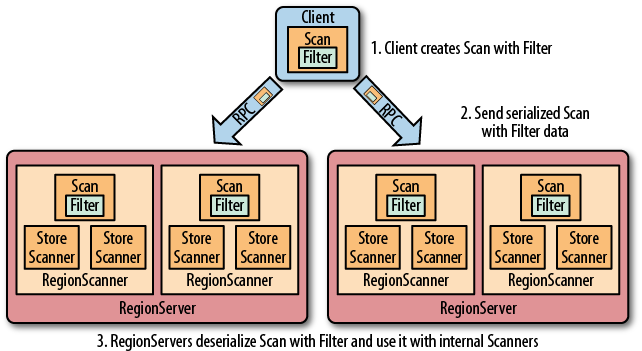
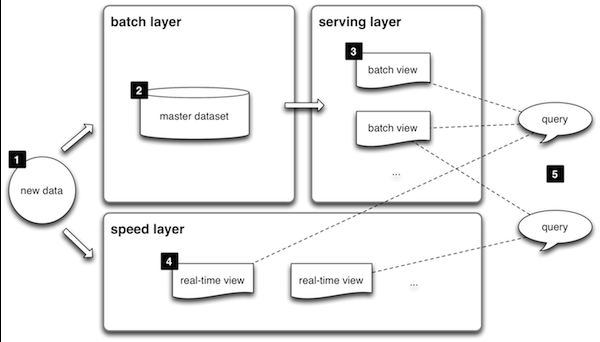
List<Long> list = new ArrayList<>(); list.add(1554975573000L); TimestampsFilter timestampsFilter = new TimestampsFilter(list); scan.setFilter(timestampsFilter);
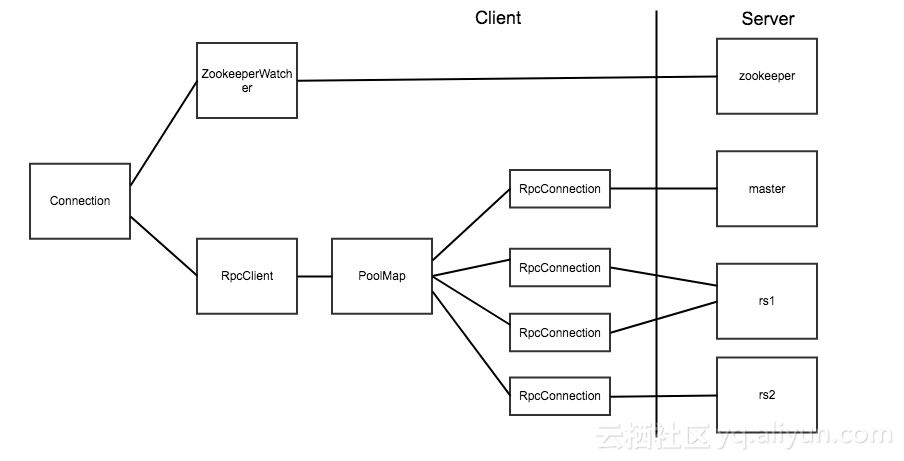
Connection Pooling For applications which require high-end multithreaded access (e.g., web-servers or application servers that may serve many application threads in a single JVM), you can pre-create a Connection, as shown in the following example:
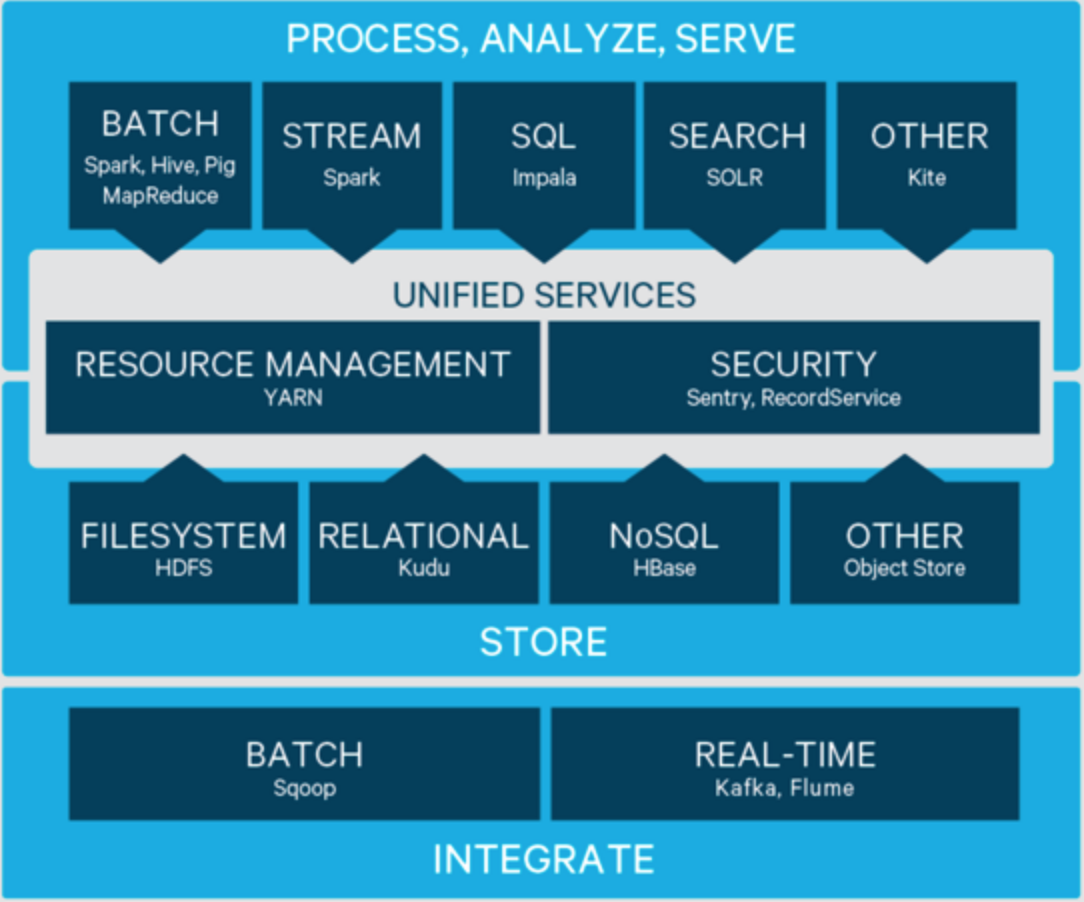
对于高并发多线程访问的应用程序(例如,在单个 JVM 中存在的为多个线程服务的 Web 服务器或应用程序服务器), 您只需要预先创建一个 Connection。例子如下:
