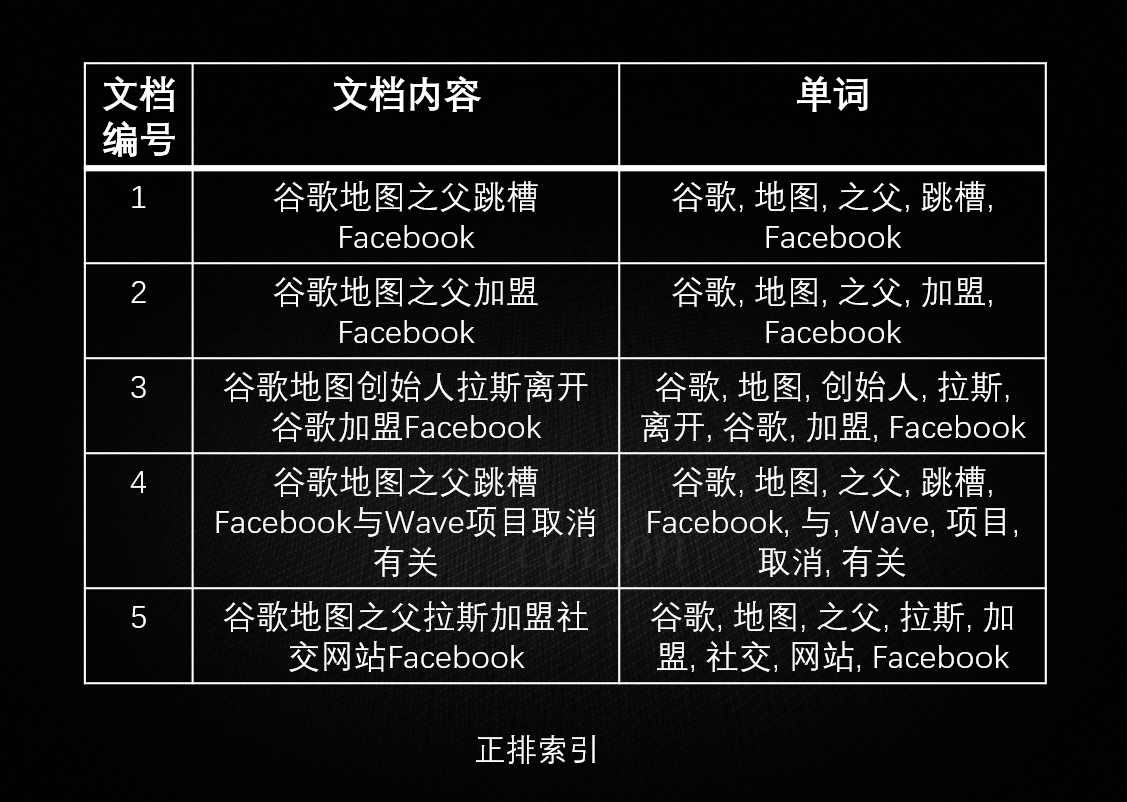
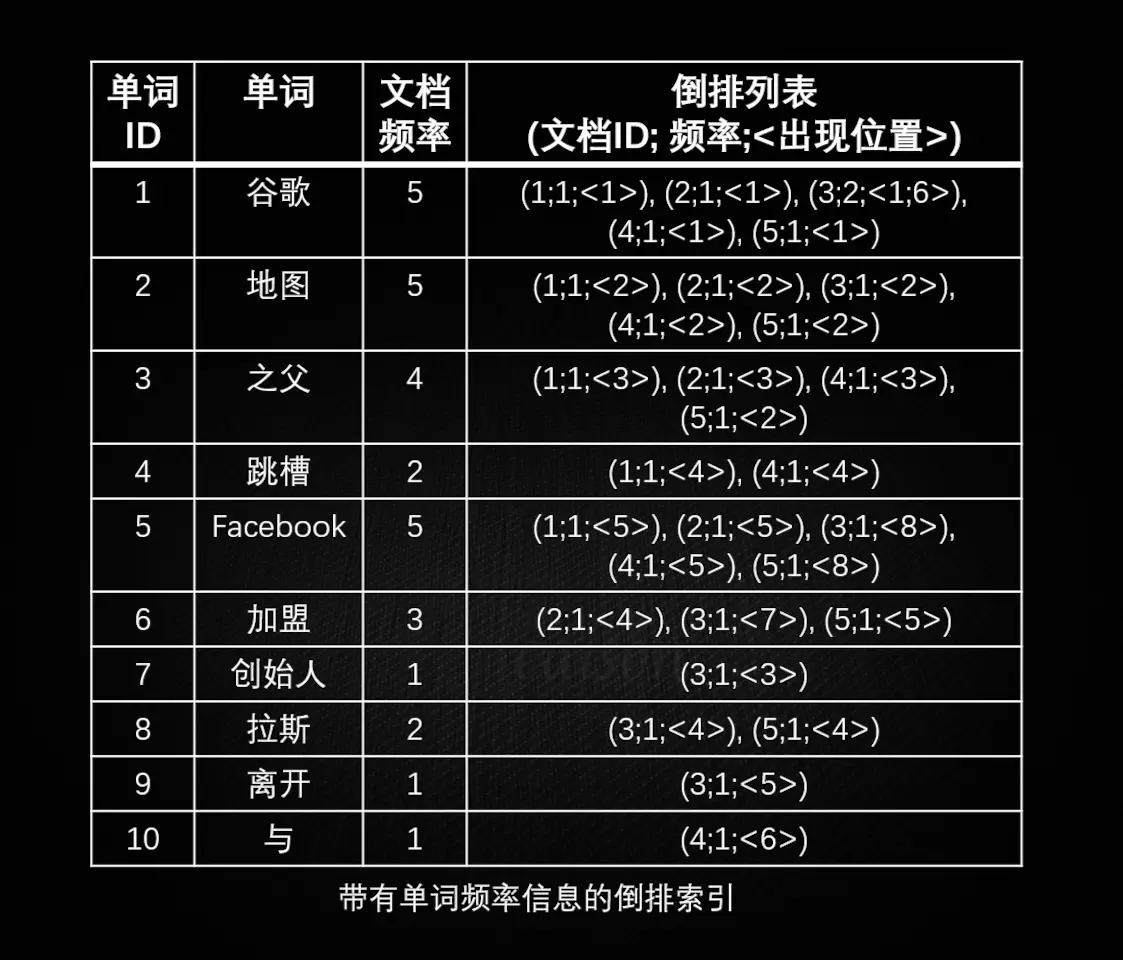
Java NIO NIO 简介 在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。也就是说,当一个线程执行一个 I/O 操作时,它会被阻塞直到操作完成。这种阻塞模型在处理多个并发连接时可能会导致性能瓶颈,因为需要为每个连接创建一个线程,而线程的创建和切换都是有开销的。
为了解决此问题,在 Java 1.4 中引入了非阻塞的 I/O 模型——NIO(New IO,也称为 Non-blocking IO)。NIO 对应 java.nio 包,提供了 Channel 、Selector、Buffer 等抽象。它支持面向缓冲的,基于通道的 I/O 操作方法。
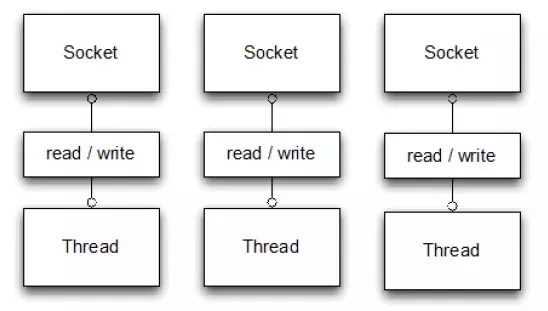
NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
注意:使用 NIO 并不一定意味着高性能,它的性能优势主要体现在高并发和高延迟的网络环境下。当连接数较少、并发程度较低或者网络传输速度较快时,NIO 的性能并不一定优于传统的 BIO 。
NIO 的基本流程 通常来说 NIO 中的所有 IO 都是从 Channel(通道) 开始的。
从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
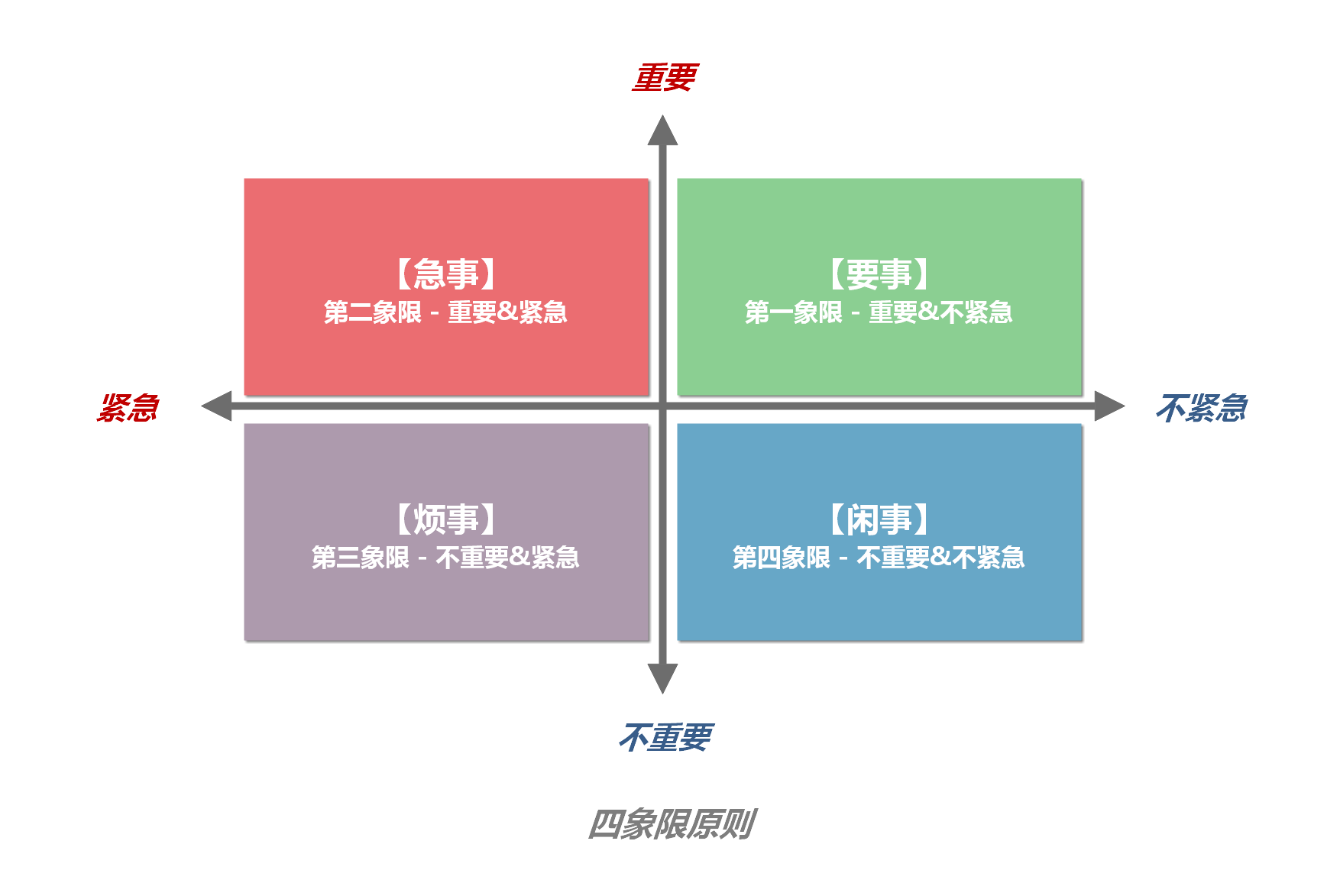
NIO 核心组件 NIO 包含下面几个核心的组件:
Channel(通道) - Channel 是一个双向的、可读可写的数据传输通道,NIO 通过 Channel 来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。Buffer(缓冲区) - NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。Selector(选择器) - 允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到 Selector 上,由 Selector 来分配线程来处理事件。
Channel(通道) 通道(Channel)是对 BIO 中的流的模拟,可以通过它读写数据。
Channel,类似在 Linux 之类操作系统上看到的文件描述符,是 NIO 中被用来支持批量式 IO 操作的一种抽象。
File 或者 Socket,通常被认为是比较高层次的抽象,而 Channel 则是更加操作系统底层的一种抽象,这也使得 NIO 得以充分利用现代操作系统底层机制,获得特定场景的性能优化,例如,DMA(Direct Memory Access)等。不同层次的抽象是相互关联的,我们可以通过 Socket 获取 Channel,反之亦然。
通道与流的不同之处在于:
流是单向的 - 一个流只能单纯的负责读或写。通道是双向的 - 一个通道可以同时用于读写。
通道包括以下类型:
FileChannel:从文件中读写数据;DatagramChannel:通过 UDP 读写网络中数据;SocketChannel:通过 TCP 读写网络中数据;ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
Buffer(缓冲区) **BIO 面向流 (Stream oriented),而 NIO 面向缓冲区 (Buffer oriented)**。
在 NIO 中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读缓冲区中的数据;在写入数据时,写入到缓冲区中。任何时候访问 NIO 中的数据,都是通过缓冲区进行操作。
向 Channel 读写的数据都必须先置于缓冲区中 。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
BIO 和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
事实上,每一种 Java 基本类型(除了 Boolean 类型)都对应有一种缓冲区:
ByteBufferCharBufferShortBufferIntBufferLongBufferFloatBufferDoubleBuffer
缓冲区状态变量
capacity:最大容量;position:当前已经读写的字节数;limit:还可以读写的字节数。mark:记录上一次 postion 的位置,默认是 0,算是一个便利性的考虑,往往不是必须
缓冲区状态变量的改变过程举例:
新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 移动设置为 5,limit 保持不变。
在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
文件 NIO 示例 以下展示了使用 NIO 快速复制文件的实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public static void fastCopy (String src, String dist) throws IOException { FileInputStream fin = new FileInputStream (src); FileChannel fcin = fin.getChannel(); FileOutputStream fout = new FileOutputStream (dist); FileChannel fcout = fout.getChannel(); ByteBuffer buffer = ByteBuffer.allocateDirect(1024 ); while (true ) { int r = fcin.read(buffer); if (r == -1 ) { break ; } buffer.flip(); fcout.write(buffer); buffer.clear(); } }
DirectBuffer NIO 还提供了一个可以直接访问物理内存的类 DirectBuffer。普通的 Buffer 分配的是 JVM 堆内存,而 DirectBuffer 是直接分配物理内存。
