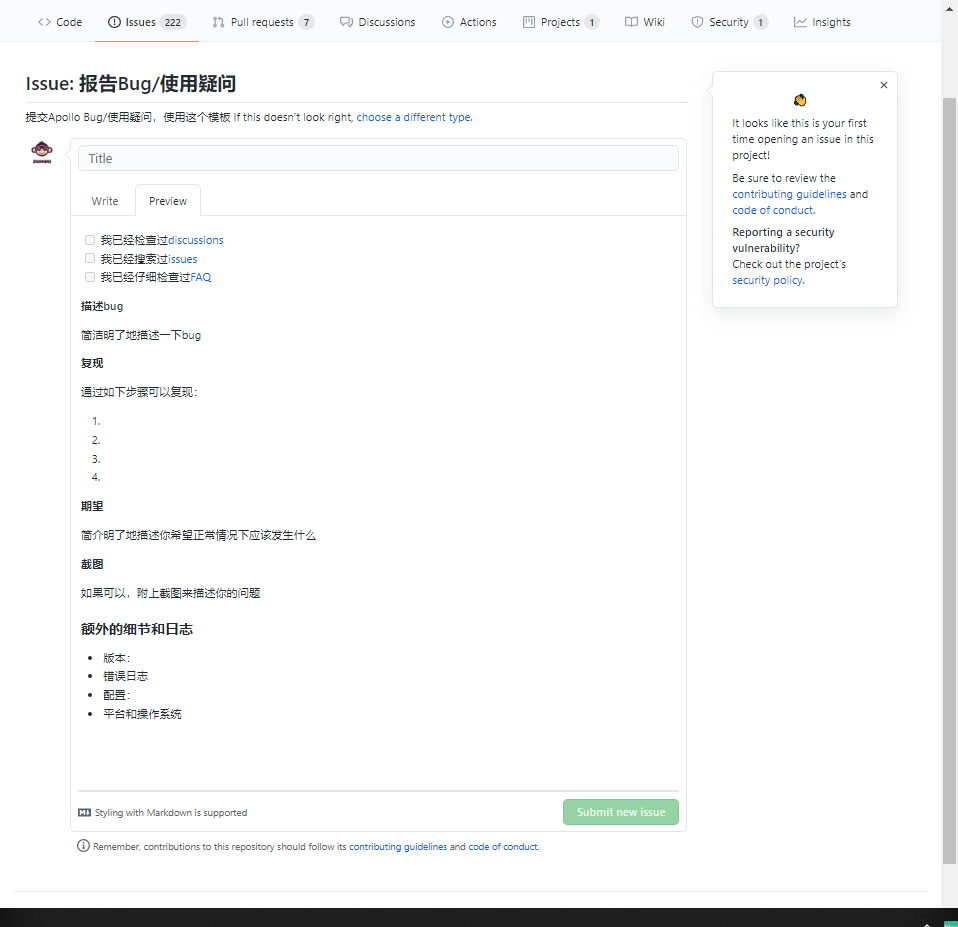
===========PrintallColor=========== RED ordinal:0 GREEN ordinal:1 BLUE ordinal:2 ===========PrintallSize=========== BIG ordinal:0 MIDDLE ordinal:1 SMALL ordinal:2 green name():GREEN green getDeclaringClass():classorg.zp.javase.enumeration.EnumDemo$Color green hashCode():460141958 green compareTo Color.GREEN:0 green equals Color.GREEN:true green equals Size.MIDDLE:false green equals 1:false green==Color.BLUE:false
枚举的特性
枚举的特性,归结起来就是一句话:
除了不能继承,基本上可以将 enum 看做一个常规的类。
但是这句话需要拆分去理解,让我们细细道来。
基本特性
如果枚举中没有定义方法,也可以在最后一个实例后面加逗号、分号或什么都不加。
如果枚举中没有定义方法,枚举值默认为从 0 开始的有序数值。以 Color 枚举类型举例,它的枚举常量依次为 RED:0,GREEN:1,BLUE:2。
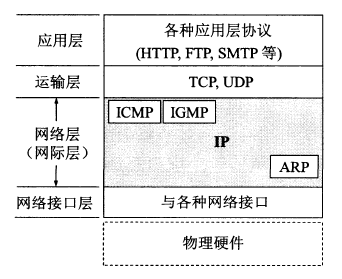
java.lang.reflect 包下主要包含一些实现反射功能的工具类。实际上,java.lang.reflect 包所有提供的反射 API 扩充了读取运行时注解信息的能力。当一个注解类型被定义为运行时的注解后,该注解才能是运行时可见,当 class 文件被装载时被保存在 class 文件中的注解才会被虚拟机读取。 AnnotatedElement 接口是所有程序元素(Class、Method 和 Constructor)的父接口,所以程序通过反射获取了某个类的AnnotatedElement 对象之后,程序就可以调用该对象的如下四个个方法来访问注解信息:
Sets the maximum permanent generation space size (inbytes). This option was deprecated in JDK 8, and superseded bythe -XX:MaxMetaspaceSize option.
