MapReduce
MapReduce
MapReduce 简介
Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。
MapReduce 的设计思路是:
- 分而治之,并行计算
- 移动计算,而非移动数据
MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值对处理,它将作业的输入视为一组 <key,value> 对,并生成一组 <key,value> 对作为输出。输出和输出的 key 和 value 都必须实现Writable 接口。
1 | (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output) |
特点
- 计算跟着数据走
- 良好的扩展性:计算能力随着节点数增加,近似线性递增
- 高容错
- 状态监控
- 适合海量数据的离线批处理
- 降低了分布式编程的门槛
应用场景
适用场景:
- 数据统计,如:网站的 PV、UV 统计
- 搜索引擎构建索引
- 海量数据查询
不适用场景:
- OLAP
- 要求毫秒或秒级返回结果
- 流计算
- 流计算的输入数据集是动态的,而 MapReduce 是静态的
- DAG 计算
- 多个作业存在依赖关系,后一个的输入是前一个的输出,构成有向无环图 DAG
- 每个 MapReduce 作业的输出结果都会落盘,造成大量磁盘 IO,导致性能非常低下
MapReduce 编程模型
MapReduce 编程模型:MapReduce 程序被分为 Map(映射)阶段和 Reduce(化简)阶段。
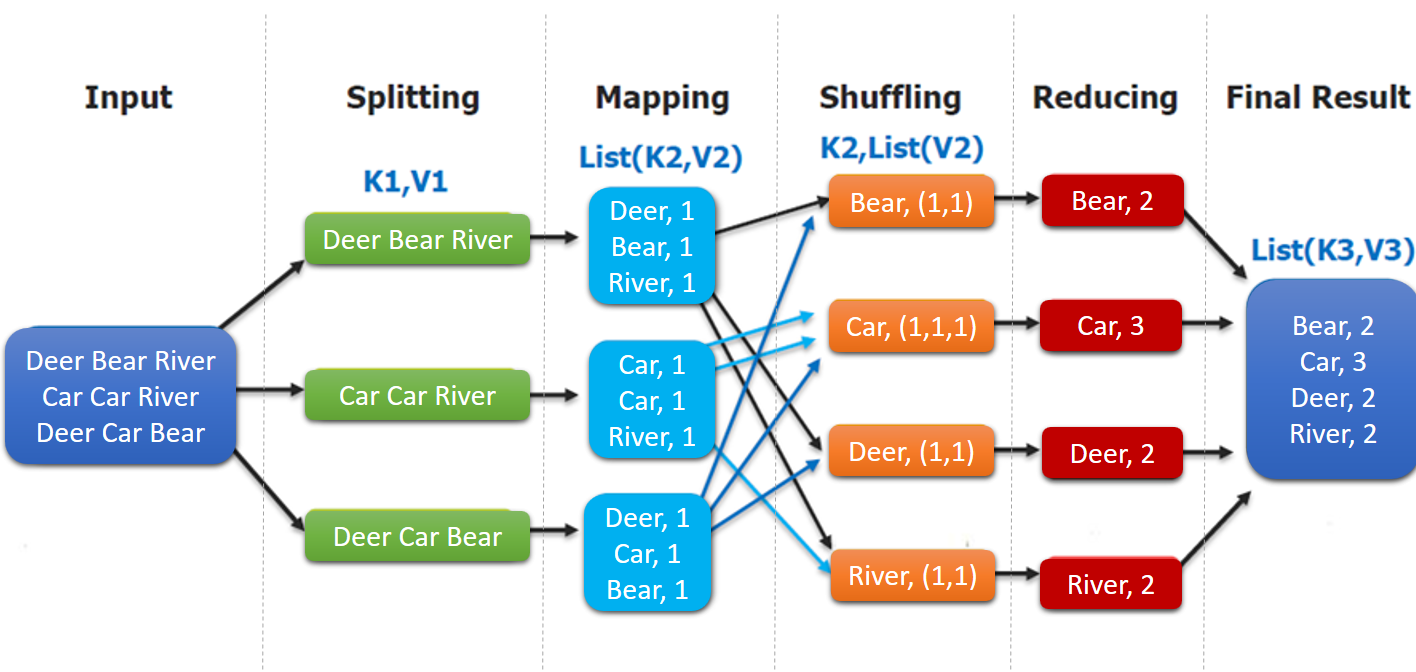
- input : 读取文本文件;
- splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容; - mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为 1,代表出现 1 次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是 Mapping 中的 V2; - Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
