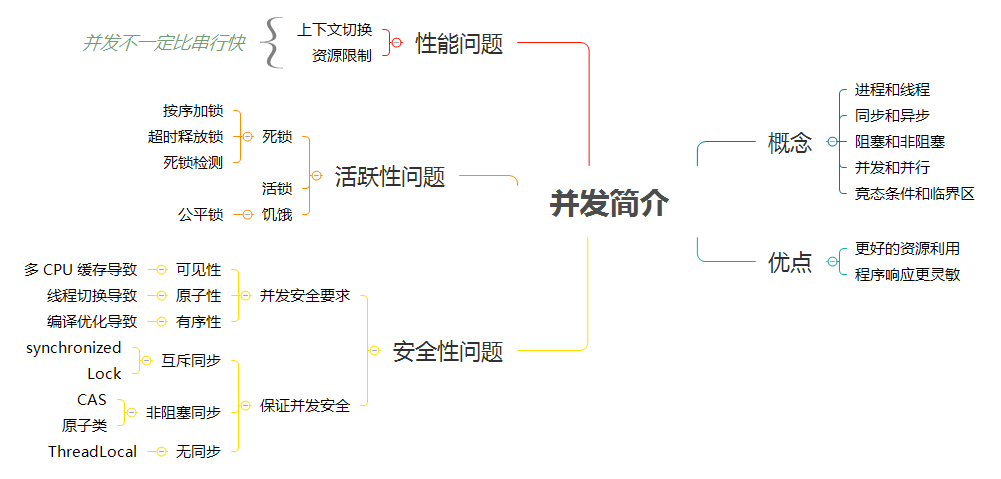
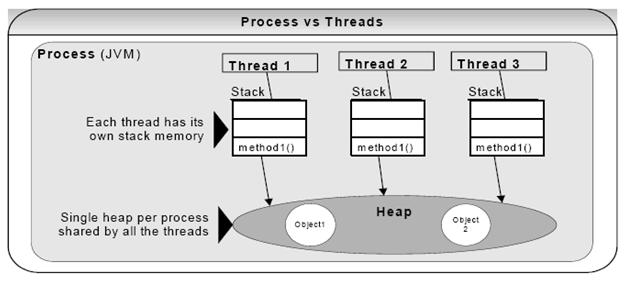
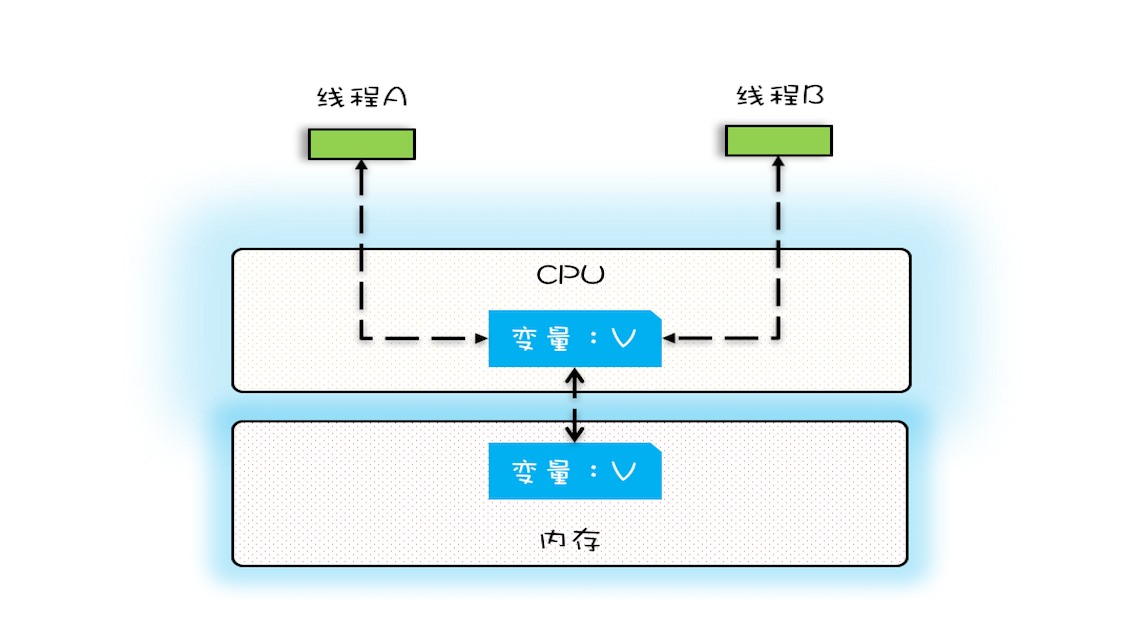
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。
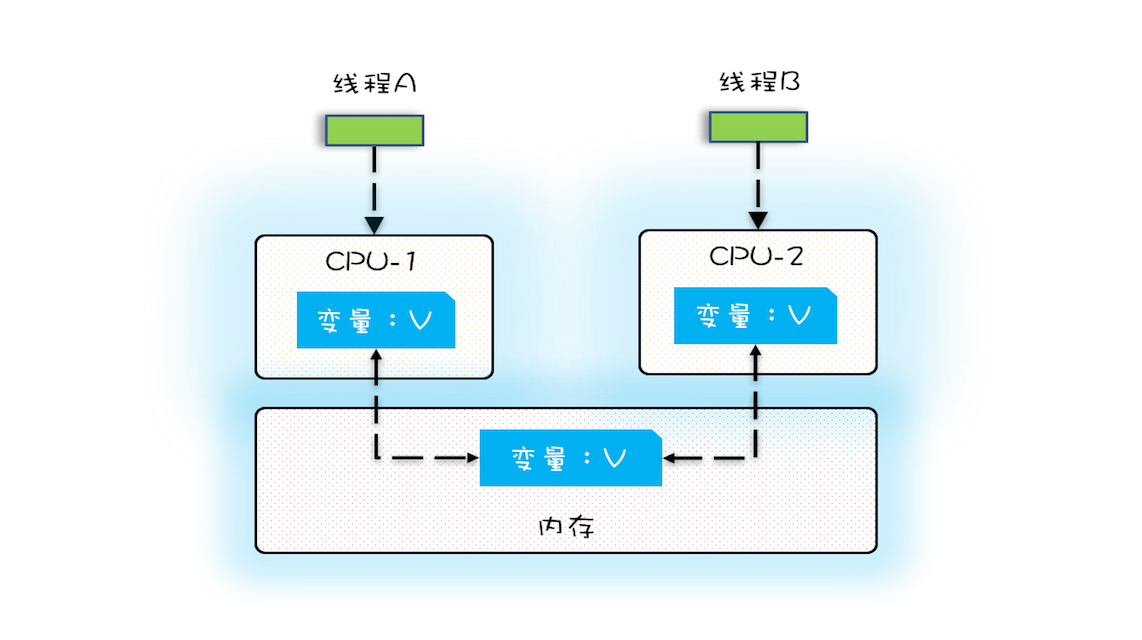
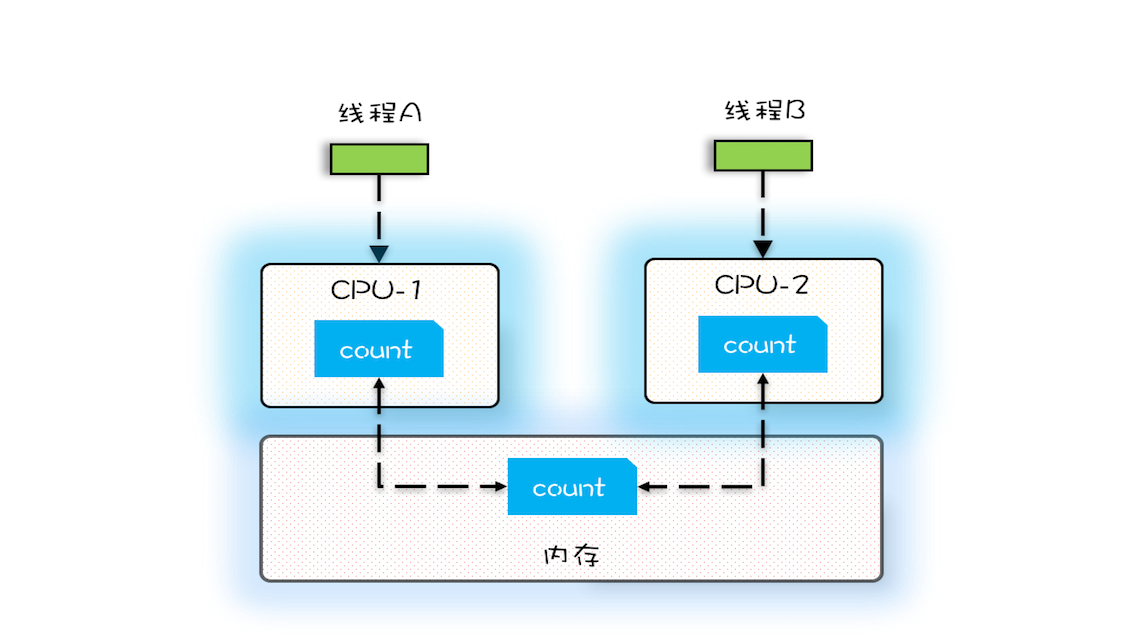
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
我们假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异 Bug 的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的 count += 1,至少需要三条 CPU 指令。
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
指令 2:之后,在寄存器中执行 +1 操作;
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
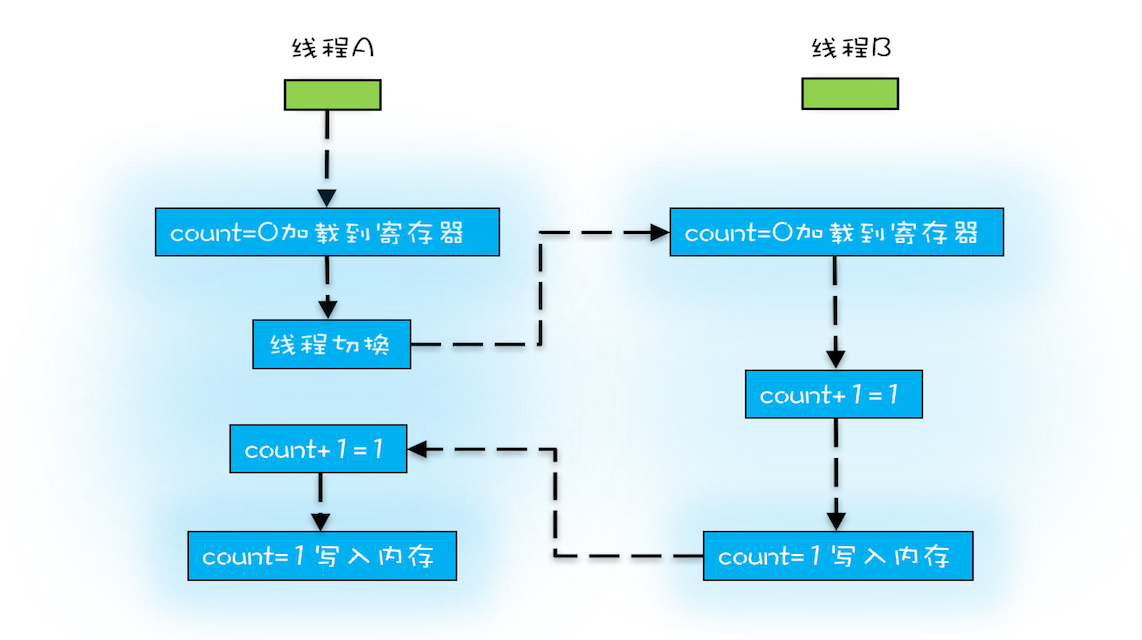
操作系统做任务切换,可以发生在任何一条CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
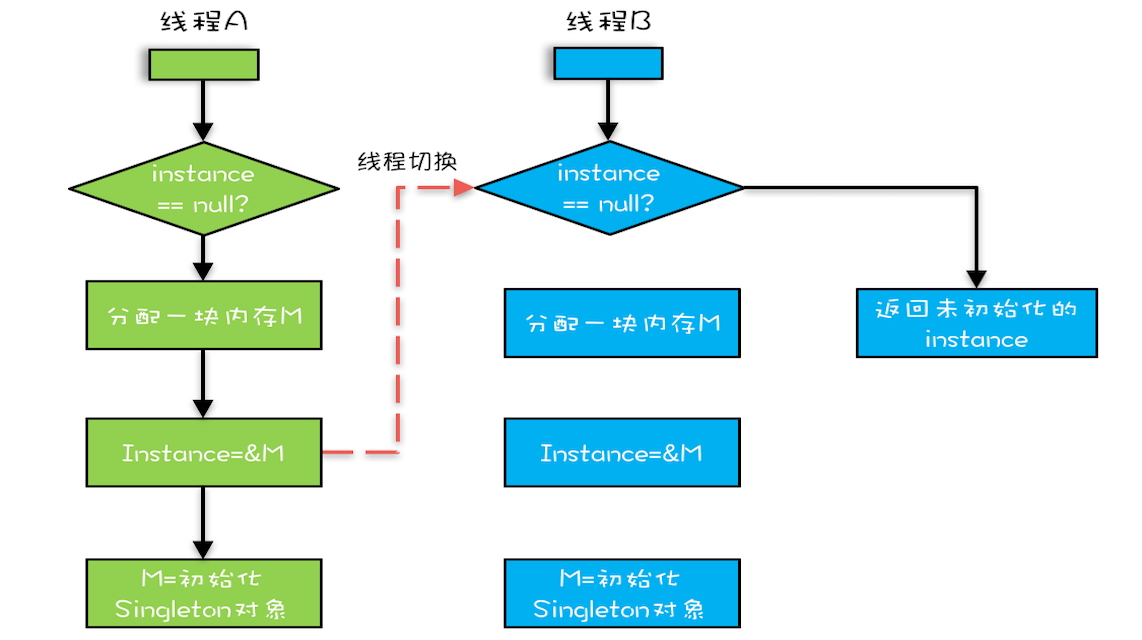
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
Integera=127; //Integer.valueOf(127) Integerb=127; //Integer.valueOf(127) log.info("\nInteger a = 127;\nInteger b = 127;\na == b ? {}", a == b); // true