// Create a connection to the cluster. Configuration conf = HBaseConfiguration.create(); try (Connection connection = ConnectionFactory.createConnection(conf); Tabletable = connection.getTable(TableName.valueOf(tablename))) { // use tableas needed, the table returned is lightweight }
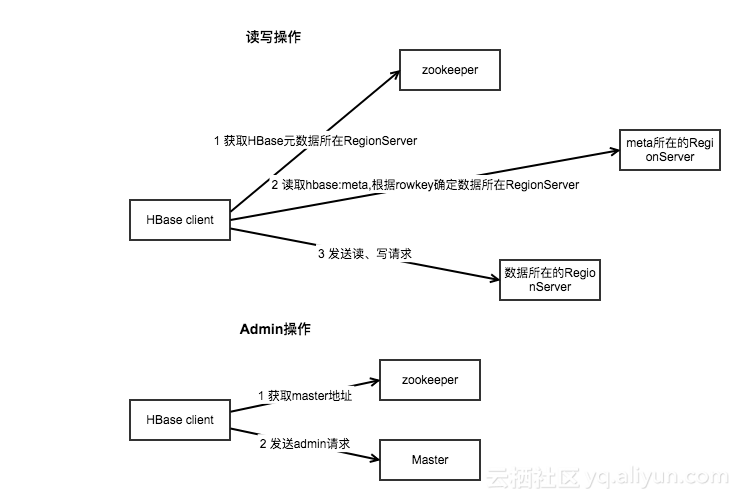
A clusterconnection encapsulating lower level individual connections to actual servers and a connectionto zookeeper. Connections are instantiated through the ConnectionFactory class. The lifecycle of the connectionis managed by the caller, who has toclose() the connection torelease the resources.
