Java 基础面试一 Java 常识 【简单】Java 语言有什么优势?
跨平台 :【一次编写,到处执行(Write Once, Run Anywhere) 】——JVM 执行字节码。自动垃圾回收 :垃圾回收(GC)减少内存泄漏风险。强大生态 :Spring、Hadoop、Android 等广泛支持。面向对象 :支持封装、继承、多态,代码结构清晰易维护。高性能 :JIT 编译优化,多线程支持高并发。健壮安全 :强类型检查、异常处理、JVM 安全机制。
【简单】Oracle JDK 和 Open JDK 有什么区别?
OpenJDK
Oracle JDK
是否开源
完全开源
闭源
是否免费
完全免费
JDK8u221 之后存在限制
更新频率
一般每 3 个月发布一个版本;不提供 LTS 服务
一般每 6 个月发布一个版本;大概每三年推出一个 LTS 版本
功能性
Java 11 之后,OracleJDK 和 OpenJDK 的功能基本一致
协议
GPL v2
BCL/OTN
【简单】Java SE 和 Java EE 有什么区别? Java 技术既是一种编程语言,又是一种平台。Java 编程语言是一种具有特定语法和风格的高级面向对象语言。Java 平台是 Java 编程语言应用程序运行的特定环境。
Java SE (Java Platform, Standard Edition) - Java 平台标准版 。Java SE 的 API 提供了 Java 编程语言的核心功能。它定义了从 Java 编程语言的基本类型和对象到用于网络、安全、数据库访问、图形用户界面 (GUI) 开发和 XML 解析的高级类的所有内容。除了核心 API 之外,Java SE 平台还包括虚拟机、开发工具、部署技术以及 Java 技术应用程序中常用的其他类库和工具包。Java EE (Java Platform, Enterprise Edition) - Java 平台企业版 。Java EE 构建在 Java SE 基础之上。 Java EE 定义了企业级应用程序开发和部署的标准和规范,如:Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS。
::: tip 扩展
Your First Cup
:::
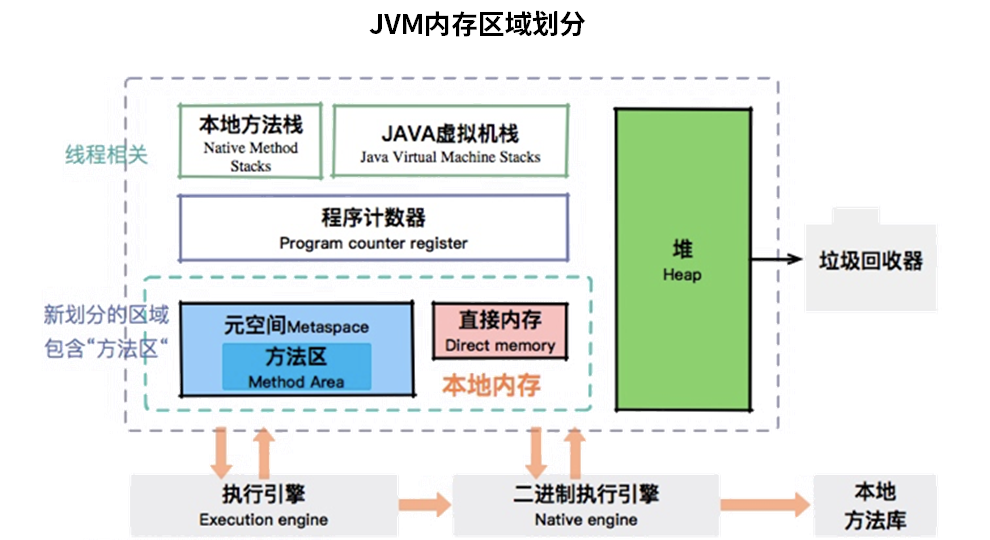
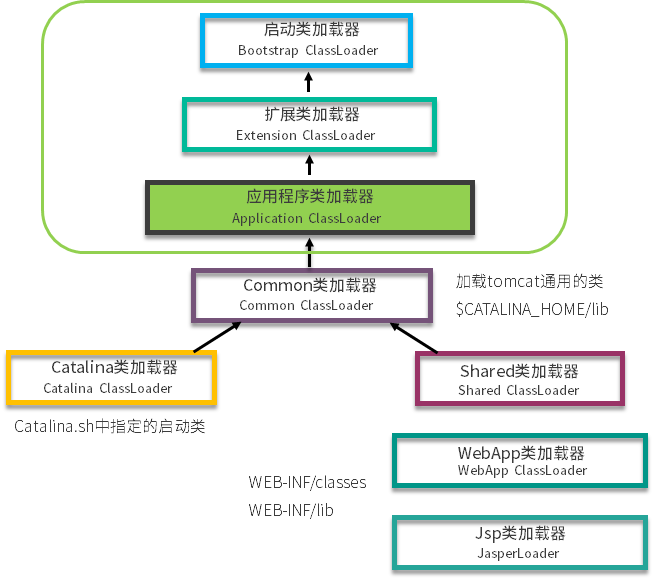
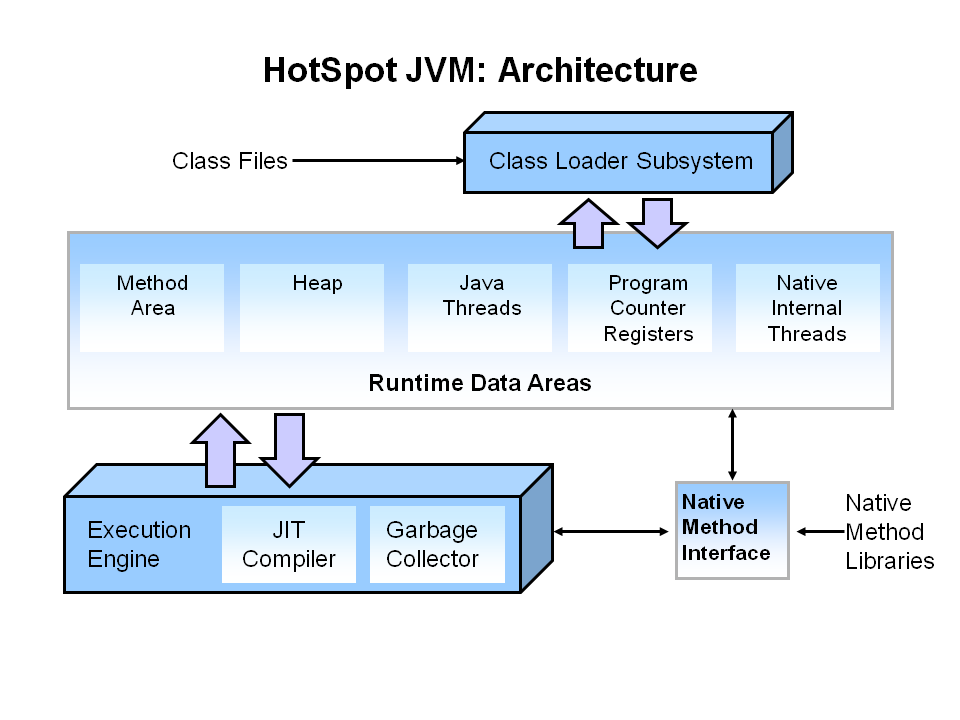
【简单】JDK、JRE、JVM 之间有什么关系? JDK、JRE、JVM 的定义和简介:
JVM - Java Virtual Machine 的缩写,即 Java 虚拟机。JVM 是运行 Java 字节码的虚拟机。JVM 不理解 Java 源代码,这就是为什么要将 *.java 文件编译为 JVM 可理解的 *.class 文件(字节码)。Java 有一句著名的口号:“Write Once, Run Anywhere(一次编写,随处运行) ”,JVM 正是其核心所在。实际上,JVM 针对不同的系统(Windows、Linux、MacOS)有不同的实现,目的在于用相同的字节码执行同样的结果。JRE - Java Runtime Environment 的缩写,即 Java 运行时环境。它是运行已编译 Java 程序所需的一切的软件包,主要包括 JVM、Java 类库(Class Library)、Java 命令和其他基础结构。但是,它不能用于创建新程序。JDK - Java Development Kit 的缩写,即 Java SDK。它不仅包含 JRE 的所有功能,还包含编译器 (javac) 和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
总结来说,JDK、JRE、JVM 三者的关系是:JDK > JRE > JVM
