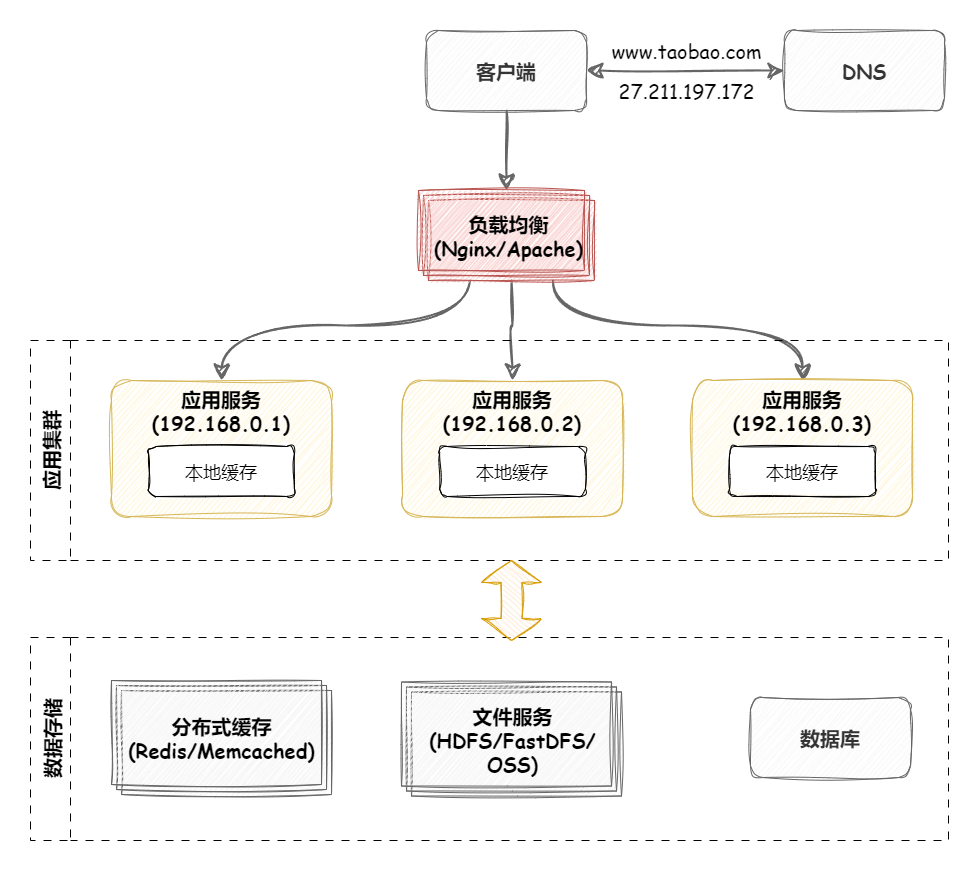
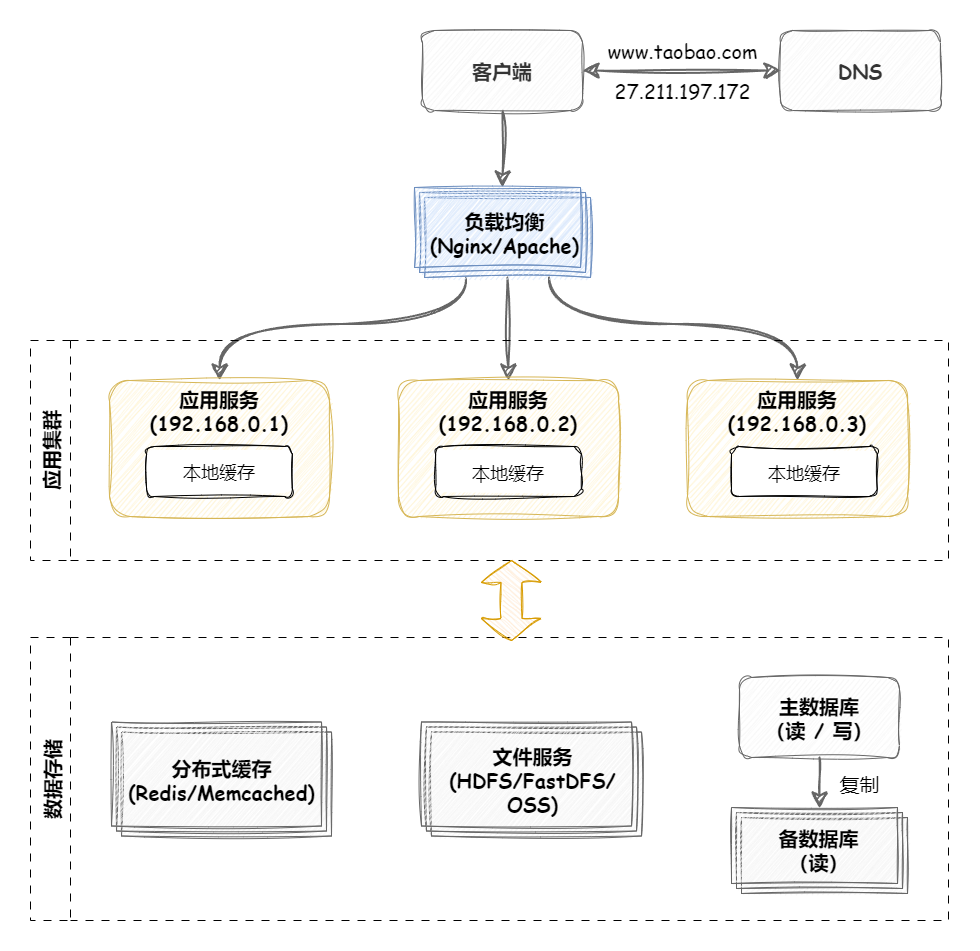
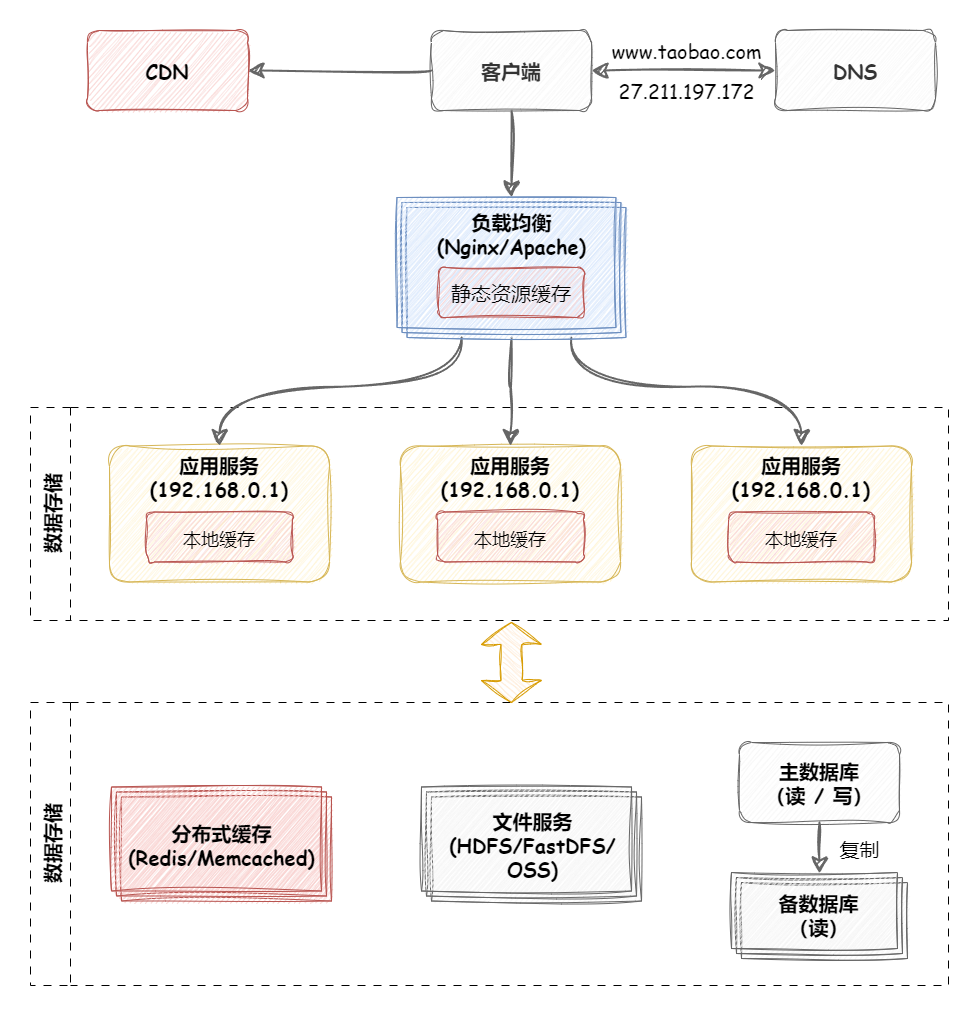
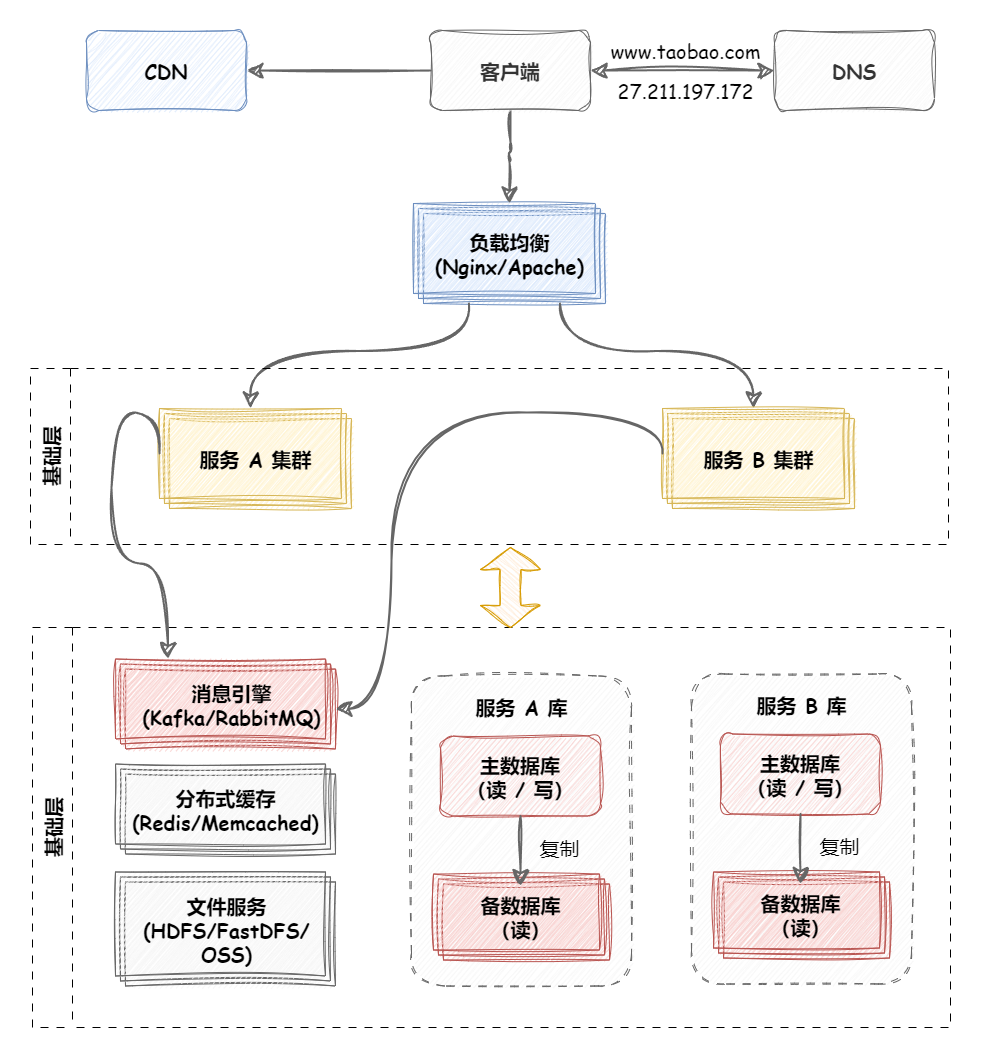
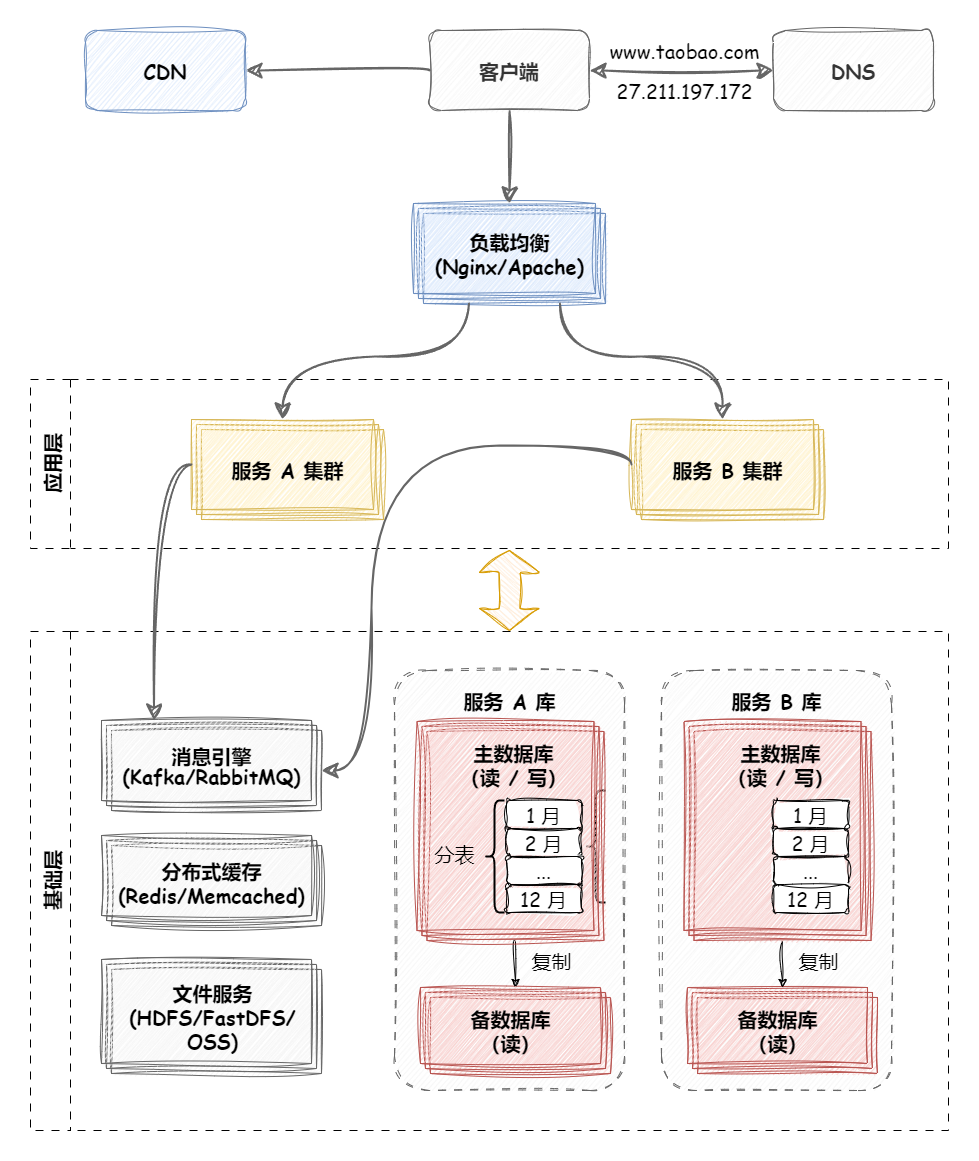
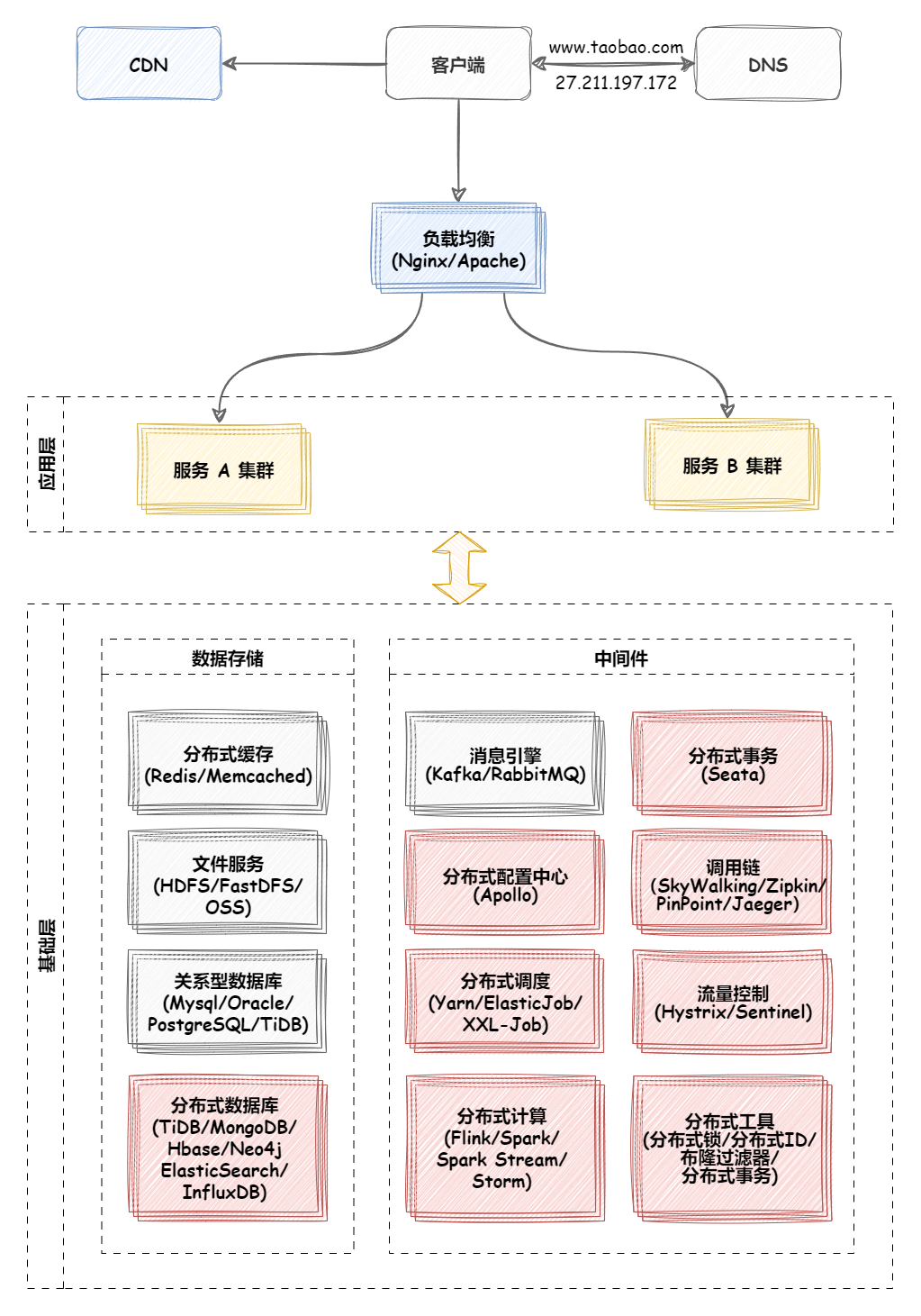
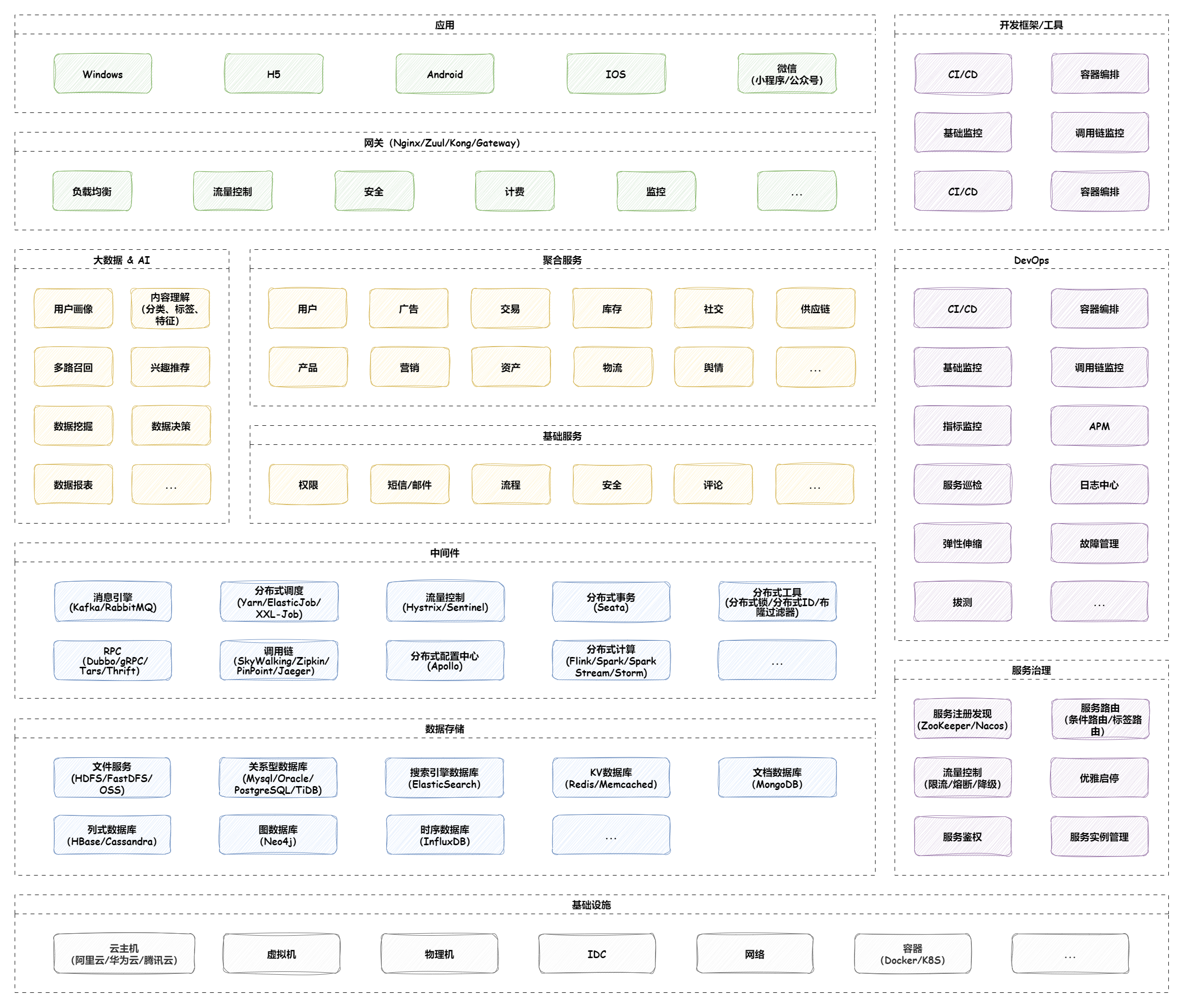
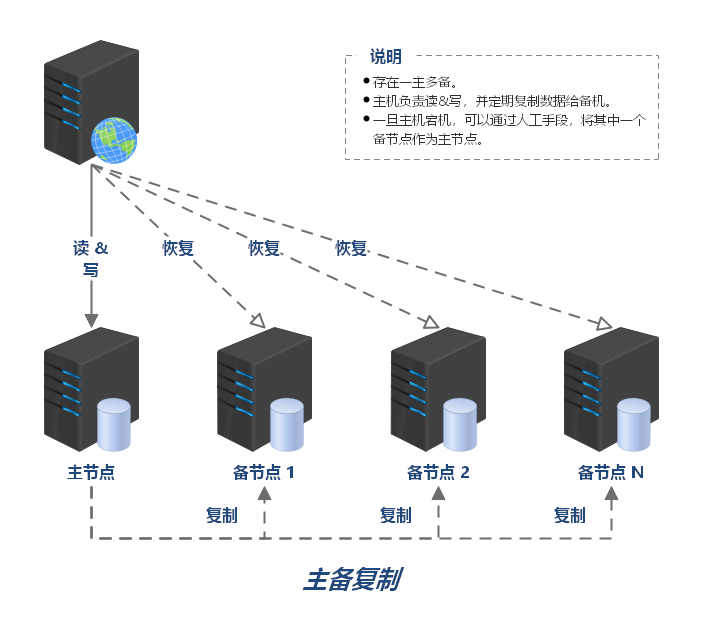
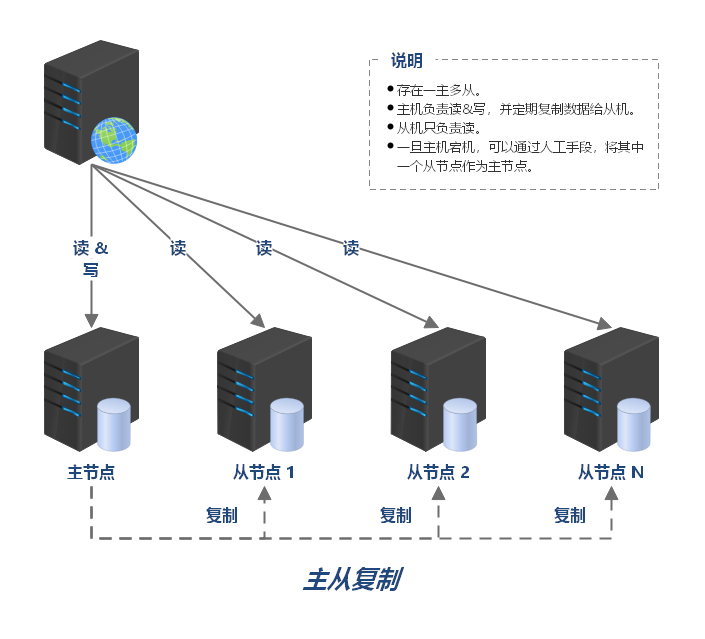
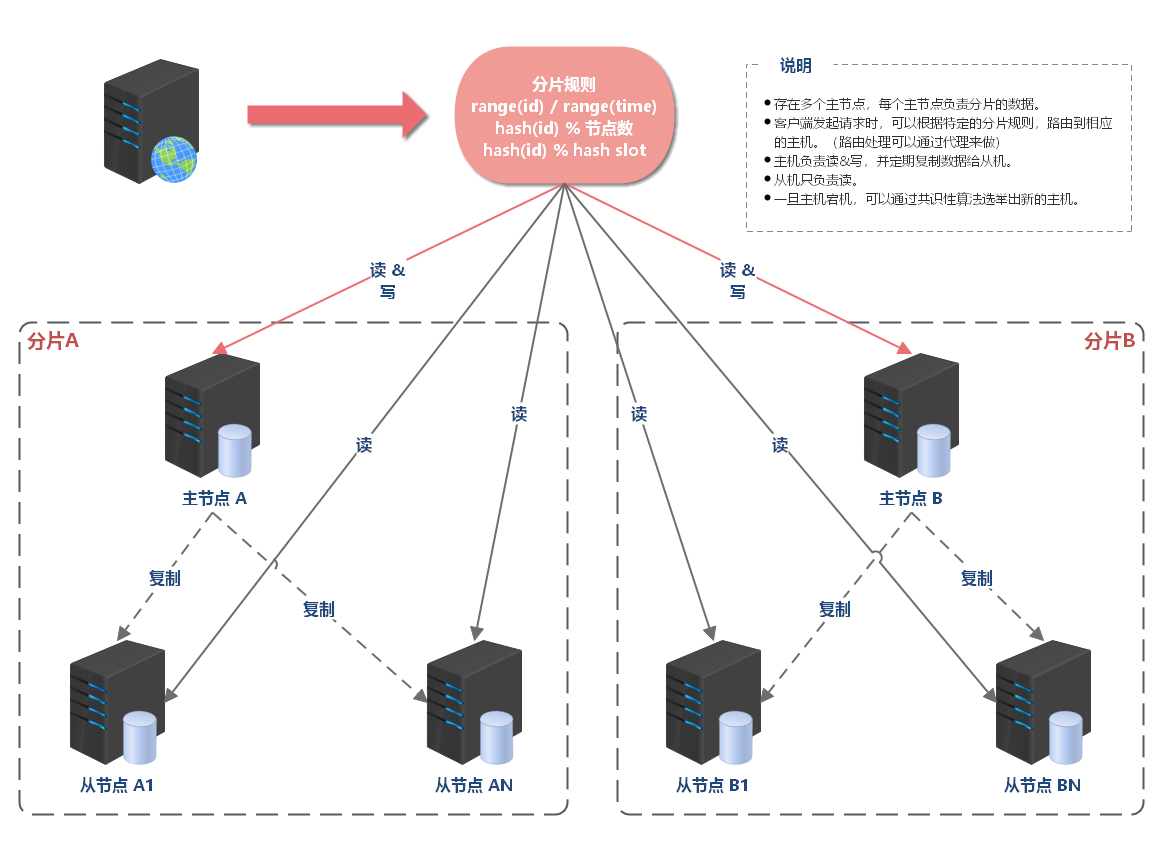
负载均衡 负载均衡简介 大型系统面临的挑战 大型系统通常要面对高并发、高可用、海量数据等挑战。
为了提升系统整体的性能,可以采用垂直扩展和水平扩展两种方式。
垂直扩展 :在网站发展早期,可以从单机的角度通过提升硬件处理能力 ,比如 CPU 处理能力,内存容量,磁盘等方面,实现机器处理能力的提升。但是,单机是有性能瓶颈的,一旦触及瓶颈,再想提升,付出的成本和代价会极高。通俗来说,就三个字:得加钱 !这显然不能满足大型分布式系统(网站)所有应对的大流量,高并发,海量数据等挑战。水平扩展 :通过集群来分担大型网站的流量。集群中的应用机器(节点)通常被设计成无状态,用户可以请求任何一个节点,这些节点共同分担访问压力。水平扩展有两个要点:
集群化、分区化 :将一个完整的应用化整为零,如果是无状态应用,可以直接集群化部署;如果是有状态应用,可以将状态数据分区(分片),然后部署到多台机器上。负载均衡 :集群化、分区化后,要解决的问题是,请求应该被分发(寻址)到哪台机器上。这就需要通过某种策略来控制分发,这种技术就是负载均衡。
什么是负载均衡 “负载均衡(Load Balance,简称 LB)”是一种技术,用来在多个计算机、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到优化资源利用率、最大化吞吐率、最小化响应时间、同时避免过载的目的 。
负载均衡的主要作用如下:
高并发 :负载均衡可以优化资源使用率,通过算法调整负载,尽力均匀的分配资源,以此提高资源利用率、从而提升整体吞吐量。伸缩性 :发生增减资源时,负载均衡可以自动调整分发,使得应用集群具备伸缩性。高可用 :负载均衡器可以监控候选机器,当某机器不可用时,自动跳过,将请求分发给可用的机器。这使得应用集群具备高可用的特性。安全防护 :有些负载均衡软件或硬件提供了安全性功能,如:黑白名单、防火墙,防 DDos 攻击等。
