树和二叉树
树和二叉树
树
什么是树
在计算机科学中,树(英语:tree)是一种抽象数据类型(ADT)或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由 n(n>0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:
- 每个节点都只有有限个子节点或无子节点。
- 树有且仅有一个根节点。
- 根节点没有父节点;非根节点有且仅有一个父节点。
- 每个非根节点可以分为多个不相交的子树。
- 树里面没有环路。
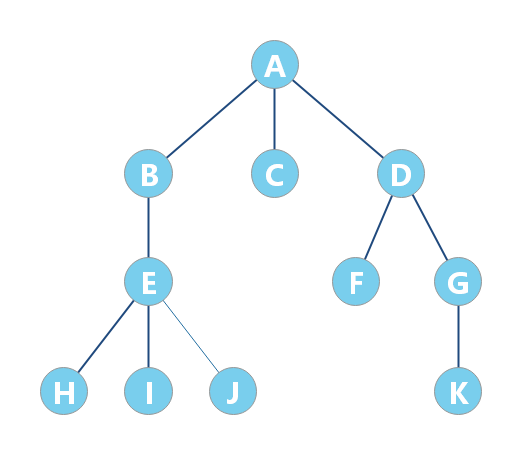
树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点度称为树的度;
- 叶子节点或终端节点:度为零的节点;
- 非终端节点或分支节点:度不为零的节点;
- 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由 m(m>=0)棵互不相交的树的集合称为森林;
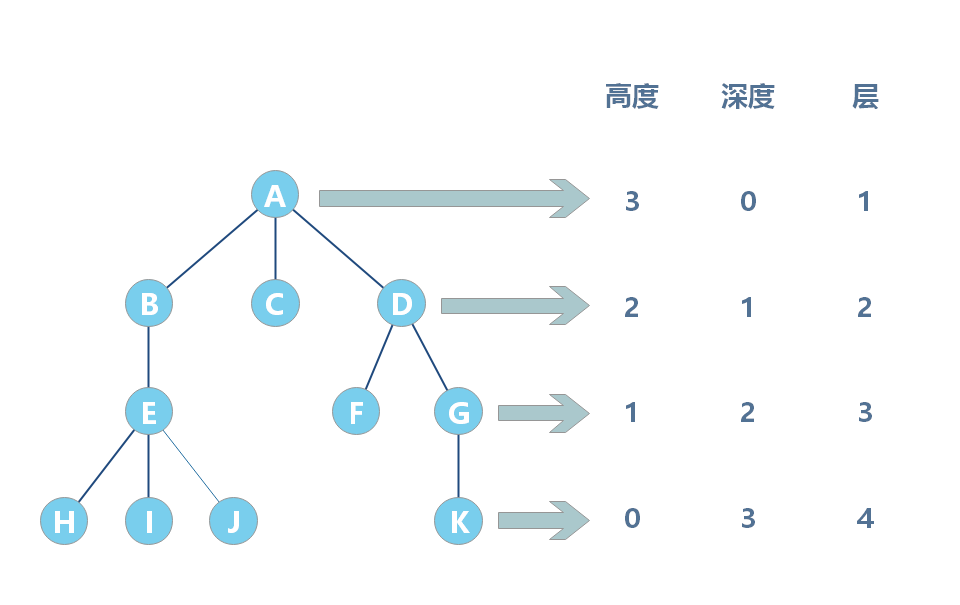