1 2 3 JDK = JRE + 开发/调试工具JRE = JVM + Java 类库 + Java 运行库JVM = 类加载系统 + 运行时内存区域 + 执行引擎
::: tip 扩展
stackoverflow 高票问题 - What is the difference between JDK and JRE?
:::
【中等】Java 如何调用外部可执行程序或系统命令? Java 提供了两种调用外部可执行程序或系统命令的方式:
ProcessBuilderRuntime.exec()
::: tip 扩展
https://blog.csdn.net/m0_46487331/article/details/128827908
:::
Java 基础语法 【简单】Java 有几种注释形式? 注释用于在源代码中解释代码的作用,可以增强程序的可读性,可维护性。 空白行,或者注释的内容,都会被 Java 编译器忽略掉。
Java 注释主要有三种类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class HelloWorld { public static void main (String[] args) { System.out.println("Hello World" ); } }
【简单】Java 有哪些标识符命名规则? Java 所有的组成部分都需要名字。类名、变量名以及方法名都被称为标识符。
标识符基本规则
组成元素 :类名、变量名、方法名等统称为标识符允许字符 :可包含字母、数字、$、_首字符要求 :不能以数字开头禁止关键字 :如 class、public 等保留字不可作为标识符大小写敏感 :age 和 Age 被视为不同标识符
命名规范
在 Java 中,标识符通常遵循 驼峰命名法 。
类型 命名法 示例
类/接口名 大驼峰(Upper CamelCase)
StudentInfo、UserService
方法/变量名 小驼峰(Lower CamelCase)
getUserName()、studentAge
常量名 全大写蛇形(SNAKE_CASE)
MAX_SIZE、DEFAULT_TIMEOUT
注意事项
**避免使用 $**:虽然合法,但通常用于编译器生成代码
无长度限制 :但应保持简洁且语义明确(如用 count 而非 c)Unicode 支持 :可使用中文等字符(但不推荐)
【简单】Java 中有哪些关键字? 下面列出了 Java 保留字,这些保留字不能用于常量、变量、和任何标识符的名称。
分类
关键字
访问级别修饰符
private、protected、public、default
类,方法和变量修饰符
abstract、class、extends、final、implements、interface、native、new、static、strictfp、synchronized、transient、volatile、enum
程序控制语句
break、continue、return、do、while、if、else、for、instanceof、switch、case
错误处理
assert、try、catch、throw、throws、finally
包相关
import、package
数据类型
boolean、byte、char、short、int、long、float、double、enum
变量引用
super、this、void
其他保留字
goto、const
::: warning
Java 的 null 不是关键字,类似于 true 和 false,它是一个字面常量,不允许作为标识符使用。
官方文档 :https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
:::
【中等】如果移位操作位数超限会怎样? 移位位数处理机制
Java 对移位位数超限的处理采用隐式取模运算 :
int 类型(32 位)指定位数 % 32
例如:x << 42 → 实际左移 42 % 32 = 10 位