// 写入单行 put voidput(Put put)throws IOException; // 批量写入 put voidput(List<Put> puts)throws IOException;
Put 类提供了多种构造器方法用来初始化实例。
Put 类还提供了一系列有用的方法:
多个 add 方法:用于添加指定的列数据。
has 方法:用于检查是否存在特定的单元格,而不需要遍历整个集合
getFamilyMap 方法:可以遍历 Put 实例中每一个可用的 KeyValue 实例
getRow 方法:用于获取 rowkey Put.heapSize() 可以计算当前 Put 实例所需的堆大小,既包含其中的数据,也包含内部数据结构所需的空间
KeyValue 类
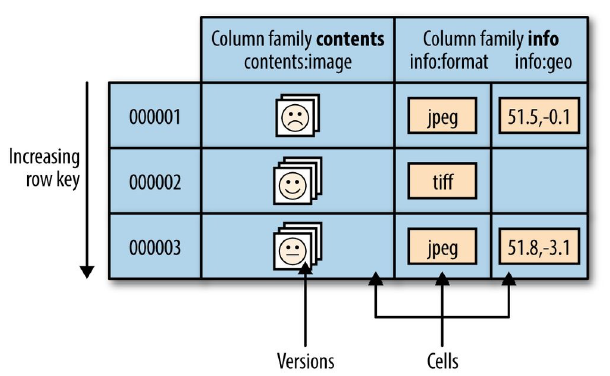
特定单元格的数据以及坐标,坐标包括行键、列族名、列限定符以及时间戳 KeyValue(byte[] row, int roffset, int rlength, byte[] family, int foffoset, int flength, byte[] qualifier, int qoffset, int qlength, long timestamp, Type type, byte[] value, int voffset, int vlength) 每一个字节数组都有一个 offset 参数和一个 length 参数,允许用户提交一个已经存在的字节数组进行字节级别操作。 行目前来说指的是行键,即 Put 构造器里的 row 参数。
客户端的写缓冲区
每一个 put 操作实际上都是一个 RPC 操作,它将客户端数据传送到服务器然后返回。
HBase 的 API 配备了一个客户端的写缓冲区,缓冲区负责收集 put 操作,然后调用 RPC 操作一次性将 put 送往服务器。
Column Family 数量多,会影响数据刷新。HBase 的数据刷新是在每个 Region 的基础上完成的。因此,如果一个 Column Family 携带大量导致刷新的数据,那么相邻的列族即使携带的数据量很小,也会被刷新。当存在许多 Column Family 时,刷新交互会导致一堆不必要的 IO。 此外,在表/区域级别的压缩操作也会在每个存储中发生。
Column Family 数量多,会影响查找效率。如:Column Family A 有 100 万行,Column Family B 有 10 亿行,那么 Column Family A 的数据可能会分布在很多很多区域(和 RegionServers)。 这会降低 Column Family A 的批量扫描效率。
Column Family 名尽量简短,最好是一个字符。Column Family 会在列限定符中被频繁使用,缩短长度有利于节省空间并提升效率。
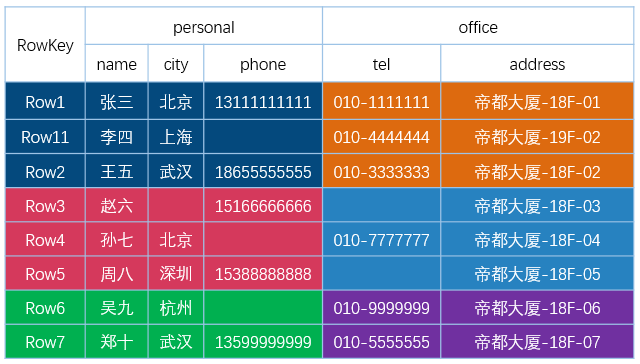
Row 设计
HBase 中的 Row 按 Row Key 的字典顺序排序。
