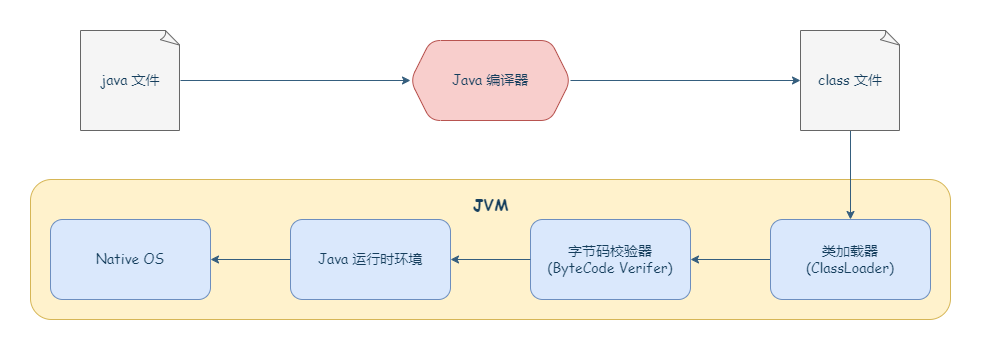
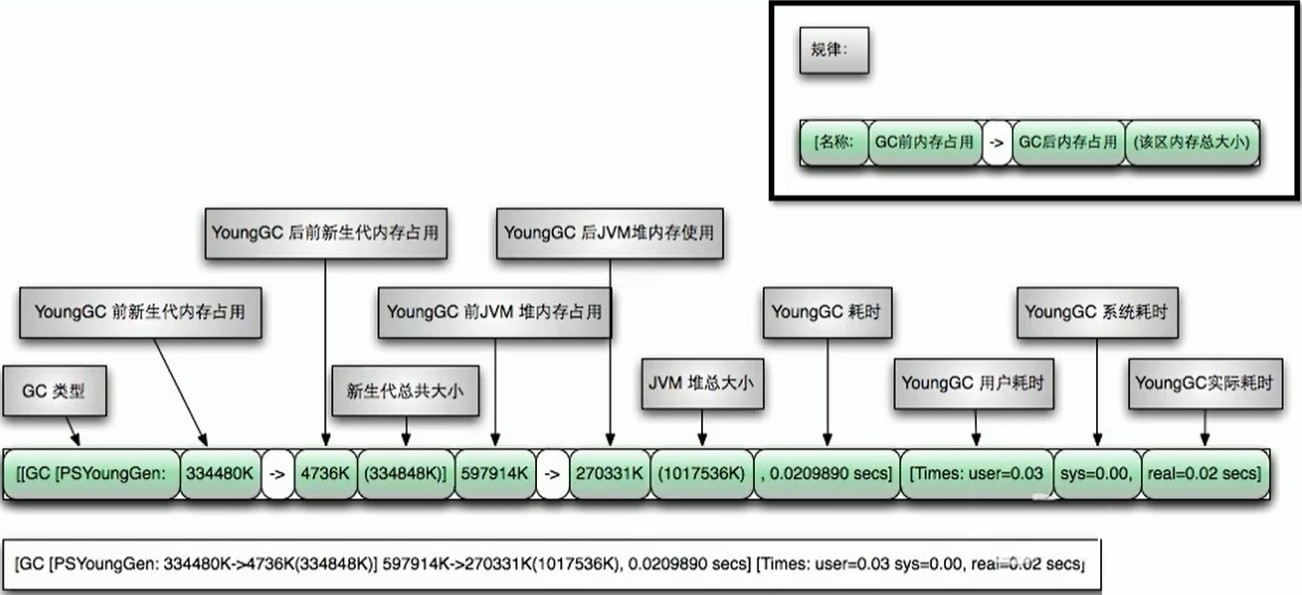
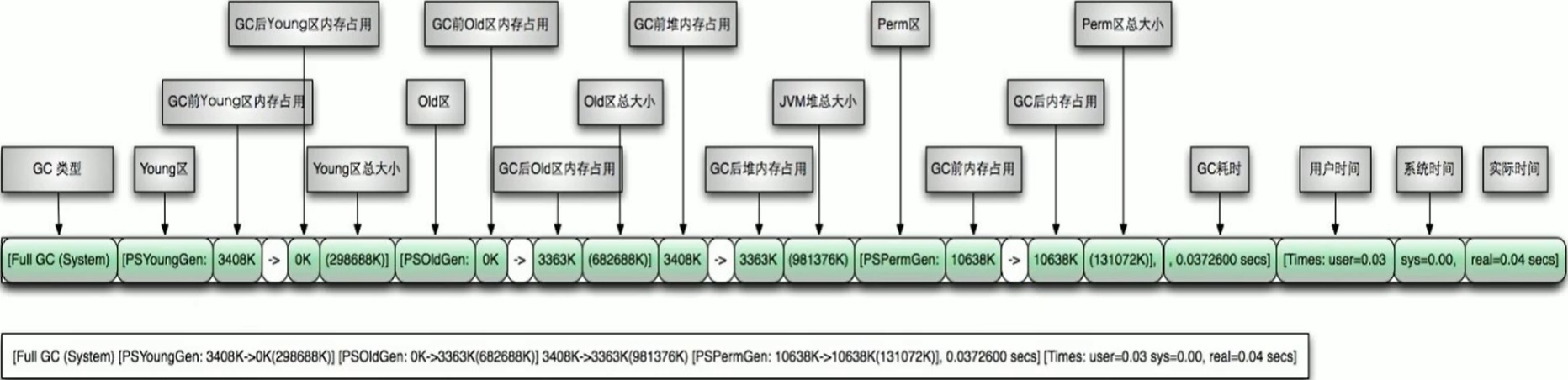
如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
降低 Full GC 的频率
Full GC 相对来说会比 Minor GC 更耗时。减少进入老年代的对象数量可以显著降低 Full GC 的频率。
减少创建大对象:如果对象占用内存过大,在 Eden 区被创建后会直接被传入老年代。在平常的业务场景中,我们习惯一次性从数据库中查询出一个大对象用于 web 端显示。例如,我之前碰到过一个一次性查询出 60 个字段的业务操作,这种大对象如果超过年轻代最大对象阈值,会被直接创建在老年代;即使被创建在了年轻代,由于年轻代的内存空间有限,通过 Minor GC 之后也会进入到老年代。这种大对象很容易产生较多的 Full GC。
jstat -gc 1262 S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT 26112.024064.06562.50.0564224.076274.5434176.0388518.3524288.042724.73206.41710.3986.815
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6800 root 20027.299g 0.021t 7172 S 54.770.1187:55.61 java 6803 root 20027.299g 0.021t 7172 S 54.470.1187:52.59 java 6798 root 20027.299g 0.021t 7172 S 53.770.1187:55.08 java 6801 root 20027.299g 0.021t 7172 S 53.770.1187:55.25 java 6797 root 20027.299g 0.021t 7172 S 53.170.1187:52.78 java 6804 root 20027.299g 0.021t 7172 S 53.170.1187:55.76 java 6802 root 20027.299g 0.021t 7172 S 52.170.1187:54.79 java 6799 root 20027.299g 0.021t 7172 S 51.870.1187:53.36 java 6807 root 20027.299g 0.021t 7172 S 13.670.148:58.60 java 11014 root 20027.299g 0.021t 7172 R 8.470.18:00.32 java 10642 root 20027.299g 0.021t 7172 R 6.570.16:32.06 java 6808 root 20027.299g 0.021t 7172 S 6.170.1159:08.40 java 11315 root 20027.299g 0.021t 7172 S 3.970.15:54.10 java 12545 root 20027.299g 0.021t 7172 S 3.970.16:55.48 java 23353 root 20027.299g 0.021t 7172 S 3.970.12:20.55 java 24868 root 20027.299g 0.021t 7172 S 3.970.12:12.46 java 9146 root 20027.299g 0.021t 7172 S 3.670.17:42.72 java
