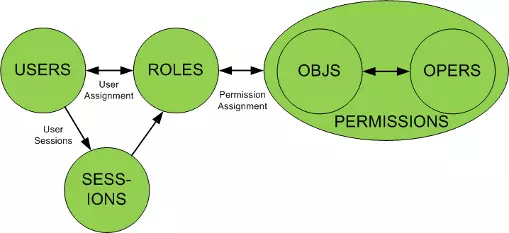
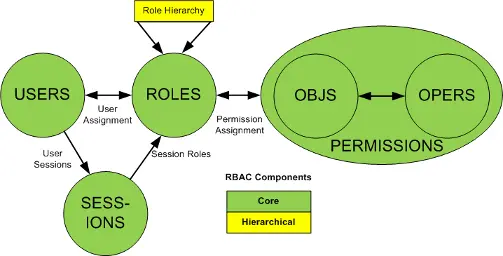
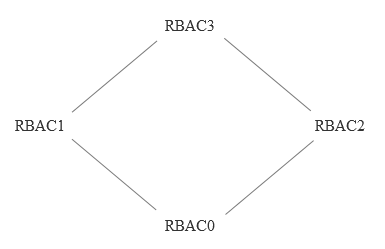
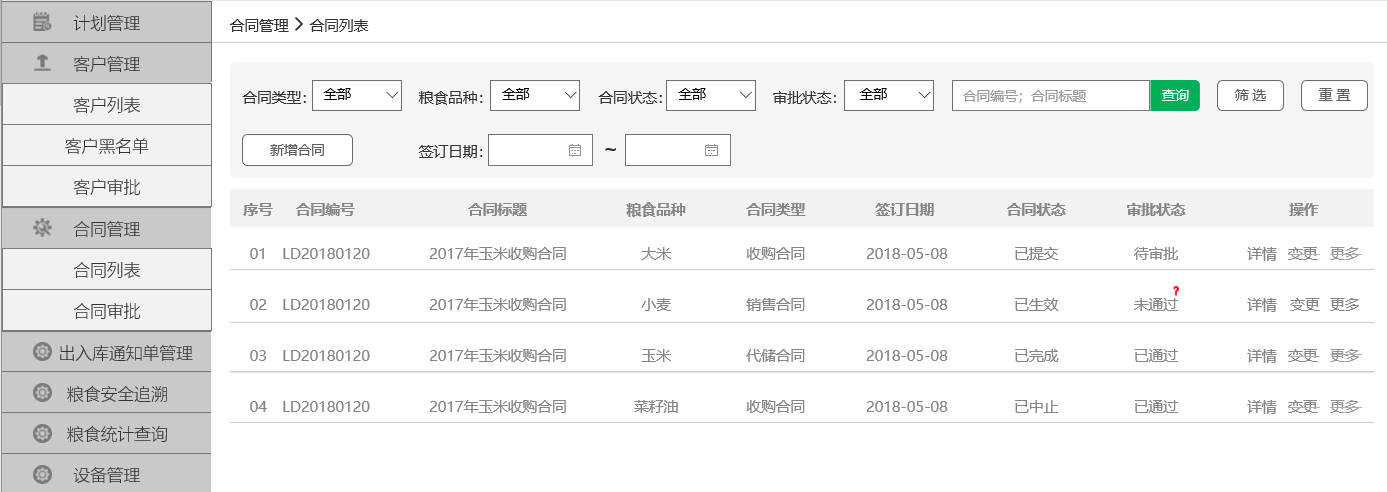
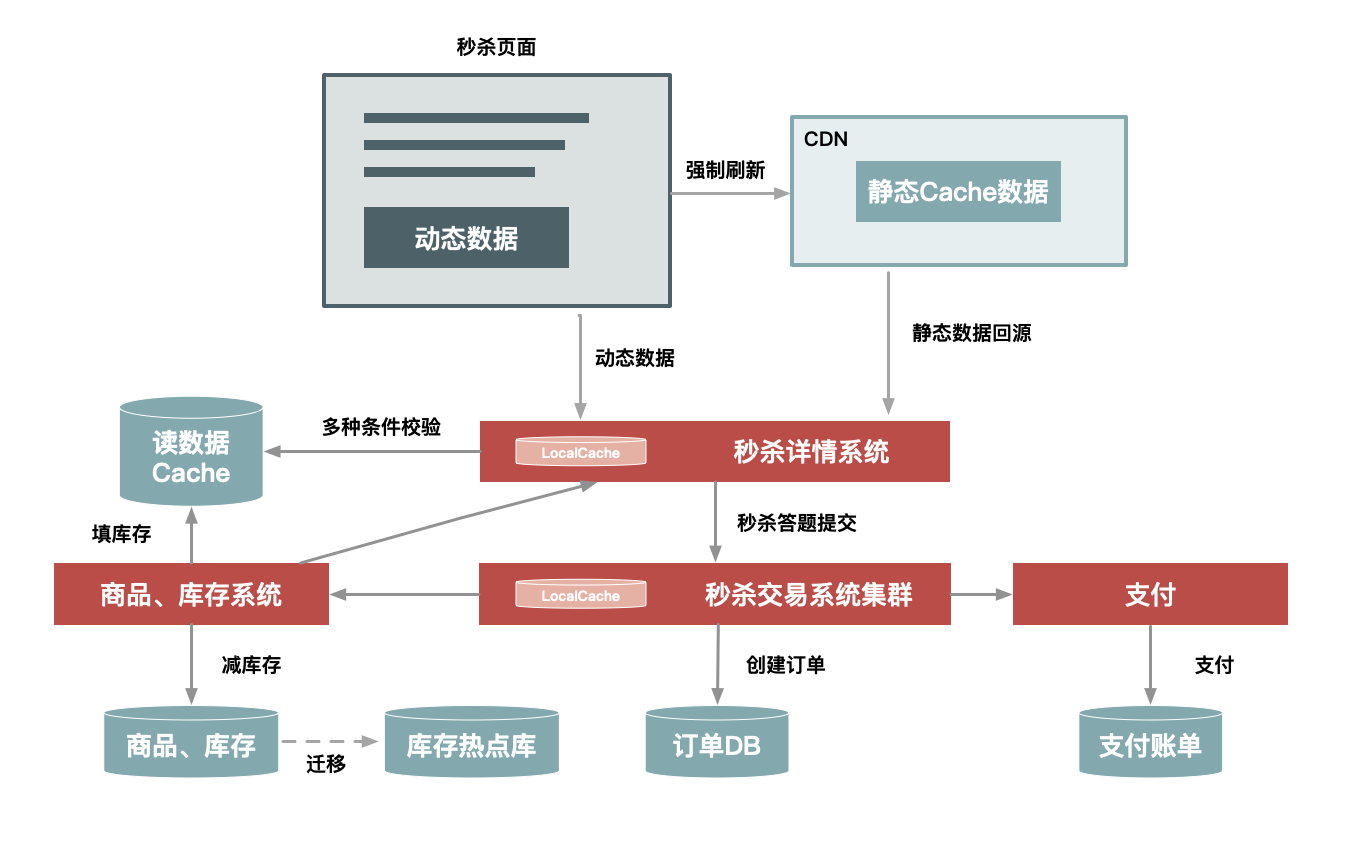
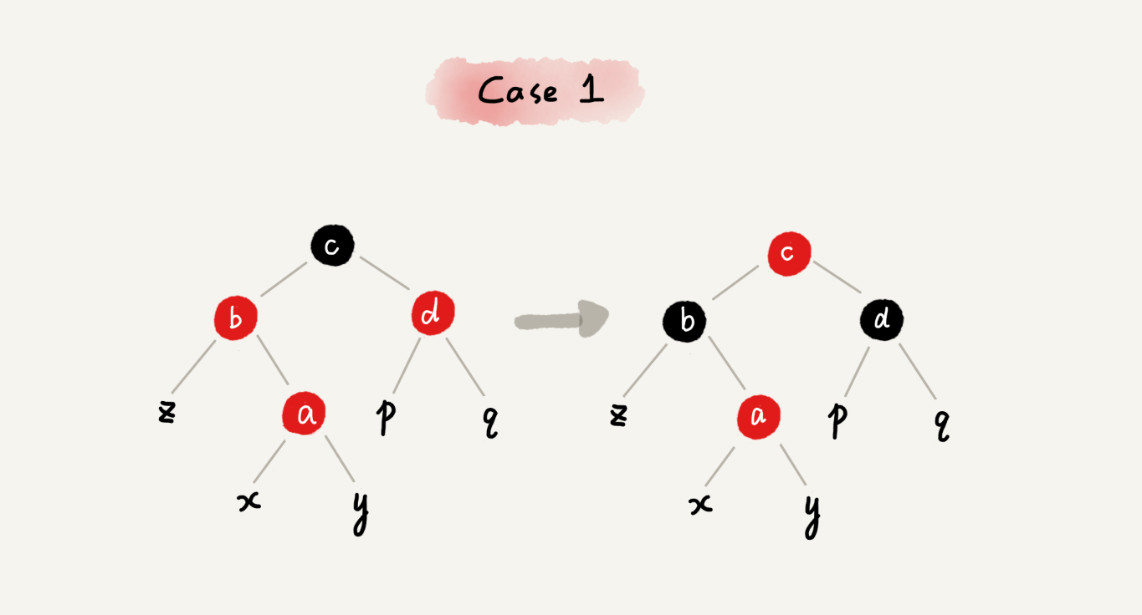
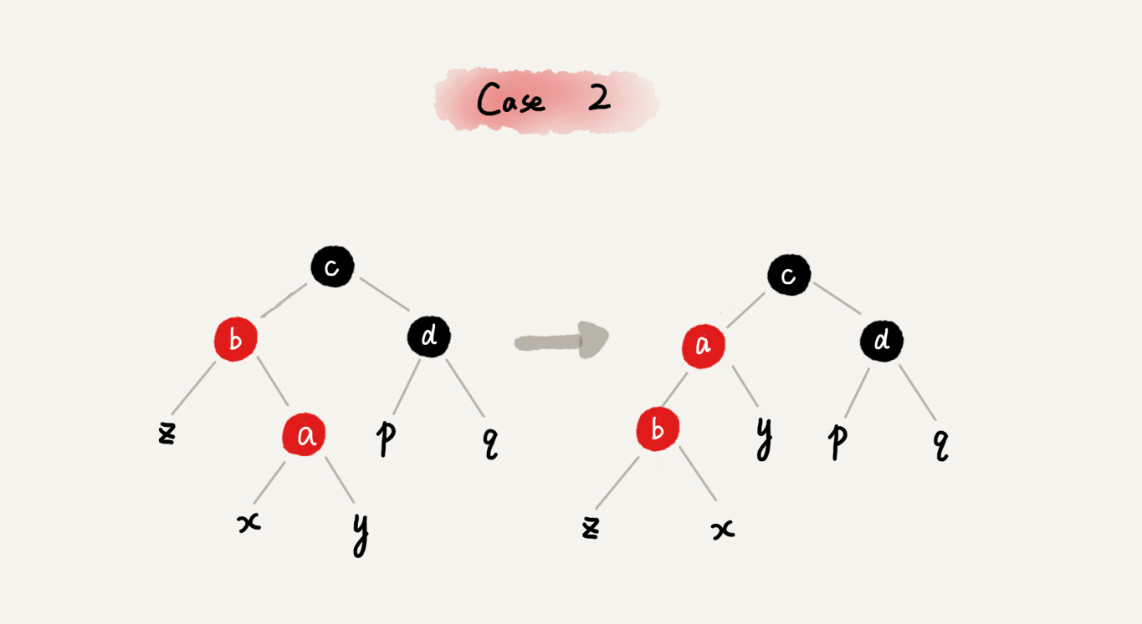
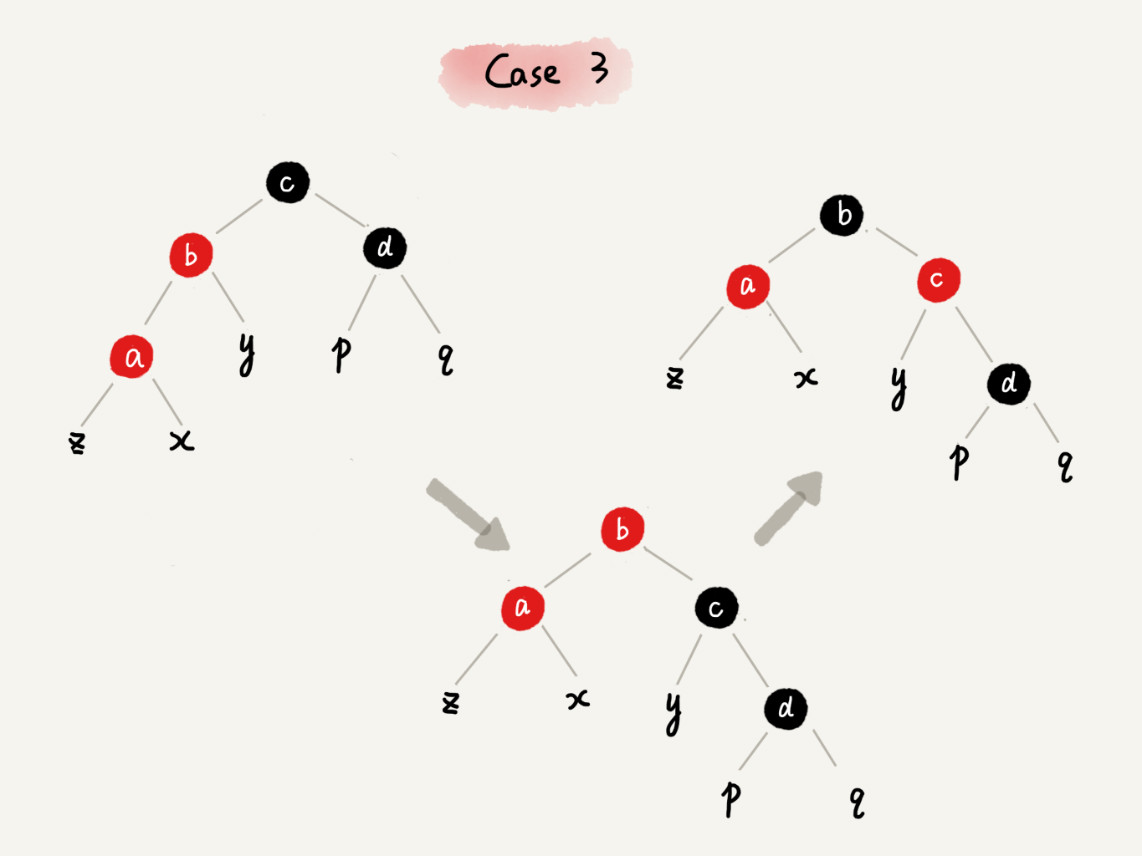
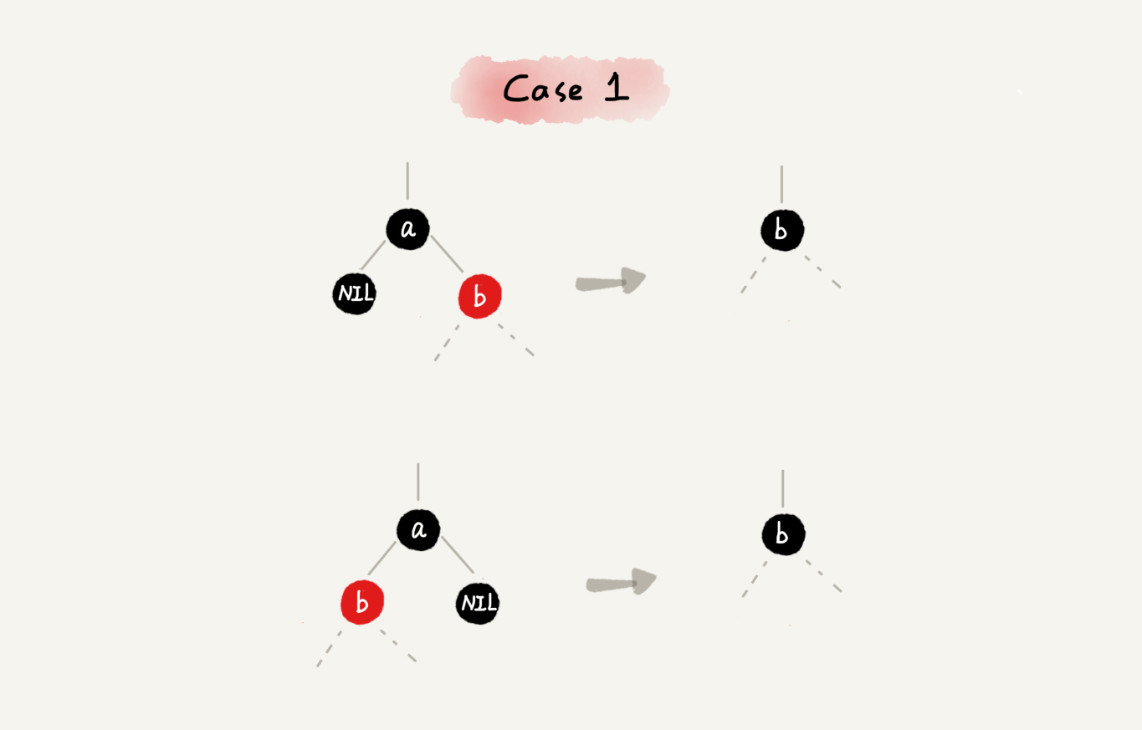
