$ jinfo -sysprops 29527 Attaching to process ID 29527, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.222-b10 ...
jhat eclipse.bin Reading from eclipse.bin... Dump file created Fri Nov 19 22:07:21 CST 2010 Snapshot read, resolving... Resolving 1225951 objects... Chasing references, expect 245 dots.... Eliminating duplicate references... Snapshot resolved. Started HTTP server on port 7000 Server is ready.
"resin-22129" daemon prio=10 tid=0x00007fbe5c34e000 nid=0x4cb1 waiting on condition [0x00007fbe4ff7c000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:315) at com.caucho.env.thread2.ResinThread2.park(ResinThread2.java:196) at com.caucho.env.thread2.ResinThread2.runTasks(ResinThread2.java:147) at com.caucho.env.thread2.ResinThread2.run(ResinThread2.java:118)
"Finalizer" daemon prio=10 tid=0x00007fbea80da000 nid=0x5eb in Object.wait() [0x00007fbeac044000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:135) - locked <0x00000006d173c1a8> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:151) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
“Reference Handler”
JVM 在创建 main 线程后就创建 Reference Handler 线程,其优先级最高,为 10,它主要用于处理引用对象本身(软引用、弱引用、虚引用)的垃圾回收问题 。
1 2 3 4 5 6
"Reference Handler" daemon prio=10 tid=0x00007fbea80d8000 nid=0x5ea in Object.wait() [0x00007fbeac085000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.Object.wait(Object.java:503) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133) - locked <0x00000006d173c1f0> (a java.lang.ref.Reference$Lock)
“VM Thread”
