使用另一个 CPU 核,而不是之前那个检测数据就绪的 CPU 核,这样 CPU 缓存中的数据就用不上了,并且线程切换也需要开销。
因此 Jetty 的 Connector 做了一个大胆尝试,那就是把 I/O 事件的生产和消费放到同一个线程来处理,如果这两个任务由同一个线程来执行,如果执行过程中线程不阻塞,操作系统会用同一个 CPU 核来执行这两个任务,这样就能利用 CPU 缓存了。
ProduceExecuteConsume:任务生产者开启新线程来运行任务,这是典型的 I/O 事件侦测和处理用不同的线程来处理,缺点是不能利用 CPU 缓存,并且线程切换成本高。同样我们通过一张图来理解,图中的棕色表示线程切换。
ExecuteProduceConsume:任务生产者自己运行任务,但是该策略可能会新建一个新线程以继续生产和执行任务。这种策略也被称为“吃掉你杀的猎物”,它来自狩猎伦理,认为一个人不应该杀死他不吃掉的东西,对应线程来说,不应该生成自己不打算运行的任务。它的优点是能利用 CPU 缓存,但是潜在的问题是如果处理 I/O 事件的业务代码执行时间过长,会导致线程大量阻塞和线程饥饿。
// without annotation, we'd get "theName", but we want "name": @JsonProperty("name") public String getTheName() { return _name; }
// note: it is enough to add annotation on just getter OR setter; // so we can omit it here publicvoidsetTheName(String n) { _name = n; } }
@JsonIgnoreProperties 和 @JsonIgnore
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// means that if we see "foo" or "bar" in JSON, they will be quietly skipped // regardless of whether POJO has such properties @JsonIgnoreProperties({ "foo", "bar" }) publicclassMyBean { // will not be written as JSON; nor assigned from JSON: @JsonIgnore public String internal;
// no annotation, public field is read/written normally public String external;
@JsonIgnore publicvoidsetCode(int c) { _code = c; }
// note: will also be ignored because setter has annotation! publicintgetCode() { return _code; } }
//不强制要求注册类(注册行为无法保证多个 JVM 内同一个类的注册编号相同;而且业务系统中大量的 Class 也难以一一注册) kryo.setRegistrationRequired(false); //默认值就是 false,添加此行的目的是为了提醒维护者,不要改变这个配置
//Fix the NPE bug when deserializing Collections. ((DefaultInstantiatorStrategy) kryo.getInstantiatorStrategy()) .setFallbackInstantiatorStrategy(newStdInstantiatorStrategy());
@java.lang.Override publicbooleanequals(final java.lang.Object o) { if (o == this) returntrue; if (o == null) returnfalse; if (o.getClass() != this.getClass()) returnfalse; if (!super.equals(o)) returnfalse; finalPersonother= (Person)o; if (this.name == null ? other.name != null : !this.name.equals(other.name)) returnfalse; if (this.gender == null ? other.gender != null : !this.gender.equals(other.gender)) returnfalse; if (this.ssn == null ? other.ssn != null : !this.ssn.equals(other.ssn)) returnfalse; returntrue; }
@java.lang.Override publicinthashCode() { finalintPRIME=31; intresult=1; result = result * PRIME + super.hashCode(); result = result * PRIME + (this.name == null ? 0 : this.name.hashCode()); result = result * PRIME + (this.gender == null ? 0 : this.gender.hashCode()); result = result * PRIME + (this.ssn == null ? 0 : this.ssn.hashCode()); return result; } }
Exception in thread "main" com.fasterxml.jackson.databind.exc.MismatchedInputException: Cannot construct instance of `io.github.dunwu.javatech.bean.lombok.BuilderDemo01` (although at least one Creator exists): cannot deserialize from Object value (no delegate- or property-based Creator) at [Source: (String)"{"name":"demo01"}"; line: 1, column: 2] at com.fasterxml.jackson.databind.exc.MismatchedInputException.from(MismatchedInputException.java:63) at com.fasterxml.jackson.databind.DeserializationContext.reportInputMismatch(DeserializationContext.java:1432) at com.fasterxml.jackson.databind.DeserializationContext.handleMissingInstantiator(DeserializationContext.java:1062) at com.fasterxml.jackson.databind.deser.BeanDeserializerBase.deserializeFromObjectUsingNonDefault(BeanDeserializerBase.java:1297) at com.fasterxml.jackson.databind.deser.BeanDeserializer.deserializeFromObject(BeanDeserializer.java:326) at com.fasterxml.jackson.databind.deser.BeanDeserializer.deserialize(BeanDeserializer.java:159) at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:4218) at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3214) at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3182) at io.github.dunwu.javatech.bean.lombok.BuilderDemo01.main(BuilderDemo01.java:22)
