if (mysqlUserDao != null && mysqlUserDao.getJdbcTemplate() != null) { printDataSourceInfo(mysqlUserDao.getJdbcTemplate()); log.info("Connect to mysql datasource success."); } else { log.error("Connect to mysql datasource failed!"); return; }
if (h2UserDao != null) { printDataSourceInfo(h2UserDao.getJdbcTemplate()); log.info("Connect to h2 datasource success."); } else { log.error("Connect to h2 datasource failed!"); return; }
b not matches: [^abc] m not matches: [^a-z] O not matches: [^A-Z] K not matches: [^a-zA-Z] k not matches: [^a-zA-Z] 5 not matches: [^0-9]
限制字符数量 - {}
如果想要控制字符出现的次数,可以使用{}。
字符
描述
{n}
n 是一个非负整数。匹配确定的 n 次。
{n,}
n 是一个非负整数。至少匹配 n 次。
{n,m}
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。
例 限制字符出现次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// {n}: n 是一个非负整数。匹配确定的 n 次。 checkMatches("ap{1}", "a"); checkMatches("ap{1}", "ap"); checkMatches("ap{1}", "app"); checkMatches("ap{1}", "apppppppppp");
// {n,}: n 是一个非负整数。至少匹配 n 次。 checkMatches("ap{1,}", "a"); checkMatches("ap{1,}", "ap"); checkMatches("ap{1,}", "app"); checkMatches("ap{1,}", "apppppppppp");
// {n,m}: m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 checkMatches("ap{2,5}", "a"); checkMatches("ap{2,5}", "ap"); checkMatches("ap{2,5}", "app"); checkMatches("ap{2,5}", "apppppppppp");
输出
1 2 3 4 5 6 7 8 9 10 11 12
a not matches: ap{1} ap matches: ap{1} app not matches: ap{1} apppppppppp not matches: ap{1} a not matches: ap{1,} ap matches: ap{1,} app matches: ap{1,} apppppppppp matches: ap{1,} a not matches: ap{2,5} ap not matches: ap{2,5} app matches: ap{2,5} apppppppppp not matches: ap{2,5}
a matches: ap* ap matches: ap* app matches: ap* apppppppppp matches: ap* a not matches: ap+ ap matches: ap+ app matches: ap+ apppppppppp matches: ap+ a matches: ap? ap matches: ap? app not matches: ap? apppppppppp not matches: ap?
// (\w+)\s\1\W(\w+) 匹配重复的单词和紧随每个重复的单词的单词 Assert.assertTrue(findAll("(\\w+)\\s\\1\\W(\\w+)", "He said that that was the the correct answer.") > 0);
输出
1 2 3
regex= (\w+)\s\1\W(\w+), content: He said that that was the the correct answer. [1th] start:8, end:21, group: that that was [2th] start:22, end:37, group: the the correct
