publicfinalclassString implementsjava.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ privatefinalchar value[];
String 类被 final 关键字修饰,表示不可继承 String 类。
String 类的数据存储于 char[] 数组,这个数组被 final 关键字修饰,表示 String 对象不可被更改。
为什么 Java 要这样设计?
(1)保证 String 对象安全性。避免 String 被篡改。
(2)保证 hash 值不会频繁变更。
(3)可以实现字符串常量池。通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str="abc"; 另一种是字符串变量通过 new 形式的创建,如 String str = new String("abc")。
helloworld lookingAt: hello helloworld not lookingAt: world helloworld find: hello helloworld find: world helloworld not matches: hello helloworld not matches: world helloworld matches: helloworld
publicstaticvoidmain(String[] args) { Stringregex="can"; Stringreplace="can not"; Stringcontent="I can because I think I can."; StringBuffersb=newStringBuffer(); StringBuffersb2=newStringBuffer();
Exception in thread "main" java.lang.IllegalArgumentException: No group with name {product} at java.util.regex.Matcher.appendReplacement(Matcher.java:849) at java.util.regex.Matcher.replaceAll(Matcher.java:955) at org.zp.notes.javase.regex.RegexDemo.wrongMethod(RegexDemo.java:42) at org.zp.notes.javase.regex.RegexDemo.main(RegexDemo.java:18) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