不要将 Row Key 设计为单调递增的,例如:递增的整数或时间戳
问题:因为 Hbase 的 Row Key 是就近存储的,这样会导致一段时间内大部分写入集中在某一个 Region 上,即所谓热点问题。
数据存储容量的问题。RAID 使用了 N 块磁盘构成一个存储阵列,如果使用 RAID 5,数据就可以存储在 N-1 块磁盘上,这样将存储空间扩大了 N-1 倍。
数据读写速度的问题。RAID 根据可以使用的磁盘数量,将待写入的数据分成多片,并发同时向多块磁盘进行写入,显然写入的速度可以得到明显提高;同理,读取速度也可以得到明显提高。不过,需要注意的是,由于传统机械磁盘的访问延迟主要来自于寻址时间,数据真正进行读写的时间可能只占据整个数据访问时间的一小部分,所以数据分片后对 N 块磁盘进行并发读写操作并不能将访问速度提高 N 倍。
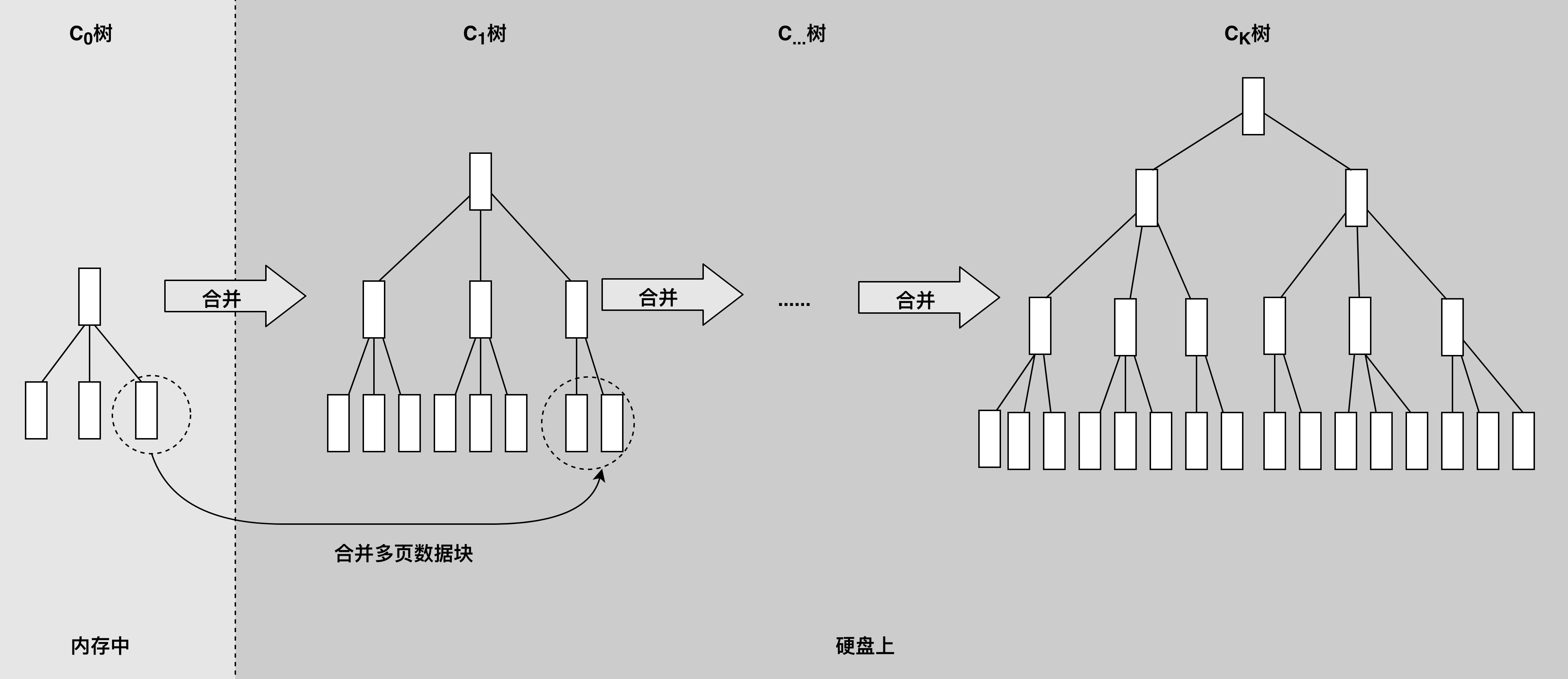
LSM 树可以看作是一个 N 阶合并树。数据写操作(包括插入、修改、删除)都在内存中进行,并且都会创建一个新记录(修改会记录新的数据值,而删除会记录一个删除标志)。这些数据在内存中仍然还是一棵排序树,当数据量超过设定的内存阈值后,会将这棵排序树和磁盘上最新的排序树合并。当这棵排序树的数据量也超过设定阈值后,会和磁盘上下一级的排序树合并。合并过程中,会用最新更新的数据覆盖旧的数据(或者记录为不同版本)。
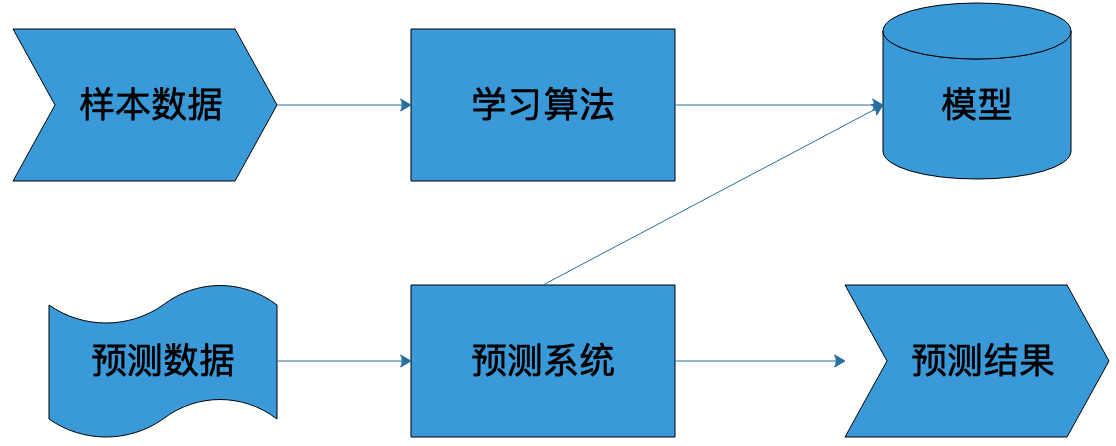
算法:算法就是要从模型的假设空间中寻找一个最优的函数,使得样本空间的输入 X 经过该函数的映射得到的 f(X),和真实的 Y 值之间的距离最小。这个最优的函数通常没办法直接计算得到,即没有解析解,需要用数值计算的方法不断迭代求解。因此如何寻找到 f 函数的全局最优解,以及使寻找过程尽量高效,就构成了机器学习的算法。
Spring 模板库中定义的一些宏被认为是内部的(私有的),但宏定义中不存在这样的范围,这使得所有宏对调用代码和用户模板都是可见的。以下部分仅关注您需要从模板中直接调用的宏。如果您想直接查看宏代码,该文件名为 spring.ftl ,位于 org.springframework.web.servlet.view.freemarker 包中。
简单绑定
在基于充当 Spring MVC 控制器表单视图的 FreeMarker 模板的 HTML 表单中,您可以使用类似于下一个示例的代码来绑定到字段值,并以类似于 JSP 等价物的方式为每个输入字段显示错误消息。以下示例显示了一个 personForm 视图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
