MyBatis 原理
MyBatis 的前身就是 iBatis ,是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。本文以一个 MyBatis 完整示例为切入点,结合 MyBatis 底层源码分析,图文并茂的讲解 MyBatis 的核心工作机制。
MyBatis 完整示例
这里,我将以一个入门级的示例来演示 MyBatis 是如何工作的。
注:本文后面章节中的原理、源码部分也将基于这个示例来进行讲解。
完整示例源码地址
数据库准备 在本示例中,需要针对一张用户表进行 CRUD 操作。其数据模型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE IF NOT EXISTS user ( id BIGINT (10 ) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Id' , name VARCHAR (10 ) NOT NULL DEFAULT '' COMMENT '用户名' , age INT (3 ) NOT NULL DEFAULT 0 COMMENT '年龄' , address VARCHAR (32 ) NOT NULL DEFAULT '' COMMENT '地址' , email VARCHAR (32 ) NOT NULL DEFAULT '' COMMENT '邮件' , PRIMARY KEY (id) ) COMMENT = '用户表' ; INSERT INTO user (name, age, address, email)VALUES ('张三' , 18 , '北京' , 'xxx@163.com' );INSERT INTO user (name, age, address, email)VALUES ('李四' , 19 , '上海' , 'xxx@163.com' );
添加 MyBatis 如果使用 Maven 来构建项目,则需将下面的依赖代码置于 pom.xml 文件中:
1 2 3 4 5 <dependency > <groupId > org.mybatis</groupId > <artifactId > mybatis</artifactId > <version > x.x.x</version > </dependency >
MyBatis 配置 XML 配置文件中包含了对 MyBatis 系统的核心设置,包括获取数据库连接实例的数据源(DataSource)以及决定事务作用域和控制方式的事务管理器(TransactionManager)。
本示例中只是给出最简化的配置。
【示例】MyBatis-config.xml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="utf-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <configuration > <environments default ="development" > <environment id ="development" > <transactionManager type ="JDBC" /> <dataSource type ="POOLED" > <property name ="driver" value ="com.mysql.cj.jdbc.Driver" /> <property name ="url" value ="jdbc:mysql://127.0.0.1:3306/spring_tutorial?serverTimezone=UTC" /> <property name ="username" value ="root" /> <property name ="password" value ="root" /> </dataSource > </environment > </environments > <mappers > <mapper resource ="mybatis/mapper/UserMapper.xml" /> </mappers > </configuration >
说明:上面的配置文件中仅仅指定了数据源连接方式和 User 表的映射配置文件。
Mapper Mapper.xml 个人理解,Mapper.xml 文件可以看做是 MyBatis 的 JDBC SQL 模板。
【示例】UserMapper.xml 文件
