网络协议之 ICMP
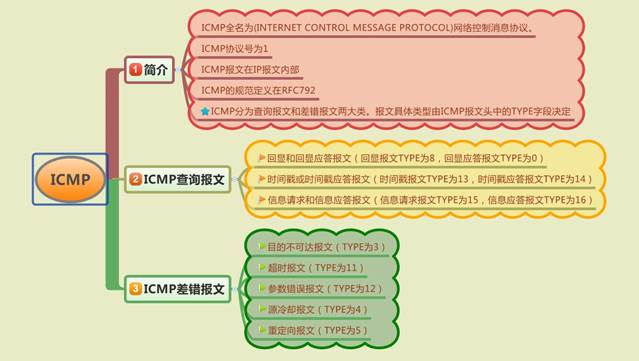
ICMP 简介
ICMP 全名为(INTERNET CONTROL MESSAGE PROTOCOL)网络控制消息协议。
ICMP 的协议号为1。
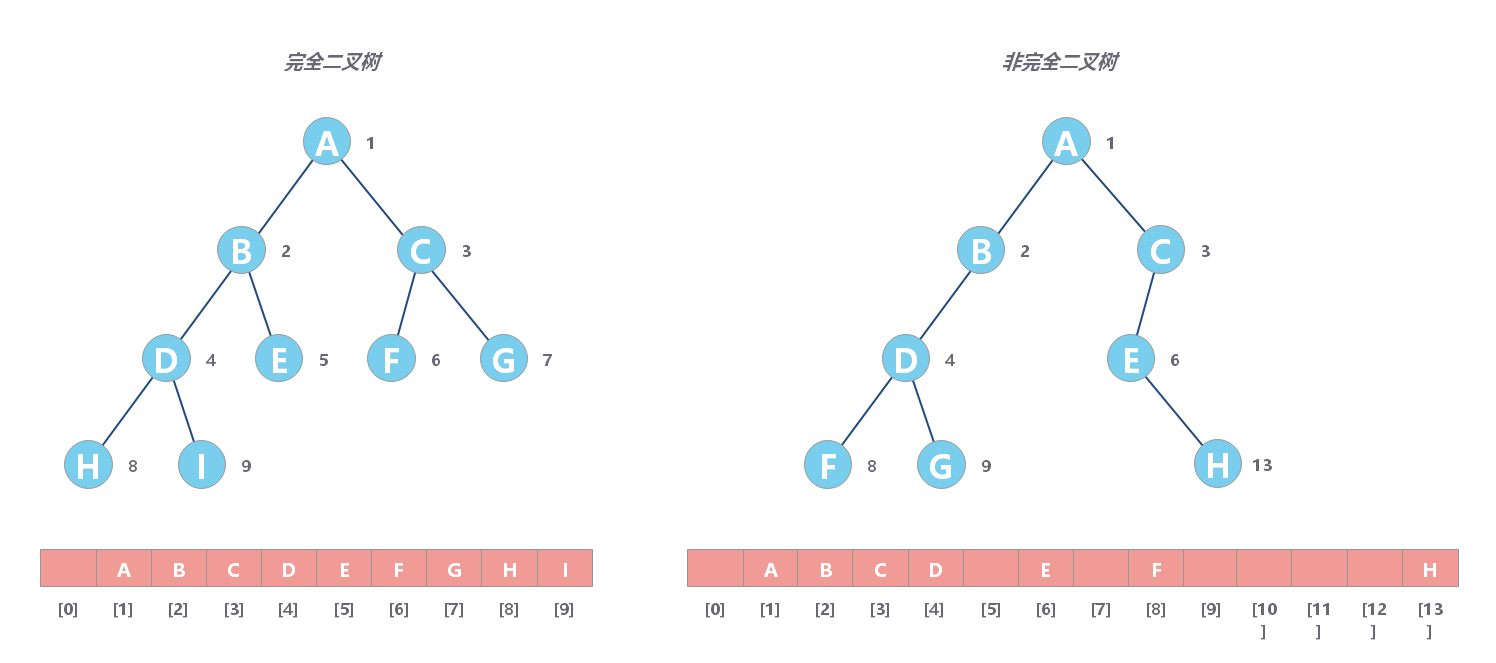
ICMP 报文就像是 IP 报文的小弟,总顶着 IP 报文的名头出来混。因为 ICMP 报文是在 IP 报文内部的,如图:

ICMP 类型
ICMP 报文主要有两大功能:查询报文和差错报文。
目的不可达(Destination Unreachable Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unused |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
日常生活中,邮寄包裹会经过多个传递环节,任意一环如果无法传下去,都会返回寄件人,并附上无法邮寄的原因。同理,当路由器收到一个无法传递下去的 IP 报文时,会发送 ICMP目的不可达报文(Type 为 3)给 IP 报文的源发送方。报文中的 Code 就表示发送失败的原因。
Code
0 = net unreachable;
1 = host unreachable;
2 = protocol unreachable;
3 = port unreachable;
4 = fragmentation needed and DF set;
5 = source route failed.
超时(Time Exceeded Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unused |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
网络传输 IP 数据报的过程中,如果 IP 数据包的 TTL 值逐渐递减为 0 时,需要丢弃数据报。这时,路由器需要向源发送方发送 ICMP 超时报文(Type 为 11),Code 为 0,表示传输过程中超时了。
一个 IP 数据报可能会因为过大而被分片,然后在目的主机侧把所有的分片重组。如果主机迟迟没有等到所有的分片报文,就会向源发送方发送一个 ICMP 超时报文,Code 为 1,表示分片重组超时了。
参数错误报文(Parameter Problem Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Pointer | unused |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
当路由器或主机处理数据报时,发现因为报文头的参数错误而不得不丢弃报文时,需要向源发送方发送参数错误报文(Type 为 12)。当 Code 为 0 时,报文中的 Pointer 表示错误的字节位置。
源冷却(Source Quench Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unused |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
路由器在处理报文时会有一个缓存队列。如果超过最大缓存队列,将无法处理,从而丢弃报文。并向源发送方发一个 ICMP 源冷却报文(Type 为 4),告诉对方:“嘿,我这里客满了,你迟点再来。”
重定向(Redirect Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Gateway Internet Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Internet Header + 64 bits of Original Data Datagram |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
想像一下,在公司中,有人来你的项目组问你某某某在哪儿。你一想,我们组没有这人啊。你肯定就会说,我们组没有这号人,你去其他组看看。当路由收到 IP 数据报,发现数据报的目的地址在路由表上没有,它就会发 ICMP 重定向报文(Type 为 5)给源发送方,提醒它想要发送的地址不在,去其他地方找找吧。
请求回显或回显应答(Echo or Echo Reply Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identifier | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data …
+-+-+-+-+-
**Type(8)是请求回显报文(Echo);Type(0)是回显应答报文(Echo Reply)**。
请求回显或回显应答报文属于查询报文。Ping 就是用这种报文进行查询和回应。
时间戳或时间戳请求(Timestamp or Timestamp Reply Message)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identifier | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Originate Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Receive Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Transmit Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
时间戳报文是用来记录收发以及传输时间的报文。Originate Timestamp 记录的是发送方发送报文的时刻;Receive Timestamp记录的是接收方收到报文的时刻;Transmit Timestamp表示回显这最后发送报文的时刻。
信息请求或信息响应
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Code | Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identifier | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
这种报文是用来找出一个主机所在的网络个数(一个主机可能会在多个网络中)。报文的 IP 消息头的目的地址会填为全 0,表示 this,源地址会填为源 IP 所在的网络 IP。
总结
图:ICMP 知识点思维导图
参考