<!-- FreeMarker macros have to be imported into a namespace. We strongly recommend sticking to 'spring'. --> <#import "/spring.ftl" as spring/> <html> ... <formaction=""method="POST"> Name: <@spring.bind "personForm.name"/> <inputtype="text" name="${spring.status.expression}" value="${spring.status.value?html}"/><br /> <#list spring.status.errorMessages as error> <b>${error}</b><br /> </#list> <br /> ... <inputtype="submit"value="submit"/> </form> ... </html>
前面描述的表单宏的默认使用导致 HTML 元素符合 HTML 4.01,并且使用 web.xml 文件中定义的 HTML 转义的默认值,如 Spring 的绑定支持所使用的那样。 要使元素符合 XHTML 或覆盖默认的 HTML 转义值,您可以在模板中指定两个变量(或在模型中,它们对模板可见)。 在模板中指定它们的好处是它们可以在稍后的模板处理中更改为不同的值,以便为表单中的不同字段提供不同的行为。
<!-- Configure the Groovy Markup Template Engine... --> <mvc:groovy-configurerresource-loader-path="/WEB-INF/"/>
示例
与传统的模板引擎不同,Groovy 标记依赖于使用构建器语法的 DSL。以下示例显示了 HTML 页面的示例模板:
1 2 3 4 5 6 7 8 9 10
yieldUnescaped '<!DOCTYPE html>' html(lang:'en') { head { meta('http-equiv':'"Content-Type" content="text/html; charset=utf-8"') title('My page') } body { p('This is an example of HTML contents') } }
脚本视图
Spring 有一个内置的集成,可以将 Spring MVC 与任何可以在 JSR-223 之上运行的模板库一起使用 Java 脚本引擎。 我们在不同的脚本引擎上测试了以下模板库:
MappingJackson2XmlView 使用 Jackson XML 扩展XmlMapper 将响应内容渲染为 XML。 如果模型包含多个条目,您应该使用 modelKey bean 属性显式设置要序列化的对象。 如果模型包含单个条目,它会自动序列化。
您可以根据需要使用 JAXB 或 Jackson 提供的注释自定义 XML 映射。当您需要进一步控制时,您可以通过 ObjectMapper 属性注入自定义 XmlMapper,对于需要为特定类型提供序列化器和反序列化器的自定义 XML 的情况
XML