JVM 中线程的母体,根据 HotSpot 源码中关于 vmThread.hpp 里面的注释,它是一个单例的对象(最原始的线程)会产生或触发所有其他的线程,这个单例的 VM 线程是会被其他线程所使用来做一些 VM 操作(如清扫垃圾等)。 在 VM Thread 的结构体里有一个 VMOperationQueue 列队,所有的 VM 线程操作 (vm_operation) 都会被保存到这个列队当中,VMThread 本身就是一个线程,它的线程负责执行一个自轮询的 loop 函数(具体可以参考:VMThread.cpp 里面的 void VMThread::loop()) ,该 loop 函数从 VMOperationQueue 列队中按照优先级取出当前需要执行的操作对象 (VM_Operation),并且调用 VM_Operation->evaluate 函数去执行该操作类型本身的业务逻辑。 VM 操作类型被定义在 vm_operations.hpp 文件内,列举几个:ThreadStop、ThreadDump、PrintThreads、GenCollectFull、GenCollectFullConcurrent、CMS_Initial_Mark、CMS_Final_Remark….. 有兴趣的同学,可以自己去查看源文件。
"DEADLOCK_TEST-1" daemon prio=6 tid=0x000000000690f800 nid=0x1820 waiting for monitor entry [0x000000000805f000] java.lang.Thread.State: BLOCKED (on object monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197) - waiting to lock <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182) - locked <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers: - None
"DEADLOCK_TEST-2" daemon prio=6 tid=0x0000000006858800 nid=0x17b8 waiting for monitor entry [0x000000000815f000] java.lang.Thread.State: BLOCKED (on object monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197) - waiting to lock <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182) - locked <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers: - None
"DEADLOCK_TEST-3" daemon prio=6 tid=0x0000000006859000 nid=0x25dc waiting for monitor entry [0x000000000825f000] java.lang.Thread.State: BLOCKED (on object monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197) - waiting to lock <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182) - locked <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor) at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
