 SQL 语法高级特性
SQL 语法高级特性
# SQL 语法高级特性
本文针对关系型数据库的基本语法。限于篇幅,本文侧重说明用法,不会展开讲解特性、原理。
本文语法主要针对 Mysql,但大部分的语法对其他关系型数据库也适用。
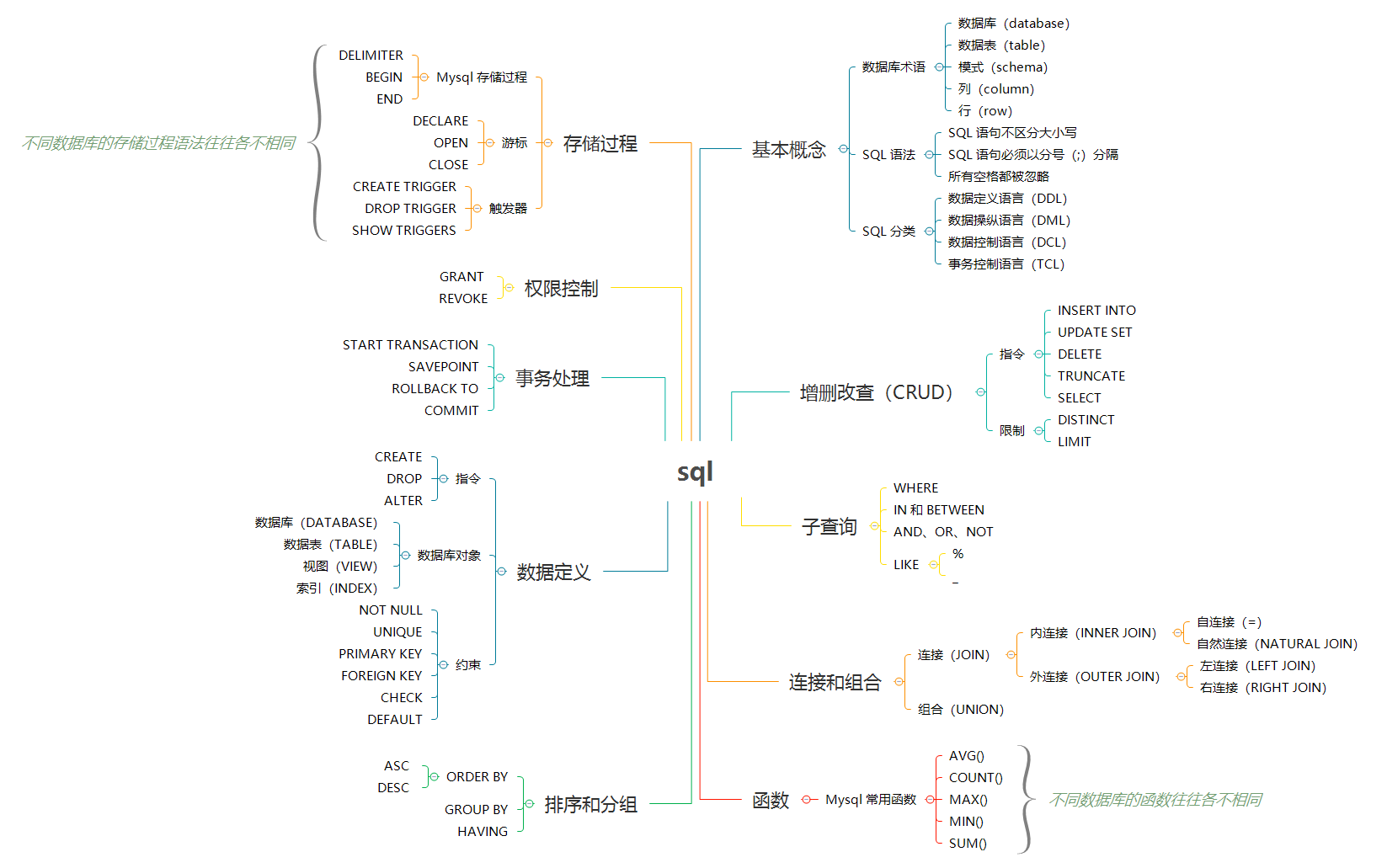
# 连接和组合
# 连接(JOIN)
连接用于连接多个表,使用
JOIN关键字,并且条件语句使用ON而不是WHERE。
如果一个 JOIN 至少有一个公共字段并且它们之间存在关系,则该 JOIN 可以在两个或多个表上工作。
JOIN 保持基表(结构和数据)不变。连接可以替换子查询,并且比子查询的效率一般会更快。
JOIN 有两种连接类型:内连接和外连接。
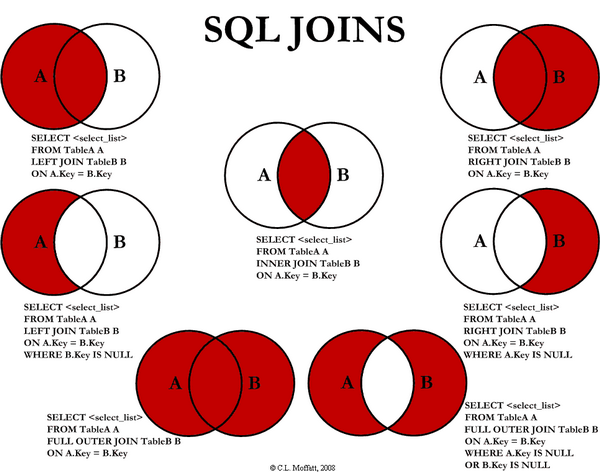
# 内连接(INNER JOIN)
内连接又称等值连接,使用 INNER JOIN 关键字。在没有条件语句的情况下返回笛卡尔积。
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id;
# 自连接(=)
自连接可以看成内连接的一种,只是连接的表是自身而已。自然连接是把同名列通过 = 连接起来的,同名列可以有多个。
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM customers c1, customers c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';
# 自然连接(NATURAL JOIN)
内连接提供连接的列,而自然连接自动连接所有同名列。自然连接使用 NATURAL JOIN 关键字。
SELECT *
FROM Products
NATURAL JOIN Customers;
# 外连接(OUTER JOIN)
外连接返回一个表中的所有行,并且仅返回来自此表中满足连接条件的那些行,即两个表中的列是相等的。外连接分为左外连接、右外连接、全外连接(Mysql 不支持)。
# 左连接(LEFT JOIN)
左外连接就是保留左表没有关联的行。
SELECT customers.cust_id, orders.order_num
FROM customers LEFT JOIN orders
ON customers.cust_id = orders.cust_id;
# 右连接(RIGHT JOIN)
右外连接就是保留右表没有关联的行。
SELECT customers.cust_id, orders.order_num
FROM customers RIGHT JOIN orders
ON customers.cust_id = orders.cust_id;
# 组合(UNION)
UNION运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自UNION中参与查询的提取行。
UNION 基本规则:
- 所有查询的列数和列顺序必须相同。
- 每个查询中涉及表的列的数据类型必须相同或兼容。
- 通常返回的列名取自第一个查询。
默认会去除相同行,如果需要保留相同行,使用 UNION ALL。
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
应用场景:
- 在一个查询中从不同的表返回结构数据。
- 对一个表执行多个查询,按一个查询返回数据。
组合查询示例:
SELECT cust_name, cust_contact, cust_email
FROM customers
WHERE cust_state IN ('IL', 'IN', 'MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM customers
WHERE cust_name = 'Fun4All';
# JOIN vs UNION
JOIN中连接表的列可能不同,但在UNION中,所有查询的列数和列顺序必须相同。UNION将查询之后的行放在一起(垂直放置),但JOIN将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
# 函数
🔔 注意:不同数据库的函数往往各不相同,因此不可移植。本节主要以 Mysql 的函数为例。