MarshallingView 使用 XML Marshaller(在 org.springframework.oxm 包中定义)将响应内容渲染为 XML。 您可以使用 MarshallingView 实例的 modelKey 属性显式设置要编组的对象。 或者,视图遍历所有模型属性并编组 Marshaller 支持的第一个类型。 有关 org.springframework.oxm 包中功能的更多信息,请参阅 Marshalling XML using O/X Mappers。
XSLT
XSLT 是 XML 的一种转换语言,作为 Web 应用程序中的一种视图技术很受欢迎。 如果您的应用程序自然地处理 XML,或者如果您的模型可以很容易地转换为 XML,那么 XSLT 作为一种视图技术是一个不错的选择。 以下部分展示了如何生成 XML 文档作为模型数据,并在 Spring Web MVC 应用程序中使用 XSLT 对其进行转换。
此示例是一个简单的 Spring 应用程序,它在 Controller 中创建关键字列表并将它们添加到模型映射中。 返回映射以及我们的 XSLT 视图的视图名称。 有关 Spring Web MVC 的 Controller 接口的详细信息,请参阅 Annotated Controllers。 XSLT 控制器将单词列表转换为准备转换的简单 XML 文档。
Beans
配置是一个简单的 Spring Web 应用程序的标准配置:MVC 配置必须定义一个 XsltViewResolver 和常规 MVC 注释配置。以下示例显示了如何执行此操作:
Spring MVC HandlerMapping 实现提供了对 CORS 的内置支持。成功将请求映射到处理程序后,HandlerMapping 实现检查给定请求和处理程序的 CORS 配置并采取进一步的操作。预检请求被直接处理,而简单和实际的 CORS 请求被拦截、验证,并设置了所需的 CORS 响应标头。
为了启用跨源请求(即存在 Origin 标头并且与请求的主机不同),您需要有一些明确声明的 CORS 配置。如果未找到匹配的 CORS 配置,预检请求将被拒绝。没有 CORS 标头添加到简单和实际 CORS 请求的响应中,因此浏览器会拒绝它们。
可以将 HandlerMapping 级别的全局 CORS 配置与更细粒度的处理程序级别的 CORS 配置相结合。 例如,带注释的控制器可以使用类级或方法级的 @CrossOrigin 注释(其他处理程序可以实现 CorsConfigurationSource)。
The rules for combining global and local configuration are generally additive — for example, all global and all local origins. For those attributes where only a single value can be accepted, e.g. allowCredentials and maxAge, the local overrides the global value.