Integerc=128; //Integer.valueOf(128) Integerd=128; //Integer.valueOf(128) log.info("\nInteger c = 128;\nInteger d = 128;\nc == d ? {}", c == d); //false //设置-XX:AutoBoxCacheMax=1000再试试
Integere=127; //Integer.valueOf(127) Integerf=newInteger(127); //new instance log.info("\nInteger e = 127;\nInteger f = new Integer(127);\ne == f ? {}", e == f); //false
Integerg=newInteger(127); //new instance Integerh=newInteger(127); //new instance log.info("\nInteger g = new Integer(127);\nInteger h = new Integer(127);\ng == h ? {}", g == h); //false
Integeri=128; //unbox intj=128; log.info("\nInteger i = 128;\nint j = 128;\ni == j ? {}", i == j); //true
Integera=127; //Integer.valueOf(127) Integerb=127; //Integer.valueOf(127) log.info("\nInteger a = 127;\nInteger b = 127;\na == b ? {}", a == b); // true
Integerc=128; //Integer.valueOf(128) Integerd=128; //Integer.valueOf(128) log.info("\nInteger c = 128;\nInteger d = 128;\nc == d ? {}", c == d); //false //设置-XX:AutoBoxCacheMax=1000再试试
Integere=127; //Integer.valueOf(127) Integerf=newInteger(127); //new instance log.info("\nInteger e = 127;\nInteger f = new Integer(127);\ne == f ? {}", e == f); //false
Integerg=newInteger(127); //new instance Integerh=newInteger(127); //new instance log.info("\nInteger g = new Integer(127);\nInteger h = new Integer(127);\ng == h ? {}", g == h); //false
Integeri=128; //unbox intj=128; log.info("\nInteger i = 128;\nint j = 128;\ni == j ? {}", i == j); //true
static { // high value may be configured by property inth=127; StringintegerCacheHighPropValue= sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { inti= parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h;
Stringa="1"; Stringb="1"; log.info("\nString a = \"1\";\nString b = \"1\";\na == b ? {}", a == b); //true
Stringc=newString("2"); Stringd=newString("2"); log.info("\nString c = new String(\"2\");\nString d = new String(\"2\");\nc == d ? {}", c == d); //false
Stringe=newString("3").intern(); Stringf=newString("3").intern(); log.info("\nString e = new String(\"3\").intern();\nString f = new String(\"3\").intern();\ne == f ? {}", e == f); //true