-XX:PermSize=size
Sets thespace (inbytes) allocated tothe permanent generation that triggers a garbage collection ifit is exceeded. This option was deprecated un JDK 8, and superseded bythe -XX:MetaspaceSize option.
Sets the size of the allocated class metadata space that will trigger a garbage collection the first time it is exceeded. This threshold for a garbage collection is increased or decreased depending on the amount of metadata used. The default size depends on the platform.
-XX:MaxMetaspaceSize=size
Sets the maximum amount of native memory that can be allocated for class metadata. By default, the size is not limited. The amount of metadata for an application depends on the application itself, other running applications, and the amount of memory available on the system.
以下示例显示如何将类类元数据的上限设置为 256 MB:
XX:MaxMetaspaceSize=256m
字节码问题
ASM 5.0 beta 开始支持 JDK8
字节码错误
1 2
Caused by: java.io.IOException: invalid constant type: 15 at javassist.bytecode.ConstPool.readOne(ConstPool.java:1113)
说明:logger.debug("Processing trade with id: " + id + " and symbol: " + symbol); 如果日志级别是 warn,上述日志不会打印,但是会执行字符串拼接操作,如果 symbol 是对象,会执行 toString()方法,浪费了系统资源,执行了上述操作,最终日志却没有打印。
正例:(条件)
1 2 3
if (logger.isDebugEnabled()) { logger.debug("Processing trade with id: " + id + " and symbol: " + symbol); }
正例:(占位符)
1
logger.debug("Processing trade with id: {} and symbol : {} ", id, symbol);
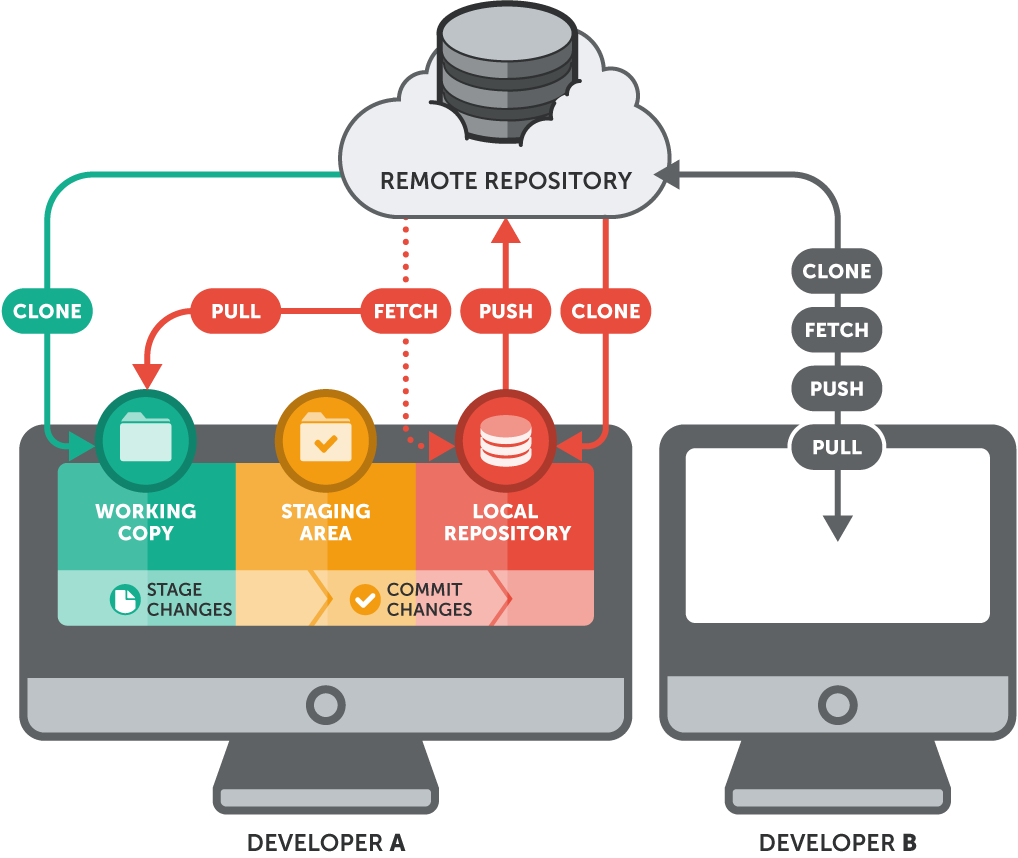