下面是一个通过 MyBatis Generator 自动生成的完整的 Mapper 文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="io.github.dunwu.spring.orm.mapper.UserMapper" > <resultMap id ="BaseResultMap" type ="io.github.dunwu.spring.orm.entity.User" > <id column ="id" jdbcType ="BIGINT" property ="id" /> <result column ="name" jdbcType ="VARCHAR" property ="name" /> <result column ="age" jdbcType ="INTEGER" property ="age" /> <result column ="address" jdbcType ="VARCHAR" property ="address" /> <result column ="email" jdbcType ="VARCHAR" property ="email" /> </resultMap > <delete id ="deleteByPrimaryKey" parameterType ="java.lang.Long" > delete from user where id = #{id,jdbcType=BIGINT} </delete > <insert id ="insert" parameterType ="io.github.dunwu.spring.orm.entity.User" > insert into user (id, name, age, address, email) values (#{id,jdbcType=BIGINT}, #{name,jdbcType=VARCHAR}, #{age,jdbcType=INTEGER}, #{address,jdbcType=VARCHAR}, #{email,jdbcType=VARCHAR}) </insert > <update id ="updateByPrimaryKey" parameterType ="io.github.dunwu.spring.orm.entity.User" > update user set name = #{name,jdbcType=VARCHAR}, age = #{age,jdbcType=INTEGER}, address = #{address,jdbcType=VARCHAR}, email = #{email,jdbcType=VARCHAR} where id = #{id,jdbcType=BIGINT} </update > <select id ="selectByPrimaryKey" parameterType ="java.lang.Long" resultMap ="BaseResultMap" > select id, name, age, address, email from user where id = #{id,jdbcType=BIGINT} </select > <select id ="selectAll" resultMap ="BaseResultMap" > select id, name, age, address, email from user </select > </mapper >
Mapper.java Mapper.java 文件是 Mapper.xml 对应的 Java 对象。
【示例】UserMapper.java 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface UserMapper { int deleteByPrimaryKey (Long id) ; int insert (User record) ; User selectByPrimaryKey (Long id) ; List<User> selectAll () ; int updateByPrimaryKey (User record) ; }
对比 UserMapper.java 和 UserMapper.xml 文件,不难发现:
UserMapper.java 中的方法和 UserMapper.xml 的 CRUD 语句元素( <insert>、<delete>、<update>、<select>)存在一一对应关系。
在 MyBatis 中,正是通过方法的全限定名,将二者绑定在一起。
数据实体.java 【示例】User.java 文件
1 2 3 4 5 6 7 8 9 10 11 12 public class User { private Long id; private String name; private Integer age; private String address; private String email; }