- 节点的高度:节点到叶子节点的最长路径。高度是从下往上度量。
- 节点的深度:根节点到该节点的最长路径。深度是从上往下度量。
- 节点的层次:节点的深度 + 1。
- 树的高度:根节点的高度。
树的性质
- 树中的节点数等于所有节点的度数加 1。
- 度为 m 的树中第
i层上至多有 $$m^{i-1}$$ 个节点($$i ≥ 1$$)。 - 高度为 h 的 m 次树至多有 $$(m^h-1)/(m-1)$$ 个节点。
- 具有 n 个节点的 m 次树的最小高度为 $$\log_m{(n(m-1)+1)}$$ 。
树的种类
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
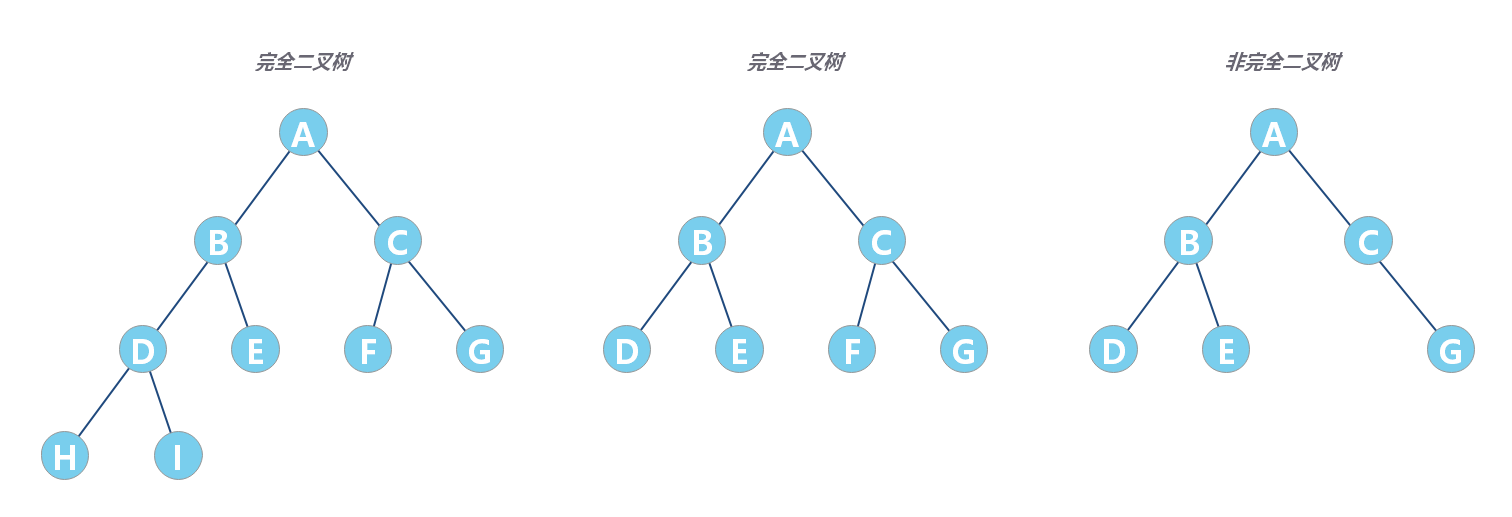
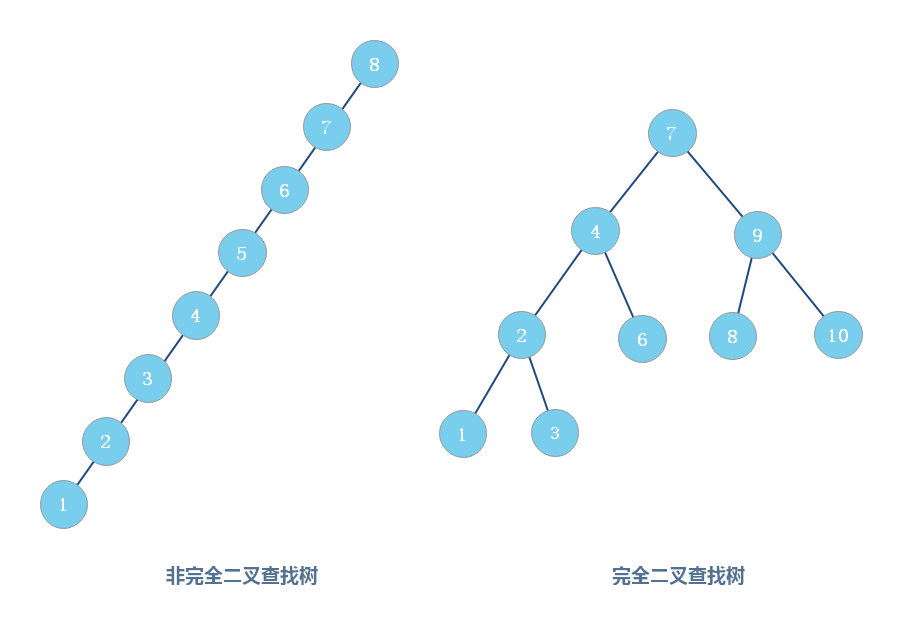
- 完全二叉树:对于一颗二叉树,假设其深度为 d(d>1)。除了第 d 层外,其它各层的节点数目均已达最大值,且第 d 层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树;