负载均衡的分类 支持负载均衡的技术很多,我们可以通过不同维度去进行分类。
载体维度分类 从支持负载均衡的载体来看,可以将负载均衡分为两类:
硬件负载均衡 硬件负载均衡,一般是在定制处理器上运行的独立负载均衡服务器,价格昂贵,土豪专属 。
硬件负载均衡的主流产品 有:F5 和 A10 。
硬件负载均衡的优点 :
功能强大 :支持全局负载均衡并提供较全面的、复杂的负载均衡算法。性能强悍 :硬件负载均衡由于是在专用处理器上运行,因此吞吐量大,可支持单机百万以上的并发。安全性高 :往往具备防火墙,防 DDos 攻击等安全功能。
硬件负载均衡的缺点 :
成本昂贵 :购买和维护硬件负载均衡的成本都很高。扩展性差 :当访问量突增时,超过限度不能动态扩容。
软件负载均衡 软件负载均衡,应用最广泛 ,无论大公司还是小公司都会使用。
软件负载均衡从软件层面实现负载均衡,一般可以在任何标准物理设备上运行。
软件负载均衡的 主流产品 有:Nginx 、HAProxy 、LVS 。
软件负载均衡的 优点 :
扩展性好 :适应动态变化,可以通过添加软件负载均衡实例,动态扩展到超出初始容量的能力。成本低廉 :软件负载均衡可以在任何标准物理设备上运行,降低了购买和运维的成本。
软件负载均衡的 缺点 :
性能略差 :相比于硬件负载均衡,软件负载均衡的性能要略低一些。
网络通信分类 软件负载均衡从通信层面来看,又可以分为四层和七层负载均衡。
七层负载均衡:就是可以根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。
四层负载均衡:基于 IP 地址和端口进行请求的转发。
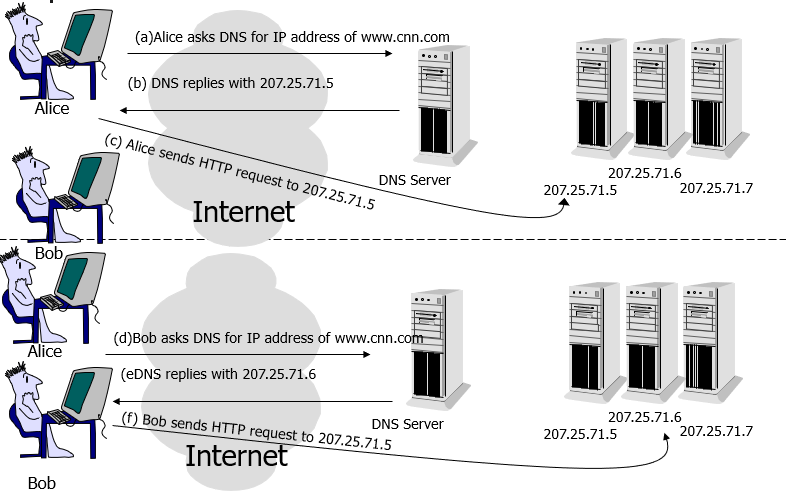
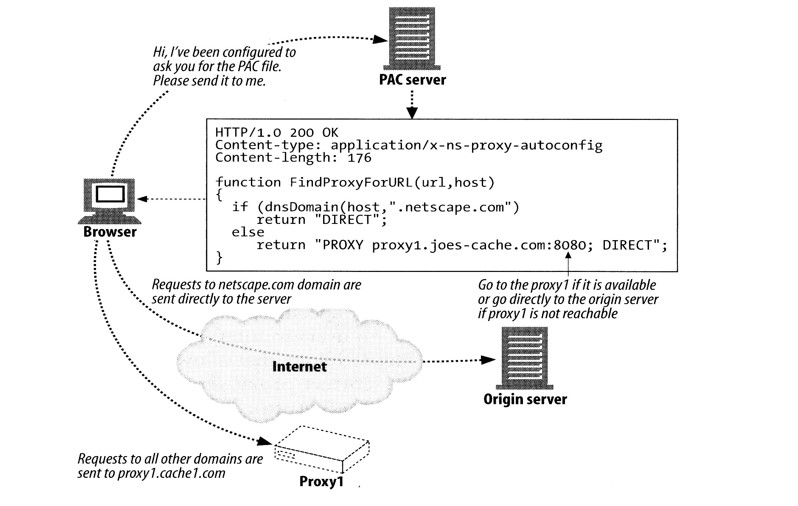
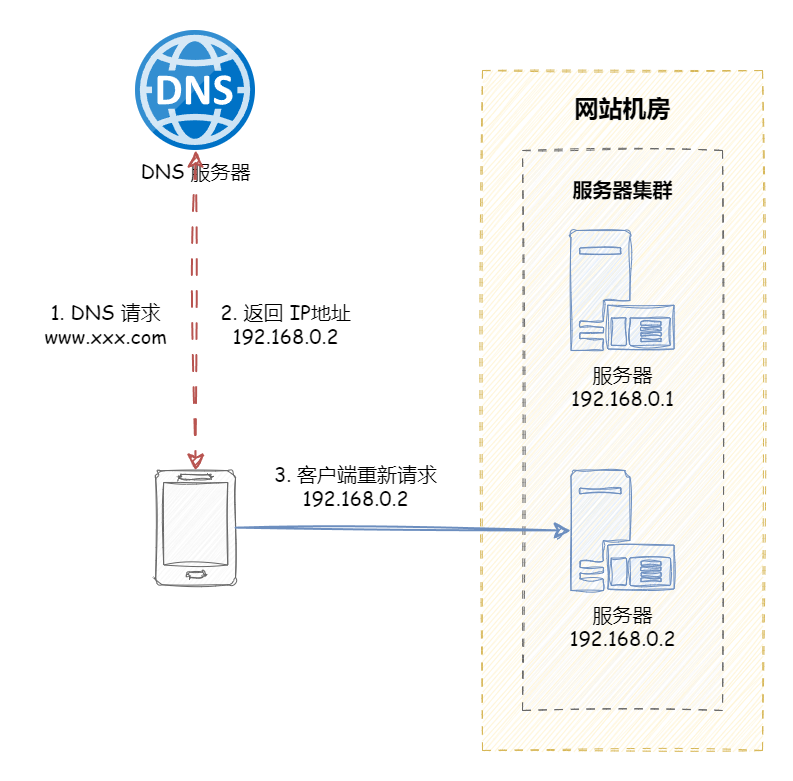
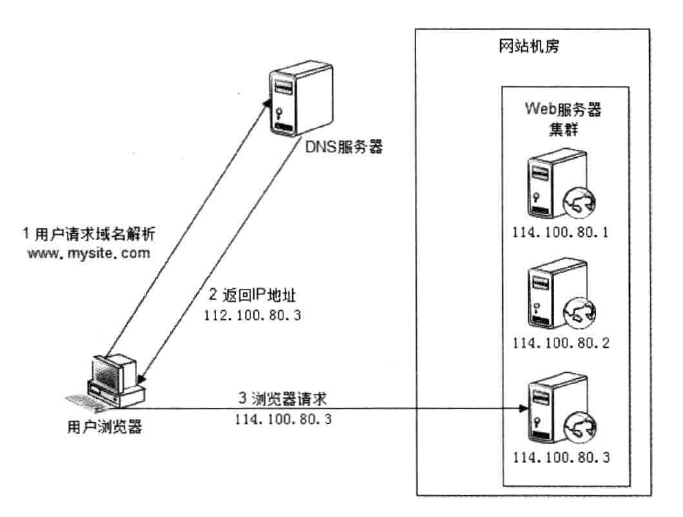
DNS 负载均衡 DNS 负载均衡一般用于互联网公司,复杂的业务系统不适合使用。大型网站一般使用 DNS 负载均衡作为 第一级负载均衡手段 ,然后在内部使用其它方式做第二级负载均衡。DNS 负载均衡属于七层负载均衡。
DNS 即 域名解析服务 ,是 OSI 第七层网络协议。DNS 被设计为一个树形结构的分布式应用,自上而下依次为:根域名服务器,一级域名服务器,二级域名服务器,… ,本地域名服务器。显然,如果所有数据都存储在根域名服务器,那么 DNS 查询的负载和开销会非常庞大。