"BLOCKED_TEST pool-1-thread-2" prio=6 tid=0x0000000007673800 nid=0x260c waiting for monitor entry [0x0000000008abf000] java.lang.Thread.State: BLOCKED (on object monitor) at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:43) - waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState) at com.nbp.theplatform.threaddump.ThreadBlockedState$2.run(ThreadBlockedState.java:26) at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908) at java.lang.Thread.run(Thread.java:662) Locked ownable synchronizers: - <0x0000000780b0c6a0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync) "BLOCKED_TEST pool-1-thread-3" prio=6 tid=0x00000000074f5800 nid=0x1994 waiting for monitor entry [0x0000000008bbf000] java.lang.Thread.State: BLOCKED (on object monitor) at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:42) - waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState) at com.nbp.theplatform.threaddump.ThreadBlockedState$3.run(ThreadBlockedState.java:34) at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908) at java.lang.Thread.run(Thread.java:662) Locked ownable synchronizers: - <0x0000000780b0e1b8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
所以一定要结合系统的一些性能观察工具进行综合分析,比如 netstat 统计单位时间的发送包的数量,看是否很明显超过了所在网络带宽的限制;观察 CPU 的利用率,看系统态的 CPU 时间是否明显大于用户态的 CPU 时间。这些都指向由于网络带宽所限导致的网络瓶颈。
(3)还有一种常见的情况是该线程在 sleep,等待 sleep 的时间到了,将被唤醒。
【示例】等待状态样例
1 2 3 4 5 6 7 8 9 10
"IoWaitThread" prio=6 tid=0x0000000007334800 nid=0x2b3c waiting on condition [0x000000000893f000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007d5c45850> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:156) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1987) at