Mysql 将每个数据库保存为数据目录下的一个子目录。建表时,MySQL 会在数据库子目录下创建一个和表同名的 .frm 文件保存表的定义。因为 MySQL 使用文件系统的目录和文件来保存数据库和表的定义,大小写敏感性和具体的平台密切相关:在 Windows 中,大小写不敏感;在 Linux 中,大小写敏感。
如果不是按照索引的最左列开始查找,则无法使用索引。例如上面例子中的索引无法用于查找名字为 Bill 的人,也无法查找某个特定生日的人,因为这两列都不是最左数据列。类似地,也无法查找姓氏以某个字母结尾的人。
不能跳过索引中的列。也就是说,前面所述的索引无法用于查找姓为 Smith 并且在某个特定日期出生的人。如果不指定名 (first_name),则 MySQL 只能使用索引的第一列。
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。例如有查询 WHERE last_name=' Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23' ,这个查询只能使用索引的前两列,因为这里 LIKE 是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。
SELECT prod_name, prod_price FROM Products WHERE vend_id ='DLL01'OR vend_id ='BRS01' AND prod_price >=10;
任何时候使用具有 AND 和 OR 操作符的 WHERE 子句,都应该使用圆括号明确地分组操作符。
1 2 3 4
SELECT prod_name, prod_price FROM Products WHERE (vend_id ='DLL01'OR vend_id ='BRS01') AND prod_price >=10;
IN 操作符
IN 操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN 取一组由逗号分隔、括在圆括号中的合法值。
1 2 3 4
SELECT prod_name, prod_price FROM Products WHERE vend_id IN ( 'DLL01', 'BRS01' ) ORDERBY prod_name;
和下面的示例作用相同
1 2 3 4
SELECT prod_name, prod_price FROM Products WHERE vend_id ='DLL01'OR vend_id ='BRS01' ORDERBY prod_name;
为什么要使用 IN 操作符?其优点如下。
在有很多合法选项时,IN 操作符的语法更清楚,更直观。
在与其他 AND 和 OR 操作符组合使用 IN 时,求值顺序更容易管理。
IN 操作符一般比一组 OR 操作符执行得更快。
IN 的最大优点是可以包含其他 SELECT 语句,能够更动态地建立 HERE 子句。
NOT 操作符
NOT 用来否定其后条件的关键字。
检索除 DLL01 之外的所有供应商制造的产品
1 2 3 4
SELECT prod_name FROM Products WHERENOT vend_id ='DLL01' ORDERBY prod_name;
和下面的示例作用相同
1 2 3 4
SELECT prod_name FROM Products WHERE vend_id <>'DLL01' ORDERBY prod_name;
第 6 课 用通配符进行过滤
通配符(wildcard)用来匹配值的一部分的特殊字符。
搜索模式(search pattern)由字面值、通配符或两者组合构成的搜索条件。
在搜索子句中使用通配符,必须使用 LIKE 操作符。LIKE 指示 DBMS,后跟的搜索模式利用通配符匹配而不是简单的相等匹配进行比较。
百分号(%)通配符
%表示任何字符出现任意次数。
检索所有产品名以 Fish 开头的产品
1 2 3
SELECT prod_id, prod_name FROM Products WHERE prod_name LIKE'Fish%';
匹配任何位置上包含文本 bean bag 的值, 不论它之前或之后出现什么字符。
检索产品名中包含 bean bag 的产品
1 2 3
SELECT prod_id, prod_name FROM Products WHERE prod_name LIKE'%bean bag%';
检索产品名中以 F 开头,y 结尾的产品
1 2 3
SELECT prod_name FROM Products WHERE prod_name LIKE'F%y';
下划线(_)通配符
下划线(_)的用途与%一样,但它只匹配单个字符。
1 2 3