// 输出 // b not matches: [^abc] // m not matches: [^a-z] // O not matches: [^A-Z] // K not matches: [^a-zA-Z] // k not matches: [^a-zA-Z] // 5 not matches: [^0-9]
// {n}: n 是一个非负整数。匹配确定的 n 次。 checkMatches("ap{1}", "a"); checkMatches("ap{1}", "ap"); checkMatches("ap{1}", "app"); checkMatches("ap{1}", "apppppppppp");
// {n,}: n 是一个非负整数。至少匹配 n 次。 checkMatches("ap{1,}", "a"); checkMatches("ap{1,}", "ap"); checkMatches("ap{1,}", "app"); checkMatches("ap{1,}", "apppppppppp");
// {n,m}: m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 checkMatches("ap{2,5}", "a"); checkMatches("ap{2,5}", "ap"); checkMatches("ap{2,5}", "app"); checkMatches("ap{2,5}", "apppppppppp");
// 输出 // a not matches: ap{1} // ap matches: ap{1} // app not matches: ap{1} // apppppppppp not matches: ap{1} // a not matches: ap{1,} // ap matches: ap{1,} // app matches: ap{1,} // apppppppppp matches: ap{1,} // a not matches: ap{2,5} // ap not matches: ap{2,5} // app matches: ap{2,5} // apppppppppp not matches: ap{2,5}
// (\w+)\s\1\W(\w+) 匹配重复的单词和紧随每个重复的单词的单词 Assert.assertTrue(findAll("(\\w+)\\s\\1\\W(\\w+)", "He said that that was the the correct answer.") > 0);
// 输出 // regex = (\w+)\s\1\W(\w+), content: He said that that was the the correct answer. // [1th] start: 8, end: 21, group: that that was // [2th] start: 22, end: 37, group: the the correct