<insert>、<delete>、<update>、<select> 的 parameterType 属性以及 <resultMap> 的 type 属性都可能会绑定到数据实体。这样就可以把 JDBC 操作的输入输出和 JavaBean 结合起来,更加方便、易于理解。
测试程序 【示例】MybatisDemo.java 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class MybatisDemo { public static void main (String[] args) throws Exception { InputStream inputStream = Resources.getResourceAsStream("MyBatis/MyBatis-config.xml" ); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder (); SqlSessionFactory factory = builder.build(inputStream); SqlSession sqlSession = factory.openSession(); Long params = 1L ; List<User> list = sqlSession.selectList("io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey" , params); for (User user : list) { System.out.println("user name: " + user.getName()); } } }
说明:
SqlSession 接口是 MyBatis API 核心中的核心,它代表了 MyBatis 和数据库的一次完整会话。
MyBatis 会解析配置,并根据配置创建 SqlSession 。
然后,MyBatis 将 Mapper 映射为 SqlSession,然后传递参数,执行 SQL 语句并获取结果。
MyBatis 生命周期
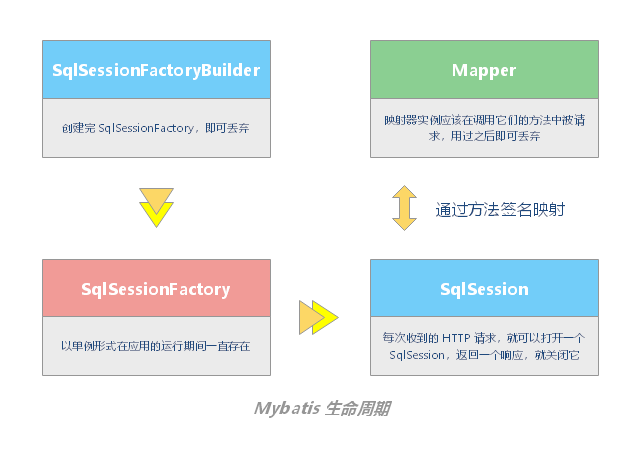
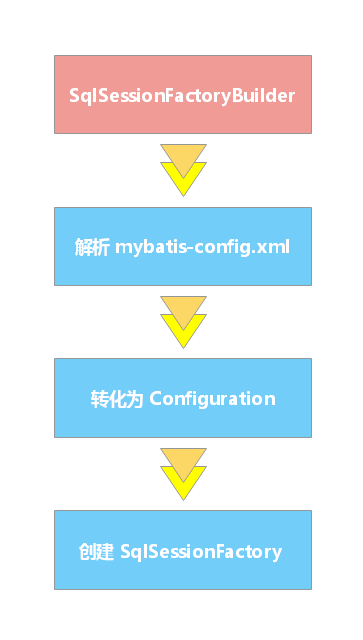
SqlSessionFactoryBuilder SqlSessionFactoryBuilder 的职责 SqlSessionFactoryBuilder 负责创建 SqlSessionFactory 实例SqlSessionFactoryBuilder 可以从 XML 配置文件或一个预先定制的 Configuration 的实例构建出 SqlSessionFactory 的实例。
Configuration 类包含了对一个 SqlSessionFactory 实例你可能关心的所有内容。
SqlSessionFactoryBuilder 应用了建造者设计模式,它有五个 build 方法,允许你通过不同的资源创建 SqlSessionFactory 实例。
1 2 3 4 5 SqlSessionFactory build (InputStream inputStream) SqlSessionFactory build (InputStream inputStream, String environment) SqlSessionFactory build (InputStream inputStream, Properties properties) SqlSessionFactory build (InputStream inputStream, String env, Properties props) SqlSessionFactory build (Configuration config)
SqlSessionFactoryBuilder 的生命周期 SqlSessionFactoryBuilder 可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但最好还是不要一直保留着它,以保证所有的 XML 解析资源可以被释放给更重要的事情。
SqlSessionFactory SqlSessionFactory 职责 SqlSessionFactory 负责创建 SqlSession 实例。
SqlSessionFactory 应用了工厂设计模式,它提供了一组方法,用于创建 SqlSession 实例。
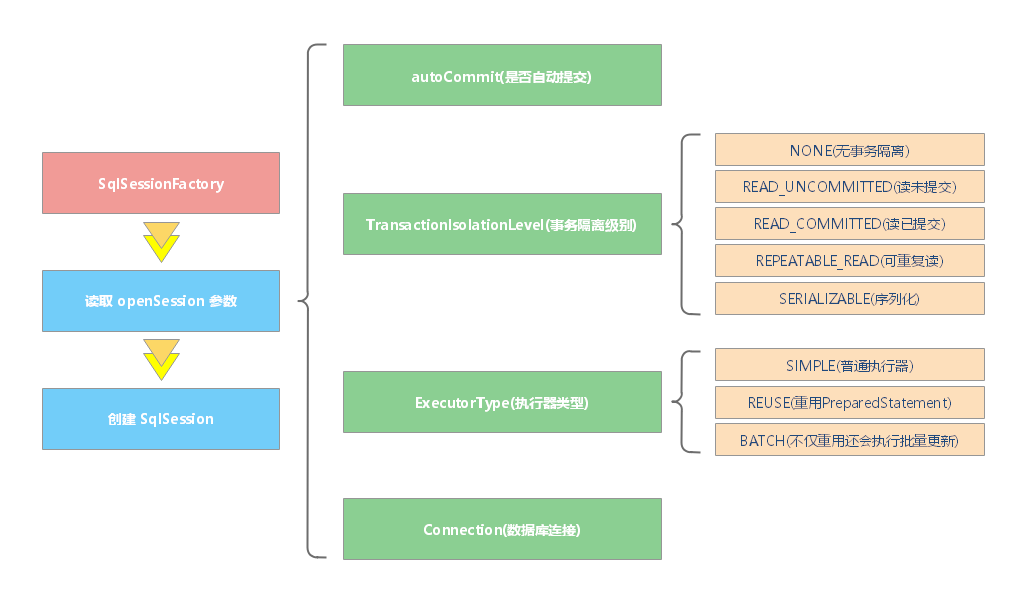