SELECT prod_id, prod_name FROM Products WHERE prod_name LIKE'__ inch teddy bear';
方括号([ ])通配符
方括号([])通配符用来指定一个字符集,它必须匹配指定位置(通配符的位置)的一个字符。
说明:并不是所有 DBMS 都支持用来创建集合的 []。只有微软的 Access 和 SQL Server 支持集合。
找出所有名字以 J 或 M 开头的联系人:
1 2 3 4
SELECT cust_contact FROM Customers WHERE cust_contact LIKE'[JM]%' ORDERBY cust_contact;
第 7 课 创建计算字段
拼接字段
拼接字符串值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- Access 和 SQL Server SELECT vend_name +' ('+ vend_country +')' FROM Vendors ORDERBY vend_name;
-- DB2、Oracle、PostgreSQL、SQLite 和 Open Office Base SELECT vend_name ||' ('|| vend_country ||')' FROM Vendors ORDERBY vend_name;
-- MySQL 或 MariaDB SELECT Concat(vend_name, ' (', vend_country, ')') FROM Vendors ORDERBY vend_name;
去除字符串中的空格
1 2 3 4 5 6 7 8 9
-- Access 和 SQL Server SELECT RTRIM(vend_name) +' ('+ RTRIM(vend_country) +')' FROM Vendors ORDERBY vend_name;
-- DB2、Oracle、PostgreSQL、SQLite 和 Open Office Base SELECT RTRIM(vend_name) ||' ('|| RTRIM(vend_country) ||')' FROM Vendors ORDERBY vend_name;
别名
使用别名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- Access 和 SQL Server SELECT RTRIM(vend_name) +' ('+ RTRIM(vend_country) +')' AS vend_title FROM Vendors ORDERBY vend_name;
-- DB2、Oracle、PostgreSQL、SQLite 和 Open Office Base SELECT RTRIM(vend_name) ||' ('|| RTRIM(vend_country) ||')' AS vend_title FROM Vendors ORDERBY vend_name;
-- MySQL 和 MariaDB SELECT Concat(vend_name, ' (', vend_country, ')') AS vend_title FROM Vendors ORDERBY vend_name;
执行算术计算
汇总物品的价格(单价乘以订购数量):
1 2 3 4 5 6
SELECT prod_id, quantity, item_price, quantity*item_price AS expanded_price FROM OrderItems WHERE order_num =20008;
第 8 课 使用函数处理数据
大多数 SQL 实现支持以下类型的函数:
算术函数
文本处理函数
时间处理函数
聚合函数
返回 DBMS 正使用的特殊信息(如返回用户登录信息)的系统函数
文本处理函数
函数
说明
LEFT()(或使用子字符串函数)
返回字符串左边的字符
LENGTH()(也使用 DATALENGTH() 或 LEN())
返回字符串的长度
LOWER()(Access 使用 LCASE())
将字符串转换为小写
LTRIM()
去掉字符串左边的空格
RIGHT()(或使用子字符串函数)
返回字符串右边的字符
RTRIM()
去掉字符串右边的空格
SOUNDEX()
返回字符串的 SOUNDEX 值
UPPER()(Access 使用 UCASE())
将字符串转换为大写
UPPER() 将文本转换为大写
1 2 3
SELECT vend_name, UPPER(vend_name) AS vend_name_upcase FROM Vendors ORDERBY vend_name;
HAVING 非常类似于 WHERE。唯一的差别是,WHERE 过滤行,而 HAVING 过滤分组。