// (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+) 匹配重复的单词和紧随每个重复的单词的单词 Assert.assertTrue(findAll("(?<duplicateWord>\\w+)\\s\\k<duplicateWord>\\W(?<nextWord>\\w+)", "He said that that was the the correct answer.") > 0);
输出
1 2 3
regex= (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+), content: He said that that was the the correct answer. [1th] start:8, end:21, group: that that was [2th] start:22, end:37, group: the the correct
// \b\w+(?=\sis\b) 表示要捕获is之前的单词 Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "The dog is a Malamute.") > 0); Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The island has beautiful birds.") > 0); Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The pitch missed home plate.") > 0); Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "Sunday is a weekend day.") > 0);
输出
1 2 3 4 5 6 7 8
regex= \b\w+(?=\sis\b), content: The dog is a Malamute. [1th] start:4, end:7, group: dog regex= \b\w+(?=\sis\b), content: The island has beautiful birds. not found regex= \b\w+(?=\sis\b), content: The pitch missed home plate. not found regex= \b\w+(?=\sis\b), content: Sunday is a weekend day. [1th] start:0, end:6, group: Sunday
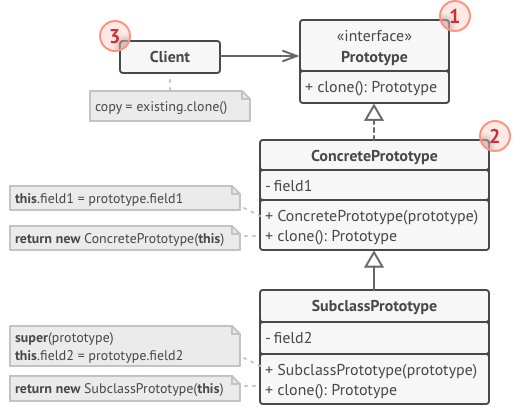
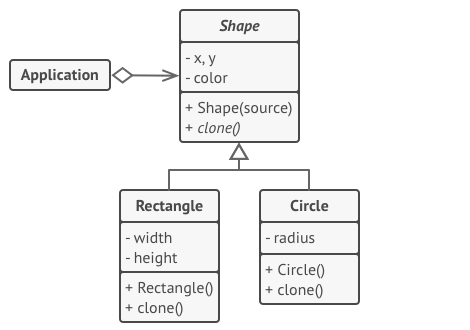
// 具体原型。克隆方法会创建一个新对象并将其传递给构造函数。直到构造函数运 // 行完成前,它都拥有指向新克隆对象的引用。因此,任何人都无法访问未完全生 // 成的克隆对象。这可以保持克隆结果的一致。 classRectangleextendsShape is field width: int field height: int
method businessLogic() is // 原型是很强大的东西,因为它能在不知晓对象类型的情况下生成一个与 // 其完全相同的复制品。 ArrayshapesCopy=newArray of Shapes.
// 例如,我们不知晓形状数组中元素的具体类型,只知道它们都是形状。 // 但在多态机制的帮助下,当我们在某个形状上调用 `clone(克隆)` // 方法时,程序会检查其所属的类并调用其中所定义的克隆方法。这样, // 我们将获得一个正确的复制品,而不是一组简单的形状对象。 foreach (s in shapes) do shapesCopy.add(s.clone())
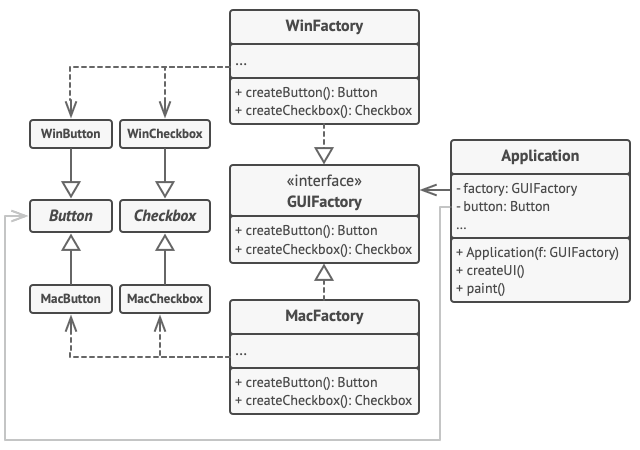
// 具体工厂可生成属于同一变体的系列产品。工厂会确保其创建的产品能相互搭配 // 使用。具体工厂方法签名会返回一个抽象产品,但在方法内部则会对具体产品进 // 行实例化。 classWinFactoryimplementsGUIFactory is method createButton():Button is returnnewWinButton() method createCheckbox():Checkbox is returnnewWinCheckbox()
// 每个具体工厂中都会包含一个相应的产品变体。 classMacFactoryimplementsGUIFactory is method createButton():Button is returnnewMacButton() method createCheckbox():Checkbox is returnnewMacCheckbox()
// 系列产品中的特定产品必须有一个基础接口。所有产品变体都必须实现这个接口。 interfaceButton is method paint()