# 文本处理
| 函数 | 说明 |
|---|---|
LEFT()、RIGHT() | 左边或者右边的字符 |
LOWER()、UPPER() | 转换为小写或者大写 |
LTRIM()、RTIM() | 去除左边或者右边的空格 |
LENGTH() | 长度 |
SOUNDEX() | 转换为语音值 |
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
SELECT *
FROM mytable
WHERE SOUNDEX(col1) = SOUNDEX('apple')
# 日期和时间处理
- 日期格式:
YYYY-MM-DD - 时间格式:
HH:MM:SS
| 函 数 | 说 明 |
|---|---|
AddDate() | 增加一个日期(天、周等) |
AddTime() | 增加一个时间(时、分等) |
CurDate() | 返回当前日期 |
CurTime() | 返回当前时间 |
Date() | 返回日期时间的日期部分 |
DateDiff() | 计算两个日期之差 |
Date_Add() | 高度灵活的日期运算函数 |
Date_Format() | 返回一个格式化的日期或时间串 |
Day() | 返回一个日期的天数部分 |
DayOfWeek() | 对于一个日期,返回对应的星期几 |
Hour() | 返回一个时间的小时部分 |
Minute() | 返回一个时间的分钟部分 |
Month() | 返回一个日期的月份部分 |
Now() | 返回当前日期和时间 |
Second() | 返回一个时间的秒部分 |
Time() | 返回一个日期时间的时间部分 |
Year() | 返回一个日期的年份部分 |
mysql> SELECT NOW();
2018-4-14 20:25:11
# 数值处理
| 函数 | 说明 |
|---|---|
| SIN() | 正弦 |
| COS() | 余弦 |
| TAN() | 正切 |
| ABS() | 绝对值 |
| SQRT() | 平方根 |
| MOD() | 余数 |
| EXP() | 指数 |
| PI() | 圆周率 |
| RAND() | 随机数 |
# 汇总
| 函 数 | 说 明 |
|---|---|
AVG() | 返回某列的平均值 |
COUNT() | 返回某列的行数 |
MAX() | 返回某列的最大值 |
MIN() | 返回某列的最小值 |
SUM() | 返回某列值之和 |
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以让汇总函数值汇总不同的值。
SELECT AVG(DISTINCT col1) AS avg_col
FROM mytable
# 分组
# GROUP BY
GROUP BY子句将记录分组到汇总行中,GROUP BY为每个组返回一个记录。
GROUP BY 可以按一列或多列进行分组。
GROUP BY 通常还涉及聚合函数:COUNT,MAX,SUM,AVG 等。
GROUP BY 按分组字段进行排序后,ORDER BY 可以以汇总字段来进行排序。
分组示例:
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name;
分组后排序示例:
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name
ORDER BY cust_name DESC;
# HAVING
HAVING用于对汇总的GROUP BY结果进行过滤。HAVING要求存在一个GROUP BY子句。
WHERE 和 HAVING 可以在相同的查询中。
HAVING vs WHERE:
WHERE和HAVING都是用于过滤。HAVING适用于汇总的组记录;而WHERE适用于单个记录。
使用 WHERE 和 HAVING 过滤数据示例:
SELECT cust_name, COUNT(*) AS num
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
HAVING COUNT(*) >= 1;
(以下为 DDL 语句用法)