过滤两个以上订单的分组
1 2 3 4
SELECT cust_id, COUNT(*) AS orders FROM Orders GROUPBY cust_id HAVINGCOUNT(*) >=2;
列出具有两个以上产品且其价格大于等于 4 的供应商:
1 2 3 4 5
SELECT vend_id, COUNT(*) AS num_prods FROM Products WHERE prod_price >=4 GROUPBY vend_id HAVINGCOUNT(*) >=2;
检索包含三个或更多物品的订单号和订购物品的数目:
1 2 3 4
SELECT order_num, COUNT(*) AS items FROM orderitems GROUPBY order_num HAVINGCOUNT(*) >=3;
要按订购物品的数目排序输出,需要添加 ORDER BY 子句
1 2 3 4 5
SELECT order_num, COUNT(*) AS items FROM orderitems GROUPBY order_num HAVINGCOUNT(*) >=3 ORDERBY items, order_num;
在 SELECT 语句中使用时必须遵循的次序:
1
SELECT->FROM->WHERE->GROUPBY->HAVING->ORDERBY
第 11 课 使用子查询
子查询(subquery),即嵌套在其他查询中的查询。
假如需要列出订购物品 RGAN01 的所有顾客,应该怎样检索?下面列出具体的步骤。
(1) 检索包含物品 RGAN01 的所有订单的编号。
1 2 3
SELECT order_num FROM OrderItems WHERE prod_id ='RGAN01';
输出
1 2 3 4
order_num ----------- 20007 20008
(2) 检索具有前一步骤列出的订单编号的所有顾客的 ID。
1 2 3
SELECT cust_id FROM Orders WHERE order_num IN (20007,20008);
输出
1 2 3 4
cust_id ---------- 1000000004 1000000005
(3) 检索前一步骤返回的所有顾客 ID 的顾客信息。
1 2 3
SELECT cust_name, cust_contact FROM Customers WHERE cust_id IN ('1000000004','1000000005');
现在,结合这两个查询,把第一个查询(返回订单号的那一个)变为子查询。
1 2 3 4 5
SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id ='RGAN01');
再进一步结合第三个查询
1 2 3 4 5 6 7
SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id ='RGAN01'));
SELECT vend_name, prod_name, prod_price FROM vendors INNERJOIN products ON vendors.vend_id = products.vend_id;
联结多个表
下面两个 SQL 等价:
1 2 3 4 5 6 7 8 9 10 11
SELECT cust_name, cust_contact FROM customers, orders, orderitems WHERE customers.cust_id = orders.cust_id AND orderitems.order_num = orders.order_num AND prod_id ='RGAN01';
SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id ='RGAN01'));
第 13 课 创建高级联结
自联结
给与 Jim Jones 同一公司的所有顾客发送一封信件:
1 2 3 4 5 6 7 8 9 10 11
-- 子查询方式 SELECT cust_id, cust_name, cust_contact FROM customers WHERE cust_name = (SELECT cust_name FROM customers WHERE cust_contact ='Jim Jones');
-- 自联结方式 SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM customers AS c1, customers AS c2 WHERE c1.cust_name = c2.cust_name AND c2.cust_contact ='Jim Jones';
自然联结