减库存在数据一致性上,主要就是保证大并发请求时库存数据不能为负数,也就是要保证数据库中的库存字段值不能为负数,一般我们有多种解决方案:一种是在应用程序中通过事务来判断,即保证减后库存不能为负数,否则就回滚;另一种办法是直接设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时会直接执行 SQL 语句来报错;再有一种就是使用 CASE WHEN 判断语句,例如这样的 SQL 语句:
1
UPDATE item SET inventory = CASEWHEN inventory >= xxx THEN inventory-xxx ELSE inventory END
Window -> Preferences -> Web -> HTML Files -> Editor -> Content Assist -> Auto-Activation
保存后,我们再来输入看看,感觉真是不错呀:
插件安装
很多教科书上说到 Eclipse 的插件安装都是通过 Help -> Install New SoftWare 这种自动检索的方式,操作起来固然是方便,不过当我们不需要某种插件时不太容易找到要删除哪些内容,而且以后 Eclipse 版本升级的时候,通过这种方式安装过的插件都得再重新装一次。另外一种通过 Link 链接方式,就可以解决这些问题。
defprint_func1(): a = 17# 局部变量 print("in print_func a = ", a) defprint_func2(): print("in print_func a = ", a) print_func1() print_func2() print("a = ", a)
以上实例运行结果如下:
1 2 3
in print_func a = 17 in print_func a = 4 a = 4
关键字参数
函数也可以使用 kwarg=value 的关键字参数形式被调用.例如,以下函数:
1 2 3 4 5
defparrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'): print("-- This parrot wouldn't", action, end=' ') print("if you put", voltage, "volts through it.") print("-- Lovely plumage, the", type) print("-- It's", state, "!")