String to Complex Type if the Complex Type contains a String constructor
字符串和有字符串构造器的复杂类型(类)
String to Map
字符串和 Map
Collection to Collection
集合和集合
Collection to Array
集合和数组
Map to Complex Type
Map 和复杂类型
Map to Custom Map Type
Map 和定制 Map 类型
Enum to Enum
枚举和枚举
Each of these can be mapped to one another: java.util.Date, java.sql.Date, java.sql.Time, java.sql.Timestamp, java.util.Calendar, java.util.GregorianCalendar
<!-- You are responsible for mapping everything between ClassA and ClassB --> <converter type="org.dozer.converters.TestCustomHashMapConverter" > <class-a>org.dozer.vo.TestCustomConverterHashMapObject</class-a> <class-b>org.dozer.vo.TestCustomConverterHashMapPrimeObject</class-b> </converter> </custom-converters> </configuration> </mappings>
Denotes that a method is a test method. Unlike JUnit 4’s @Test annotation, this annotation does not declare any attributes, since test extensions in JUnit Jupiter operate based on their own dedicated annotations. Such methods are inherited unless they are overridden.
@ParameterizedTest
Denotes that a method is a parameterized test. Such methods are inherited unless they are overridden.
@RepeatedTest
Denotes that a method is a test template for a repeated test. Such methods are inherited unless they are overridden.
@TestFactory
Denotes that a method is a test factory for dynamic tests. Such methods are inherited unless they are overridden.
@TestInstance
Used to configure the test instance lifecycle for the annotated test class. Such annotations are inherited.
@TestTemplate
Denotes that a method is a template for test cases designed to be invoked multiple times depending on the number of invocation contexts returned by the registered providers. Such methods are inherited unless they are overridden.
@DisplayName
Declares a custom display name for the test class or test method. Such annotations are not inherited.
@BeforeEach
Denotes that the annotated method should be executed beforeeach@Test, @RepeatedTest, @ParameterizedTest, or @TestFactory method in the current class; analogous to JUnit 4’s @Before. Such methods are inherited unless they are overridden.
@AfterEach
Denotes that the annotated method should be executed aftereach@Test, @RepeatedTest, @ParameterizedTest, or @TestFactory method in the current class; analogous to JUnit 4’s @After. Such methods are inherited unless they are overridden.
@BeforeAll
Denotes that the annotated method should be executed beforeall@Test, @RepeatedTest, @ParameterizedTest, and @TestFactory methods in the current class; analogous to JUnit 4’s @BeforeClass. Such methods are inherited (unless they are hidden or overridden) and must be static (unless the “per-class” test instance lifecycle is used).
@AfterAll
Denotes that the annotated method should be executed afterall@Test, @RepeatedTest, @ParameterizedTest, and @TestFactory methods in the current class; analogous to JUnit 4’s @AfterClass. Such methods are inherited (unless they are hidden or overridden) and must be static (unless the “per-class” test instance lifecycle is used).
@Nested
Denotes that the annotated class is a nested, non-static test class. @BeforeAll and @AfterAllmethods cannot be used directly in a @Nested test class unless the “per-class” test instance lifecycle is used. Such annotations are not inherited.
@Tag
Used to declare tags for filtering tests, either at the class or method level; analogous to test groups in TestNG or Categories in JUnit 4. Such annotations are inherited at the class level but not at the method level.
@Disabled
Used to disable a test class or test method; analogous to JUnit 4’s @Ignore. Such annotations are not inherited.
@ExtendWith
Used to register custom extensions. Such annotations are inherited.
