数据库连接池
数据库连接池
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。——摘自百度百科
什么是数据库连接池
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。 一个数据库连接对象均对应一个物理数据库连接,每次操作都打开一个物理连接,使用完都关闭连接,这样造成系统的 性能低下。 数据库连接池的解决方案是在应用程序启动时建立足够的数据库连接,并讲这些连接组成一个连接池(简单说:在一个“池”里放了好多半成品的数据库联接对象),由应用程序动态地对池中的连接进行申请、使用和释放。对于多于连接池中连接数的并发请求,应该在请求队列中排队等待。并且应用程序可以根据池中连接的使用率,动态增加或减少池中的连接数。 连接池技术尽可能多地重用了消耗内存地资源,大大节省了内存,提高了服务器地服务效率,能够支持更多的客户服务。通过使用连接池,将大大提高程序运行效率,同时,我们可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
为什么需要数据库连接池
不使用数据库连接池
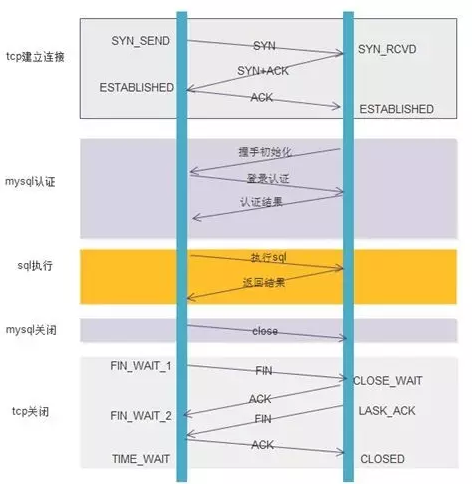
不使用数据库连接池的步骤:
- TCP 建立连接的三次握手
- MySQL 认证的三次握手
- 真正的 SQL 执行
- MySQL 的关闭
- TCP 的四次握手关闭
不使用数据库连接池的特性:
- 优点:实现简单
- 缺点:
- 网络 IO 较多
- 数据库的负载较高
- 响应时间较长及 QPS 较低
- 应用频繁的创建连接和关闭连接,导致临时对象较多,GC 频繁
- 在关闭连接后,会出现大量 TIME_WAIT 的 TCP 状态(在 2 个 MSL 之后关闭)
使用数据库连接池
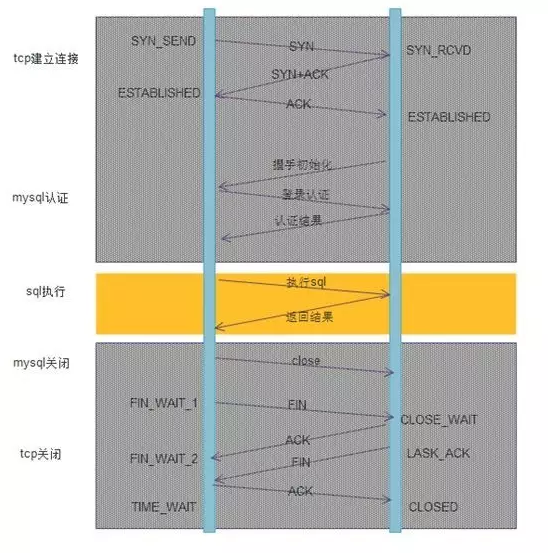
使用数据库连接池的步骤:只有第一次访问的时候,需要建立连接。 但是之后的访问,均会复用之前创建的连接,直接执行 SQL 语句。
使用数据库连接池的优点:
- 减少了网络开销
- 系统的性能会有一个实质的提升
- 没有了 TIME_WAIT 状态
数据库连接池如何工作
数据库连接池工作的核心在于以下几点:
创建连接池:与线程池等池化对象类似,数据库连接池会在进程启动之初,根据配置初始化,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,以避免创建、关闭所带来的系统开销。
使用、管理连接池中:连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。合理的策略可以保证数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。通常,数据库连接池的管理策略如下:
- 当请求数据库连接时,首先查看连接池中是否有空闲连接。
- 如果存在空闲连接,则将连接分配给客户使用。
- 如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数。若未达到,就重新创建一个连接,并分配给请求的客户;如果达到,就按设定的最大等待时间进行等待,若超出最大等待时间,则抛出异常给客户。
- 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值。如果超过,就从连接池中删除该连接;否则保留为其他客户服务。
关闭连接池:当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
数据库连接池的核心参数
使用数据库连接池,需要为其配置一些参数,以控制其工作。
通常,数据库连接池都会包含以下核心参数:
- 最小连接数:是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费.