1 2 3
SELECT c.*, o.order_num, o.order_date, oi.prod_id, oi.quantity, oi.item_price FROM customers AS c, orders AS o, orderitems AS oi WHERE c.cust_id = o.cust_id AND oi.order_num = o.order_num AND prod_id ='RGAN01';
左外联结
1 2 3 4 5 6 7 8 9
SELECT customers.cust_id, orders.order_num FROM customers INNERJOIN orders ON customers.cust_id = orders.cust_id;
SELECT customers.cust_id, orders.order_num FROM customers LEFTOUTERJOIN orders ON customers.cust_id = orders.cust_id;
右外联结
1 2 3 4
SELECT customers.cust_id, orders.order_num FROM customers RIGHTOUTERJOIN orders ON orders.cust_id = customers.cust_id;
全外联结
1 2 3 4
SELECT customers.cust_id, orders.order_num FROM orders FULLOUTERJOIN customers ON orders.cust_id = customers.cust_id;
注意:Access、MariaDB、MySQL、Open Office Base 和 SQLite 不支持 FULLOUTER JOIN 语法。
使用带聚集函数的联结
1 2 3 4 5 6
SELECT customers.cust_id, COUNT(orders.order_num) AS num_ord FROM customers INNERJOIN orders ON customers.cust_id = orders.cust_id GROUPBY customers.cust_id;
第 14 课 组合查询
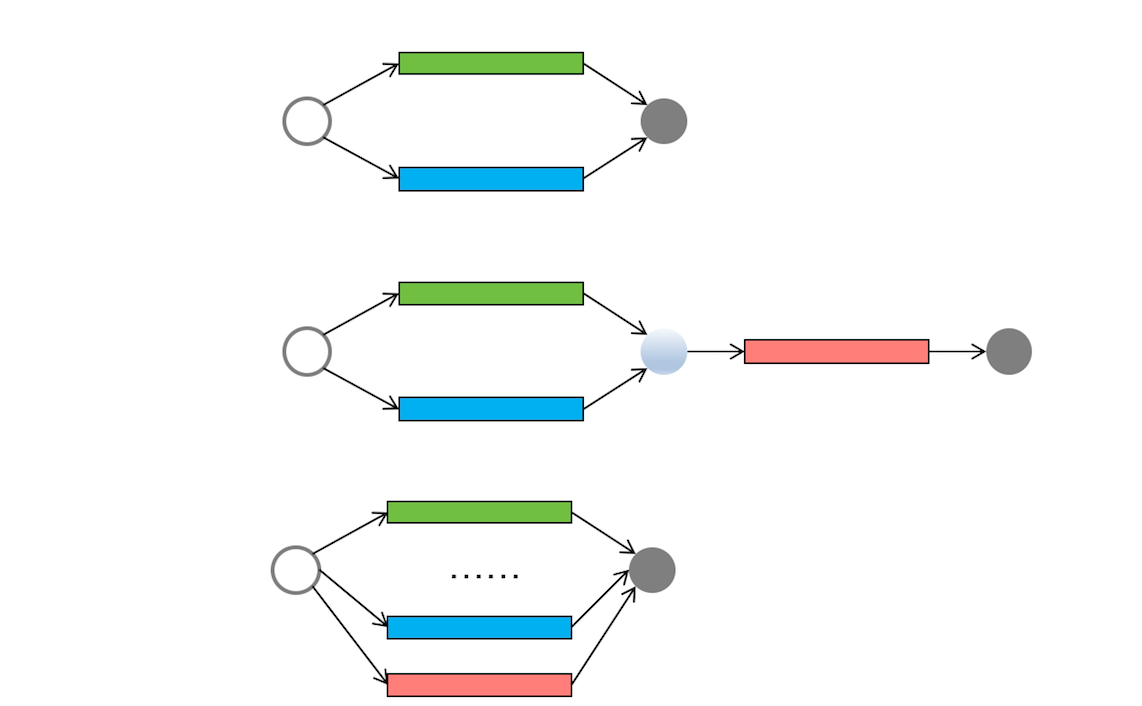
主要有两种情况需要使用组合查询:
在一个查询中从不同的表返回结构数据;
对一个表执行多个查询,按一个查询返回数据。
把 Illinois、Indiana、Michigan 等州的缩写传递给 IN 子句,检索出这些州的所有行
1 2 3
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_state IN ('IL','IN','MI');
找出所有 Fun4All
1 2 3
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_name ='Fun4All';
组合这两条语句
1 2 3 4 5 6 7
SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNION SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4All';
UNION 默认从查询结果集中自动去除了重复的行;如果想返回所有的匹配行,可使用 UNION ALL
1 2 3 4 5 6 7
SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNIONALL SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4All';
CREATEVIEW ProductCustomers AS SELECT cust_name, cust_contact, prod_id FROM Customers, Orders, OrderItems WHERE Customers.cust_id = Orders.cust_id AND OrderItems.order_num = Orders.order_num;
检索订购了产品 RGAN01 的顾客
1 2 3
SELECT cust_name, cust_contact FROM ProductCustomers WHERE prod_id ='RGAN01';
第 19 课 使用存储过程
创建存储过程
对邮件发送清单中具有邮件地址的顾客进行计数
1 2 3 4 5 6 7 8 9 10 11 12
CREATEPROCEDURE MailingListCount ( ListCount OUTINTEGER ) IS v_rows INTEGER;
