如果不想使用 Spring 框架的 WebSocket API,你也可以选择基本的 javax.websocket。
首先,需要引入 API jar 包。
1 2 3 4 5 6
<!-- To write basic javax.websocket against --> <dependency> <groupId>javax.websocket</groupId> <artifactId>javax.websocket-api</artifactId> <version>1.0</version> </dependency>
如果使用嵌入式 jetty,你还需要引入它的实现包:
1 2 3 4 5 6 7 8 9 10 11 12
<!-- To run javax.websocket in embedded server --> <dependency> <groupId>org.eclipse.jetty.websocket</groupId> <artifactId>javax-websocket-server-impl</artifactId> <version>${jetty-version}</version> </dependency> <!-- To run javax.websocket client --> <dependency> <groupId>org.eclipse.jetty.websocket</groupId> <artifactId>javax-websocket-client-impl</artifactId> <version>${jetty-version}</version> </dependency>
server { # this section is specific to the WebSockets proxying location /socket.io { proxy_pass http://app_server_wsgiapp/socket.io; proxy_redirectoff;
<projectxmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <!-- "Project Build" contains more elements than just the BaseBuild set --> <build>...</build>
<profiles> <profile> <!-- "Profile Build" contains a subset of "Project Build"s elements --> <build>...</build> </profile> </profiles> </project>
C:\Program Files (x86)\GnuPG\bin>gpg --version gpg (GnuPG) 2.2.10 libgcrypt 1.8.3 Copyright (C) 2018 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <https://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the exdunwu permitted by law.
C:\Program Files (x86)\GnuPG\bin>gpg --gen-key gpg (GnuPG) 2.2.10; Copyright (C) 2018 Free Software Foundation, Inc. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the exdunwu permitted by law.
