源码级深度理解 Java SPI SPI 简介 SPI 全称 Service Provider Interface,是 Java 提供的,旨在由第三方实现或扩展的 API,它是一种用于动态加载服务的机制。Java 中 SPI 机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦 。
Java SPI 有四个要素:
SPI 接口 :为服务提供者实现类约定的的接口或抽象类。SPI 实现类 :实际提供服务的实现类。SPI 配置 :Java SPI 机制约定的配置文件,提供查找服务实现类的逻辑。配置文件必须置于 META-INF/services 目录中,并且,文件名应与服务提供者接口的完全限定名保持一致。文件中的每一行都有一个实现服务类的详细信息,同样是服务提供者类的完全限定名称。**ServiceLoader**:Java SPI 的核心类,用于加载 SPI 实现类。 ServiceLoader 中有各种实用方法来获取特定实现、迭代它们或重新加载服务。
SPI 示例 正所谓,实践出真知,我们不妨通过一个具体的示例来看一下,如何使用 Java SPI。
SPI 接口 首先,需要定义一个 SPI 接口,和普通接口并没有什么差别。
1 2 3 4 5 package io.github.dunwu.javacore.spi;public interface DataStorage { String search (String key) ; }
SPI 实现类 假设,我们需要在程序中使用两种不同的数据存储——Mysql 和 Redis。因此,我们需要两个不同的实现类去分别完成相应工作。
Mysql 查询 MOCK 类
1 2 3 4 5 6 7 8 package io.github.dunwu.javacore.spi;public class MysqlStorage implements DataStorage { @Override public String search (String key) { return "【Mysql】搜索" + key + ",结果:No" ; } }
Redis 查询 MOCK 类
1 2 3 4 5 6 7 8 package io.github.dunwu.javacore.spi;public class RedisStorage implements DataStorage { @Override public String search (String key) { return "【Redis】搜索" + key + ",结果:Yes" ; } }
到目前为止,定义接口,并实现接口和普通的 Java 接口实现没有任何不同。
SPI 配置 如果想通过 Java SPI 机制来发现服务,就需要在 SPI 配置中约定好发现服务的逻辑。配置文件必须置于 META-INF/services 目录中,并且,文件名应与服务提供者接口的完全限定名保持一致。文件中的每一行都有一个实现服务类的详细信息,同样是服务提供者类的完全限定名称。以本示例代码为例,其文件名应该为 io.github.dunwu.javacore.spi.DataStorage,文件中的内容如下:
1 2 io.github .dunwu .javacore .spi .MysqlStorage io.github .dunwu .javacore .spi .RedisStorage
ServiceLoader 完成了上面的步骤,就可以通过 ServiceLoader 来加载服务。示例如下:
1 2 3 4 5 6 7 8 9 10 11 import java.util.ServiceLoader;public class SpiDemo { public static void main (String[] args) { ServiceLoader<DataStorage> serviceLoader = ServiceLoader.load(DataStorage.class); System.out.println("============ Java SPI 测试============" ); serviceLoader.forEach(loader -> System.out.println(loader.search("Yes Or No" ))); } }
输出:
1 2 3 = = = = = = = = = = = = Java SPI 测试= = = = = = = = = = = = 【Mysql】搜索Yes Or No,结果:No 【Redis】搜索Yes Or No,结果:Yes
SPI 原理 上文中,我们已经了解 Java SPI 的要素以及使用 Java SPI 的方法。你有没有想过,Java SPI 和普通 Java 接口有何不同,Java SPI 是如何工作的。实际上,Java SPI 机制依赖于 ServiceLoader 类去解析、加载服务。因此,掌握了 ServiceLoader 的工作流程,就掌握了 SPI 的原理。ServiceLoader 的代码本身很精练,接下来,让我们通过走读源码的方式,逐一理解 ServiceLoader 的工作流程。
ServiceLoader 的成员变量 先看一下 ServiceLoader 类的成员变量,大致有个印象,后面的源码中都会使用到。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public final class ServiceLoader <S> implements Iterable <S> { private static final String PREFIX = "META-INF/services/" ; private final Class<S> service; private final ClassLoader loader; private final AccessControlContext acc; private LinkedHashMap<String,S> providers = new LinkedHashMap <>(); private LazyIterator lookupIterator; }
ServiceLoader 的工作流程 (1)ServiceLoader.load 静态方法
应用程序加载 Java SPI 服务,都是先调用 ServiceLoader.load 静态方法。ServiceLoader.load 静态方法的作用是:
指定类加载 ClassLoader 和访问控制上下文;
然后,重新加载 SPI 服务
清空缓存中所有已实例化的 SPI 服务
根据 ClassLoader 和 SPI 类型,创建懒加载迭代器
这里,摘录 ServiceLoader.load 相关源码,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static <S> ServiceLoader<S> load (Class<S> service, ClassLoader loader) { return new ServiceLoader <>(service, loader); } public void reload () { providers.clear(); lookupIterator = new LazyIterator (service, loader); } private ServiceLoader (Class<S> svc, ClassLoader cl) { service = Objects.requireNonNull(svc, "Service interface cannot be null" ); loader = (cl == null ) ? ClassLoader.getSystemClassLoader() : cl; acc = (System.getSecurityManager() != null ) ? AccessController.getContext() : null ; reload(); }
(2)应用程序通过 ServiceLoader 的 iterator 方法遍历 SPI 实例
ServiceLoader 的类定义,明确了 ServiceLoader 类实现了 Iterable<T> 接口,所以,它是可以迭代遍历的。实际上,ServiceLoader 类维护了一个缓存 providers( LinkedHashMap 对象),缓存 providers 中保存了已经被成功加载的 SPI 实例,这个 Map 的 key 是 SPI 接口实现类的全限定名,value 是该实现类的一个实例对象。
当应用程序调用 ServiceLoader 的 iterator 方法时,ServiceLoader 会先判断缓存 providers 中是否有数据:如果有,则直接返回缓存 providers 的迭代器;如果没有,则返回懒加载迭代器的迭代器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public Iterator<S> iterator () { return new Iterator <S>() { Iterator<Map.Entry<String,S>> knownProviders = providers.entrySet().iterator(); public boolean hasNext () { if (knownProviders.hasNext()) return true ; return lookupIterator.hasNext(); } public S next () { if (knownProviders.hasNext()) return knownProviders.next().getValue(); return lookupIterator.next(); } public void remove () { throw new UnsupportedOperationException (); } }; }
(3)懒加载迭代器的工作流程
上面的源码中提到了,lookupIterator 是 LazyIterator 实例,而 LazyIterator 用于懒加载 SPI 实例。那么, LazyIterator 是如何工作的呢?
