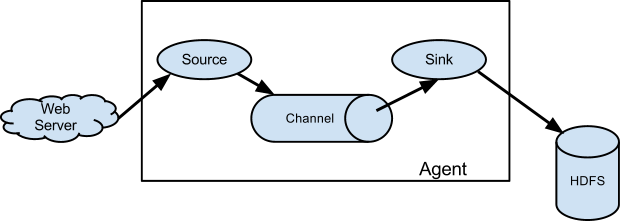
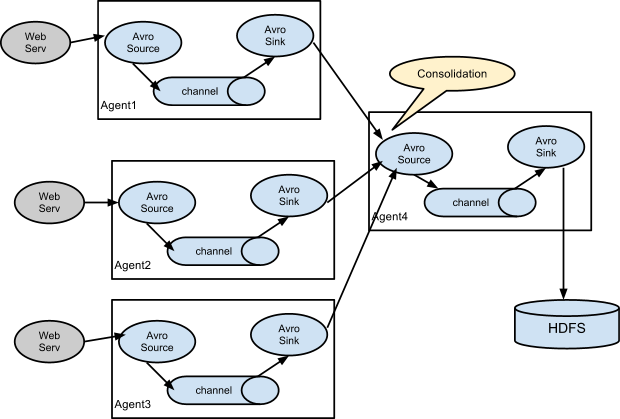
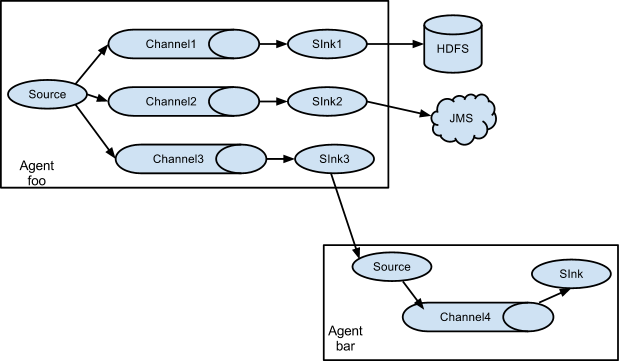
Apache Flume 是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以 NG 为基础。
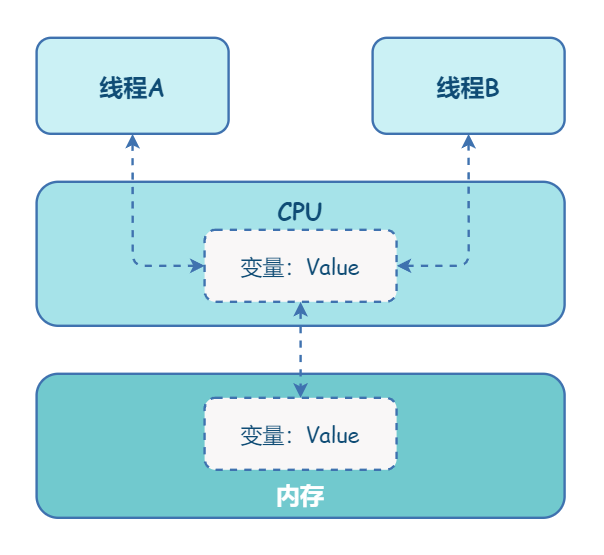
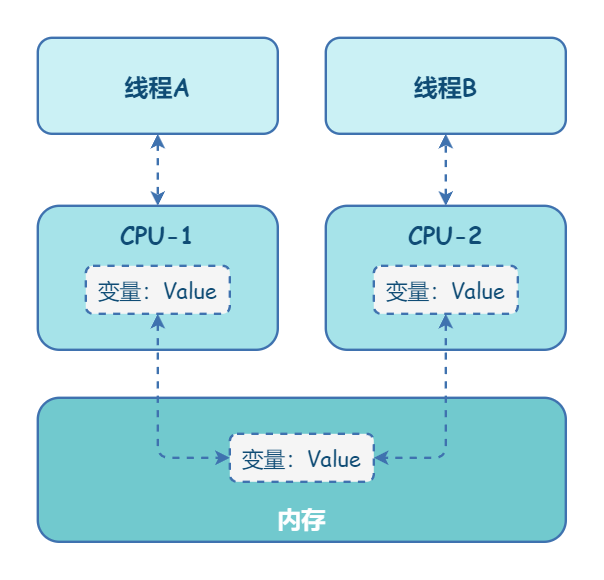
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。
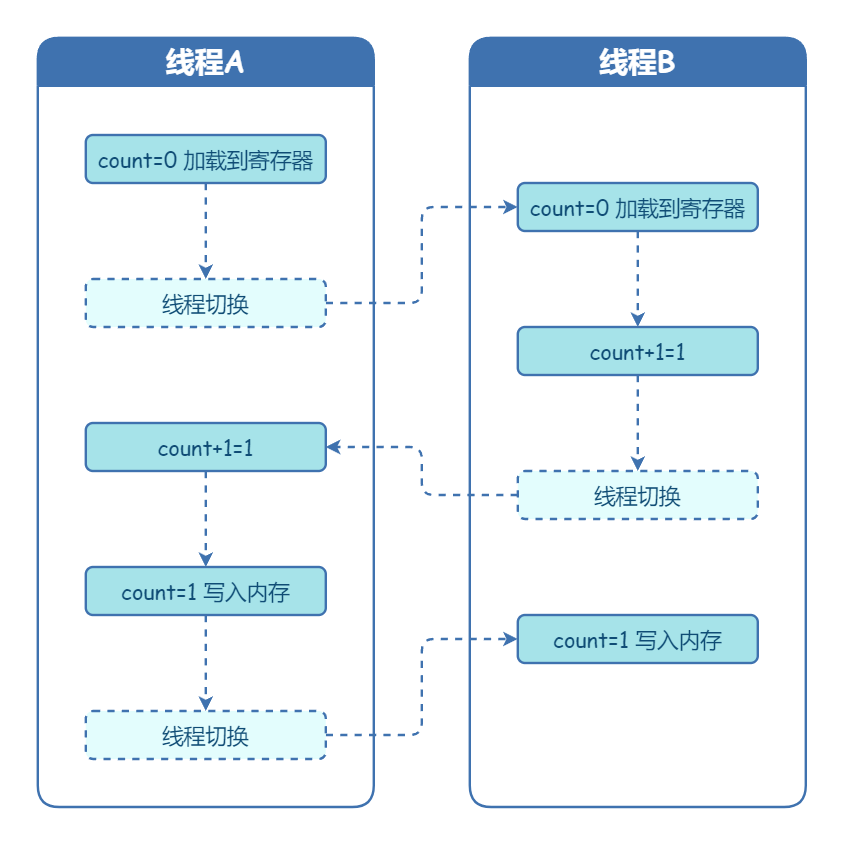
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
Exception in thread "main" java.lang.ArithmeticException: / by zero at io.github.dunwu.javacore.exception.RumtimeExceptionDemo01.main(RumtimeExceptionDemo01.java:6)
Exception in thread "main" io.github.dunwu.javacore.exception.MyExceptionDemo$MyException: 自定义异常 at io.github.dunwu.javacore.exception.MyExceptionDemo.main(MyExceptionDemo.java:9)
// 反射获取 digits 方法成功 java.lang.NoSuchMethodException: java.lang.String.toString(int) at java.lang.Class.getMethod(Class.java:1786) at io.github.dunwu.javacore.exception.ThrowsDemo.f1(ThrowsDemo.java:12) at io.github.dunwu.javacore.exception.ThrowsDemo.f2(ThrowsDemo.java:21) at io.github.dunwu.javacore.exception.ThrowsDemo.main(ThrowsDemo.java:30)
Exception in thread "main" io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException2: 出现 MyException2 at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:29) at io.github.dunwu.javacore.exception.ExceptionChainDemo.main(ExceptionChainDemo.java:34) Caused by: io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException1: 出现 MyException1 at io.github.dunwu.javacore.exception.ExceptionChainDemo.f1(ExceptionChainDemo.java:22) at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:27) ... 1 more