# 事务
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL 默认采用隐式提交策略(autocommit),每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
通过 set autocommit=0 可以取消自动提交,直到 set autocommit=1 才会提交;autocommit 标记是针对每个连接而不是针对服务器的。
事务处理指令:
START TRANSACTION- 指令用于标记事务的起始点。SAVEPOINT- 指令用于创建保留点。ROLLBACK TO- 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到START TRANSACTION语句处。COMMIT- 提交事务。RELEASE SAVEPOINT:删除某个保存点。SET TRANSACTION:设置事务的隔离级别。
事务处理示例:
-- 开始事务
START TRANSACTION;
-- 插入操作 A
INSERT INTO `user`
VALUES (1, 'root1', 'root1', 'xxxx@163.com');
-- 创建保留点 updateA
SAVEPOINT updateA;
-- 插入操作 B
INSERT INTO `user`
VALUES (2, 'root2', 'root2', 'xxxx@163.com');
-- 回滚到保留点 updateA
ROLLBACK TO updateA;
-- 提交事务,只有操作 A 生效
COMMIT;
# ACID
# 事务隔离级别
(以下为 DCL 语句用法)
# 权限控制
GRANT 和 REVOKE 可在几个层次上控制访问权限:
- 整个服务器,使用
GRANT ALL和REVOKE ALL; - 整个数据库,使用 ON database.*;
- 特定的表,使用 ON database.table;
- 特定的列;
- 特定的存储过程。
新创建的账户没有任何权限。
账户用 username@host 的形式定义,username@% 使用的是默认主机名。
MySQL 的账户信息保存在 mysql 这个数据库中。
USE mysql;
SELECT user FROM user;
# 创建账户
CREATE USER myuser IDENTIFIED BY 'mypassword';
# 修改账户名
UPDATE user SET user='newuser' WHERE user='myuser';
FLUSH PRIVILEGES;
# 删除账户
DROP USER myuser;
# 查看权限
SHOW GRANTS FOR myuser;
# 授予权限
GRANT SELECT, INSERT ON *.* TO myuser;
# 删除权限
REVOKE SELECT, INSERT ON *.* FROM myuser;
# 更改密码
SET PASSWORD FOR myuser = 'mypass';
# 存储过程
存储过程的英文是 Stored Procedure。它可以视为一组 SQL 语句的批处理。一旦存储过程被创建出来,使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。
定义存储过程的语法格式:
CREATE PROCEDURE 存储过程名称 ([参数列表])
BEGIN
需要执行的语句
END
存储过程定义语句类型:
CREATE PROCEDURE用于创建存储过程DROP PROCEDURE用于删除存储过程ALTER PROCEDURE用于修改存储过程
# 使用存储过程
创建存储过程的要点:
DELIMITER用于定义语句的结束符- 存储过程的 3 种参数类型:
IN:存储过程的入参OUT:存储过程的出参INPUT:既是存储过程的入参,也是存储过程的出参
- 流控制语句:
BEGIN…END:BEGIN…END中间包含了多个语句,每个语句都以(;)号为结束符。DECLARE:DECLARE用来声明变量,使用的位置在于BEGIN…END语句中间,而且需要在其他语句使用之前进行变量的声明。SET:赋值语句,用于对变量进行赋值。SELECT…INTO:把从数据表中查询的结果存放到变量中,也就是为变量赋值。每次只能给一个变量赋值,不支持集合的操作。IF…THEN…ENDIF:条件判断语句,可以在IF…THEN…ENDIF中使用ELSE和ELSEIF来进行条件判断。CASE:CASE语句用于多条件的分支判断。