@BeforeAll publicstaticvoidbeforeAll() { person = newPerson("John", "Doe"); }
@Test voidstandardAssertions() { assertEquals(2, 2); assertEquals(4, 4, "The optional assertion message is now the last parameter."); assertTrue('a' < 'b', () -> "Assertion messages can be lazily evaluated -- " + "to avoid constructing complex messages unnecessarily."); }
@Test voidgroupedAssertions() { // In a grouped assertion all assertions are executed, and any // failures will be reported together. assertAll("person", () -> assertEquals("John", person.getFirstName()), () -> assertEquals("Doe", person.getLastName())); }
@Test voiddependentAssertions() { // Within a code block, if an assertion fails the // subsequent code in the same block will be skipped. assertAll("properties", () -> { StringfirstName= person.getFirstName(); assertNotNull(firstName);
// Executed only if the previous assertion is valid. assertAll("first name", () -> assertTrue(firstName.startsWith("J")), () -> assertTrue(firstName.endsWith("n"))); }, () -> { // Grouped assertion, so processed independently // of results of first name assertions. StringlastName= person.getLastName(); assertNotNull(lastName);
// Executed only if the previous assertion is valid. assertAll("last name", () -> assertTrue(lastName.startsWith("D")), () -> assertTrue(lastName.endsWith("e"))); }); }
@Test voidtimeoutNotExceeded() { // The following assertion succeeds. assertTimeout(ofMinutes(2), () -> { // Perform task that takes less than 2 minutes. }); }
@Test voidtimeoutNotExceededWithResult() { // The following assertion succeeds, and returns the supplied object. StringactualResult= assertTimeout(ofMinutes(2), () -> { return"a result"; }); assertEquals("a result", actualResult); }
@Test voidtimeoutNotExceededWithMethod() { // The following assertion invokes a method reference and returns an object. StringactualGreeting= assertTimeout(ofMinutes(2), AssertionsDemo::greeting); assertEquals("Hello, World!", actualGreeting); }
@Test voidtimeoutExceeded() { // The following assertion fails with an error message similar to: // execution exceeded timeout of 10 ms by 91 ms assertTimeout(ofMillis(10), () -> { // Simulate task that takes more than 10 ms. Thread.sleep(100); }); }
@Test voidtimeoutExceededWithPreemptiveTermination() { // The following assertion fails with an error message similar to: // execution timed out after 10 ms assertTimeoutPreemptively(ofMillis(10), () -> { // Simulate task that takes more than 10 ms. Thread.sleep(100); }); }
@Test voidtestOnlyOnCiServer() { assumeTrue("CI".equals(System.getenv("ENV"))); // remainder of test }
@Test voidtestOnlyOnDeveloperWorkstation() { assumeTrue("DEV".equals(System.getenv("ENV")), () -> "Aborting test: not on developer workstation"); // remainder of test }
@Test voidtestInAllEnvironments() { assumingThat("CI".equals(System.getenv("ENV")), () -> { // perform these assertions only on the CI server assertEquals(2, 2); });
// perform these assertions in all environments assertEquals("a string", "a string"); }
@Test @DisplayName("it is no longer empty") voidisNotEmpty() { assertFalse(stack.isEmpty()); }
@Test @DisplayName("returns the element when popped and is empty") voidreturnElementWhenPopped() { assertEquals(anElement, stack.pop()); assertTrue(stack.isEmpty()); }
@Test @DisplayName("returns the element when peeked but remains not empty") voidreturnElementWhenPeeked() { assertEquals(anElement, stack.peek()); assertFalse(stack.isEmpty()); } } } }
@RepeatedTest(value = 1, name = RepeatedTest.LONG_DISPLAY_NAME) @DisplayName("Details...") voidcustomDisplayNameWithLongPattern(TestInfo testInfo) { assertEquals(testInfo.getDisplayName(), "Details... :: repetition 1 of 1"); }
@RepeatedTest(value = 5, name = "Wiederholung {currentRepetition} von {totalRepetitions}") voidrepeatedTestInGerman() { // ... }
}
参数化测试
1 2 3 4 5
@ParameterizedTest @ValueSource(strings = { "racecar", "radar", "able was I ere I saw elba" }) voidpalindromes(String candidate) { assertTrue(isPalindrome(candidate)); }