combiner & partitioner
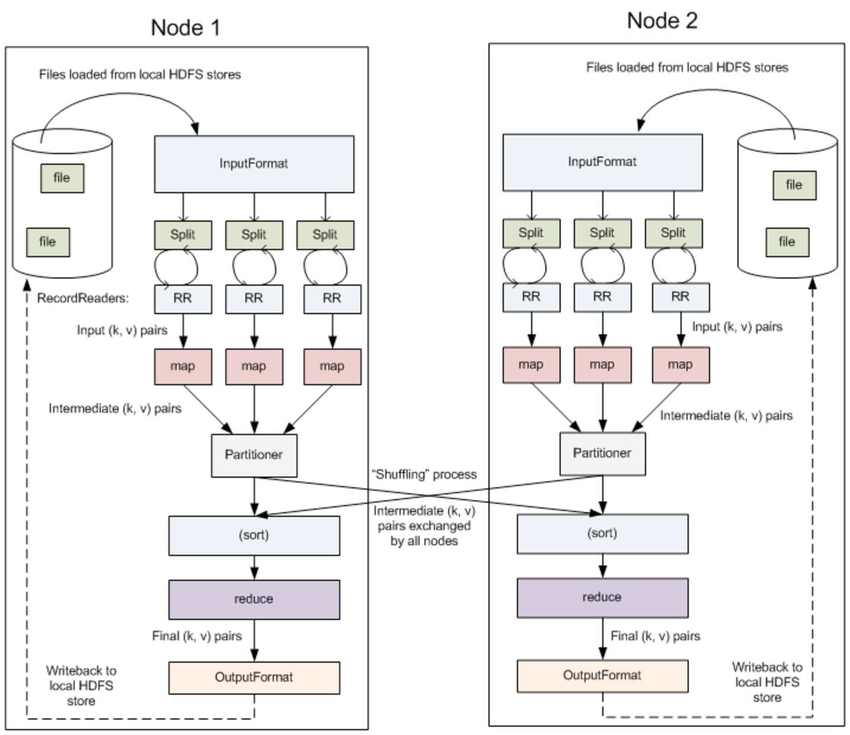
InputFormat & RecordReaders
InputFormat 将输出文件拆分为多个 InputSplit,并由 RecordReaders 将 InputSplit 转换为标准的<key,value>键值对,作为 map 的输出。这一步的意义在于只有先进行逻辑拆分并转为标准的键值对格式后,才能为多个 map 提供输入,以便进行并行处理。
Combiner
combiner 是 map 运算后的可选操作,它实际上是一个本地化的 reduce 操作,它主要是在 map 计算出中间文件后做一个简单的合并重复 key 值的操作。这里以词频统计为例:
map 在遇到一个 hadoop 的单词时就会记录为 1,但是这篇文章里 hadoop 可能会出现 n 多次,那么 map 输出文件冗余就会很多,因此在 reduce 计算前对相同的 key 做一个合并操作,那么需要传输的数据量就会减少,传输效率就可以得到提升。
但并非所有场景都适合使用 combiner,使用它的原则是 combiner 的输出不会影响到 reduce 计算的最终输入,例如:求总数,最大值,最小值时都可以使用 combiner,但是做平均值计算则不能使用 combiner。
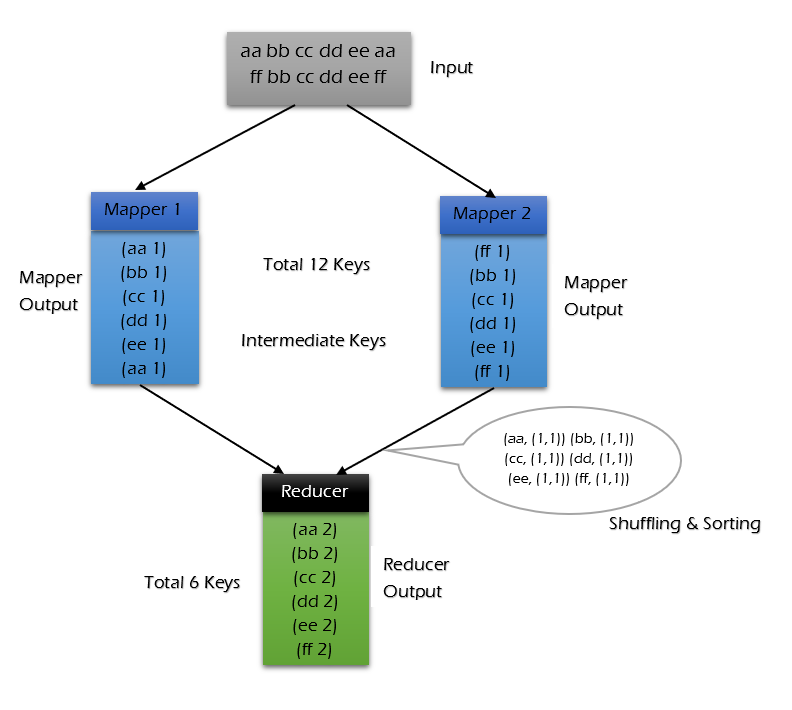
不使用 combiner 的情况:
使用 combiner 的情况:
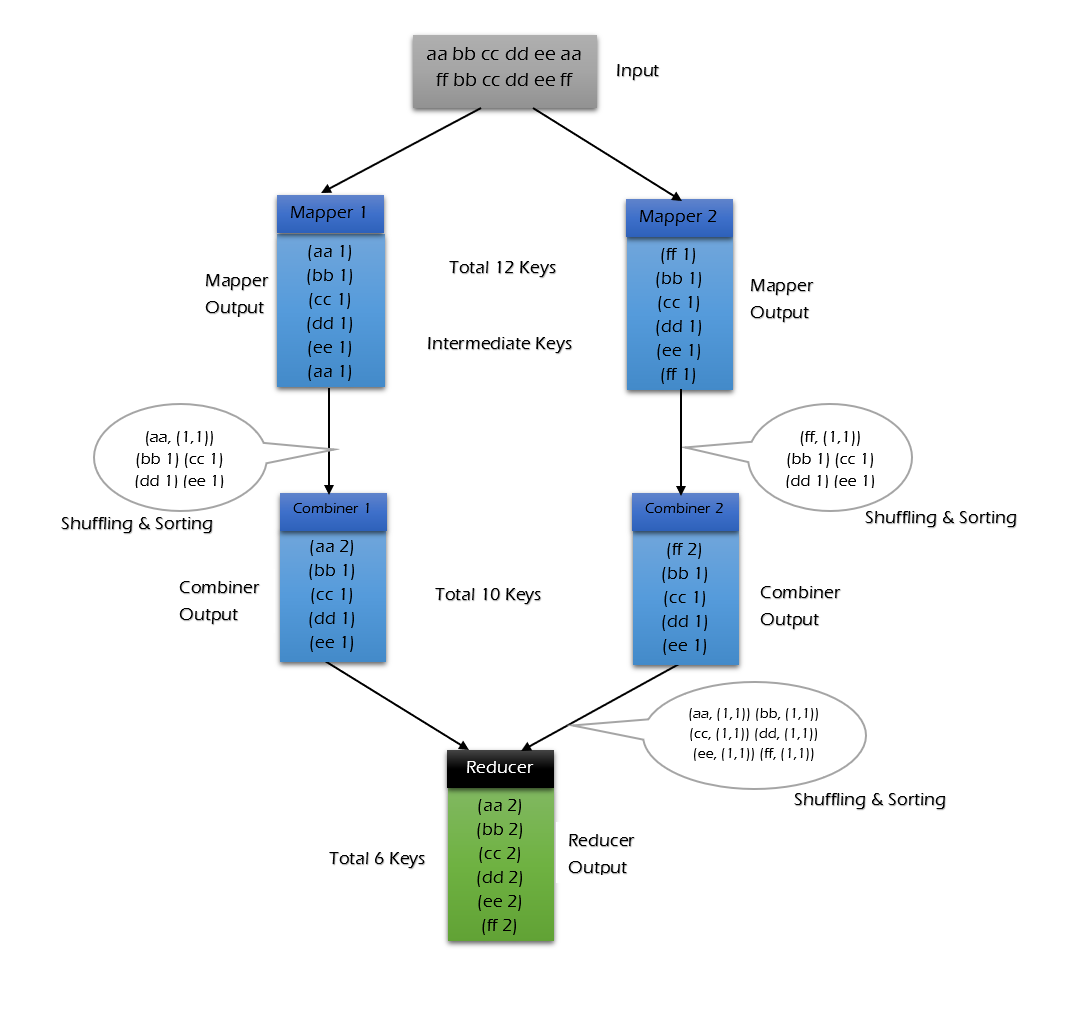
可以看到使用 combiner 的时候,需要传输到 reducer 中的数据由 12keys,降低到 10keys。降低的幅度取决于你 keys 的重复率,下文词频统计案例会演示用 combiner 降低数百倍的传输量。
MapReduce 词频统计案例
项目简介
这里给出一个经典的词频统计的案例:统计如下样本数据中每个单词出现的次数。
1 | Spark HBase |
为方便大家开发,我在项目源码中放置了一个工具类 WordCountDataUtils,用于模拟产生词频统计的样本,生成的文件支持输出到本地或者直接写到 HDFS 上。
项目完整源码下载地址:hadoop-word-count
项目依赖