BEGIN SELECTCOUNT(*) INTO v_rows FROM customers WHERENOT cust_email ISNULL; ListCount := v_rows; END;
-- SQL Server CREATETRIGGER customer_state ON Customers FORINSERT, UPDATE AS UPDATE Customers SET cust_state =Upper(cust_state) WHERE Customers.cust_id = inserted.cust_id;
-- Oracle 和 PostgreSQL CREATETRIGGER customer_state AFTER INSERTORUPDATE FOREACHROW BEGIN UPDATE Customers SET cust_state =Upper(cust_state) WHERE Customers.cust_id = :OLD.cust_id END;
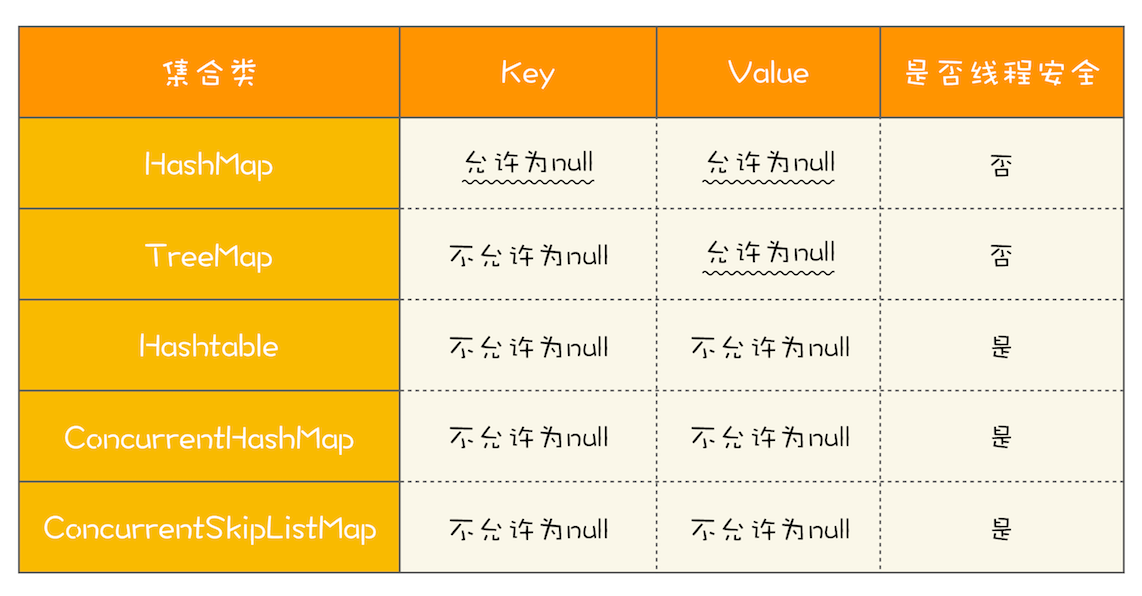
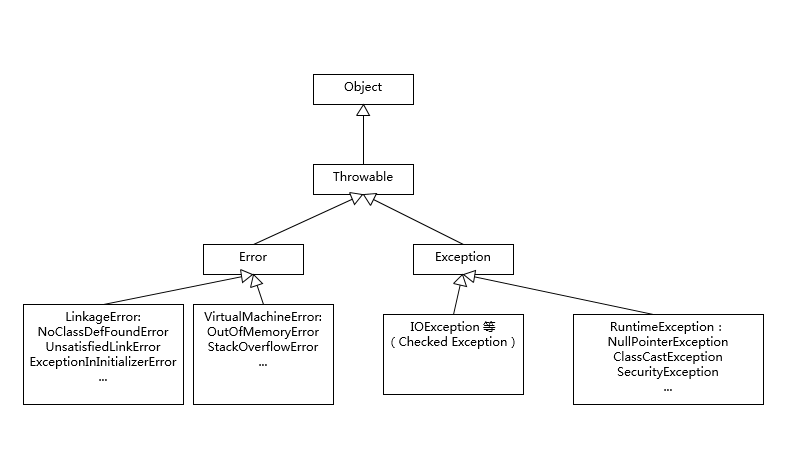
HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
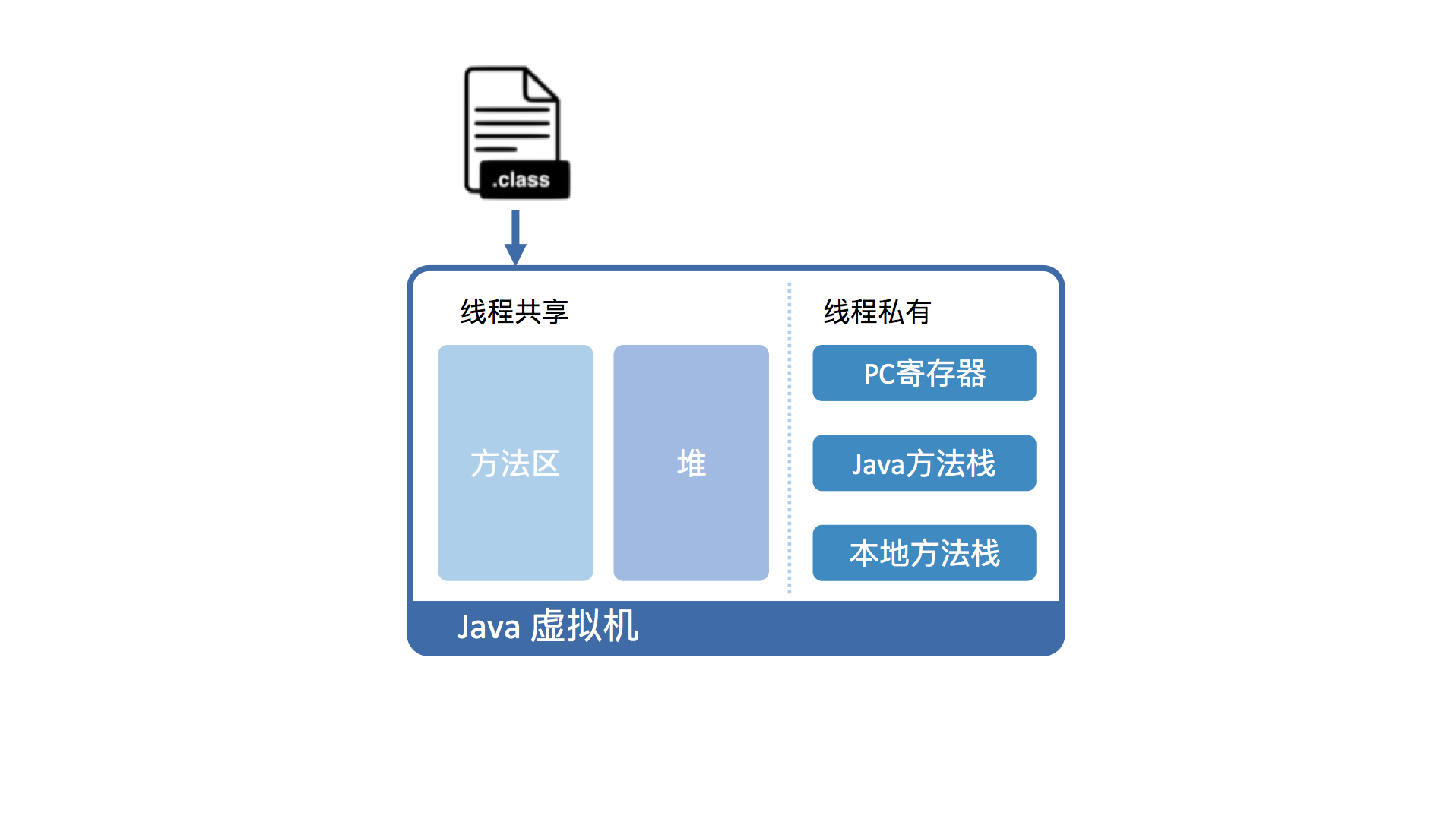
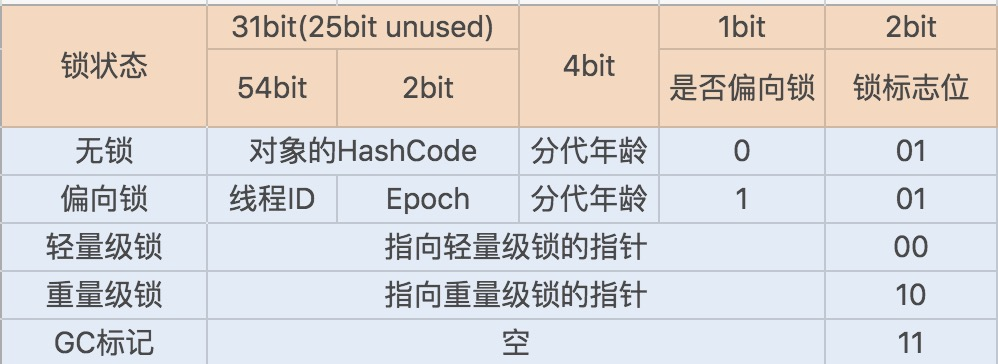
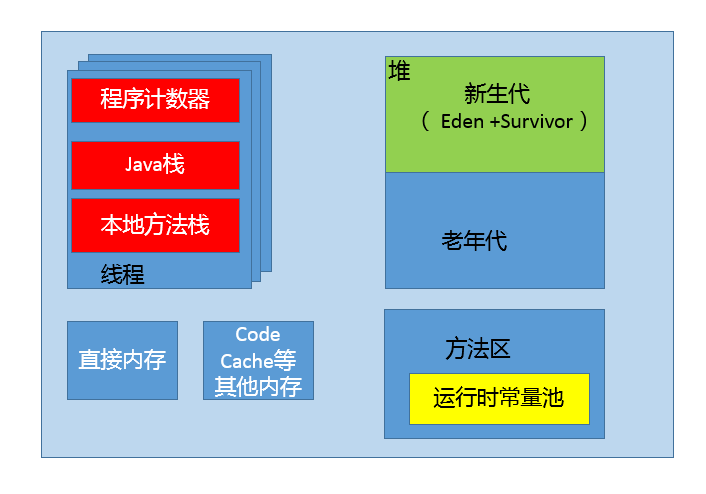
在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。如下图所示:
锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位,synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。
Java 1.6 引入了偏向锁和轻量级锁,从而让 synchronized 拥有了四个状态:
无锁状态(unlocked)
偏向锁状态(biasble)
轻量级锁状态(lightweight locked)
重量级锁状态(inflated)
当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现。
当没有竞争出现时,默认会使用偏向锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏向锁,并切换到轻量级锁实现。轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
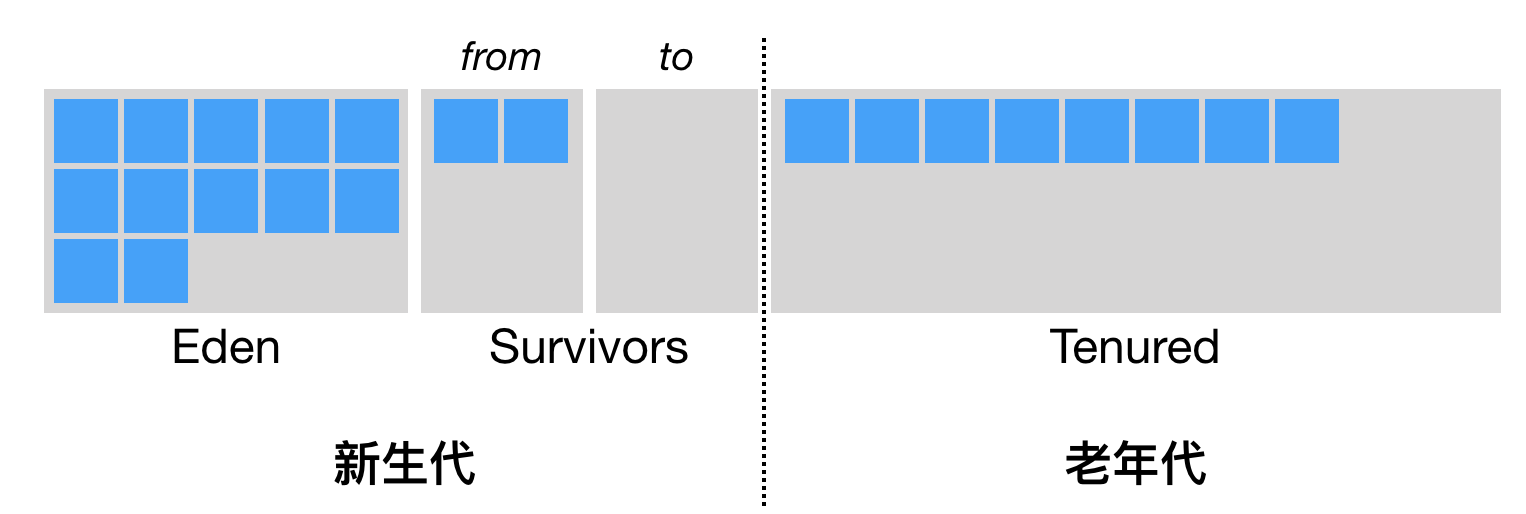
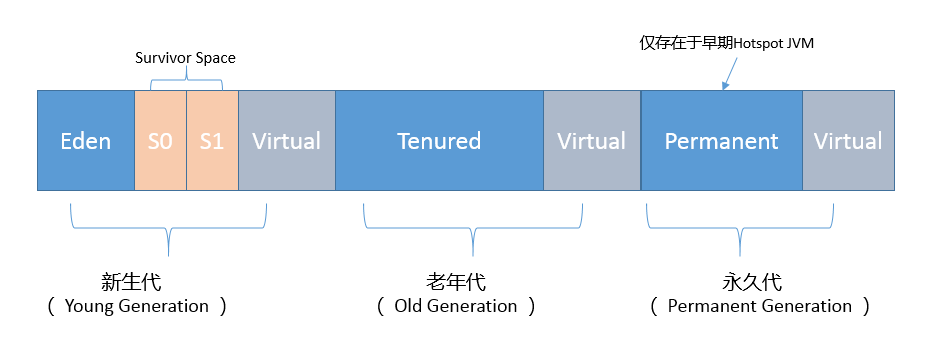
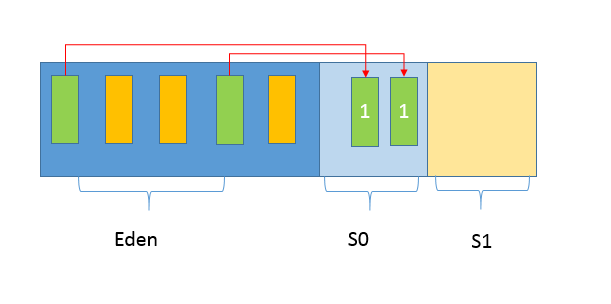
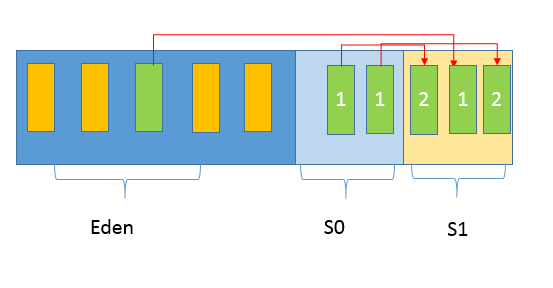
新生代是大部分对象创建和销毁的区域,在通常的 Java 应用中,绝大部分对象生命周期都是很短暂的。其内部又分为 Eden 区域,作为对象初始分配的区域;两个 Survivor,有时候也叫 from、to 区域,被用来放置从 Minor GC 中保留下来的对象。
JVM 会随意选取一个 Survivor 区域作为“to”,然后会在 GC 过程中进行区域间拷贝,也就是将 Eden 中存活下来的对象和 from 区域的对象,拷贝到这个“to”区域。这种设计主要是为了防止内存的碎片化,并进一步清理无用对象。
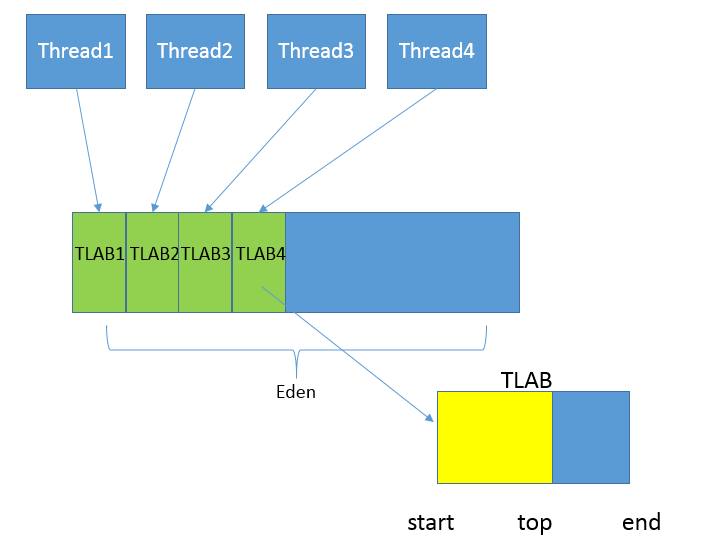
从内存模型而不是垃圾收集的角度,对 Eden 区域继续进行划分,Hotspot JVM 还有一个概念叫做 Thread Local Allocation Buffer(TLAB)。这是 JVM 为每个线程分配的一个私有缓存区域,否则,多线程同时分配内存时,为避免操作同一地址,可能需要使用加锁等机制,进而影响分配速度。TLAB 仍然在堆上,它是分配在 Eden 区域内的。其内部结构比较直观易懂,start、end 就是起始地址,top(指针)则表示已经分配到哪里了。所以我们分配新对象,JVM 就会移动 top,当 top 和 end 相遇时,即表示该缓存已满,JVM 会试图再从 Eden 里分配一块儿。
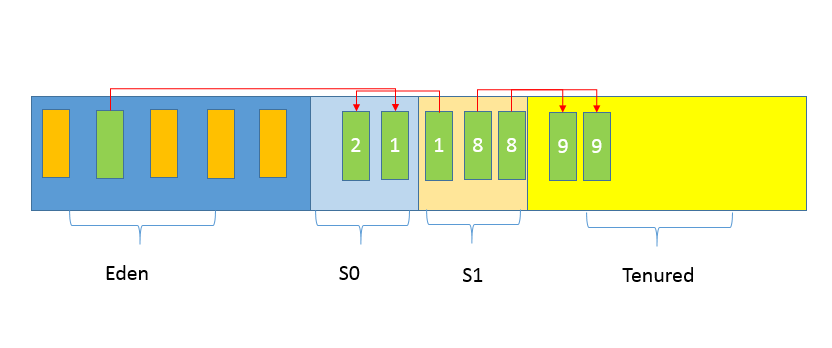
老年代
放置长生命周期的对象,通常都是从 Survivor 区域拷贝过来的对象。当然,也有特殊情况,我们知道普通的对象会被分配在 TLAB 上;如果对象较大,JVM 会试图直接分配在 Eden 其他位置上;如果对象太大,完全无法在新生代找到足够长的连续空闲空间,JVM 就会直接分配到老年代。