// (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+) 匹配重复的单词和紧随每个重复的单词的单词 Assert.assertTrue(findAll("(?<duplicateWord>\\w+)\\s\\k<duplicateWord>\\W(?<nextWord>\\w+)", "He said that that was the the correct answer.") > 0);
// 输出 // regex = (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+), content: He said that that was the the correct answer. // [1th] start: 8, end: 21, group: that that was // [2th] start: 22, end: 37, group: the the correct
// \b\w+(?=\sis\b) 表示要捕获is之前的单词 Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "The dog is a Malamute.") > 0); Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The island has beautiful birds.") > 0); Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The pitch missed home plate.") > 0); Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "Sunday is a weekend day.") > 0);
// 输出 // regex = \b\w+(?=\sis\b), content: The dog is a Malamute. // [1th] start: 4, end: 7, group: dog // regex = \b\w+(?=\sis\b), content: The island has beautiful birds. // not found // regex = \b\w+(?=\sis\b), content: The pitch missed home plate. // not found // regex = \b\w+(?=\sis\b), content: Sunday is a weekend day. // [1th] start: 0, end: 6, group: Sunday
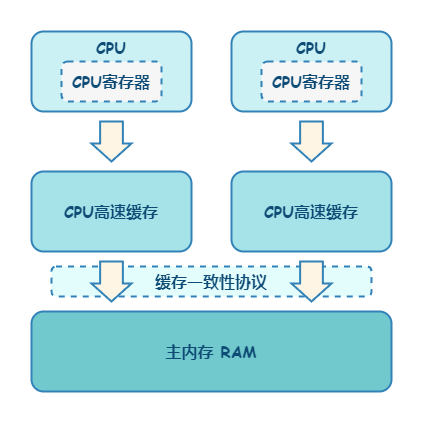
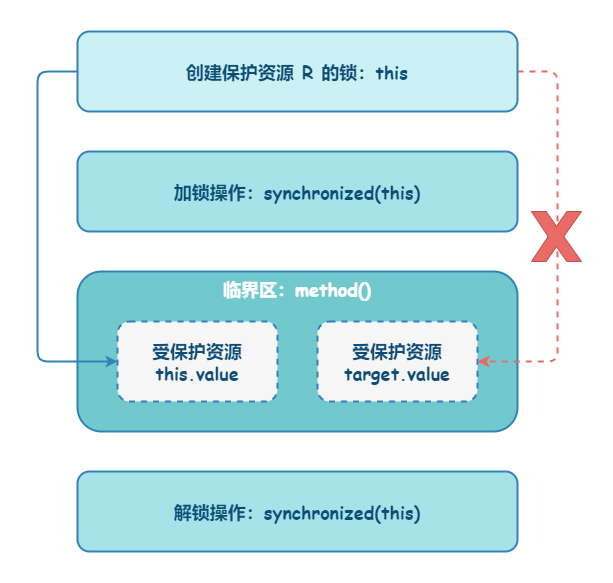
在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
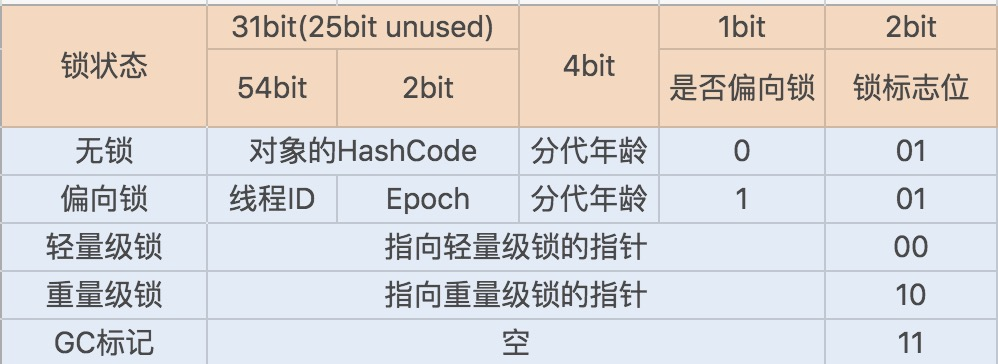
Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。如下图所示:
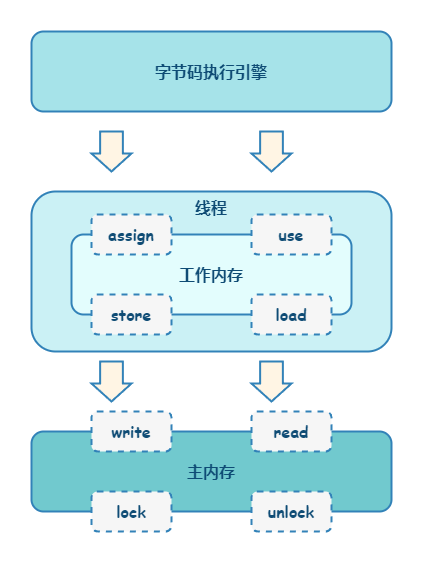
锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位,synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。
Java 1.6 引入了偏向锁和轻量级锁,从而让 synchronized 拥有了四个状态:
无锁状态(unlocked)
偏向锁状态(biasble)
轻量级锁状态(lightweight locked)
重量级锁状态(inflated)
当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现。
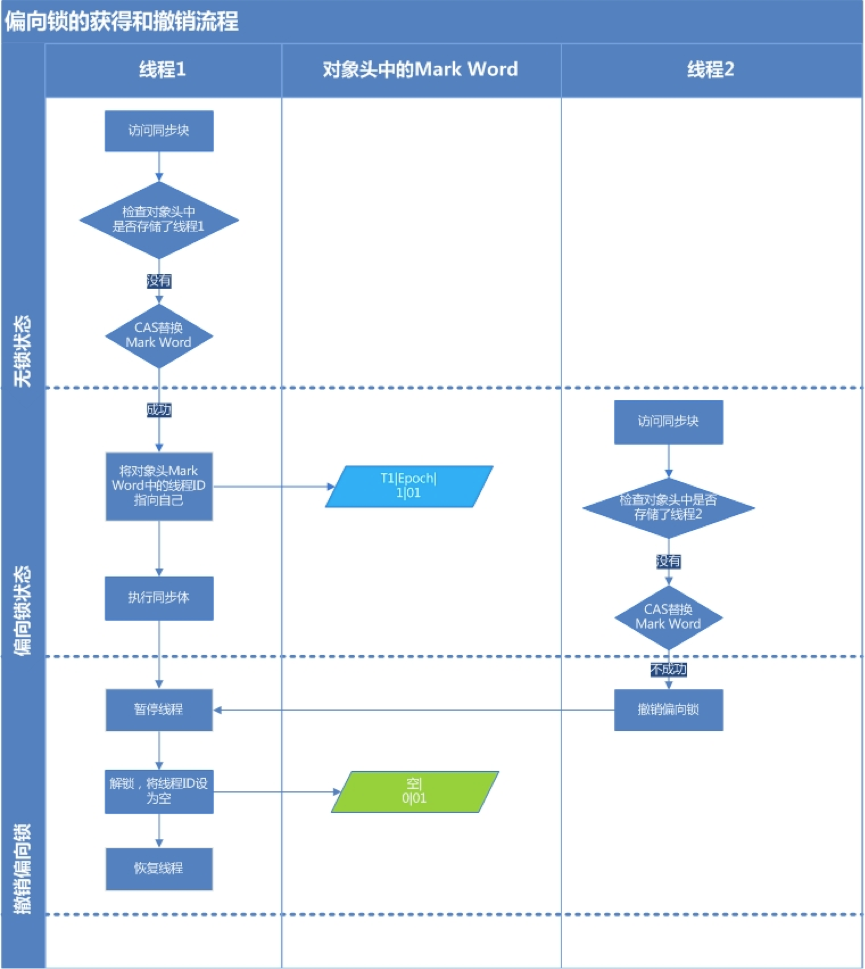
当没有竞争出现时,默认会使用偏向锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏向锁,并切换到轻量级锁实现。轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
偏向锁
偏向锁的思想是偏向于第一个获取锁对象的线程,这个线程在之后获取该锁就不再需要进行同步操作,甚至连 CAS 操作也不再需要。
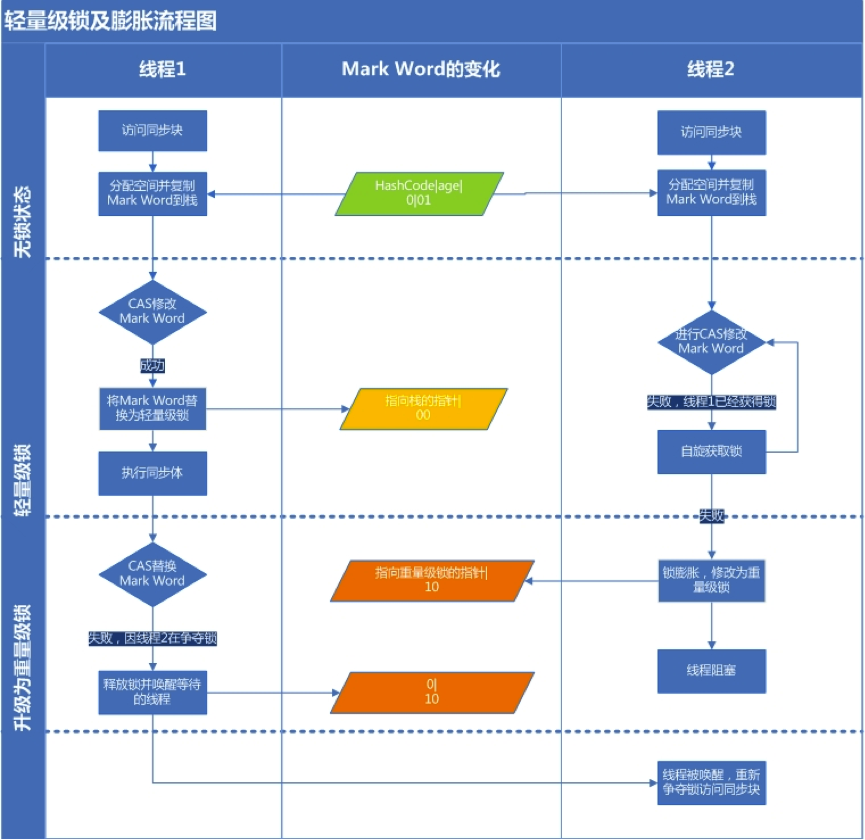
轻量级锁
轻量级锁是相对于传统的重量级锁而言,它 使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
当尝试获取一个锁对象时,如果锁对象标记为 0|01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
publicsynchronizedvoidadd() { log.info("add start"); for (inti=0; i < 10000; i++) { a++; b++; } log.info("add done"); }