这里,摘取 LazyIterator 关键代码
hasNextService 方法:
拼接 META-INF/services/ + SPI 接口全限定名
通过类加载器,尝试加载资源文件
解析资源文件中的内容,获取 SPI 接口的实现类的全限定名 nextName
nextService 方法:
hasNextService() 方法解析出了 SPI 实现类的的全限定名 nextName,通过反射,获取 SPI 实现类的类定义 Class<?>。然后,尝试通过 Class<?> 的 newInstance 方法实例化一个 SPI 服务对象。如果成功,则将这个对象加入到缓存 providers 中并返回该对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 private boolean hasNextService () { if (nextName != null ) { return true ; } if (configs == null ) { try { String fullName = PREFIX + service.getName(); if (loader == null ) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); } catch (IOException x) { fail(service, "Error locating configuration files" , x); } } while ((pending == null ) || !pending.hasNext()) { if (!configs.hasMoreElements()) { return false ; } pending = parse(service, configs.nextElement()); } nextName = pending.next(); return true ; } private S nextService () { if (!hasNextService()) throw new NoSuchElementException (); String cn = nextName; nextName = null ; Class<?> c = null ; try { c = Class.forName(cn, false , loader); } catch (ClassNotFoundException x) { fail(service, "Provider " + cn + " not found" ); } if (!service.isAssignableFrom(c)) { fail(service, "Provider " + cn + " not a s" ); } try { S p = service.cast(c.newInstance()); providers.put(cn, p); return p; } catch (Throwable x) { fail(service, "Provider " + cn + " could not be instantiated" , x); } throw new Error (); }
SPI 和类加载器 通过上面两个章节中,走读 ServiceLoader 代码,我们已经大致了解 Java SPI 的工作原理,即通过 ClassLoader 加载 SPI 配置文件,解析 SPI 服务,然后通过反射,实例化 SPI 服务实例。我们不妨思考一下,为什么加载 SPI 服务时,需要指定类加载器 ClassLoader 呢?
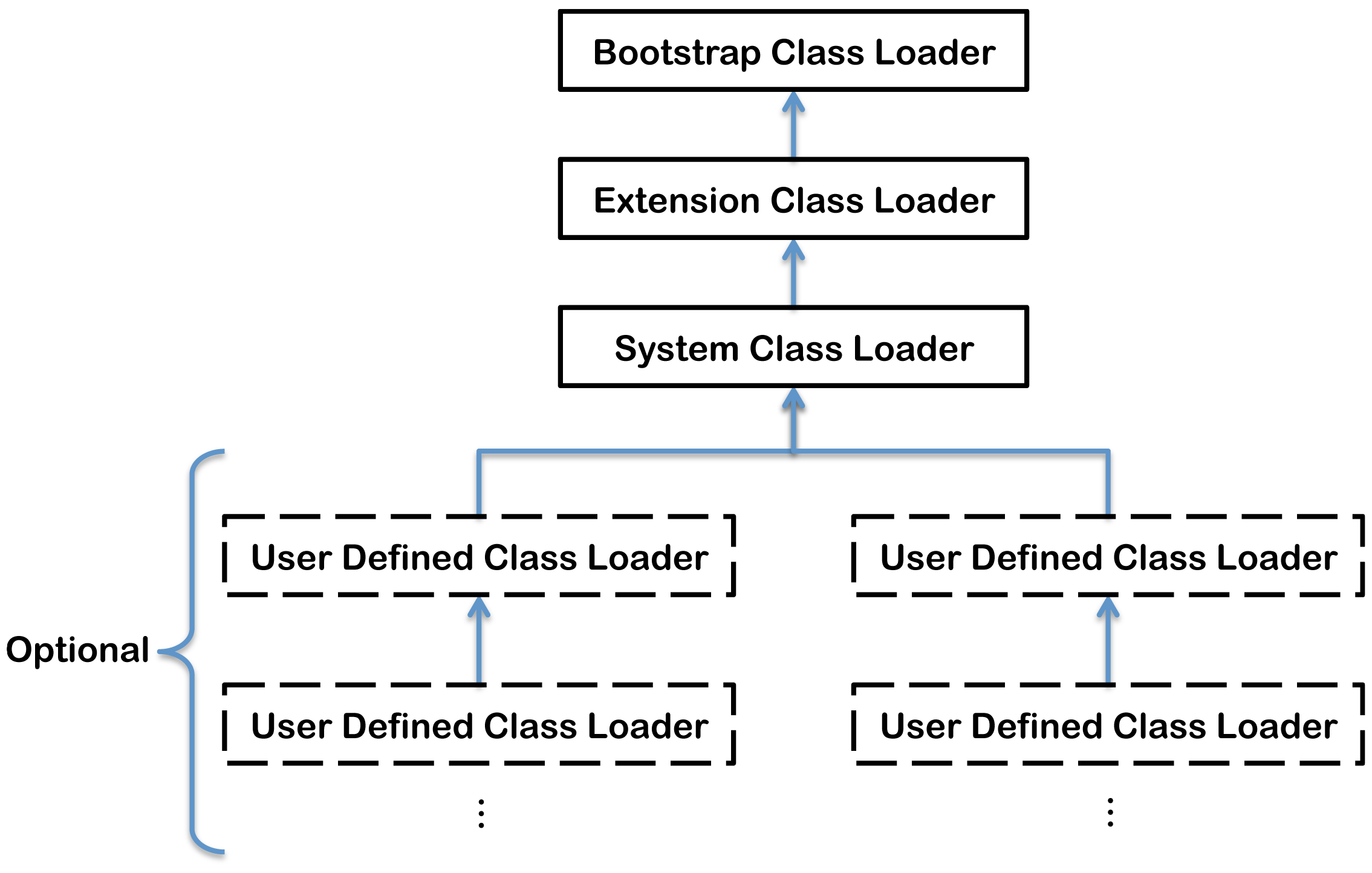
学习过 JVM 的读者,想必都了解过类加载器的双亲委派模型(Parents Delegation Model) 。双亲委派模型要求除了顶层的 BootstrapClassLoader
