 Tomcat容器
Tomcat容器
# Tomcat 容器
# Tomcat 实现热部署和热加载
- 热加载的实现方式是 Web 容器启动一个后台线程,定期检测类文件的变化,如果有变化,就重新加载类,在这个过程中不会清空 Session ,一般用在开发环境。
- 热部署原理类似,也是由后台线程定时检测 Web 应用的变化,但它会重新加载整个 Web 应用。这种方式会清空 Session,比热加载更加干净、彻底,一般用在生产环境。
Tomcat 通过开启后台线程,使得各个层次的容器组件都有机会完成一些周期性任务。Tomcat 是基于 ScheduledThreadPoolExecutor 实现周期性任务的:
bgFuture = exec.scheduleWithFixedDelay(
new ContainerBackgroundProcessor(),// 要执行的 Runnable
backgroundProcessorDelay, // 第一次执行延迟多久
backgroundProcessorDelay, // 之后每次执行间隔多久
TimeUnit.SECONDS); // 时间单位
第一个参数就是要周期性执行的任务类 ContainerBackgroundProcessor,它是一个 Runnable,同时也是 ContainerBase 的内部类,ContainerBase 是所有容器组件的基类,我们来回忆一下容器组件有哪些,有 Engine、Host、Context 和 Wrapper 等,它们具有父子关系。
# ContainerBackgroundProcessor 实现
我们接来看 ContainerBackgroundProcessor 具体是如何实现的。
protected class ContainerBackgroundProcessor implements Runnable {
@Override
public void run() {
// 请注意这里传入的参数是 " 宿主类 " 的实例
processChildren(ContainerBase.this);
}
protected void processChildren(Container container) {
try {
//1. 调用当前容器的 backgroundProcess 方法。
container.backgroundProcess();
//2. 遍历所有的子容器,递归调用 processChildren,
// 这样当前容器的子孙都会被处理
Container[] children = container.findChildren();
for (int i = 0; i < children.length; i++) {
// 这里请你注意,容器基类有个变量叫做 backgroundProcessorDelay,如果大于 0,表明子容器有自己的后台线程,无需父容器来调用它的 processChildren 方法。
if (children[i].getBackgroundProcessorDelay() <= 0) {
processChildren(children[i]);
}
}
} catch (Throwable t) { ... }
上面的代码逻辑也是比较清晰的,首先 ContainerBackgroundProcessor 是一个 Runnable,它需要实现 run 方法,它的 run 很简单,就是调用了 processChildren 方法。这里有个小技巧,它把“宿主类”,也就是ContainerBase 的类实例当成参数传给了 run 方法。
而在 processChildren 方法里,就做了两步:调用当前容器的 backgroundProcess 方法,以及递归调用子孙的 backgroundProcess 方法。请你注意 backgroundProcess 是 Container 接口中的方法,也就是说所有类型的容器都可以实现这个方法,在这个方法里完成需要周期性执行的任务。
这样的设计意味着什么呢?我们只需要在顶层容器,也就是 Engine 容器中启动一个后台线程,那么这个线程不但会执行 Engine 容器的周期性任务,它还会执行所有子容器的周期性任务。
# backgroundProcess 方法
上述代码都是在基类 ContainerBase 中实现的,那具体容器类需要做什么呢?其实很简单,如果有周期性任务要执行,就实现 backgroundProcess 方法;如果没有,就重用基类 ContainerBase 的方法。ContainerBase 的 backgroundProcess 方法实现如下:
public void backgroundProcess() {
//1. 执行容器中 Cluster 组件的周期性任务
Cluster cluster = getClusterInternal();
if (cluster != null) {
cluster.backgroundProcess();
}
//2. 执行容器中 Realm 组件的周期性任务
Realm realm = getRealmInternal();
if (realm != null) {
realm.backgroundProcess();
}
//3. 执行容器中 Valve 组件的周期性任务
Valve current = pipeline.getFirst();
while (current != null) {
current.backgroundProcess();
current = current.getNext();
}
//4. 触发容器的 " 周期事件 ",Host 容器的监听器 HostConfig 就靠它来调用
fireLifecycleEvent(Lifecycle.PERIODIC_EVENT, null);
}
从上面的代码可以看到,不仅每个容器可以有周期性任务,每个容器中的其他通用组件,比如跟集群管理有关的 Cluster 组件、跟安全管理有关的 Realm 组件都可以有自己的周期性任务。
我在前面的专栏里提到过,容器之间的链式调用是通过 Pipeline-Valve 机制来实现的,从上面的代码你可以看到容器中的 Valve 也可以有周期性任务,并且被 ContainerBase 统一处理。
请你特别注意的是,在 backgroundProcess 方法的最后,还触发了容器的“周期事件”。我们知道容器的生命周期事件有初始化、启动和停止等,那“周期事件”又是什么呢?它跟生命周期事件一样,是一种扩展机制,你可以这样理解:
又一段时间过去了,容器还活着,你想做点什么吗?如果你想做点什么,就创建一个监听器来监听这个“周期事件”,事件到了我负责调用你的方法。
总之,有了 ContainerBase 中的后台线程和 backgroundProcess 方法,各种子容器和通用组件不需要各自弄一个后台线程来处理周期性任务,这样的设计显得优雅和整洁。
# Tomcat 热加载
有了 ContainerBase 的周期性任务处理“框架”,作为具体容器子类,只需要实现自己的周期性任务就行。而 Tomcat 的热加载,就是在 Context 容器中实现的。Context 容器的 backgroundProcess 方法是这样实现的:
public void backgroundProcess() {
//WebappLoader 周期性的检查 WEB-INF/classes 和 WEB-INF/lib 目录下的类文件
Loader loader = getLoader();
if (loader != null) {
loader.backgroundProcess();
}
//Session 管理器周期性的检查是否有过期的 Session
Manager manager = getManager();
if (manager != null) {
manager.backgroundProcess();
}
// 周期性的检查静态资源是否有变化
WebResourceRoot resources = getResources();
if (resources != null) {
resources.backgroundProcess();
}
// 调用父类 ContainerBase 的 backgroundProcess 方法
super.backgroundProcess();
}
从上面的代码我们看到 Context 容器通过 WebappLoader 来检查类文件是否有更新,通过 Session 管理器来检查是否有 Session 过期,并且通过资源管理器来检查静态资源是否有更新,最后还调用了父类 ContainerBase 的 backgroundProcess 方法。
这里我们要重点关注,WebappLoader 是如何实现热加载的,它主要是调用了 Context 容器的 reload 方法,而 Context 的 reload 方法比较复杂,总结起来,主要完成了下面这些任务:
- 停止和销毁 Context 容器及其所有子容器,子容器其实就是 Wrapper,也就是说 Wrapper 里面 Servlet 实例也被销毁了。
- 停止和销毁 Context 容器关联的 Listener 和 Filter。
- 停止和销毁 Context 下的 Pipeline 和各种 Valve。
- 停止和销毁 Context 的类加载器,以及类加载器加载的类文件资源。
- 启动 Context 容器,在这个过程中会重新创建前面四步被销毁的资源。
在这个过程中,类加载器发挥着关键作用。一个 Context 容器对应一个类加载器,类加载器在销毁的过程中会把它加载的所有类也全部销毁。Context 容器在启动过程中,会创建一个新的类加载器来加载新的类文件。
在 Context 的 reload 方法里,并没有调用 Session 管理器的 distroy 方法,也就是说这个 Context 关联的 Session 是没有销毁的。你还需要注意的是,Tomcat 的热加载默认是关闭的,你需要在 conf 目录下的 Context.xml 文件中设置 reloadable 参数来开启这个功能,像下面这样:
<Context reloadable="true"/>
# Tomcat 热部署
我们再来看看热部署,热部署跟热加载的本质区别是,热部署会重新部署 Web 应用,原来的 Context 对象会整个被销毁掉,因此这个 Context 所关联的一切资源都会被销毁,包括 Session。
那么 Tomcat 热部署又是由哪个容器来实现的呢?应该不是由 Context,因为热部署过程中 Context 容器被销毁了,那么这个重担就落在 Host 身上了,因为它是 Context 的父容器。
跟 Context 不一样,Host 容器并没有在 backgroundProcess 方法中实现周期性检测的任务,而是通过监听器 HostConfig 来实现的,HostConfig 就是前面提到的“周期事件”的监听器,那“周期事件”达到时,HostConfig 会做什么事呢?
public void lifecycleEvent(LifecycleEvent event) {
// 执行 check 方法。
if (event.getType().equals(Lifecycle.PERIODIC_EVENT)) {
check();
}
}
它执行了 check 方法,我们接着来看 check 方法里做了什么。
protected void check() {
if (host.getAutoDeploy()) {
// 检查这个 Host 下所有已经部署的 Web 应用
DeployedApplication[] apps =
deployed.values().toArray(new DeployedApplication[0]);
for (int i = 0; i < apps.length; i++) {
// 检查 Web 应用目录是否有变化
checkResources(apps[i], false);
}
// 执行部署
deployApps();
}
}
其实 HostConfig 会检查 webapps 目录下的所有 Web 应用:
- 如果原来 Web 应用目录被删掉了,就把相应 Context 容器整个销毁掉。
- 是否有新的 Web 应用目录放进来了,或者有新的 WAR 包放进来了,就部署相应的 Web 应用。
因此 HostConfig 做的事情都是比较“宏观”的,它不会去检查具体类文件或者资源文件是否有变化,而是检查 Web 应用目录级别的变化。
# Tomcat 的类加载机制
Tomcat 的自定义类加载器 WebAppClassLoader 打破了双亲委派机制,它首先自己尝试去加载某个类,如果找不到再代理给父类加载器,其目的是优先加载 Web 应用自己定义的类。具体实现就是重写 ClassLoader 的两个方法:findClass 和 loadClass。
# findClass 方法
我们先来看看 findClass 方法的实现,为了方便理解和阅读,我去掉了一些细节:
public Class<?> findClass(String name) throws ClassNotFoundException {
...