publicvoidcompare() { log.info("compare start"); for (inti=0; i < 10000; i++) { //a 始终等于 b 吗? if (a < b) { log.info("a:{},b:{},{}", a, b, a > b); //最后的 a>b 应该始终是 false 吗? } } log.info("compare done"); }
}
【输出】
1 2 3 4
16:05:25.541[Thread-0] INFO io.github.dunwu.javacore.concurrent.sync.synchronized 使用范围不当 - add start 16:05:25.544[Thread-0] INFO io.github.dunwu.javacore.concurrent.sync.synchronized 使用范围不当 - add done 16:05:25.544[Thread-1] INFO io.github.dunwu.javacore.concurrent.sync.synchronized 使用范围不当 - compare start 16:05:25.544[Thread-1] INFO io.github.dunwu.javacore.concurrent.sync.synchronized 使用范围不当 - compare done
if (x == 1) { System.out.print("Value of X is 1"); } elseif (x == 2) { System.out.print("Value of X is 2"); } elseif (x == 3) { System.out.print("Value of X is 3"); } else { System.out.print("This is else statement"); } } } // output: // Value of X is 3
嵌套的 if…else 语句
使用嵌套的 if else 语句是合法的。也就是说你可以在另一个 if 或者 else if 语句中使用 if 或者 else if 语句。
语法
1 2 3 4 5 6
if (布尔表达式 1) { ////如果布尔表达式 1的值为true执行代码 if (布尔表达式 2) { ////如果布尔表达式 2的值为true执行代码 } }
publicclassWhileDemo { publicstaticvoidmain(String args[]) { intx=10; while (x < 20) { System.out.print("value of x : " + x); x++; System.out.print("\n"); } } } // output: // value of x : 10 // value of x : 11 // value of x : 12 // value of x : 13 // value of x : 14 // value of x : 15 // value of x : 16 // value of x : 17 // value of x : 18 // value of x : 19