创建存储过程示例:
DROP PROCEDURE IF EXISTS `proc_adder`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
BEGIN
DECLARE c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set sum = a + b;
END
;;
DELIMITER ;
使用存储过程示例:
set @b=5;
call proc_adder(2,@b,@s);
select @s as sum;
# 存储过程的利弊
存储过程的优点:
- 执行效率高:一次编译多次使用。
- 安全性强:在设定存储过程的时候可以设置对用户的使用权限,这样就和视图一样具有较强的安全性。
- 可复用:将代码封装,可以提高代码复用。
- 性能好
- 由于是预先编译,因此具有很高的性能。
- 一个存储过程替代大量 T_SQL 语句 ,可以降低网络通信量,提高通信速率。
存储过程的缺点:
- 可移植性差:存储过程不能跨数据库移植。由于不同数据库的存储过程语法几乎都不一样,十分难以维护(不通用)。
- 调试困难:只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容易。
- 版本管理困难:比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
- 不适合高并发的场景:高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护,增加数据库的压力,显然就不适用了。
综上,存储过程的优缺点都非常突出,是否使用一定要慎重,需要根据具体应用场景来权衡。
# 触发器
触发器可以视为一种特殊的存储过程。
触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
# 触发器特性
可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
BEGIN 和 END
当触发器的触发条件满足时,将会执行 BEGIN 和 END 之间的触发器执行动作。
🔔 注意:在 MySQL 中,分号
;是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。这时就会用到
DELIMITER命令(DELIMITER是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:DELIMITER new_delemiter。new_delemiter可以设为 1 个或多个长度的符号,默认的是分号;,我们可以把它修改为其他符号,如$-DELIMITER $。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了$,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
NEW 和 OLD
- MySQL 中定义了
NEW和OLD关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。 - 在
INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据; - 在
UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据; - 在
DELETE型触发器中,OLD用来表示将要或已经被删除的原数据; - 使用方法:
NEW.columnName(columnName 为相应数据表某一列名)
# 触发器指令
提示:为了理解触发器的要点,有必要先了解一下创建触发器的指令。
CREATE TRIGGER 指令用于创建触发器。
语法:
CREATE TRIGGER trigger_name
trigger_time
trigger_event
ON table_name
FOR EACH ROW
BEGIN
trigger_statements
END;
说明:
- trigger_name:触发器名
- trigger_time: 触发器的触发时机。取值为
BEFORE或AFTER。 - trigger_event: 触发器的监听事件。取值为
INSERT、UPDATE或DELETE。 - table_name: 触发器的监听目标。指定在哪张表上建立触发器。
- FOR EACH ROW: 行级监视,Mysql 固定写法,其他 DBMS 不同。
- trigger_statements: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号
;来结尾。
创建触发器示例:
DELIMITER $
CREATE TRIGGER `trigger_insert_user`
AFTER INSERT ON `user`
FOR EACH ROW
BEGIN
INSERT INTO `user_history`(user_id, operate_type, operate_time)
VALUES (NEW.id, 'add a user', now());
END $
DELIMITER ;
查看触发器示例:
SHOW TRIGGERS;
删除触发器示例:
DROP TRIGGER IF EXISTS trigger_insert_user;
# 游标
游标(CURSOR)是一个存储在 DBMS 服务器上的数据库查询,它不是一条
SELECT语句,而是被该语句检索出来的结果集。在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
使用游标的步骤:
- 定义游标:通过
DECLARE cursor_name CURSOR FOR <语句>定义游标。这个过程没有实际检索出数据。 - 打开游标:通过
OPEN cursor_name打开游标。 - 取出数据:通过
FETCH cursor_name INTO var_name ...获取数据。 - 关闭游标:通过
CLOSE cursor_name关闭游标。 - 释放游标:通过
DEALLOCATE PREPARE释放游标。
游标使用示例:
DELIMITER $
CREATE PROCEDURE getTotal()
BEGIN
DECLARE total INT;
-- 创建接收游标数据的变量
DECLARE sid INT;
DECLARE sname VARCHAR(10);
-- 创建总数变量
DECLARE sage INT;
-- 创建结束标志变量
DECLARE done INT DEFAULT false;
-- 创建游标
DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
-- 指定游标循环结束时的返回值
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
SET total = 0;
OPEN cur;
FETCH cur INTO sid, sname, sage;
WHILE(NOT done)
DO
SET total = total + 1;
FETCH cur INTO sid, sname, sage;
END WHILE;
CLOSE cur;
SELECT total;
END $
DELIMITER ;
-- 调用存储过程
call getTotal();
# 参考资料
- 《SQL 必知必会》 (opens new window)
- 『浅入深出』MySQL 中事务的实现 (opens new window)
- MySQL 的学习--触发器 (opens new window)
- 维基百科词条 - SQL (opens new window)
- https://www.sitesbay.com/sql/index (opens new window)
- SQL Subqueries (opens new window)
- Quick breakdown of the types of joins (opens new window)
- SQL UNION (opens new window)
- SQL database security (opens new window)
- Mysql 中的存储过程 (opens new window)