java.util.concurrent.LinkedBlockingDeque.takeFirst(LinkedBlockingDeque.java:440) at java.util.concurrent.LinkedBlockingDeque.take(LinkedBlockingDeque.java:629) at com.nbp.theplatform.threaddump.ThreadIoWaitState$IoWaitHandler2.run(ThreadIoWaitState.java:89) at java.lang.Thread.run(Thread.java:662)
waiting for monitor entry 或 in Object.wait()
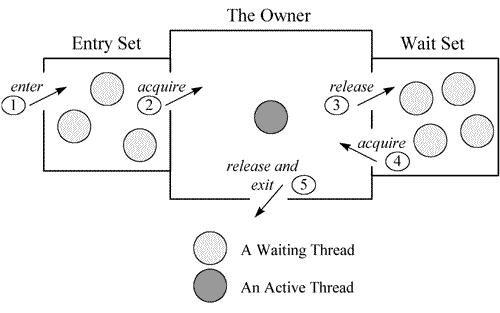
Moniter 是 Java 中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 class 的锁,每个对象都有,也仅有一个 Monitor。
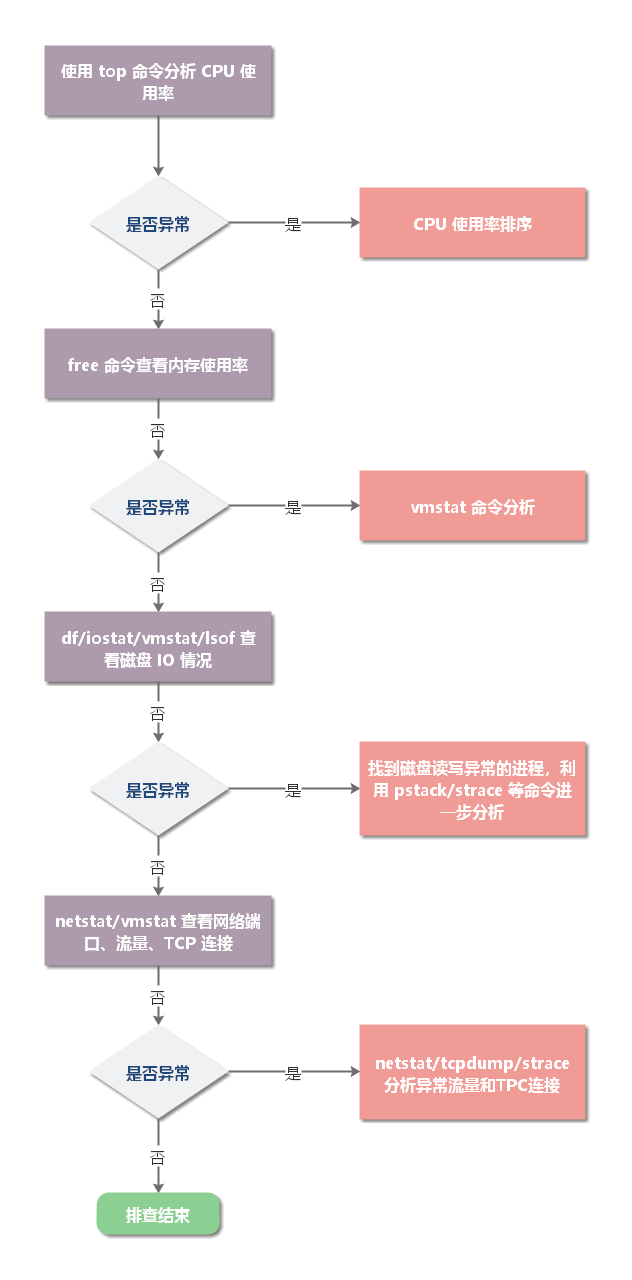
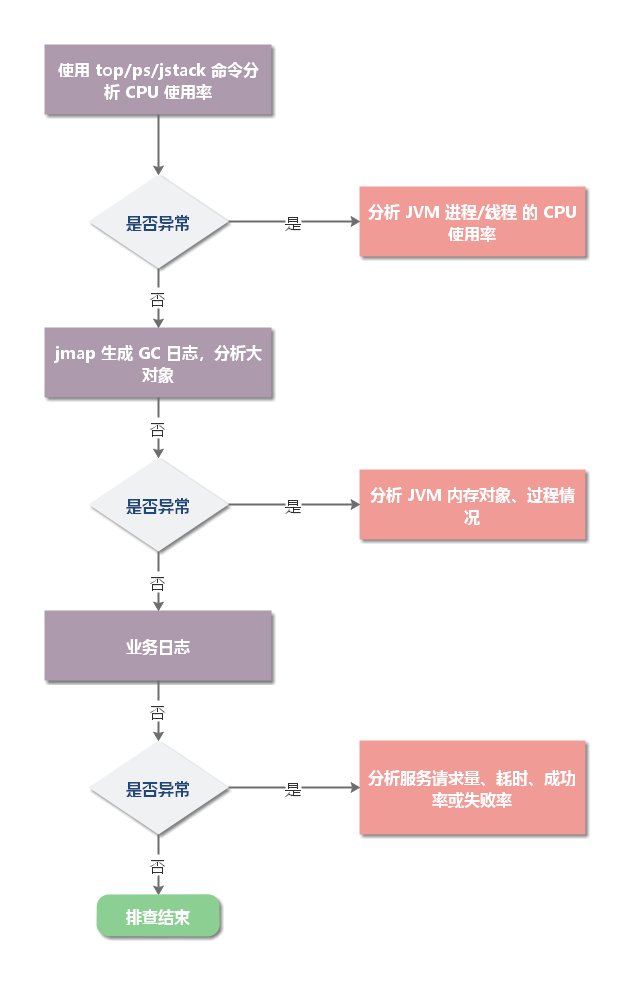
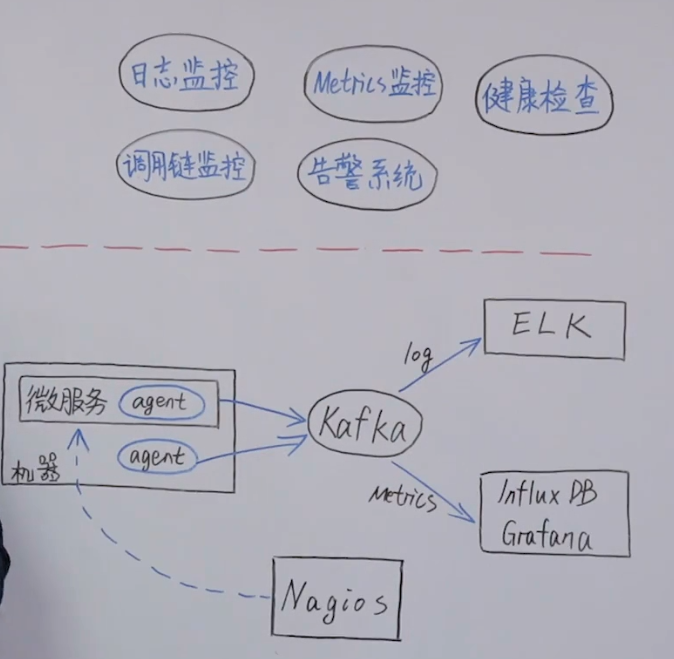
一、CPU 使用率过高:往往是由于程序逻辑问题导致的。常见导致 CPU 飙升的问题场景如:死循环,无限递归、频繁 GC、线程上下文切换过多。
二、CPU 始终升不上去:往往是由于程序中存在大量 IO 操作并且时间很长(数据库读写、日志等)。
查找 CPU 占用率较高的进程、线程
线上环境的 Java 应用可能有多个进程、线程,所以,要先找到 CPU 占用率较高的进程、线程。
(1)使用 ps 命令查看 xxx 应用的进程 ID(PID)
1
ps -ef | grep xxx
也可以使用 jps 命令来查看。
(2)如果应用有多个进程,可以用 top 命令查看哪个占用 CPU 较高。
(3)用 top -Hp pid 来找到 CPU 使用率比较高的一些线程。
(4)将占用 CPU 最高的 PID 转换为 16 进制,使用 printf '%x\n' pid 得到 nid
(5)使用 jstack pic | grep 'nid' -C5 命令,查看堆栈信息:
1 2 3 4 5 6 7 8 9 10 11 12
$ jstack 7129 | grep '0x1c23' -C5 at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) - locked <0x00000000b5383ff0> (a java.lang.ref.Reference$Lock) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
"main" #1 prio=5 os_prio=0 tid=0x00007f4df400a800 nid=0x1c23 in Object.wait() [0x00007f4dfdec8000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000b5384018> (a org.apache.felix.framework.util.ThreadGate) at org.apache.felix.framework.util.ThreadGate.await(ThreadGate.java:79) - locked <0x00000000b5384018> (a org.apache.felix.framework.util.ThreadGate)