想要进行 MapReduce 编程,需要导入 hadoop-client 依赖:
1 | <dependency> |
WordCountMapper
将每行数据按照指定分隔符进行拆分。这里需要注意在 MapReduce 中必须使用 Hadoop 定义的类型,因为 Hadoop 预定义的类型都是可序列化,可比较的,所有类型均实现了 WritableComparable 接口。
1 | public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { |
WordCountMapper 对应下图的 Mapping 操作:
WordCountMapper 继承自 Mappe 类,这是一个泛型类,定义如下:
1 | WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> |
- KEYIN :
mapping输入 key 的类型,即每行的偏移量 (每行第一个字符在整个文本中的位置),Long类型,对应 Hadoop 中的LongWritable类型; - VALUEIN :
mapping输入 value 的类型,即每行数据;String类型,对应 Hadoop 中Text类型; - KEYOUT :
mapping输出的 key 的类型,即每个单词;String类型,对应 Hadoop 中Text类型; - VALUEOUT:
mapping输出 value 的类型,即每个单词出现的次数;这里用int类型,对应IntWritable类型。
WordCountReducer
在 Reduce 中进行单词出现次数的统计:
1 | public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { |
如下图,shuffling 的输出是 reduce 的输入。这里的 key 是每个单词,values 是一个可迭代的数据类型,类似 (1,1,1,...)。
WordCountApp
组装 MapReduce 作业,并提交到服务器运行,代码如下:
1 | /** |
需要注意的是:如果不设置 Mapper 操作的输出类型,则程序默认它和 Reducer 操作输出的类型相同。
提交到服务器运行