1 2 3 4 5 6 7 8 9 SqlSession openSession () SqlSession openSession (boolean autoCommit) SqlSession openSession (Connection connection) SqlSession openSession (TransactionIsolationLevel level) SqlSession openSession (ExecutorType execType, TransactionIsolationLevel level) SqlSession openSession (ExecutorType execType) SqlSession openSession (ExecutorType execType, boolean autoCommit) SqlSession openSession (ExecutorType execType, Connection connection) Configuration getConfiguration () ;
方法说明:
默认的 openSession() 方法没有参数,它会创建具备如下特性的 SqlSession:
事务作用域将会开启(也就是不自动提交)。
将由当前环境配置的 DataSource 实例中获取 Connection 对象。
事务隔离级别将会使用驱动或数据源的默认设置。
预处理语句不会被复用,也不会批量处理更新。
TransactionIsolationLevel 表示事务隔离级别,它对应着 JDBC 的五个事务隔离级别。ExecutorType 枚举类型定义了三个值:
ExecutorType.SIMPLE:该类型的执行器没有特别的行为。它为每个语句的执行创建一个新的预处理语句。ExecutorType.REUSE:该类型的执行器会复用预处理语句。ExecutorType.BATCH:该类型的执行器会批量执行所有更新语句,如果 SELECT 在多个更新中间执行,将在必要时将多条更新语句分隔开来,以方便理解。
SqlSessionFactory 生命周期 SqlSessionFactory 应该以单例形式在应用的运行期间一直存在。
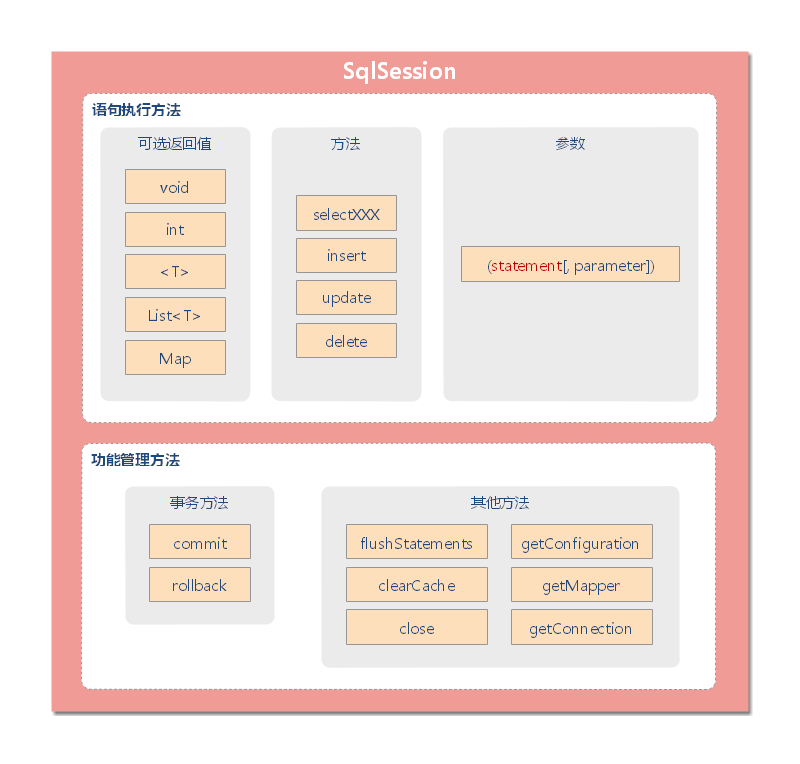
SqlSession SqlSession 职责 MyBatis 的主要 Java 接口就是 SqlSession。它包含了所有执行语句,获取映射器和管理事务等方法。
详细内容可以参考:“ MyBatis 官方文档之 SqlSessions ” 。
SqlSession 类的方法可以按照下图进行大致分类:
SqlSession 生命周期 SqlSessions 是由 SqlSessionFactory 实例创建的;而 SqlSessionFactory 是由 SqlSessionFactoryBuilder 创建的。
🔔 注意:当 MyBatis 与一些依赖注入框架(如 Spring 或者 Guice)同时使用时,SqlSessions 将被依赖注入框架所创建,所以你不需要使用 SqlSessionFactoryBuilder 或者 SqlSessionFactory。
每个线程都应该有它自己的 SqlSession 实例。
SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。 绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行。 也绝不能将 SqlSession 实例的引用放在任何类型的托管作用域中,比如 Servlet 框架中的 HttpSession。 正确在 Web 中使用 SqlSession 的场景是:每次收到的 HTTP 请求,就可以打开一个 SqlSession,返回一个响应,就关闭它。
编程模式:
1 2 3 try (SqlSession session = sqlSessionFactory.openSession()) { }
映射器 映射器职责 映射器是一些由用户创建的、绑定 SQL 语句的接口。
SqlSession 中的 insert、update、delete 和 select 方法都很强大,但也有些繁琐。更通用的方式是使用映射器类来执行映射语句。一个映射器类就是一个仅需声明与 SqlSession 方法相匹配的方法的接口类 。
MyBatis 将配置文件中的每一个 <mapper> 节点抽象为一个 Mapper 接口,而这个接口中声明的方法和跟 <mapper> 节点中的 <select|update|delete|insert> 节点相对应,即 <select|update|delete|insert> 节点的 id 值为 Mapper 接口中的方法名称,parameterType 值表示 Mapper 对应方法的入参类型,而 resultMap 值则对应了 Mapper 接口表示的返回值类型或者返回结果集的元素类型。
MyBatis 会根据相应的接口声明的方法信息,通过动态代理机制生成一个 Mapper 实例;MyBatis 会根据这个方法的方法名和参数类型,确定 Statement Id,然后和 SqlSession 进行映射,底层还是通过 SqlSession 完成和数据库的交互。
