@Override public List<User> list() { return jdbcTemplate.query("SELECT * FROM user", newBeanPropertyRowMapper<>(User.class)); }
@Override public User queryByName(String name) { try { return jdbcTemplate.queryForObject("SELECT * FROM user WHERE name = ?", newBeanPropertyRowMapper<>(User.class), name); } catch (EmptyResultDataAccessException e) { returnnull; } }
@Override public JdbcTemplate getJdbcTemplate() { return jdbcTemplate; }
public User queryByName(String name) { try { return jdbcTemplate .queryForObject("SELECT * FROM user WHERE name = ?", newBeanPropertyRowMapper<>(User.class), name); } catch (EmptyResultDataAccessException e) { returnnull; } }
查多个对象
1 2 3
public List<User> list() { return jdbcTemplate.query("select * from USER", newBeanPropertyRowMapper(User.class)); }
获取某个记录某列或者 count、avg、sum 等函数返回唯一值
1 2 3 4 5 6 7
public Integer count() { try { return jdbcTemplate.queryForObject("SELECT COUNT(*) FROM user", Integer.class); } catch (EmptyResultDataAccessException e) { returnnull; } }
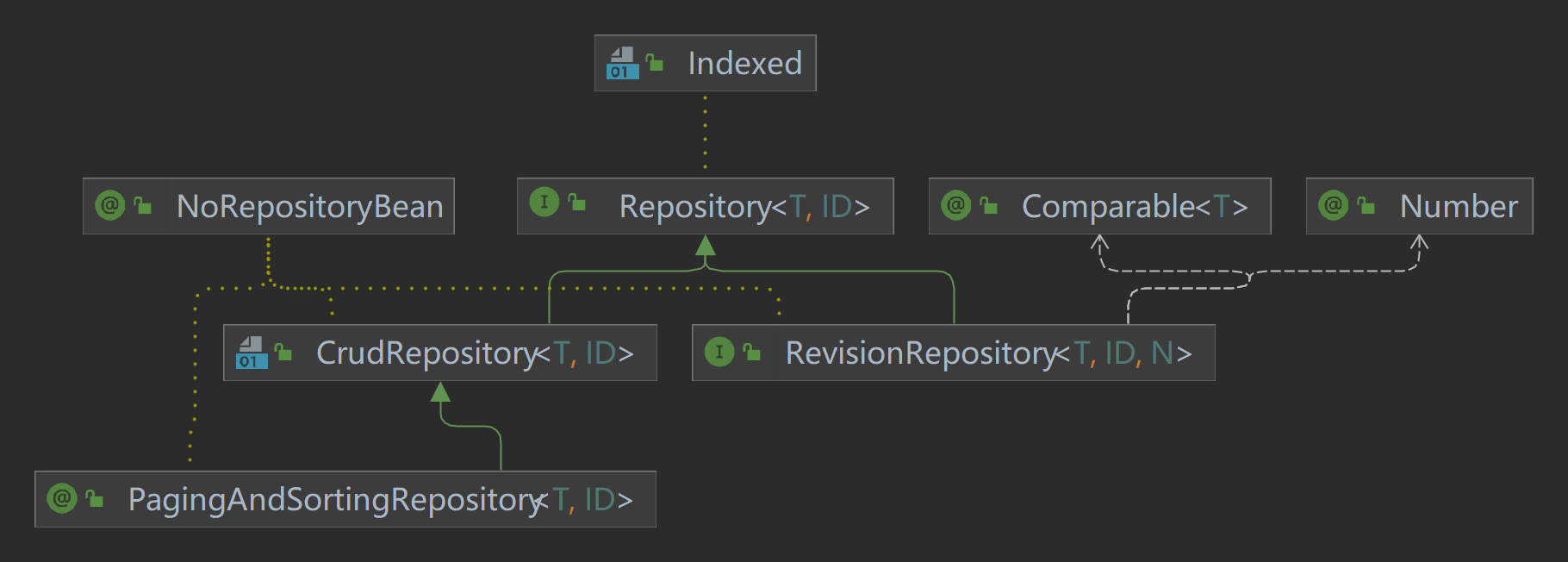
Spring Data 项目包含了对 JDBC 的存储库支持,并将自动为 CrudRepository 上的方法生成 SQL。对于更高级的查询,提供了 @Query 注解。
当 classpath 上存在必要的依赖项时,Spring Boot 将自动配置 Spring Data 的 JDBC 存储库。它们可以通过 spring-boot-starter-data-jdbc 的单一依赖项添加到项目中。如有必要,可以通过将 @EnableJdbcRepositories 批注或 JdbcConfiguration 子类添加到应用程序来控制 Spring Data JDBC 的配置。
… where x.firstname like ?1 (parameter bound with appended %)
EndingWith
findByFirstnameEndingWith
… where x.firstname like ?1 (parameter bound with prepended %)
Containing
findByFirstnameContaining
… where x.firstname like ?1 (parameter bound wrapped in %)
OrderBy
findByAgeOrderByLastnameDesc
… where x.age = ?1 order by x.lastname desc
Not
findByLastnameNot
… where x.lastname <> ?1
In
findByAgeIn(Collection<Age> ages)
… where x.age in ?1
NotIn
findByAgeNotIn(Collection<Age> age)
… where x.age not in ?1
True
findByActiveTrue()
… where x.active = true
False
findByActiveFalse()
… where x.active = false
IgnoreCase
findByFirstnameIgnoreCase
… where UPPER(x.firstame) = UPPER(?1)
@Query 注解方式查询
注解 @Query 允许在方法上使用 JPQL。
其中操作针对的是对象名和对象属性名,而非数据库中的表名和字段名。
1 2
@Query("select u form User u where u.name=?1 and u.depantment.id=?2"); public User findUser(String name, Integer departmentId);
1 2
@Query("form User u where u.name=?1 and u.depantment.id=?2"); public User findUser(String name, Integer departmentId);
