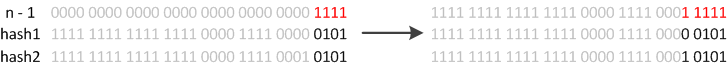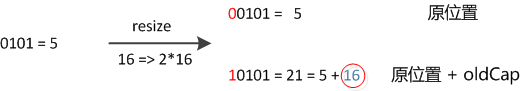graph LR A[Hard edge] -->|Link text| B(Round edge) B --> C{Decision} C -->|One| D[Result one] C -->|Two| E[Result two]
时序图
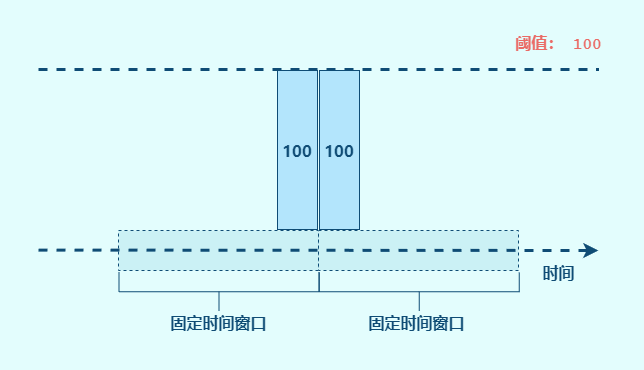
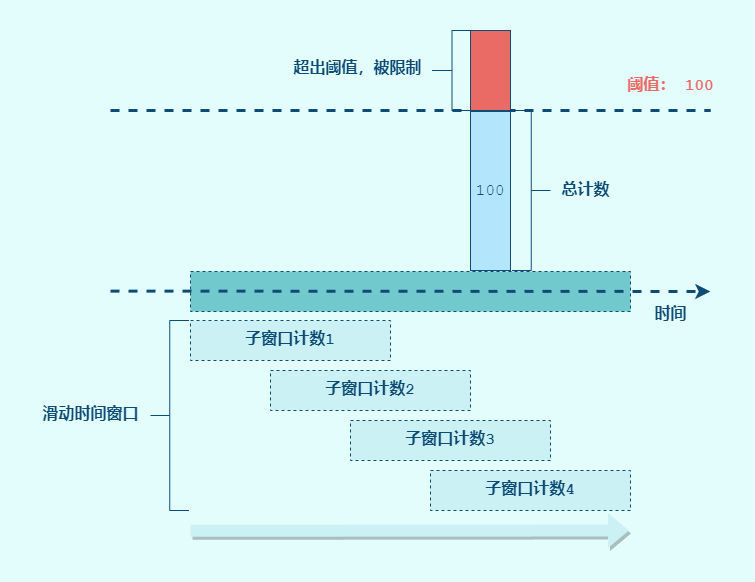
1 2 3 4 5 6 7 8 9 10
sequenceDiagram Alice->>Bob: Hello Bob, how are you? alt is sick Bob->>Alice: Not so good :( else is well Bob->>Alice: Feeling fresh like a daisy end opt Extra response Bob->>Alice: Thanks for asking end
gantt dateFormat YYYY-MM-DD title Adding GANTT diagram functionality to mermaid
section A section Completed task :done, des1, 2014-01-06,2014-01-08 Active task :active, des2, 2014-01-09, 3d Future task : des3, after des2, 5d Future task2 : des4, after des3, 5d
section Critical tasks Completed task in the critical line :crit, done, 2014-01-06,24h Implement parser and jison :crit, done, after des1, 2d Create tests for parser :crit, active, 3d Future task in critical line :crit, 5d Create tests for renderer :2d Add to mermaid :1d
section Documentation Describe gantt syntax :active, a1, after des1, 3d Add gantt diagram to demo page :after a1 , 20h Add another diagram to demo page :doc1, after a1 , 48h
section Last section Describe gantt syntax :after doc1, 3d Add gantt diagram to demo page :20h Add another diagram to demo page :48h