因此,DNS 查询相对于 DNS 层级结构,是一个逆向的递归流程,DNS 客户端依次请求本地 DNS 服务器,上一级 DNS 服务器,上上一级 DNS 服务器,… ,根 DNS 服务器(又叫权威 DNS 服务器),一旦命中,立即返回。为了减少查询次数,每一级 DNS 服务器都会设置 DNS 查询缓存。
DNS 负载均衡的工作原理就是:基于 DNS 查询缓存,按照负载情况返回不同服务器的 IP 地址 。
DNS 重定向的 优点 :
使用简单 :负载均衡工作,交给 DNS 服务器处理,省掉了负载均衡服务器维护的麻烦提高性能 :可以支持基于地址的域名解析,解析成距离用户最近的服务器地址(类似 CDN 的原理),可以加快访问速度,改善性能;
DNS 重定向的 缺点 :
可用性差 :DNS 解析是多级解析,新增/修改 DNS 后,解析时间较长;解析过程中,用户访问网站将失败;扩展性差 :DNS 负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展;维护性差 :也不能反映服务器的当前运行状态;支持的算法少;不能区分服务器的差异(不能根据系统与服务的状态来判断负载)
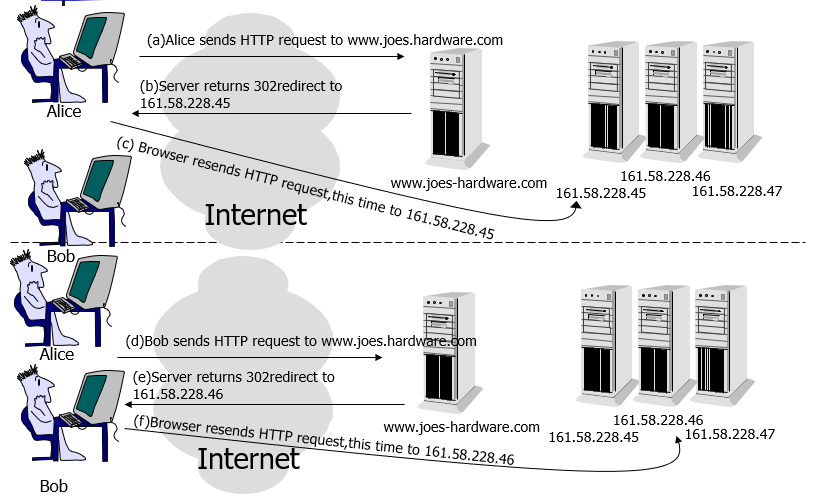
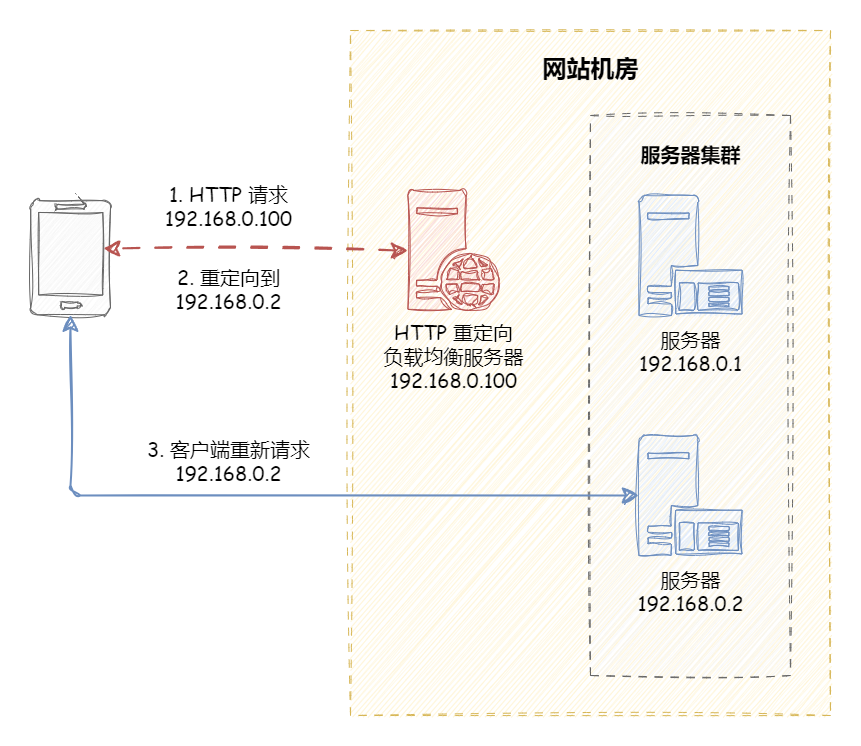
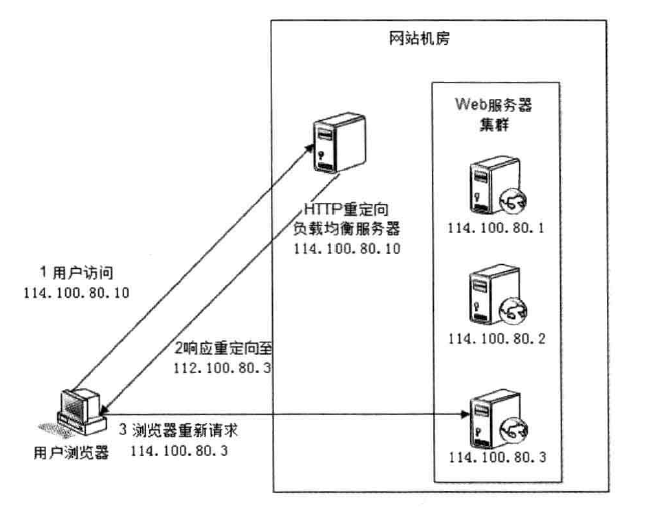
HTTP 负载均衡 HTTP 负载均衡是基于 HTTP 重定向实现的 。HTTP 负载均衡属于七层负载均衡。
HTTP 重定向原理是:根据用户的 HTTP 请求计算出一个真实的服务器地址,将该服务器地址写入 HTTP 重定向响应中,返回给浏览器,由浏览器重新进行访问 。
HTTP 重定向的 优点 :方案简单 。
HTTP 重定向的 缺点 :
额外的转发开销 :每次访问需要两次请求服务器,增加了访问的延迟。降低搜索排名 :使用重定向后,搜索引擎会视为 SEO 作弊。如果负载均衡器宕机,就无法访问该站点。
由于其缺点比较明显,所以这种负载均衡策略实际应用较少。
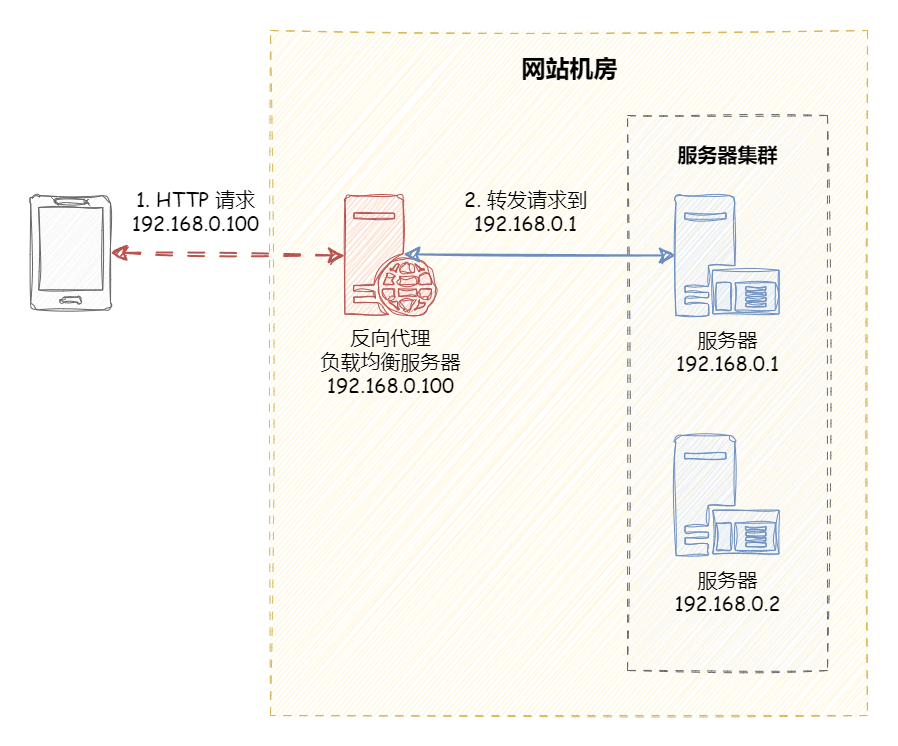
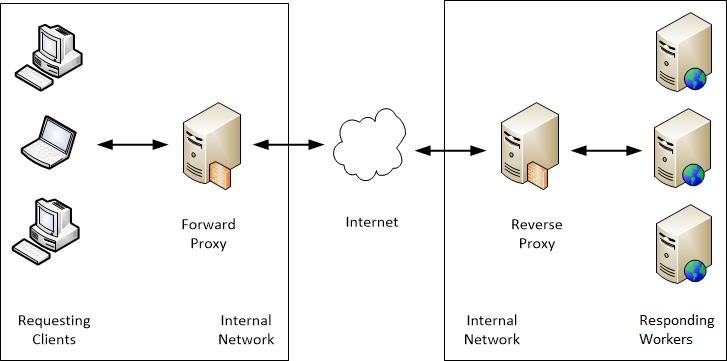
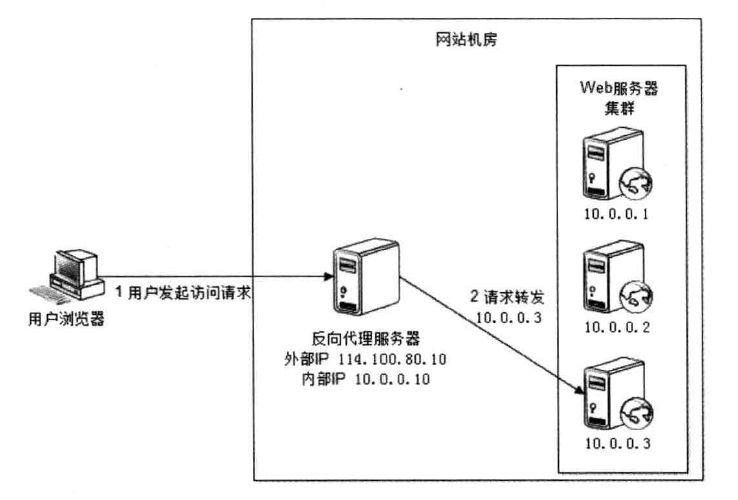
反向代理负载均衡 反向代理(Reverse Proxy)方式是指以 代理服务器 来接受网络请求,然后 将请求转发给内网中的服务器 ,并将从内网中的服务器上得到的结果返回给网络请求的客户端。反向代理负载均衡属于七层负载均衡。
反向代理服务的主流产品:Nginx 、Apache 。
正向代理与反向代理有什么区别?
