Settingssettings= Settings.builder() .put("cluster.name", "myClusterName").build(); TransportClientclient=newPreBuiltTransportClient(settings); // Add transport addresses and do something with the client...
# 如果没有给出过滤器,默认是查询所有节点 GET /_nodes # 查询所有节点 GET /_nodes/_all # 查询本地节点 GET /_nodes/_local # 查询主节点 GET /_nodes/_master # 根据名称查询节点(支持通配符) GET /_nodes/node_name_goes_here GET /_nodes/node_name_goes_* # 根据地址查询节点(支持通配符) GET /_nodes/10.0.0.3,10.0.0.4 GET /_nodes/10.0.0.* # 根据规则查询节点 GET /_nodes/_all,master:false GET /_nodes/data:true,ingest:true GET /_nodes/coordinating_only:true GET /_nodes/master:true,voting_only:false # 根据自定义属性查询节点(如:查询配置文件中含 node.attr.rack:2 属性的节点) GET /_nodes/rack:2 GET /_nodes/ra*:2 GET /_nodes/ra*:2*
集群健康 API
1 2 3 4
GET /_cluster/health GET /_cluster/health?level=shards GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights GET /_cluster/health/kibana_sample_data_flights?level=shards
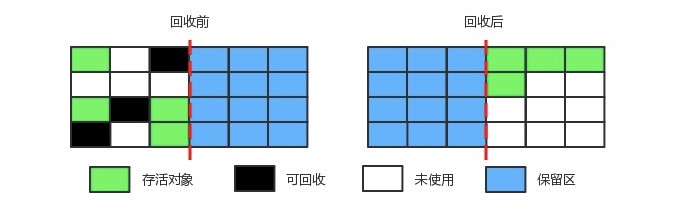
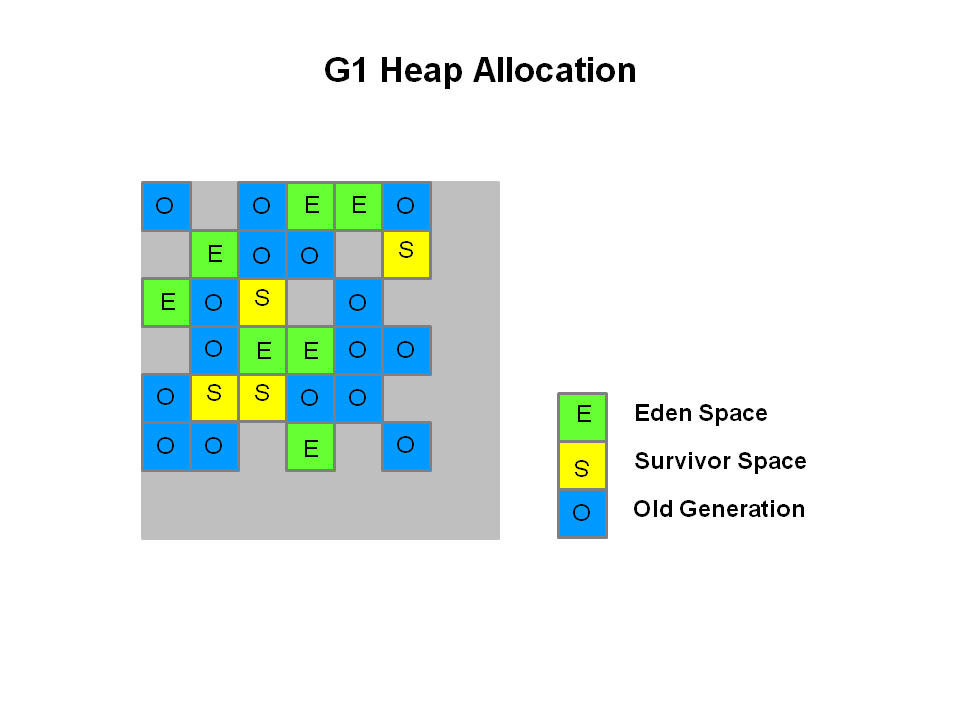