如果使用 SQL 而不是 JPSQL,可以使用 nativeQuery 属性,设置为 true。
1 2
@Query(value="select * from user where name=?1 and department_id=?2", nativeQuery=true) public User nativeQuery(String name, Integer departmentId);
无论 JPQL,还是 SQL,都支持”命名参数”:
1 2
@Query(value="select * from user where name=:name and department_id=:departmentId", nativeQuery=true) public User nativeQuery2(String name, Integer departmentId);
public List<User> getByExample(String name) { Departmentdept=newDepartment(); dept.setId(1);
Useruser=newUser(); user.setName(name); user.setDepartment(dept); Example<User> example = Example.of(user); List<User> list = userDao.findAll(example); return list }
以上代码首先创建了 User 对象,设置 查询条件,名称为参数 name,部门 id 为 1,通过 Example.of 构造了此查询。
如果使用 Jackson 序列化和反序列化 JSON 数据,您可能需要编写自己的 JsonSerializer 和 JsonDeserializer 类。自定义序列化程序通常通过模块向 Jackson 注册,但 Spring Boot 提供了另一种 @JsonComponent 注释,可以更容易地直接注册 Spring Beans。
当 Spring Boot 的 json 库为 jackson 时,可以使用以下配置属性(对应 JacksonProperties 类):
1 2 3 4 5 6 7 8 9 10 11 12
spring.jackson.date-format= # Date format string or a fully-qualified date format class name. For instance, `yyyy-MM-dd HH:mm:ss`. spring.jackson.default-property-inclusion= # Controls the inclusion of properties during serialization. Configured with one of the values in Jackson's JsonInclude.Include enumeration. spring.jackson.deserialization.*= # Jackson on/off features that affect the way Java objects are deserialized. spring.jackson.generator.*= # Jackson on/off features for generators. spring.jackson.joda-date-time-format= # Joda date time format string. If not configured, "date-format" is used as a fallback if it is configured with a format string. spring.jackson.locale= # Locale used for formatting. spring.jackson.mapper.*= # Jackson general purpose on/off features. spring.jackson.parser.*= # Jackson on/off features for parsers. spring.jackson.property-naming-strategy= # One of the constants on Jackson's PropertyNamingStrategy. Can also be a fully-qualified class name of a PropertyNamingStrategy subclass. spring.jackson.serialization.*= # Jackson on/off features that affect the way Java objects are serialized. spring.jackson.time-zone= # Time zone used when formatting dates. For instance, "America/Los_Angeles" or "GMT+10". spring.jackson.visibility.*= # Jackson visibility thresholds that can be used to limit which methods (and fields) are auto-detected.