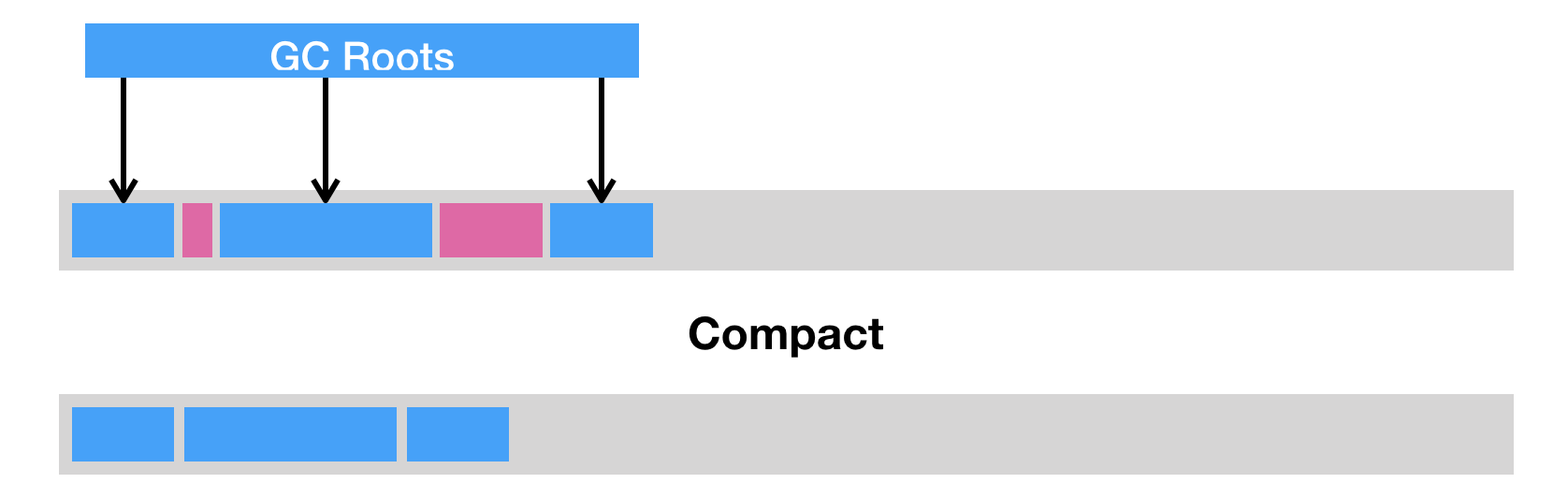
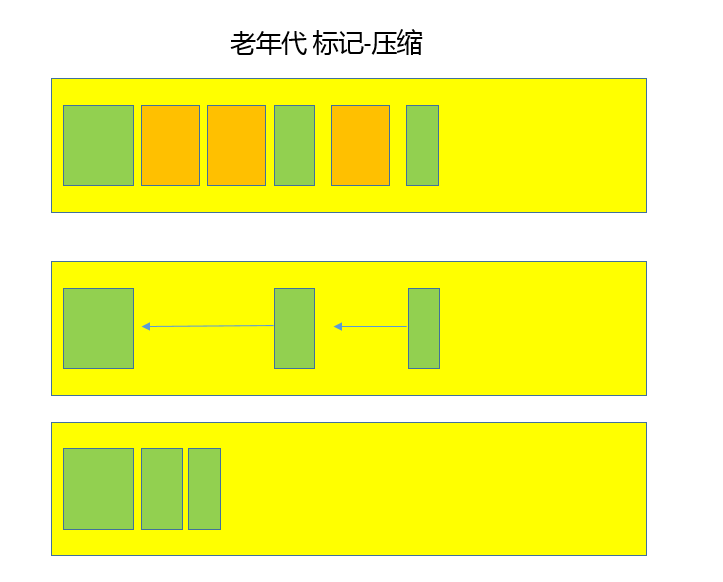
Serial GC,它是最古老的垃圾收集器,“Serial”体现在其收集工作是单线程的,并且在进行垃圾收集过程中,会进入臭名昭著的“Stop-The-World”状态。当然,其单线程设计也意味着精简的 GC 实现,无需维护复杂的数据结构,初始化也简单,所以一直是 Client 模式下 JVM 的默认选项。从年代的角度,通常将其老年代实现单独称作 Serial Old,它采用了标记 - 整理(Mark-Compact)算法,区别于新生代的复制算法。
ParNew GC,很明显是个新生代 GC 实现,它实际是 Serial GC 的多线程版本,最常见的应用场景是配合老年代的 CMS GC 工作
CMS(Concurrent Mark Sweep) GC,基于标记 - 清除(Mark-Sweep)算法,设计目标是尽量减少停顿时间,这一点对于 Web 等反应时间敏感的应用非常重要,一直到今天,仍然有很多系统使用 CMS GC。但是,CMS 采用的标记 - 清除算法,存在着内存碎片化问题,所以难以避免在长时间运行等情况下发生 full GC,导致恶劣的停顿。另外,既然强调了并发(Concurrent),CMS 会占用更多 CPU 资源,并和用户线程争抢。
Parallel GC,在早期 JDK 8 等版本中,它是 server 模式 JVM 的默认 GC 选择,也被称作是吞吐量优先的 GC。它的算法和 Serial GC 比较相似,尽管实现要复杂的多,其特点是新生代和老年代 GC 都是并行进行的,在常见的服务器环境中更加高效。
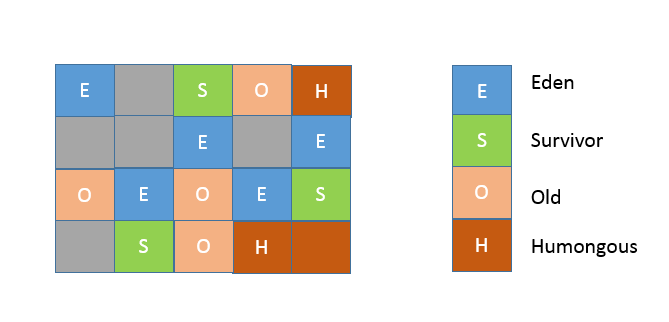
在 G1 实现中,年代是个逻辑概念,具体体现在,一部分 region 是作为 Eden,一部分作为 Survivor,除了意料之中的 Old region,G1 会将超过 region 50% 大小的对象(在应用中,通常是 byte 或 char 数组)归类为 Humongous 对象,并放置在相应的 region 中。逻辑上,Humongous region 算是老年代的一部分,因为复制这样的大对象是很昂贵的操作,并不适合新生代 GC 的复制算法。
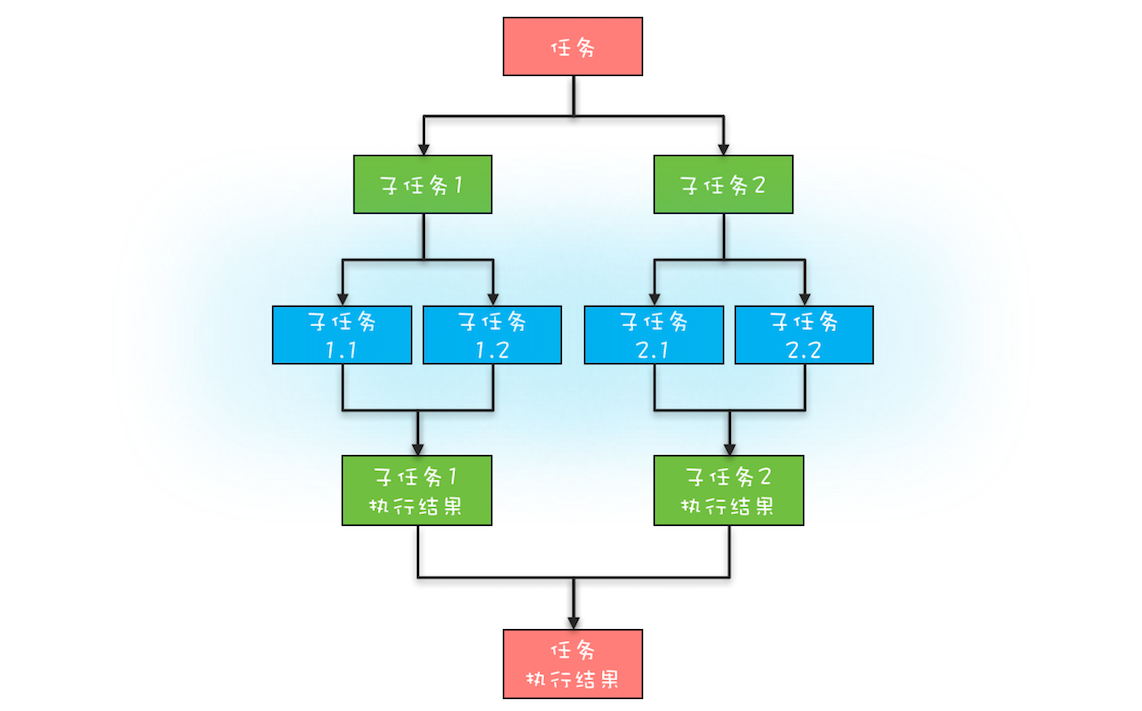
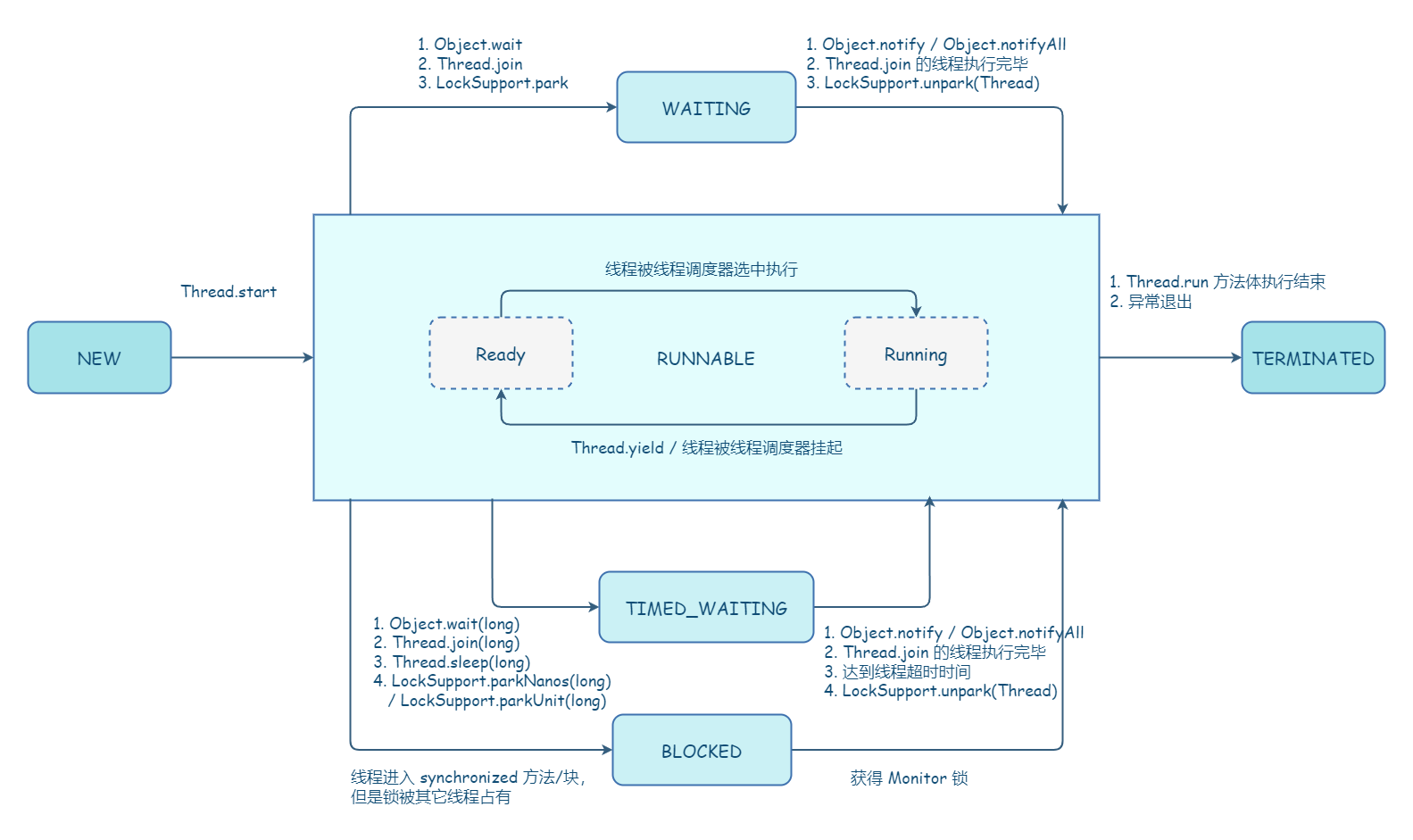
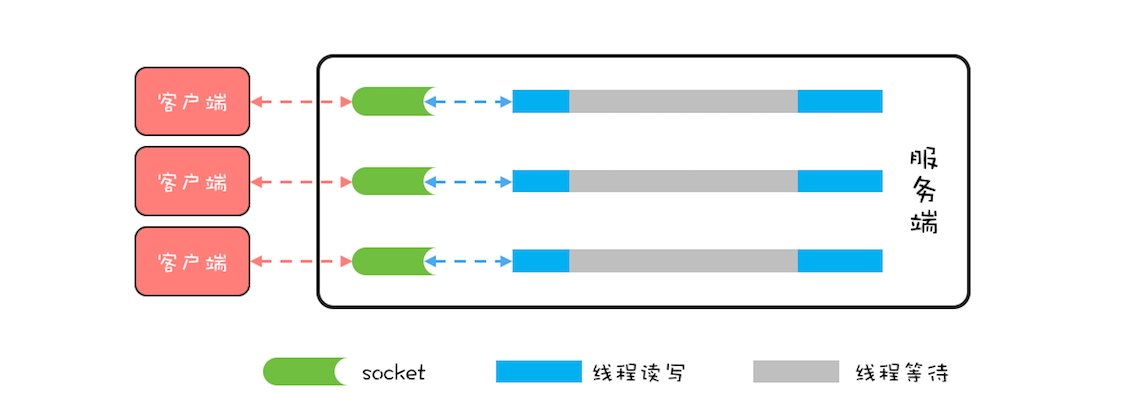
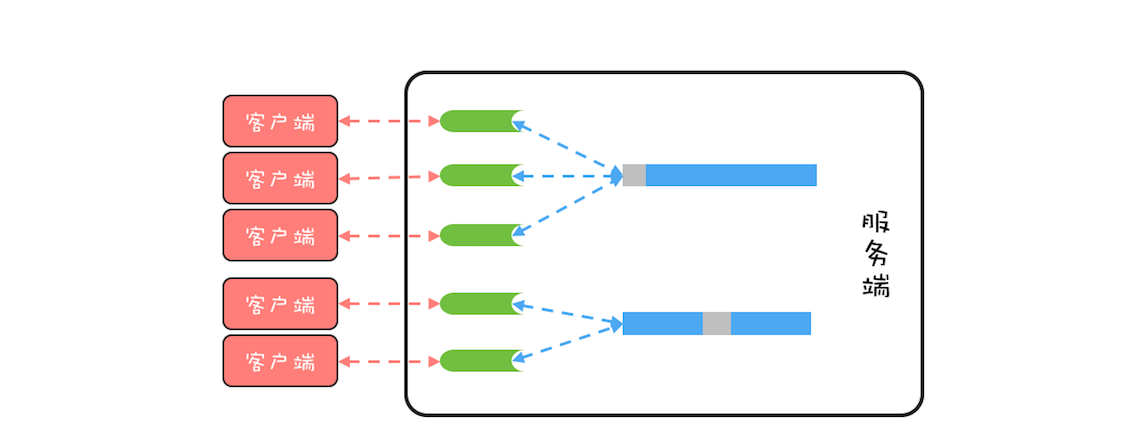
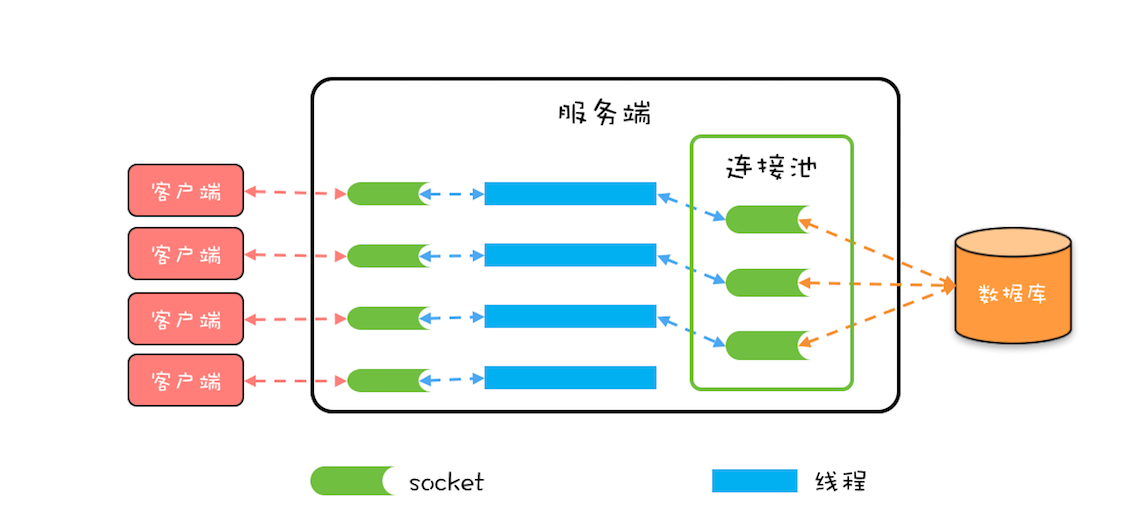
BIO 这种线程模型适用于 socket 连接不是很多的场景;但是现在的互联网场景,往往需要服务器能够支撑十万甚至百万连接,而创建十万甚至上百万个线程显然并不现实,所以 BIO 线程模型无法解决百万连接的问题。如果仔细观察,你会发现互联网场景中,虽然连接多,但是每个连接上的请求并不频繁,所以线程大部分时间都在等待 I/O 就绪。也就是说线程大部分时间都阻塞在那里,这完全是浪费,如果我们能够解决这个问题,那就不需要这么多线程了。
可以用一个线程来处理多个连接,这样线程的利用率就上来了,同时所需的线程数量也跟着降下来了。这个思路很好,可是使用 BIO 相关的 API 是无法实现的,这是为什么呢?因为 BIO 相关的 socket 读写操作都是阻塞式的,而一旦调用了阻塞式 API,在 I/O 就绪前,调用线程会一直阻塞,也就无法处理其他的 socket 连接了。
Actor 中的消息机制,就可以类比这现实世界里的写信。Actor 内部有一个邮箱(Mailbox),接收到的消息都是先放到邮箱里,如果邮箱里有积压的消息,那么新收到的消息就不会马上得到处理,也正是因为 Actor 使用单线程处理消息,所以不会出现并发问题。你可以把 Actor 内部的工作模式想象成只有一个消费者线程的生产者-消费者模式。
在 Actor 模型里,发送消息仅仅是把消息发出去而已,接收消息的 Actor 在接收到消息后,也不一定会立即处理,也就是说** Actor 中的消息机制完全是异步的。而调用对象方法,实际上是同步**的,对象方法 return 之前,调用方会一直等待。
除此之外,调用对象方法,需要持有对象的引用,所有的对象必须在同一个进程中。而在 Actor 中发送消息,类似于现实中的写信,只需要知道对方的地址就可以,发送消息和接收消息的 Actor 可以不在一个进程中,也可以不在同一台机器上。因此,Actor 模型不但适用于并发计算,还适用于分布式计算。