数据要输出到外部设备,必须先从用户空间复制到内核空间,再复制到输出设备,而 DirectBuffer 则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
这里拓展一点,由于 DirectBuffer 申请的是非 JVM 的物理内存,所以创建和销毁的代价很高。DirectBuffer 申请的内存并不是直接由 JVM 负责垃圾回收,但在 DirectBuffer 包装类被回收时,会通过 Java 引用机制来释放该内存块。
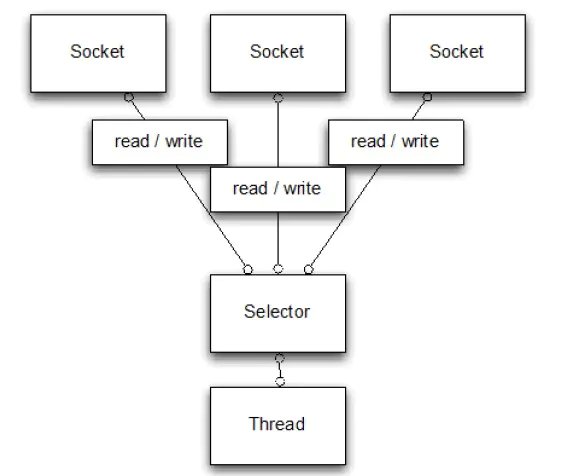
Selector(选择器) NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
Selector 是 Java NIO 编程的基础。用于检查一个或多个 NIO Channel 的状态是否处于可读、可写。
NIO 实现了 IO 多路复用中的 Reactor 模型 :
一个线程(Thread)使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件(accpet、read) ,如果某个 Channel 上面发生监听事件,这个 Channel 就处于就绪状态,然后进行 I/O 操作。
通过配置监听的通道 Channel 为非阻塞 ,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件 而不是一个线程处理一个事件具有更好的性能。
需要注意的是,只有 SocketChannel 才能配置为非阻塞,而 FileChannel 不能,因为 FileChannel 配置非阻塞也没有意义。
目前操作系统的 I/O 多路复用机制都使用了 epoll,相比传统的 select 机制,epoll 没有最大连接句柄 1024 的限制。所以 Selector 在理论上可以轮询成千上万的客户端。
创建选择器 1 Selector selector = Selector.open();
将通道注册到选择器上 1 2 3 ServerSocketChannel ssChannel = ServerSocketChannel.open();ssChannel.configureBlocking(false ); ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
SelectionKey.OP_CONNECTSelectionKey.OP_ACCEPTSelectionKey.OP_READSelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
1 2 3 4 public static final int OP_READ = 1 << 0 ;public static final int OP_WRITE = 1 << 2 ;public static final int OP_CONNECT = 1 << 3 ;public static final int OP_ACCEPT = 1 << 4 ;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