@Override publicvoidonNext(HealthCounts hc) { // check if we are past the statisticalWindowVolumeThreshold if (hc.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) { // we are not past the minimum volume threshold for the stat window, // so no change to circuit status. // if it was CLOSED, it stays CLOSED // if it was half-open, we need to wait for a successful command execution // if it was open, we need to wait for sleep window to elapse } else { if (hc.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) { //we are not past the minimum error threshold for the stat window, // so no change to circuit status. // if it was CLOSED, it stays CLOSED // if it was half-open, we need to wait for a successful command execution // if it was open, we need to wait for sleep window to elapse } else { // our failure rate is too high, we need to set the state to OPEN if (status.compareAndSet(Status.CLOSED, Status.OPEN)) { circuitOpened.set(System.currentTimeMillis()); } } } }
限流框架 - Sentinel
其他限流解决方案
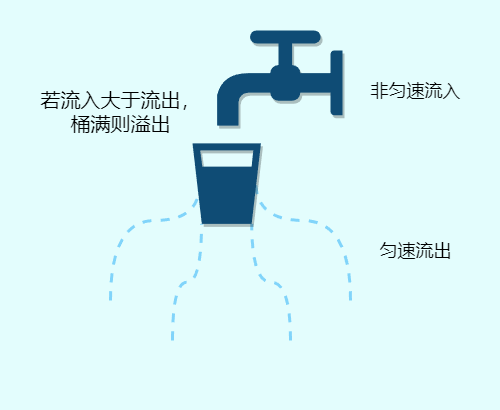
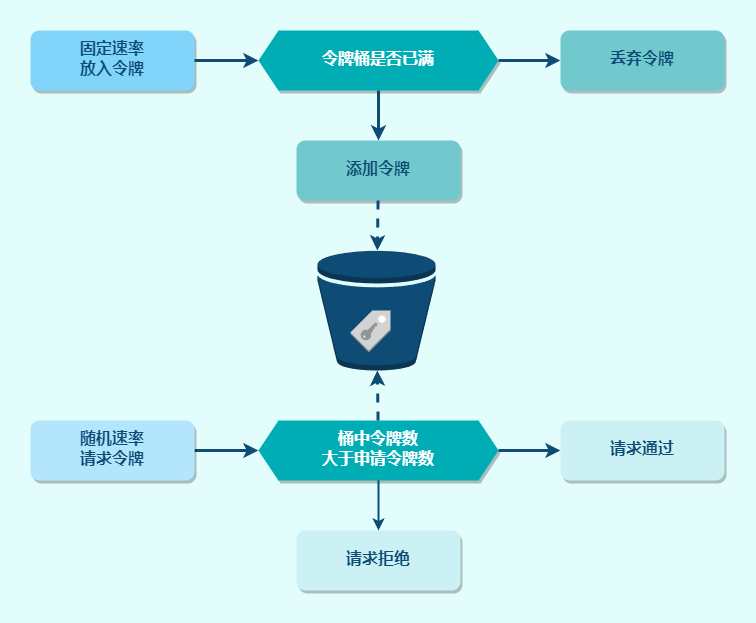
Guava RateLimiter
Guava 是 Google 开源的 Java 类库,提供了一个工具类 RateLimiter,它基于令牌桶算法实现了本地限流器。