long 类型(64 位)指定位数 % 64
例如:x << 100 → 实际左移 100 % 64 = 36 位
位操作统一规则
操作符 示例 等效操作 说明
<<x << 35x << 3 (35%32=3)左移,低位补 0
>>x >> 35x >> 3 (35%32=3)右移,高位补符号位(算术右移)
>>>x >>> 35x >>> 3 (35%32=3)无符号右移,高位补 0
底层原理
硬件优化 :CPU 执行移位指令时,实际只使用指定位数的低 5 位(int)或低 6 位(long),与 Java 的取模规则一致。安全设计 :避免无效的大位数移位(如 x << 1000)导致不可预测行为。
示例
1 2 3 4 5 6 int i = -1 ; System.out.println(i << 10 ); System.out.println(i << 42 ); long l = -1L ;System.out.println(l << 70 );
特殊情况
移位 0 位 :任何 x << 32 或 x >> 64 等效不移位(因 32%32=0,64%64=0)。负数移位 :移位位数可为负数,但会通过取模转为正数(如 x << -6 → x << 26,因 -6 % 32 = 26)。
::: info 为什么这样设计?
兼容性 :与 C/C++的移位行为一致。性能 :直接映射到 CPU 指令,无需额外检查。确定性 :保证结果可预测,避免未定义行为。
Java 数据类型 【简单】Java 有哪些值类型? Java 中的数据类型有两类:
值类型(又叫内置数据类型,基本数据类型)
引用类型(除值类型以外,都是引用类型,包括 String、数组等)
Java 语言提供了 8 种基本类型,大致分为 4 类:布尔型、字符型、整数型、浮点型。
基本数据类型
分类
大小
默认值
取值范围
包装类
说明
boolean布尔型 -
falsefalse, trueBoolean
boolean 的大小,是由具体的 JVM 实现来决定的
char字符型 16 bit
'u0000'[0, 2^16 - 1]Character
存储 Unicode 码,用单引号赋值
byte整数型 8 bit
0[-2^7, 2^7 - 1]Byte
short整数型 16 bit
0[-2^15, 2^15 - 1]Short
int整数型 32 bit
0[-2^31, 2^31 - 1]Integer
long整数型 64 bit
0L[-2^63, 2^63 - 1]Long
赋值时一般在数字后加上 l 或 L
float浮点型 32 bit
0.0f[2^-149, 2^128 - 1]Float
赋值时必须在数字后加上 f 或 F
double浮点型 64 bit
0.0d[2^-1074, 2^1024 - 1]Double
赋值时一般在数字后加 d 或 D
::: tip 扩展
菜鸟教程 - Java 基本数据类型
:::
【简单】什么是装箱、拆箱? ::: info 什么是装箱、拆箱?
Java 中为每一种基本数据类型提供了相应的包装类,如下:
1 2 3 4 5 6 7 8 Byte <-> byte Short <-> short Integer <-> int Long <-> long Float <-> float Double <-> double Character <-> char Boolean <-> boolean
引入包装类的目的 就是:提供一种机制,使得基本数据类型可以与引用类型互相转换 。
基本数据类型与包装类的转换被称为装箱和拆箱。
装箱(boxing)是将值类型转换为引用类型 。例如:int 转 Integer
装箱过程是通过调用包装类的 valueOf 方法实现的 。
拆箱(unboxing)是将引用类型转换为值类型 。例如:Integer 转 int
拆箱过程是通过调用包装类的 xxxValue 方法实现的 。(xxx 代表对应的基本数据类型)。
::: info 什么是自动装箱与拆箱?