正向代理:发生在 客户端 ,是由用户主动发起的。翻墙软件就是典型的正向代理,客户端通过主动访问代理服务器,让代理服务器获得需要的外网数据,然后转发回客户端。
反向代理:发生在 服务端 ,用户不知道代理的存在。
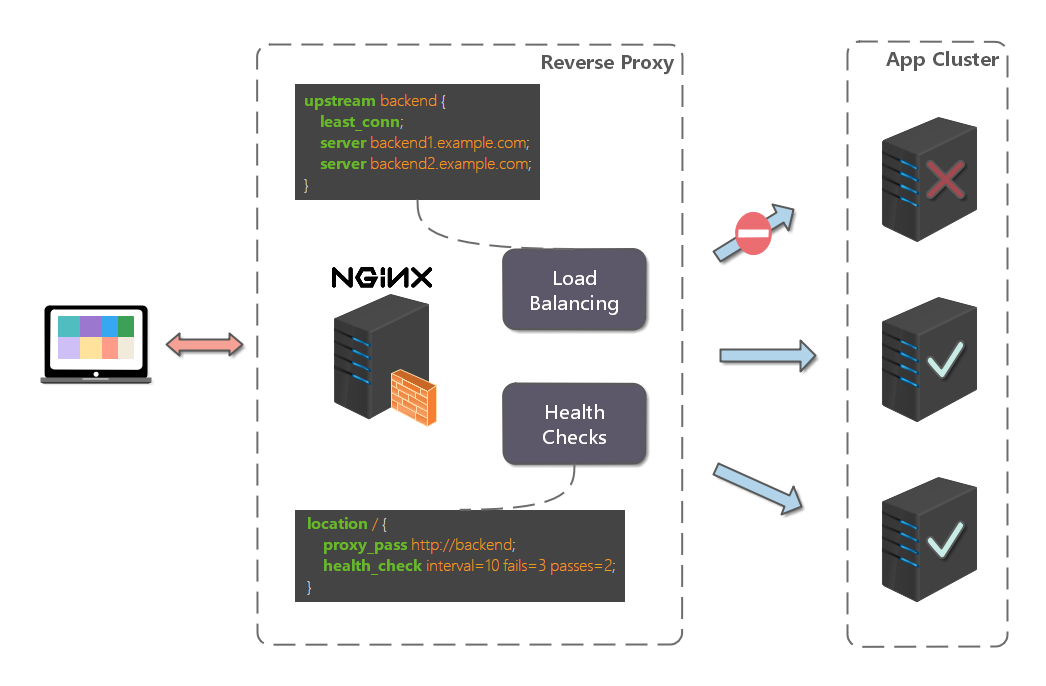
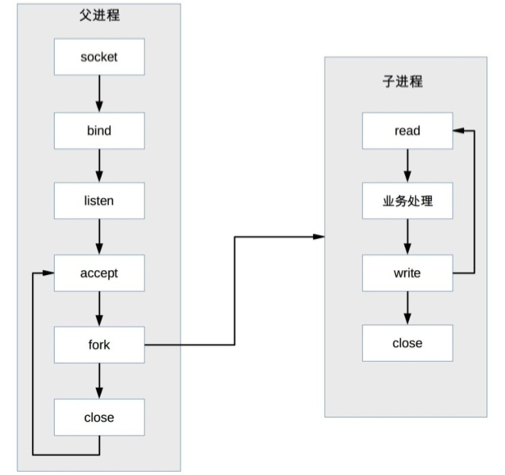
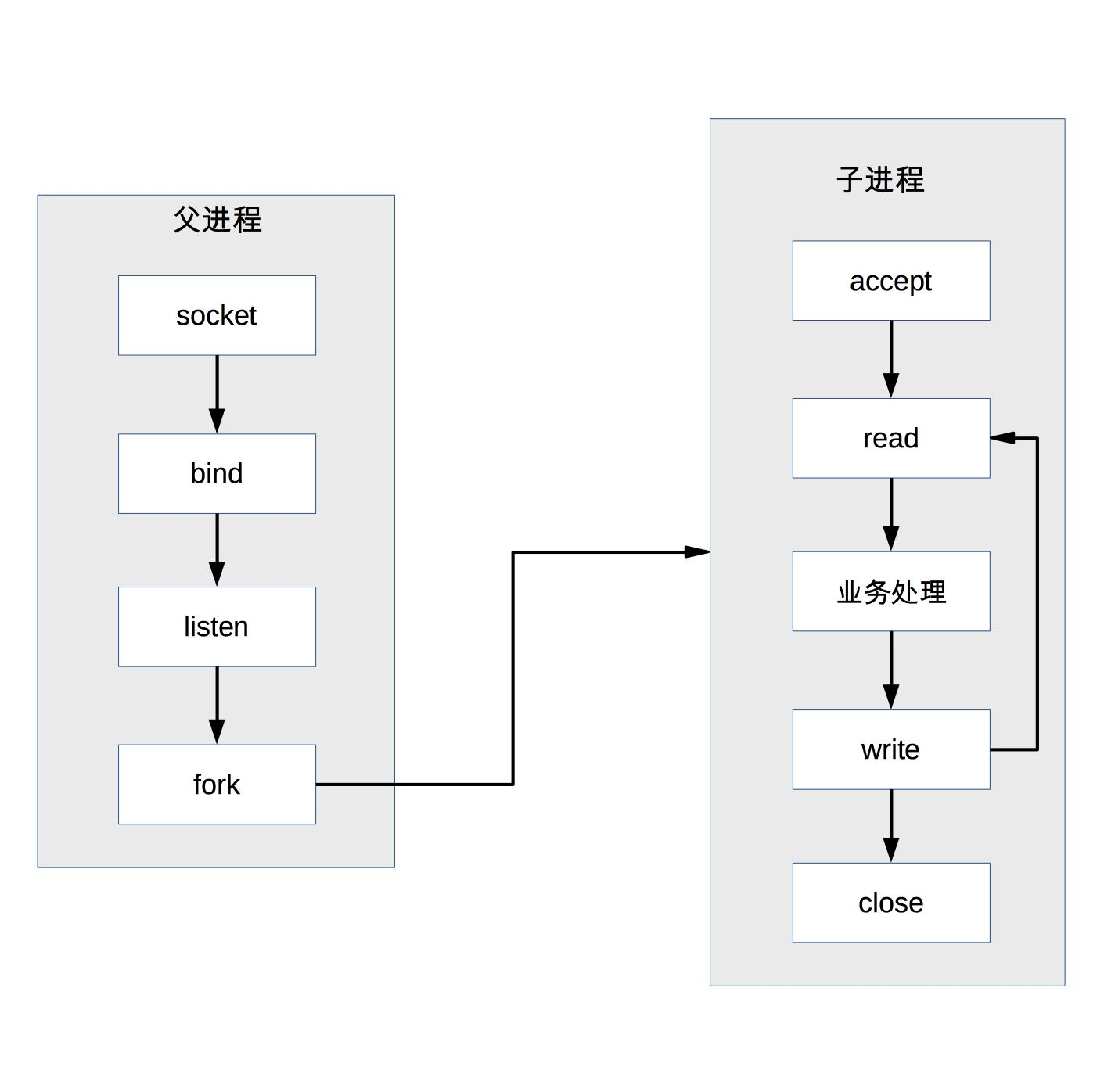
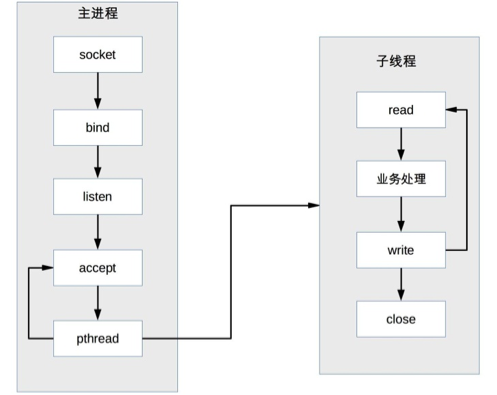
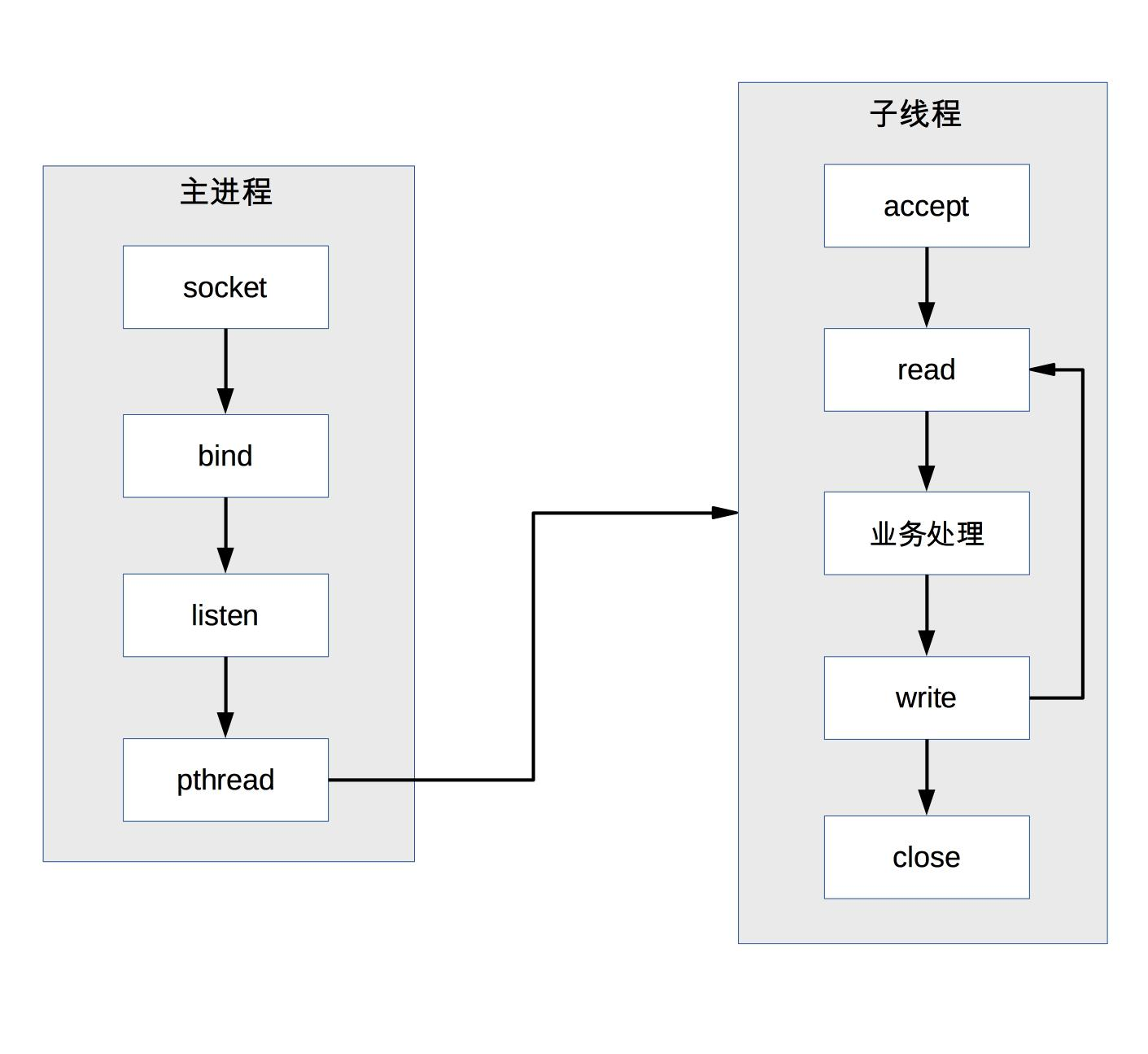
反向代理是如何实现负载均衡的呢?以 Nginx 为例,如下所示:
首先,在代理服务器上设定好负载均衡规则。然后,当收到客户端请求,反向代理服务器拦截指定的域名或 IP 请求,根据负载均衡算法,将请求分发到候选服务器上。其次,如果某台候选服务器宕机,反向代理服务器会有容错处理,比如分发请求失败 3 次以上,将请求分发到其他候选服务器上。
反向代理的 优点 :
多种负载均衡算法 :支持多种负载均衡算法,以应对不同的场景需求。可以监控服务器 :基于 HTTP 协议,可以监控转发服务器的状态,如:系统负载、响应时间、是否可用、连接数、流量等,从而根据这些数据调整负载均衡的策略。
反向代理的 缺点 :
额外的转发开销 :反向代理的转发操作本身是有性能开销的,可能会包括创建连接,等待连接响应,分析响应结果等操作。
增加系统复杂度 :反向代理常用于做分布式应用的水平扩展,但反向代理服务存在以下问题,为了解决以下问题会给系统整体增加额外的复杂度和运维成本:
反向代理服务如果自身宕机,就无法访问站点,所以需要有 高可用 方案,常见的方案有:主备模式(一主一备)、双主模式(互为主备)。
反向代理服务自身也存在性能瓶颈,随着需要转发的请求量不断攀升,需要有 可扩展 方案。
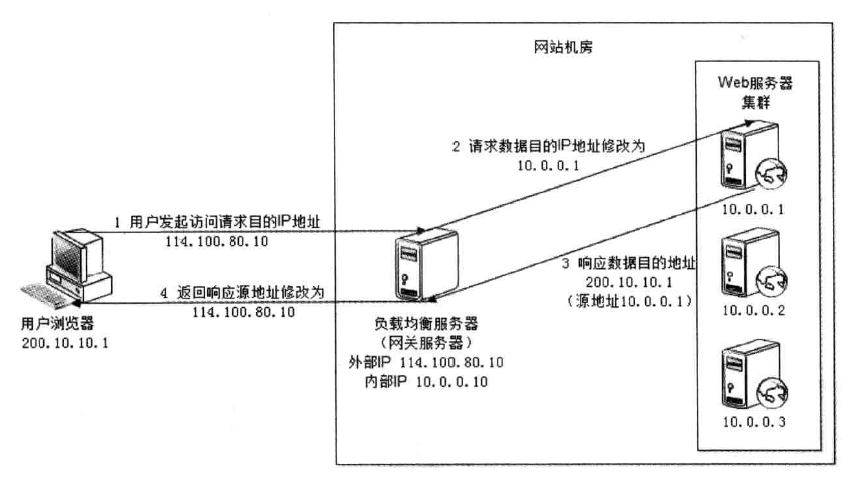
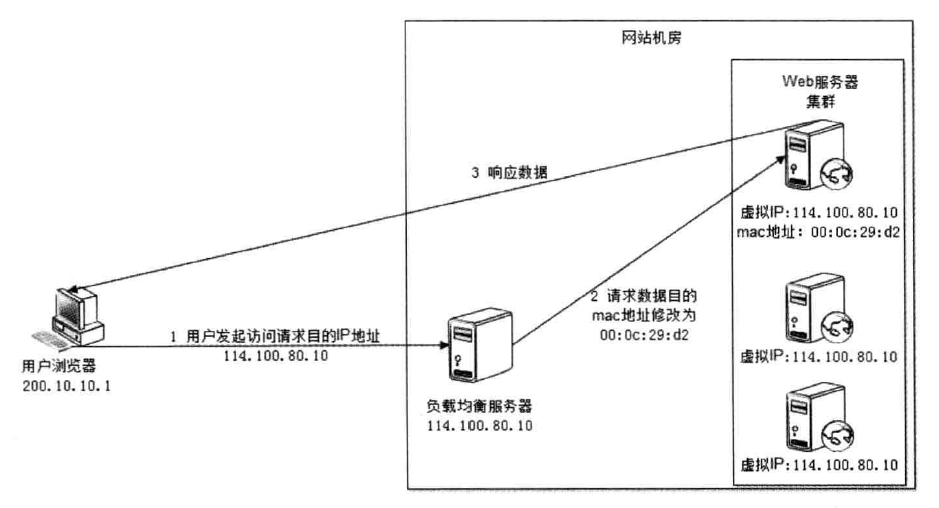
IP 负载均衡 IP 负载均衡是在网络层通过修改请求目的地址进行负载均衡。
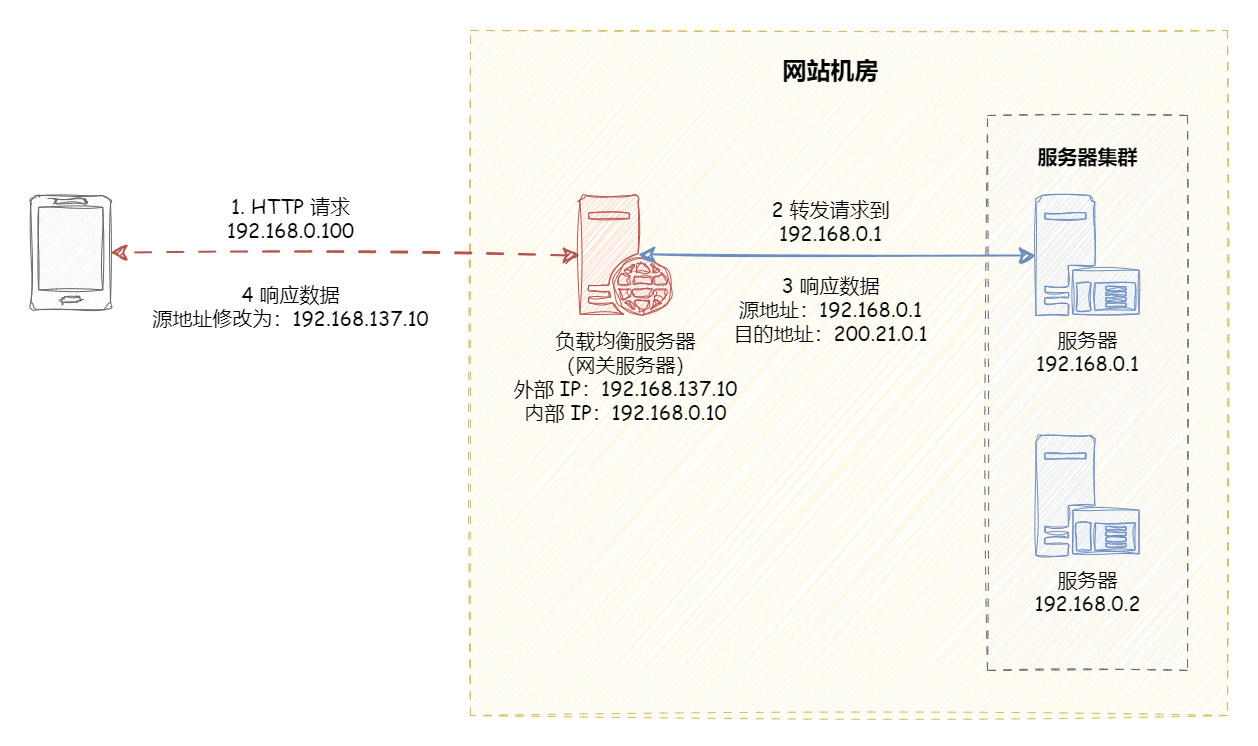
如上图所示,IP 均衡处理流程大致为:
客户端请求 192.168.137.10,由负载均衡服务器接收到报文。
负载均衡服务器根据算法选出一个服务节点 192.168.0.1,然后将报文请求地址改为该节点的 IP。
真实服务节点收到请求报文,处理后,返回响应数据到负载均衡服务器。
负载均衡服务器将响应数据的源地址改负载均衡服务器地址,返回给客户端。
IP 负载均衡在内核进程完成数据分发,较反向代理负载均衡有更好的处理性能。但是,由于所有请求响应都要经过负载均衡服务器,集群的吞吐量受制于负载均衡服务器的带宽。
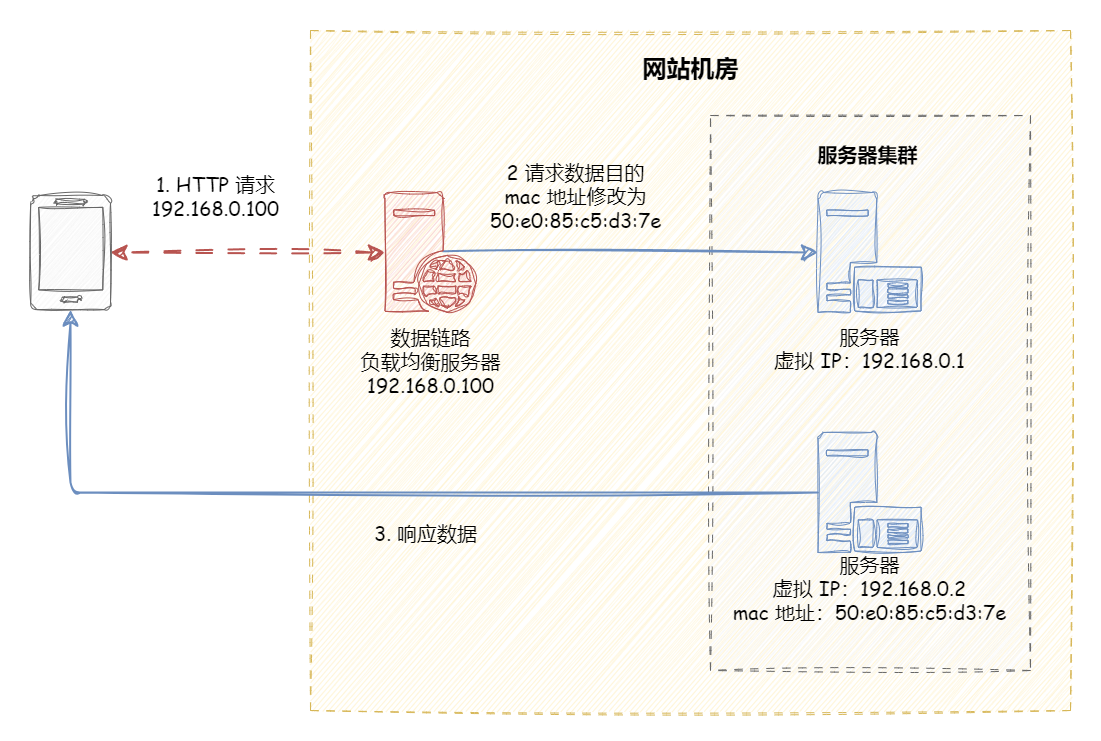
数据链路层负载均衡 数据链路层负载均衡是指在通信协议的数据链路层修改 mac 地址进行负载均衡。
在 Linux 平台上最好的链路层负载均衡开源产品是 LVS (Linux Virtual Server)。
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统。netfilter 是内核态的 Linux 防火墙机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。
LVS 的工作流程大致如下:
当用户访问 www.sina.com.cn 时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。
进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上
IPVS 是工作在 INPUT 链上,会根据访问的 vip+port 判断请求是否 IPVS 服务,如果是则调用注册的 IPVS HOOK 函数,进行 IPVS 相关主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。
POSTROUTING 上收到数据包后,根据目标 IP 地址(后端服务器),通过路由选路,将数据包最终发往后端的服务器上。
开源 LVS 版本有 3 种工作模式,每种模式工作原理截然不同,说各种模式都有自己的优缺点,分别适合不同的应用场景,不过最终本质的功能都是能实现均衡的流量调度和良好的扩展性。主要包括三种模式:DR 模式、NAT 模式、Tunnel 模式。
负载均衡算法 负载均衡器的实现可以分为两个部分:
根据负载均衡算法在候选机器列表选出一个机器;
将请求数据发送到该机器上。
负载均衡算法是负载均衡服务核心中的核心。负载均衡产品多种多样,但是各种负载均衡算法原理是共性的。
负载均衡算法有很多种,分别适用于不同的应用场景。本章节将由浅入深的,逐一讲解各种负载均衡算法的策略和特性,并根据算法之间的互补关系将它们串联起来。
注:负载均衡算法的实现,推荐阅读 Dubbo 官方负载均衡算法说明 ,源码讲解非常详细,非常值得借鉴。
下文中的各种算法的可执行示例已归档在 Github 仓库:java-load-balance ,可以通过执行 io.github.dunwu.javatech.LoadBalanceDemo 查看各算法执行效果。
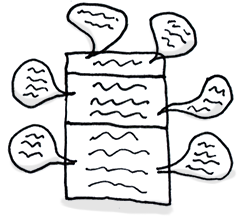
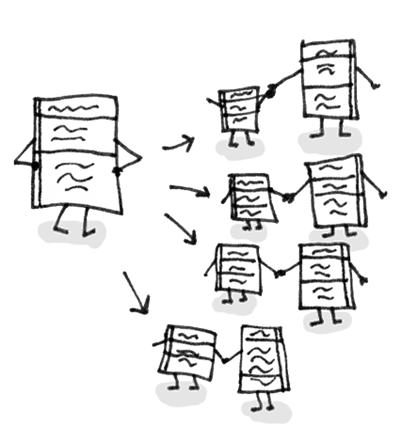
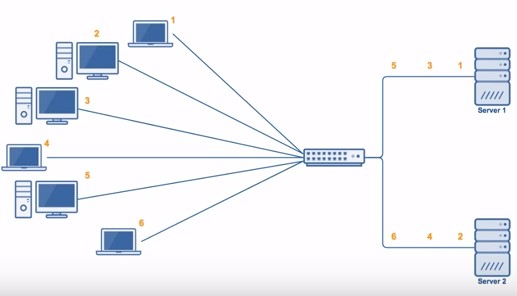