-- 申请令牌数 local permits = tonumber(ARGV[1]) -- QPS local qps = tonumber(ARGV[2]) -- 桶的容量 local capacity = tonumber(ARGV[3]) -- 当前时间(单位:毫秒) local nowMillis = tonumber(ARGV[4]) -- 填满令牌桶所需要的时间 local fillTime = capacity / qps local ttl = math.min(capacity, math.floor(fillTime * 2))
local currentTokenNum = tonumber(redis.call("GET", tokenKey)) if currentTokenNum == nilthen currentTokenNum = capacity end
local endTimeMillis = tonumber(redis.call("GET", timeKey)) if endTimeMillis == nilthen endTimeMillis = 0 end
local gap = nowMillis - endTimeMillis local newTokenNum = math.max(0, gap * qps / 1000) local currentTokenNum = math.min(capacity, currentTokenNum + newTokenNum)
if currentTokenNum < permits then -- 请求拒绝 return-1 else -- 请求通过 local finalTokenNum = currentTokenNum - permits redis.call("SETEX", tokenKey, ttl, finalTokenNum) redis.call("SETEX", timeKey, ttl, nowMillis) return finalTokenNum end
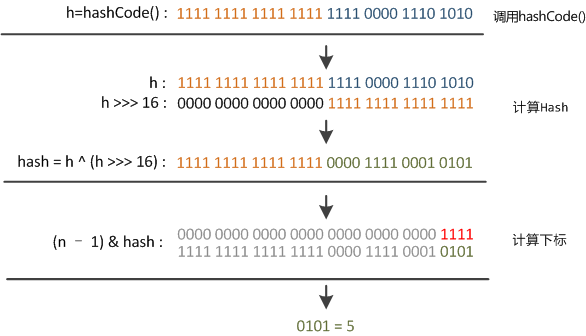
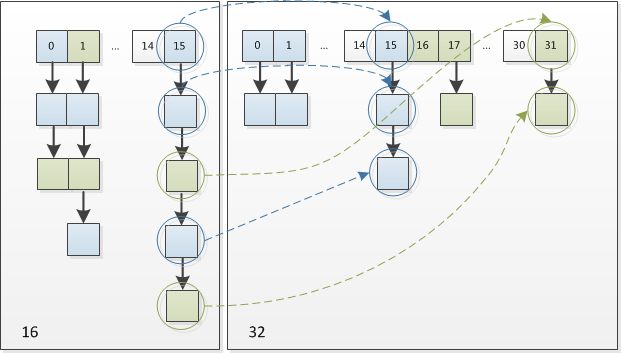
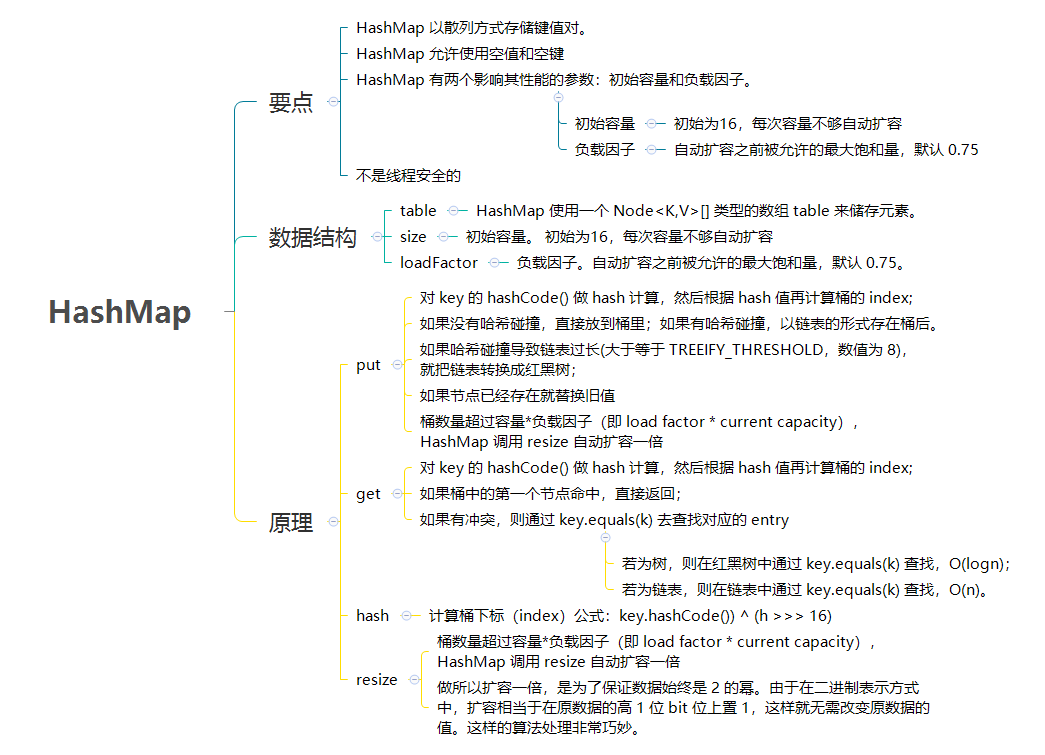
如果还是产生了频繁的碰撞,会发生什么问题呢?作者注释说,他们使用树来处理频繁的碰撞(we use trees to handle large sets of collisions in bins),在 JEP-180 中,描述了这个问题:
Improve the performance of java.util.HashMap under high hash-collision conditions by using balanced trees rather than linked lists to store map entries. Implement the same improvement in the LinkedHashMap class.