- 满二叉树:所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL 树):当且仅当任何节点的两棵子树的高度差不大于 1 的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree)):也称二叉搜索树、有序二叉树;
- 霍夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B 树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个子树。
二叉树
二叉树中的每个节点最多有两个子节点,分别是左子节点和右子节点。
二叉树的性质
- 二叉树第 i 层上的结点数目最多为 2i-1 (i≥1)。
- 深度为 k 的二叉树至多有 2k-1 个结点(k≥1)。
- 包含 n 个结点的二叉树的高度至少为 **log2(n+1)**。
- 在任意一棵二叉树中,若终端结点的个数为 n0,度为 2 的结点数为 n2,则 n0=n2+1。
满二叉树
除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫作满二叉树。
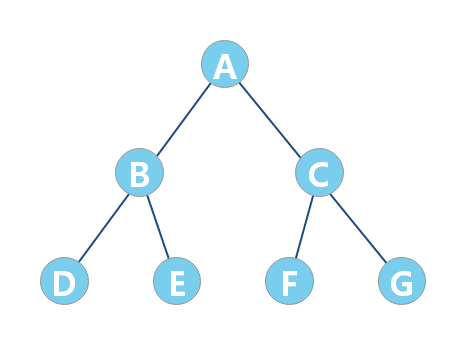