1 2 Integer a = 10 ; int b = a;
上面这两行代码对应的字节码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 L1 LINENUMBER 8 L1 ALOAD 0 BIPUSH 10 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; PUTFIELD AutoBoxTest.i : Ljava/lang/Integer; L2 LINENUMBER 9 L2 ALOAD 0 ALOAD 0 GETFIELD AutoBoxTest.i : Ljava/lang/Integer; INVOKEVIRTUAL java/lang/Integer.intValue ()I PUTFIELD AutoBoxTest.n : I RETURN
通过字节码代码,不难发现,装箱其实就是调用了 包装类的 valueOf() 方法;而拆箱其实就是调用了 xxxValue() 方法。再次印证前文的内容:
装箱过程是通过调用包装类的 valueOf 方法实现的 。拆箱过程是通过调用包装类的 xxxValue 方法实现的 。
因此,
Integer a = 10 等价于 Integer a = Integer.valueOf(10)int b = a 等价于 int b = a.intValue();
::: tip 扩展
深入剖析 Java 中的装箱和拆箱
:::
【中等】包装类型的缓存机制了解么? Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
::: tabs
@tab Integer 缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 public static Integer valueOf (int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer (i); } private static class IntegerCache { static final int low = -128 ; static final int high; static { int h = 127 ; } }
@tab Character 缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static Character valueOf (char c) { if (c <= 127 ) { return CharacterCache.cache[(int )c]; } return new Character (c); } private static class CharacterCache { private CharacterCache () {} static final Character cache[] = new Character [127 + 1 ]; static { for (int i = 0 ; i < cache.length; i++) cache[i] = new Character ((char )i); } }
@tab Boolean 缓存
1 2 3 public static Boolean valueOf (boolean b) { return (b ? TRUE : FALSE); }
@tab Float 和 Double 无缓存
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
1 2 3 4 5 6 7 8 9 10 11 Integer i1 = 33 ;Integer i2 = 33 ;System.out.println(i1 == i2); Float i11 = 333f ;Float i22 = 333f ;System.out.println(i11 == i22); Double i3 = 1.2 ;Double i4 = 1.2 ;System.out.println(i3 == i4);
:::
下面我们来看一个问题:下面的代码的输出结果是 true 还是 false 呢?
1 2 3 Integer i1 = 40 ;Integer i2 = new Integer (40 );System.out.println(i1==i2);
Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是缓存中的对象。而Integer i2 = new Integer(40) 会直接创建新的对象。
因此,答案是 false 。你答对了吗?
值得一提的是,包装类通过缓存一定范围的常用数值,避免重复创建对象,以减少内存使用的思想,正是采用了享元模式 (设计模式之一)。
记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较 。
【简单】比较包装类型为什么不能用 ==? Java 值类型的包装类大部分都使用了缓存机制来提升性能:
Byte、Short、Integer、Long 这 4 种包装类,默认都创建了数值在 [-128,127] 范围之间的相应类型缓存数据;Character 创建了数值在 [0,127] 范围之间的缓存数据;Boolean 直接返回 True or False;
试图装箱的数值,如果超出缓存范围,则会创建新的对象。
以 Long.valueOf 方法为例:
1 2 3 4 5 6 7 public static Long valueOf (long l) { final int offset = 128 ; if (l >= -128 && l <= 127 ) { return LongCache.cache[(int )l + offset]; } return new Long (l); }
【中等】为什么浮点数运算的时候会有精度丢失的风险? 浮点数运算精度丢失代码演示:
1 2 3 4 5 float a = 2.0f - 1.9f ;float b = 1.8f - 1.7f ;System.out.println(a); System.out.println(b); System.out.println(a == b);
为什么会出现这个问题呢?
这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么浮点数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
1 2 3 4 5 6 7 8 0.2 * 2 = 0.4 -> 0 0.4 * 2 = 0.8 -> 0 0.8 * 2 = 1.6 -> 1 0.6 * 2 = 1.2 -> 1 0.2 * 2 = 0.4 -> 0 (发生循环)...
【简单】如何解决浮点数运算的精度丢失问题? BigDecimal 直接使用字符串初始化(如 new BigDecimal("0.1"))可完全避免二进制浮点误差。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)可以通过 BigDecimal 来处理。
1 2 3 4 5 6 7 8 9 10 BigDecimal a = new BigDecimal ("1.0" );BigDecimal b = new BigDecimal ("0.9" );BigDecimal c = new BigDecimal ("0.8" );BigDecimal x = a.subtract(b);BigDecimal y = b.subtract(c);System.out.println(x); System.out.println(y); System.out.println(Objects.equals(x, y));
【简单】超过 long 整型的数据应该如何表示? 基本数值类型都有一个表达范围,如果超过这个范围就会有数值溢出的风险。
在 Java 中,64 位 long 整型是最大的整数类型。
1 2 3 long l = Long.MAX_VALUE;System.out.println(l + 1 ); System.out.println(l + 1 == Long.MIN_VALUE);
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
相对于常规整数类型的运算来说,BigInteger 运算的效率会相对较低。
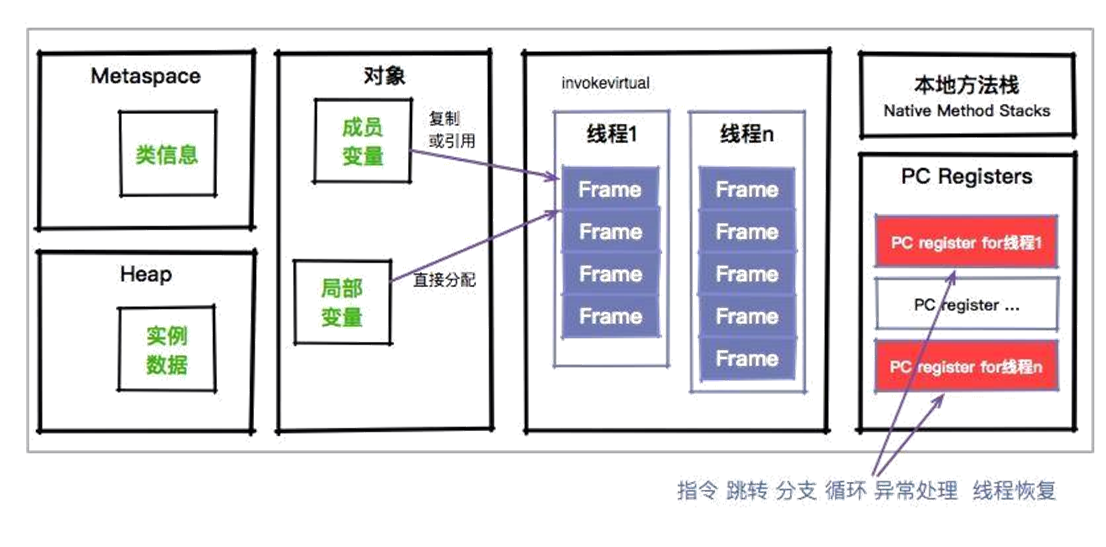
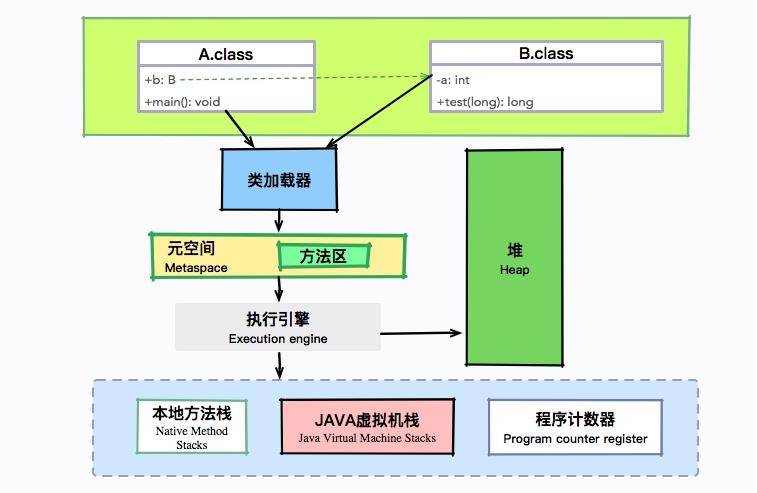
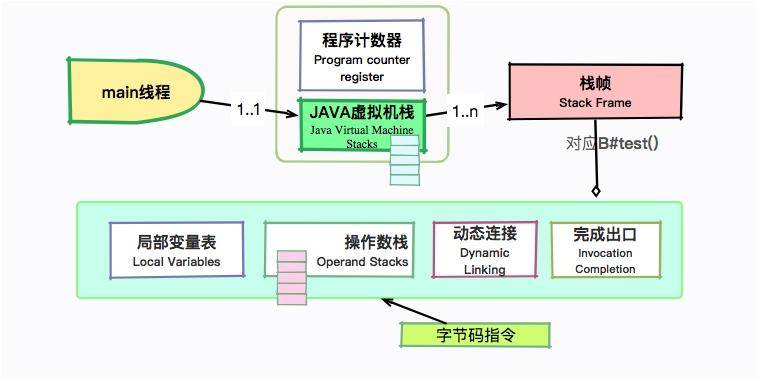
Java 变量 【简单】静态变量、成员变量、局部变量的区别? 静态变量、成员变量、局部变量的主要区别
特性 静态变量(static) 成员变量(非 static) 局部变量
所属 类(所有实例共享)
对象(每个实例独立)
方法/代码块内
生命周期 类加载时创建,程序结束时销毁
对象创建时存在,垃圾回收时销毁
方法调用时创建,执行完销毁
存储位置 方法区(JDK8+在元空间/堆)
堆(对象内部)
栈(方法栈帧)
默认值 有(如int默认为 0)
有(同静态变量)
无 (必须手动初始化)
访问方式 类名.变量名 或 对象.变量名对象.变量名只能在声明的方法/块内使用
一句话总结 :
静态变量 :全局唯一,类共享。成员变量 :对象私有,每个实例独立。局部变量 :临时使用,方法内有效。
【简单】为什么成员变量有默认值? 成员变量有默认值的核心原因是:防止随机值风险 。
内存安全 :未初始化的变量会指向内存中的随机值,可能导致程序行为异常或崩溃。稳定运行 :自动赋默认值(如 int→0,boolean→false)确保程序逻辑可预测。
编译器设计的权衡
成员变量 :自动赋默认值是内存安全与灵活性的平衡 。
运行时可能通过反射、构造器等动态赋值,编译器无法完全静态检测。
为避免误报错误,统一自动赋默认值。
局部变量 :严格编译检查确保代码可靠性 。
作用域限于方法内,编译器可严格检查是否赋值。
强制手动初始化以规避潜在风险。
【简单】字符型常量和字符串常量的区别?