下面的示例展示了一些方法签名以及它们是如何映射到 SqlSession 上的。
注意
映射器接口不需要去实现任何接口或继承自任何类。只要方法可以被唯一标识对应的映射语句就可以了。
映射器接口可以继承自其他接口。当使用 XML 来构建映射器接口时要保证语句被包含在合适的命名空间中。而且,唯一的限制就是你不能在两个继承关系的接口中拥有相同的方法签名(潜在的危险做法不可取)。
映射器生命周期 映射器接口的实例是从 SqlSession 中获得的。因此从技术层面讲,任何映射器实例的最大作用域是和请求它们的 SqlSession 相同的。尽管如此,映射器实例的最佳作用域是方法作用域。 也就是说,映射器实例应该在调用它们的方法中被请求,用过之后即可丢弃。
编程模式:
1 2 3 4 try (SqlSession session = sqlSessionFactory.openSession()) { BlogMapper mapper = session.getMapper(BlogMapper.class); }
MyBatis 是一个 XML 驱动的框架。配置信息是基于 XML 的,而且映射语句也是定义在 XML 中的。MyBatis 3 以后,支持注解配置。注解配置基于配置 API;而配置 API 基于 XML 配置。
MyBatis 支持诸如 @Insert、@Update、@Delete、@Select、@Result 等注解。
详细内容请参考:MyBatis 官方文档之 sqlSessions ,其中列举了 MyBatis 支持的注解清单,以及基本用法。
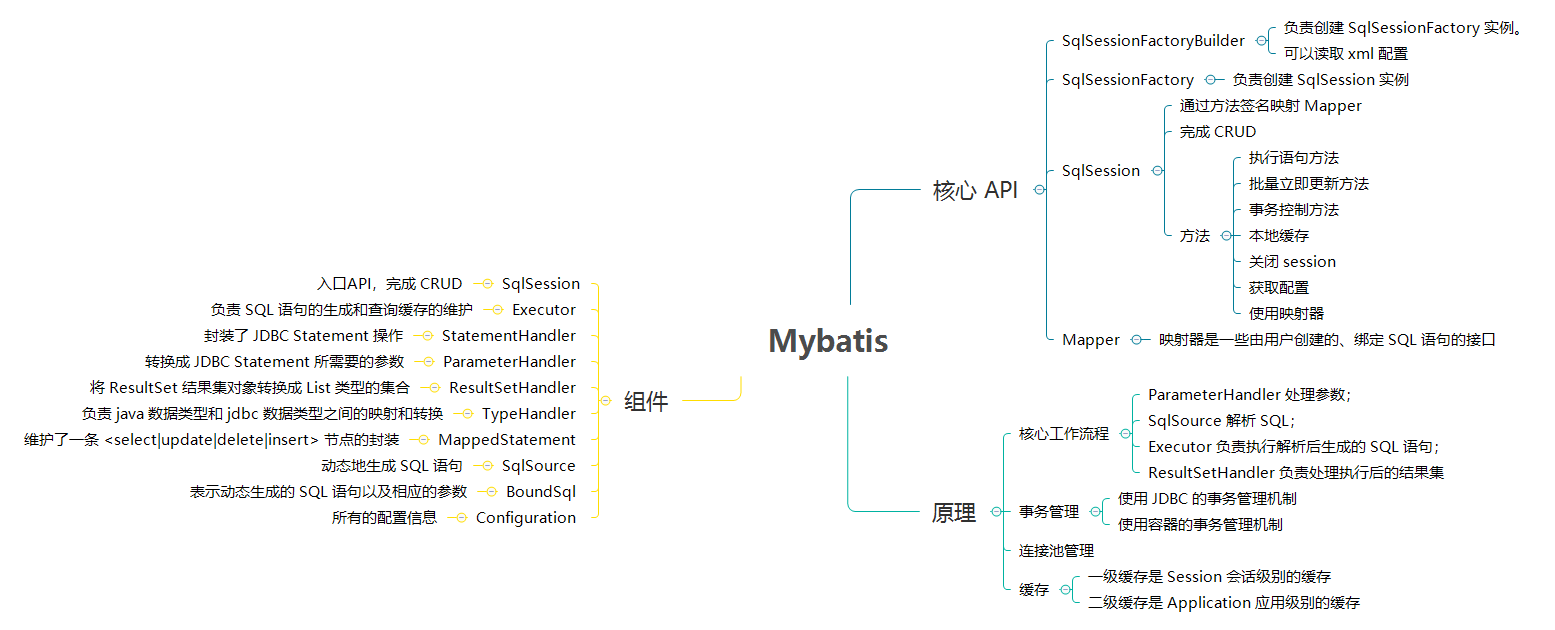
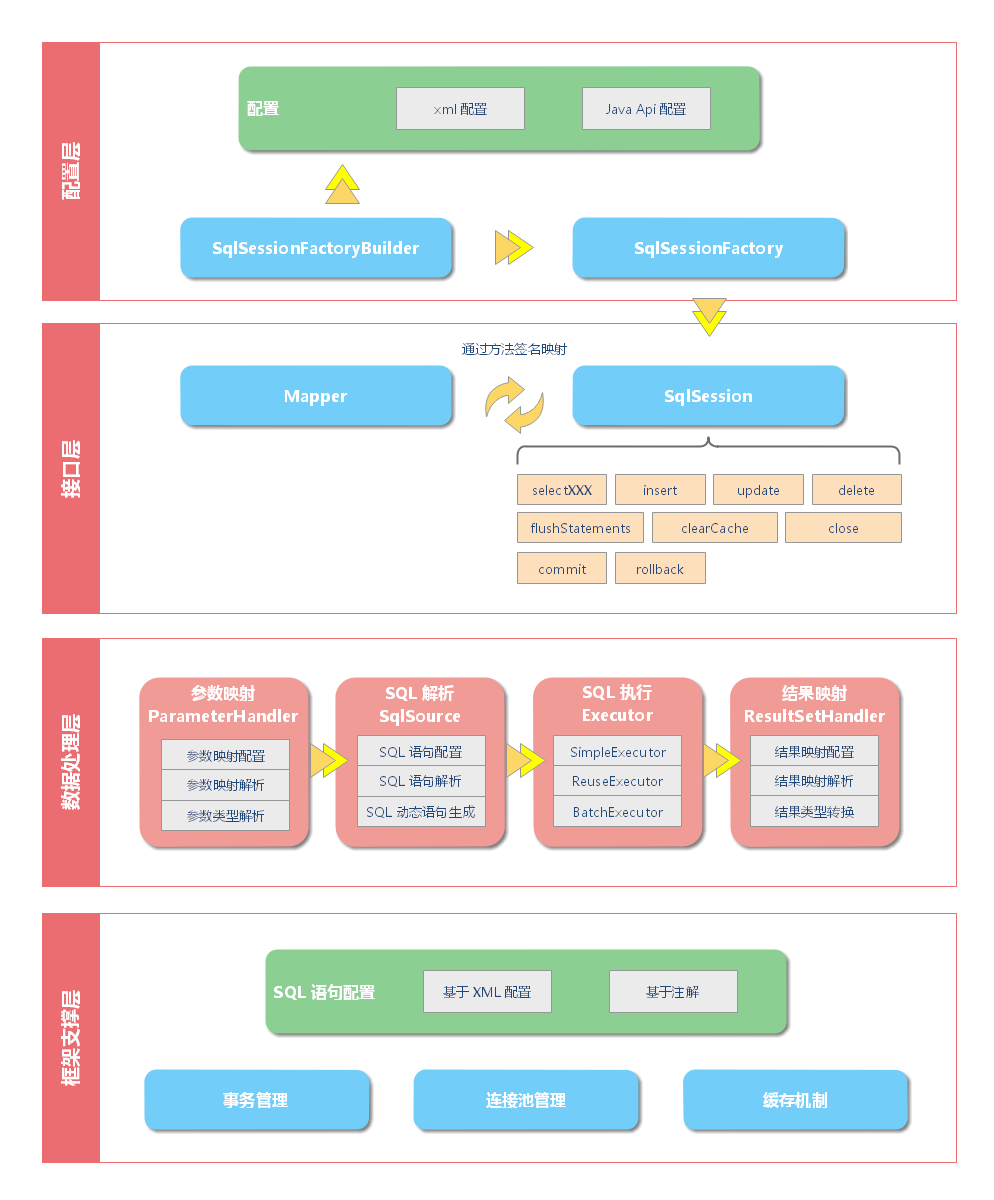
MyBatis 的架构 从 MyBatis 代码实现的角度来看,MyBatis 的主要组件有以下几个:
SqlSession - 作为 MyBatis 工作的主要顶层 API,表示和数据库交互的会话,完成必要数据库增删改查功能。Executor - MyBatis 执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成和查询缓存的维护。StatementHandler - 封装了 JDBC Statement 操作,负责对 JDBC statement 的操作,如设置参数、将 Statement 结果集转换成 List 集合。ParameterHandler - 负责对用户传递的参数转换成 JDBC Statement 所需要的参数。ResultSetHandler - 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。TypeHandler - 负责 java 数据类型和 jdbc 数据类型之间的映射和转换。MappedStatement - MappedStatement 维护了一条 <select|update|delete|insert> 节点的封装。SqlSource - 负责根据用户传递的 parameterObject,动态地生成 SQL 语句,将信息封装到 BoundSql 对象中,并返回。BoundSql - 表示动态生成的 SQL 语句以及相应的参数信息。Configuration - MyBatis 所有的配置信息都维持在 Configuration 对象之中。
这些组件的架构层次如下:
配置层 配置层决定了 MyBatis 的工作方式。
MyBatis 提供了两种配置方式:
基于 XML 配置文件的方式
基于 Java API 的方式
SqlSessionFactoryBuilder 会根据配置创建 SqlSessionFactory ;
SqlSessionFactory 负责创建 SqlSessions 。
接口层 接口层负责和数据库交互的方式。
MyBatis 和数据库的交互有两种方式:
使用 SqlSession :SqlSession 封装了所有执行语句,获取映射器和管理事务的方法。
用户只需要传入 Statement Id 和查询参数给 SqlSession 对象,就可以很方便的和数据库进行交互。
这种方式的缺点是不符合面向对象编程的范式。
使用 Mapper 接口 :MyBatis 会根据相应的接口声明的方法信息,通过动态代理机制生成一个 Mapper 实例;MyBatis 会根据这个方法的方法名和参数类型,确定 Statement Id,然后和 SqlSession 进行映射,底层还是通过 SqlSession 完成和数据库的交互。
数据处理层 数据处理层可以说是 MyBatis 的核心,从大的方面上讲,它要完成两个功能:
根据传参 Statement 和参数构建动态 SQL 语句
