Kafka 流式处理
Kafka 流式处理
简介
什么是流式处理
数据流是无边界数据集的抽象表示。无边界意味着无限和持续增长。无边界数据集之所以是无限的,是因为随着时间的推移,新的记录会不断加入进来。
- 事件流是有序的。事件的发生总是有先后顺序。而数据库里的记录是无序的。
- 不可变的数据记录。事件一旦发生,就不能被改变。
- 事件流是可重播的。对于大多数业务来说,重播发生在几个月前(甚至几年前)的原始事件流是一个很重要的需求。可能是为了尝试使用新的分析方法纠正过去的错误,或是为了进行审计。如果没有这项能力,流式处理充其量只是数据科学实验室里的一个玩具而已。
流式处理是指实时地处理一个或多个事件流。流式处理是一种编程范式,就像请求与响应范式和批处理范式那样。
编程范式对比
- 请求与响应 - 这是延迟最小的一种范式,响应时间处于亚毫秒到毫秒之间,而且响应时间一般非常稳定。这种处理模式一般是阻塞的,应用程序向处理系统发出请求,然后等待响应。
- 批处理 - 这种范式具有高延迟和高吞吐量的特点。处理系统按照设定的时间启动处理进程,读取所有的输入数据(从上一次执行之后的所有可用数据,或者从月初开始的所有数据等),输出结果,然后等待下一次启动。处理时间从几分钟到几小时不等,并且用户从结果里读到的都是旧数据。一般用于 BI 生成分析报表。
- 流式处理 - 这种范式介于上述两者之间。大部分的业务不要求亚毫秒级的响应,不过也接受不了长时间的等待。大部分业务流程都是持续进行的,只要业务报告保持更新,业务产品线能够持续响应,那么业务流程就可以进行下去,而无需等待特定的响应,也不要求在几毫秒内得到响应。一些业务流程具有持续性和非阻塞的特点。
流的定义不依赖任何一个特定的框架、 API 或特性。只要持续地从一个无边界的数据集读取数据,然后对它们进行处理并生成结果,那就是在进行流式处理。重点是,整个处理过程必须是持续的。
流处理的核心概念
时间
时间或许是流式处理最为重要的概念。大部分流式应用的操作都是基于时间窗口的。有这么几个时间概念:
- 事件时间 - 事件时间是指所追踪事件的发生时间和记录的创建时间。
- 日志追加时间 - 日志追加时间是指事件保存到 broker 的时间。
- 处理时间 - 处理时间是指应用程序在收到事件之后要对其进行处理的时间。这个时间可以是在事件发生之后的几毫秒、几小时或几天。同一个事件可能会被分配不同的时间戳,这取决于应用程序何时读取这个事件。如果应用程序使用了两个线程来读取同一个事件,这个时间戳也会不一样!所以这个时间戳非常不可靠,应该避免使用它。
注意:在处理与时间有关的问题时,需要注意时区问题。整个数据管道应该使用同一个时区。
状态
如果只是单独处理每一个事件,那么流式处理就很简单。