之前已经提过,在获取 HashMap 的元素时,基本分两步:
首先根据 hashCode() 做 hash,然后确定 bucket 的 index;
如果 bucket 的节点的 key 不是我们需要的,则通过 keys.equals()在链中找。
在 JDK8 之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行 get 时,两步的时间复杂度是 O(1)+O(n)。因此,当碰撞很厉害的时候 n 很大,O(n)的速度显然是影响速度的。
因此在 JDK8 中,利用红黑树替换链表,这样复杂度就变成了 O(1)+O(logn)了,这样在 n 很大的时候,能够比较理想的解决这个问题,在 JDK8:HashMap 的性能提升一文中有性能测试的结果。
public V get(Object key) { Entry<K,V> p = getEntry(key); return (p==null ? null : p.value); }
final Entry<K,V> getEntry(Object key) { // Offload comparator-based version for sake of performance if (comparator != null) return getEntryUsingComparator(key); if (key == null) thrownewNullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; Entry<K,V> p = root; // 按照二叉树搜索的方式进行搜索,搜到返回 while (p != null) { intcmp= k.compareTo(p.key); if (cmp < 0) p = p.left; elseif (cmp > 0) p = p.right; else return p; } returnnull; }
// 如果当前节点有左右孩子节点,使用后继节点替换要删除的节点 // If strictly internal, copy successor's element to p and then make p // point to successor. if (p.left != null && p.right != null) { Entry<K,V> s = successor(p); p.key = s.key; p.value = s.value; p = s; } // p has 2 children