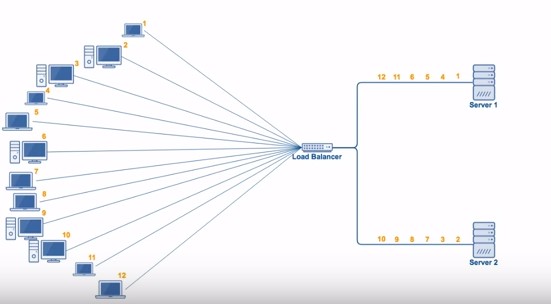
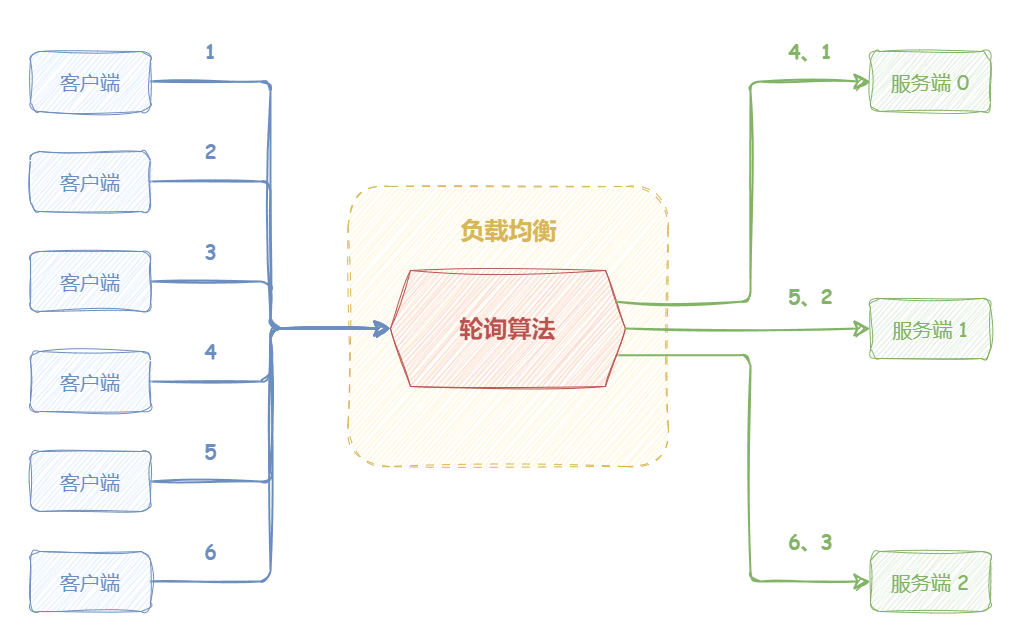
轮询算法 “轮询算法(Round Robin)”的策略是:将请求“依次”分发到候选机器 。
如下图所示,轮询负载均衡器收到来自客户端的 6 个请求,编号为 1、4 的请求会被发送到服务端 0;编号为 2、5 的请求会被发送到服务端 1;编号为 3、6 的请求会被发送到服务端 2。
轮询算法适合的场景需要满足:各机器处理能力相近,且每个请求工作量差异不大 。
【示例】轮询负载均衡算法实现示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class RoundRobinLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private final AtomicInteger position = new AtomicInteger (0 ); @Override protected N doSelect (List<N> nodes, String ip) { int length = nodes.size(); position.compareAndSet(length, 0 ); N node = nodes.get(position.get()); position.getAndIncrement(); return node; } }
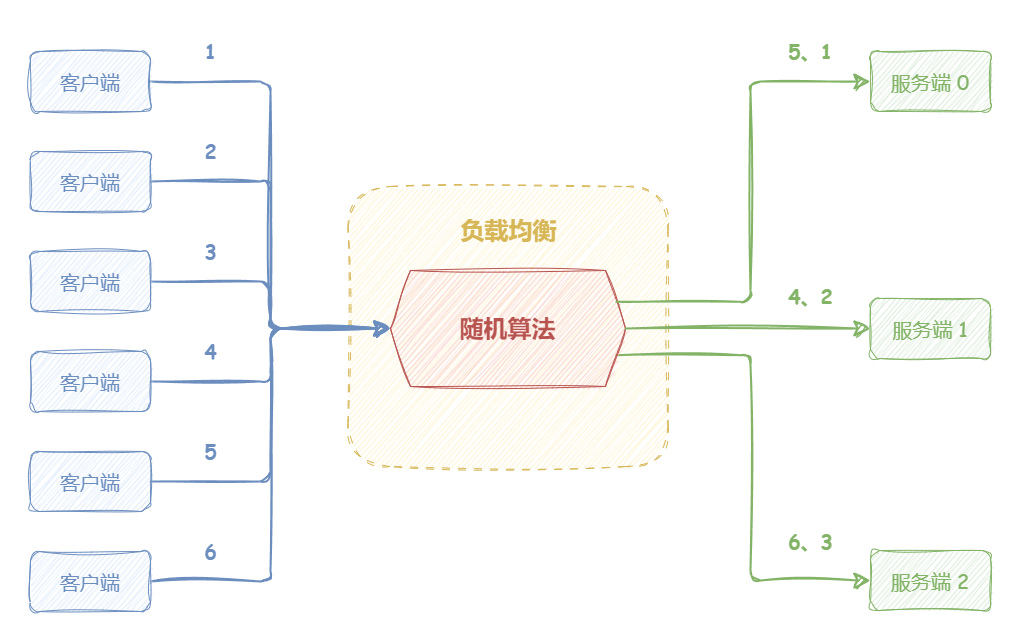
随机算法 “随机算法(Random)” 将请求“随机”分发到候选机器 。
如下图所示,随机负载均衡器收到来自客户端的 6 个请求,会随机分发请求,可能会出现:编号为 1、5 的请求会被发送到服务端 0;编号为 2、4 的请求会被发送到服务端 1;编号为 3、6 的请求会被发送到服务端 2。
随机算法适合的场景需要满足:各机器处理能力相近,且每个请求工作量差异不大 。
学习过概率论的都知道,调用量较小的时候,可能负载并不均匀,调用量越大,负载越均衡 。
【示例】随机负载均衡算法实现示例
负载均衡接口
1 2 3 4 5 public interface LoadBalance <N extends Node > { N select (List<N> nodes, String ip) ; }
负载均衡抽象类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public abstract class BaseLoadBalance <N extends Node > implements LoadBalance <N> { @Override public N select (List<N> nodes, String ip) { if (CollectionUtil.isEmpty(nodes)) { return null ; } if (nodes.size() == 1 ) { return nodes.get(0 ); } return doSelect(nodes, ip); } protected abstract N doSelect (List<N> nodes, String ip) ; }
机器节点类
1 2 3 4 5 6 7 8 9 10 public class Node implements Comparable <Node> { protected String url; protected Integer weight; protected Integer active; }
随机算法实现
1 2 3 4 5 6 7 8 9 10 11 12 public class RandomLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private final Random random = new Random (); @Override protected N doSelect (List<N> nodes, String ip) { int index = random.nextInt(nodes.size()); return nodes.get(index); } }
加权轮询/随机算法 轮询/随机算法适合的场景都需要满足:各机器处理能力相近,且每个请求工作量差异不大。
在理想状况下,假设每个机器的硬件条件相同,如:CPU、内存、网络 IO 等配置都相同;并且每个请求的耗时一样(请求传输时间、请求访问数据时间、计算时间等),这时轮询算法才能真正做到负载均衡。显然,要满足以上条件都相同是几乎不可能的,更不要说实际的网络通信中还有更多复杂的情况。
以上,如果有一点不能满足,都无法做到真正的负载均衡。个体存在较大差异,当请求量较大时,处理较慢的机器可能会逐渐积压请求,从而导致过载甚至宕机。
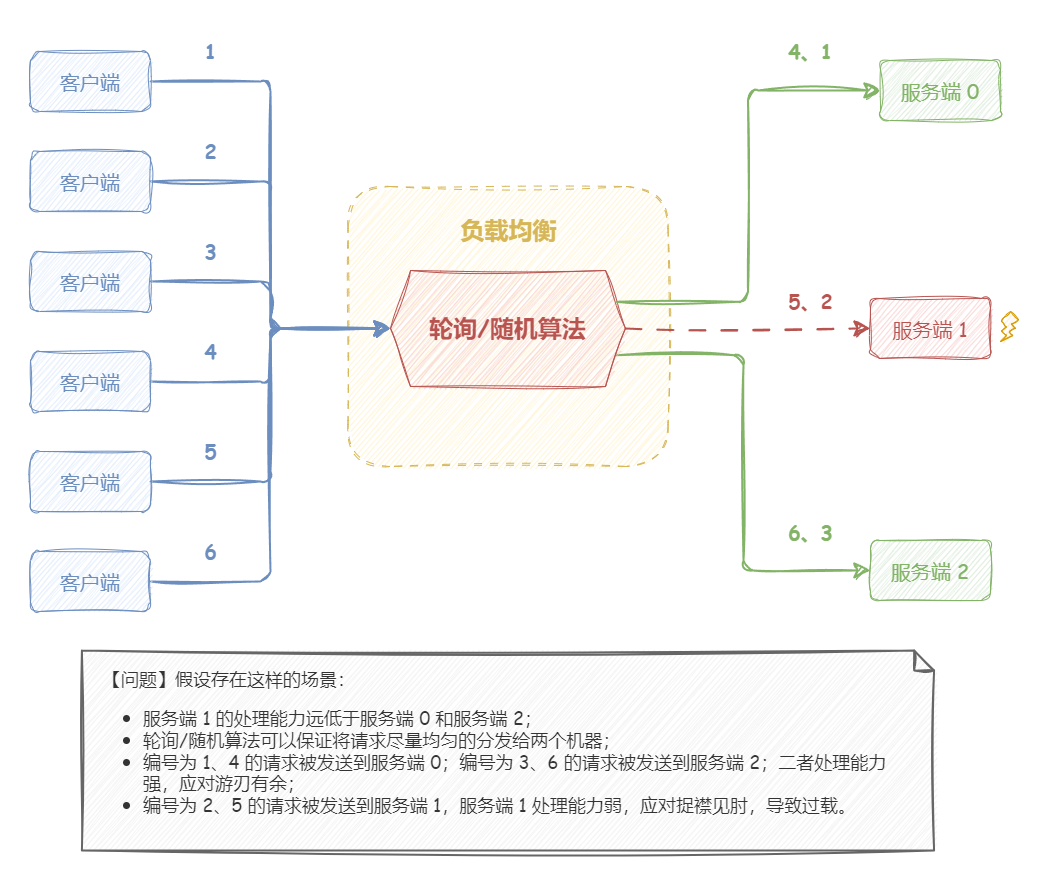
如下图所示,假设存在这样的场景:
服务端 1 的处理能力远低于服务端 0 和服务端 2;
轮询/随机算法可以保证将请求尽量均匀的分发给两个机器;
编号为 1、4 的请求被发送到服务端 0;编号为 3、6 的请求被发送到服务端 2;二者处理能力强,应对游刃有余;
编号为 2、5 的请求被发送到服务端 1,服务端 1 处理能力弱,应对捉襟见肘,导致过载。
《蜘蛛侠》电影中有一句经典台词:能力越大,责任越大 。显然,以上情况不符合这句话,处理能力强的机器并没有被分发到更多的请求,它的处理能力被闲置了。那么,如何解决这个问题呢?