$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/schacon/.ssh/id_rsa): Created directory '/home/schacon/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/schacon/.ssh/id_rsa. Your public key has been saved in /home/schacon/.ssh/id_rsa.pub. The key fingerprint is: d0:82:24:8e:d7:f1:bb:9b:33:53:96:93:49:da:9b:e3 schacon@mylaptop.local
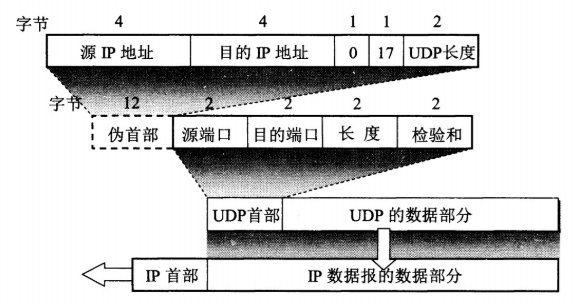
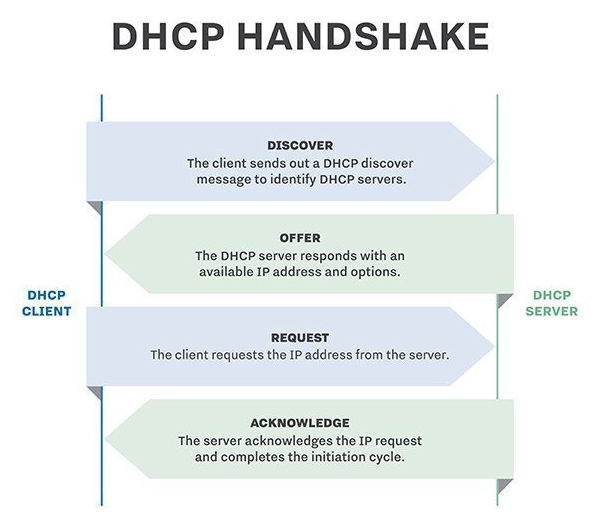
该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:FF:FF:FF:FF:FF,将广播到与交换机连接的所有设备。
连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
ARP 解析 MAC 地址
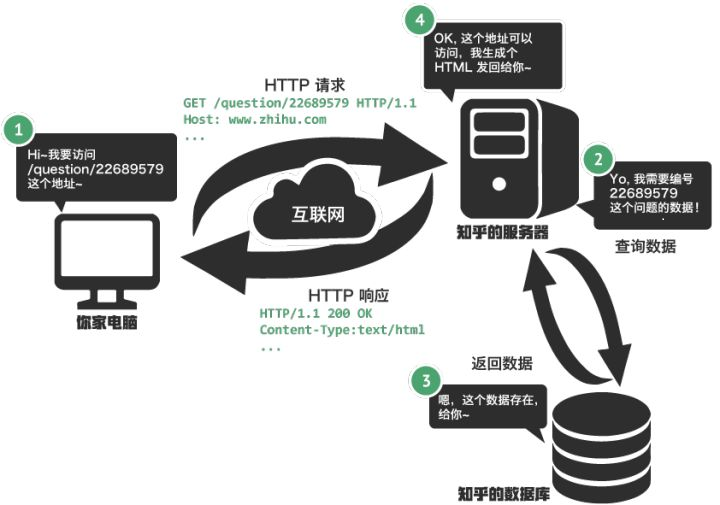
主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:FF:FF:FF:FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