1 int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
监听事件 1 int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
获取到达的事件 1 2 3 4 5 6 7 8 9 10 11 Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> keyIterator = keys.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { } else if (key.isReadable()) { } keyIterator.remove(); }
事件循环 因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 while (true ) { int num = selector.select(); Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> keyIterator = keys.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { } else if (key.isReadable()) { } keyIterator.remove(); } }
套接字 NIO 示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 public class NIOServer { public static void main (String[] args) throws IOException { Selector selector = Selector.open(); ServerSocketChannel ssChannel = ServerSocketChannel.open(); ssChannel.configureBlocking(false ); ssChannel.register(selector, SelectionKey.OP_ACCEPT); ServerSocket serverSocket = ssChannel.socket(); InetSocketAddress address = new InetSocketAddress ("127.0.0.1" , 8888 ); serverSocket.bind(address); while (true ) { selector.select(); Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> keyIterator = keys.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel(); SocketChannel sChannel = ssChannel1.accept(); sChannel.configureBlocking(false ); sChannel.register(selector, SelectionKey.OP_READ); } else if (key.isReadable()) { SocketChannel sChannel = (SocketChannel) key.channel(); System.out.println(readDataFromSocketChannel(sChannel)); sChannel.close(); } keyIterator.remove(); } } } private static String readDataFromSocketChannel (SocketChannel sChannel) throws IOException { ByteBuffer buffer = ByteBuffer.allocate(1024 ); StringBuilder data = new StringBuilder (); while (true ) { buffer.clear(); int n = sChannel.read(buffer); if (n == -1 ) { break ; } buffer.flip(); int limit = buffer.limit(); char [] dst = new char [limit]; for (int i = 0 ; i < limit; i++) { dst[i] = (char ) buffer.get(i); } data.append(dst); buffer.clear(); } return data.toString(); } }
1 2 3 4 5 6 7 8 9 10 public class NIOClient { public static void main (String[] args) throws IOException { Socket socket = new Socket ("127.0.0.1" , 8888 ); OutputStream out = socket.getOutputStream(); String s = "hello world" ; out.write(s.getBytes()); out.close(); } }
内存映射文件 内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
1 MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0 , 1024 );
NIO vs. BIO BIO 与 NIO 最重要的区别是数据打包和传输的方式。**BIO 面向流 (Stream oriented),而 NIO 面向缓冲区 (Buffer oriented)**。
面向流的 BIO 一次处理一个字节数据 :一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。面向块的 NIO 一次处理一个数据块 ,按块处理数据比按流处理数据要快得多。但是面向块的 NIO 缺少一些面向流的 BIO 所具有的优雅性和简单性。
BIO 模式:
NIO 模式:
参考资料