parrot()# required argument missing parrot(voltage=5.0, 'dead')# non-keyword argument after a keyword argument parrot(110, voltage=220)# duplicate value for the same argument parrot(actor='John Cleese')# unknown keyword argument
try: f = open('myfile.txt') s = f.readline() i = int(s.strip()) except OSError as err: print("OS error: {0}".format(err)) except ValueError: print("Could not convert data to an integer.") except: print("Unexpected error:", sys.exc_info()[0]) raise finally: # 清理行为
抛出异常
Python 使用 raise 语句抛出一个指定的异常。例如:
1 2 3 4
>>> raise NameError('HiThere') Traceback (most recent call last): File "<stdin>", line 1, in ? NameError: HiThere
classError(Exception): """Base class for exceptions in this module.""" pass
classInputError(Error): """Exception raised for errors in the input. Attributes: expression -- input expression in which the error occurred message -- explanation of the error """
classTransitionError(Error): """Raised when an operation attempts a state transition that's not allowed. Attributes: previous -- state at beginning of transition next -- attempted new state message -- explanation of why the specific transition is not allowed """
>>> sys.stderr.write('Warning, log file not found starting a new one\n') Warning, log file not found starting a new one
字符串正则匹配
re 模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
1 2 3 4 5
>>> import re >>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') ['foot', 'fell', 'fastest'] >>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat') 'cat in the hat'
privatevoidgrow(int minCapacity) { // overflow-conscious code intoldCapacity= elementData.length; intnewCapacity= oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
ArrayList 在每一次有效的删除操作后,都要进行数组的重组,并且删除的元素位置越靠前,数组重组的开销就越大。具体来说,ArrayList 会**调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上。
1 2 3 4 5 6 7 8 9 10 11 12 13
public E remove(int index) { rangeCheck(index);
modCount++; EoldValue= elementData(index);
intnumMoved= size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work
privatevoidwriteObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff intexpectedModCount= modCount; s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone() s.writeInt(size);
// Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); }
if (modCount != expectedModCount) { thrownewConcurrentModificationException(); } }
if (index < (size >> 1)) { Node<E> x = first; for (inti=0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (inti= size - 1; i > index; i--) x = x.prev; return x; } }
privatevoidlinkFirst(E e) { final Node<E> f = first; final Node<E> newNode = newNode<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; }
voidlinkLast(E e) { final Node<E> l = last; final Node<E> newNode = newNode<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
voidlinkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = newNode<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
算法如下:
将新添加的数据包装为 Node;
如果往头部添加元素,将头指针 first 指向新的 Node,之前的 first 对象的 prev 指向新的 Node。
如果是向尾部添加元素,则将尾指针 last 指向新的 Node,之前的 last 对象的 next 指向新的 Node。
publicbooleanremove(Object o) { if (o == null) { // 遍历找到要删除的元素节点 for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { // 遍历找到要删除的元素节点 for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
E unlink(Node<E> x) { // assert x != null; finalEelement= x.item; final Node<E> next = x.next; final Node<E> prev = x.prev;
if (prev == null) { first = next; } else { prev.next = next; x.prev = null; }
if (next == null) { last = prev; } else { next.prev = prev; x.next = null; }
ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
LinkedList 采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、 removeLast()),时间复杂度为 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
CREATEVIEW ProductCustomers AS SELECT cust_name, cust_contact, prod_id FROM Customers, Orders, OrderItems WHERE Customers.cust_id = Orders.cust_id AND OrderItems.order_num = Orders.order_num;
检索订购了产品 RGAN01 的顾客
1 2 3
SELECT cust_name, cust_contact FROM ProductCustomers WHERE prod_id ='RGAN01';
PRIMARY KEY - PRIMARY KEY 的作用是唯一标识一条记录,不能重复,不能为空,即相当于 NOT NULL + UNIQUE。确保字段(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 用于检查字段取值范围的有效性。
DEFAULT - 表明字段的默认值。如果插入数据时,该字段没有赋值,就会被设置为默认值。
以下为约束定义示例:
::: tabs#约束定义
@tab NOT NULL
1 2 3
CREATE TABLE demo ( id INT UNSIGNED NOT NULL );
@tab UNIQUE KEY
1 2 3 4
CREATE TABLE demo2 ( id INT UNSIGNED NOT NULL, name VARCHAR(50) NOT NULLUNIQUE KEY );
@tab PRIMARY KEY
1 2 3 4
CREATE TABLE demo3 ( id INT UNSIGNED NOT NULLPRIMARY KEY, name VARCHAR(50) NOT NULLUNIQUE KEY );
@tab FOREIGN KEY
1 2 3 4 5 6
CREATE TABLE demo4 ( id INT UNSIGNED NOT NULLPRIMARY KEY, name VARCHAR(50) NOT NULLUNIQUE KEY, fid INT UNSIGNED, FOREIGN KEY (fid) REFERENCES demo3(id) );
@tab CHECK
1 2 3 4 5
CREATE TABLE demo5 ( id INT UNSIGNED NOT NULLPRIMARY KEY, name VARCHAR(50) NOT NULLUNIQUE KEY, age INTCHECK (age >0) );
@tab DEFAULT
1 2 3 4 5
CREATE TABLE demo6 ( id INT UNSIGNED NOT NULLPRIMARY KEY, name VARCHAR(50) NOT NULLUNIQUE KEY, age INTDEFAULT0 );
SELECTDISTINCT player_id, player_name, count(*) as num -- 顺序 5 FROM player JOIN team ON player.team_id = team.team_id -- 顺序 1 WHERE height >1.80-- 顺序 2 GROUPBY player.team_id -- 顺序 3 HAVING num >2-- 顺序 4 ORDERBY num DESC-- 顺序 6 LIMIT 2-- 顺序 7
SELECT column1, column2 FROM table_name WHEREcondition; SELECT*FROM table_name WHERE condition1 AND condition2; SELECT*FROM table_name WHERE condition1 OR condition2; SELECT*FROM table_name WHERENOTcondition; SELECT*FROM table_name WHERE condition1 AND (condition2 OR condition3); SELECT*FROM table_name WHEREEXISTS (SELECT column_name FROM table_name WHEREcondition)
WHERE 可以与 SELECT,UPDATE 和 DELETE 一起使用。
::: tabs#WHERE 示例
@tab SELECT 语句中的 WHERE 子句
检索所有价格小于 10 美元的产品。
1 2 3
SELECT prod_name, prod_price FROM Products WHERE prod_price <10;