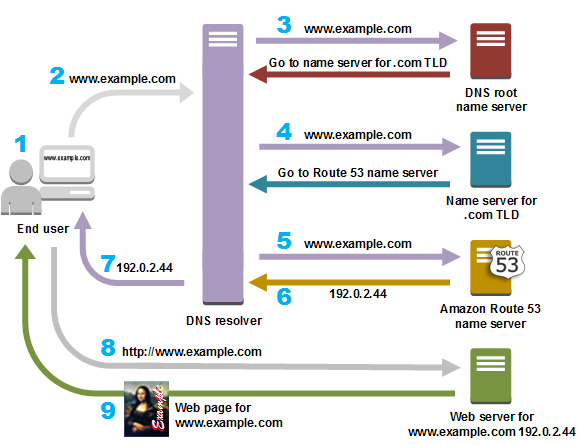
DNS 解析域名
知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
HTTP 请求页面
有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
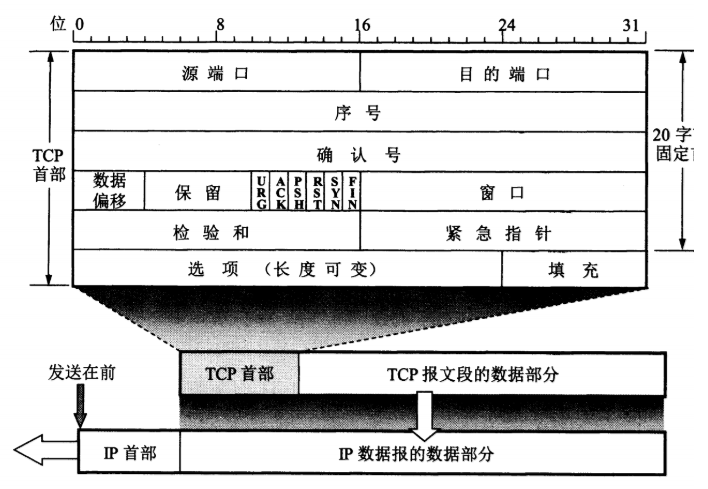
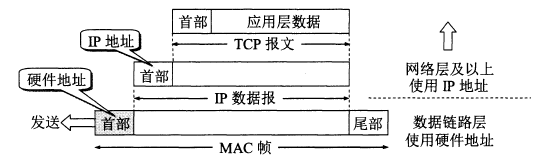
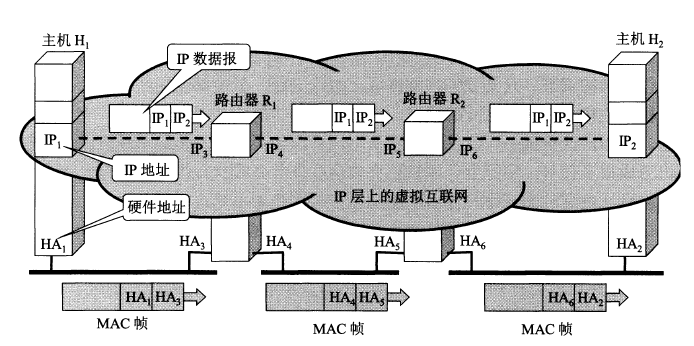
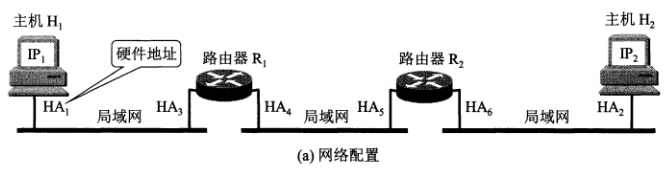
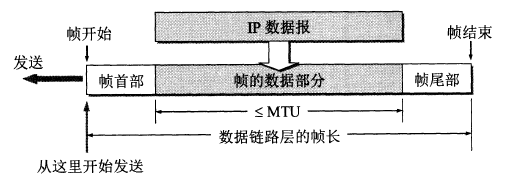
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
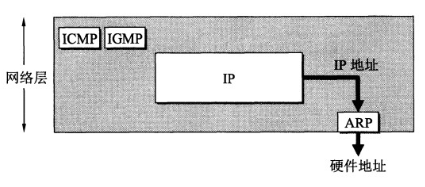
ARP 实现由 IP 地址得到 MAC 地址。
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
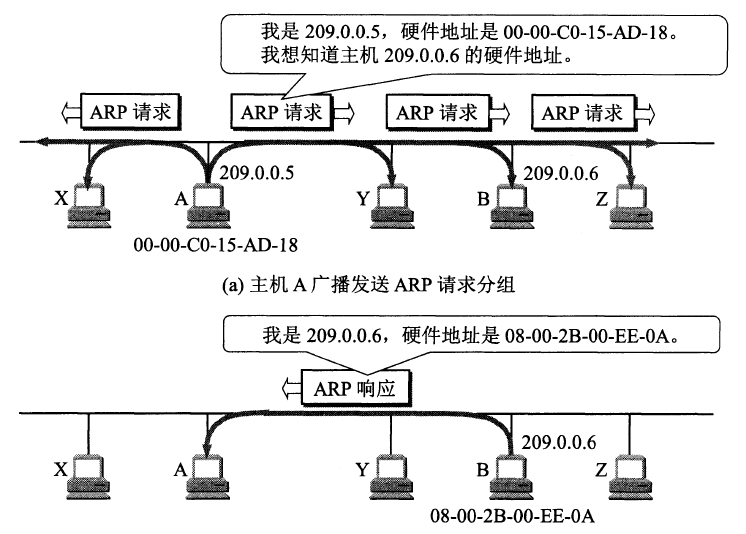
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
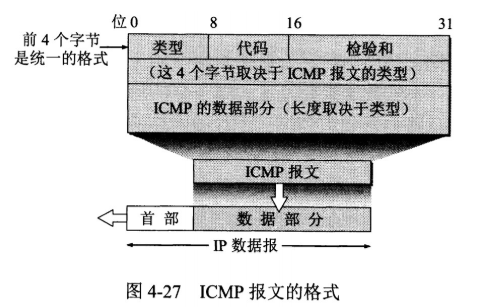
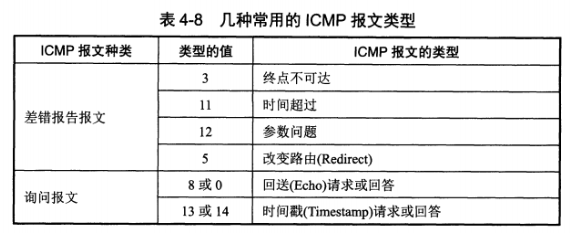