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
G1 回收机制
G1 收集器运行示意图
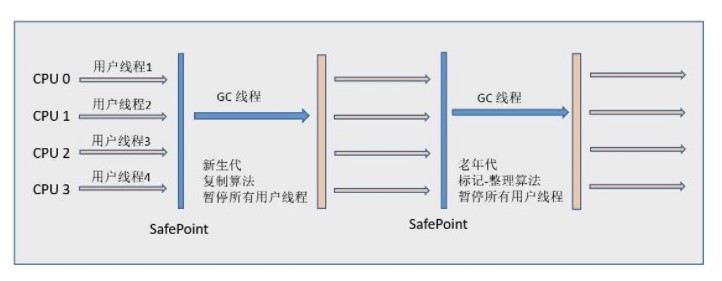
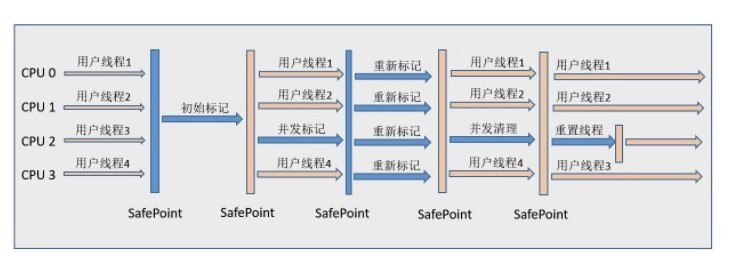
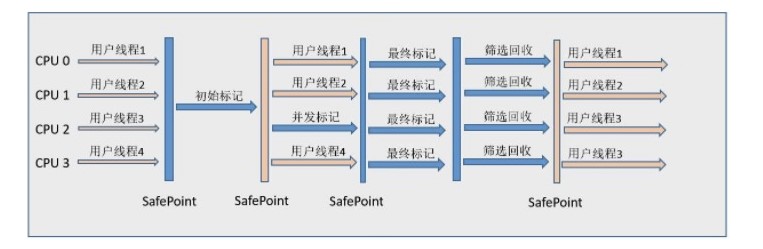
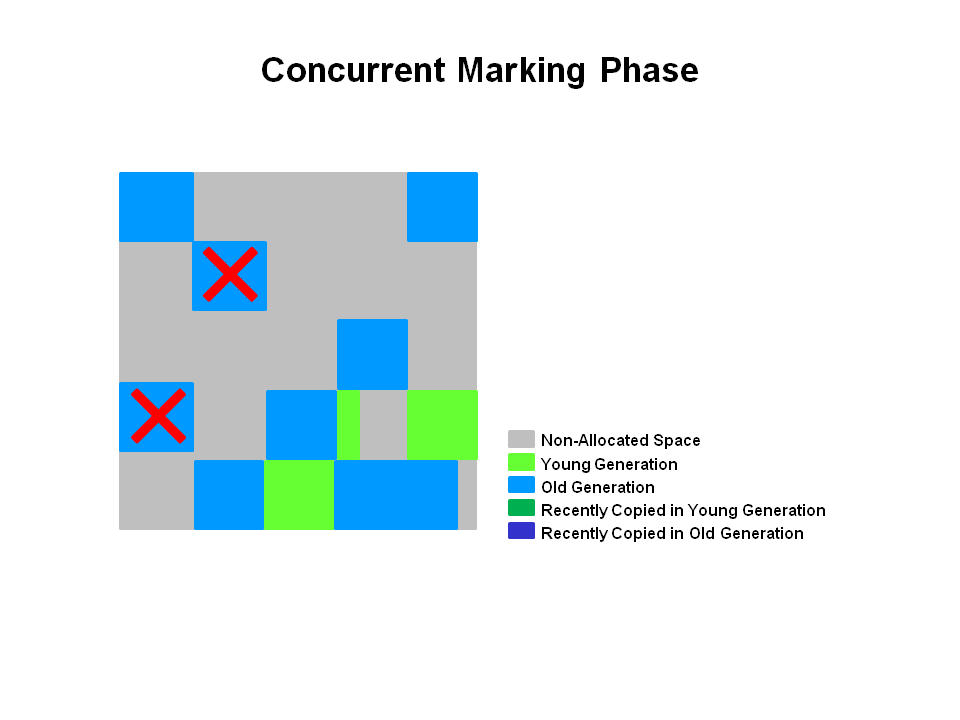
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
初始标记
并发标记
最终标记 - 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
筛选回收 - 首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
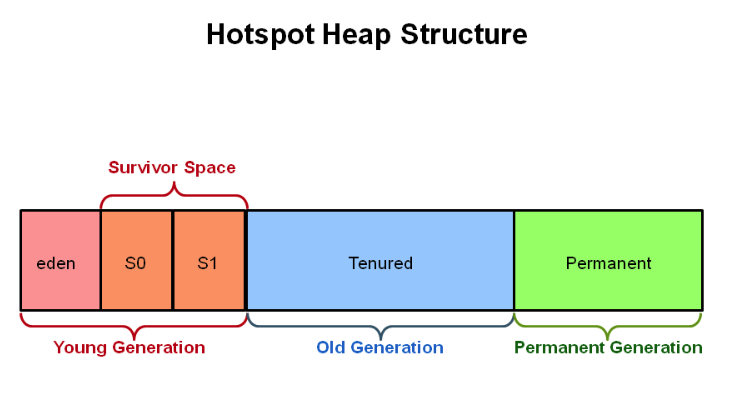
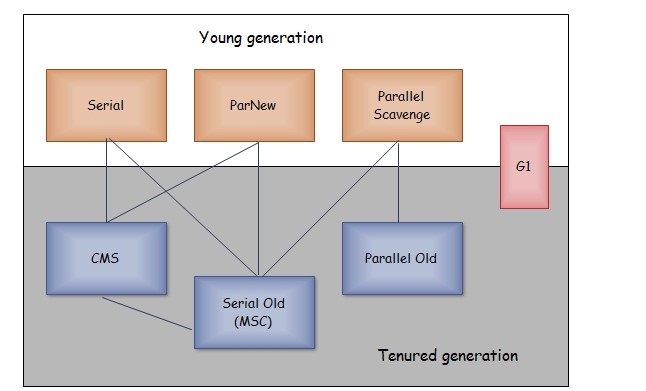
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于年轻代所有对象总空间,如果条件成立的话,那么 Minor GC 可以确认是安全的;如果不成立的话虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC,尽管这次 Minor GC 是有风险的;如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一次 Full GC。
Full GC 的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 区空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
(1)调用 System.gc()
此方法的调用是建议虚拟机进行 Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加 Full GC 的频率,也即增加了间歇性停顿的次数。因此强烈建议能不使用此方法就不要使用,让虚拟机自己去管理它的内存。可通过 -XX:DisableExplicitGC 来禁止 RMI 调用 System.gc()。