一种比较容易想到的思路是:引入权重属性,可以根据机器的硬件条件为其设置合理的权重值,负载均衡时,优先将请求分发到权重较高的机器。
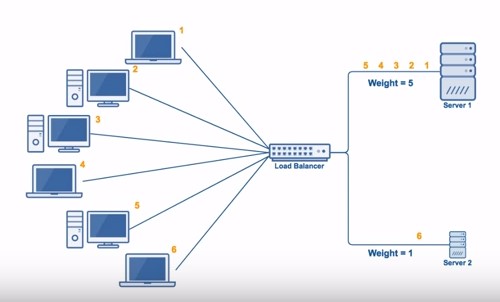
“加权轮询算法(Weighted Round Robbin)” 和“加权随机算法(Weighted Random)” 都采用了加权的思路,在轮询/随机算法的基础上,引入了权重属性,优先将请求分发到权重较高的机器。这样,就可以针对性能高、处理速度快的机器设置较高的权重,让其处理更多的请求;而针对性能低、处理速度慢的机器则与之相反。一言以蔽之,加权策略强调了——能力越大,责任越大。
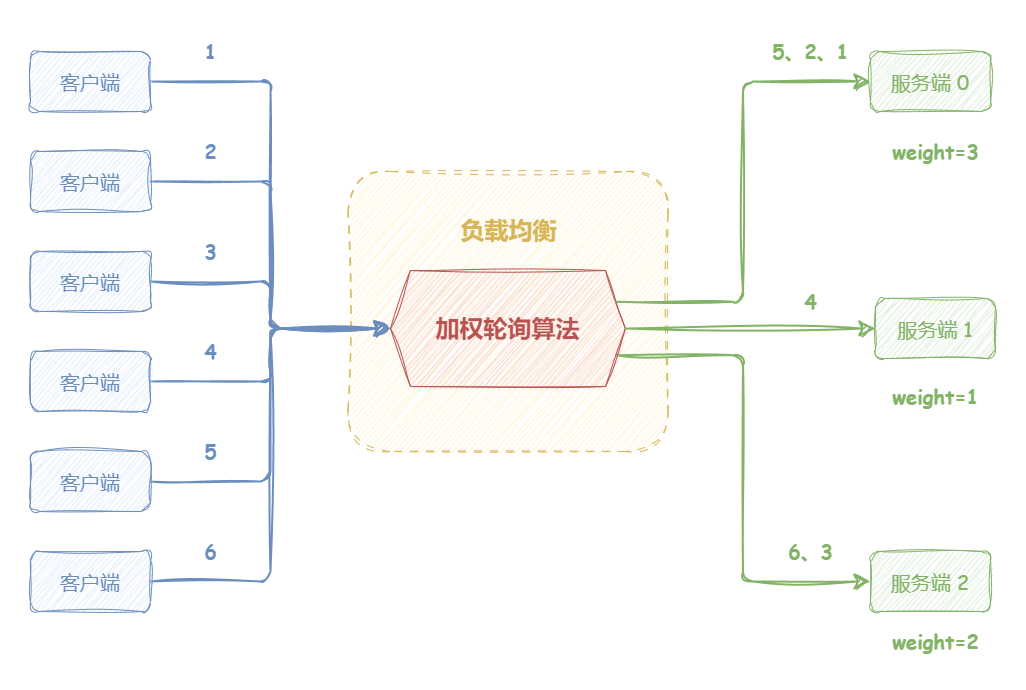
如下图所示,服务端 0 设置权重为 3,服务端 1 设置权重为 1,服务端 2 设置权重为 2。负载均衡器收到来自客户端的 6 个请求,那么编号为 1、2、5 的请求会被发送到服务端 0,编号为 4 的请求会被发送到服务端 1,编号为 3、6 的请求会被发送到机器 2。
【示例】加权随机负载均衡算法实现示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class WeightRandomLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private final Random random = ThreadLocalRandom.current(); @Override protected N doSelect (List<N> nodes, String ip) { int length = nodes.size(); AtomicInteger totalWeight = new AtomicInteger (0 ); for (N node : nodes) { Integer weight = node.getWeight(); totalWeight.getAndAdd(weight); } if (totalWeight.get() > 0 ) { int offset = random.nextInt(totalWeight.get()); for (N node : nodes) { offset -= node.getWeight(); if (offset < 0 ) { return node; } } } return nodes.get(random.nextInt(length)); } }
【示例】加权轮询负载均衡算法实现示例
以下实现基于 Dubbo 加权轮询算法做了一些简化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 public class WeightRoundRobinLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private static final int RECYCLE_PERIOD = 60000 ; private ConcurrentMap<Integer, WeightedRoundRobin> weightMap = new ConcurrentHashMap <>(); private AtomicBoolean updateLock = new AtomicBoolean (); @Override protected N doSelect (List<N> nodes, String ip) { int totalWeight = 0 ; long maxCurrent = Long.MIN_VALUE; long now = System.currentTimeMillis(); N selectedNode = null ; WeightedRoundRobin selectedWRR = null ; for (N node : nodes) { int hashCode = node.hashCode(); WeightedRoundRobin weightedRoundRobin = weightMap.get(hashCode); int weight = node.getWeight(); if (weight < 0 ) { weight = 0 ; } if (weightedRoundRobin == null ) { weightedRoundRobin = new WeightedRoundRobin (); weightedRoundRobin.setWeight(weight); weightMap.putIfAbsent(hashCode, weightedRoundRobin); weightedRoundRobin = weightMap.get(hashCode); } if (weight != weightedRoundRobin.getWeight()) { weightedRoundRobin.setWeight(weight); } long current = weightedRoundRobin.increaseCurrent(); weightedRoundRobin.setLastUpdate(now); if (current > maxCurrent) { maxCurrent = current; selectedNode = node; selectedWRR = weightedRoundRobin; } totalWeight += weight; } if (!updateLock.get() && nodes.size() != weightMap.size()) { if (updateLock.compareAndSet(false , true )) { try { weightMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD); } finally { updateLock.set(false ); } } } if (selectedNode != null ) { selectedWRR.decreaseCurrent(totalWeight); return selectedNode; } return nodes.get(0 ); } protected static class WeightedRoundRobin { private int weight; private AtomicLong current = new AtomicLong (0 ); private long lastUpdate; public long increaseCurrent () { return current.addAndGet(weight); } public long decreaseCurrent (int total) { return current.addAndGet(-1 * total); } public int getWeight () { return weight; } public void setWeight (int weight) { this .weight = weight; current.set(0 ); } public AtomicLong getCurrent () { return current; } public void setCurrent (AtomicLong current) { this .current = current; } public long getLastUpdate () { return lastUpdate; } public void setLastUpdate (long lastUpdate) { this .lastUpdate = lastUpdate; } } }
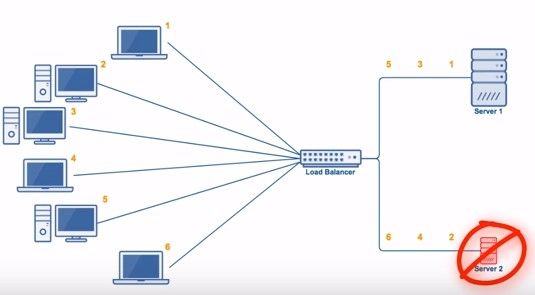
最少连接数算法 加权轮询/随机算法虽然一定程度上解决了机器处理能力不同时的负载均衡场景,但它最大的问题在于不能动态应对网络中负载不均的场景。加权的思路是在负载均衡处理的事前,预设好不同机器的权重,然后分发。然而,每个请求的连接时长不同,负载均衡器也不可能准确预估出请求的连接时长。因此,采用加权轮询/随机算法算法,都无法动态应对连接时长不均的网络场景,可能会出现某些机器当前连接数过多,而另一些机器的连接过少 的情况,即并非真正的流量负载均衡。
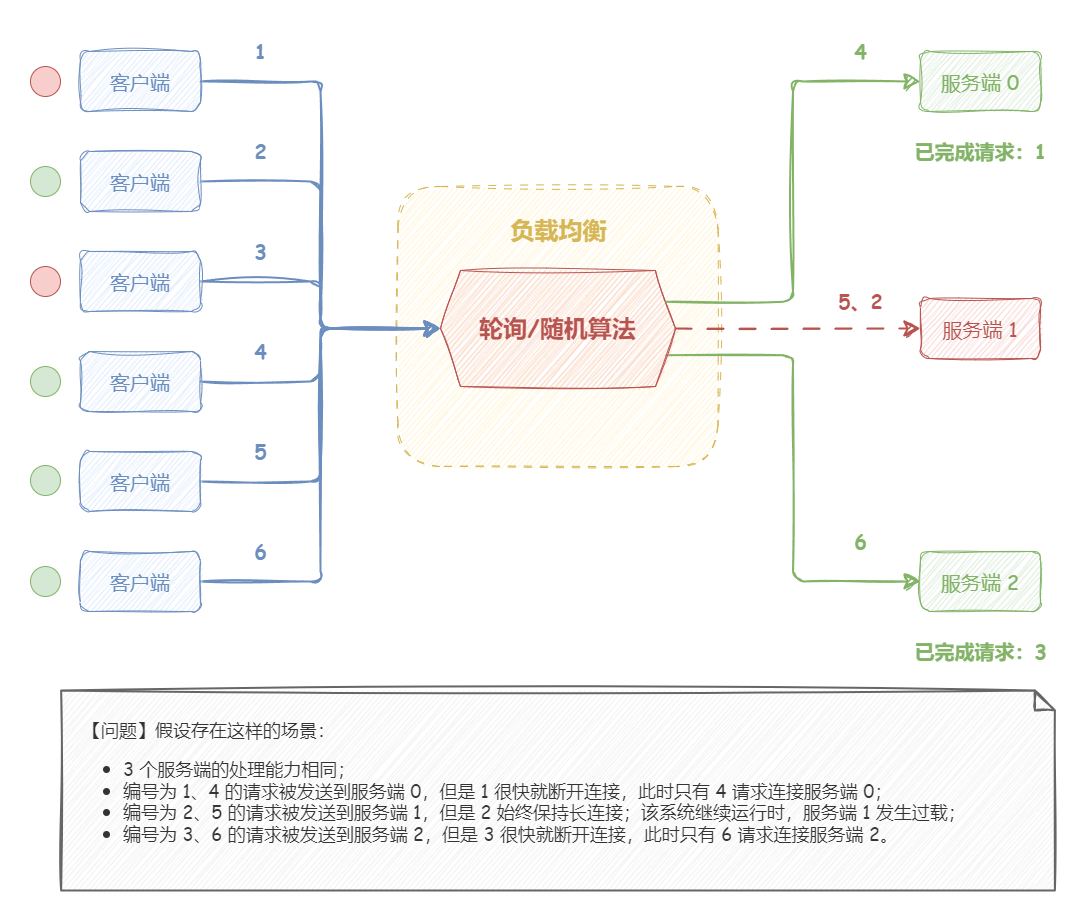
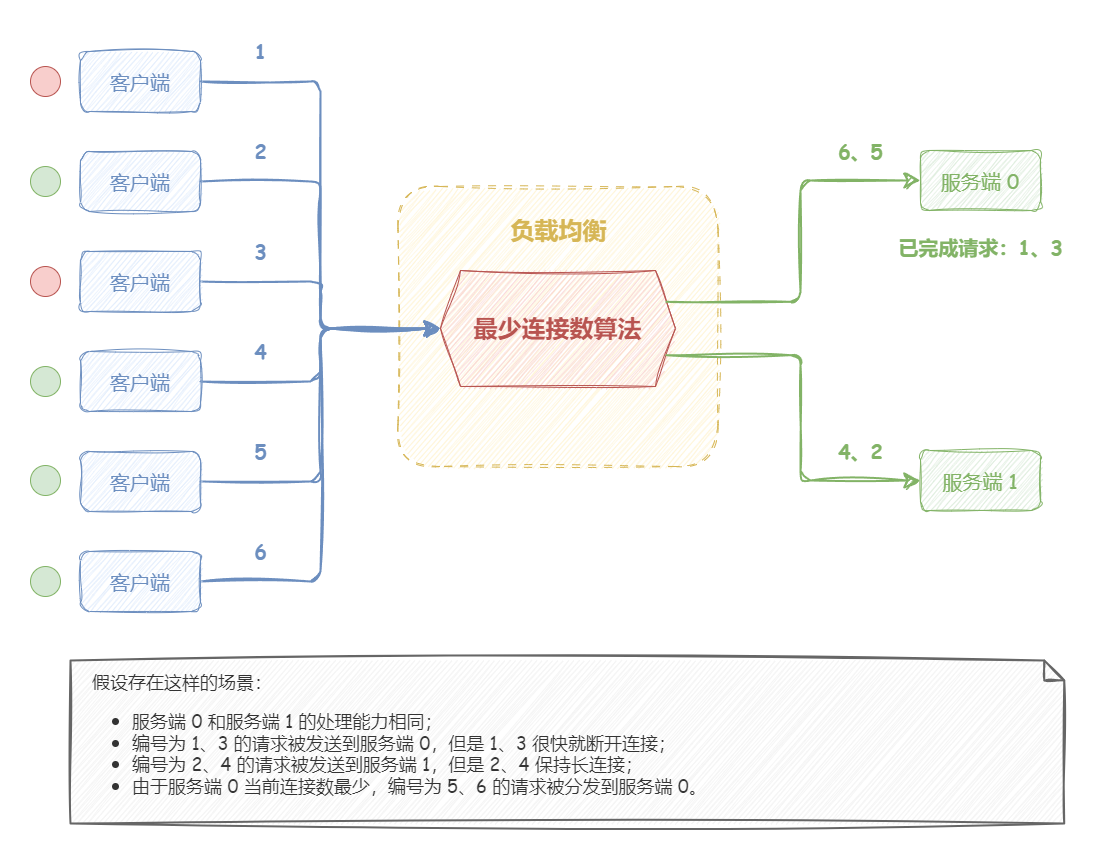
如下图所示,假设存在这样的场景:
3 个服务端的处理能力相同;
编号为 1、4 的请求被发送到服务端 0,但是 1 很快就断开连接,此时只有 4 请求连接服务端 0;
编号为 2、5 的请求被发送到服务端 1,但是 2 始终保持长连接;该系统继续运行时,服务端 1 发生过载;
编号为 3、6 的请求被发送到服务端 2,但是 3 很快就断开连接,此时只有 6 请求连接服务端 2;
既然,请求的连接时长不同,会导致有的服务端处理慢,积压大量连接数;而有的服务端处理快,保持的连接数少。那么,我们不妨想一下,如果负载均衡器监控一下服务端当前所持有的连接数,优先将请求分发给连接数少的服务端,不就能有效提高分发效率了吗?最少连接数算法正是采用这个思路去设计的。
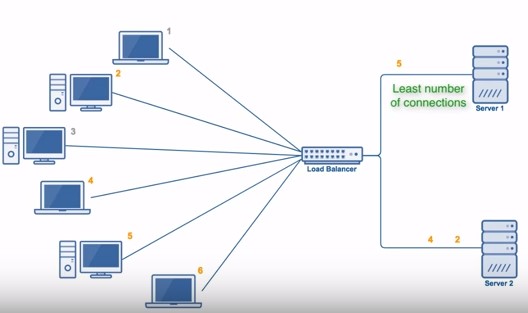