网际控制报文协议 ICMP
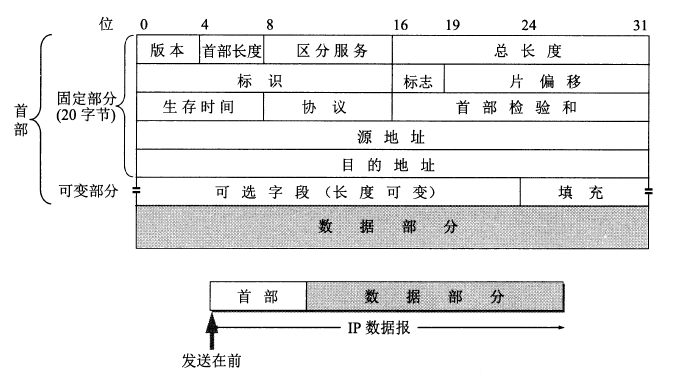
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
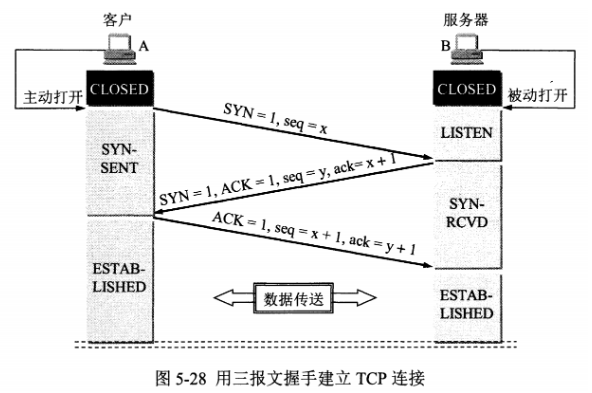
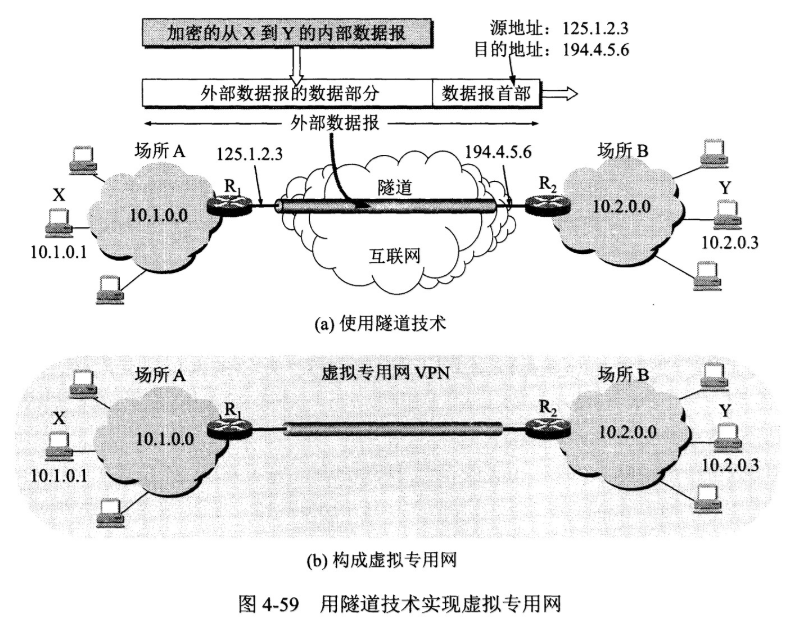
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
网络地址转换 NAT
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
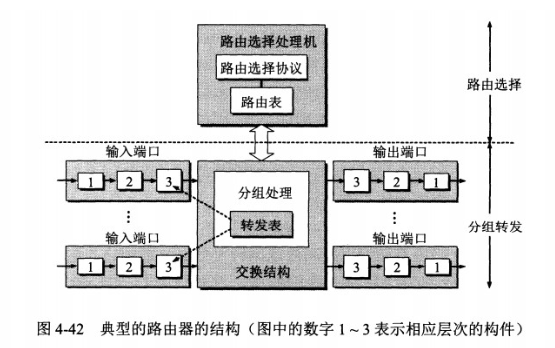
路由器的结构
路由器从功能上可以划分为:路由选择和分组转发。
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
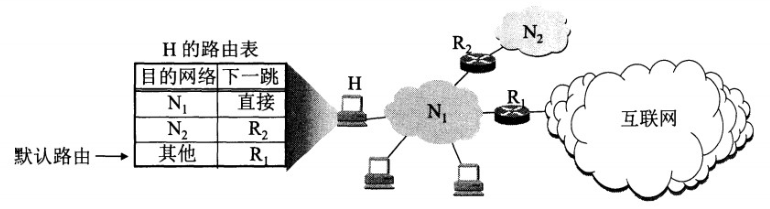
路由器分组转发流程
从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
报告转发分组出错。
路由选择协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
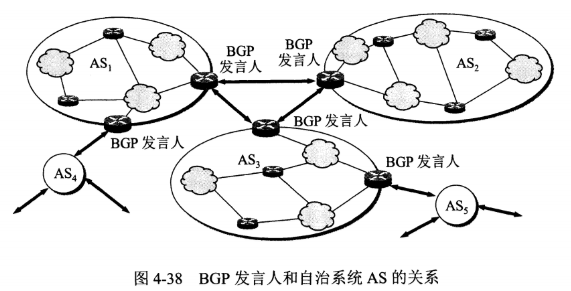
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。