Integera=127; //Integer.valueOf(127) Integerb=127; //Integer.valueOf(127) log.info("\nInteger a = 127;\nInteger b = 127;\na == b ? {}", a == b); // true
Integerc=128; //Integer.valueOf(128) Integerd=128; //Integer.valueOf(128) log.info("\nInteger c = 128;\nInteger d = 128;\nc == d ? {}", c == d); //false //设置-XX:AutoBoxCacheMax=1000再试试
Integere=127; //Integer.valueOf(127) Integerf=newInteger(127); //new instance log.info("\nInteger e = 127;\nInteger f = new Integer(127);\ne == f ? {}", e == f); //false
Integerg=newInteger(127); //new instance Integerh=newInteger(127); //new instance log.info("\nInteger g = new Integer(127);\nInteger h = new Integer(127);\ng == h ? {}", g == h); //false
Integeri=128; //unbox intj=128; log.info("\nInteger i = 128;\nint j = 128;\ni == j ? {}", i == j); //true
static { // high value may be configured by property inth=127; StringintegerCacheHighPropValue= sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { inti= parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h;
Stringa="1"; Stringb="1"; log.info("\nString a = \"1\";\nString b = \"1\";\na == b ? {}", a == b); //true
Stringc=newString("2"); Stringd=newString("2"); log.info("\nString c = new String(\"2\");\nString d = new String(\"2\");\nc == d ? {}", c == d); //false
Stringe=newString("3").intern(); Stringf=newString("3").intern(); log.info("\nString e = new String(\"3\").intern();\nString f = new String(\"3\").intern();\ne == f ? {}", e == f); //true
Stringg=newString("4"); Stringh=newString("4"); log.info("\nString g = new String(\"4\");\nString h = new String(\"4\");\ng == h ? {}", g.equals(h)); //true