“最少连接数算法(Least Connections)” 将请求分发到连接数/请求数最少的候选机器 。
要根据机器连接数分发,显然要先维护机器的连接数。因此,最少连接数算法需要实时追踪每个候选机器的活跃连接数;然后,动态选出连接数最少的机器,优先分发请求 。最少连接数算法会记录当前时刻,每个候选节点正在处理的连接数,然后选择连接数最小的节点。该策略能够动态、实时地反应机器的当前状况,较为合理地将负责分配均匀,适用于对当前系统负载较为敏感的场景。
由此可见,最少连接数算法适用于对系统负载较为敏感且请求连接时长相差较大的场景 。
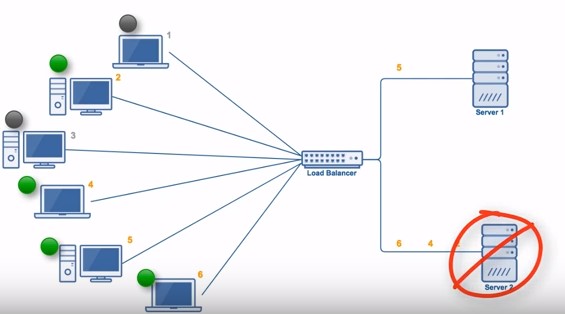
如下图所示,假设存在这样的场景:
服务端 0 和服务端 1 的处理能力相同;
编号为 1、3 的请求被发送到服务端 0,但是 1、3 很快就断开连接;
编号为 2、4 的请求被发送到服务端 1,但是 2、4 保持长连接;
由于服务端 0 当前连接数最少,编号为 5、6 的请求被分发到服务端 0。
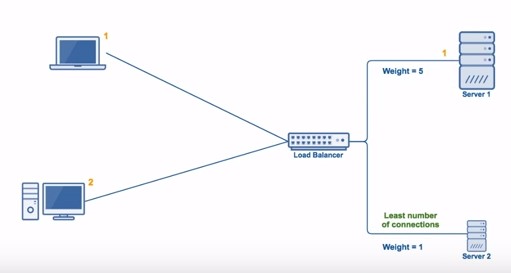
“加权最少连接数算法(Weighted Least Connection)”在最少连接数算法的基础上,根据机器的性能为每台机器分配权重,再根据权重计算出每台机器能处理的连接数。
【示例】最少连接数算法实现
最少连接数算法实现要点:活跃调用数越小,表明该服务节点处理能力越高,单位时间内可处理更多的请求,应优先将请求分发给该服务。在具体实现中,每个服务节点对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为 0。每收到一个请求,活跃数加 1,完成请求后则将活跃数减 1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最少连接数负载均衡算法的基本思想。
以下实现基于 Dubbo 最少连接数负载均衡算法做了些许改动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 public class LeastActiveLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private final Random random = new Random (); @Override protected N doSelect (List<N> nodes, String ip) { int length = nodes.size(); int leastActive = -1 ; int leastCount = 0 ; int [] leastIndexs = new int [length]; int totalWeight = 0 ; int firstWeight = 0 ; boolean sameWeight = true ; for (int i = 0 ; i < length; i++) { N node = nodes.get(i); if (leastActive == -1 || node.getActive() < leastActive) { leastActive = node.getActive(); leastCount = 1 ; leastIndexs[0 ] = i; totalWeight = node.getWeight(); firstWeight = node.getWeight(); sameWeight = true ; } else if (node.getActive() == leastActive) { leastIndexs[leastCount++] = i; totalWeight += node.getWeight(); if (sameWeight && i > 0 && node.getWeight() != firstWeight) { sameWeight = false ; } } } if (leastCount == 1 ) { return nodes.get(leastIndexs[0 ]); } if (!sameWeight && totalWeight > 0 ) { int offsetWeight = random.nextInt(totalWeight); for (int i = 0 ; i < leastCount; i++) { int leastIndex = leastIndexs[i]; offsetWeight -= nodes.get(leastIndex).getWeight(); if (offsetWeight <= 0 ) { return nodes.get(leastIndex); } } } return nodes.get(leastIndexs[random.nextInt(leastCount)]); } }
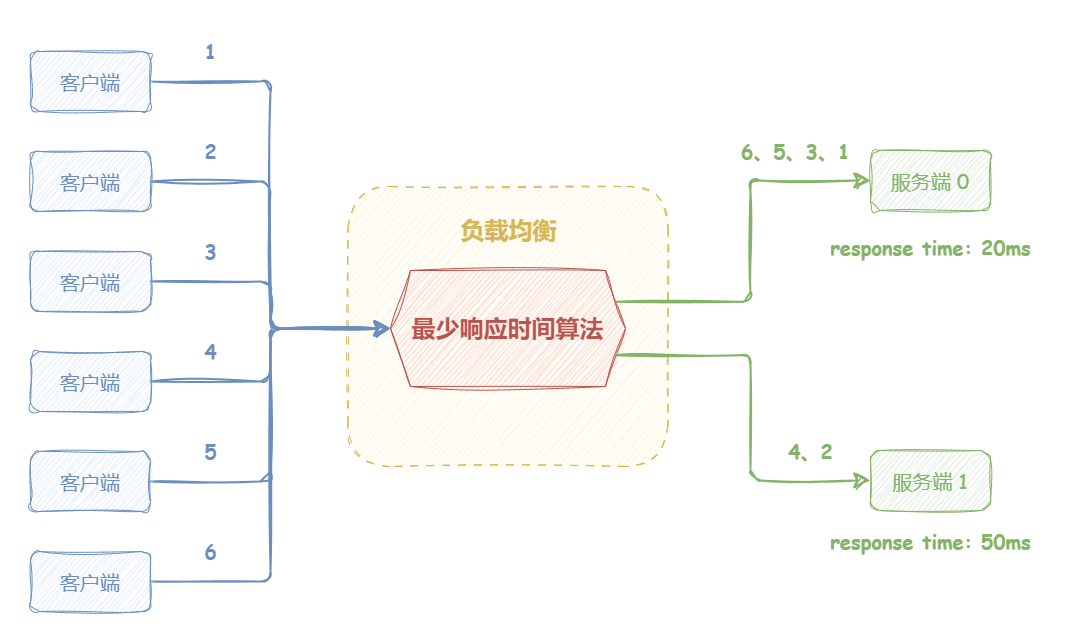
最少响应时间算法 “最少响应时间算法(Least Time)” 将请求分发到响应时间最短的候选机器 。最少响应时间算法和最少连接数算法二者的目标其实是殊途同归,都是动态调整,将请求尽量分发到处理能力强的机器上。不同点在于,最少连接数关注的维度是机器持有的连接数,而最少响应时间关注的维度是机器上一次响应时间哪个最短。理论上来说,持有的连接数少,响应时间短,都可以表明机器潜在的处理能力比较强。
最少响应时间算法具有高度的敏感性、自适应性 。但是,由于它需要持续监控候选机器的响应时延,相比于监控候选机器的连接数,会显著增加监控的开销。此外,请求的响应时延并不一定能完全反应机器的处理能力,有可能某机器上一次处理的请求恰好是一个开销非常小的请求。
哈希算法 前面提到的负载均衡算法,都只适用于无状态应用。所谓无状态应用,意味着:请求无论分发到集群中的任意机器上,得到的响应都是相同的:然而,有状态服务则不然:请求分发到不同的机器上,得到的结果是不一样的。典型的无状态应用是普通的 Web 服务器;典型的有状态应用是各种分布式数据库(如:Redis、ElasticSearch 等),这些数据库存储了大量,乃至海量的数据,无法全部存储在一台机器上,为了提高整体容量以及吞吐量,采用了分区(分片)的设计,将数据化整为零的存储在不同机器上。
对于有状态应用,不仅仅需要保证负载的均衡,更为重要的是,需要保证针对相同数据的请求始终访问的是相同的机器,否则,就无法获取到正确的数据。
那么,如何解决有状态应用的负载均衡呢?有一种方案是哈希算法。
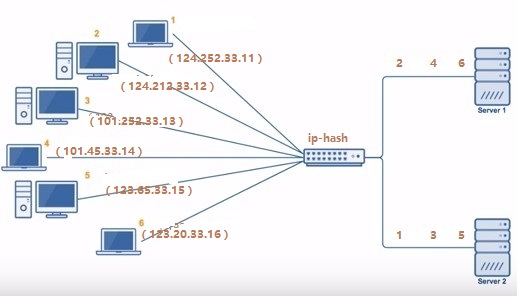
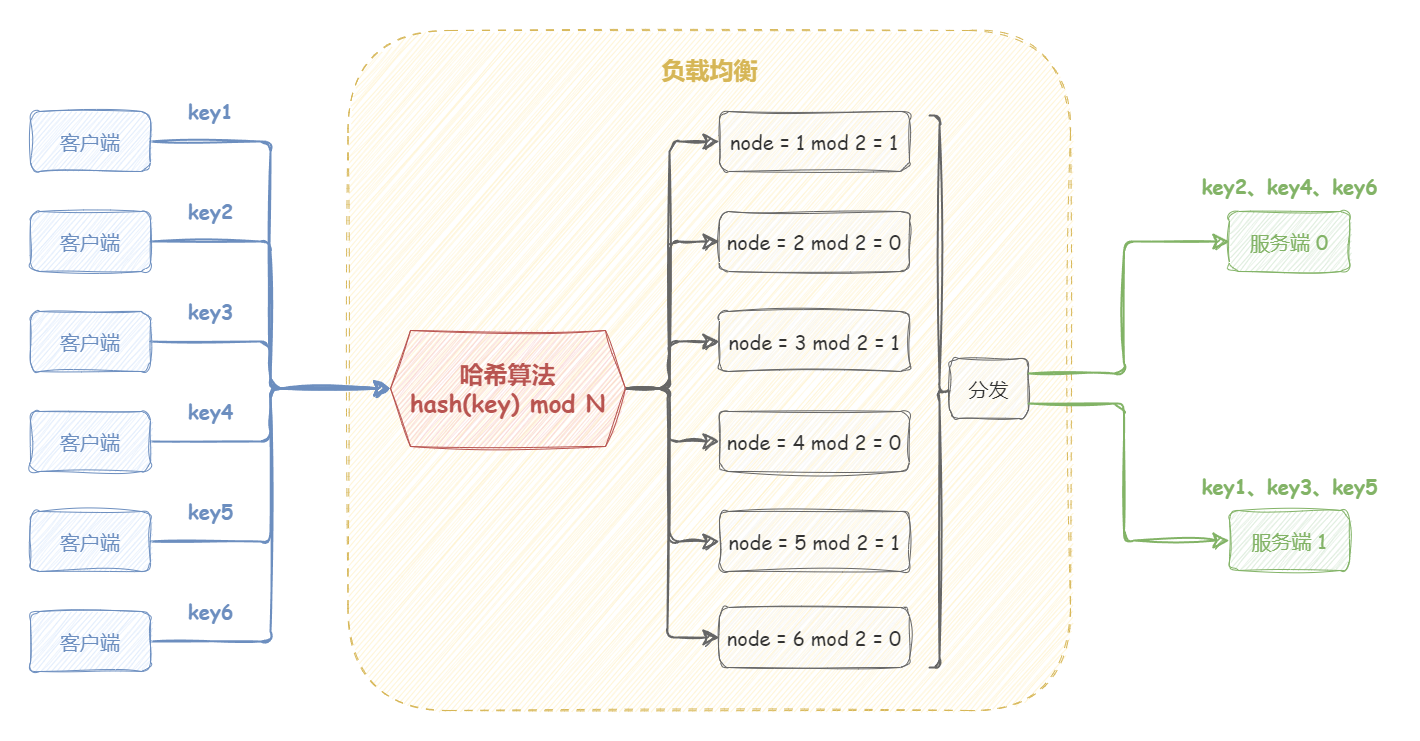
“哈希算法(Hash)” 根据一个 key (可以是唯一 ID、IP、URL 等),通过哈希函数计算得到一个数值,用该数值在候选机器列表的进行取模运算,得到的结果便是选中的机器 。
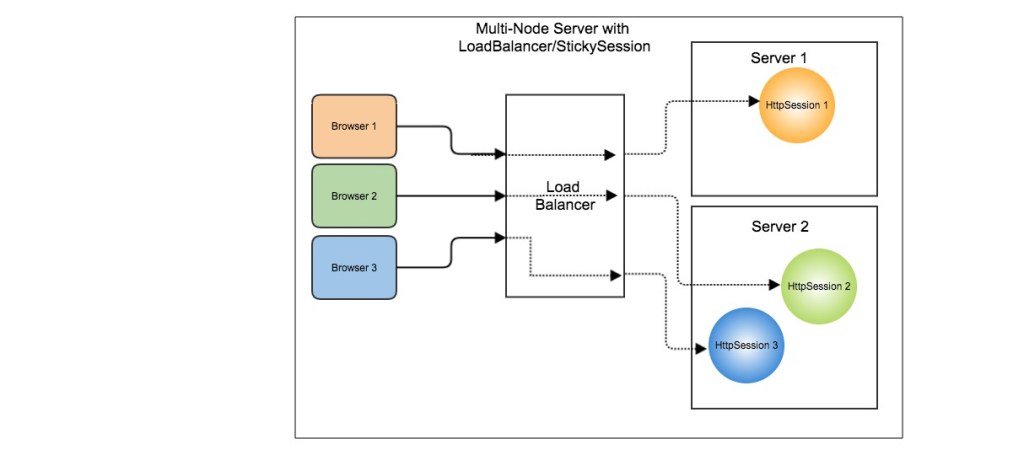
这种算法可以保证,同一关键字(IP 或 URL 等)的请求,始终会被转发到同一台机器上。哈希负载均衡算法常被用于实现会话粘滞(Sticky Session)。
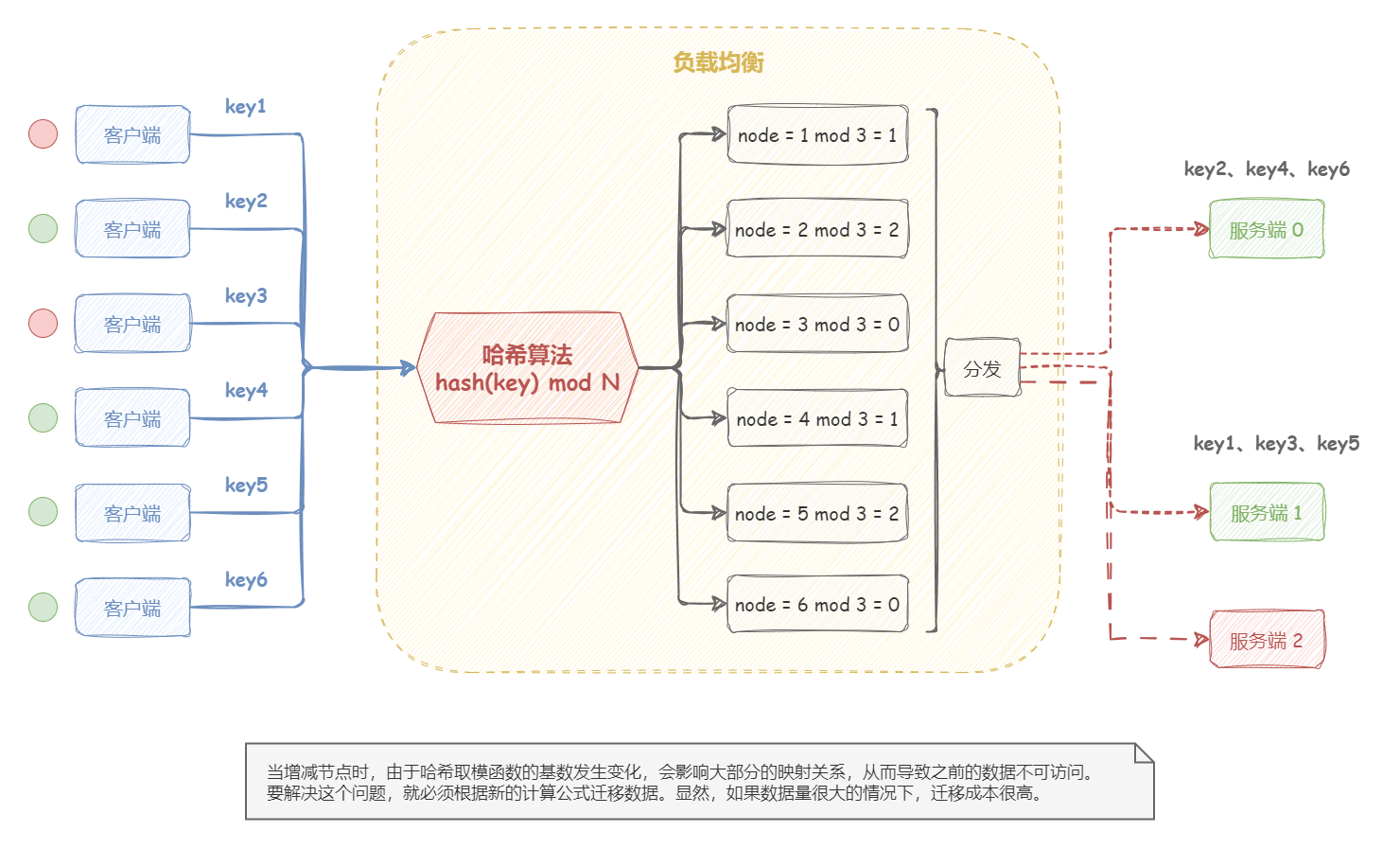
但是 ,哈希算法的问题是:当增减节点时,由于哈希取模函数的基数发生变化,会影响大部分的映射关系,从而导致之前的数据不可访问。要解决这个问题,就必须根据新的计算公式迁移数据。显然,如果数据量很大的情况下,迁移成本很高;并且,在迁移过程中,要保证业务平滑过渡,需要使用数据双写等较为复杂的技术手段。
【示例】源地址哈希算法实现示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class IpHashLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { @Override protected N doSelect (List<N> nodes, String ip) { if (StrUtil.isBlank(ip)) { ip = "127.0.0.1" ; } int length = nodes.size(); int index = hash(ip) % length; return nodes.get(index); } public int hash (String text) { return HashUtil.fnvHash(text); } }
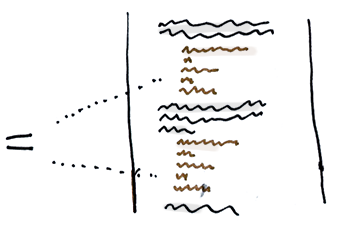
一致性哈希算法 哈希算法的缺点是:当集群中出现增减节点时,由于哈希取模函数的基数发生变化,会导致大量集群中的机器不可用;需要通过代价高昂的数据迁移,来解决问题。那么,我们自然会希望有一种更优化的方案,来尽量减少影响的机器数。一致性哈希算法就是为了这个目标而应运而生。
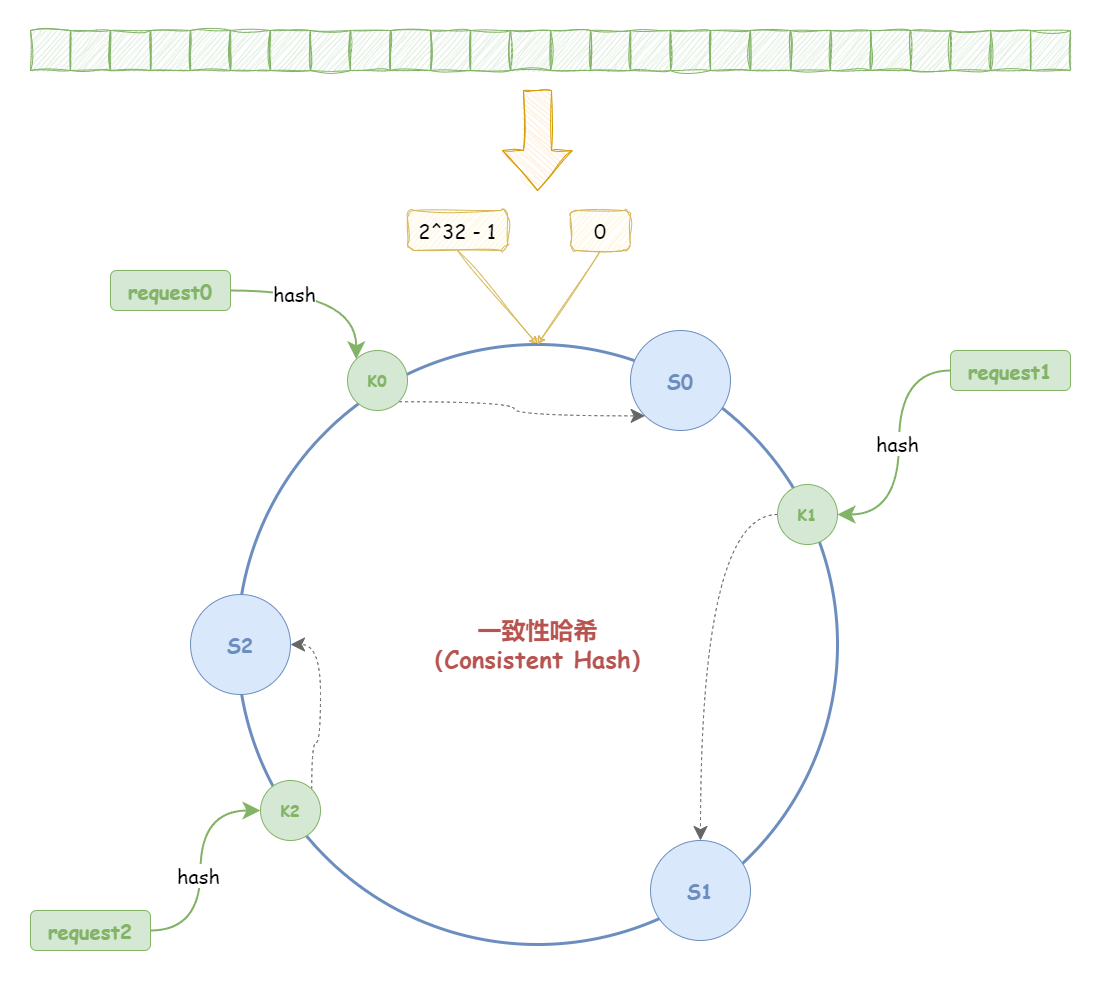
一致性哈希算法对哈希算法进行了改良。“一致性哈希算法(Consistent Hash)”,根据哈希算法将对应的 key 哈希到一个具有 2^32 个桶的空间,并且头尾相连(0 到 2^32-1),即一个闭合的环形,这个圆环被称为“哈希环” 。哈希算法是对节点的数量进行取模运算;而一致性哈希算法则是对 2^32 进行取模运算。
哈希环的空间是按顺时针方向组织的 ,需要对指定 key 的数据进行读写时,会执行两步:
先对节点进行哈希计算,计算的关键字通常是 IP 或其他唯一标识(例:hash(ip)),然后对 2^32 取模,以确定节点在哈希环上的位置。
先对 key 进行哈希计算(hash(key)),然后对 2^32 取模,以确定 key 在哈希环上的位置。
然后根据 key 的位置,顺时针找到的第一个节点,就是 key 对应的节点。
所以,一致性哈希是将“存储节点”和“数据”都映射到一个顺时针排序的哈希环上 。
一致性哈希算法会尽可能保证,相同的请求被分发到相同的机器上。当出现增减节点时,只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响,不会引起剧烈变动 。
相同的请求 是指:一般在使用一致性哈希时,需要指定一个 key 用于 hash 计算,可能是:用户 ID、请求方 IP、请求服务名称,参数列表构成的串尽可能 是指:哈希环上出现增减节点时,少数机器的变化不应该影响大多数的请求。
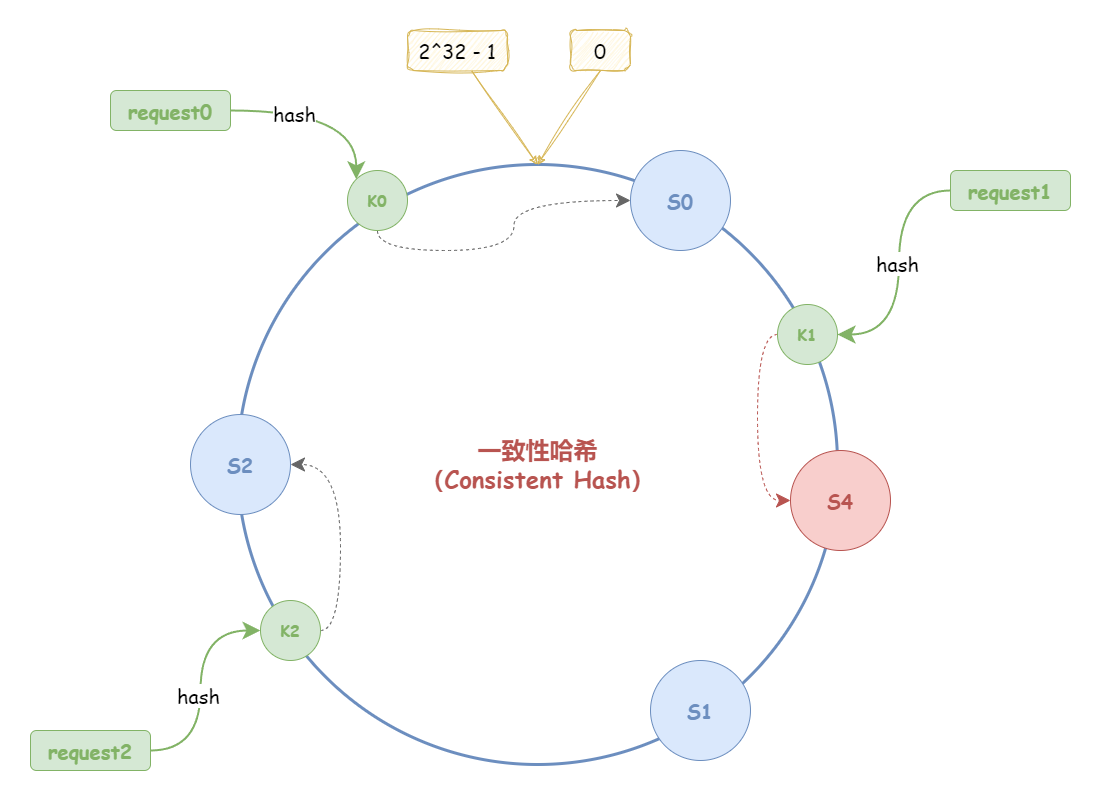
(1)增加节点
如下图所示,假设,哈希环中新增了一个节点 S4,新增节点经过哈希计算映射到图中位置:
此时,只有 K1 收到影响;而 K0、K2 均不受影响。
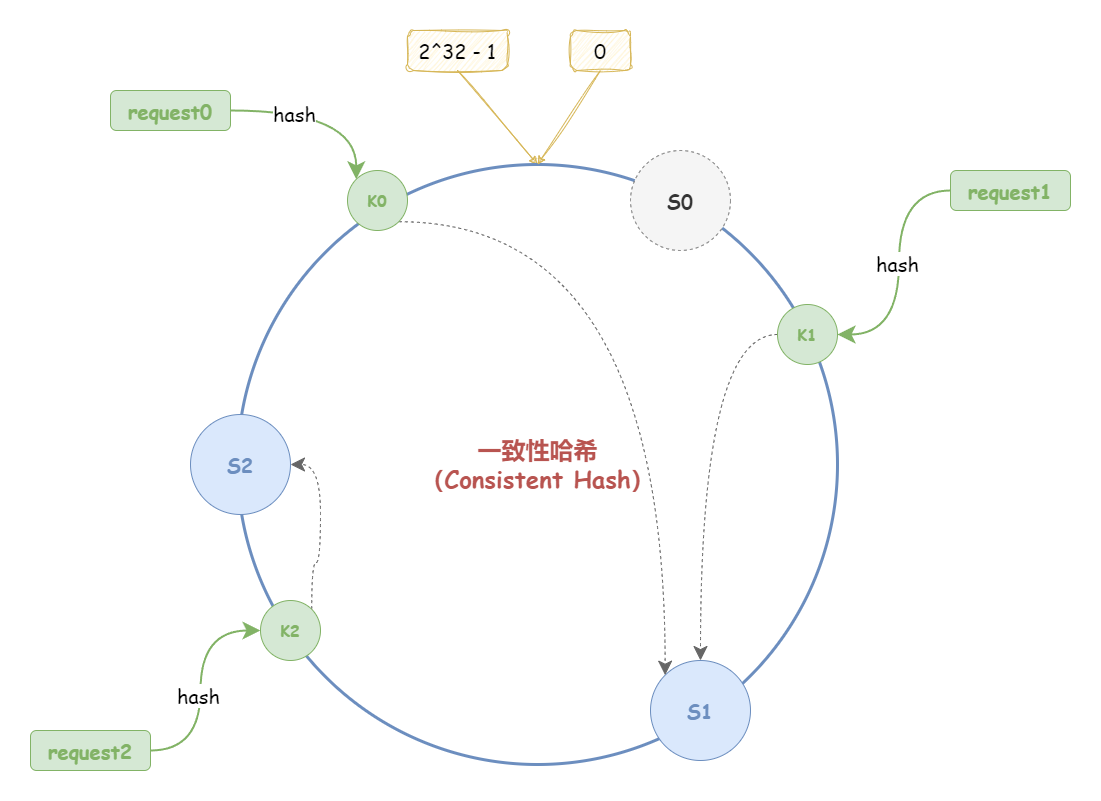
(2)减少节点
如下图所示,假设,哈希环中减少了一个节点 S0:
此时,只有 K0 收到影响;而 K1、K2 均不受影响。
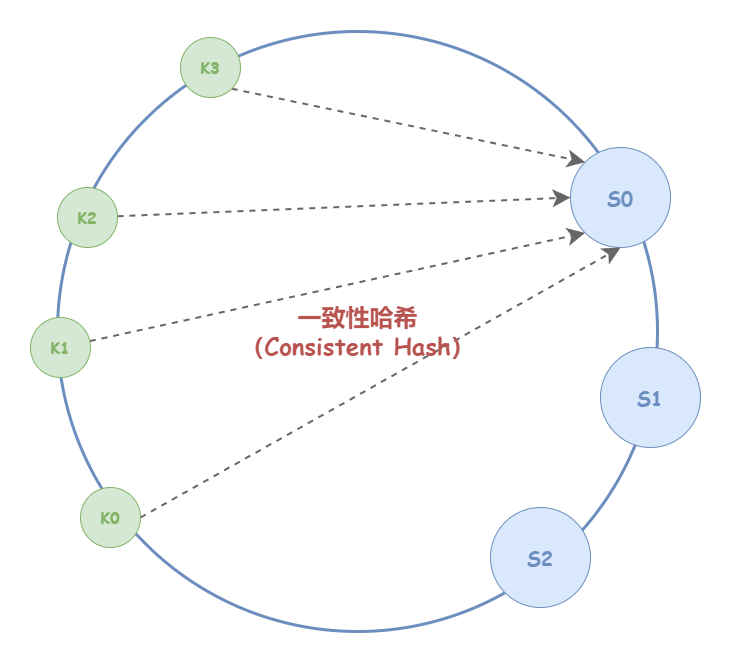
一致性哈希算法并不保证节点能够在哈希环上分布均匀 ,由此而产生一个问题,哈希环上可能有大量的请求集中在一个节点上。从概率角度来看,哈希环上的节点越多,分布就越均匀 。正因为如此,一致性哈希算法不适用于节点数过少的场景。
如下图所示:极端情况下,可能由于节点在哈希环上分布不均,有大量请求计算得到的 key 会被集中映射到少数节点,甚至某一个节点上。此外,节点分布不均匀的情况下,进行容灾与扩容时,哈希环上的相邻节点容易受到过大影响,从而引发雪崩式的连锁反应。
【示例】一致性哈希算法示例
以下示例基于 Dubbo 的一致性哈希负载均衡算法做了一些简化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 public class ConsistentHashLoadBalance <N extends Node > extends BaseLoadBalance <N> implements LoadBalance <N> { private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap <>(); @SuppressWarnings("unchecked") @Override protected N doSelect (List<N> nodes, String ip) { Integer replicaNum = nodes.size() * 4 ; int identityHashCode = System.identityHashCode(nodes); ConsistentHashSelector<N> selector = (ConsistentHashSelector<N>) selectors.get(ip); if (selector == null || selector.identityHashCode != identityHashCode) { selectors.put(ip, new ConsistentHashSelector <>(nodes, identityHashCode, replicaNum)); selector = (ConsistentHashSelector<N>) selectors.get(ip); } return selector.select(ip); } private static final class ConsistentHashSelector <N extends Node > { private final TreeMap<Long, N> virtualNodes; private final int identityHashCode; ConsistentHashSelector(List<N> nodes, int identityHashCode, Integer replicaNum) { this .virtualNodes = new TreeMap <>(); this .identityHashCode = identityHashCode; if (replicaNum == null ) { replicaNum = 100 ; } for (N node : nodes) { for (int i = 0 ; i < replicaNum / 4 ; i++) { byte [] digest = md5(node.getUrl()); for (int j = 0 ; j < 4 ; j++) { long m = hash(digest, j); virtualNodes.put(m, node); } } } } public N select (String key) { byte [] digest = md5(key); return selectForKey(hash(digest, 0 )); } private N selectForKey (long hash) { Map.Entry<Long, N> entry = virtualNodes.ceilingEntry(hash); if (entry == null ) { entry = virtualNodes.firstEntry(); } return entry.getValue(); } } public static long hash (byte [] digest, int number) { return (((long ) (digest[3 + number * 4 ] & 0xFF ) << 24 ) | ((long ) (digest[2 + number * 4 ] & 0xFF ) << 16 ) | ((long ) (digest[1 + number * 4 ] & 0xFF ) << 8 ) | (digest[number * 4 ] & 0xFF )) & 0xFFFFFFFFL ; } public static byte [] md5(String value) { MessageDigest md5; try { md5 = MessageDigest.getInstance("MD5" ); } catch (NoSuchAlgorithmException e) { throw new IllegalStateException (e.getMessage(), e); } md5.reset(); byte [] bytes = value.getBytes(StandardCharsets.UTF_8); md5.update(bytes); return md5.digest(); } }
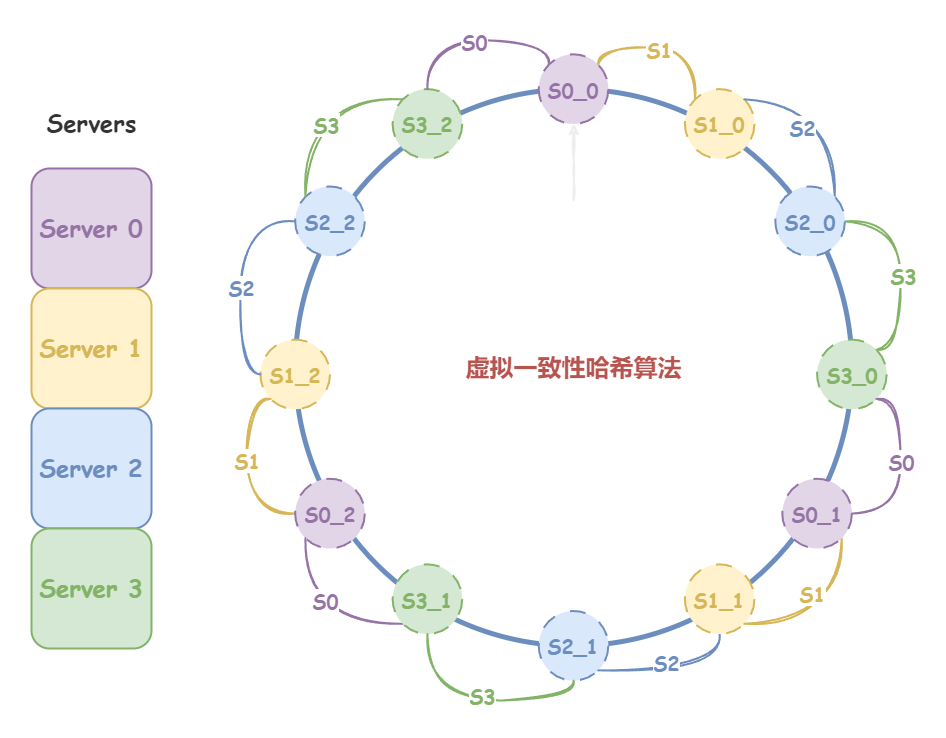
虚拟一致性哈希算法 在一致性哈希算法中,如果节点数过少,可能会分布不均,从而导致负载不均衡。在实际生产环境中,一个分布式系统应该具备良好的伸缩性,既能从容的扩展到大规模的集群,也要能支持小规模的集群。为此,又产生了虚拟哈希算法,进一步对一致性哈希算法进行了改良。
虚拟哈希算法的解决思路是:虽然实际的集群可能节点数较少,但是在哈希环上引入大量的虚拟哈希节点。具体来说,“虚拟哈希算法”有二次映射:先将虚拟节点映射到哈希环上,再将虚拟节点映射到实际节点上。
如下图所示,假设存在这样的场景:
分布式集群中有 4 个真实节点,分别是:S0、S1、S2、S3;
我们不妨先假定分配给哈希环 12 个虚拟节点,并将虚拟节点映射到真实节点上,映射关系如下:
S0 - S0_0、S0_1、S0_2、S0_3
S1 - S1_0、S1_1、S1_2、S1_3
S2 - S2_0、S2_1、S2_2、S2_3
S3 - S3_0、S3_1、S3_2、S3_3
通过引入虚拟哈希节点,是的哈希环上的节点分布相对均匀了。举例来说,假如此时,某请求的 key 哈希取模后,先映射到哈希环的 [S3_2, S0_0]、[S3_0, S0_1]、[S3_1, S0_2] 这三个区间的任意一点;接下来的二次映射都会匹配到真实节点 S0。
在实际应用中,虚拟哈希节点数一般都比较大(例如:Redis 的虚拟哈希槽有 16384 个),较大的数量保证了虚拟哈希环上的节点分布足够均匀。
虚拟节点除了会提高节点的均衡度,还会提高系统的稳定性。当节点变化时,会有不同的节点共同分担系统的变化,因此稳定性更高 。例如,当某个节点被移除时,分配给该节点的多个虚拟节点会被一并移除,而这些虚拟节点按顺时针方向的下一个虚拟节点,可能会对应不同的真实节点,即这些不同的真实节点共同分担了节点变化导致的压力。
此外,有了虚拟节点后,可以通过调整分配给真实节点的虚拟节点数,来达到设置权重一样的效果,使得负载均衡更加灵活。
综上所述,虚拟一致性哈希算法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景 。
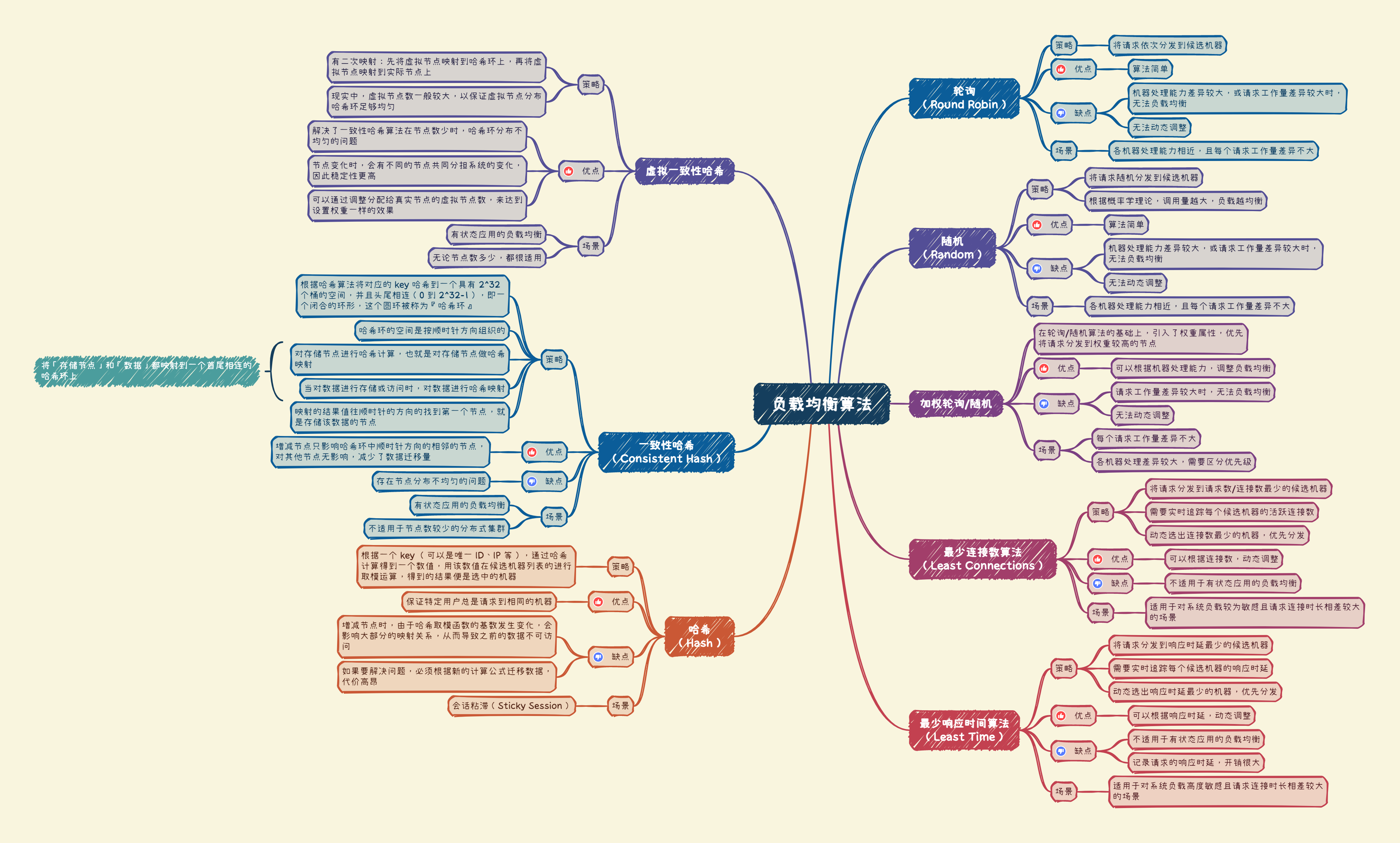
小结 下面通过一张思维导图对介绍的负载均衡算法做一个小结:
参考资料