do while 循环
对于 while 语句而言,如果不满足条件,则不能进入循环。但有时候我们需要即使不满足条件,也至少执行一次。
do { System.out.print("value of x : " + x); x++; System.out.print("\n"); } while (x < 20); } } // output: // value of x:10 // value of x:11 // value of x:12 // value of x:13 // value of x:14 // value of x:15 // value of x:16 // value of x:17 // value of x:18 // value of x:19
for 循环
虽然所有循环结构都可以用 while 或者 do while 表示,但 Java 提供了另一种语句 —— for 循环,使一些循环结构变得更加简单。 for 循环执行的次数是在执行前就确定的。
publicclassForDemo { publicstaticvoidmain(String args[]) { for (intx=10; x < 20; x = x + 1) { System.out.print("value of x : " + x); System.out.print("\n"); } } } // output: // value of x : 10 // value of x : 11 // value of x : 12 // value of x : 13 // value of x : 14 // value of x : 15 // value of x : 16 // value of x : 17 // value of x : 18 // value of x : 19
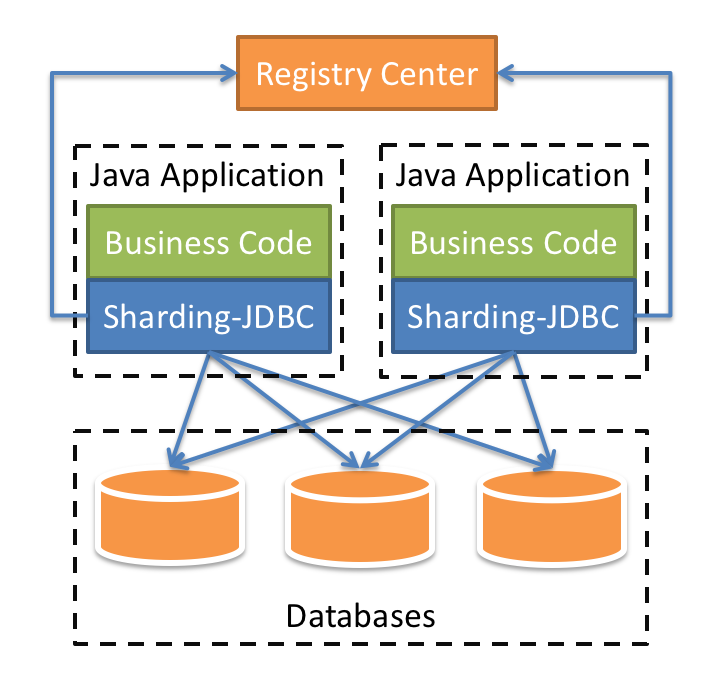
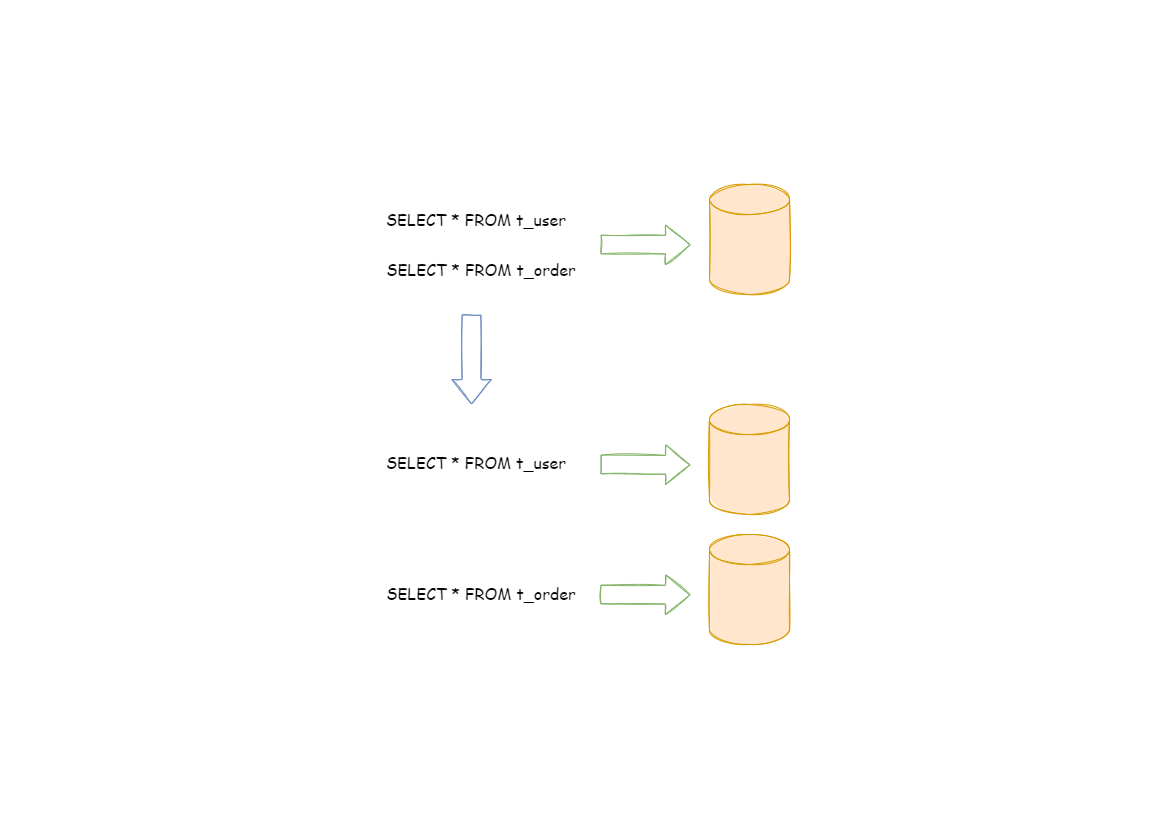
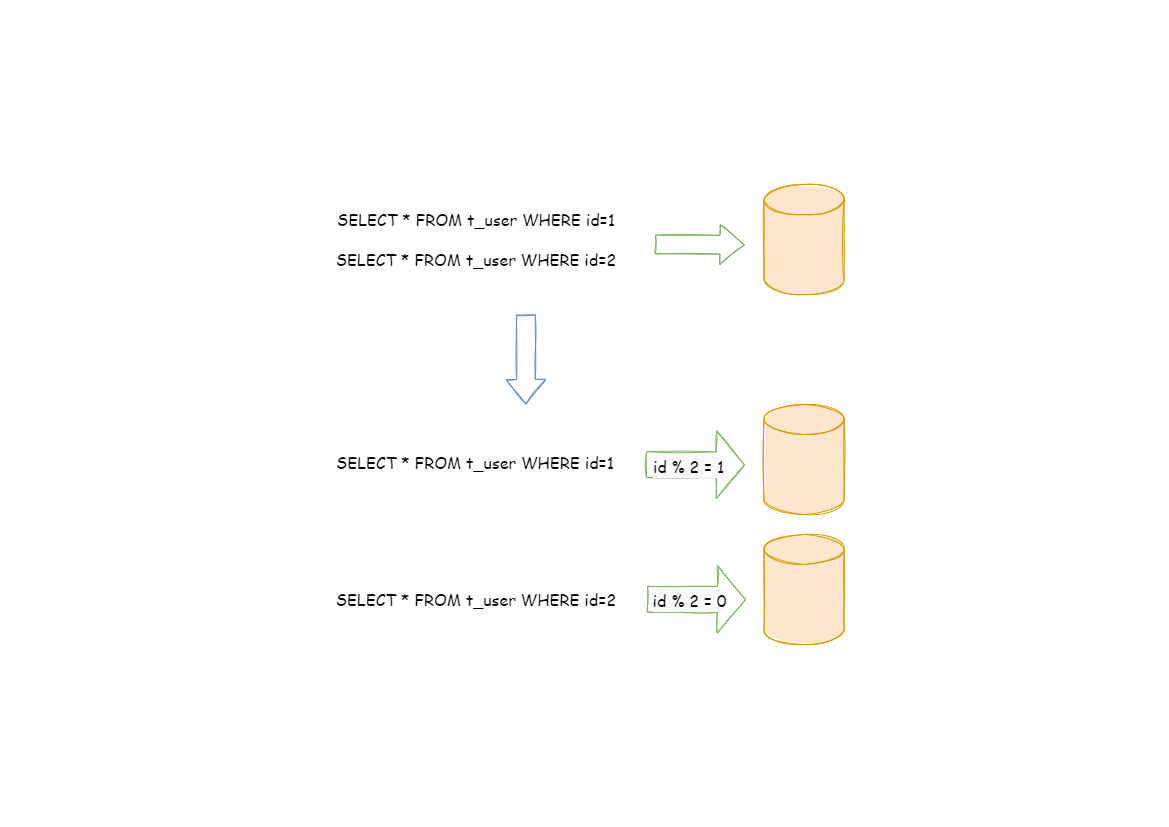
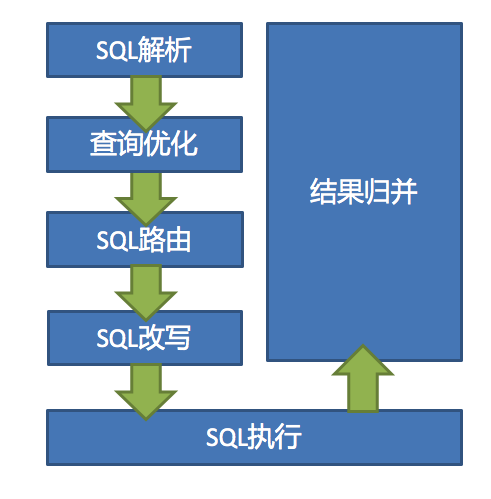
跨库事务:合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。 在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。