Note: Use "gpg --full-generate-key" for a full featured key generation dialog.
GnuPG needs to construct a user ID to identify your key.
Real name: Zhang Peng Email address: forbreak@163.com You selected this USER-ID: "Zhang Peng <forbreak@163.com>"
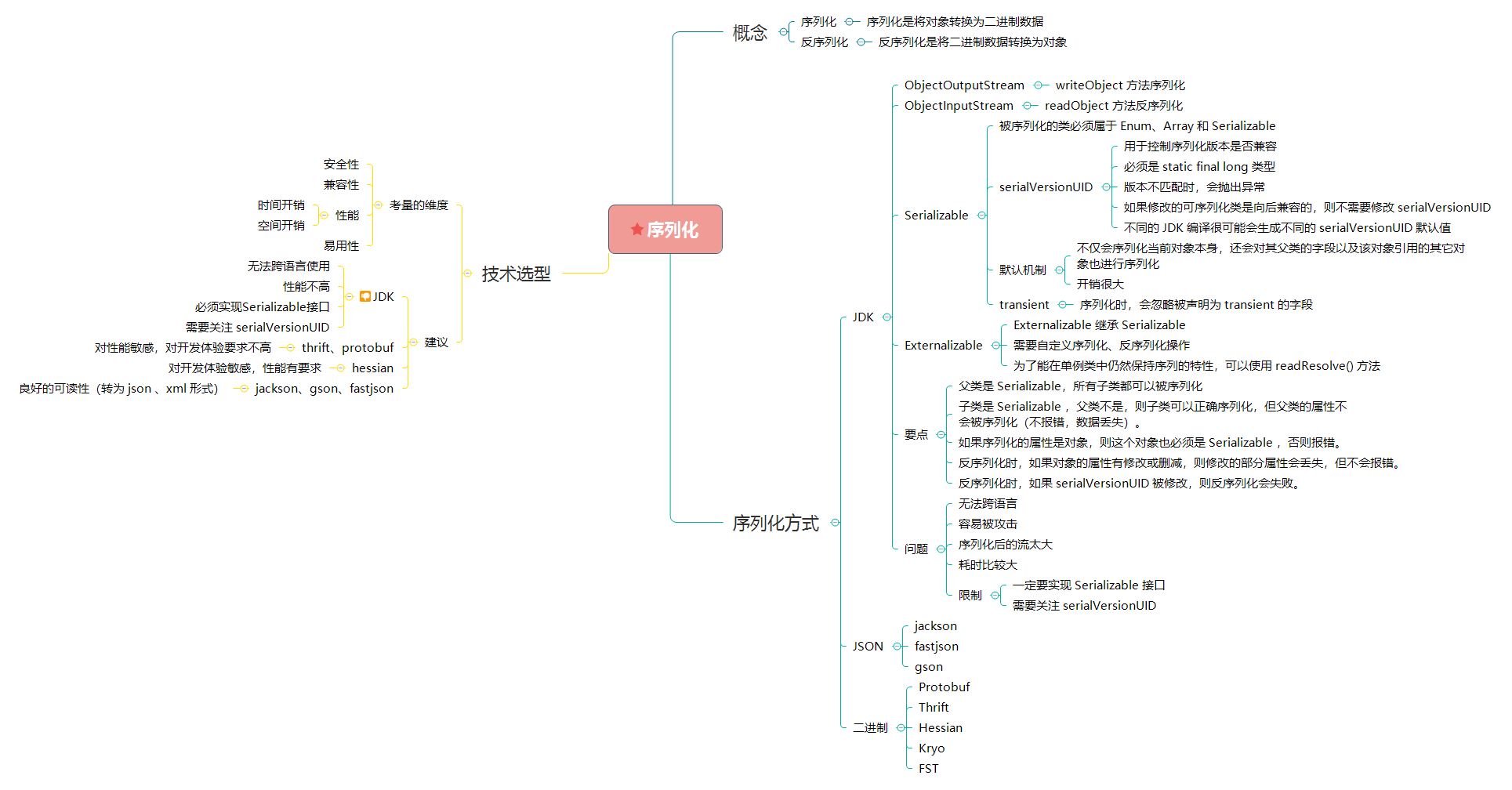
值得注意的是,从文件中获取的 Person 对象与 Person 类中的单例对象并不相等。为了能在单例类中仍然保持序列的特性,可以使用 readResolve() 方法。在该方法中直接返回 Person 的单例对象。我们在 SerializeDemo04 示例的基础上添加一个 readResolve 方法, 如下所示:
当然,还有很多可以在 XML 文件中配置的选项,上面的示例仅罗列了最关键的部分。 注意 XML 头部的声明,它用来验证 XML 文档的正确性。environment 元素体中包含了事务管理和连接池的配置。mappers 元素则包含了一组映射器(mapper),这些映射器的 XML 映射文件包含了 SQL 代码和映射定义信息。
不使用 XML 构建 SqlSessionFactory
如果你更愿意直接从 Java 代码而不是 XML 文件中创建配置,或者想要创建你自己的配置构建器,MyBatis 也提供了完整的配置类,提供了所有与 XML 文件等价的配置项。
在上面提到的例子中,一个语句既可以通过 XML 定义,也可以通过注解定义。我们先看看 XML 定义语句的方式,事实上 MyBatis 提供的所有特性都可以利用基于 XML 的映射语言来实现,这使得 MyBatis 在过去的数年间得以流行。如果你用过旧版本的 MyBatis,你应该对这个概念比较熟悉。 但相比于之前的版本,新版本改进了许多 XML 的配置,后面我们会提到这些改进。这里给出一个基于 XML 映射语句的示例,它应该可以满足上个示例中 SqlSession 的调用。
1 2 3 4 5 6 7 8 9
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC"-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mappernamespace="org.mybatis.example.BlogMapper"> <selectid="selectBlog"resultType="Blog"> select * from Blog where id = #{id} </select> </mapper>
很多人习惯鼠标使用相反的滚动方向,而触控板类似 iPad 那样的自然滚动,问如何设置,当时我的回答是不知道,因为目前 OS X 的系统设置里,鼠标和触控板的设置是统一 的。今天发现了一个免费的软件 Scroll Reverser,可以实现鼠标和触控板的分别设置。下载地址:https://pilotmoon.com/scrollreverser/ 启动后程序显示在顶部菜单栏,设置简单明了,有需要的用户体验一下吧。
Touch Bar 自定义
打开“系统偏好设置-键盘”,下面有个自定义控制条。
色温调节:夜间模式
iOS9.3 的最明显变化,莫过于苹果在发布会上特意提到的 Night Shift 夜间护眼模式。
iCloud 邮箱
如果您用于设置 iCloud 的 Apple ID 不以“@icloud.com”、“@me.com”或“@mac.com”结尾,您必须先设置一个“@icloud.com”电子邮件地址,然后才能使用 iCloud“邮件”。