$ vmstat 7129 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 6836 737532 1588 3504956 0 0 1 4 5 3 0 0 100 0 0
其中,cs 一列代表了上下文切换的次数。
【解决方法】
如果,线程上下文切换很频繁,可以考虑在应用中针对线程进行优化,方法有:
无锁并发:多线程竞争时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的 ID 按照 Hash 取模分段,不同的线程处理不同段的数据;
晋升失败:在 GC 的时候没有足够的内存供存活/晋升对象使用,所以触发了 Full GC。这时候可以通过-XX:G1ReservePercent来增加预留内存百分比,减少-XX:InitiatingHeapOccupancyPercent来提前启动标记,-XX:ConcGCThreads来增加标记线程数也是可以的。
大对象分配失败:大对象找不到合适的 region 空间进行分配,就会进行 fullGC,这种情况下可以增大内存或者增大-XX:G1HeapRegionSize。
function route(invokers){ var result = new java.util.ArrayList(invokers.size()); for(i =0; i < invokers.size(); i ++){ if("10.20.153.10".equals(invokers.get(i).getUrl().getHost())){ result.add(invokers.get(i)); } } return result; } (invokers));
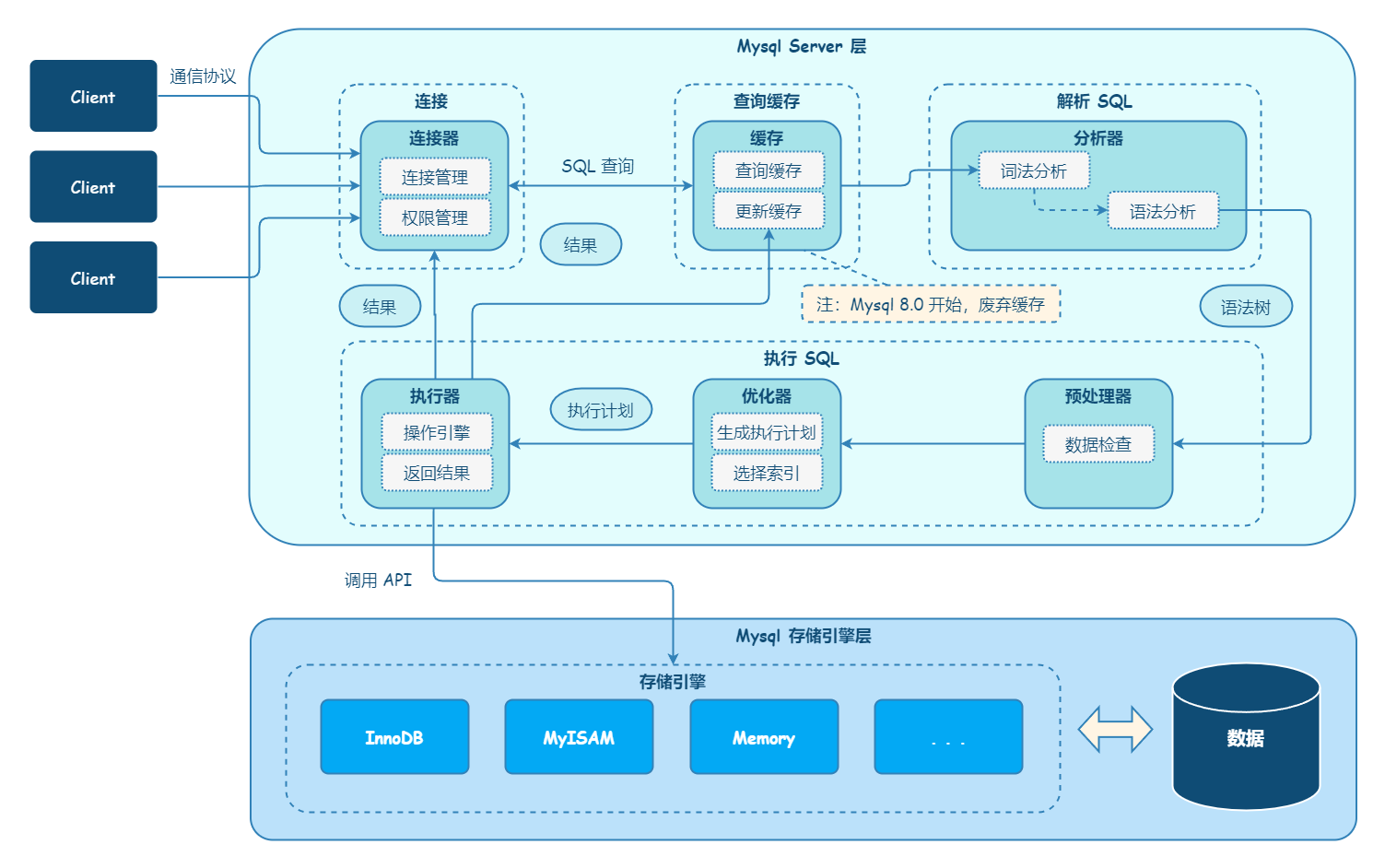
Server 层包括连接器、查询缓存、解析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
MySQL 查询流程
SQL 语句在 MySQL 中是如何执行的?
MySQL 整个查询执行过程,总的来说分为 6 个步骤:
连接器 - 客户端和 MySQL 服务器建立连接;连接器负责跟客户端建立连接、获取权限、维持和管理连接。
查询缓存 - MySQL 服务器首先检查查询缓存,如果命中缓存,则立刻返回结果。否则进入下一阶段。MySQL 缓存弊大于利,因为失效非常频繁——任何更新都会清空查询缓存。
分析器 - MySQL 服务器进行 SQL 解析:语法分析、词法分析。
优化器 - MySQL 服务器用优化器生成对应的执行计划,根据策略选择最优索引。
执行器 - MySQL 服务器根据执行计划,调用存储引擎的 API 来执行查询。
返回结果 - MySQL 服务器将结果返回给客户端,同时缓存查询结果。
连接器
使用 MySQL 第一步自然是要连接数据库。连接器负责跟客户端建立连接、获取权限、维持和管理连接。
MySQL 客户端/服务端通信是半双工模式:即任一时刻,要么是服务端向客户端发送数据,要么是客户端向服务器发送数据。客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置 max_allowed_packet 参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
MySQL 客户端连接命令形式为:mysql -h<主机> -P<端口> -u<用户名> -p<密码>。如果没有显式指定密码,会要求输入密码才能访问。