GSON 配置
当 Spring Boot 的 json 库为 gson 时,可以使用以下配置属性(对应 GsonProperties 类):
1 2 3 4 5 6 7 8 9 10 11
spring.gson.date-format= # Format to use when serializing Date objects. spring.gson.disable-html-escaping= # Whether to disable the escaping of HTML characters such as '<', '>', etc. spring.gson.disable-inner-class-serialization= # Whether to exclude inner classes during serialization. spring.gson.enable-complex-map-key-serialization= # Whether to enable serialization of complex map keys (i.e. non-primitives). spring.gson.exclude-fields-without-expose-annotation= # Whether to exclude all fields from consideration for serialization or deserialization that do not have the "Expose" annotation. spring.gson.field-naming-policy= # Naming policy that should be applied to an object's field during serialization and deserialization. spring.gson.generate-non-executable-json= # Whether to generate non executable JSON by prefixing the output with some special text. spring.gson.lenient= # Whether to be lenient about parsing JSON that doesn't conform to RFC 4627. spring.gson.long-serialization-policy= # Serialization policy for Long and long types. spring.gson.pretty-printing= # Whether to output serialized JSON that fits in a page for pretty printing. spring.gson.serialize-nulls= # Whether to serialize null fields.
Spring Boot 中使用 Fastjson
国内很多的 Java 程序员更喜欢使用阿里的 fastjson 作为 json lib。那么,如何在 Spring Boot 中将其替换默认的 jackson 库呢?
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
在 Spring 中,spring-data-mongodb 项目对访问 MongoDB 进行了 API 封装,提供了便捷的访问方式。 Spring Data MongoDB 的核心是一个以 POJO 为中心的模型,用于与 MongoDB DBCollection 交互并轻松编写 Repository 样式的数据访问层。
// save a couple of customers repository.save(newCustomer("Alice", "Smith")); repository.save(newCustomer("Bob", "Smith"));
// fetch all customers System.out.println("Customers found with findAll():"); System.out.println("-------------------------------"); for (Customer customer : repository.findAll()) { System.out.println(customer); } System.out.println();
// fetch an individual customer System.out.println("Customer found with findByFirstName('Alice'):"); System.out.println("--------------------------------"); System.out.println(repository.findByFirstName("Alice"));
System.out.println("Customers found with findByLastName('Smith'):"); System.out.println("--------------------------------"); for (Customer customer : repository.findByLastName("Smith")) { System.out.println(customer); } }
}
运行 DataMongodbApplication 的 main 方法后,输出类似如下类容:
1 2 3 4 5 6 7 8 9 10 11 12
Customers found with findAll(): ------------------------------- Customer(id=63d6157b265e7c5e48077f63, firstName=Alice, lastName=Smith) Customer(id=63d6157b265e7c5e48077f64, firstName=Bob, lastName=Smith) Customer found with findByFirstName('Alice'): -------------------------------- Customer(id=63d6157b265e7c5e48077f63, firstName=Alice, lastName=Smith) Customers found with findByLastName('Smith'): -------------------------------- Customer(id=63d6157b265e7c5e48077f63, firstName=Alice, lastName=Smith) Customer(id=63d6157b265e7c5e48077f64, firstName=Bob, lastName=Smith)