检索所有不是供应商 DLL01 制造的产品
1 2 3 4 5 6 7 8 9
-- 下面两条查询语句作用相同
SELECT vend_id, prod_name FROM Products WHERE vend_id <>'DLL01';
SELECT vend_id, prod_name FROM Products WHERE vend_id !='DLL01';
检索价格在 5 美元和 10 美元之间的所有产品
1 2 3
SELECT prod_name, prod_price FROM Products WHERE prod_price BETWEEN5AND10;
检索所有没有邮件地址的顾客
1 2 3
SELECT cust_name FROM CUSTOMERS WHERE cust_email ISNULL;
@tab UPDATE 语句中的 WHERE 子句
1 2 3
UPDATE Customers SET cust_name ='Jack Jones' WHERE cust_name ='Kids Place';
@tab DELETE 语句中的 WHERE 子句
1 2
DELETEFROM Customers WHERE cust_name ='Kids Place';
:::
比较操作符
操作符
描述
=
等于
<>
不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=
>
大于
<
小于
>=
大于等于
<=
小于等于
IS NULL
是否为空
【示例】查询所有价格小于 10 美元的产品
1 2 3
SELECT prod_name, prod_price FROM Products WHERE prod_price <10;
【示例】查询所有不是供应商 DLL01 制造的产品
1 2 3
SELECT vend_id, prod_name FROM Products WHERE vend_id !='DLL01';
【示例】查询邮件地址为空的客户
1 2 3
SELECT cust_name FROM CUSTOMERS WHERE cust_email ISNULL;
范围操作符
操作符
描述
BETWEEN
在某个范围内
IN
指定针对某个列的多个可能值
BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。
IN 操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN 取一组由逗号分隔、括在圆括号中的合法值。
为什么要使用 IN 操作符?其优点如下。
在有很多合法选项时,IN 操作符的语法更清楚,更直观。
在与其他 AND 和 OR 操作符组合使用 IN 时,求值顺序更容易管理。
IN 操作符一般比一组 OR 操作符执行得更快(在上面这个合法选项很 少的例子中,你看不出性能差异)。
IN 的最大优点是可以包含其他 SELECT 语句,能够更动态地建立 WHERE 子句。
以下为范围操作符使用示例:
::: tabs#范围操作符
@tab IN 示例
下面两条 SQL 的语义等价:
1 2 3 4 5 6 7 8 9
SELECT prod_name, prod_price FROM Products WHERE vend_id IN ( 'DLL01', 'BRS01' ) ORDERBY prod_name;
SELECT prod_name, prod_price FROM Products WHERE vend_id ='DLL01'OR vend_id ='BRS01' ORDERBY prod_name;
@tab BETWEEN 示例
1 2 3
SELECT prod_name, prod_price FROM Products WHERE prod_price BETWEEN5AND10;
:::
逻辑操作符
操作符
描述
AND
并且(与)
OR
或者(或)
NOT
否定(非)
AND、OR、NOT 是用于对过滤条件的逻辑处理指令。
AND 优先级高于 OR,为了明确处理顺序,可以使用 ()。AND 操作符表示左右条件都要满足。
OR 操作符表示左右条件满足任意一个即可。
NOT 操作符用于否定其后条件。
以下为逻辑操作符使用示例:
::: tabs#逻辑操作符
@tab AND 示例
检索由供应商 DLL01 制造且价格小于等于 4 美元的所有产品的名称和价格
1 2 3
SELECT prod_id, prod_price, prod_name FROM Products WHERE vend_id ='DLL01'AND prod_price <=4;
@tab OR 示例
检索由供应商 DLL01 或供应商 BRS01 制造的所有产品的名称和价格
1 2 3
SELECT prod_id, prod_price, prod_name FROM Products WHERE vend_id ='DLL01'OR vend_id ='BRS01';
@tab NOT 示例
检索除 DLL01 之外的所有供应商制造的产品
1 2 3 4
SELECT prod_name FROM Products WHERENOT vend_id ='DLL01' ORDERBY prod_name;
和下面的示例作用相同
1 2 3 4
SELECT prod_name FROM Products WHERE vend_id <>'DLL01' ORDERBY prod_name;
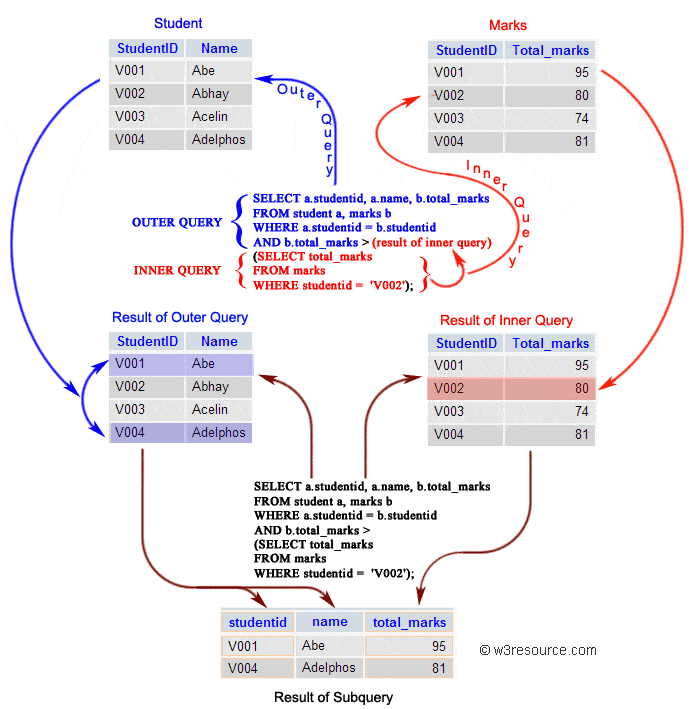
SELECT order_num FROM OrderItems WHERE prod_id ='RGAN01';
输出
1 2 3 4
order_num ----------- 20007 20008
(2) 检索具有前一步骤列出的订单编号的所有顾客的 ID。
1 2 3
SELECT cust_id FROM Orders WHERE order_num IN (20007,20008);
输出
1 2 3 4
cust_id ---------- 1000000004 1000000005
(3) 检索前一步骤返回的所有顾客 ID 的顾客信息。
1 2 3
SELECT cust_name, cust_contact FROM Customers WHERE cust_id IN ('1000000004','1000000005');
现在,结合这两个查询,把第一个查询(返回订单号的那一个)变为子查询。
1 2 3 4 5
SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id ='RGAN01');
再进一步结合第三个查询
1 2 3 4 5 6 7
SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id ='RGAN01'));
-- 子查询方式 SELECT cust_id, cust_name, cust_contact FROM customers WHERE cust_name = (SELECT cust_name FROM customers WHERE cust_contact ='Jim Jones');
-- 自联结方式 SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM customers AS c1, customers AS c2 WHERE c1.cust_name = c2.cust_name AND c2.cust_contact ='Jim Jones';
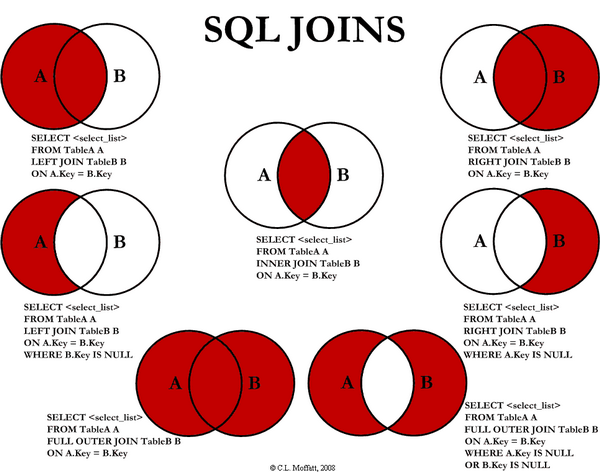
“左外联结”会获取左表所有记录,即使右表没有对应匹配的记录。左外联结使用 LEFT JOIN 关键字。
1 2 3
SELECT customers.cust_id, orders.order_num FROM customers LEFTJOIN orders ON customers.cust_id = orders.cust_id;
右联结(RIGHT JOIN)
“右外联结”会获取右表所有记录,即使左表没有对应匹配的记录。右外联结使用 RIGHT JOIN 关键字。
1 2 3
SELECT customers.cust_id, orders.order_num FROM customers RIGHTJOIN orders ON customers.cust_id = orders.cust_id;
组合(UNION)
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 基本规则:
所有查询的列数和列顺序必须相同。
每个查询中涉及表的列的数据类型必须相同或兼容。
通常返回的列名取自第一个查询。
主要有两种情况需要使用组合查询:
在一个查询中从不同的表返回结构数据;
对一个表执行多个查询,按一个查询返回数据。
把 Illinois、Indiana、Michigan 等州的缩写传递给 IN 子句,检索出这些州的所有行
1 2 3
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_state IN ('IL','IN','MI');
找出所有 Fun4All
1 2 3
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_name ='Fun4All';
组合这两条语句
1 2 3 4 5 6 7
SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNION SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4All';
UNION 默认从查询结果集中自动去除了重复的行;如果想返回所有的匹配行,可使用 UNION ALL。
1 2 3 4 5 6 7
SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNIONALL SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4All';
JOIN vs UNION
JOIN 中联结表的列可能不同,但在 UNION 中,所有查询的列数和列顺序必须相同。
UNION 将查询之后的行放在一起(垂直放置),但 JOIN 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
排序和分组
ORDER BY
ORDER BY 用于对结果集进行排序。ORDER BY 子句取一个或多个列的名字,据此对输出进行排序。ORDER BY 支持两种排序方式:
DROPPROCEDURE IF EXISTS `proc_adder`; DELIMITER ;; CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int) BEGIN DECLARE c int; if a isnullthenset a =0; end if;
-- SQL Server CREATETRIGGER customer_state ON Customers FORINSERT, UPDATE AS UPDATE Customers SET cust_state =Upper(cust_state) WHERE Customers.cust_id = inserted.cust_id;
-- Oracle 和 PostgreSQL CREATETRIGGER customer_state AFTER INSERTORUPDATE FOREACHROW BEGIN UPDATE Customers SET cust_state =Upper(cust_state) WHERE Customers.cust_id = :OLD.cust_id END;
DELIMITER $ CREATEPROCEDURE getTotal() BEGIN DECLARE total INT; -- 创建接收游标数据的变量 DECLARE sid INT; DECLARE sname VARCHAR(10); -- 创建总数变量 DECLARE sage INT; -- 创建结束标志变量 DECLARE done INTDEFAULTfalse; -- 创建游标 DECLARE cur CURSORFORSELECT id,name,age from cursor_table where age>30; -- 指定游标循环结束时的返回值 DECLARE CONTINUE HANDLER FORNOT FOUND SET done =true; SET total =0; -- 打开游标 OPEN cur; FETCH cur INTO sid, sname, sage; WHILE(NOT done) DO SET total = total +1; FETCH cur INTO sid, sname, sage; END WHILE; -- 关闭游标 CLOSE cur; SELECT total; END $ DELIMITER ;