动态语句生成可以说是 MyBatis 框架非常优雅的一个设计,MyBatis 通过传入的参数值,使用 Ognl 来动态地构造 SQL 语句 ,使得 MyBatis 有很强的灵活性和扩展性。
参数映射指的是对于 java 数据类型和 jdbc 数据类型之间的转换:这里有包括两个过程:查询阶段,我们要将 java 类型的数据,转换成 jdbc 类型的数据,通过 preparedStatement.setXXX() 来设值;另一个就是对 resultset 查询结果集的 jdbcType 数据转换成 java 数据类型。
执行 SQL 语句以及处理响应结果集 ResultSet
动态 SQL 语句生成之后,MyBatis 将执行 SQL 语句,并将可能返回的结果集转换成 List<E> 列表。
MyBatis 在对结果集的处理中,支持结果集关系一对多和多对一的转换,并且有两种支持方式,一种为嵌套查询语句的查询,还有一种是嵌套结果集的查询。
框架支撑层
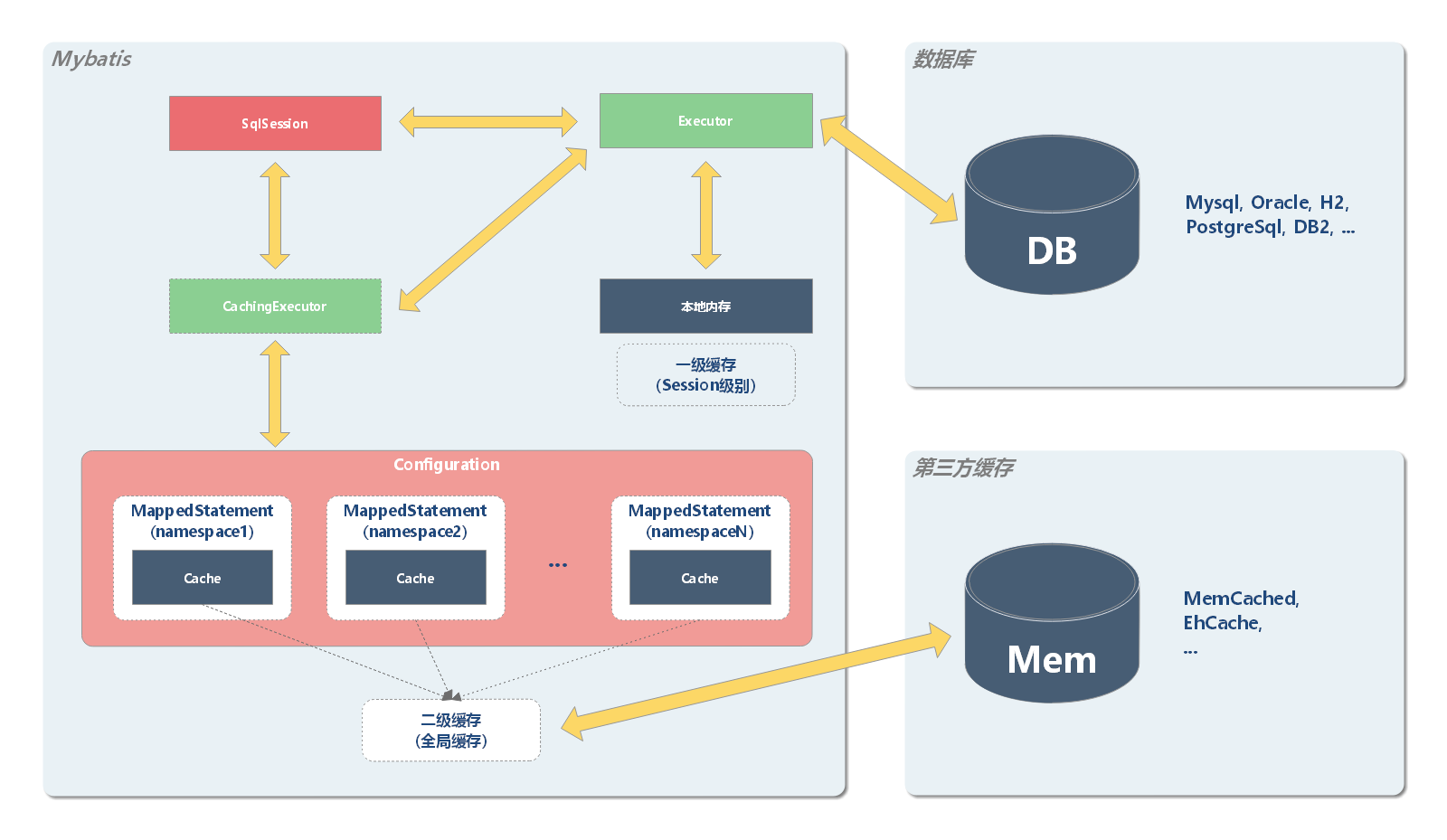
SqlSession 内部工作机制 从前文,我们已经了解了,MyBatis 封装了对数据库的访问,把对数据库的会话和事务控制放到了 SqlSession 对象中。那么具体是如何工作的呢?接下来,我们通过源码解读来进行分析。
SqlSession 对于 insert、update、delete、select 的内部处理机制基本上大同小异。所以,接下来,我会以一次完整的 select 查询流程为例讲解 SqlSession 内部的工作机制。相信读者如果理解了 select 的处理流程,对于其他 CRUD 操作也能做到一通百通。
SqlSession 子组件 前面的内容已经介绍了:SqlSession 是 MyBatis 的顶层接口,它提供了所有执行语句,获取映射器和管理事务等方法。
实际上,SqlSession 是通过聚合多个子组件,让每个子组件负责各自功能的方式,实现了任务的下发。
在了解各个子组件工作机制前,先让我们简单认识一下 SqlSession 的核心子组件。
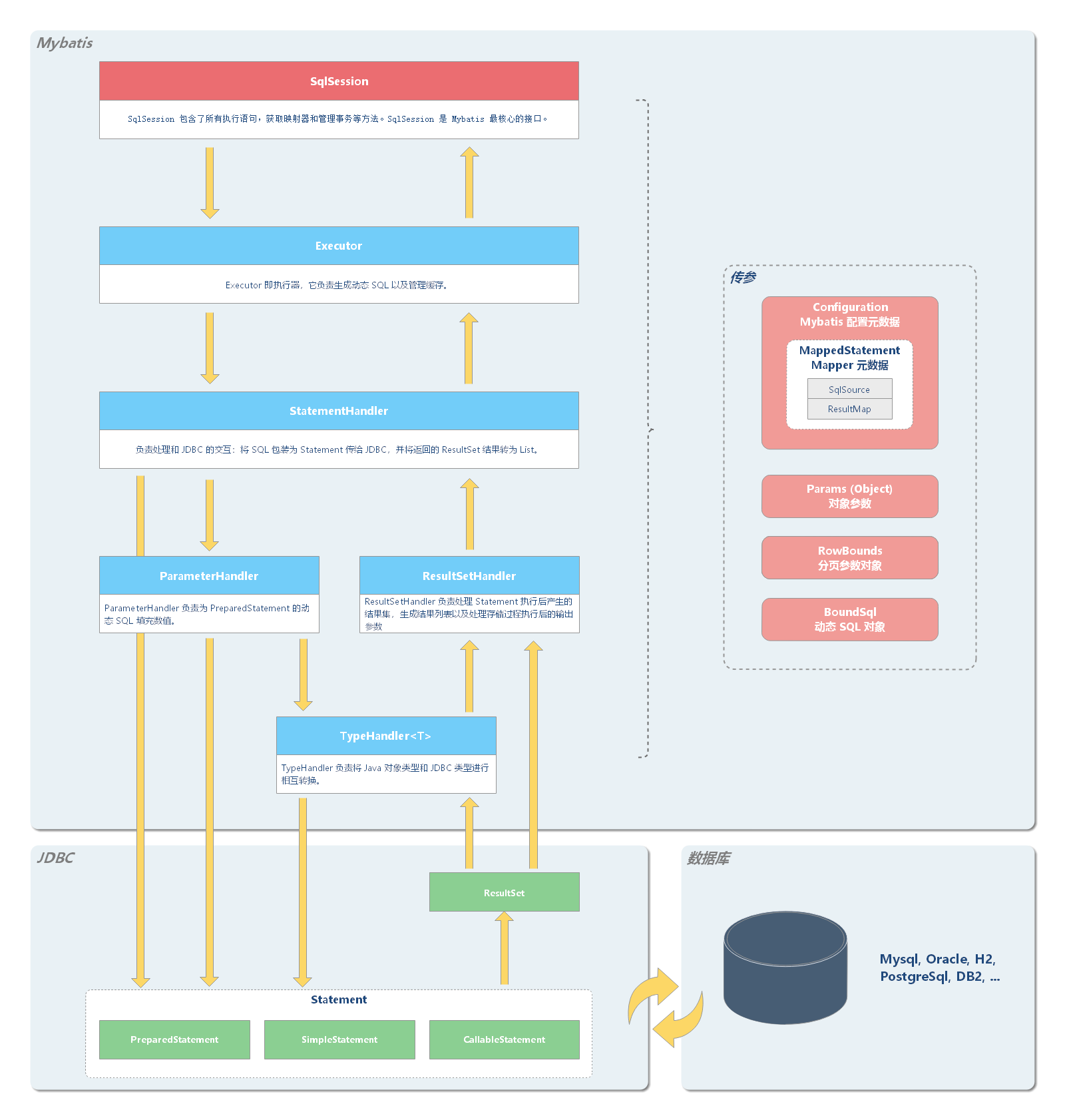
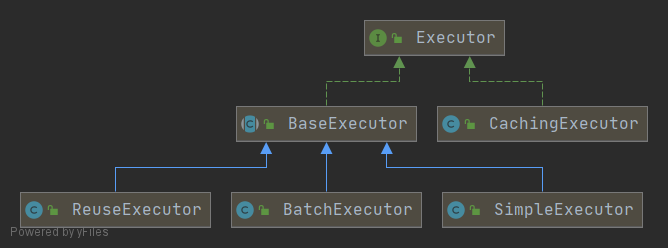
Executor Executor 即执行器,它负责生成动态 SQL 以及管理缓存。
Executor 即执行器接口。BaseExecutor 是 Executor 的抽象类,它采用了模板方法设计模式,内置了一些共性方法,而将定制化方法留给子类去实现。SimpleExecutor 是最简单的执行器。它只会直接执行 SQL,不会做额外的事。BatchExecutor 是批处理执行器。它的作用是通过批处理来优化性能。值得注意的是,批量更新操作,由于内部有缓存机制,使用完后需要调用 flushStatements 来清除缓存。ReuseExecutor 是可重用的执行器。重用的对象是 Statement,也就是说,该执行器会缓存同一个 SQL 的 Statement,避免重复创建 Statement。其内部的实现是通过一个 HashMap 来维护 Statement 对象的。由于当前 Map 只在该 session 中有效,所以使用完后需要调用 flushStatements 来清除 Map。CachingExecutor 是缓存执行器。它只在启用二级缓存时才会用到。
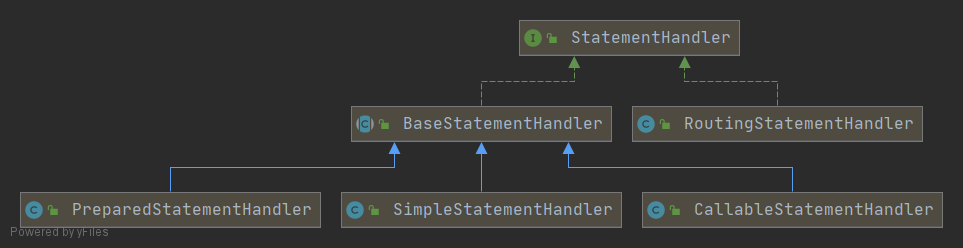
StatementHandler StatementHandler 对象负责设置 Statement 对象中的查询参数、处理 JDBC 返回的 resultSet,将 resultSet 加工为 List 集合返回。
StatementHandler 的家族成员:
StatementHandler 是接口;BaseStatementHandler 是实现 StatementHandler 的抽象类,内置一些共性方法;SimpleStatementHandler 负责处理 Statement;PreparedStatementHandler 负责处理 PreparedStatement;CallableStatementHandler 负责处理 CallableStatement。RoutingStatementHandler 负责代理 StatementHandler 具体子类,根据 Statement 类型,选择实例化 SimpleStatementHandler、PreparedStatementHandler、CallableStatementHandler。
ParameterHandler ParameterHandler 负责将传入的 Java 对象转换 JDBC 类型对象,并为 PreparedStatement 的动态 SQL 填充数值。
ParameterHandler 只有一个具体实现类,即 DefaultParameterHandler。
