Flink 架构
Flink 架构
Flink 的部署
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink 用户报告了其生产环境中一些令人印象深刻的扩展性数字
- 处理每天处理数万亿的事件,
- 应用维护几 TB 大小的状态
- 应用在数千个内核上运行
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
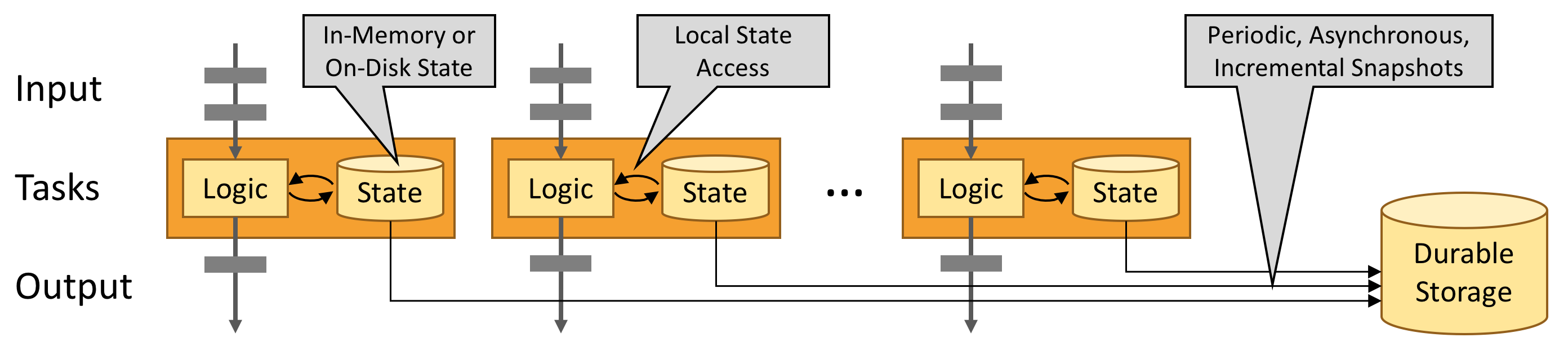
Flink 集群剖析
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 **TaskManager**。

Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(_分离模式_),或保持连接来接收进程报告(_附加模式_)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程 ./bin/flink run ... 中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为 standalone 集群启动、在容器中启动、或者通过 YARN 等资源框架管理并启动。TaskManager 连接到 JobManager,宣布自己可用,并被分配工作。
JobManager
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责,它决定
- 何时调度下一个 task(或一组 task)
- 对完成的 task 或执行失败做出反应
- 协调 checkpoint
- 协调从失败中恢复
- 等等
JobManager 由三个不同的组件组成:
ResourceManager:负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考 TaskManager。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
Dispatcher:提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
JobMaster:负责管理单个 JobGraph 的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 _leader_,其他的则是 _standby_(请参考 高可用(HA))。
TaskManager
_TaskManager_(也称为 _worker_)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task _slot_。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(请参考Tasks 和算子链)。
Tasks 和算子链
对于分布式执行,Flink 将算子的 subtasks 链接成 _tasks_。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的;请参考链文档以获取详细信息。
下图中样例数据流用 5 个 subtask 执行,因此有 5 个并行线程。

Task Slots 和资源
每个 worker(TaskManager)都是一个 _JVM 进程_,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。

默认情况下,Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。允许 slot 共享有两个主要优点:
- Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(_source/map()_)将阻塞和密集型 subtask(_window_) 一样多的资源。通过 slot 共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的 subtask 在 TaskManager 之间公平分配。