双亲委派机制约定了:一个类加载器首先将类加载请求传送到父类加载器,只有当父类加载器无法完成类加载请求时才尝试加载 。
双亲委派的好处 :使得 Java 类伴随着它的类加载器,天然具备一种带有优先级的层次关系,从而使得类加载得到统一,不会出现重复加载的问题:
系统类防止内存中出现多份同样的字节码
保证 Java 程序安全稳定运行
例如: java.lang.Object 存放在 rt.jar 中,如果编写另外一个 java.lang.Object 的类并放到 classpath 中,程序可以编译通过。因为双亲委派模型的存在,所以在 rt.jar 中的 Object 比在 classpath 中的 Object 优先级更高,因为 rt.jar 中的 Object 使用的是启动类加载器,而 classpath 中的 Object 使用的是应用程序类加载器。正因为 rt.jar 中的 Object 优先级更高,因为程序中所有的 Object 都是这个 Object。
双亲委派的限制 :子类加载器可以使用父类加载器已经加载的类,而父类加载器无法使用子类加载器已经加载的。——这就导致了双亲委派模型并不能解决所有的类加载器问题。Java SPI 就面临着这样的问题:
SPI 的接口是 Java 核心库的一部分,是由 BootstrapClassLoader 加载的;
而 SPI 实现的 Java 类一般是由 AppClassLoader 来加载的。BootstrapClassLoader 是无法找到 SPI 的实现类的,因为它只加载 Java 的核心库。它也不能代理给 AppClassLoader,因为它是最顶层的类加载器。这也解释了本节开始的问题——为什么加载 SPI 服务时,需要指定类加载器 ClassLoader 呢?因为如果不指定 ClassLoader,则无法获取 SPI 服务。
如果不做任何的设置,Java 应用的线程的上下文类加载器默认就是 AppClassLoader。在核心类库使用 SPI 接口时,传递的类加载器使用线程上下文类加载器,就可以成功的加载到 SPI 实现的类。线程上下文类加载器在很多 SPI 的实现中都会用到。
通常可以通过 Thread.currentThread().getClassLoader() 和 Thread.currentThread().getContextClassLoader() 获取线程上下文类加载器。
Java SPI 的不足 Java SPI 存在一些不足:
不能按需加载,需要遍历所有的实现,并实例化,然后在循环中才能找到我们需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。
获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。
多个并发多线程使用 ServiceLoader 类的实例是不安全的。
SPI 应用场景 SPI 在 Java 开发中应用十分广泛。首先,在 Java 的 java.util.spi package 中就约定了很多 SPI 接口。下面,列举一些 SPI 接口:
除此以外,SPI 还有很多应用,下面列举几个经典案例。
SPI 应用案例之 JDBC DriverManager 作为 Java 工程师,尤其是 CRUD 工程师,相必都非常熟悉 JDBC。众所周知,关系型数据库有很多种,如:Mysql、Oracle、PostgreSQL 等等。JDBC 如何识别各种数据库的驱动呢?
创建数据库连接 我们先回顾一下,JDBC 如何创建数据库连接的呢?
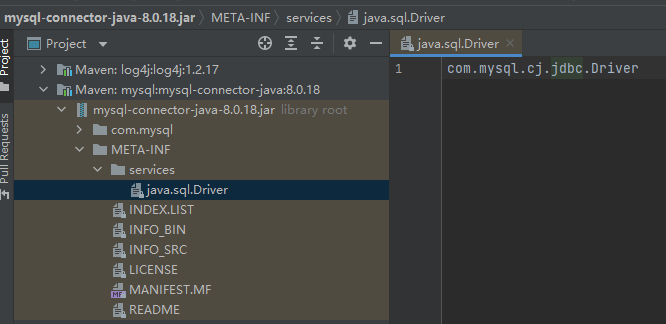
在 JDBC4.0 之前 ,连接数据库的时候,通常会用 Class.forName(XXX)
1 Class.forName("com.mysql.jdbc.Driver" )
而 JDBC4.0 之后 ,不再需要用 Class.forName(XXX)
DriverManager 从前文,我们已经知道 DriverManager 是创建数据库连接的关键。它究竟是如何工作的呢?