ResultSetHandler ResultSetHandler 负责两件事:
处理 Statement 执行后产生的结果集,生成结果列表
处理存储过程执行后的输出参数
ResultSetHandler 只有一个具体实现类,即 DefaultResultSetHandler。
TypeHandler TypeHandler 负责将 Java 对象类型和 JDBC 类型进行相互转换。
SqlSession 和 Mapper 先来回忆一下 MyBatis 完整示例章节的 测试程序部分的代码。
MybatisDemo.java 文件中的代码片段:
1 2 3 4 5 6 7 8 9 SqlSession sqlSession = factory.openSession();Long params = 1L ;List<User> list = sqlSession.selectList("io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey" , params); for (User user : list) { System.out.println("user name: " + user.getName()); }
示例代码中,给 sqlSession 对象的传递一个配置的 Sql 语句的 Statement Id 和参数,然后返回结果
io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey 是配置在 UserMapper.xml 的 Statement ID,params 是 SQL 参数。
UserMapper.xml 文件中的代码片段:
1 2 3 4 5 <select id ="selectByPrimaryKey" parameterType ="java.lang.Long" resultMap ="BaseResultMap" > select id, name, age, address, email from user where id = #{id,jdbcType=BIGINT} </select >
MyBatis 通过方法的全限定名,将 SqlSession 和 Mapper 相互映射起来。
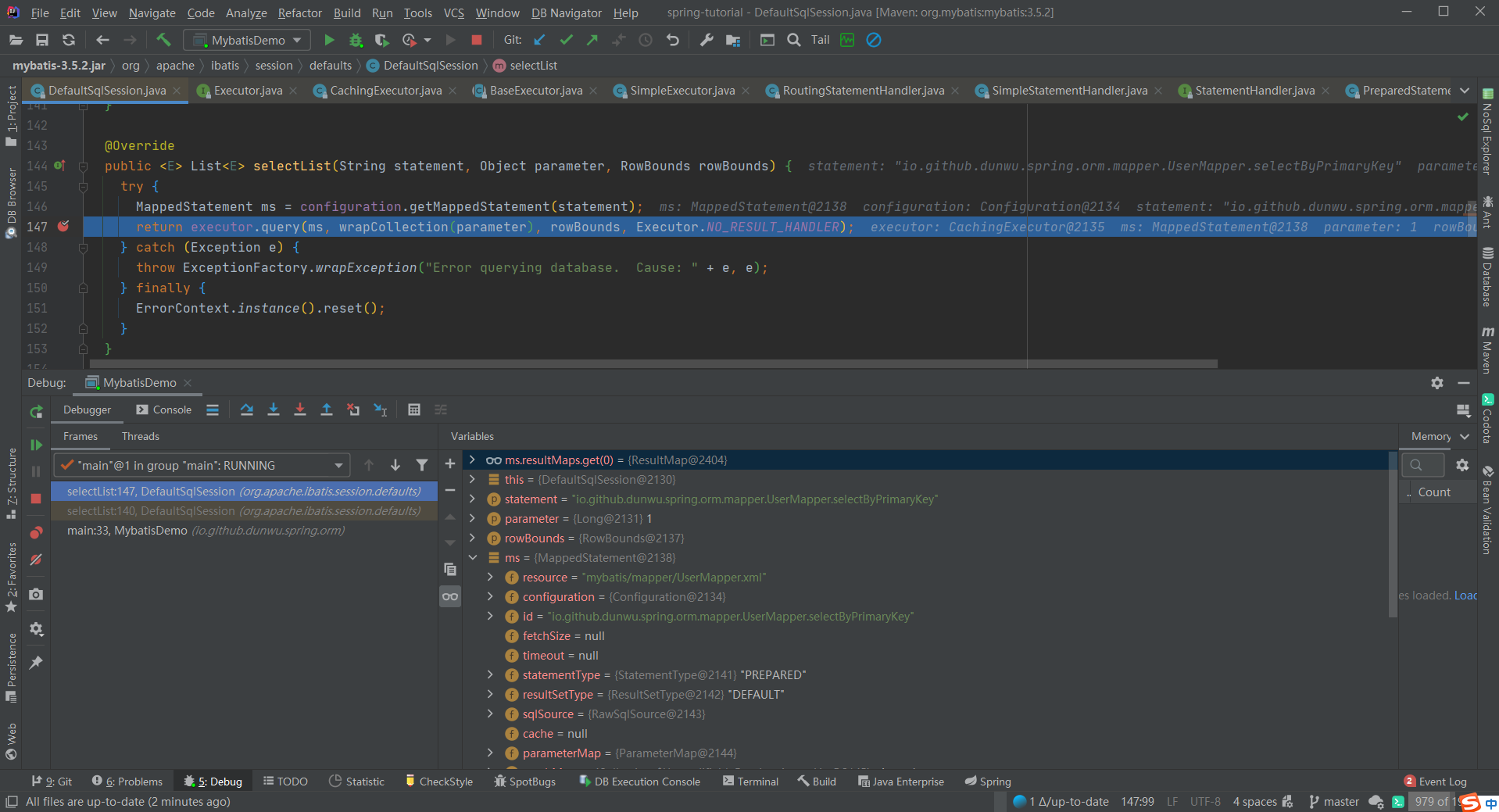
SqlSession 和 Executor org.apache.ibatis.session.defaults.DefaultSqlSession 中 selectList 方法的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override public <E> List<E> selectList (String statement) { return this .selectList(statement, null ); } @Override public <E> List<E> selectList (String statement, Object parameter) { return this .selectList(statement, parameter, RowBounds.DEFAULT); } @Override public <E> List<E> selectList (String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
说明:
MyBatis 所有的配置信息都维持在 Configuration 对象之中。中维护了一个 Map<String, MappedStatement> 对象。其中,key 为 Mapper 方法的全限定名(对于本例而言,key 就是 io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey ),value 为 MappedStatement 对象。所以,传入 Statement Id 就可以从 Map 中找到对应的 MappedStatement。
MappedStatement 维护了一个 Mapper 方法的元数据信息,其数据组织可以参考下面的 debug 截图:
小结:
通过 “SqlSession 和 Mapper” 以及 “SqlSession 和 Executor” 这两节,我们已经知道:
SqlSession 的职能是:根据 Statement ID, 在 Configuration 中获取到对应的 MappedStatement 对象,然后调用 Executor 来执行具体的操作。
Executor 工作流程 继续上一节的流程,SqlSession 将 SQL 语句交由执行器 Executor 处理。Executor 又做了哪些事儿呢?