如果操作里包含了多个事件,流式处理就会变得复杂而有趣。事件与事件之间的信息被称为状态。这些状态一般被保存在应用程序的本地变量里。
流式处理含以下几种状态:
- 本地状态或内部状态 - 这种状态只能被单个应用程序实例访问,它们一般使用内嵌在应用程序里的数据库进行维护和管理。本地状态的优势在于它的速度,不足之处在于它受到内存大小的限制 。 所以,流式处理的很多设计模式都将数据拆分到多个子流,这样就可以使用有限的本地状态来处理它们。
- 外部状态 - 这种状态使用外部的数据存储来维护,一般使用 NoSQL 系统,比如 Cassandra。大部分流式处理应用尽量避免使用外部存储,或者将信息缓存在本地,减少与外部存储发生交互,以此来降低延迟,而这就引入了如何维护内部和外部状态一致性的问题。
流和表
流是一系列事件,每个事件就是一个变更。表包含了当前的状态,是多个变更所产生的结果。所以说, 表和流是同一个硬币的两面,世界总是在发生变化,用户有时候关注变更事件,有时候则关注世界的当前状态。如果一个系统允许使用这两种方式来查看数据,那么它就比只支持一种方式的系统强大。
时间窗口
时间窗口有不同的类型,基于以下属性决定:
- 窗口的大小
- 窗口移动的频率
- 窗口的可更新时间多长
流处理的设计模式
单个事件处理
处理单个事件是流式处理最基本的模式。这个模式也叫 map 或 filter 模式,因为它经常被用于过滤无用的事件或者用于转换事件( map 这个术语是从 Map-Reduce 模式中来的, map 阶段转换事件, reduce 阶段聚合转换过的事件)。
在这种模式下,应用程序读取流中的事件 ,修改它们,然后把事件生成到另一个流上。
使用本地状态
大部分流式处理应用程序关心的是如何聚合信息,特别是基于时间窗口进行聚合。
要实现这些聚合操作,需要维护流的状态,可以通过本地状态(而不是共享状态)来实现。
如果流式处理应用包含了本地状态,会变得非常复杂,还需要解决下列问题:
- 内存使用 - 应用实例必须有可用的内存来保存本地状态。
- 持久化 - 要确保在应用程序关闭时不会丢失状态,并且在应用程序重启后或者切换到另一个应用实例时可以恢复状态。
- 再均衡 - 有时候,分区会被重新分配给不同的消费者。在这种情况下,失去分区的实例必须把最后的状态保存起来 , 同时获得分区的实例必须知道如何恢复到正确的状态。
多阶段处理和重分区
数据量不大的时候,可以使用本地状态。但面对海量的流数据时,可以使用多阶段处理(类似 Hadoop 的 map reduce)
流和表的连接
有些场景下,流式处理需要将外部数据和流集成在一起。
可以考虑将外部的数据信息(如数据库存储)缓存到流式处理应用程序里。
流和流的连接
有些场景下,需要连接两个真实的事件流。