由此可以看出占用 CPU 较高的线程,但是这些还不高,无法直接定位到具体的类。nid 是 16 进制的,所以我们要获取线程的 16 进制 ID:
1
printf"%x\n"6800
1
输出结果:45cd
然后根据输出结果到 jstack 打印的堆栈日志中查定位:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
"catalina-exec-5692" daemon prio=10 tid=0x00007f3b05013800 nid=0x45cd waiting on condition [0x00007f3ae08e3000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000006a7800598> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:226) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2082) at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:86) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:32) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1068) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:745)
跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
有些读者可能并不太理解,为什么不能像获取第一页数据那样简单处理(排序取出前 10 条再合并、排序)。其实并不难理解,因为各分片节点中的数据可能是随机的,为了排序的准确性,必须把所有分片节点的前 N 页数据都排序好后做合并,最后再进行整体的排序。很显然,这样的操作是比较消耗资源的,用户越往后翻页,系统性能将会越差。
那如何解决分库情况下的分页问题呢?有以下几种办法:
如果是在前台应用提供分页,则限定用户只能看前面 n 页,这个限制在业务上也是合理的,一般看后面的分页意义不大(如果一定要看,可以要求用户缩小范围重新查询)。
insert into PERSON (ID, NAME) values (1, 'Axel'); insert into PERSON (ID, NAME) values (2, 'Mr. Foo'); insert into PERSON (ID, NAME) values (3, 'Ms. Bar');
运行 Flyway
1
flyway-5.1.4> flyway migrate
运行正常的情况下,应该可以看到如下结果:
1 2 3 4 5
Database: jdbc:h2:file:./foobardb (H2 1.4) Successfully validated 2 migrations (execution time 00:00.018s) Current version of schema "PUBLIC": 1 Migrating schema "PUBLIC" to version 2 - Add people Successfully applied 1 migration to schema "PUBLIC" (execution time 00:00.016s)
insert into PERSON (ID, NAME) values (1, 'Axel'); insert into PERSON (ID, NAME) values (2, 'Mr. Foo'); insert into PERSON (ID, NAME) values (3, 'Ms. Bar');