我们首先要做的,就是让 Java 中的对象有版本号,在下面的示例代码中,VersionedRef 这个类的作用就是将对象 value 包装成带版本号的对象。按照 MVCC 理论,数据的每一次修改都对应着一个唯一的版本号,所以不存在仅仅改变 value 或者 version 的情况,用不变性模式就可以很好地解决这个问题,所以 VersionedRef 这个类被我们设计成了不可变的。
协程可以理解为一种轻量级的线程。从操作系统的角度来看,线程是在内核态中调度的,而协程是在用户态调度的,所以相对于线程来说,协程切换的成本更低。协程虽然也有自己的栈,但是相比线程栈要小得多,典型的线程栈大小差不多有 1M,而协程栈的大小往往只有几 K 或者几十 K。所以,无论是从时间维度还是空间维度来看,协程都比线程轻量得多。
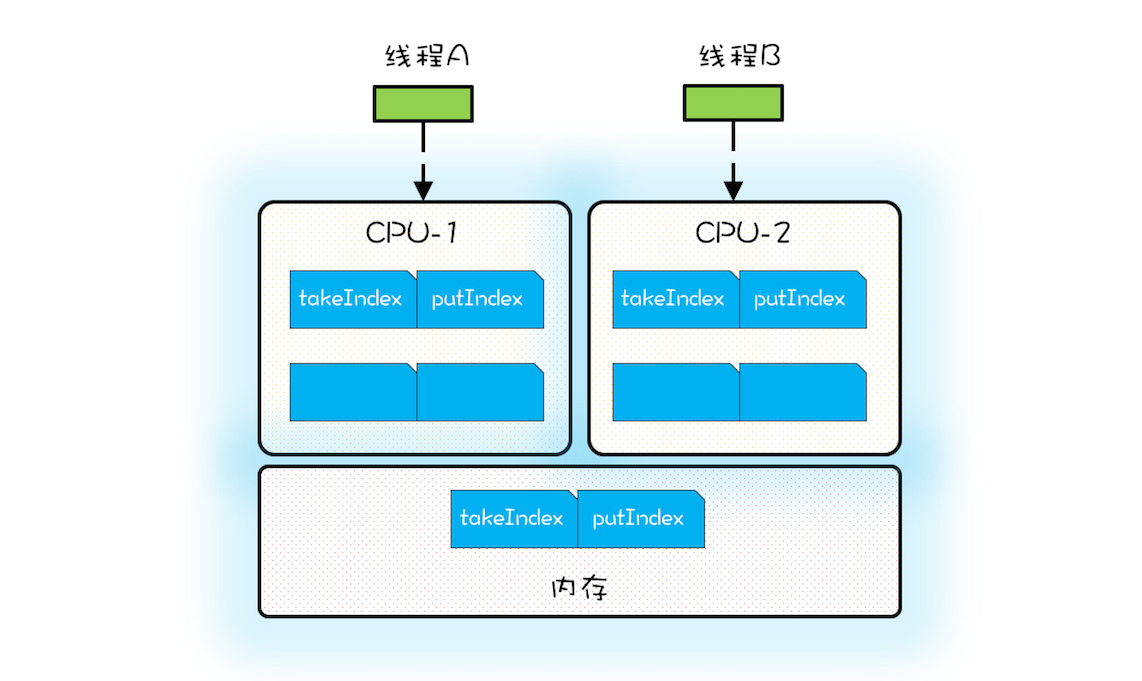
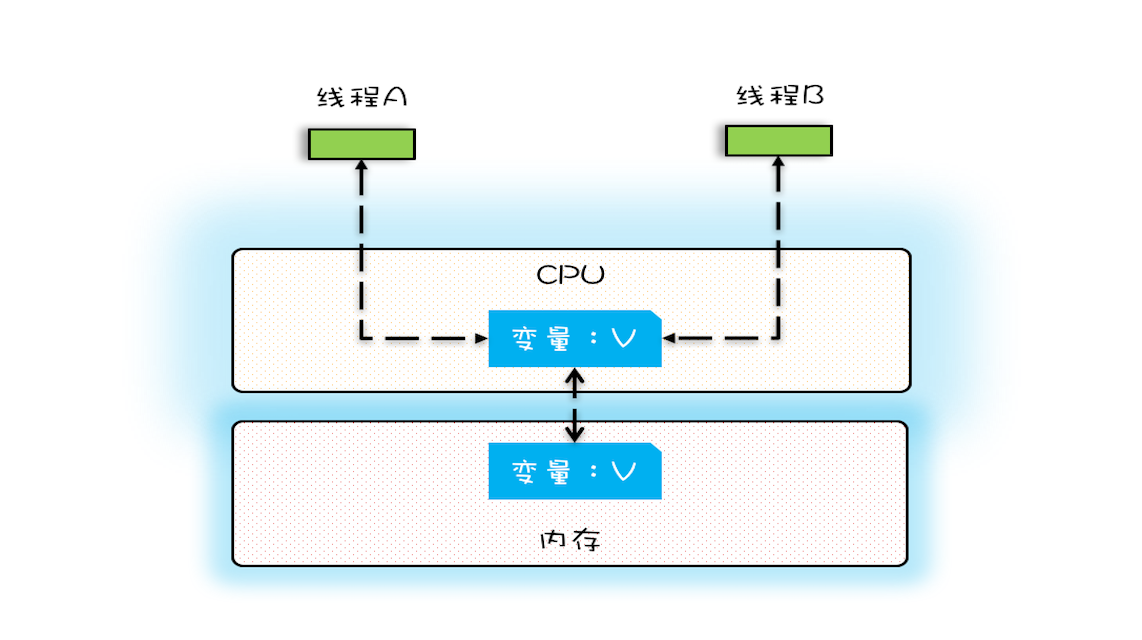
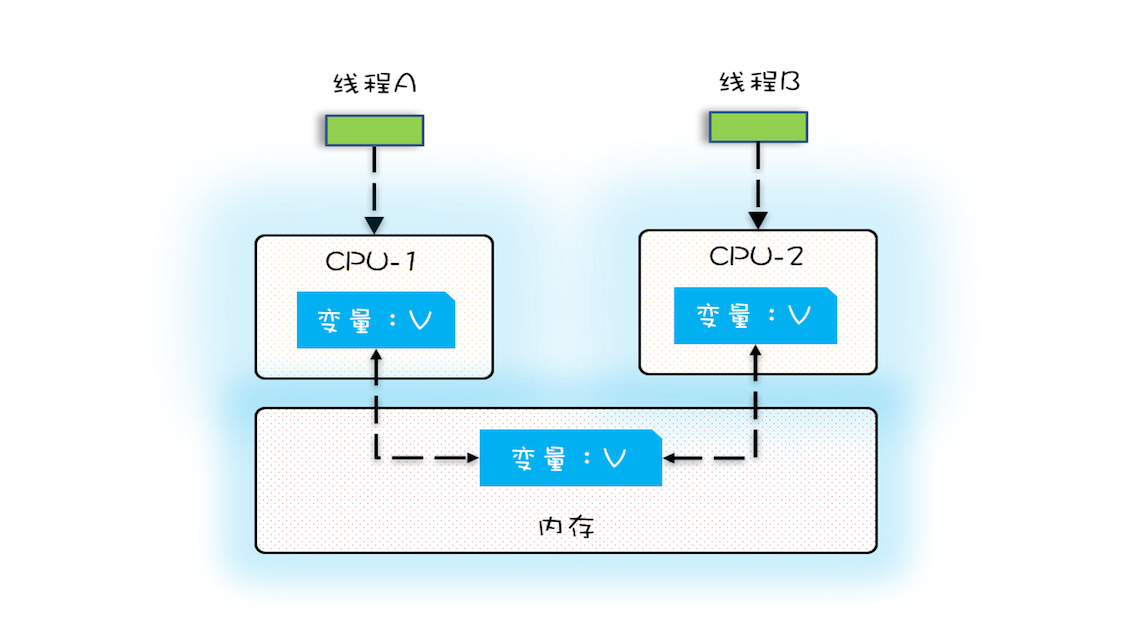
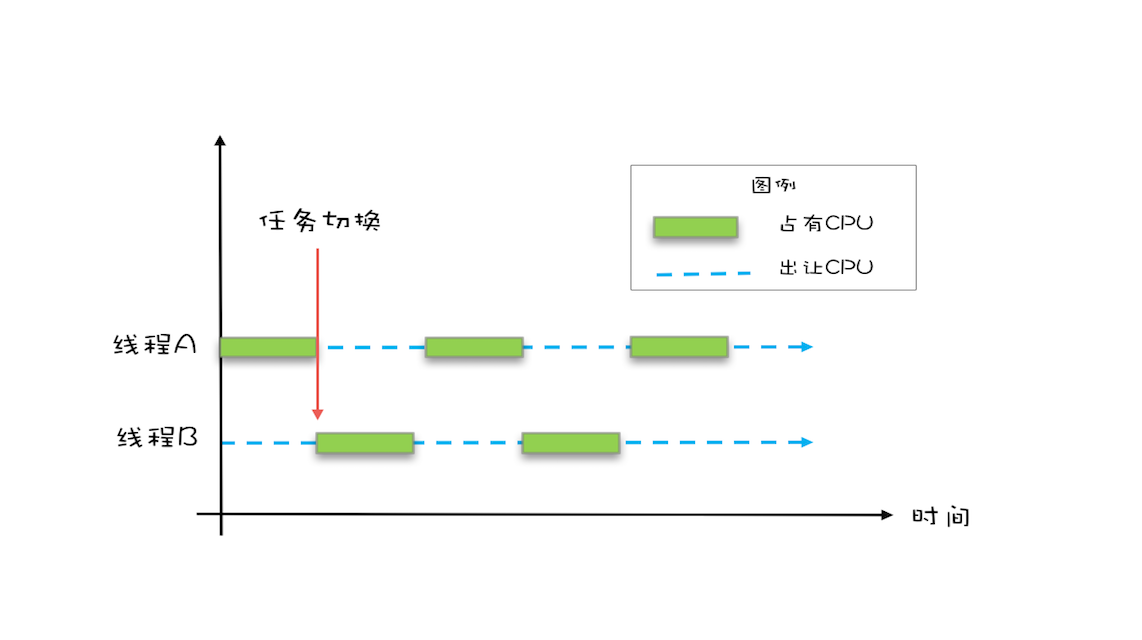
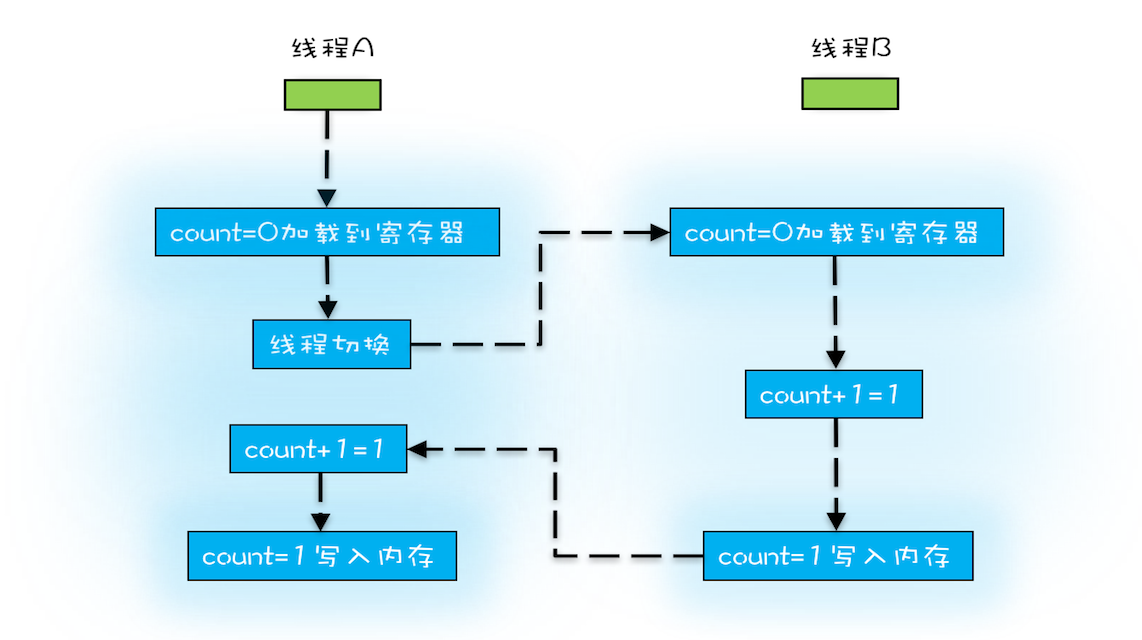
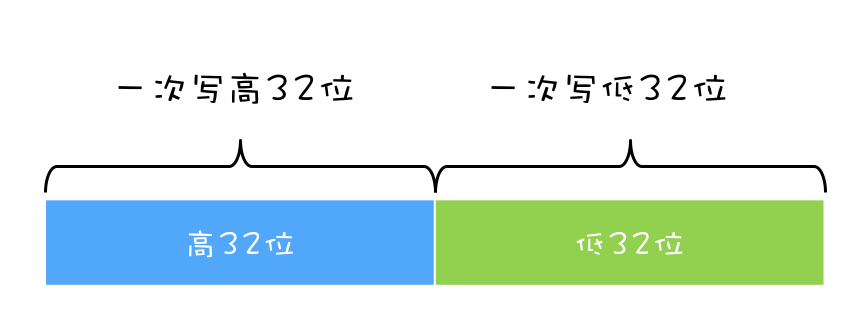
在多核场景下,同一时刻,有可能有两个线程同时在执行,一个线程执行在 CPU-1 上,一个线程执行在 CPU-2 上,此时禁止 CPU 中断,只能保证 CPU 上的线程连续执行,并不能保证同一时刻只有一个线程执行,如果这两个线程同时写 long 型变量高 32 位的话,那就有可能出现我们开头提及的诡异 Bug 了。
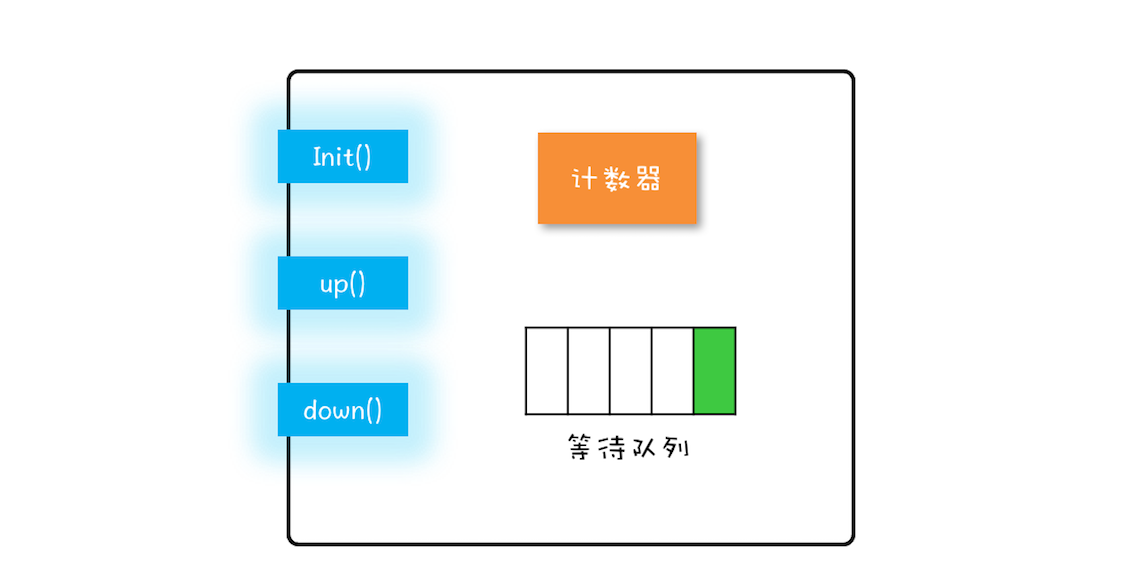
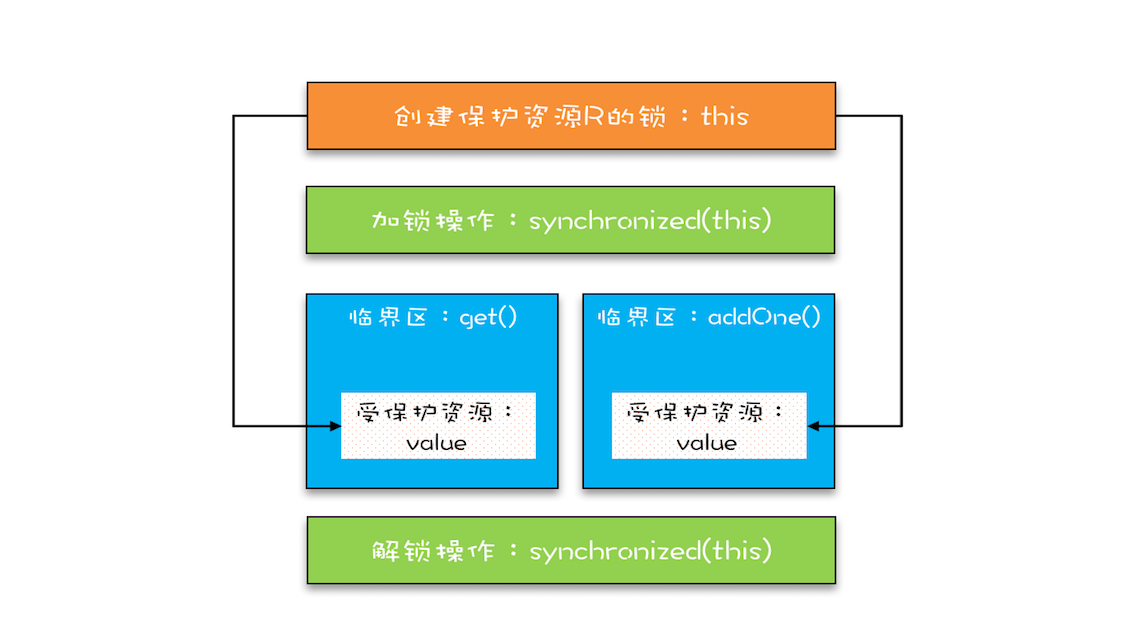
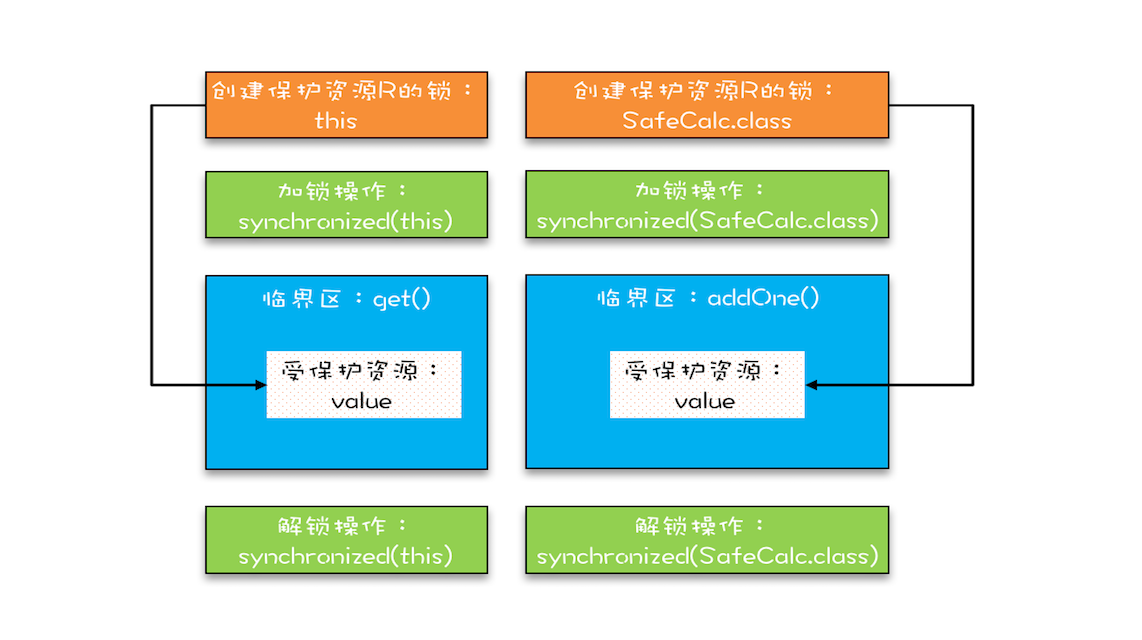
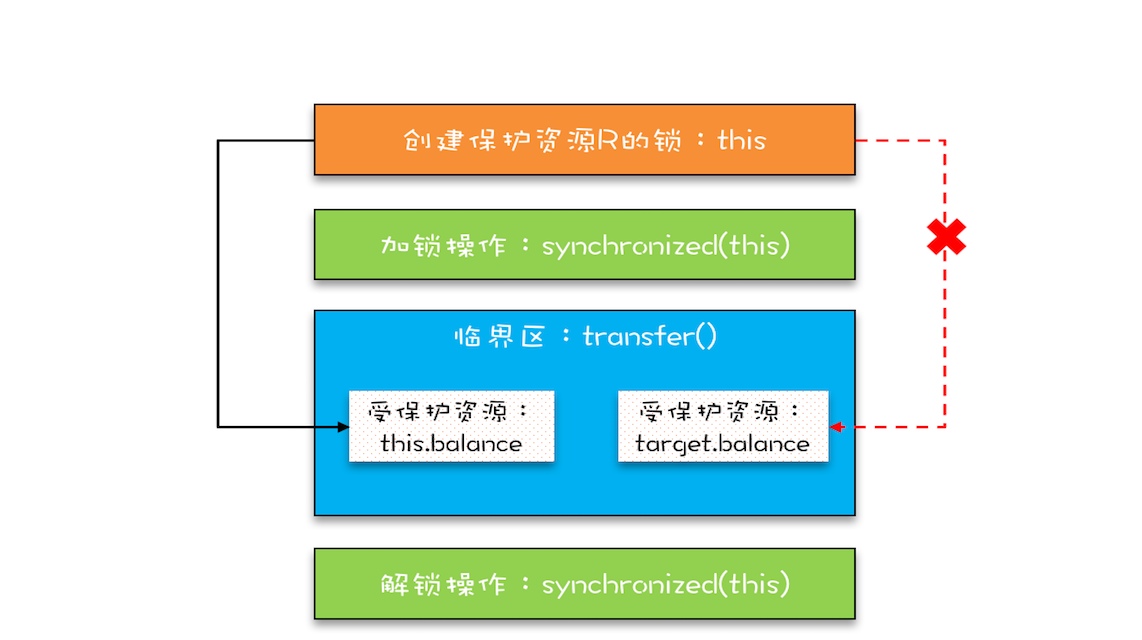
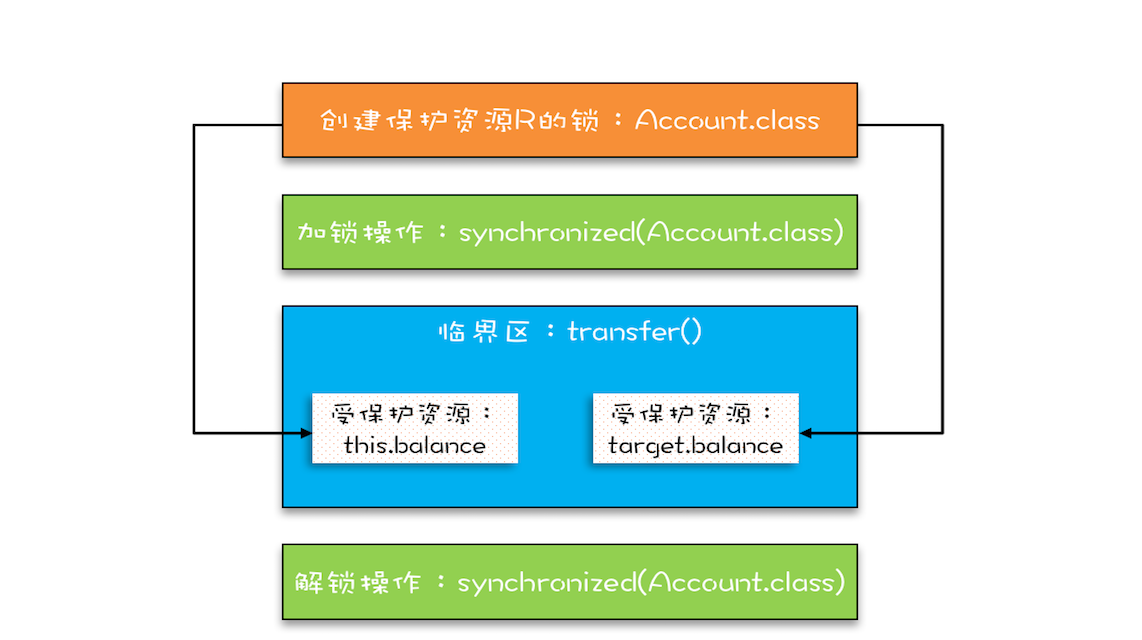
“同一时刻只有一个线程执行”称之为互斥。如果能够保证对共享变量的修改是互斥的,那么,无论是单核 CPU 还是多核 CPU,就都能保证原子性了。
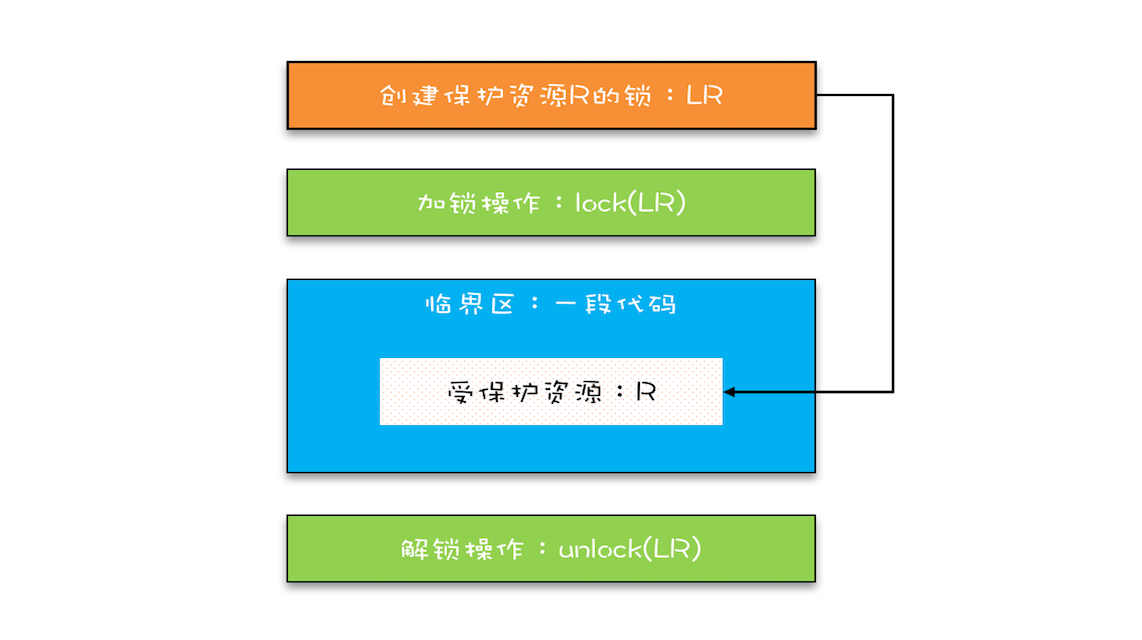
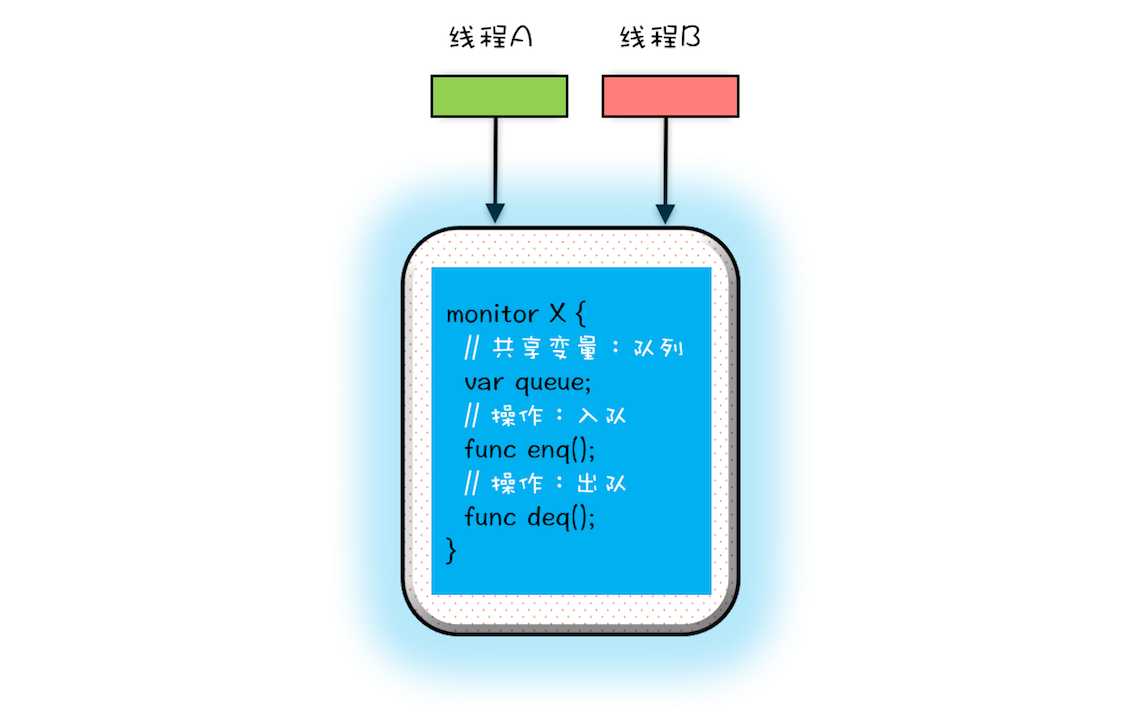
将共享变量及其对共享变量的操作统一封装起来。在下图中,管程 X 将共享变量 queue 这个队列和相关的操作入队 enq()、出队 deq() 都封装起来了;线程 A 和线程 B 如果想访问共享变量 queue,只能通过调用管程提供的 enq()、deq() 方法来实现;enq()、deq() 保证互斥性,只允许一个线程进入管程。
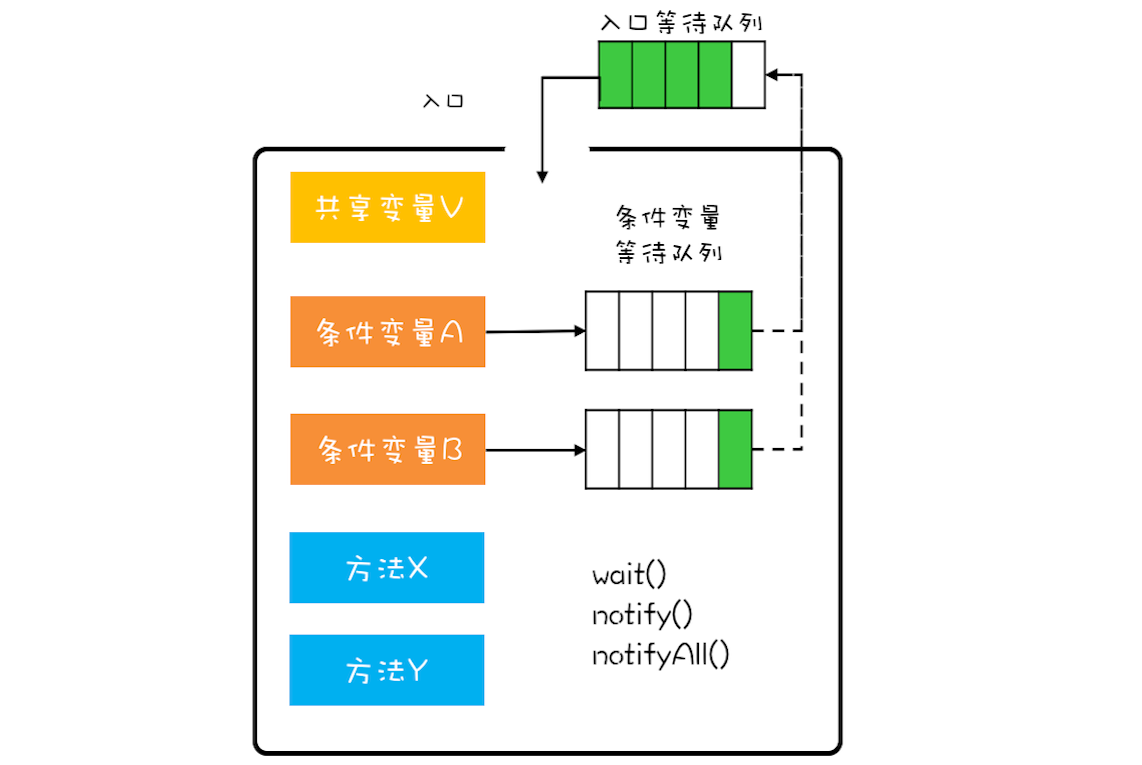
管程是如何解决线程间的同步问题的:
在管程模型里,共享变量和对共享变量的操作是被封装起来的,图中最外层的框就代表封装的意思。框的上面只有一个入口,并且在入口旁边还有一个入口等待队列。当多个线程同时试图进入管程内部时,只允许一个线程进入,其他线程则在入口等待队列中等待。管程里还引入了条件变量的概念,而且每个条件变量都对应有一个等待队列,如下图,条件变量 A 和条件变量 B 分别都有自己的等待队列。
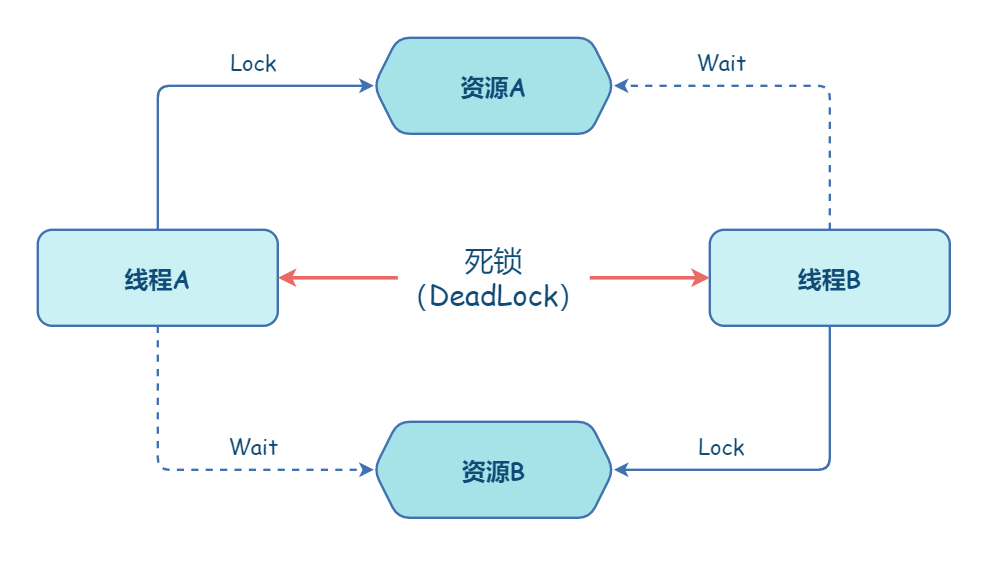
能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
// 支持中断的 API voidlockInterruptibly() throws InterruptedException; // 支持超时的 API booleantryLock(long time, TimeUnit unit) throws InterruptedException; // 支持非阻塞获取锁的 API booleantryLock();
如何保证可见性
以 ReentrantLock 为例,内部持有一个 volatile 的成员变量 state,获取锁的时候,会读写 state 的值;解锁的时候,也会读写 state 的值。由 volatile 保证变量的可见性。
在 distanceFromOrigin() 这个方法中,首先通过调用 tryOptimisticRead() 获取了一个 stamp,这里的 tryOptimisticRead() 就是我们前面提到的乐观读。之后将共享变量 x 和 y 读入方法的局部变量中,不过需要注意的是,由于 tryOptimisticRead() 是无锁的,所以共享变量 x 和 y 读入方法局部变量时,x 和 y 有可能被其他线程修改了。因此最后读完之后,还需要再次验证一下是否存在写操作,这个验证操作是通过调用 validate(stamp) 来实现的。