// 具体产品由相应的具体工厂创建。 classWinButtonimplementsButton is method paint() is // 根据 Windows 样式渲染按钮。
classMacButtonimplementsButton is method paint() is // 根据 macOS 样式渲染按钮
// 这是另一个产品的基础接口。所有产品都可以互动,但是只有相同具体变体的产 // 品之间才能够正确地进行交互。 interfaceCheckbox is method paint()
classWinCheckboximplementsCheckbox is method paint() is // 根据 Windows 样式渲染复选框。
classMacCheckboximplementsCheckbox is method paint() is // 根据 macOS 样式渲染复选框。
// 客户端代码仅通过抽象类型(GUIFactory、Button 和 Checkbox)使用工厂 // 和产品。这让你无需修改任何工厂或产品子类就能将其传递给客户端代码。 classApplication is private field factory: GUIFactory private field button: Button constructor Application(factory: GUIFactory) is this.factory = factory method createUI() is this.button = factory.createButton() method paint() is button.paint()
// 程序会根据当前配置或环境设定选择工厂类型,并在运行时创建工厂(通常在初 // 始化阶段)。 classApplicationConfigurator is method main()is config= readApplicationConfigFile()
if (config.OS == "Windows") then factory=newWinFactory() elseif (config.OS == "Mac") then factory=newMacFactory() else thrownewException("错误!未知的操作系统。")
Applicationapp=newApplication(factory)
案例
众所周知,苹果和三星这两家世界级的电子产品厂商都生产手机和电脑。
我们以生产手机和电脑为例,演示一下抽象工厂模式的应用
【AbstractProduct 角色】
首先,定义手机和电脑两个抽象接口,他们都有各自的产品信息。
1 2 3 4 5 6 7
interfaceTelephone { public String getProductInfo(); }
interfaceComputer { public String getProductInfo(); }
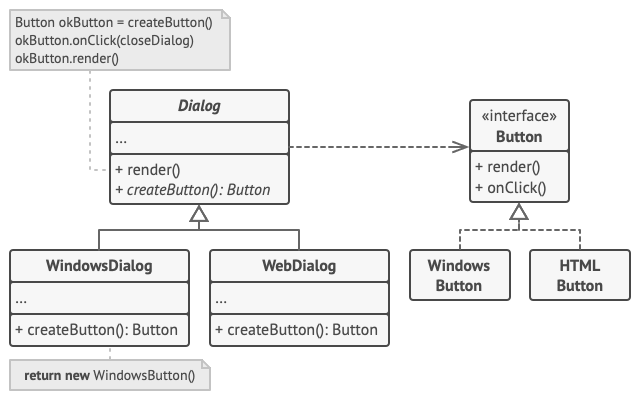
if (config.OS == "Windows") then dialog=newWindowsDialog() elseif (config.OS == "Web") then dialog=newWebDialog() else thrownewException("错误!未知的操作系统。")
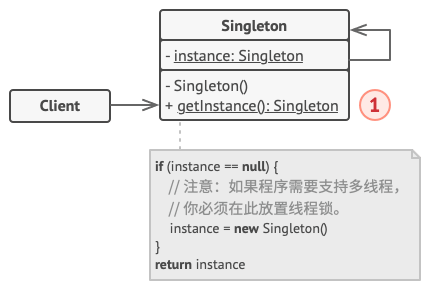
// 用于控制对单例实例的访问权限的静态方法。 publicstatic method getInstance() is if(Database.instance == null) then acquireThreadLock() and then // 确保在该线程等待解锁时,其他线程没有初始化该实例。 if (Database.instance == null) then Database.instance = newDatabase() return Database.instance
// 最后,任何单例都必须定义一些可在其实例上执行的业务逻辑。 public method query(sql) is // 比如应用的所有数据库查询请求都需要通过该方法进行。因此,你可以 // 在这里添加限流或缓冲逻辑。 // ...
// 用于控制对单例实例的访问权限的静态方法。 publicstatic method getInstance() is if(Database.instance == null) then acquireThreadLock() and then // 确保在该线程等待解锁时,其他线程没有初始化该实例。 if (Database.instance == null) then Database.instance = newDatabase() return Database.instance
// 最后,任何单例都必须定义一些可在其实例上执行的业务逻辑。 public method query(sql) is // 比如应用的所有数据库查询请求都需要通过该方法进行。因此,你可以 // 在这里添加限流或缓冲逻辑。 // ...