完全二叉树
叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫作完全二叉树。
特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
存储一棵二叉树,有两种方法,一种是基于指针或者引用的二叉链式存储法,一种是基于数组的顺序存储法。
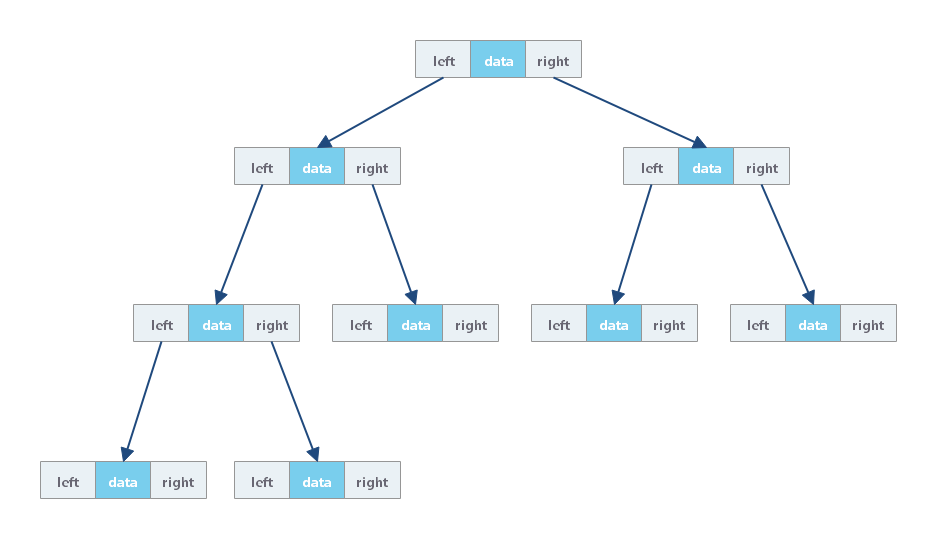
二叉链式存储法
每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。
顺序存储法
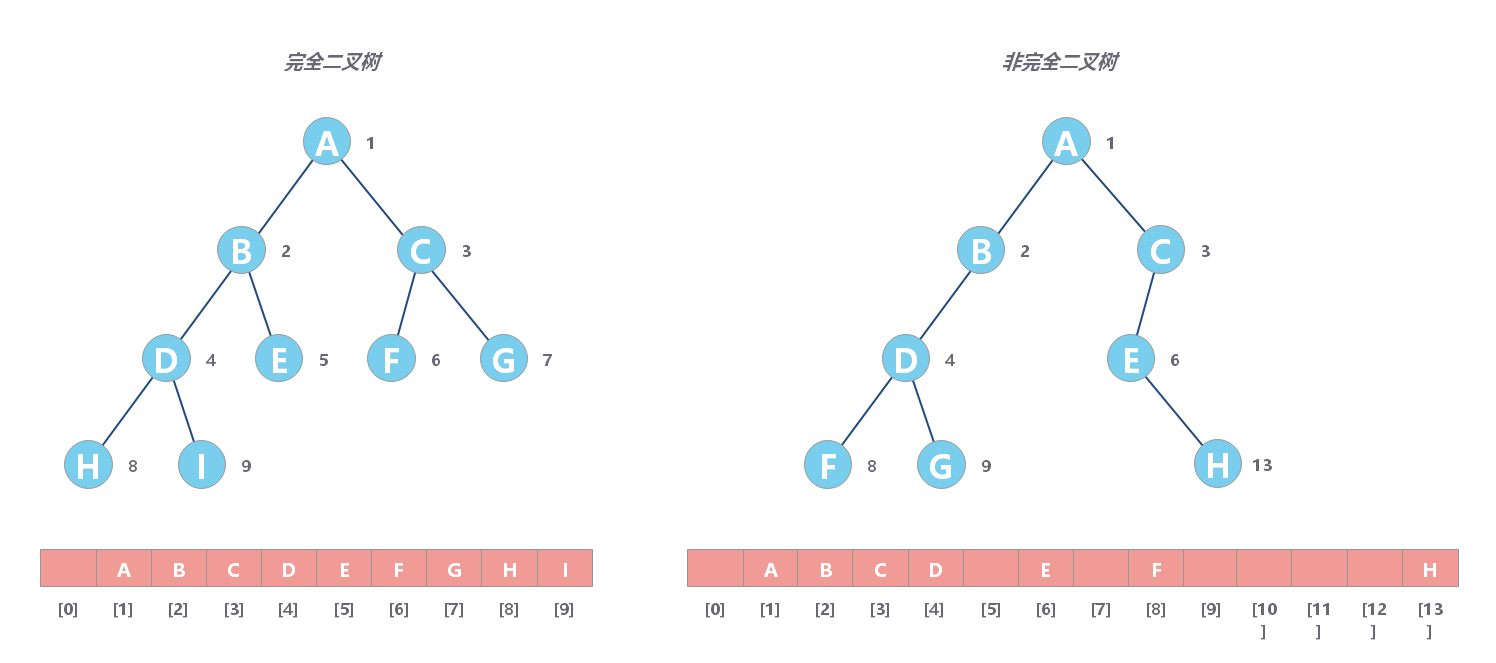
如果节点 X 存储在数组中下标为 i 的位置,下标为 2 _ i 的位置存储的就是左子节点,下标为 2 _ i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置),这样就可以通过下标计算,把整棵树都串起来。
如果是非完全二叉树,其实会浪费比较多的数组存储空间。所以,如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也是 为什么完全二叉树要求最后一层的子节点都靠左的原因。