(2)老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等,当执行 Full GC 后空间仍然不足,则抛出 java.lang.OutOfMemoryError: Java heap space。为避免以上原因引起的 Full GC,调优时应尽量做到让对象在 Minor GC 阶段被回收、让对象在年轻代多存活一段时间以及不要创建过大的对象及数组。
(3)方法区空间不足
JVM 规范中运行时数据区域中的方法区,在 HotSpot 虚拟机中又被习惯称为永久代,永久代中存放的是类的描述信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么 JVM 会抛出 java.lang.OutOfMemoryError: PermGen space 错误。为避免永久代占满造成 Full GC 现象,可采用的方法为增大 Perm Gen 空间或转为使用 CMS GC。
(4)Minor GC 的平均晋升空间大小大于老年代可用空间
如果发现统计数据说之前 Minor GC 的平均晋升大小比目前老年代剩余的空间大,则不会触发 Minor GC 而是转为触发 Full GC。
(5)对象大小大于 To 区和老年代的可用内存
由 Eden 区、From 区向 To 区复制时,对象大小大于 To 区可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
// ...省略 java.lang.Exception: #14 at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20) [Loaded sun.reflect.ClassFileConstants from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.AccessorGenerator from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.MethodAccessorGenerator from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ByteVectorFactory from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ByteVector from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ByteVectorImpl from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ClassFileAssembler from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.UTF8 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.Label from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.Label$PatchInfo from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded java.util.ArrayList$Itr from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.MethodAccessorGenerator$1 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ClassDefiner from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.ClassDefiner$1 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] [Loaded sun.reflect.GeneratedMethodAccessor1 from __JVM_DefineClass__] java.lang.Exception: #15 at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20) [Loaded