场景 字符常量 字符串常量
表示形式 单引号括起的单个字符 ('A')
双引号括起的字符序列 ("ABC")
数据类型 char(基本类型)String(引用类型)
内存占用 2 字节(Unicode 字符,如 '中'、'\n')
对象开销+字符数据(可变长度)
转义字符 支持('\t'、'\\')
同样支持("\t"、"\\")
空值表示 不可为空(至少 1 字符)
可为空("")
运算行为 按 Unicode 值运算
重载+为拼接
Java 方法 【简单】Java 方法有哪些类型? Java 方法的类型可以从不同维度分类。
::: tabs
@tab 按从属划分
类型 关键字 调用方式 特点 示例
实例方法 无
对象名.方法名 ()依赖对象实例,可访问实例成员
list.add("item")
静态方法 static类名.方法名 ()不依赖实例,只能访问静态成员
Math.abs(-1)
构造方法 无
new 类名 ()用于对象初始化,无返回值类型
new String("hello")
@tab 按能否 override 划分
类型 关键字 特点 示例
普通方法 无
可被重写(除非final修饰)
public void show()
final 方法 final禁止子类重写
public final void lock()
抽象方法 abstract无实现,需子类重写
abstract void draw();
默认方法 defaultJava 8 接口中的默认实现
default void log()
@tab 按参数与返回值划分
类型 特点 示例
无参方法 不需要参数
String getName()
有参方法 可接受基本类型/对象参数
void setAge(int age)
可变参方法 参数数量可变(...语法)
void print(String... strs)
无返回值方法 返回类型为void
void shutdown()
有返回值方法 必须返回指定类型值
int calculate()
@tab 特殊方法
类型 特点 示例
native 方法 用native声明,由本地代码实现
public native void start()
synchronized 方法 用synchronized修饰,线程安全
public synchronized void save()
递归方法 方法内部调用自身
int factorial(int n)
泛型方法 声明类型参数
<T> T getData()
@tab 接口中的方法
类型 关键字 特点
抽象方法 无
默认public abstract
默认方法 defaultJava 8 引入,提供默认实现
静态方法 staticJava 8 引入,接口直接调用
私有方法 privateJava 9 引入,仅供接口内部使用
:::
代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Calculator { public int add (int a, int b) { return a + b; } public static int staticAdd (int a, int b) { return a + b; } } abstract class Shape { abstract void draw () ; } interface Logger { default void log (String msg) { System.out.println(msg); } } class Box { public <T> T wrap (T item) { return item; } }
::: info 如何选择方法类型?
需要操作对象状态 → 实例方法(如user.getName())工具类操作 → 静态方法(如Collections.sort())强制子类实现 → 抽象方法(如Animal.eat())接口功能扩展 → 默认方法(Java 8+)线程安全控制 → synchronized方法
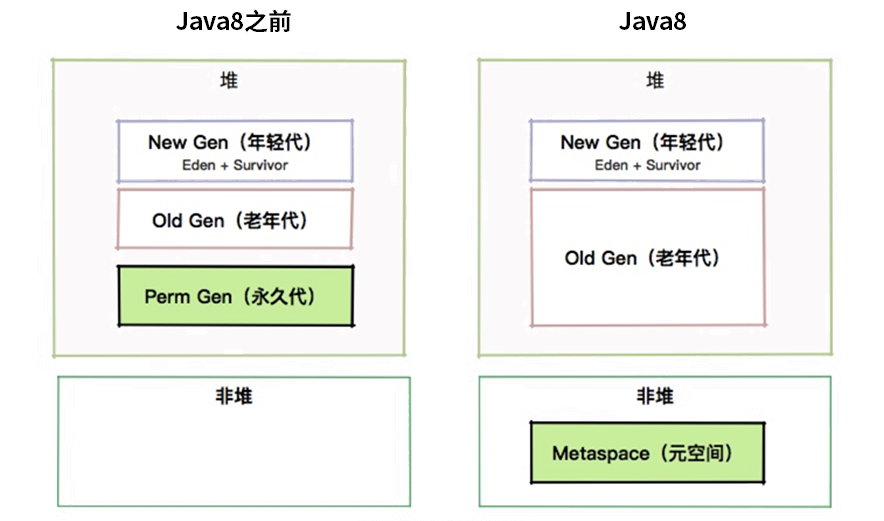
【简单】静态方法和实例方法有何不同? 静态方法和实例方法主要区别 :
维度 静态方法 (Static Method) 实例方法 (Instance Method)
归属 属于类
属于对象实例
关键字 使用 static 修饰
无 static 修饰
调用方式 类名.方法名 ()对象名.方法名 ()
内存分配 类加载时分配,永久代(JDK8 前)/元空间(JDK8+)
对象实例化时分配,堆内存
生命周期 与类相同(从类加载到 JVM 退出)
与对象相同(从对象创建到被 GC 回收)
访问权限对比 :
维度 静态方法 实例方法
访问静态成员 ✅ 可直接访问
✅ 可直接访问
访问实例成员 ❌ 不能直接访问(需先创建对象)
✅ 可直接访问
this/super ❌ 不可使用
✅ 可使用
代码示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Calculator { public static int add (int a, int b) { return a + b; } private int base; public void setBase (int base) { this .base = base; } public int calculate (int x) { return base + x; } } public class Main { public static void main (String[] args) { int sum = Calculator.add(3 , 5 ); Calculator calc = new Calculator (); calc.setBase(10 ); int result = calc.calculate(5 ); } }
【简单】重载和重写有什么区别? Java 重载(Overload)与重写(Override)的核心区别 :
特性 重载(Overload) 重写(Override)
定义 同一类中方法名相同但参数不同
子类重新实现父类的方法
目的 处理不同类型/数量的参数
修改或扩展父类方法的行为
多态类型 编译时多态(静态绑定)
运行时多态(动态绑定)
作用范围 同一类中(或父子类间)
子类与父类之间
方法签名 必须不同参数 (类型/数量/顺序)必须完全相同 (方法名+参数)
返回值 可自由修改
基本类型/void:必须相同;引用类型:可协变(子类更具体)
异常 可自由声明
子类异常 ≤ 父类异常范围
访问权限 可自由修改
子类权限 ≥ 父类(不能更严格)
限制方法 无
不能重写 private/final/static 方法
::: code-tabs#重载和重写的示例
@tab 重载示例
1 2 3 4 5 6 7 8 class Calculator { int add (int a, int b) { return a + b; } double add (double a, double b) { return a + b; } int add (int a, int b, int c) { return a + b + c; } }
@tab 重写示例
1 2 3 4 5 6 7 8 9 10 class Animal { protected String sound () { return "Unknown sound" ; } } class Cat extends Animal { @Override public String sound () { return "Meow" ; } }
:::
::: note 关键区别总结
绑定时机
重载:编译时根据参数决定调用的方法(Calculator.add(int) vs Calculator.add(double))
重写:运行时根据对象实际类型决定方法(Animal.sound() 实际调用 Cat.sound())
设计目的
重载:横向扩展 (同一功能的不同参数版本)
重写:纵向覆盖 (子类定制父类行为)
验证阶段
重载:编译器检查参数差异
重写:编译器检查方法签名 + JVM 运行时验证
:::
【简单】什么是可变长参数? 从 Java5 开始,Java 支持定义可变长参数,所谓可变长参数就是允许在调用方法时传入不定长度的参数。就比如下面这个方法就可以接受 0 个或者多个参数。
1 2 3 public static void method1 (String... args) { }
另外,可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数。
1 2 3 public static void method2 (String arg1, String... args) { }
遇到方法重载的情况怎么办呢?会优先匹配固定参数还是可变参数的方法呢?