连接完成后,如果没有后续的动作,这个连接就处于空闲状态。可以执行 show processlist 命令查看当前有多少个客户端连接。客户端如果空闲太久,连接器就会自动将它断开。客户端连接维持时间是由参数 wait_timeout 控制的,默认值是 8 小时。如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
MySQL 使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。在 MySQL 可以通过查询当前会话的 last_query_cost 的值来得到其计算当前查询的成本。
1 2 3 4 5 6 7 8 9
mysql> select * from t_message limit 10; ...省略结果集
mysql> show status like 'last_query_cost'; +-----------------+-------------+ | Variable_name | Value | +-----------------+-------------+ | Last_query_cost | 6391.799000 | +-----------------+-------------+
结果集返回客户端是一个增量且逐步返回的过程。有可能 MySQL 在生成第一条结果时,就开始向客户端逐步返回结果集了。这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果。需要注意的是,结果集中的每一行都会以一个数据包发送,再通过 TCP 协议进行传输,在传输过程中,可能对 MySQL 的数据包进行缓存然后批量发送。
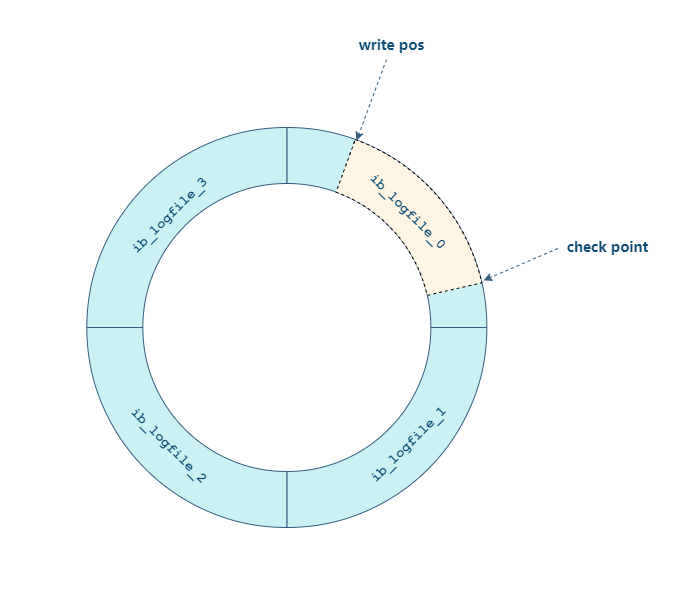
MySQL 更新流程
MySQL 更新过程和 MySQL 查询过程类似,也会将流程走一遍。不一样的是:更新流程还涉及两个重要的日志模块,:redo log(重做日志)和 binlog(归档日志)。
索引是提高 MySQL 查询性能的一个重要途径,但过多的索引可能会导致过高的磁盘使用率以及过高的内存占用,从而影响应用程序的整体性能。应当尽量避免事后才想起添加索引,因为事后可能需要监控大量的 SQL 才能定位到问题所在,而且添加索引的时间肯定是远大于初始添加索引所需要的时间,可见索引的添加也是非常有技术含量的。
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
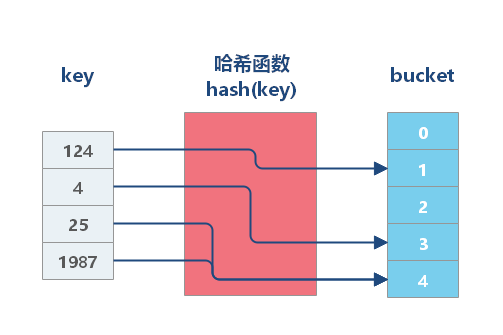
全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
全文索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的 WHERE 语句的参数匹配。全文索引配合 match against 操作使用,而不是一般的 WHERE 语句加 LIKE。它可以在 CREATE TABLE,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,先将数据放入一个没有全局索引的表中,然后再用 CREATE INDEX 创建全文索引,要比先为一张表建立全文索引然后再将数据写入的速度快很多。
SELECTCOUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment;
【示例】如有索引 (a, b, c, d),查询条件 c > 3 and b = 2 and a = 1 and d < 4 与 a = 1 and c > 3 and b = 2 and d < 4 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b、c、d。