可以看到是加载实例化驱动的,接着看 loadInitialDrivers 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 private static void loadInitialDrivers () { String drivers; try { drivers = AccessController.doPrivileged(new PrivilegedAction <String>() { public String run () { return System.getProperty("jdbc.drivers" ); } }); } catch (Exception ex) { drivers = null ; } AccessController.doPrivileged(new PrivilegedAction <Void>() { public Void run () { ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); Iterator<Driver> driversIterator = loadedDrivers.iterator(); try { while (driversIterator.hasNext()) { driversIterator.next(); } } catch (Throwable t) { } return null ; } }); println("DriverManager.initialize: jdbc.drivers = " + drivers); if (drivers == null || drivers.equals("" )) { return ; } String[] driversList = drivers.split(":" ); println("number of Drivers:" + driversList.length); for (String aDriver : driversList) { try { println("DriverManager.Initialize: loading " + aDriver); Class.forName(aDriver, true , ClassLoader.getSystemClassLoader()); } catch (Exception ex) { println("DriverManager.Initialize: load failed: " + ex); } } }
上面的代码主要步骤是:
从系统变量中获取驱动的实现类。
利用 SPI 来获取所有驱动的实现类。
遍历所有驱动,尝试实例化各个实现类。
根据第 1 步获取到的驱动列表来实例化具体的实现类。
需要关注的是下面这行代码:
1 ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
这里实际获取的是 java.util.ServiceLoader.LazyIterator 迭代器。调用其 hasNext 方法时,会搜索 classpath 下以及 jar 包中的 META-INF/services 目录,查找 java.sql.Driver 文件,并找到文件中的驱动实现类的全限定名。调用其 next 方法时,会根据驱动类的全限定名去尝试实例化一个驱动类的对象。
SPI 应用案例之 Common-Logging common-logging(也称 Jakarta Commons Logging,缩写 JCL)是常用的日志门面工具包。
common-logging 的核心类是入口是 LogFactory,LogFatory 是一个抽象类,它负责加载具体的日志实现。
其入口方法是 LogFactory.getLog 方法,源码如下:
1 2 3 4 5 6 7 public static Log getLog (Class clazz) throws LogConfigurationException { return getFactory().getInstance(clazz); } public static Log getLog (String name) throws LogConfigurationException { return getFactory().getInstance(name); }
从以上源码可知,getLog 采用了工厂设计模式,是先调用 getFactory 方法获取具体日志库的工厂类,然后根据类名称或类型创建日志实例。
LogFatory.getFactory 方法负责选出匹配的日志工厂,其源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 public static LogFactory getFactory () throws LogConfigurationException { Properties props = getConfigurationFile(contextClassLoader, FACTORY_PROPERTIES); if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] Looking for system property [" + FACTORY_PROPERTY + "] to define the LogFactory subclass to use..." ); } try { String factoryClass = getSystemProperty(FACTORY_PROPERTY, null ); if (factoryClass != null ) { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] Creating an instance of LogFactory class '" + factoryClass + "' as specified by system property " + FACTORY_PROPERTY); } factory = newFactory(factoryClass, baseClassLoader, contextClassLoader); } else { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] No system property [" + FACTORY_PROPERTY + "] defined." ); } } } catch (SecurityException e) { } catch (RuntimeException e) { } if (factory == null ) { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] Looking for a resource file of name [" + SERVICE_ID + "] to define the LogFactory subclass to use..." ); } try { final InputStream is = getResourceAsStream(contextClassLoader, SERVICE_ID); if ( is != null ) { BufferedReader rd; try { rd = new BufferedReader (new InputStreamReader (is, "UTF-8" )); } catch (java.io.UnsupportedEncodingException e) { rd = new BufferedReader (new InputStreamReader (is)); } String factoryClassName = rd.readLine(); rd.close(); if (factoryClassName != null && ! "" .equals(factoryClassName)) { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] Creating an instance of LogFactory class " + factoryClassName + " as specified by file '" + SERVICE_ID + "' which was present in the path of the context classloader." ); } factory = newFactory(factoryClassName, baseClassLoader, contextClassLoader ); } } else { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] No resource file with name '" + SERVICE_ID + "' found." ); } } } catch (Exception ex) { if (isDiagnosticsEnabled()) { logDiagnostic( "[LOOKUP] A security exception occurred while trying to create an" + " instance of the custom factory class" + ": [" + trim(ex.getMessage()) + "]. Trying alternative implementations..." ); } } } if (factory == null ) { if (props != null ) { if (isDiagnosticsEnabled()) { logDiagnostic( "[LOOKUP] Looking in properties file for entry with key '" + FACTORY_PROPERTY + "' to define the LogFactory subclass to use..." ); } String factoryClass = props.getProperty(FACTORY_PROPERTY); if (factoryClass != null ) { if (isDiagnosticsEnabled()) { logDiagnostic( "[LOOKUP] Properties file specifies LogFactory subclass '" + factoryClass + "'" ); } factory = newFactory(factoryClass, baseClassLoader, contextClassLoader); } else { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] Properties file has no entry specifying LogFactory subclass." ); } } } else { if (isDiagnosticsEnabled()) { logDiagnostic("[LOOKUP] No properties file available to determine" + " LogFactory subclass from.." ); } } } if (factory == null ) { if (isDiagnosticsEnabled()) { logDiagnostic( "[LOOKUP] Loading the default LogFactory implementation '" + FACTORY_DEFAULT + "' via the same classloader that loaded this LogFactory" + " class (ie not looking in the context classloader)." ); } factory = newFactory(FACTORY_DEFAULT, thisClassLoader, contextClassLoader); } if (factory != null ) { cacheFactory(contextClassLoader, factory); if (props != null ) { Enumeration names = props.propertyNames(); while (names.hasMoreElements()) { String name = (String) names.nextElement(); String value = props.getProperty(name); factory.setAttribute(name, value); } } } return factory; }