二叉树的遍历
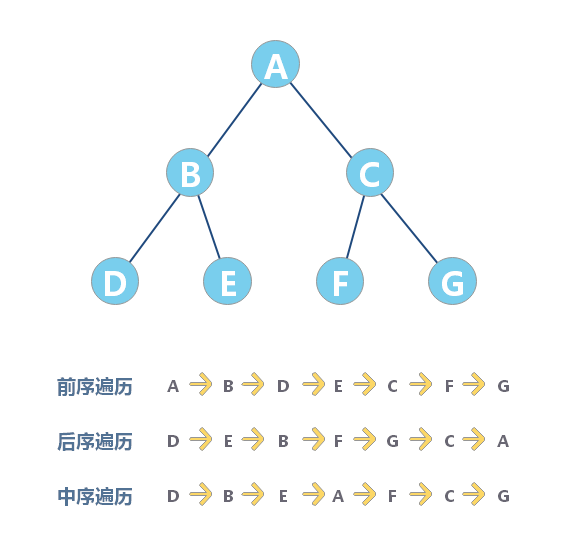
二叉树的遍历有三种方式:
- 前序遍历:对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
- 中序遍历:对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身。
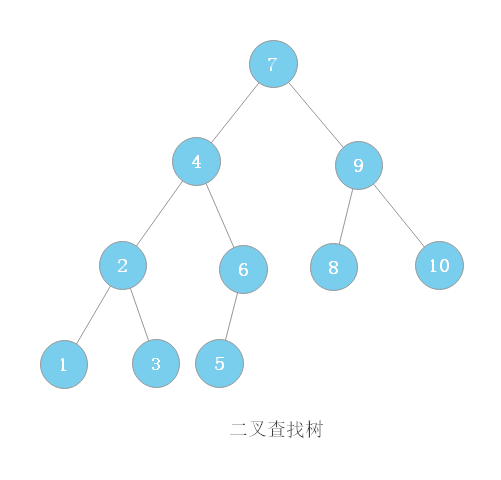
二叉查找树
二叉查找树是二叉树中最常用的一种类型,也叫二叉搜索树。顾名思义,二叉查找树是为了实现快速查找而生的。不过,它不仅仅支持快速查找一个数据,还支持快速插入、删除一个数据。
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
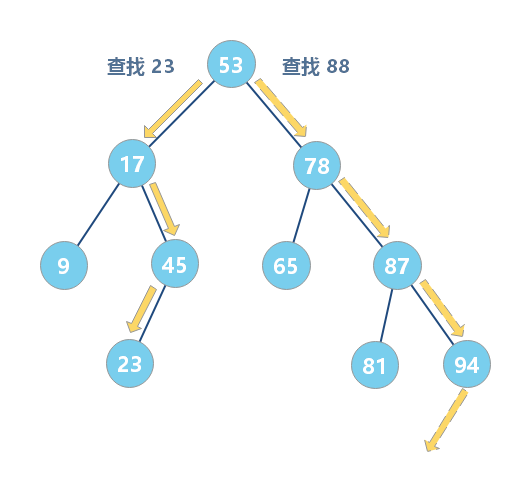
二叉查找树的查找
首先,我们看如何在二叉查找树中查找一个节点。我们先取根节点,如果它等于我们要查找的数据,那就返回。如果要查找的数据比根节点的值小,那就在左子树中递归查找;如果要查找的数据比根节点的值大,那就在右子树中递归查找。