CPU 为了解决并发问题,提供了 CAS 指令(CAS,全称是 Compare And Swap,即“比较并交换”)。CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
使用 CAS 来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。
CAS 存在 ABA 问题。
看 Java 如何实现原子化的 count += 1
AtomicLong 的 getAndIncrement() 方法会转调 unsafe.getAndAddLong() 方法。这里 this 和 valueOffset 两个参数可以唯一确定共享变量的内存地址。
publicfinallonggetAndAddLong(Object o, long offset, long delta){ long v; do { // 读取内存中的值 v = getLongVolatile(o, offset); } while (!compareAndSwapLong(o, offset, v, v + delta)); return v; } //原子性地将变量更新为 x //条件是内存中的值等于 expected //更新成功则返回 true nativebooleancompareAndSwapLong( Object o, long offset, long expected, long x);
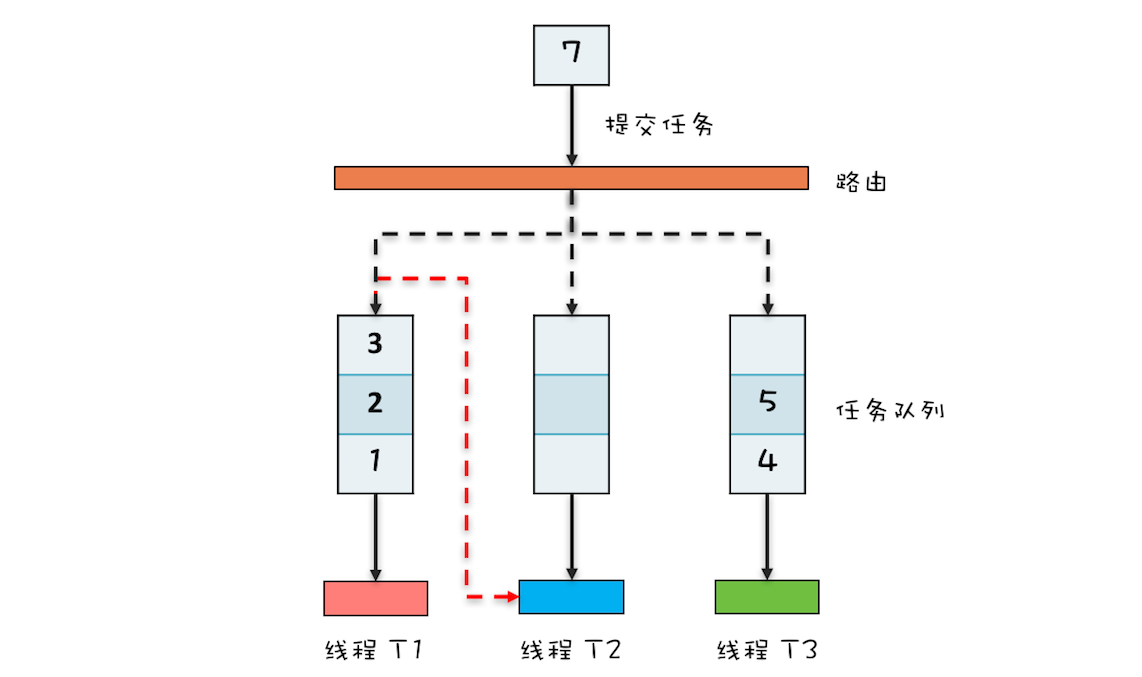
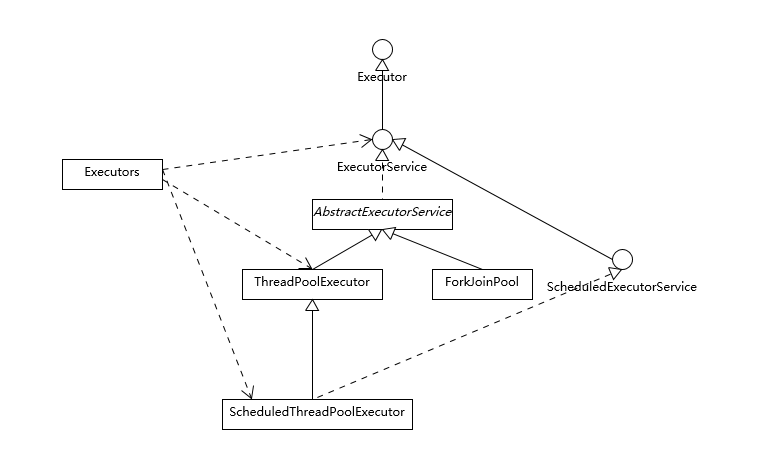
ThreadPoolExecutor( int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
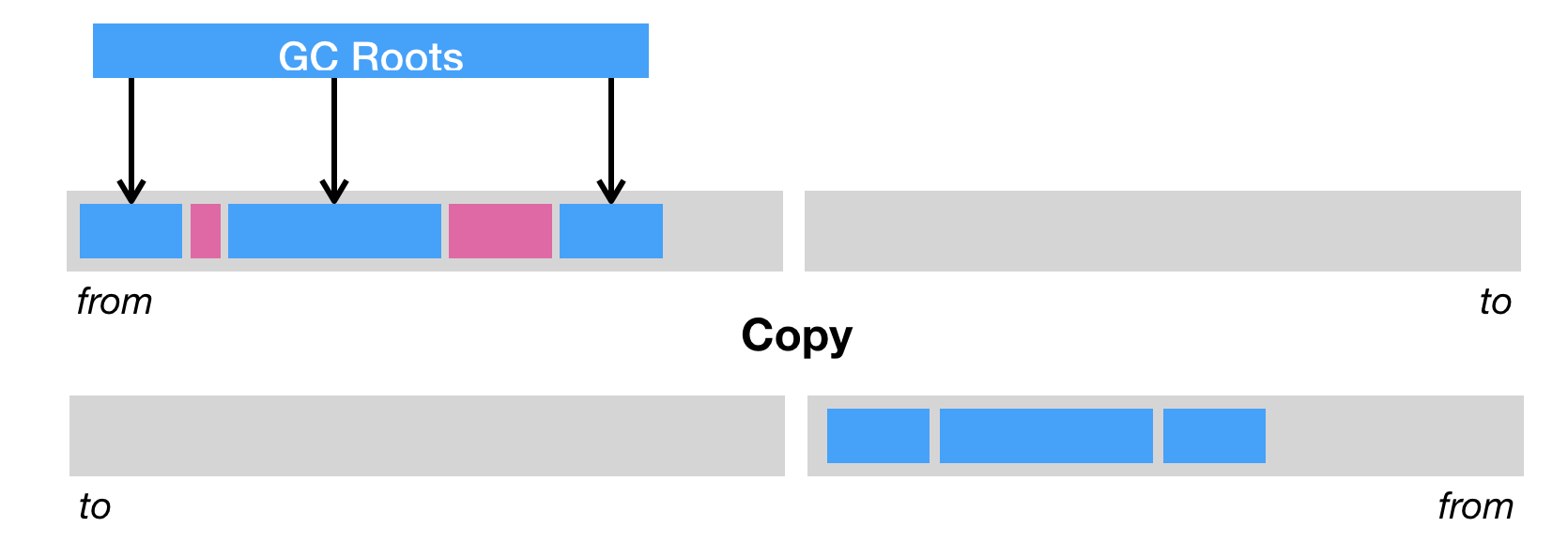
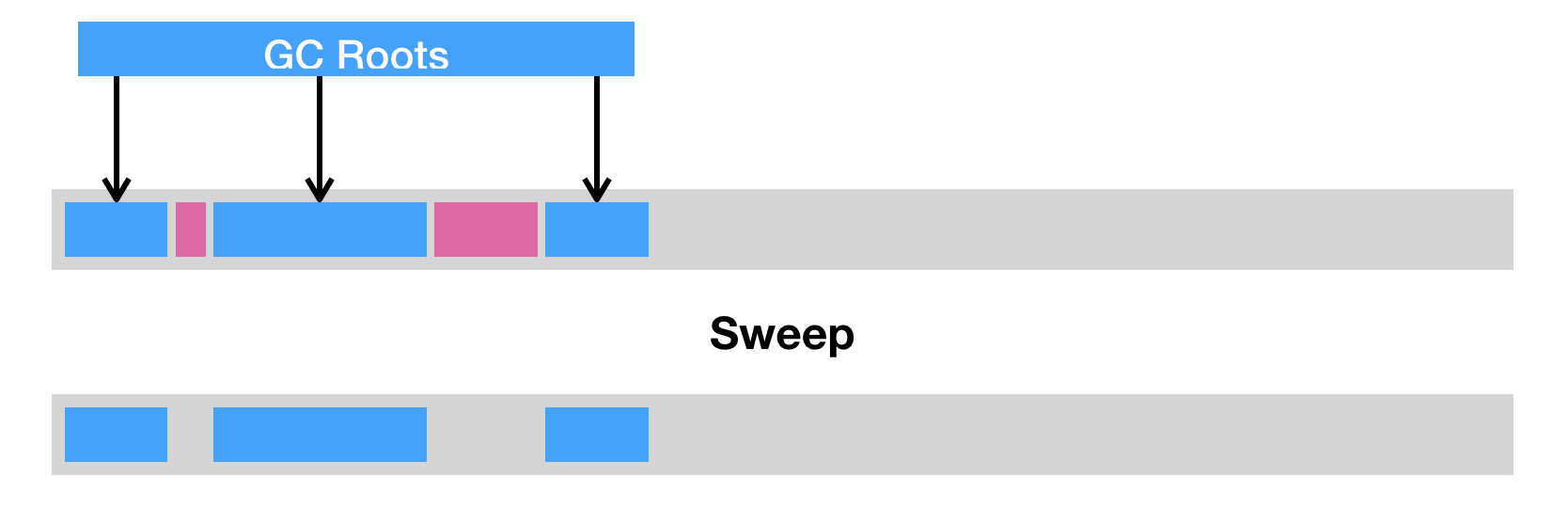
标记-复制把内存区域分为两等分,分别用两个指针 from 和 to 来维护,并且只是用 from 指针指向的内存区域来分配内存。当发生垃圾回收时,便把存活的对象复制到 to 指针指向的内存区域中,并且交换 from 指针和 to 指针的内容。复制这种回收方式同样能够解决内存碎片化的问题,但是它的缺点也极其明显,即堆空间的使用效率极其低下。









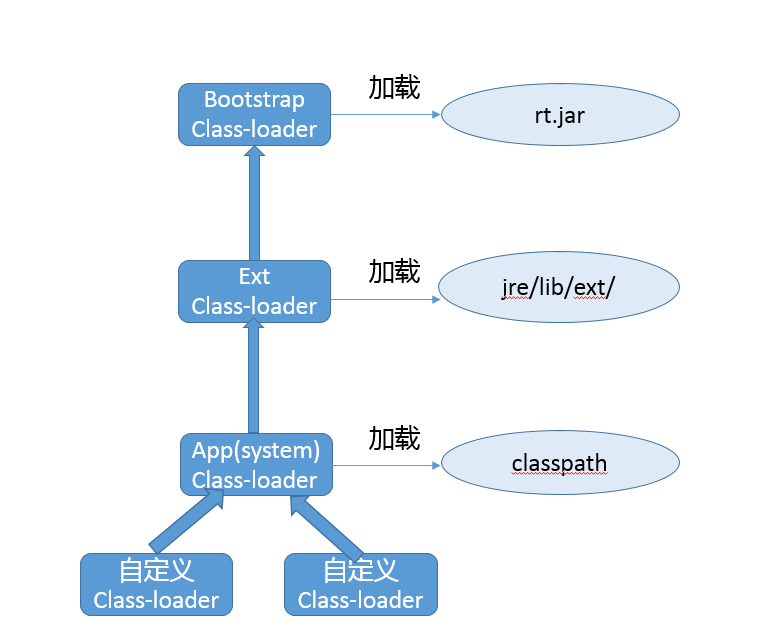
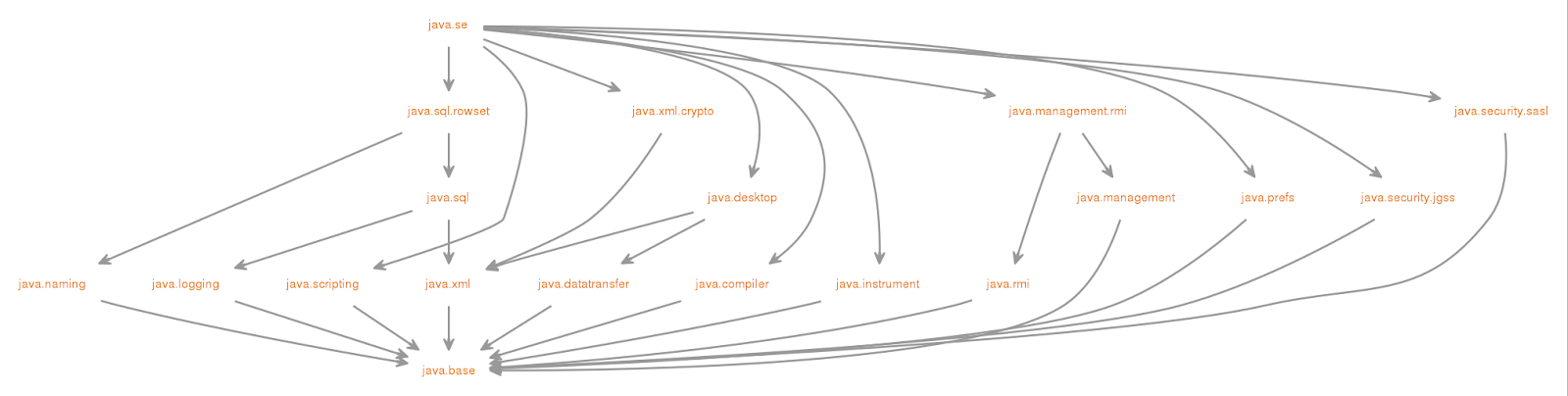
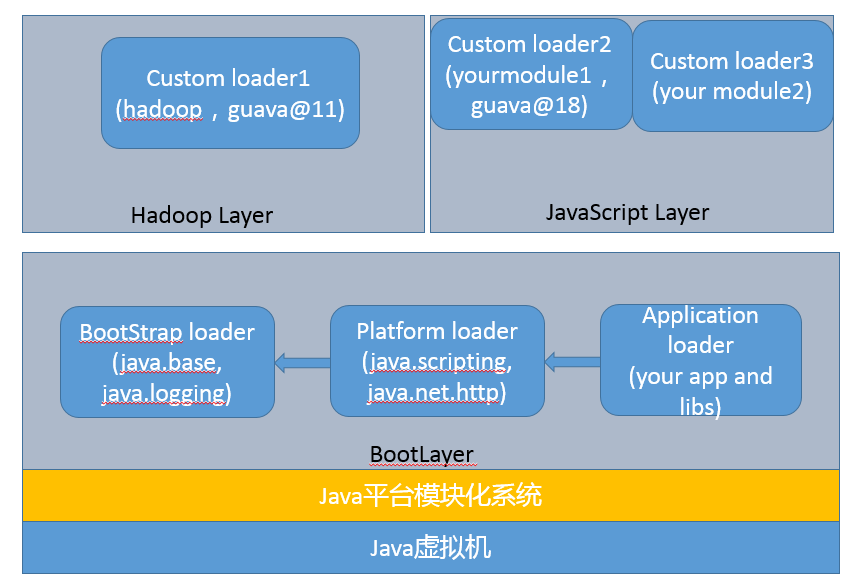


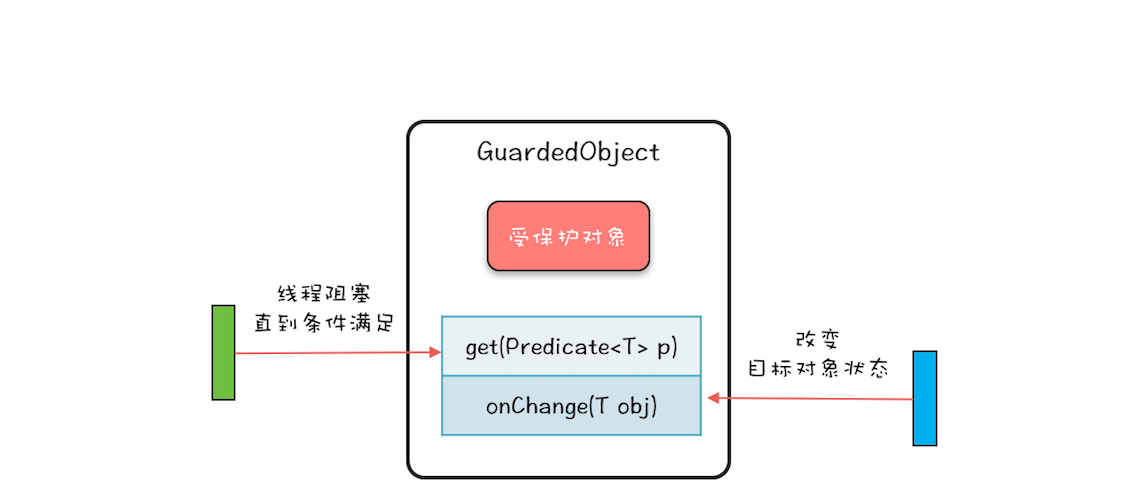
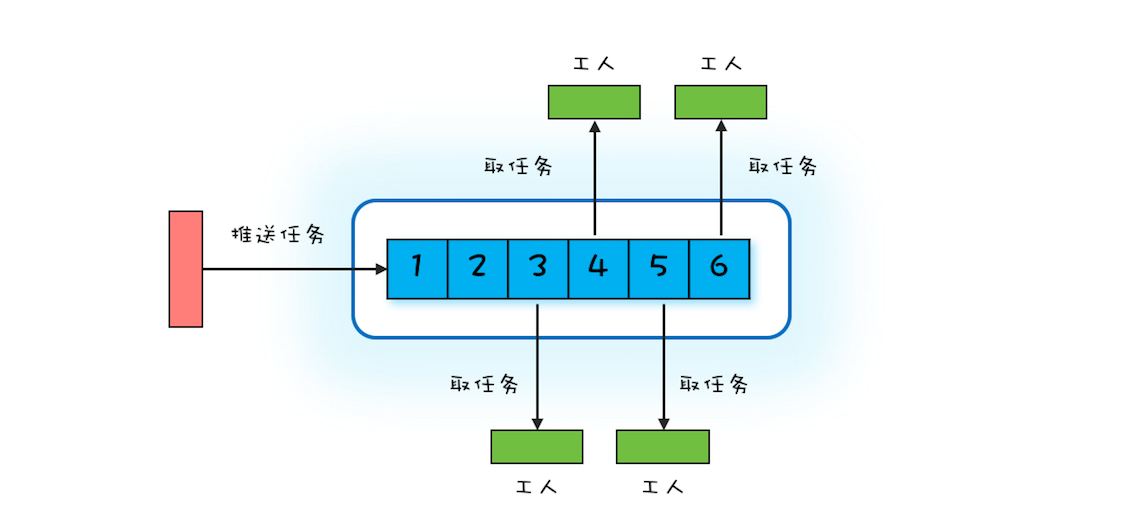
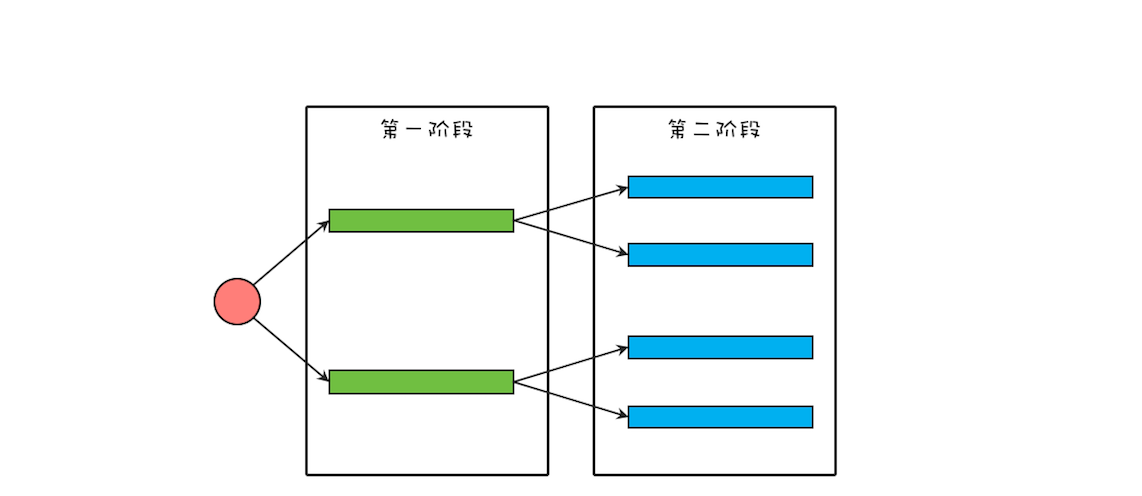
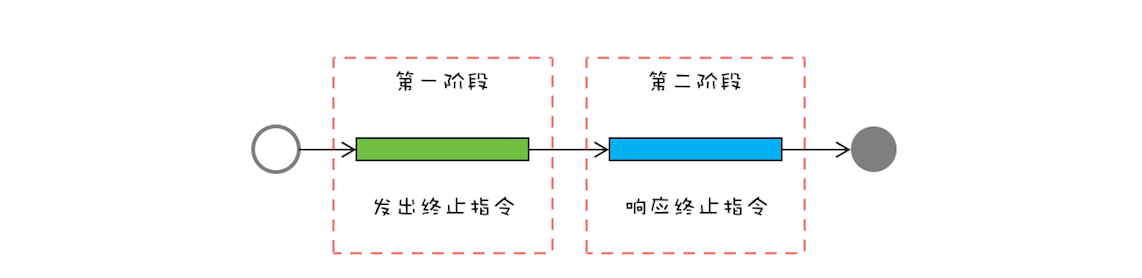
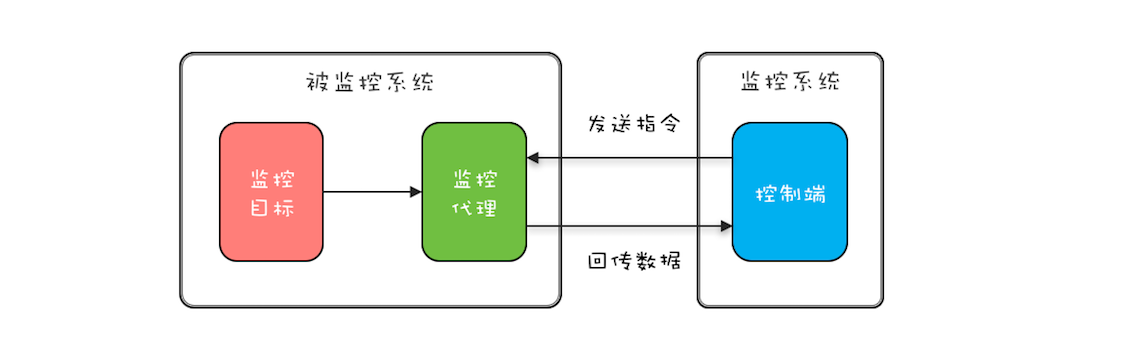
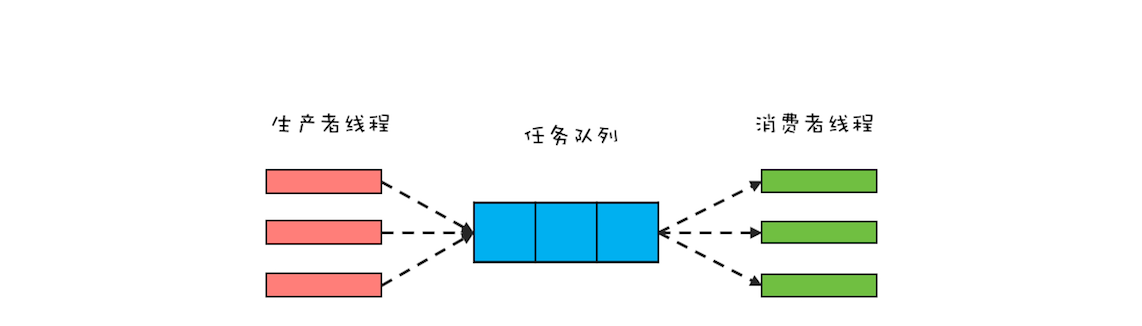
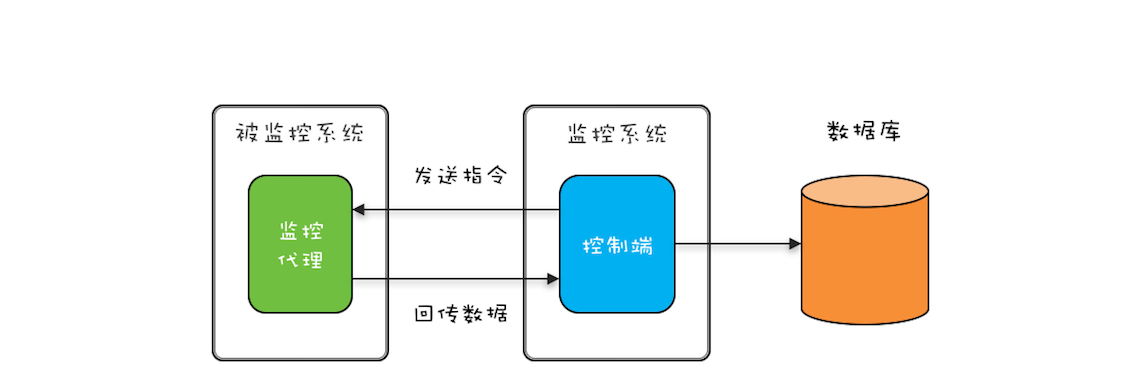
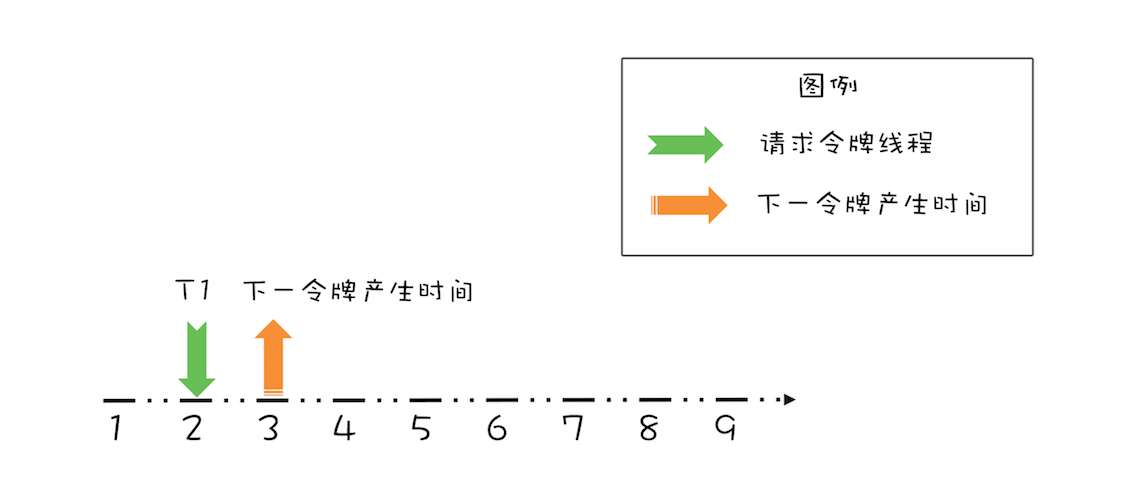
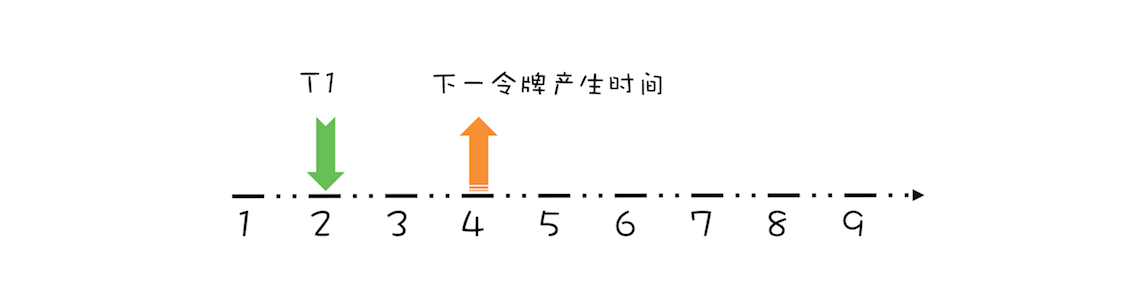
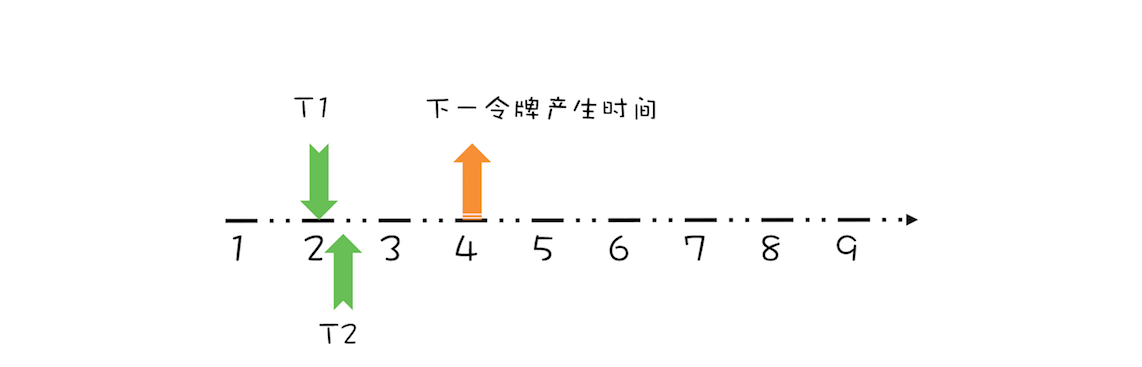
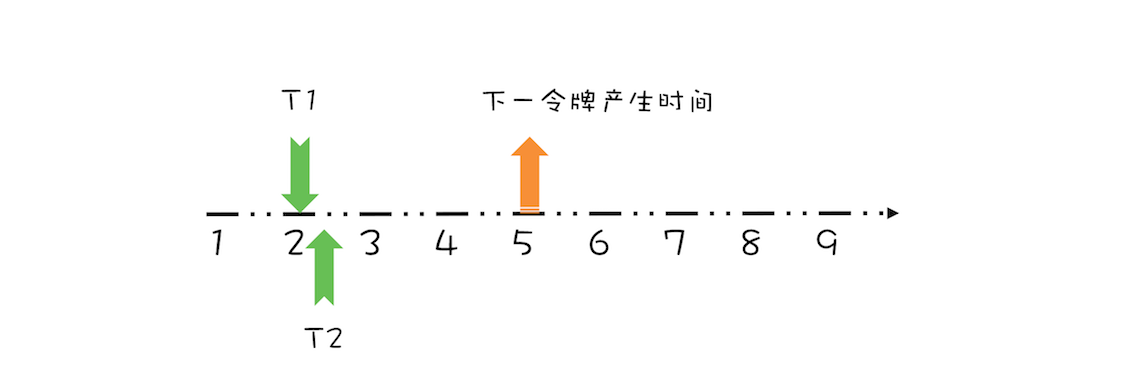
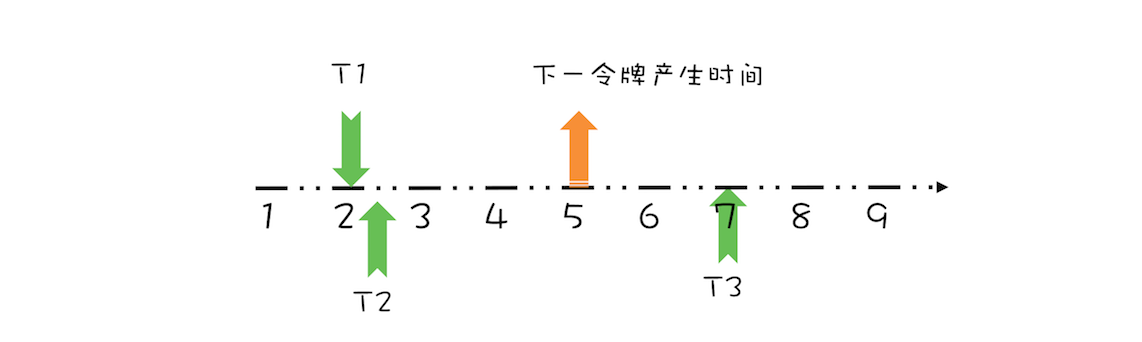
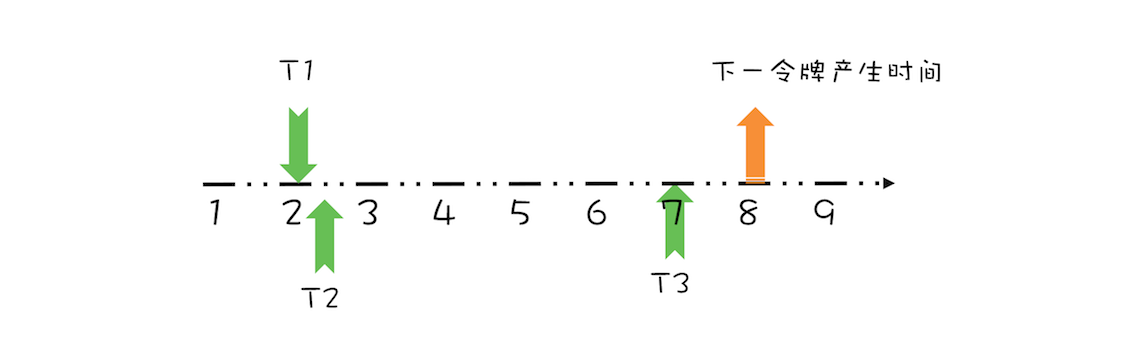
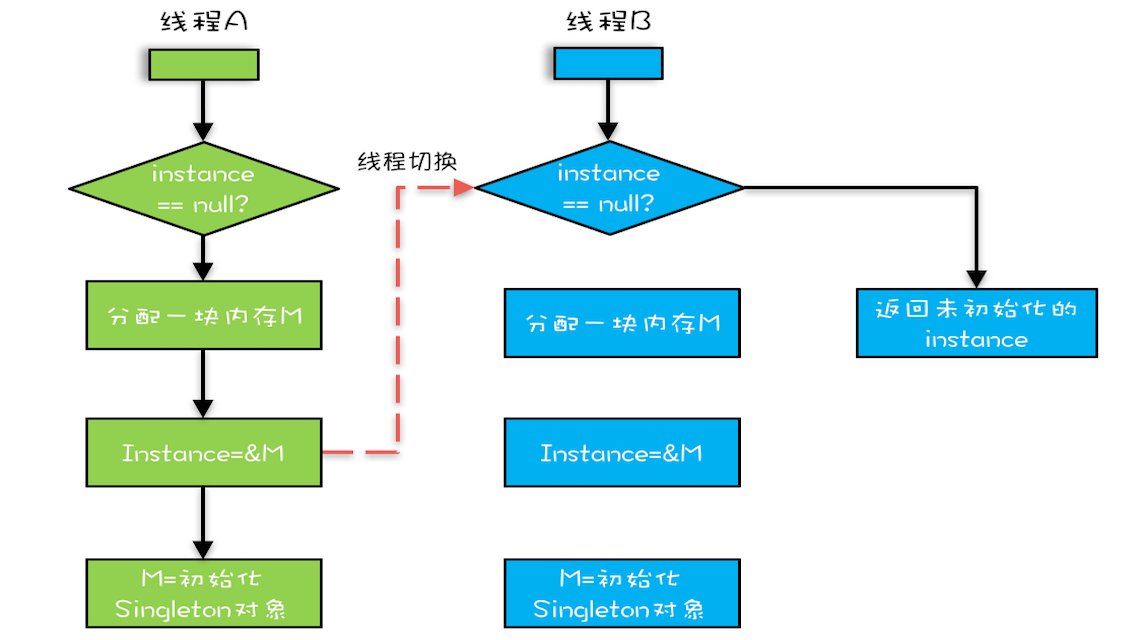
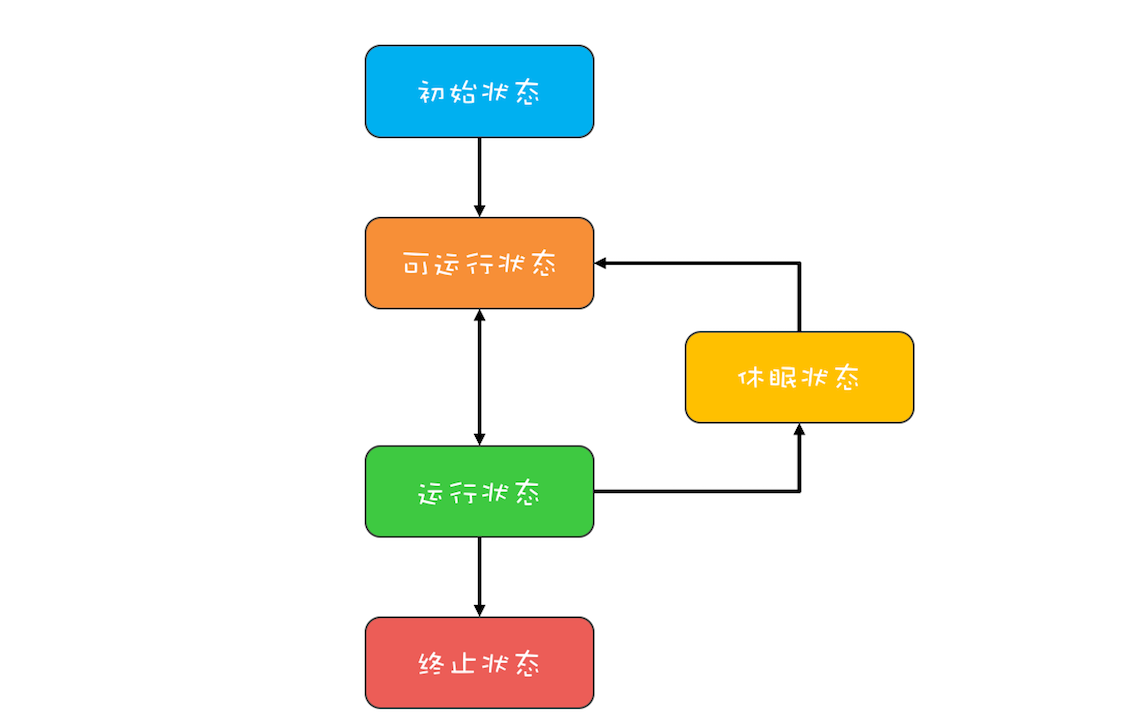
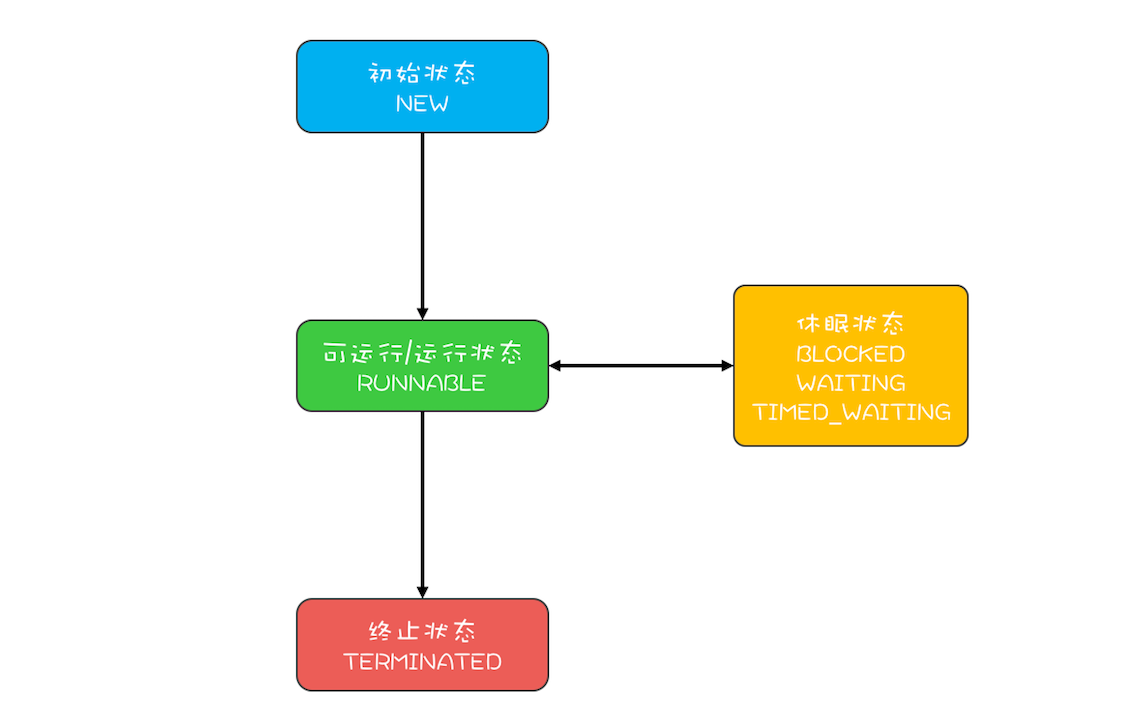
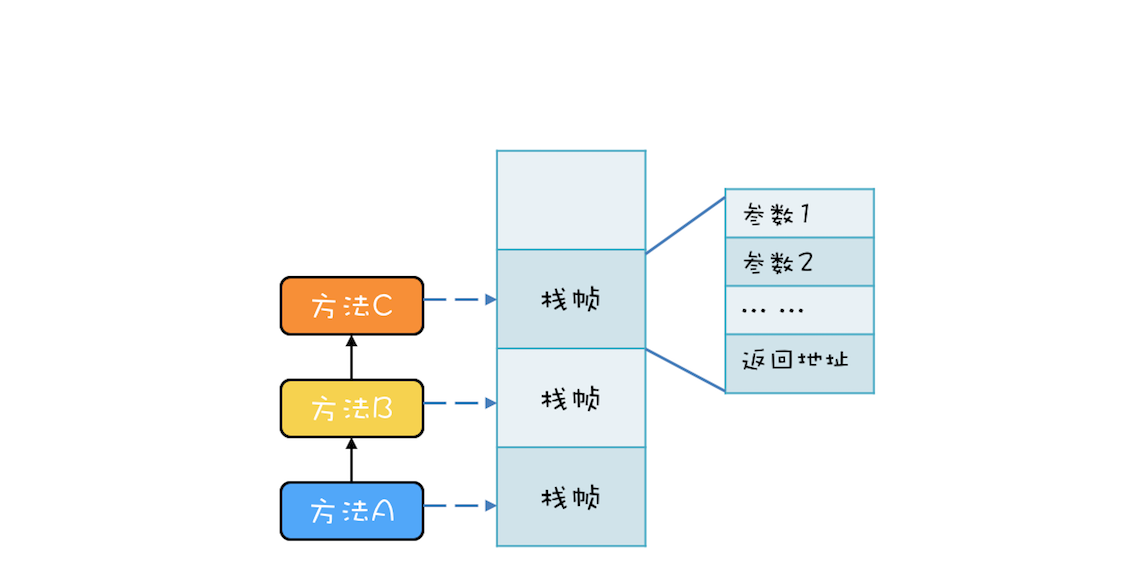
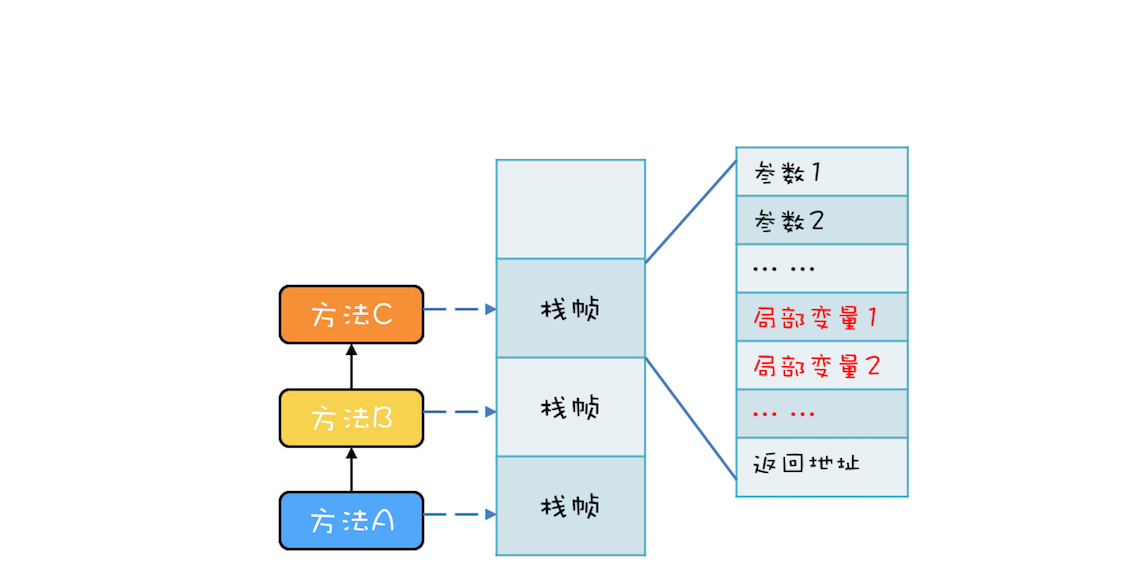
 “CPU 去哪里找到调用方法的参数和返回地址?
“CPU 去哪里找到调用方法的参数和返回地址?