从 getFactory 方法的源码可以看出,其核心逻辑分为 4 步:
首先,尝试查找全局属性 org.apache.commons.logging.LogFactory,如果指定了具体类,尝试创建实例。
利用 Java SPI 机制,尝试在 classpatch 的 META-INF/services 目录下寻找 org.apache.commons.logging.LogFactory 的实现类。
尝试从 classpath 目录下的 commons-logging.properties 文件中查找 org.apache.commons.logging.LogFactory 属性,如果指定了具体类,尝试创建实例。
以上情况如果都不满足,则实例化默认实现类,即 org.apache.commons.logging.impl.LogFactoryImpl。
SPI 应用案例之 Spring Boot Spring Boot 是基于 Spring 构建的框架,其设计目的在于简化 Spring 应用的配置、运行。在 Spring Boot 中,大量运用了自动装配来尽可能减少配置。
下面是一个 Spring Boot 入口示例,可以看到,代码非常简洁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;@SpringBootApplication @RestController public class DemoApplication { public static void main (String[] args) { SpringApplication.run(DemoApplication.class, args); } @GetMapping("/hello") public String hello (@RequestParam(value = "name", defaultValue = "World") String name) { return String.format("Hello %s!" , name); } }
那么,Spring Boot 是如何做到寥寥几行代码,就可以运行一个 Spring Boot 应用的呢。我们不妨带着疑问,从源码入手,一步步探究其原理。
@SpringBootApplication 注解首先,Spring Boot 应用的启动类上都会标记一个 @SpringBootApplication 注解。@SpringBootApplication 注解定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @SpringBootConfiguration @EnableAutoConfiguration @ComponentScan( excludeFilters = {@Filter( type = FilterType.CUSTOM, classes = {TypeExcludeFilter.class} ), @Filter( type = FilterType.CUSTOM, classes = {AutoConfigurationExcludeFilter.class} )} ) public @interface SpringBootApplication { }
除了 @Target、 @Retention、@Documented、@Inherited 这几个元注解, @SpringBootApplication 注解的定义中还标记了 @SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan 三个注解。
@SpringBootConfiguration 注解从@SpringBootConfiguration 注解的定义来看,@SpringBootConfiguration 注解本质上就是一个 @Configuration 注解,这意味着被@SpringBootConfiguration 注解修饰的类会被 Spring Boot 识别为一个配置类。
1 2 3 4 5 6 7 8 9 10 @Target ({ElementType.TYPE})@Retention (RetentionPolicy.RUNTIME)@Documented @Configuration public @interface SpringBootConfiguration { @AliasFor ( annotation = Configuration.class ) boolean proxyBeanMethods () default true; }
@EnableAutoConfiguration 注解@EnableAutoConfiguration 注解定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @AutoConfigurationPackage @Import({AutoConfigurationImportSelector.class}) public @interface EnableAutoConfiguration { String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration" ; Class<?>[] exclude() default {}; String[] excludeName() default {}; }
@EnableAutoConfiguration 注解包含了 @AutoConfigurationPackage 与 @Import({AutoConfigurationImportSelector.class}) 两个注解。
@AutoConfigurationPackage 注解@AutoConfigurationPackage 会将被修饰的类作为主配置类,该类所在的 package 会被视为根路径,Spring Boot 默认会自动扫描根路径下的所有 Spring Bean(被 @Component 以及继承 @Component 的各个注解所修饰的类)。——这就是为什么 Spring Boot 的启动类一般要置于根路径的原因。这个功能等同于在 Spring xml 配置中通过 context:component-scan 来指定扫描路径。@Import 注解的作用是向 Spring 容器中直接注入指定组件。@AutoConfigurationPackage 注解中注明了 @Import({Registrar.class})。Registrar 类用于保存 Spring Boot 的入口类、根路径等信息。
SpringFactoriesLoader.loadFactoryNames 方法@Import(AutoConfigurationImportSelector.class) 表示直接注入 AutoConfigurationImportSelector。AutoConfigurationImportSelector 有一个核心方法 getCandidateConfigurations 用于获取候选配置。该方法调用了 SpringFactoriesLoader.loadFactoryNames 方法,这个方法即为 Spring Boot SPI 的关键,它负责加载所有 META-INF/spring.factories 文件,加载的过程由 SpringFactoriesLoader 负责。
Spring Boot 的 META-INF/spring.factories 文件本质上就是一个 properties 文件,数据内容就是一个个键值对。
SpringFactoriesLoader.loadFactoryNames 方法的关键源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public static List<String> loadFactoryNames (Class<?> factoryType, @Nullable ClassLoader classLoader) { String factoryTypeName = factoryType.getName(); return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList()); } private static Map<String, List<String>> loadSpringFactories (@Nullable ClassLoader classLoader) { MultiValueMap<String, String> result = cache.get(classLoader); if (result != null ) { return result; } try { Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) : ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION)); result = new LinkedMultiValueMap <>(); while (urls.hasMoreElements()) { URL url = urls.nextElement(); UrlResource resource = new UrlResource (url); Properties properties = PropertiesLoaderUtils.loadProperties(resource); for (Map.Entry<?, ?> entry : properties.entrySet()) { String factoryTypeName = ((String) entry.getKey()).trim(); for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) { result.add(factoryTypeName, factoryImplementationName.trim()); } } } cache.put(classLoader, result); return result; } catch (IOException ex) { throw new IllegalArgumentException ("Unable to load factories from location [" + FACTORIES_RESOURCE_LOCATION + "]" , ex); } }
归纳上面的方法,主要作了这些事:
加载所有 META-INF/spring.factories 文件,加载过程有 SpringFactoriesLoader 负责。
在 CLASSPATH 中搜寻所有 META-INF/spring.factories 配置文件
然后,解析 spring.factories 文件,获取指定自动装配类的全限定名
Spring Boot 的 AutoConfiguration 类 Spring Boot 有各种 starter 包,可以根据实际项目需要,按需取材。在项目开发中,只要将 starter 包引入,我们就可以用很少的配置,甚至什么都不配置,即可获取相关的能力。通过前面的 Spring Boot SPI 流程,只完成了自动装配工作的一半,剩下的工作如何处理呢 ?