在实际开发中,可以在本机配置 hadoop 开发环境,直接在 IDE 中启动进行测试。这里主要介绍一下打包提交到服务器运行。由于本项目没有使用除 Hadoop 外的第三方依赖,直接打包即可:
1 |
使用以下命令提交作业:
1 | hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \ |
作业完成后查看 HDFS 上生成目录:
1 | # 查看目录 |
词频统计案例进阶之 Combiner
代码实现
想要使用 combiner 功能只要在组装作业时,添加下面一行代码即可:
1 | // 设置 Combiner |
执行结果
加入 combiner 后统计结果是不会有变化的,但是可以从打印的日志看出 combiner 的效果:
没有加入 combiner 的打印日志:
加入 combiner 后的打印日志如下:
这里我们只有一个输入文件并且小于 128M,所以只有一个 Map 进行处理。可以看到经过 combiner 后,records 由 3519 降低为 6(样本中单词种类就只有 6 种),在这个用例中 combiner 就能极大地降低需要传输的数据量。
词频统计案例进阶之 Partitioner
默认的 Partitioner
这里假设有个需求:将不同单词的统计结果输出到不同文件。这种需求实际上比较常见,比如统计产品的销量时,需要将结果按照产品种类进行拆分。要实现这个功能,就需要用到自定义 Partitioner。
这里先介绍下 MapReduce 默认的分类规则:在构建 job 时候,如果不指定,默认的使用的是 HashPartitioner:对 key 值进行哈希散列并对 numReduceTasks 取余。其实现如下:
1 | public class HashPartitioner<K, V> extends Partitioner<K, V> { |
自定义 Partitioner
这里我们继承 Partitioner 自定义分类规则,这里按照单词进行分类:
1 | public class CustomPartitioner extends Partitioner<Text, IntWritable> { |
在构建 job 时候指定使用我们自己的分类规则,并设置 reduce 的个数:
1 | // 设置自定义分区规则 |
执行结果
执行结果如下,分别生成 6 个文件,每个文件中为对应单词的统计结果: