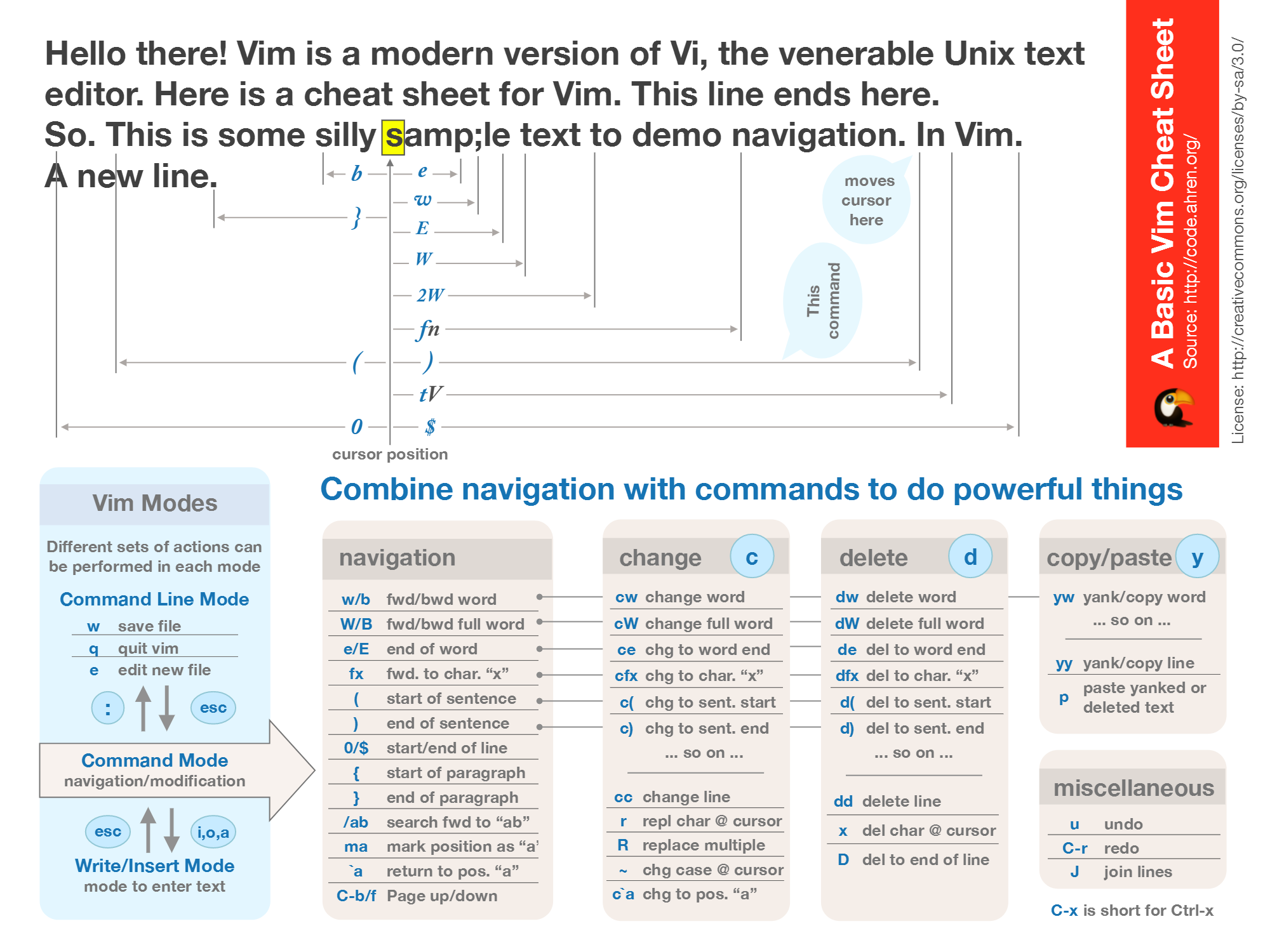
一篇文章让你彻底掌握 Shell
由于 bash 是 Linux 标准默认的 shell 解释器,可以说 bash 是 shell 编程的基础。
_本文主要介绍 bash 的语法,对于 linux 指令不做任何介绍_。
💻 本文的源码已归档到“ linux-tutorial
1 2 3 4 5 ███████╗██╗ ██╗███████╗██╗ ██╗ ██╔════╝██║ ██║██╔════╝██║ ██║ ███████╗███████║█████╗ ██║ ██║ ╚════██║██╔══██║██╔══╝ ██║ ██║ ███████║██║ ██║███████╗███████╗███████╗
简介 什么是 shell
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。
Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问 Linux 内核的服务。
Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
什么是 shell 脚本 Shell 脚本(shell script),是一种为 shell 编写的脚本程序,一般文件后缀为 .sh。
业界所说的 shell 通常都是指 shell 脚本,但 shell 和 shell script 是两个不同的概念。
Shell 环境 Shell 编程跟 java、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Shell 的解释器种类众多,常见的有:
sh - 即 Bourne Shell。sh 是 Unix 标准默认的 shell。bash - 即 Bourne Again Shell。bash 是 Linux 标准默认的 shell。fish - 智能和用户友好的命令行 shell。xiki - 使 shell 控制台更友好,更强大。zsh - 功能强大的 shell 与脚本语言。
指定脚本解释器 在 shell 脚本,#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 解释器。#! 被称作shebang(也称为 Hashbang ) 。
所以,你应该会在 shell 中,见到诸如以下的注释:
注意
上面的指定解释器的方式是比较常见的,但有时候,你可能也会看到下面的方式:
这样做的好处是,系统会自动在 PATH 环境变量中查找你指定的程序(本例中的bash)。相比第一种写法,你应该尽量用这种写法,因为程序的路径是不确定的。这样写还有一个好处,操作系统的PATH变量有可能被配置为指向程序的另一个版本。比如,安装完新版本的bash,我们可能将其路径添加到PATH中,来“隐藏”老版本。如果直接用#!/bin/bash,那么系统会选择老版本的bash来执行脚本,如果用#!/usr/bin/env bash,则会使用新版本。
模式 shell 有交互和非交互两种模式。
交互模式
简单来说,你可以将 shell 的交互模式理解为执行命令行。
看到形如下面的东西,说明 shell 处于交互模式下:
接着,便可以输入一系列 Linux 命令,比如 ls,grep,cd,mkdir,rm 等等。
非交互模式
简单来说,你可以将 shell 的非交互模式理解为执行 shell 脚本。
在非交互模式下,shell 从文件或者管道中读取命令并执行。
当 shell 解释器执行完文件中的最后一个命令,shell 进程终止,并回到父进程。
可以使用下面的命令让 shell 以非交互模式运行:
1 2 3 4 sh /path/to/script.sh bash /path/to/script.sh source /path/to/script.sh ./path/to/script.sh
上面的例子中,script.sh是一个包含 shell 解释器可以识别并执行的命令的普通文本文件,sh和bash是 shell 解释器程序。你可以使用任何喜欢的编辑器创建script.sh(vim,nano,Sublime Text, Atom 等等)。
其中,source /path/to/script.sh 和 ./path/to/script.sh 是等价的。
除此之外,你还可以通过chmod命令给文件添加可执行的权限,来直接执行脚本文件:
1 2 chmod +x /path/to/script.sh #使脚本具有执行权限 /path/to/test.sh
这种方式要求脚本文件的第一行必须指明运行该脚本的程序,比如:
💻 “示例源码”
1 2 # !/usr/bin/env bash echo "Hello, world!"
上面的例子中,我们使用了一个很有用的命令echo来输出字符串到屏幕上。
基本语法 解释器 前面虽然两次提到了#! ,但是本着重要的事情说三遍的精神,这里再强调一遍:
在 shell 脚本,#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 解释器。#! 被称作shebang(也称为 Hashbang ) 。
#! 决定了脚本可以像一个独立的可执行文件一样执行,而不用在终端之前输入sh, bash, python, php等。
1 2 3 # 以下两种方式都可以指定 shell 解释器为 bash,第二种方式更好 # !/bin/bash # !/usr/bin/env bash
注释 注释可以说明你的代码是什么作用,以及为什么这样写。
shell 语法中,注释是特殊的语句,会被 shell 解释器忽略。
单行注释 - 以 # 开头,到行尾结束。
多行注释 - 以 :<<EOF 开头,到 EOF 结束。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # -------------------------------------------- # shell 注释示例 # author:zp # -------------------------------------------- # echo '这是单行注释' # :<<EOF echo '这是多行注释' echo '这是多行注释' echo '这是多行注释' EOF
echo echo 用于字符串的输出。
输出普通字符串:
1 2 echo "hello, world" # Output: hello, world
输出含变量的字符串:
1 2 echo "hello, \"zp\"" # Output: hello, "zp"
输出含变量的字符串:
1 2 3 name=zp echo "hello, \"${name}\"" # Output: hello, "zp"
输出含换行符的字符串:
1 2 3 4 5 6 7 8 # 输出含换行符的字符串 echo "YES\nNO" # Output: YES\nNO echo -e "YES\nNO" # -e 开启转义 # Output: # YES # NO
输出含不换行符的字符串:
1 2 3 4 5 6 7 8 9 10 echo "YES" echo "NO" # Output: # YES # NO echo -e "YES\c" # -e 开启转义 \c 不换行 echo "NO" # Output: # YESNO
输出重定向至文件
输出执行结果
1 2 echo `pwd` # Output:(当前目录路径)
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # !/usr/bin/env bash # 输出普通字符串 echo "hello, world" # Output: hello, world # 输出含变量的字符串 echo "hello, \"zp\"" # Output: hello, "zp" # 输出含变量的字符串 name=zp echo "hello, \"${name}\"" # Output: hello, "zp" # 输出含换行符的字符串 echo "YES\nNO" # Output: YES\nNO echo -e "YES\nNO" # -e 开启转义 # Output: # YES # NO # 输出含不换行符的字符串 echo "YES" echo "NO" # Output: # YES # NO echo -e "YES\c" # -e 开启转义 \c 不换行 echo "NO" # Output: # YESNO # 输出内容定向至文件 echo "test" > test.txt # 输出执行结果 echo `pwd` # Output:(当前目录路径)
printf printf 用于格式化输出字符串。
默认,printf 不会像 echo 一样自动添加换行符,如果需要换行可以手动添加 \n。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # 单引号 printf '%d %s\n' 1 "abc" # Output:1 abc # 双引号 printf "%d %s\n" 1 "abc" # Output:1 abc # 无引号 printf %s abcdef # Output: abcdef(并不会换行) # 格式只指定了一个参数,但多出的参数仍然会按照该格式输出 printf "%s\n" abc def # Output: # abc # def printf "%s %s %s\n" a b c d e f g h i j # Output: # a b c # d e f # g h i # j # 如果没有参数,那么 %s 用 NULL 代替,%d 用 0 代替 printf "%s and %d \n" # Output: # and 0 # 格式化输出 printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234 printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543 printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876 # Output: # 姓名 性别 体重kg # 郭靖 男 66.12 # 杨过 男 48.65 # 郭芙 女 47.99
printf 的转义符
序列
说明
\a警告字符,通常为 ASCII 的 BEL 字符
\b后退
\c抑制(不显示)输出结果中任何结尾的换行字符(只在%b 格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略
\f换页(formfeed)
\n换行
\r回车(Carriage return)
\t水平制表符
\v垂直制表符
\\一个字面上的反斜杠字符
\ddd表示 1 到 3 位数八进制值的字符。仅在格式字符串中有效
\0ddd表示 1 到 3 位的八进制值字符
变量 跟许多程序设计语言一样,你可以在 bash 中创建变量。
Bash 中没有数据类型,bash 中的变量可以保存一个数字、一个字符、一个字符串等等。同时无需提前声明变量,给变量赋值会直接创建变量。
变量命名原则
命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
中间不能有空格,可以使用下划线(_)。
不能使用标点符号。
不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
声明变量 访问变量的语法形式为:${var} 和 $var 。
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,所以推荐加花括号。
1 2 3 word="hello" echo ${word} # Output: hello
只读变量 使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
1 2 3 4 rword="hello" echo ${rword} readonly rword # rword="bye"
删除变量 使用 unset 命令可以删除变量。变量被删除后不能再次使用。unset 命令不能删除只读变量。
1 2 3 4 5 6 7 dword="hello" # 声明变量 echo ${dword} # 输出变量值 # Output: hello unset dword # 删除变量 echo ${dword} # Output: (空)
变量类型
局部变量 - 局部变量是仅在某个脚本内部有效的变量。它们不能被其他的程序和脚本访问。环境变量 - 环境变量是对当前 shell 会话内所有的程序或脚本都可见的变量。创建它们跟创建局部变量类似,但使用的是 export 关键字,shell 脚本也可以定义环境变量。
常见的环境变量:
变量
描述
$HOME当前用户的用户目录
$PATH用分号分隔的目录列表,shell 会到这些目录中查找命令
$PWD当前工作目录
$RANDOM0 到 32767 之间的整数
$UID数值类型,当前用户的用户 ID
$PS1主要系统输入提示符
$PS2次要系统输入提示符
这里 有一张更全面的 Bash 环境变量列表。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 # !/usr/bin/env bash # name="world" echo "hello ${name}" # Output: hello world # folder=$(pwd) echo "current path: ${folder}" # rword="hello" echo ${rword} # Output: hello readonly rword # rword="bye" # dword="hello" # 声明变量 echo ${dword} # 输出变量值 # Output: hello unset dword # 删除变量 echo ${dword} # Output: (空) # echo "UID:$UID" echo LOGNAME:$LOGNAME echo User:$USER echo HOME:$HOME echo PATH:$PATH echo HOSTNAME:$HOSTNAME echo SHELL:$SHELL echo LANG:$LANG # days=10 user="admin" echo "$user logged in $days days age" days=5 user="root" echo "$user logged in $days days age" # Output: # admin logged in 10 days age # root logged in 5 days age # colors="Red Yellow Blue" colors=$colors" White Black" for color in $colors do echo " $color" done
字符串 单引号和双引号 shell 字符串可以用单引号 '',也可以用双引号 “”,也可以不用引号。
单引号的特点
单引号里不识别变量
单引号里不能出现单独的单引号(使用转义符也不行),但可成对出现,作为字符串拼接使用。
双引号的特点
综上,推荐使用双引号。
拼接字符串 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 使用单引号拼接 name1='white' str1='hello, '${name1}'' str2='hello, ${name1}' echo ${str1}_${str2} # Output: # hello, white_hello, ${name1} # 使用双引号拼接 name2="black" str3="hello, "${name2}"" str4="hello, ${name2}" echo ${str3}_${str4} # Output: # hello, black_hello, black
获取字符串长度 1 2 3 4 text="12345" echo ${#text} # Output: # 5
截取子字符串 1 2 3 4 text="12345" echo ${text:2:2} # Output: # 34
从第 3 个字符开始,截取 2 个字符
查找子字符串 1 2 3 4 5 6 7 8 # !/usr/bin/env bash text="hello" echo `expr index "${text}" ll` # Execute: ./str-demo5.sh # Output: # 3
查找 ll 子字符在 hello 字符串中的起始位置。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 # !/usr/bin/env bash # name1='white' str1='hello, '${name1}'' str2='hello, ${name1}' echo ${str1}_${str2} # Output: # hello, white_hello, ${name1} # name2="black" str3="hello, "${name2}"" str4="hello, ${name2}" echo ${str3}_${str4} # Output: # hello, black_hello, black # text="12345" echo "${text} length is: ${#text}" # Output: # 12345 length is: 5 # 获取子字符串 text="12345" echo ${text:2:2} # Output: # 34 # text="hello" echo `expr index "${text}" ll` # Output: # 3 # result=$(echo "${str}" | grep "feature/") if [[ "$result" != "" ]]; then echo "feature/ 是 ${str} 的子字符串" else echo "feature/ 不是 ${str} 的子字符串" fi # full_branch="feature/1.0.0" branch=`echo ${full_branch#feature/}` echo "branch is ${branch}" # full_version="0.0.1-SNAPSHOT" version=`echo ${full_version%-SNAPSHOT}` echo "version is ${version}" # str="0.0.0.1" OLD_IFS="$IFS" IFS="." array=( ${str} ) IFS="$OLD_IFS" size=${#array[*]} lastIndex=`expr ${size} - 1` echo "数组长度:${size}" echo "最后一个数组元素:${array[${lastIndex}]}" for item in ${array[@]} do echo "$item" done # # -n 判断长度是否非零 # -z 判断长度是否为零 str=testing str2='' if [[ -n "$str" ]] then echo "The string $str is not empty" else echo "The string $str is empty" fi if [[ -n "$str2" ]] then echo "The string $str2 is not empty" else echo "The string $str2 is empty" fi # Output: # The string testing is not empty # The string is empty # str=hello str2=world if [[ $str = "hello" ]]; then echo "str equals hello" else echo "str not equals hello" fi if [[ $str2 = "hello" ]]; then echo "str2 equals hello" else echo "str2 not equals hello" fi
数组 bash 只支持一维数组。
数组下标从 0 开始,下标可以是整数或算术表达式,其值应大于或等于 0。
创建数组 1 2 3 # 创建数组的不同方式 nums=([2]=2 [0]=0 [1]=1) colors=(red yellow "dark blue")
访问数组元素
1 2 echo ${nums[1]} # Output: 1
1 2 3 4 5 echo ${colors[*]} # Output: red yellow dark blue echo ${colors[@]} # Output: red yellow dark blue
上面两行有很重要(也很微妙)的区别:
为了将数组中每个元素单独一行输出,我们用 printf 命令:
1 2 3 4 5 6 printf "+ %s\n" ${colors[*]} # Output: # + red # + yellow # + dark # + blue
为什么dark和blue各占了一行?尝试用引号包起来:
1 2 3 printf "+ %s\n" "${colors[*]}" # Output: # + red yellow dark blue
现在所有的元素都在一行输出 —— 这不是我们想要的!让我们试试${colors[@]}
1 2 3 4 5 printf "+ %s\n" "${colors[@]}" # Output: # + red # + yellow # + dark blue
在引号内,${colors[@]}将数组中的每个元素扩展为一个单独的参数;数组元素中的空格得以保留。
1 2 3 echo ${nums[@]:0:2} # Output: # 0 1
在上面的例子中,${array[@]} 扩展为整个数组,:0:2取出了数组中从 0 开始,长度为 2 的元素。
访问数组长度 1 2 3 echo ${#nums[*]} # Output: # 3
向数组中添加元素 向数组中添加元素也非常简单:
1 2 3 4 colors=(white "${colors[@]}" green black) echo ${colors[@]} # Output: # white red yellow dark blue green black
上面的例子中,${colors[@]} 扩展为整个数组,并被置换到复合赋值语句中,接着,对数组colors的赋值覆盖了它原来的值。
从数组中删除元素 用unset命令来从数组中删除一个元素:
1 2 3 4 unset nums[0] echo ${nums[@]} # Output: # 1 2
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 # !/usr/bin/env bash # nums=( [ 2 ] = 2 [ 0 ] = 0 [ 1 ] = 1 ) colors=( red yellow "dark blue" ) # echo ${nums[1]} # Output: 1 # echo ${colors[*]} # Output: red yellow dark blue echo ${colors[@]} # Output: red yellow dark blue printf "+ %s\n" ${colors[*]} # Output: # + red # + yellow # + dark # + blue printf "+ %s\n" "${colors[*]}" # Output: # + red yellow dark blue printf "+ %s\n" "${colors[@]}" # Output: # + red # + yellow # + dark blue # echo ${nums[@]:0:2} # Output: # 0 1 # echo ${#nums[*]} # Output: # 3 # colors=( white "${colors[@]}" green black ) echo ${colors[@]} # Output: # white red yellow dark blue green black # unset nums[ 0 ] echo ${nums[@]} # Output: # 1 2
运算符 算术运算符 下表列出了常用的算术运算符,假定变量 x 为 10,变量 y 为 20:
运算符
说明
举例
+
加法
expr $x + $y 结果为 30。
-
减法
expr $x - $y 结果为 -10。
*
乘法
expr $x * $y 结果为 200。
/
除法
expr $y / $x 结果为 2。
%
取余
expr $y % $x 结果为 0。
=
赋值
x=$y 将把变量 y 的值赋给 x。
==
相等。用于比较两个数字,相同则返回 true。
[ $x == $y ] 返回 false。
!=
不相等。用于比较两个数字,不相同则返回 true。
[ $x != $y ] 返回 true。
注意: 条件表达式要放在方括号之间,并且要有空格,例如: [$x==$y] 是错误的,必须写成 [ $x == $y ]。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 x=10 y=20 echo "x=${x}, y=${y}" val=`expr ${x} + ${y}` echo "${x} + ${y} = $val" val=`expr ${x} - ${y}` echo "${x} - ${y} = $val" val=`expr ${x} \* ${y}` echo "${x} * ${y} = $val" val=`expr ${y} / ${x}` echo "${y} / ${x} = $val" val=`expr ${y} % ${x}` echo "${y} % ${x} = $val" if [[ ${x} == ${y} ]] then echo "${x} = ${y}" fi if [[ ${x} != ${y} ]] then echo "${x} != ${y}" fi # Output: # x=10, y=20 # 10 + 20 = 30 # 10 - 20 = -10 # 10 * 20 = 200 # 20 / 10 = 2 # 20 % 10 = 0 # 10 != 20
关系运算符 关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 x 为 10,变量 y 为 20:
运算符
说明
举例
-eq检测两个数是否相等,相等返回 true。
[ $a -eq $b ]返回 false。
-ne检测两个数是否相等,不相等返回 true。
[ $a -ne $b ] 返回 true。
-gt检测左边的数是否大于右边的,如果是,则返回 true。
[ $a -gt $b ] 返回 false。
-lt检测左边的数是否小于右边的,如果是,则返回 true。
[ $a -lt $b ] 返回 true。
-ge检测左边的数是否大于等于右边的,如果是,则返回 true。
[ $a -ge $b ] 返回 false。
-le检测左边的数是否小于等于右边的,如果是,则返回 true。
[ $a -le $b ]返回 true。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 x=10 y=20 echo "x=${x}, y=${y}" if [[ ${x} -eq ${y} ]]; then echo "${x} -eq ${y} : x 等于 y" else echo "${x} -eq ${y}: x 不等于 y" fi if [[ ${x} -ne ${y} ]]; then echo "${x} -ne ${y}: x 不等于 y" else echo "${x} -ne ${y}: x 等于 y" fi if [[ ${x} -gt ${y} ]]; then echo "${x} -gt ${y}: x 大于 y" else echo "${x} -gt ${y}: x 不大于 y" fi if [[ ${x} -lt ${y} ]]; then echo "${x} -lt ${y}: x 小于 y" else echo "${x} -lt ${y}: x 不小于 y" fi if [[ ${x} -ge ${y} ]]; then echo "${x} -ge ${y}: x 大于或等于 y" else echo "${x} -ge ${y}: x 小于 y" fi if [[ ${x} -le ${y} ]]; then echo "${x} -le ${y}: x 小于或等于 y" else echo "${x} -le ${y}: x 大于 y" fi # Output: # x=10, y=20 # 10 -eq 20: x 不等于 y # 10 -ne 20: x 不等于 y # 10 -gt 20: x 不大于 y # 10 -lt 20: x 小于 y # 10 -ge 20: x 小于 y # 10 -le 20: x 小于或等于 y
布尔运算符 下表列出了常用的布尔运算符,假定变量 x 为 10,变量 y 为 20:
运算符
说明
举例
!非运算,表达式为 true 则返回 false,否则返回 true。
[ ! false ] 返回 true。
-o或运算,有一个表达式为 true 则返回 true。
[ $a -lt 20 -o $b -gt 100 ] 返回 true。
-a与运算,两个表达式都为 true 才返回 true。
[ $a -lt 20 -a $b -gt 100 ] 返回 false。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 x=10 y=20 echo "x=${x}, y=${y}" if [[ ${x} != ${y} ]]; then echo "${x} != ${y} : x 不等于 y" else echo "${x} != ${y}: x 等于 y" fi if [[ ${x} -lt 100 && ${y} -gt 15 ]]; then echo "${x} 小于 100 且 ${y} 大于 15 : 返回 true" else echo "${x} 小于 100 且 ${y} 大于 15 : 返回 false" fi if [[ ${x} -lt 100 || ${y} -gt 100 ]]; then echo "${x} 小于 100 或 ${y} 大于 100 : 返回 true" else echo "${x} 小于 100 或 ${y} 大于 100 : 返回 false" fi if [[ ${x} -lt 5 || ${y} -gt 100 ]]; then echo "${x} 小于 5 或 ${y} 大于 100 : 返回 true" else echo "${x} 小于 5 或 ${y} 大于 100 : 返回 false" fi # Output: # x=10, y=20 # 10 != 20 : x 不等于 y # 10 小于 100 且 20 大于 15 : 返回 true # 10 小于 100 或 20 大于 100 : 返回 true # 10 小于 5 或 20 大于 100 : 返回 false
逻辑运算符 以下介绍 Shell 的逻辑运算符,假定变量 x 为 10,变量 y 为 20:
运算符
说明
举例
&&逻辑的 AND
[[ ${x} -lt 100 && ${y} -gt 100 ]] 返回 false
`
`
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 x=10 y=20 echo "x=${x}, y=${y}" if [[ ${x} -lt 100 && ${y} -gt 100 ]] then echo "${x} -lt 100 && ${y} -gt 100 返回 true" else echo "${x} -lt 100 && ${y} -gt 100 返回 false" fi if [[ ${x} -lt 100 || ${y} -gt 100 ]] then echo "${x} -lt 100 || ${y} -gt 100 返回 true" else echo "${x} -lt 100 || ${y} -gt 100 返回 false" fi # Output: # x=10, y=20 # 10 -lt 100 && 20 -gt 100 返回 false # 10 -lt 100 || 20 -gt 100 返回 true
字符串运算符 下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
运算符
说明
举例
=检测两个字符串是否相等,相等返回 true。
[ $a = $b ] 返回 false。
!=检测两个字符串是否相等,不相等返回 true。
[ $a != $b ] 返回 true。
-z检测字符串长度是否为 0,为 0 返回 true。
[ -z $a ] 返回 false。
-n检测字符串长度是否为 0,不为 0 返回 true。
[ -n $a ] 返回 true。
str检测字符串是否为空,不为空返回 true。
[ $a ] 返回 true。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 x="abc" y="xyz" echo "x=${x}, y=${y}" if [[ ${x} = ${y} ]]; then echo "${x} = ${y} : x 等于 y" else echo "${x} = ${y}: x 不等于 y" fi if [[ ${x} != ${y} ]]; then echo "${x} != ${y} : x 不等于 y" else echo "${x} != ${y}: x 等于 y" fi if [[ -z ${x} ]]; then echo "-z ${x} : 字符串长度为 0" else echo "-z ${x} : 字符串长度不为 0" fi if [[ -n "${x}" ]]; then echo "-n ${x} : 字符串长度不为 0" else echo "-n ${x} : 字符串长度为 0" fi if [[ ${x} ]]; then echo "${x} : 字符串不为空" else echo "${x} : 字符串为空" fi # Output: # x=abc, y=xyz # abc = xyz: x 不等于 y # abc != xyz : x 不等于 y # -z abc : 字符串长度不为 0 # -n abc : 字符串长度不为 0 # abc : 字符串不为空
文件测试运算符 文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
操作符
说明
举例
-b file
检测文件是否是块设备文件,如果是,则返回 true。
[ -b $file ] 返回 false。
-c file
检测文件是否是字符设备文件,如果是,则返回 true。
[ -c $file ] 返回 false。
-d file
检测文件是否是目录,如果是,则返回 true。
[ -d $file ] 返回 false。
-f file
检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。
[ -f $file ] 返回 true。
-g file
检测文件是否设置了 SGID 位,如果是,则返回 true。
[ -g $file ] 返回 false。
-k file
检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。
[ -k $file ]返回 false。
-p file
检测文件是否是有名管道,如果是,则返回 true。
[ -p $file ] 返回 false。
-u file
检测文件是否设置了 SUID 位,如果是,则返回 true。
[ -u $file ] 返回 false。
-r file
检测文件是否可读,如果是,则返回 true。
[ -r $file ] 返回 true。
-w file
检测文件是否可写,如果是,则返回 true。
[ -w $file ] 返回 true。
-x file
检测文件是否可执行,如果是,则返回 true。
[ -x $file ] 返回 true。
-s file
检测文件是否为空(文件大小是否大于 0),不为空返回 true。
[ -s $file ] 返回 true。
-e file
检测文件(包括目录)是否存在,如果是,则返回 true。
[ -e $file ] 返回 true。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 file="/etc/hosts" if [[ -r ${file} ]]; then echo "${file} 文件可读" else echo "${file} 文件不可读" fi if [[ -w ${file} ]]; then echo "${file} 文件可写" else echo "${file} 文件不可写" fi if [[ -x ${file} ]]; then echo "${file} 文件可执行" else echo "${file} 文件不可执行" fi if [[ -f ${file} ]]; then echo "${file} 文件为普通文件" else echo "${file} 文件为特殊文件" fi if [[ -d ${file} ]]; then echo "${file} 文件是个目录" else echo "${file} 文件不是个目录" fi if [[ -s ${file} ]]; then echo "${file} 文件不为空" else echo "${file} 文件为空" fi if [[ -e ${file} ]]; then echo "${file} 文件存在" else echo "${file} 文件不存在" fi # Output:(根据文件的实际情况,输出结果可能不同) # /etc/hosts 文件可读 # /etc/hosts 文件可写 # /etc/hosts 文件不可执行 # /etc/hosts 文件为普通文件 # /etc/hosts 文件不是个目录 # /etc/hosts 文件不为空 # /etc/hosts 文件存在
控制语句 条件语句 跟其它程序设计语言一样,Bash 中的条件语句让我们可以决定一个操作是否被执行。结果取决于一个包在[[ ]]里的表达式。
由[[ ]](sh中是[ ])包起来的表达式被称作 检测命令 或 基元 。这些表达式帮助我们检测一个条件的结果。这里可以找到有关bash 中单双中括号区别 的答案。
共有两个不同的条件表达式:if和case。
if(1)if 语句
if在使用上跟其它语言相同。如果中括号里的表达式为真,那么then和fi之间的代码会被执行。fi标志着条件代码块的结束。
1 2 3 4 5 6 7 8 9 10 # 写成一行 if [[ 1 -eq 1 ]]; then echo "1 -eq 1 result is: true"; fi # Output: 1 -eq 1 result is: true # 写成多行 if [[ "abc" -eq "abc" ]] then echo ""abc" -eq "abc" result is: true" fi # Output: abc -eq abc result is: true
(2)if else 语句
同样,我们可以使用if..else语句,例如:
1 2 3 4 5 6 if [[ 2 -ne 1 ]]; then echo "true" else echo "false" fi # Output: true
(3)if elif else 语句
有些时候,if..else不能满足我们的要求。别忘了if..elif..else,使用起来也很方便。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 x=10 y=20 if [[ ${x} > ${y} ]]; then echo "${x} > ${y}" elif [[ ${x} < ${y} ]]; then echo "${x} < ${y}" else echo "${x} = ${y}" fi # Output: 10 < 20
case如果你需要面对很多情况,分别要采取不同的措施,那么使用case会比嵌套的if更有用。使用case来解决复杂的条件判断,看起来像下面这样:
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 exec case ${oper} in "+") val=`expr ${x} + ${y}` echo "${x} + ${y} = ${val}" ;; "-") val=`expr ${x} - ${y}` echo "${x} - ${y} = ${val}" ;; "*") val=`expr ${x} \* ${y}` echo "${x} * ${y} = ${val}" ;; "/") val=`expr ${x} / ${y}` echo "${x} / ${y} = ${val}" ;; *) echo "Unknown oper!" ;; esac
每种情况都是匹配了某个模式的表达式。|用来分割多个模式,)用来结束一个模式序列。第一个匹配上的模式对应的命令将会被执行。*代表任何不匹配以上给定模式的模式。命令块儿之间要用;;分隔。
循环语句 循环其实不足为奇。跟其它程序设计语言一样,bash 中的循环也是只要控制条件为真就一直迭代执行的代码块。
Bash 中有四种循环:for,while,until和select。
for循环for与它在 C 语言中的姊妹非常像。看起来是这样:
1 2 3 4 for arg in elem1 elem2 ... elemN do # done
在每次循环的过程中,arg依次被赋值为从elem1到elemN。这些值还可以是通配符或者大括号扩展 。
当然,我们还可以把for循环写在一行,但这要求do之前要有一个分号,就像下面这样:
1 for i in {1..5}; do echo $i; done
还有,如果你觉得for..in..do对你来说有点奇怪,那么你也可以像 C 语言那样使用for,比如:
1 2 3 for (( i = 0; i < 10; i++ )); do echo $i done
当我们想对一个目录下的所有文件做同样的操作时,for就很方便了。举个例子,如果我们想把所有的.bash文件移动到script文件夹中,并给它们可执行权限,我们的脚本可以这样写:
💻 “示例源码”
1 2 3 4 5 DIR=/home/zp for FILE in ${DIR}/*.sh; do mv "$FILE" "${DIR}/scripts" done # 将 /home/zp 目录下所有 sh 文件拷贝到 /home/zp/scripts
while循环while循环检测一个条件,只要这个条件为 _真_,就执行一段命令。被检测的条件跟if..then中使用的基元 并无二异。因此一个while循环看起来会是这样:
1 2 3 4 while [[ condition ]] do # done
跟for循环一样,如果我们把do和被检测的条件写到一行,那么必须要在do之前加一个分号。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # x=0 while [[ ${x} -lt 10 ]]; do echo $((x * x)) x=$((x + 1)) done # Output: # 0 # 1 # 4 # 9 # 16 # 25 # 36 # 49 # 64 # 81
until循环until循环跟while循环正好相反。它跟while一样也需要检测一个测试条件,但不同的是,只要该条件为 假 就一直执行循环:
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 x=0 until [[ ${x} -ge 5 ]]; do echo ${x} x=`expr ${x} + 1` done # Output: # 0 # 1 # 2 # 3 # 4
select循环select循环帮助我们组织一个用户菜单。它的语法几乎跟for循环一致:
1 2 3 4 select answer in elem1 elem2 ... elemN do # done
select会打印elem1..elemN以及它们的序列号到屏幕上,之后会提示用户输入。通常看到的是$?(PS3变量)。用户的选择结果会被保存到answer中。如果answer是一个在1..N之间的数字,那么语句会被执行,紧接着会进行下一次迭代 —— 如果不想这样的话我们可以使用break语句。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # !/usr/bin/env bash PS3="Choose the package manager: " select ITEM in bower npm gem pip do echo -n "Enter the package name: " && read PACKAGE case ${ITEM} in bower) bower install ${PACKAGE} ;; npm) npm install ${PACKAGE} ;; gem) gem install ${PACKAGE} ;; pip) pip install ${PACKAGE} ;; esac break # 避免无限循环 done
这个例子,先询问用户他想使用什么包管理器。接着,又询问了想安装什么包,最后执行安装操作。
运行这个脚本,会得到如下输出:
1 2 3 4 5 6 7 $ ./my_script 1) bower 2) npm 3) gem 4) pip Choose the package manager: 2 Enter the package name: gitbook-cli
break 和 continue如果想提前结束一个循环或跳过某次循环执行,可以使用 shell 的break和continue语句来实现。它们可以在任何循环中使用。
break语句用来提前结束当前循环。
continue语句用来跳过某次迭代。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 # 查找 10 以内第一个能整除 2 和 3 的正整数 i=1 while [[ ${i} -lt 10 ]]; do if [[ $((i % 3)) -eq 0 ]] && [[ $((i % 2)) -eq 0 ]]; then echo ${i} break; fi i=`expr ${i} + 1` done # Output: 6
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 # 打印10以内的奇数 for (( i = 0; i < 10; i ++ )); do if [[ $((i % 2)) -eq 0 ]]; then continue; fi echo ${i} done # Output: # 1 # 3 # 5 # 7 # 9
函数 bash 函数定义语法如下:
1 2 3 4 [ function ] funname [()] { action; [return int;] }
💡 说明:
函数定义时,function 关键字可有可无。
函数返回值 - return 返回函数返回值,返回值类型只能为整数(0-255)。如果不加 return 语句,shell 默认将以最后一条命令的运行结果,作为函数返回值。
函数返回值在调用该函数后通过 $? 来获得。
所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至 shell 解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # !/usr/bin/env bash calc(){ PS3="choose the oper: " select oper in + - \* / # 生成操作符选择菜单 do echo -n "enter first num: " && read x # 读取输入参数 echo -n "enter second num: " && read y # 读取输入参数 exec case ${oper} in "+") return $((${x} + ${y})) ;; "-") return $((${x} - ${y})) ;; "*") return $((${x} * ${y})) ;; "/") return $((${x} / ${y})) ;; *) echo "${oper} is not support!" return 0 ;; esac break done } calc echo "the result is: $?" # $? 获取 calc 函数返回值
执行结果:
1 2 3 4 5 6 7 8 9 $ ./function-demo.sh 1) + 2) - 3) * 4) / choose the oper: 3 enter first num: 10 enter second num: 10 the result is: 100
位置参数 位置参数 是在调用一个函数并传给它参数时创建的变量。
位置参数变量表:
变量
描述
$0脚本名称
$1 … $9第 1 个到第 9 个参数列表
${10} … ${N}第 10 个到 N 个参数列表
$* or $@除了$0外的所有位置参数
$#不包括$0在内的位置参数的个数
$FUNCNAME函数名称(仅在函数内部有值)
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # !/usr/bin/env bash x=0 if [[ -n $1 ]]; then echo "第一个参数为:$1" x=$1 else echo "第一个参数为空" fi y=0 if [[ -n $2 ]]; then echo "第二个参数为:$2" y=$2 else echo "第二个参数为空" fi paramsFunction(){ echo "函数第一个入参:$1" echo "函数第二个入参:$2" } paramsFunction ${x} ${y}
执行结果:
1 2 3 4 5 6 7 8 9 10 11 $ ./function-demo2.sh 第一个参数为空 第二个参数为空 函数第一个入参:0 函数第二个入参:0 $ ./function-demo2.sh 10 20 第一个参数为:10 第二个参数为:20 函数第一个入参:10 函数第二个入参:20
执行 ./variable-demo4.sh hello world ,然后在脚本中通过 $1、$2 … 读取第 1 个参数、第 2 个参数。。。
函数处理参数 另外,还有几个特殊字符用来处理参数:
参数处理
说明
$#返回参数个数
$*返回所有参数
$$脚本运行的当前进程 ID 号
$!后台运行的最后一个进程的 ID 号
$@返回所有参数
$-返回 Shell 使用的当前选项,与 set 命令功能相同。
$?函数返回值
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 runner() { return 0 } name=zp paramsFunction(){ echo "函数第一个入参:$1" echo "函数第二个入参:$2" echo "传递到脚本的参数个数:$#" echo "所有参数:" printf "+ %s\n" "$*" echo "脚本运行的当前进程 ID 号:$$" echo "后台运行的最后一个进程的 ID 号:$!" echo "所有参数:" printf "+ %s\n" "$@" echo "Shell 使用的当前选项:$-" runner echo "runner 函数的返回值:$?" } paramsFunction 1 "abc" "hello, \"zp\"" # Output: # 函数第一个入参:1 # 函数第二个入参:abc # 传递到脚本的参数个数:3 # 所有参数: # + 1 abc hello, "zp" # 脚本运行的当前进程 ID 号:26400 # 后台运行的最后一个进程的 ID 号: # 所有参数: # + 1 # + abc # + hello, "zp" # Shell 使用的当前选项:hB # runner 函数的返回值:0
Shell 扩展 扩展 发生在一行命令被分成一个个的 记号(tokens) 之后。换言之,扩展是一种执行数学运算的机制,还可以用来保存命令的执行结果,等等。
感兴趣的话可以阅读关于 shell 扩展的更多细节 。
大括号扩展 大括号扩展让生成任意的字符串成为可能。它跟 文件名扩展 很类似,举个例子:
1 echo beg{i,a,u}n ### begin began begun
大括号扩展还可以用来创建一个可被循环迭代的区间。
1 2 echo {0..5} ### 0 1 2 3 4 5 echo {00..8..2} ### 00 02 04 06 08
命令置换 命令置换允许我们对一个命令求值,并将其值置换到另一个命令或者变量赋值表达式中。当一个命令被``或$()包围时,命令置换将会执行。举个例子:
1 2 3 4 5 now=`date +%T` # now=$(date +%T) echo $now ### 19:08:26
算数扩展 在 bash 中,执行算数运算是非常方便的。算数表达式必须包在$(( ))中。算数扩展的格式为:
1 2 result=$(( ((10 + 5*3) - 7) / 2 )) echo $result ### 9
在算数表达式中,使用变量无需带上$前缀:
1 2 3 4 5 x=4 y=7 echo $(( x + y )) ### 11 echo $(( ++x + y++ )) ### 12 echo $(( x + y )) ### 13
单引号和双引号 单引号和双引号之间有很重要的区别。在双引号中,变量引用或者命令置换是会被展开的。在单引号中是不会的。举个例子:
1 2 echo "Your home: $HOME" ### Your home: /Users/<username> echo 'Your home: $HOME' ### Your home: $HOME
当局部变量和环境变量包含空格时,它们在引号中的扩展要格外注意。随便举个例子,假如我们用echo来输出用户的输入:
1 2 3 INPUT="A string with strange whitespace." echo $INPUT ### A string with strange whitespace. echo "$INPUT" ### A string with strange whitespace.
调用第一个echo时给了它 5 个单独的参数 —— $INPUT 被分成了单独的词,echo在每个词之间打印了一个空格。第二种情况,调用echo时只给了它一个参数(整个$INPUT 的值,包括其中的空格)。
来看一个更严肃的例子:
1 2 3 FILE="Favorite Things.txt" cat $FILE ### 尝试输出两个文件: `Favorite` 和 `Things.txt` cat "$FILE" ### 输出一个文件: `Favorite Things.txt`
尽管这个问题可以通过把 FILE 重命名成Favorite-Things.txt来解决,但是,假如这个值来自某个环境变量,来自一个位置参数,或者来自其它命令(find, cat, 等等)呢。因此,如果输入 可能 包含空格,务必要用引号把表达式包起来。
流和重定向 Bash 有很强大的工具来处理程序之间的协同工作。使用流,我们能将一个程序的输出发送到另一个程序或文件,因此,我们能方便地记录日志或做一些其它我们想做的事。
管道给了我们创建传送带的机会,控制程序的执行成为可能。
学习如何使用这些强大的、高级的工具是非常非常重要的。
输入、输出流 Bash 接收输入,并以字符序列或 字符流 的形式产生输出。这些流能被重定向到文件或另一个流中。
有三个文件描述符:
代码
描述符
描述
0stdin标准输入
1stdout标准输出
2stderr标准错误输出
重定向 重定向让我们可以控制一个命令的输入来自哪里,输出结果到什么地方。这些运算符在控制流的重定向时会被用到:
Operator
Description
>重定向输出
&>重定向输出和错误输出
&>>以附加的形式重定向输出和错误输出
<重定向输入
<<Here 文档 语法
<<<Here 字符串
以下是一些使用重定向的例子:
1 2 3 4 5 6 7 8 9 10 11 # ls -l > list.txt # ls -a >> list.txt # grep da * 2> errors.txt # less < errors.txt
/dev/null 文件如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null:
/dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到”禁止输出”的效果。
如果希望屏蔽 stdout 和 stderr,可以这样写:
1 $ command > /dev/null 2>&1
Debug shell 提供了用于 debug 脚本的工具。
如果想采用 debug 模式运行某脚本,可以在其 shebang 中使用一个特殊的选项:
options 是一些可以改变 shell 行为的选项。下表是一些可能对你有用的选项:
Short
Name
Description
-fnoglob
禁止文件名展开(globbing)
-iinteractive
让脚本以 交互 模式运行
-nnoexec
读取命令,但不执行(语法检查)
-t—
执行完第一条命令后退出
-vverbose
在执行每条命令前,向stderr输出该命令
-xxtrace
在执行每条命令前,向stderr输出该命令以及该命令的扩展参数
举个例子,如果我们在脚本中指定了-x例如:
1 2 3 4 5 # !/bin/bash -x for (( i = 0; i < 3; i++ )); do echo $i done
这会向stdout打印出变量的值和一些其它有用的信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ ./my_script + (( i = 0 )) + (( i < 3 )) + echo 0 0 + (( i++ )) + (( i < 3 )) + echo 1 1 + (( i++ )) + (( i < 3 )) + echo 2 2 + (( i++ )) + (( i < 3 ))
有时我们值需要 debug 脚本的一部分。这种情况下,使用set命令会很方便。这个命令可以启用或禁用选项。使用-启用选项,+禁用选项:
💻 “示例源码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 开启 debug set -x for (( i = 0; i < 3; i++ )); do printf ${i} done # 关闭 debug set +x # Output: # + (( i = 0 )) # + (( i < 3 )) # + printf 0 # 0+ (( i++ )) # + (( i < 3 )) # + printf 1 # 1+ (( i++ )) # + (( i < 3 )) # + printf 2 # 2+ (( i++ )) # + (( i < 3 )) # + set +x for i in {1..5}; do printf ${i}; done printf "\n" # Output: 12345
参考资料
最后,Stack Overflow 上 bash 标签下 有很多你可以学习的问题,当你遇到问题时,也是一个提问的好地方。