(1)执行器查询入口
1 2 3 4 5 6 7 public <E> List<E> query (MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql); }
执行器查询入口主要做两件事:
生成动态 SQL :根据传参,动态生成需要执行的 SQL 语句,用 BoundSql 对象表示。管理缓存 :根据传参,创建一个缓存 Key。
(2)执行器查询第二入口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @SuppressWarnings("unchecked") @Override public <E> List<E> query (MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; try { queryStack++; list = resultHandler == null ? (List<E>) localCache.getObject(key) : null ; if (list != null ) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } return list; }
实际查询方法主要的职能是判断缓存 key 是否能命中缓存:
命中,则将缓存中数据返回;
不命中,则查询数据库:
(3)查询数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private <E> List<E> queryFromDatabase (MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
queryFromDatabase 方法的职责是调用 doQuery,向数据库发起查询,并将返回的结果更新到本地缓存。
(4)实际查询方法
SimpleExecutor 类的 doQuery()方法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override public <E> List<E> doQuery (MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null ; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }
上述的 Executor.query()方法几经转折,最后会创建一个 StatementHandler 对象,然后将必要的参数传递给 StatementHandler,使用 StatementHandler 来完成对数据库的查询,最终返回 List 结果集。Executor 的功能和作用是:
根据传递的参数,完成 SQL 语句的动态解析,生成 BoundSql 对象,供 StatementHandler 使用;
为查询创建缓存,以提高性能
创建 JDBC 的 Statement 连接对象,传递给 StatementHandler 对象,返回 List 查询结果。
prepareStatement() 方法的实现:
1 2 3 4 5 6 7 8 private Statement prepareStatement (StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); stmt = handler.prepare(connection, transaction.getTimeout()); handler.parameterize(stmt); return stmt; }
对于 JDBC 的 PreparedStatement 类型的对象,创建的过程中,我们使用的是 SQL 语句字符串会包含 若干个? 占位符,我们其后再对占位符进行设值。
StatementHandler 工作流程 StatementHandler 有一个子类 RoutingStatementHandler,它负责代理其他 StatementHandler 子类的工作。
它会根据配置的 Statement 类型,选择实例化相应的 StatementHandler,然后由其代理对象完成工作。
【源码】RoutingStatementHandler
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public RoutingStatementHandler (Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql); break ; case PREPARED: delegate = new PreparedStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql); break ; case CALLABLE: delegate = new CallableStatementHandler (executor, ms, parameter, rowBounds, resultHandler, boundSql); break ; default : throw new ExecutorException ("Unknown statement type: " + ms.getStatementType()); } }
【源码】RoutingStatementHandler 的 parameterize 方法源码
【源码】PreparedStatementHandler 的 parameterize 方法源码
StatementHandler 使用 ParameterHandler 对象来完成对 Statement 的赋值。
1 2 3 4 5 @Override public void parameterize (Statement statement) throws SQLException { parameterHandler.setParameters((PreparedStatement) statement); }
【源码】StatementHandler 的 query 方法源码
StatementHandler 使用 ResultSetHandler 对象来完成对 ResultSet 的处理。
1 2 3 4 5 6 7 @Override public <E> List<E> query (Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); return resultSetHandler.handleResultSets(ps); }
ParameterHandler 工作流程 【源码】DefaultParameterHandler 的 setParameters 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Override public void setParameters (PreparedStatement ps) { List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); if (parameterMappings != null ) { for (int i = 0 ; i < parameterMappings.size(); i++) { ParameterMapping parameterMapping = parameterMappings.get(i); if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; String propertyName = parameterMapping.getProperty(); if (boundSql.hasAdditionalParameter(propertyName)) { value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == null ) { value = null ; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } TypeHandler typeHandler = parameterMapping.getTypeHandler(); JdbcType jdbcType = parameterMapping.getJdbcType(); if (value == null && jdbcType == null ) { jdbcType = configuration.getJdbcTypeForNull(); } try { typeHandler.setParameter(ps, i + 1 , value, jdbcType); } catch (TypeException | SQLException e) { throw new TypeException ("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } } } } }
ResultSetHandler 工作流程 ResultSetHandler 的实现可以概括为:将 Statement 执行后的结果集,按照 Mapper 文件中配置的 ResultType 或 ResultMap 来转换成对应的 JavaBean 对象,最后将结果返回。
【源码】DefaultResultSetHandler 的 handleResultSets 方法
handleResultSets 方法是 DefaultResultSetHandler 的最关键方法。其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Override public List<Object> handleResultSets (Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results" ).object(mappedStatement.getId()); final List<Object> multipleResults = new ArrayList <>(); int resultSetCount = 0 ; ResultSetWrapper rsw = getFirstResultSet(stmt); List<ResultMap> resultMaps = mappedStatement.getResultMaps(); int resultMapCount = resultMaps.size(); validateResultMapsCount(rsw, resultMapCount); while (rsw != null && resultMapCount > resultSetCount) { ResultMap resultMap = resultMaps.get(resultSetCount); handleResultSet(rsw, resultMap, multipleResults, null ); rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } String[] resultSets = mappedStatement.getResultSets(); if (resultSets != null ) { while (rsw != null && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != null ) { String nestedResultMapId = parentMapping.getNestedResultMapId(); ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, null , parentMapping); } rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } } return collapseSingleResultList(multipleResults); }
参考资料












 另外,
另外,