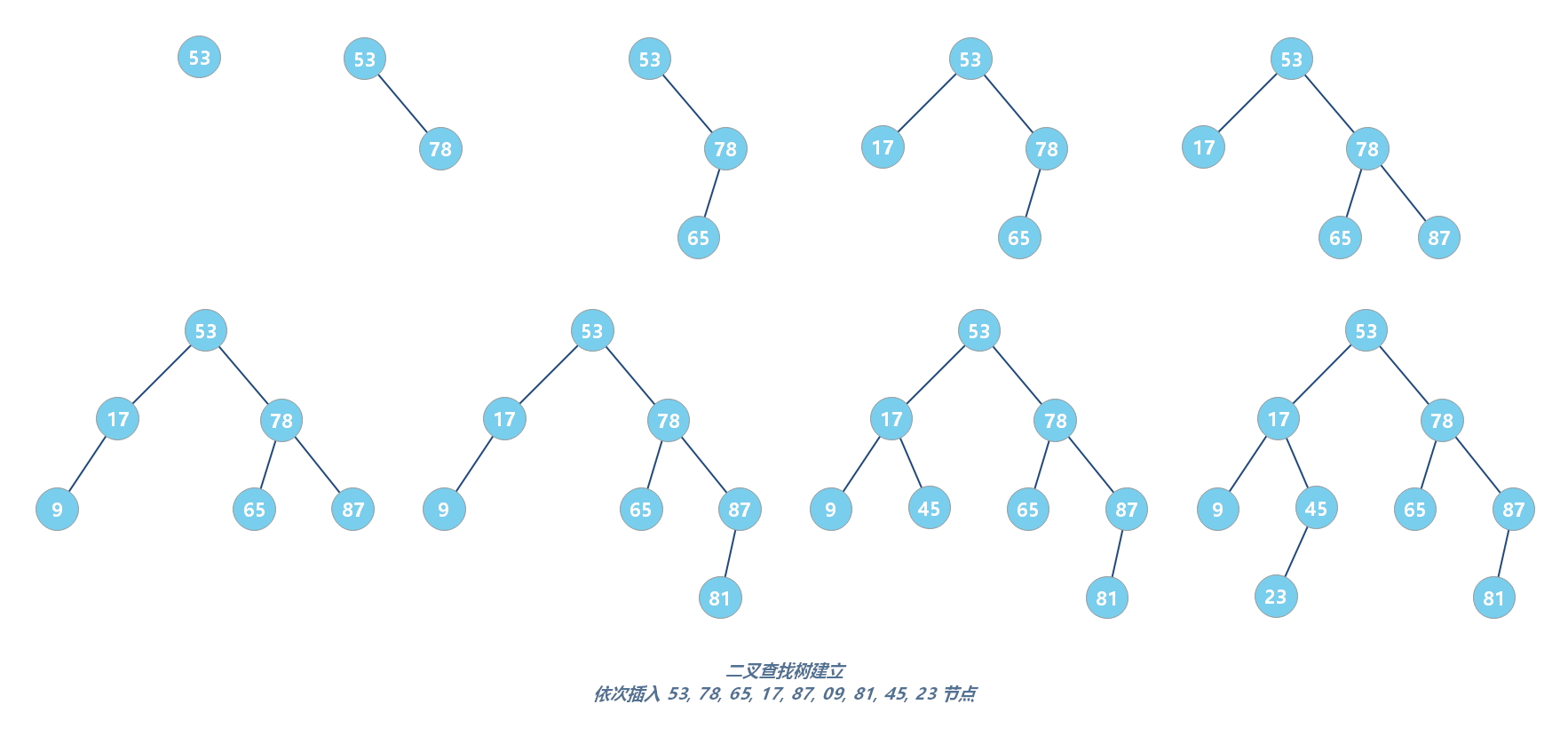
二叉查找树的插入
如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位置;如果不为空,就再递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点数值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;如果不为空,就再递归遍历左子树,查找插入位置。
二叉查找树的删除
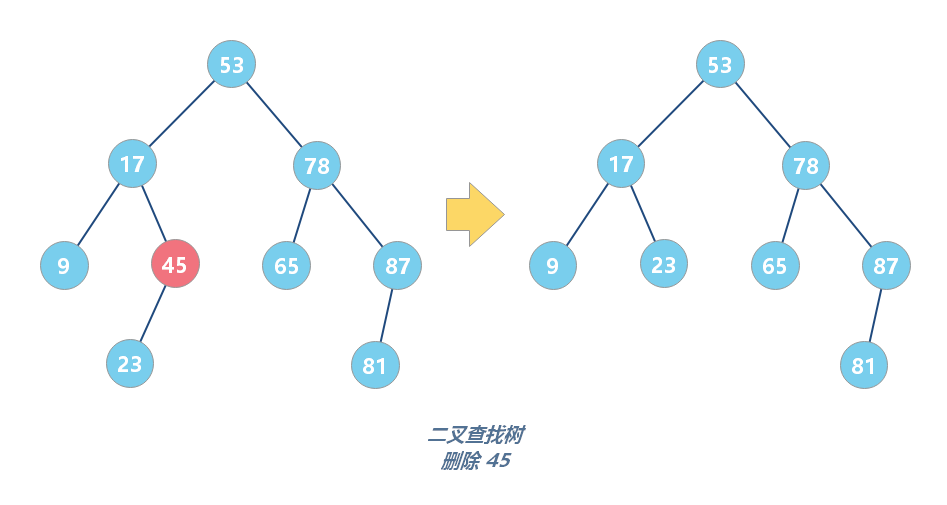
第一种情况是,如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为 null。
第二种情况是,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。
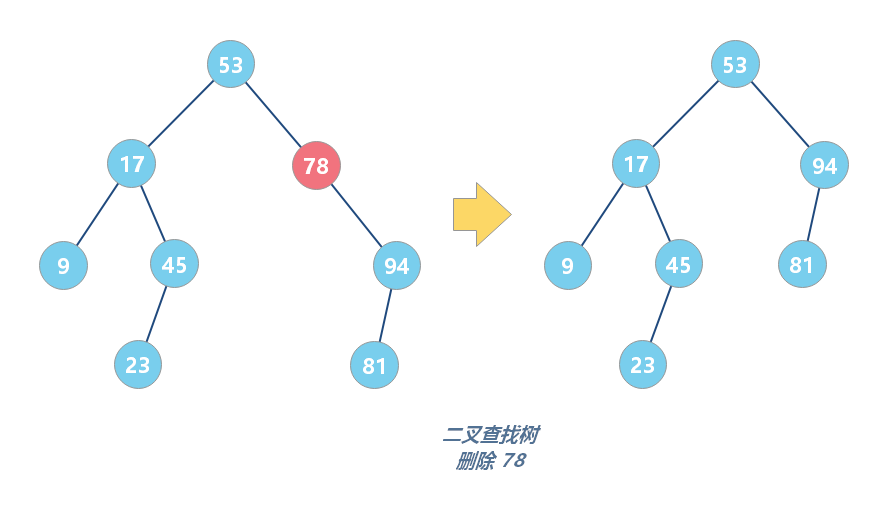
第三种情况是,如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。