- 最大连接数:是连接池能申请的最大连接数,如果数据库连接请求超过次数,后面的数据库连接请求将被加入到等待队列中,这会影响以后的数据库操作
- 最大空闲时间
- 获取连接超时时间
- 超时重试连接次数
数据库连接池的问题
并发问题:为了保证连接管理服务具有最大的通用性,必须考虑多线程环境,即并发问题。
事务处理:我们知道,事务具有原子性,此时要求对数据库的操作符合“ALL-OR-NOTHING”原则,即对于一组 SQL 语句要么全做,要么全不做。我们知道当 2 个线程共用一个连接 Connection 对象,而且各自都有自己的事务要处理时候,对于连接池是一个很头疼的问题,因为即使 Connection 类提供了相应的事务支持,可是我们仍然不能确定那个数据库操作是对应那个事务的,这是由于我们有2个线程都在进行事务操作而引起的。为此我们可以使用每一个事务独占一个连接来实现,虽然这种方法有点浪费连接池资源但是可以大大降低事务管理的复杂性。
连接池的分配与释放:连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。 对于连接的管理可使用一个 List。即把已经创建的连接都放入 List 中去统一管理。每当用户请求一个连接时,系统检查这个 List 中有没有可以分配的连接。如果有就把那个最合适的连接分配给他;如果没有就抛出一个异常给用户。
连接池的配置与维护:连接池中到底应该放置多少连接,才能使系统的性能最佳?系统可采取设置最小连接数(minConnection)和最大连接数(maxConnection)等参数来控制连接池中的连接。比方说,最小连接数是系统启动时连接池所创建的连接数。如果创建过多,则系统启动就慢,但创建后系统的响应速度会很快;如果创建过少,则系统启动的很快,响应起来却慢。这样,可以在开发时,设置较小的最小连接数,开发起来会快,而在系统实际使用时设置较大的,因为这样对访问客户来说速度会快些。最大连接数是连接池中允许连接的最大数目,具体设置多少,要看系统的访问量,可通过软件需求上得到。 如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接,以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。
数据库连接池技术选型
常见的数据库连接池:
- HikariCP:HiKariCP 号称是跑的最快的连接池,并且是 SpringBoot 框架的默认连接池。
- Druid:Druid 是阿里巴巴开源的数据库连接池。Druid 内置强大的监控功能,监控特性不影响性能。功能强大,能防 SQL 注入,内置 Loging 能诊断 Hack 应用行为。
- DBCP: 由 Apache 开发的一个 Java 数据库连接池。
commons-dbcp2基于commons-pool2来实现底层的对象池机制。单线程,性能较差,适用于小型系统。官方自 2021 年后没有再更新。 - C3P0:开源的 JDBC 连接池,实现了数据源和 JNDI 绑定,支持 JDBC3 规范和 JDBC2 的标准扩展。单线程,性能较差,适用于小型系统。官方自 2019 年后再没有更新。
- Tomcat-jdbc:Tomcat 在 7.0 以前使用 DBCP 做为连接池组件,从 7.0 后新增了 Tomcat jdbc pool 模块,基于 Tomcat JULI,使用 Tomcat 日志框架,完全兼容 dbcp,通过异步方式获取连接,支持高并发应用环境,超级简单核心文件只有 8 个,支持 JMX,支持 XA Connection。
来自 Druid 的竞品对比(https://github.com/alibaba/druid/wiki/Druid%E8%BF%9E%E6%8E%A5%E6%B1%A0%E4%BB%8B%E7%BB%8D):
| 功能类别 | 功能 | Druid | HikariCP | DBCP | Tomcat-jdbc | C3P0 |
|---|---|---|---|---|---|---|
| 性能 | PSCache | 是 | 否 | 是 | 是 | 是 |
| LRU | 是 | 否 | 是 | 是 | 是 | |
| SLB 负载均衡支持 | 是 | 否 | 否 | 否 | 否 | |
| 稳定性 | ExceptionSorter | 是 | 否 | 否 | 否 | 否 |
| 扩展 | 扩展 | Filter | JdbcIntercepter | |||
| 监控 | 监控方式 | jmx/log/http | jmx/metrics | jmx | jmx | jmx |
| 支持 SQL 级监控 | 是 | 否 | 否 | 否 | 否 | |
| Spring/Web 关联监控 | 是 | 否 | 否 | 否 | 否 | |
| 诊断支持 | LogFilter | 否 | 否 | 否 | 否 | |
| 连接泄露诊断 | logAbandoned | 否 | 否 | 否 | 否 | |
| 安全 | SQL 防注入 | 是 | 无 | 无 | 无 | 无 |
| 支持配置加密 | 是 | 否 | 否 | 否 | 否 |
从数据库连接池最重要的性能角度来看:HikariCP 应该性能最好;Druid 也不错,并且有更多、更久的生产实践,更为可靠;而其他常见的数据库连接池性能远远不如。
从功能角度来看:Druid 功能最全面,除基本的数据库连接池能力以外,还支持 sql 级监控、扩展、SQL 防注入以及监控等功能。
综合来看:HikariCP 是 Spring Boot 首选数据库连接池,对于 Spring Boot 项目来说,无疑适配性最好。而非 Spring Boot 项目,可以优先考虑 Druid,在国内有大规模应用,中文社区支持良好。
HikariCP
HiKariCP 号称是跑的最快的连接池,并且是 SpringBoot 框架的默认连接池。
HiKariCP 为了提升性能,做了很多细节上的优化,例如:
- 使用 FastList 替代 ArrayList,通过初始化的默认值,减少了越界检查的操作
- 优化并精简了字节码,通过使用 Javassist,减少了动态代理的性能损耗,比如使用 invokestatic 指令代替 invokevirtual 指令
- 实现了无锁的 ConcurrentBag,减少了并发场景下的锁竞争
HikariCP 关键配置:
maximum-pool-size:池中最大连接数(包括空闲和正在使用的连接)。默认值是 10,这个一般预估应用的最大连接数,后期根据监测得到一个最大值的一个平均值。要知道,最大连接并不是越多越好,一个 connection 会占用系统的带宽和存储。但是 当连接池没有空闲连接并且已经到达最大值,新来的连接池请求(HikariPool#getConnection)会被阻塞直到connectionTimeout(毫秒),超时后便抛出 SQLException。minimum-idle:池中最小空闲连接数量。默认值 10,小于池中最大连接数,一般根据系统大部分情况下的数据库连接情况取一个平均值。Hikari 会尽可能、尽快地将空闲连接数维持在这个数量上。如果为了获得最佳性能和对峰值需求的响应能力,我们也不妨让他和最大连接数保持一致,使得 HikariCP 成为一个固定大小的数据库连接池。connection-timeout:连接超时时间。默认值为 30s,可以接收的最小超时时间为 250ms。但是连接池请求也可以自定义超时时间(com.zaxxer.hikari.pool.HikariPool#getConnection(long))。idle-timeout:空闲连接存活最大时间,默认 600000(十分钟)max-lifetime:连接池中连接的最大生命周期。当连接一致处于闲置状态时,超过 8 小时数据库会主动断开连接。为了防止大量的同一时间处于空闲连接因为数据库方的闲置超时策略断开连接(可以理解为连接雪崩),一般将这个值设置的比数据库的“闲置超时时间”小几秒,以便这些连接断开后,HikariCP 能迅速的创建新一轮的连接。pool-name:连接池的名字。一般会出现在日志和 JMX 控制台中。默认值:auto-genenrated。建议取一个合适的名字,便于监控。auto-commit:是否自动提交池中返回的连接。默认值为 true。一般是有必要自动提交上一个连接中的事物的。如果为 false,那么就需要应用层手动提交事物。
参考配置:
1 | # 连接池名称 |
Druid
Druid 是阿里巴巴开源的数据库连接池。Druid 连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防 SQL 注入,内置 Loging 能诊断 Hack 应用行为。
Druid 关键配置:
1 | # 数据库访问配置 |