// Start fixup at replacement node, if it exists. Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) { // 要删除的节点有一个孩子节点 // Link replacement to parent replacement.parent = p.parent; if (p.parent == null) root = replacement; elseif (p == p.parent.left) p.parent.left = replacement; else p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion. p.left = p.right = p.parent = null;
// Fix replacement if (p.color == BLACK) fixAfterDeletion(replacement); } elseif (p.parent == null) { // return if we are the only node. root = null; } else { // No children. Use self as phantom replacement and unlink. if (p.color == BLACK) fixAfterDeletion(p);
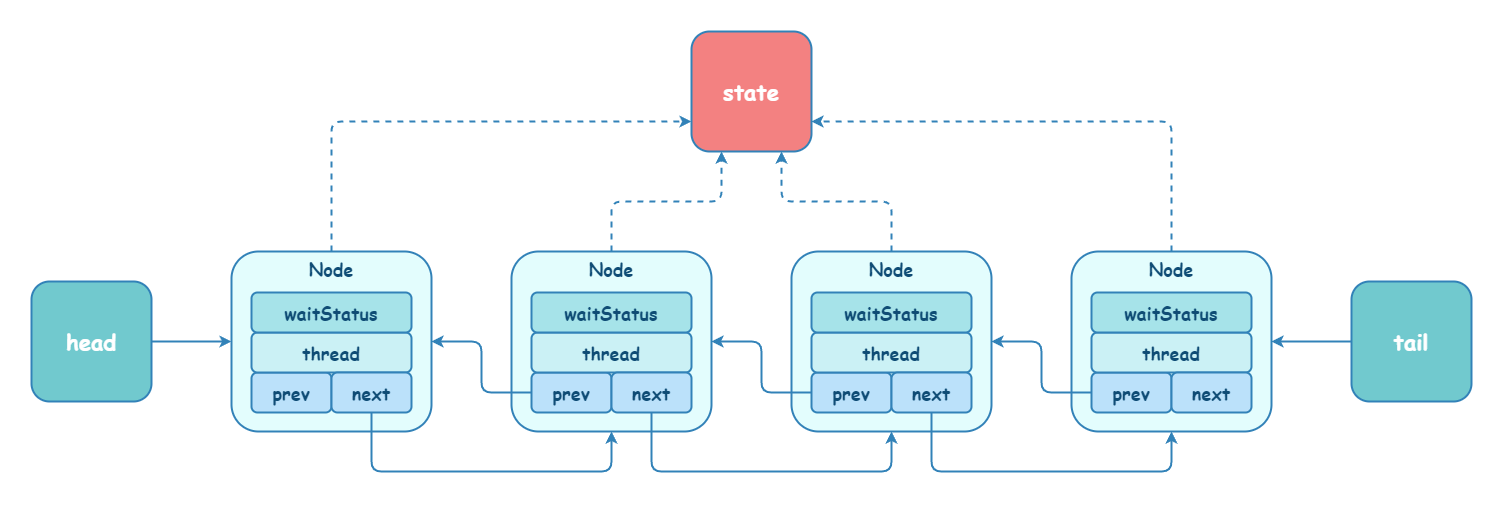
intws= node.waitStatus; if (ws < 0) compareAndSetWaitStatus(node, ws, 0);
Nodes= node.next; if (s == null || s.waitStatus > 0) { s = null; for (Nodet= tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } if (s != null) LockSupport.unpark(s.thread); }