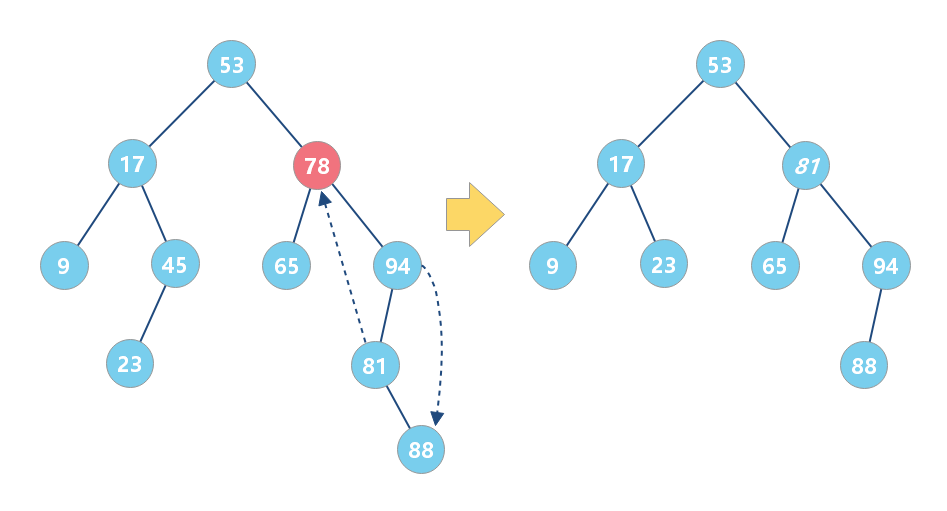
二叉查找树的时间复杂度
不管操作是插入、删除还是查找,**时间复杂度其实都跟树的高度成正比,也就是 O(log n)**。
二叉查找树的形态各式各样。比如这个图中,对于同一组数据,我们构造了三种二叉查找树。它们的查找、插入、删除操作的执行效率都是不一样的。图中第一种二叉查找树,根节点的左右子树极度不平衡,已经退化成了链表,所以查找的时间复杂度就变成了 O(n)。
为什么需要二叉查找树
第一,哈希表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,哈希表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
第三,笼统地来说,尽管哈希表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
第四,哈希表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
最后,为了避免过多的散列冲突,哈希表装载因子不能太大,特别是基于开放寻址法解决冲突的哈希表,不然会浪费一定的存储空间。