Flink 应用程序执行
Flink 应用程序 是从其 main() 方法产生的一个或多个 Flink 作业的任何用户程序。这些作业的执行可以在本地 JVM(LocalEnvironment)中进行,或具有多台机器的集群的远程设置(RemoteEnvironment)中进行。对于每个程序,ExecutionEnvironment 提供了一些方法来控制作业执行(例如设置并行度)并与外界交互(请参考 Flink 程序剖析 )。
Flink 应用程序的作业可以被提交到长期运行的 Flink Session 集群、专用的 Flink Job 集群 或 Flink Application 集群。这些选项之间的差异主要与集群的生命周期和资源隔离保证有关。
Flink Session 集群 #
- 集群生命周期:在 Flink Session 集群中,客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止 session 为止。因此,Flink Session 集群的寿命不受任何 Flink 作业寿命的约束。
- 资源隔离:TaskManager slot 由 ResourceManager 在提交作业时分配,并在作业完成时释放。由于所有作业都共享同一集群,因此在集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽。此共享设置的局限性在于,如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业。
- 其他注意事项:拥有一个预先存在的集群可以节省大量时间申请资源和启动 TaskManager。有种场景很重要,作业执行时间短并且启动时间长会对端到端的用户体验产生负面的影响 — 就像对简短查询的交互式分析一样,希望作业可以使用现有资源快速执行计算。
以前,Flink Session 集群也被称为 session 模式下的 Flink 集群。
Flink Job 集群 #
- 集群生命周期:在 Flink Job 集群中,可用的集群管理器(例如 YARN)用于为每个提交的作业启动一个集群,并且该集群仅可用于该作业。在这里,客户端首先从集群管理器请求资源启动 JobManager,然后将作业提交给在这个进程中运行的 Dispatcher。然后根据作业的资源请求惰性的分配 TaskManager。一旦作业完成,Flink Job 集群将被拆除。
- 资源隔离:JobManager 中的致命错误仅影响在 Flink Job 集群中运行的一个作业。
- 其他注意事项:由于 ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源,因此 Flink Job 集群更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
以前,Flink Job 集群也被称为 job (or per-job) 模式下的 Flink 集群。
Kubernetes 不支持 Flink Job 集群。 请参考 Standalone Kubernetes 和 Native Kubernetes。
Flink Application 集群 #
- 集群生命周期:Flink Application 集群是专用的 Flink 集群,仅从 Flink 应用程序执行作业,并且
main()方法在集群上而不是客户端上运行。提交作业是一个单步骤过程:无需先启动 Flink 集群,然后将作业提交到现有的 session 集群;相反,将应用程序逻辑和依赖打包成一个可执行的作业 JAR 中,并且集群入口(ApplicationClusterEntryPoint)负责调用main()方法来提取 JobGraph。例如,这允许你像在 Kubernetes 上部署任何其他应用程序一样部署 Flink 应用程序。因此,Flink Application 集群的寿命与 Flink 应用程序的寿命有关。 - 资源隔离:在 Flink Application 集群中,ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。
Flink Job 集群可以看做是 Flink Application 集群”客户端运行“的替代方案。
Flink 高可用
默认情况下,每个 Flink 集群只有一个 JobManager 实例。这会导致 _单点故障(SPOF)_:如果 JobManager 崩溃,则不能提交任何新程序,运行中的程序也会失败。
使用 JobManager 高可用模式,你可以从 JobManager 失败中恢复,从而消除单点故障。
如何启用集群高可用
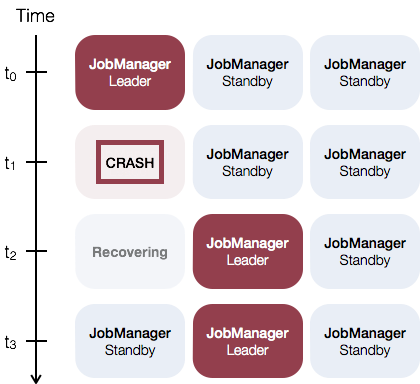
JobManager 高可用是指,在任何时候都有一个 JobManager Leader,如果 Leader 出现故障,则有多个备用 JobManager 来接管领导。这解决了单点故障问题,只要有备用 JobManager 担任领导者,程序就可以继续运行。
如下是一个使用三个 JobManager 实例的例子:
Flink 的 高可用服务 封装了所需的服务,使一切可以正常工作:
- 领导者选举:从
n个候选者中选出一个领导者 - 服务发现:检索当前领导者的地址
- 状态持久化:继承程序恢复作业所需的持久化状态(JobGraphs、用户代码 jar、已完成的检查点)
Flink 高可用服务
Flink 提供了两种高可用服务实现:
- ZooKeeper:每个 Flink 集群部署都可以使用 ZooKeeper HA 服务。它们需要一个运行的 ZooKeeper 复制组(quorum)。
- Kubernetes:Kubernetes HA 服务只能运行在 Kubernetes 上。
高可用数据生命周期
为了恢复提交的作业,Flink 持久化元数据和 job 组件。高可用数据将一直保存,直到相应的作业执行成功、被取消或最终失败。当这些情况发生时,将删除所有高可用数据,包括存储在高可用服务中的元数据。