Stringg=newString("4"); Stringh=newString("4"); log.info("\nString g = new String(\"4\");\nString h = new String(\"4\");\ng == h ? {}", g.equals(h)); //true
===========PrintallColor=========== RED ordinal:0 GREEN ordinal:1 BLUE ordinal:2 ===========PrintallSize=========== BIG ordinal:0 MIDDLE ordinal:1 SMALL ordinal:2 greenname():GREEN greengetDeclaringClass():classorg.zp.javase.enumeration.EnumDemo$Color greenhashCode():460141958 green compareTo Color.GREEN:0 green equals Color.GREEN:true green equals Size.MIDDLE:false green equals 1:false green==Color.BLUE:false
枚举的特性
枚举的特性,归结起来就是一句话:
除了不能继承,基本上可以将 enum 看做一个常规的类。
但是这句话需要拆分去理解,让我们细细道来。
基本特性
如果枚举中没有定义方法,也可以在最后一个实例后面加逗号、分号或什么都不加。
如果枚举中没有定义方法,枚举值默认为从 0 开始的有序数值。以 Color 枚举类型举例,它的枚举常量依次为 RED:0,GREEN:1,BLUE:2。
Exception in thread "main" java.lang.ArithmeticException: / by zero at io.github.dunwu.javacore.exception.RumtimeExceptionDemo01.main(RumtimeExceptionDemo01.java:6)
Exception in thread "main" io.github.dunwu.javacore.exception.MyExceptionDemo$MyException: 自定义异常 at io.github.dunwu.javacore.exception.MyExceptionDemo.main(MyExceptionDemo.java:9)
// 反射获取 digits 方法成功 java.lang.NoSuchMethodException: java.lang.String.toString(int) at java.lang.Class.getMethod(Class.java:1786) at io.github.dunwu.javacore.exception.ThrowsDemo.f1(ThrowsDemo.java:12) at io.github.dunwu.javacore.exception.ThrowsDemo.f2(ThrowsDemo.java:21) at io.github.dunwu.javacore.exception.ThrowsDemo.main(ThrowsDemo.java:30)
Exception in thread "main" io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException2: 出现 MyException2 at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:29) at io.github.dunwu.javacore.exception.ExceptionChainDemo.main(ExceptionChainDemo.java:34) Caused by: io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException1: 出现 MyException1 at io.github.dunwu.javacore.exception.ExceptionChainDemo.f1(ExceptionChainDemo.java:22) at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:27) ... 1 more