能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
Unsafe 类提供了 compareAndSwapObject、compareAndSwapInt、compareAndSwapLong方法来实现的对 Object、int、long 类型的 CAS 操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/** * 以原子方式更新对象字段的值。 */ booleancompareAndSwapObject(Object o, long offset, Object expected, Object x);
/** * 以原子方式更新 int 类型的对象字段的值。 */ booleancompareAndSwapInt(Object o, long offset, int expected, int x);
/** * 以原子方式更新 long 类型的对象字段的值。 */ booleancompareAndSwapLong(Object o, long offset, long expected, long x);
Unsafe 类中的 CAS 方法是 native 方法。native 关键字表明这些方法是用本地代码(通常是 C 或 C++)实现的,而不是用 Java 实现的。这些方法直接调用底层的、具有原子性的 CPU 指令来实现。
由于 CAS 操作可能会因为并发冲突而失败,因此通常会伴随着自旋,而所谓自旋,其实就是循环尝试。
Unsafe#getAndAddInt 源码:
1 2 3 4 5 6 7 8 9 10
// 原子地获取并增加整数值 publicfinalintgetAndAddInt(Object o, long offset, int delta) { int v; do { // 以 volatile 方式获取对象 o 在内存偏移量 offset 处的整数值 v = getIntVolatile(o, offset); } while (!compareAndSwapInt(o, offset, v, v + delta)); // 返回旧值 return v; }