答案是会优先匹配固定参数的方法,因为固定参数的方法匹配度更高。
我们通过下面这个例子来证明一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VariableLengthArgument { public static void printVariable (String... args) { for (String s : args) { System.out.println(s); } } public static void printVariable (String arg1, String arg2) { System.out.println(arg1 + arg2); } public static void main (String[] args) { printVariable("a" , "b" ); printVariable("a" , "b" , "c" , "d" ); } }
输出:
另外,Java 的可变参数编译后实际会被转换成一个数组,我们看编译后生成的 class文件就可以看出来了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class VariableLengthArgument { public static void printVariable (String... args) { String[] var1 = args; int var2 = args.length; for (int var3 = 0 ; var3 < var2; ++var3) { String s = var1[var3]; System.out.println(s); } } }
Java 异常
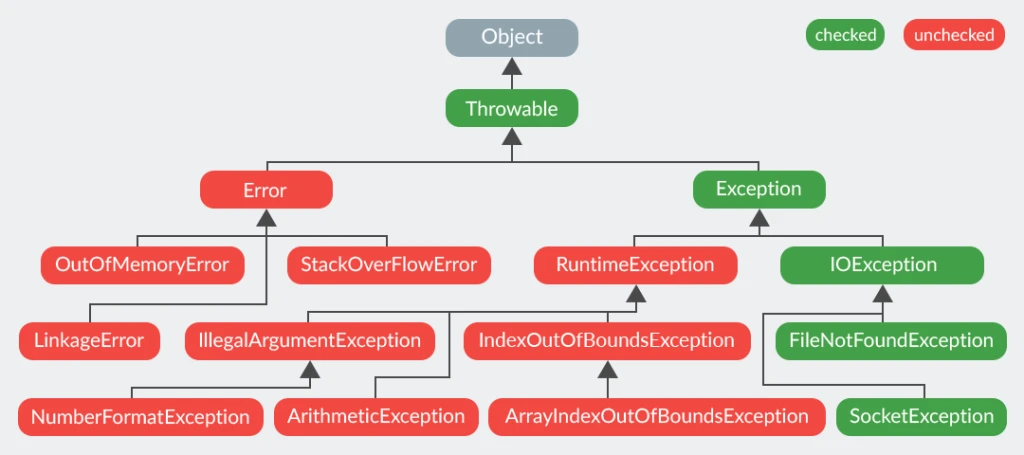
【简单】Exception 和 Error 有什么区别? 在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
Exceptioncatch 来进行捕获。Exception 又分为检查 (checked)异常和非检查 (unchecked)异常,检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。ErrorError 属于程序无法处理的错误。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
【简单】Checked Exception 和 Unchecked Exception 有什么区别? 差异对比 :
特性 Checked Exception Unchecked Exception
编译检查 必须显式处理(catch/throws),否则编译失败
不强制处理,编译可通过
继承体系 继承自 Exception(非 RuntimeException 分支)
继承自 RuntimeException
设计目的 处理可预见的、可恢复的 异常情况(如文件不存在)
处理程序逻辑错误 (如空指针)
::: tabs#Checked Exception 和 Unchecked Exception 示例对比
@tab Checked Exception 示例
1 2 3 4 5 6 try { Files.readAllBytes(Paths.get("file.txt" )); } catch (IOException e) { System.err.println("文件读取失败:" + e.getMessage()); }
@tab Unchecked Exception 示例
1 2 3 String str = null ;System.out.println(str.length());
:::
常见异常类型
Checked Exception Unchecked Exception
IOExceptionNullPointerException
SQLExceptionIllegalArgumentException
ClassNotFoundExceptionArrayIndexOutOfBoundsException
InterruptedExceptionClassCastException
选择原则
用 Checked Exception :
调用方必须处理 该异常(如文件不存在、网络断开)
异常是业务逻辑的合法流程 (如用户输入校验)
用 Unchecked Exception :
表示程序错误 (如参数为 null、数组越界)
调用方无法合理恢复 (如内存溢出)
【简单】Throwable 类常用方法有哪些?
String getMessage(): 返回异常发生时的简要描述String toString(): 返回异常发生时的详细信息String getLocalizedMessage(): 返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同void printStackTrace(): 在控制台上打印 Throwable 对象封装的异常信息
【简单】try-catch-finally 如何使用?
try块:用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。catch块:用于处理 try 捕获到的异常。finally 块:无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
代码示例:
1 2 3 4 5 6 7 8 try { System.out.println("Try to do something" ); throw new RuntimeException ("RuntimeException" ); } catch (Exception e) { System.out.println("Catch Exception -> " + e.getMessage()); } finally { System.out.println("Finally" ); }
输出:
1 2 3 Try to do something Catch Exception -> RuntimeException Finally
注意:不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
jvm 官方文档 中有明确提到:
If the try clause executes a return , the compiled code does the following:
Saves the return value (if any) in a local variable.
Executes a jsr to the code for the finally clause.
Upon return from the finally clause, returns the value saved in the local variable.
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) { System.out.println(f(2 )); } public static int f (int value) { try { return value * value; } finally { if (value == 2 ) { return 0 ; } } }
输出:
【简单】finally 中的代码一定会执行吗? 不一定的!在某些情况下,finally 中的代码不会被执行。
就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。
1 2 3 4 5 6 7 8 9 10 try { System.out.println("Try to do something" ); throw new RuntimeException ("RuntimeException" ); } catch (Exception e) { System.out.println("Catch Exception -> " + e.getMessage()); System.exit(1 ); } finally { System.out.println("Finally" ); }
输出:
1 2 Try to do somethingCatch Exception -> RuntimeException
另外,在以下 2 种特殊情况下,finally 块的代码也不会被执行:
程序所在的线程死亡。
关闭 CPU。
【简单】如何使用 try-with-resources 代替try-catch-finally?
适用范围(资源的定义): 任何实现 java.lang.AutoCloseable或者 java.io.Closeable 的对象关闭资源和 finally 块的执行顺序: 在 try-with-resources 语句中,任何 catch 或 finally 块在声明的资源关闭后运行
《Effective Java》中明确指出:
面对必须要关闭的资源,我们总是应该优先使用 try-with-resources 而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
Java 中类似于InputStream、OutputStream、Scanner、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Scanner scanner = null ;try { scanner = new Scanner (new File ("D://read.txt" )); while (scanner.hasNext()) { System.out.println(scanner.nextLine()); } } catch (FileNotFoundException e) { e.printStackTrace(); } finally { if (scanner != null ) { scanner.close(); } }
使用 Java 7 之后的 try-with-resources 语句改造上面的代码:
1 2 3 4 5 6 7 try (Scanner scanner = new Scanner (new File ("test.txt" ))) { while (scanner.hasNext()) { System.out.println(scanner.nextLine()); } } catch (FileNotFoundException fnfe) { fnfe.printStackTrace(); }
当然多个资源需要关闭的时候,使用 try-with-resources 实现起来也非常简单,如果你还是用try-catch-finally可能会带来很多问题。
通过使用分号分隔,可以在try-with-resources块中声明多个资源。
1 2 3 4 5 6 7 8 9 10 try (BufferedInputStream bin = new BufferedInputStream (new FileInputStream (new File ("test.txt" ))); BufferedOutputStream bout = new BufferedOutputStream (new FileOutputStream (new File ("out.txt" )))) { int b; while ((b = bin.read()) != -1 ) { bout.write(b); } } catch (IOException e) { e.printStackTrace(); }
【简单】NoClassDefFoundError 和 ClassNotFoundException 有什么区别 NoClassDefFoundError是一个 Error,而 ClassNotFoundException 是一个 Exception。
ClassNotFoundException 产生的原因:
使用 Class.forName、ClassLoader.loadClass、ClassLOader.findSystemClass 方法动态加载类,如果这个类没有被找到,那么就会在运行时抛出 ClassNotFoundException 异常;
当一个类已经被某个类加载器加载到内存中了,此时另一个类加载器又尝试着动态地从同一个包中加载这个类。
NoClassDefFoundError 产生的原因:当 JVM 或 ClassLoader 试图加载类,却找不到类的定义时(编译时存在,运行时找不到),抛出异常。
【简单】异常使用有哪些需要注意的地方?
不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
抛出的异常信息一定要有意义。
建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出NumberFormatException而不是其父类IllegalArgumentException。
避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
……
【中等】Java 中 final、finally 和 finalize 有什么区别?
特性
final
finally
finalize
类型 关键字
代码块
方法
作用域 变量/方法/类
异常处理块
Object 类方法
作用 声明不可变性
即使有异常也必然执行,确保资源释放
对象回收前的清理(已废弃)
特点 可修饰变量(常量)、方法(不可重写)、类(不可继承)
与try-catch搭配,必然执行 (除非 JVM 退出)
不推荐用,执行时机不可控
使用场景 定义常量/限制继承
资源清理
历史遗留的清理逻辑
一句话总结 :final管不变性 ,finally管必执行 ,finalize是过时的清理机制 。
(注:现代 Java 开发用try-with-resources替代finalize)