java.util.concurrent.ConcurrentHashMap$ForwardingNode from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar] java.lang.Exception: #16 at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13) at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20) // ...省略
publicclassInstanceofDemo { publicstaticvoidmain(String[] args) { ArrayListarrayList=newArrayList(); if (arrayList instanceof List) { System.out.println("ArrayList is List"); } if (List.class.isInstance(arrayList)) { System.out.println("ArrayList is List"); } } } //Output: //ArrayList is List //ArrayList is List
com.sun.proxy.$Proxy0 Before method Call Method: public abstract void io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.hello(java.lang.String) Hello World After method
Before method Call Method: public abstract java.lang.String io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.bye() Goodbye After method

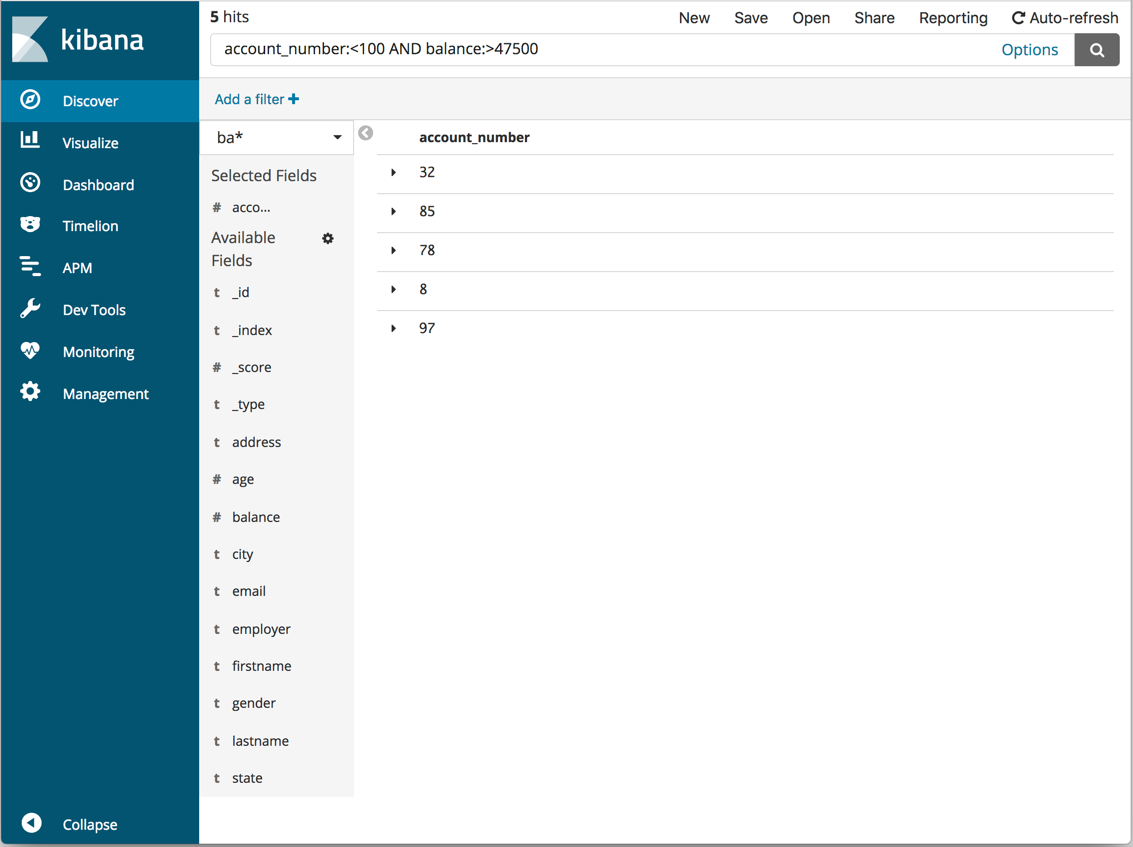

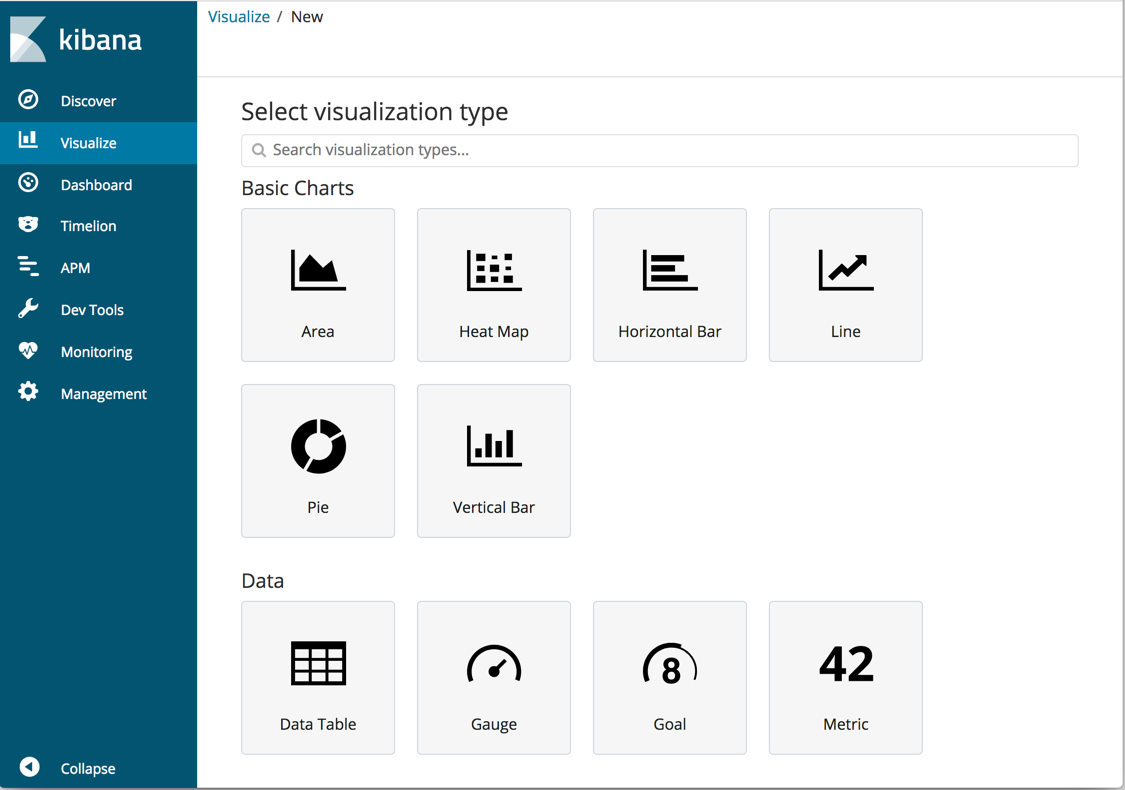
 按钮来更新图表。
按钮来更新图表。