CAS 的问题
一般情况下,CAS 比锁性能更高。因为 CAS 是一种非阻塞算法,所以其避免了线程阻塞和唤醒的等待时间。但是,事物总会有利有弊,CAS 也存在三大问题:
ABA 问题
循环时间长开销大
只能保证一个共享变量的原子性
ABA 问题
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过,这就是 ABA 问题。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
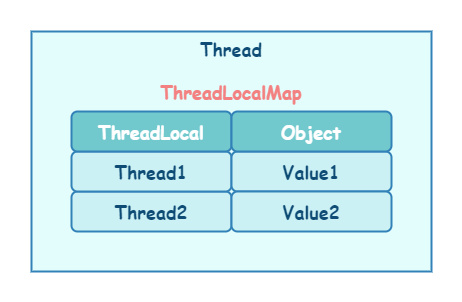
staticclassThreadLocalMap { // ... staticclassEntryextendsWeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value;
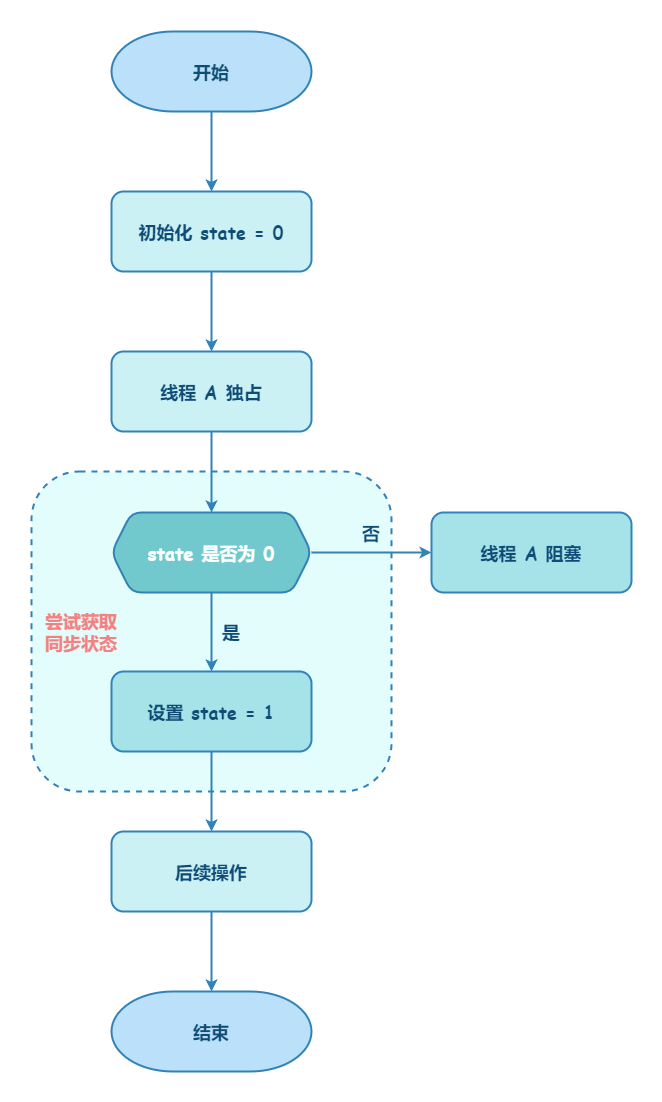
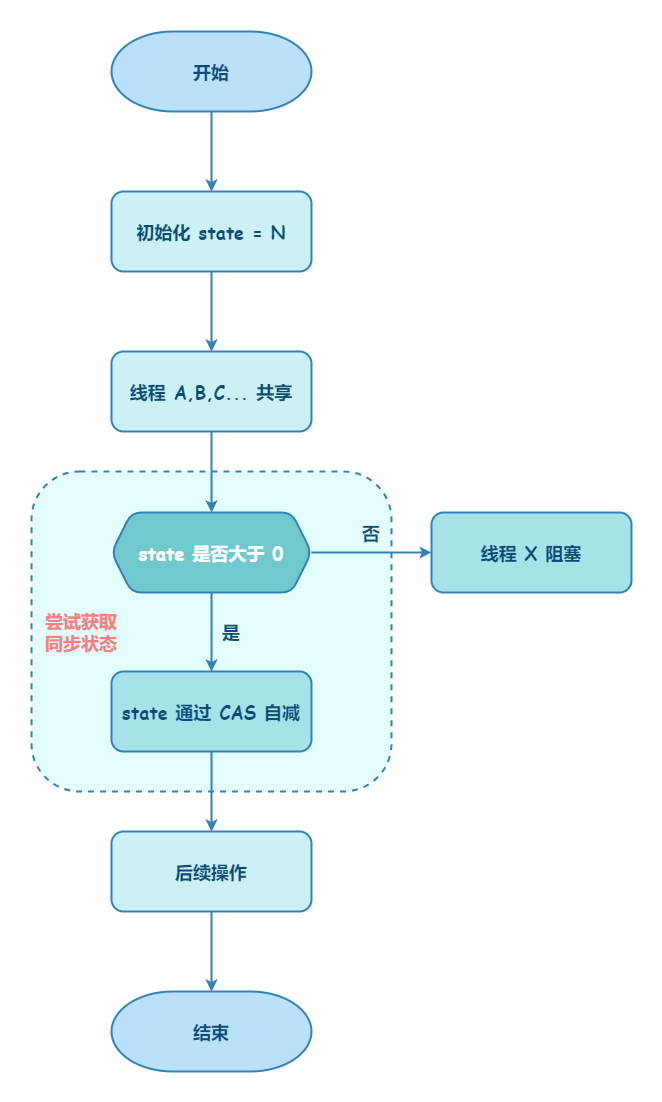
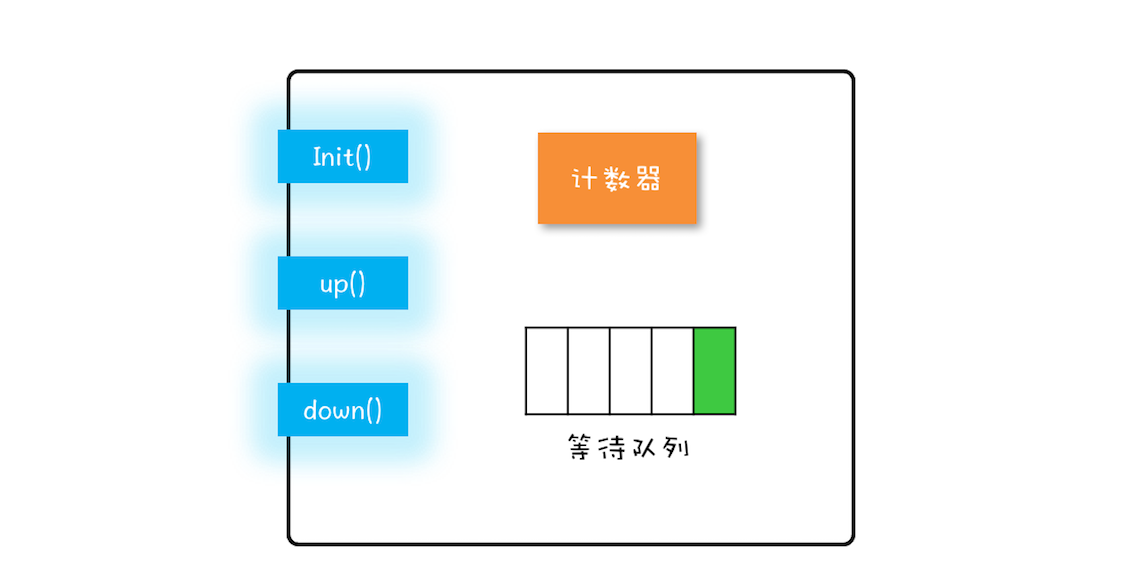
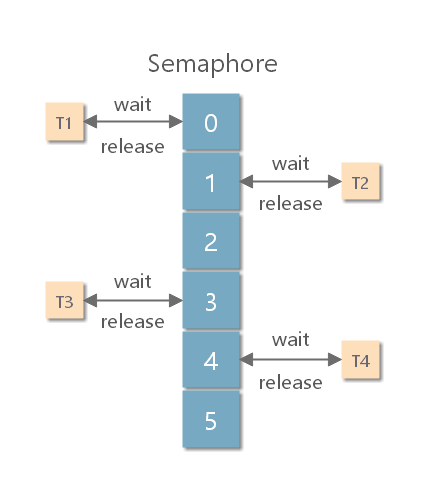
Semaphore 是共享锁的一种实现,它默认构造 AQS 的 state 值为 permits,你可以将 permits 的值理解为许可证的数量,只有拿到许可证的线程才能执行。
调用semaphore.acquire() ,线程尝试获取许可证,如果 state >= 0 的话,则表示可以获取成功。如果获取成功的话,使用 CAS 操作去修改 state 的值 state=state-1。如果 state<0 的话,则表示许可证数量不足。此时会创建一个 Node 节点加入阻塞队列,挂起当前线程。
调用semaphore.release(); ,线程尝试释放许可证,并使用 CAS 操作去修改 state 的值 state=state+1。释放许可证成功之后,同时会唤醒同步队列中的一个线程。被唤醒的线程会重新尝试去修改 state 的值 state=state-1 ,如果 state>=0 则获取令牌成功,否则重新进入阻塞队列,挂起线程。