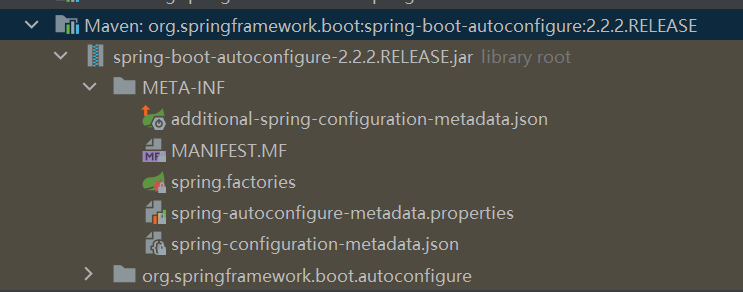
以 spring-boot-starter-web 的 jar 包为例,查看其 maven pom,可以看到,它依赖于 spring-boot-starter,所有 Spring Boot 官方 starter 包都会依赖于这个 jar 包。而 spring-boot-starter 又依赖于 spring-boot-autoconfigure,Spring Boot 的自动装配秘密,就在于这个 jar 包。
从 spring-boot-autoconfigure 包的结构来看,它有一个 META-INF/spring.factories ,显然利用了 Spring Boot SPI,来自动装配其中的配置类。
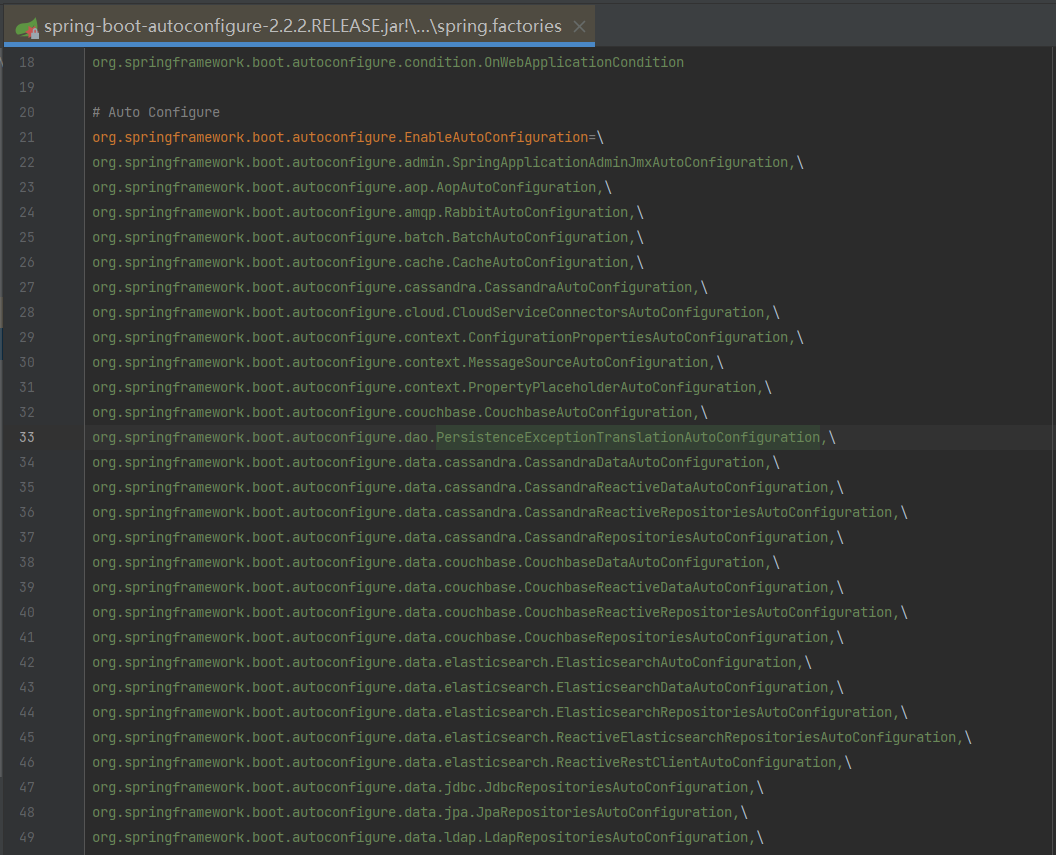
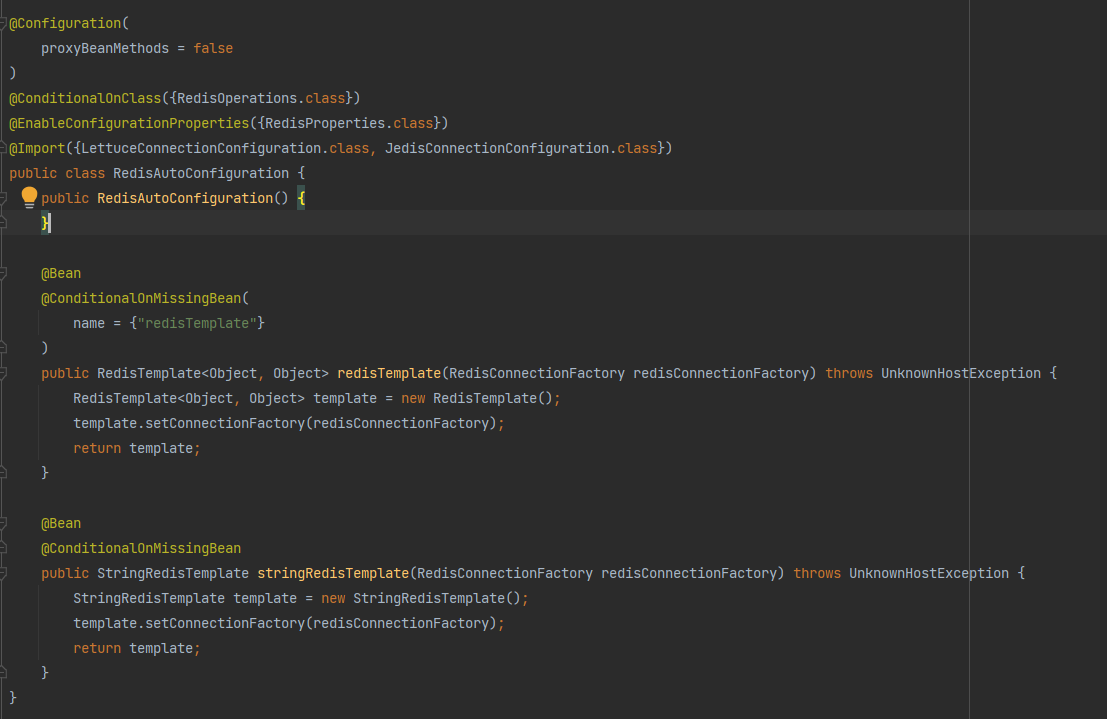
下图是 spring-boot-autoconfigure 的 META-INF/spring.factories 文件的部分内容,可以看到其中注册了一长串会被自动加载的 AutoConfiguration 类。
以 RedisAutoConfiguration 为例,这个配置类中,会根据 @ConditionalXXX 中的条件去决定是否实例化对应的 Bean,实例化 Bean 所依赖的重要参数则通过 RedisProperties 传入。
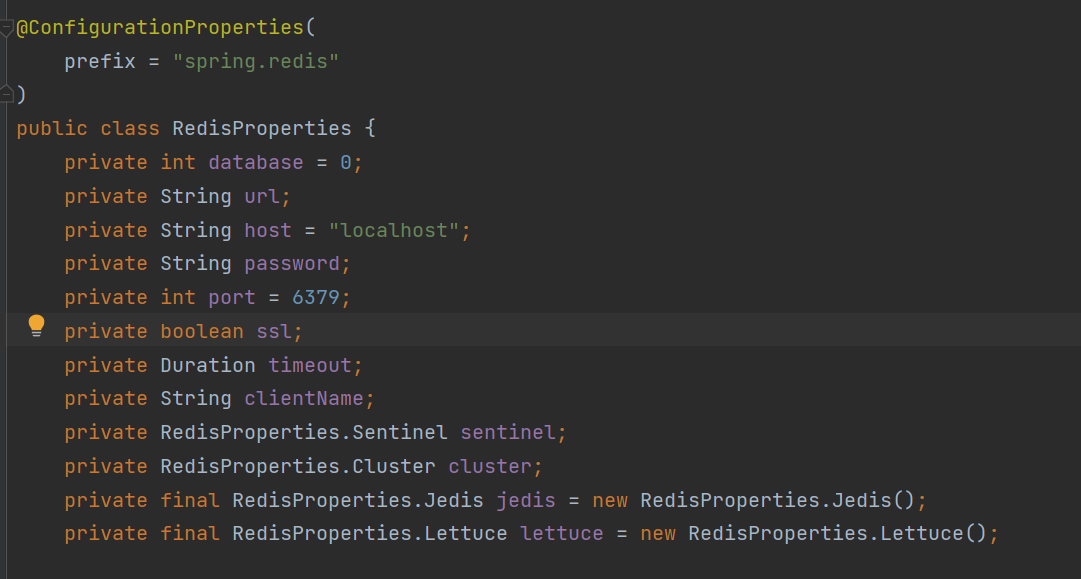
RedisProperties 中维护了 Redis 连接所需要的关键属性,只要在 yml 或 properties 配置文件中,指定 spring.redis 开头的属性,都会被自动装载到 RedisProperties 实例中。
通过以上分析,已经一步步解读出 Spring Boot 自动装载的原理。
SPI 应用案例之 Dubbo Dubbo 并未使用 Java SPI,而是自己封装了一套新的 SPI 机制。Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容形式如下:
1 2 optimusPrime = org.apache .spi .OptimusPrime bumblebee = org.apache .spi .Bumblebee
与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置 ,这样可以按需加载 指定的实现类。Dubbo SPI 除了支持按需加载接口实现类,还增加了 IOC 和 AOP 等特性。
ExtensionLoader 入口Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,可以加载指定的实现类。
ExtensionLoader 的 getExtension 方法是其入口方法,其源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public T getExtension (String name) { if (name == null || name.length() == 0 ) throw new IllegalArgumentException ("Extension name == null" ); if ("true" .equals(name)) { return getDefaultExtension(); } Holder<Object> holder = cachedInstances.get(name); if (holder == null ) { cachedInstances.putIfAbsent(name, new Holder <Object>()); holder = cachedInstances.get(name); } Object instance = holder.get(); if (instance == null ) { synchronized (holder) { instance = holder.get(); if (instance == null ) { instance = createExtension(name); holder.set(instance); } } } return (T) instance; }
可以看出,这个方法的作用就是:首先检查缓存,缓存未命中则调用 createExtension 方法创建拓展对象。那么,createExtension 是如何创建拓展对象的呢,其源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private T createExtension (String name) { Class<?> clazz = getExtensionClasses().get(name); if (clazz == null ) { throw findException(name); } try { T instance = (T) EXTENSION_INSTANCES.get(clazz); if (instance == null ) { EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance()); instance = (T) EXTENSION_INSTANCES.get(clazz); } injectExtension(instance); Set<Class<?>> wrapperClasses = cachedWrapperClasses; if (wrapperClasses != null && !wrapperClasses.isEmpty()) { for (Class<?> wrapperClass : wrapperClasses) { instance = injectExtension( (T) wrapperClass.getConstructor(type).newInstance(instance)); } } return instance; } catch (Throwable t) { throw new IllegalStateException ("..." ); } }
createExtension 方法的的工作步骤可以归纳为:
通过 getExtensionClasses 获取所有的拓展类
通过反射创建拓展对象
向拓展对象中注入依赖
将拓展对象包裹在相应的 Wrapper 对象中
以上步骤中,第一个步骤是加载拓展类的关键,第三和第四个步骤是 Dubbo IOC 与 AOP 的具体实现。
获取所有的拓展类 Dubbo 在通过名称获取拓展类之前,首先需要根据配置文件解析出拓展项名称到拓展类的映射关系表(Map<名称, 拓展类>),之后再根据拓展项名称从映射关系表中取出相应的拓展类即可。相关过程的代码分析如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private Map<String, Class<?>> getExtensionClasses() { Map<String, Class<?>> classes = cachedClasses.get(); if (classes == null ) { synchronized (cachedClasses) { classes = cachedClasses.get(); if (classes == null ) { classes = loadExtensionClasses(); cachedClasses.set(classes); } } } return classes; }
这里也是先检查缓存,若缓存未命中,则通过 synchronized 加锁。加锁后再次检查缓存,并判空。此时如果 classes 仍为 null,则通过 loadExtensionClasses 加载拓展类。下面分析 loadExtensionClasses 方法的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private Map<String, Class<?>> loadExtensionClasses() { final SPI defaultAnnotation = type.getAnnotation(SPI.class); if (defaultAnnotation != null ) { String value = defaultAnnotation.value(); if ((value = value.trim()).length() > 0 ) { String[] names = NAME_SEPARATOR.split(value); if (names.length > 1 ) { throw new IllegalStateException ("more than 1 default extension name on extension..." ); } if (names.length == 1 ) { cachedDefaultName = names[0 ]; } } } Map<String, Class<?>> extensionClasses = new HashMap <String, Class<?>>(); loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY); loadDirectory(extensionClasses, DUBBO_DIRECTORY); loadDirectory(extensionClasses, SERVICES_DIRECTORY); return extensionClasses; }
loadExtensionClasses 方法总共做了两件事情,一是对 SPI 注解进行解析,二是调用 loadDirectory 方法加载指定文件夹配置文件。SPI 注解解析过程比较简单,无需多说。下面我们来看一下 loadDirectory 做了哪些事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private void loadDirectory (Map<String, Class<?>> extensionClasses, String dir) { String fileName = dir + type.getName(); try { Enumeration<java.net.URL> urls; ClassLoader classLoader = findClassLoader(); if (classLoader != null ) { urls = classLoader.getResources(fileName); } else { urls = ClassLoader.getSystemResources(fileName); } if (urls != null ) { while (urls.hasMoreElements()) { java.net.URL resourceURL = urls.nextElement(); loadResource(extensionClasses, classLoader, resourceURL); } } } catch (Throwable t) { logger.error("..." ); } }
loadDirectory 方法先通过 classLoader 获取所有资源链接,然后再通过 loadResource 方法加载资源。我们继续跟下去,看一下 loadResource 方法的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 private void loadResource (Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) { try { BufferedReader reader = new BufferedReader ( new InputStreamReader (resourceURL.openStream(), "utf-8" )); try { String line; while ((line = reader.readLine()) != null ) { final int ci = line.indexOf('#' ); if (ci >= 0 ) { line = line.substring(0 , ci); } line = line.trim(); if (line.length() > 0 ) { try { String name = null ; int i = line.indexOf('=' ); if (i > 0 ) { name = line.substring(0 , i).trim(); line = line.substring(i + 1 ).trim(); } if (line.length() > 0 ) { loadClass(extensionClasses, resourceURL, Class.forName(line, true , classLoader), name); } } catch (Throwable t) { IllegalStateException e = new IllegalStateException ("Failed to load extension class..." ); } } } } finally { reader.close(); } } catch (Throwable t) { logger.error("Exception when load extension class..." ); } }
loadResource 方法用于读取和解析配置文件,并通过反射加载类,最后调用 loadClass 方法进行其他操作。loadClass 方法用于主要用于操作缓存,该方法的逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 private void loadClass (Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) throws NoSuchMethodException { if (!type.isAssignableFrom(clazz)) { throw new IllegalStateException ("..." ); } if (clazz.isAnnotationPresent(Adaptive.class)) { if (cachedAdaptiveClass == null ) { cachedAdaptiveClass = clazz; } else if (!cachedAdaptiveClass.equals(clazz)) { throw new IllegalStateException ("..." ); } } else if (isWrapperClass(clazz)) { Set<Class<?>> wrappers = cachedWrapperClasses; if (wrappers == null ) { cachedWrapperClasses = new ConcurrentHashSet <Class<?>>(); wrappers = cachedWrapperClasses; } wrappers.add(clazz); } else { clazz.getConstructor(); if (name == null || name.length() == 0 ) { name = findAnnotationName(clazz); if (name.length() == 0 ) { throw new IllegalStateException ("..." ); } } String[] names = NAME_SEPARATOR.split(name); if (names != null && names.length > 0 ) { Activate activate = clazz.getAnnotation(Activate.class); if (activate != null ) { cachedActivates.put(names[0 ], activate); } for (String n : names) { if (!cachedNames.containsKey(clazz)) { cachedNames.put(clazz, n); } Class<?> c = extensionClasses.get(n); if (c == null ) { extensionClasses.put(n, clazz); } else if (c != clazz) { throw new IllegalStateException ("..." ); } } } } }
如上,loadClass 方法操作了不同的缓存,比如 cachedAdaptiveClass、cachedWrapperClasses 和 cachedNames 等等。除此之外,该方法没有其他什么逻辑了。
参考资料