将两个流里具有相同键和发生在相同时间窗口内的事件匹配起来。这就是为什么流和流的连接也叫作基于时间窗口的连接( windowed-join )。
乱序的事件
不管是对于流式处理还是传统的 ETL 系统来说,处理乱序事件都是一个挑战。
要让流处理应用程序处理好这些场景,需要做到以下几点:
- 识别乱序的事件。应用程序需要检查事件的时间,并将其与当前时间进行比较。
- 规定一个时间段用于重排乱序的事件。比如 3 个小时以内的事件可以重排,但 3 周以外的事件就可以直接扔掉。
- 具有在一定时间段内重排乱序事件的能力。这是流式处理应用与批处理作业的一个主要不同点。假设有一个每天运行的作业, 一些事件在作业结束之后才到达,那么可以重新运行昨天的作业来更新事件。而在流式处理中,“重新运行昨天的作业”这种情况是不存在的,乱序事件和新到达的事件必须一起处理。
- 具备更新结果的能力。如果处理的结果保存到数据库里,那么可以通过 put 或 update 对结果进行更新。如果流应用程序通过邮件发送结果,那么要对结果进行更新,就需要很巧妙的手段。
重新处理
有两种模式:
模式一:使用新版本应用处理同一个事件流,生成新的结果,并比较两种版本的结果,然后在某个时间点将客户端切换到新的结果流上。
模式二:重置应用,让应用回到输入流的起始位置开始处理,同时重置本地状态(这样就不会将两个版本应用的处理结果棍淆起来了),而且还可能需要清理之前的输出流。
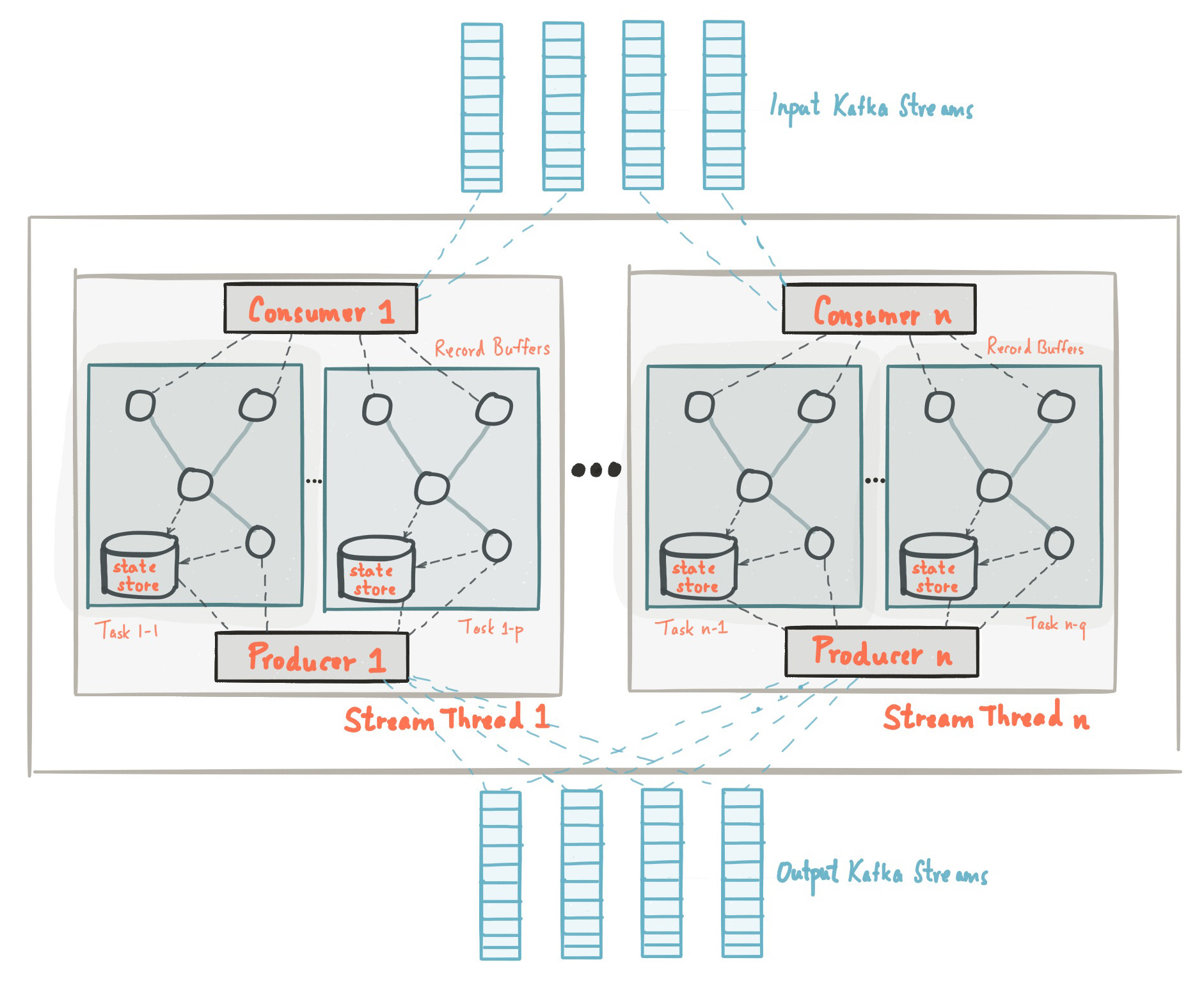
Kafka Streams 的架构
每个流式应用程序至少会实现和执行一个拓扑。拓扑(在其他流式处理框架里叫作 DAG,即有向无环图)是一个操作和变换的集合,每个事件从输入到输出都会流经它。
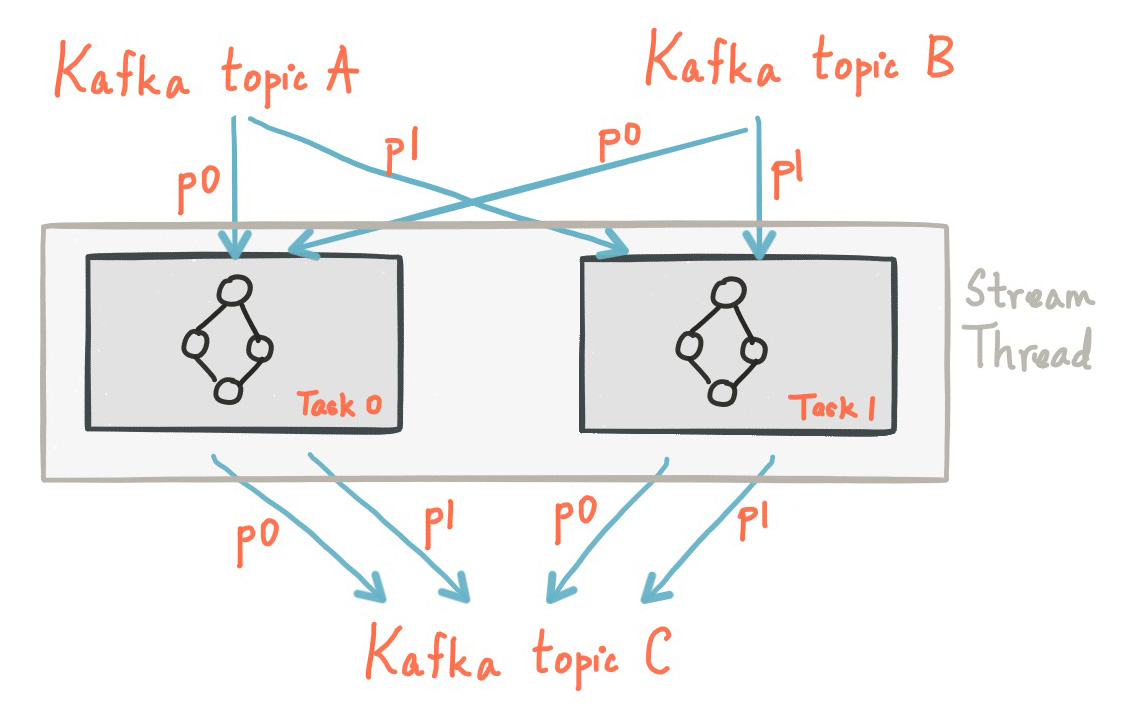
分区和任务
Kafka 的消息传递层对数据进行分区以进行存储和传输。 Kafka Streams 对数据进行分区以进行处理。Kafka Streams 使用分区和任务的概念作为基于 Kafka 主题分区的并行模型的逻辑单元。
每个流分区都是数据记录的完全有序序列,并映射到 Kafka 主题分区。流中的数据记录映射到该主题的 Kafka 消息。更具体地说,Kafka Streams 根据应用程序的输入流分区创建固定数量的任务,每个任务分配了输入流中的分区列表(即 Kafka 主题)。分区对任务的分配永远不会改变,因此每个任务都是应用程序并行性的固定单元。然后,任务可以根据分配的分区实例化其自己的处理器拓扑。它们还为其分配的每个分区维护一个缓冲区,并一次从这些记录缓冲区处理消息。结果,可以在没有人工干预的情况下独立且并行地处理流任务。