Class<?> clazz = null;
try {
//1. 先在 Web 应用目录下查找类
clazz = findClassInternal(name);
} catch (RuntimeException e) {
throw e;
}
if (clazz == null) {
try {
//2. 如果在本地目录没有找到,交给父加载器去查找
clazz = super.findClass(name);
} catch (RuntimeException e) {
throw e;
}
//3. 如果父类也没找到,抛出 ClassNotFoundException
if (clazz == null) {
throw new ClassNotFoundException(name);
}
return clazz;
}
在 findClass 方法里,主要有三个步骤:
- 先在 Web 应用本地目录下查找要加载的类。
- 如果没有找到,交给父加载器去查找,它的父加载器就是上面提到的系统类加载器 AppClassLoader。
- 如何父加载器也没找到这个类,抛出 ClassNotFound 异常。
# loadClass 方法
接着我们再来看 Tomcat 类加载器的 loadClass 方法的实现,同样我也去掉了一些细节:
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
Class<?> clazz = null;
//1. 先在本地 cache 查找该类是否已经加载过
clazz = findLoadedClass0(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
//2. 从系统类加载器的 cache 中查找是否加载过
clazz = findLoadedClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
// 3. 尝试用 ExtClassLoader 类加载器类加载,为什么?
ClassLoader javaseLoader = getJavaseClassLoader();
try {
clazz = javaseLoader.loadClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 4. 尝试在本地目录搜索 class 并加载
try {
clazz = findClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 5. 尝试用系统类加载器 (也就是 AppClassLoader) 来加载
try {
clazz = Class.forName(name, false, parent);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
}
//6. 上述过程都加载失败,抛出异常
throw new ClassNotFoundException(name);
}
loadClass 方法稍微复杂一点,主要有六个步骤:
- 先在本地 Cache 查找该类是否已经加载过,也就是说 Tomcat 的类加载器是否已经加载过这个类。
- 如果 Tomcat 类加载器没有加载过这个类,再看看系统类加载器是否加载过。
- 如果都没有,就让ExtClassLoader去加载,这一步比较关键,目的防止 Web 应用自己的类覆盖 JRE 的核心类。因为 Tomcat 需要打破双亲委派机制,假如 Web 应用里自定义了一个叫 Object 的类,如果先加载这个 Object 类,就会覆盖 JRE 里面的那个 Object 类,这就是为什么 Tomcat 的类加载器会优先尝试用 ExtClassLoader 去加载,因为 ExtClassLoader 会委托给 BootstrapClassLoader 去加载,BootstrapClassLoader 发现自己已经加载了 Object 类,直接返回给 Tomcat 的类加载器,这样 Tomcat 的类加载器就不会去加载 Web 应用下的 Object 类了,也就避免了覆盖 JRE 核心类的问题。
- 如果 ExtClassLoader 加载器加载失败,也就是说 JRE 核心类中没有这类,那么就在本地 Web 应用目录下查找并加载。
- 如果本地目录下没有这个类,说明不是 Web 应用自己定义的类,那么由系统类加载器去加载。这里请你注意,Web 应用是通过
Class.forName调用交给系统类加载器的,因为Class.forName的默认加载器就是系统类加载器。 - 如果上述加载过程全部失败,抛出 ClassNotFound 异常。
从上面的过程我们可以看到,Tomcat 的类加载器打破了双亲委派机制,没有一上来就直接委托给父加载器,而是先在本地目录下加载,为了避免本地目录下的类覆盖 JRE 的核心类,先尝试用 JVM 扩展类加载器 ExtClassLoader 去加载。那为什么不先用系统类加载器 AppClassLoader 去加载?很显然,如果是这样的话,那就变成双亲委派机制了,这就是 Tomcat 类加载器的巧妙之处。
# Tomcat 实现应用隔离
Tomcat 作为 Web 容器,需要解决以下问题:
- 如果在 Tomcat 中运行了两个 Web 应用程序,两个 Web 应用中有同名的 Servlet,但是功能不同,Tomcat 需要同时加载和管理这两个同名的 Servlet 类,保证它们不会冲突,因此 Web 应用之间的类需要隔离。
- 两个 Web 应用都依赖同一个第三方的 JAR 包,比如 Spring,那 Spring 的 JAR 包被加载到内存后,Tomcat 要保证这两个 Web 应用能够共享,也就是说 Spring 的 JAR 包只被加载一次,否则随着依赖的第三方 JAR 包增多,JVM 的内存会膨胀。
- 需要隔离 Tomcat 本身的类和 Web 应用的类。
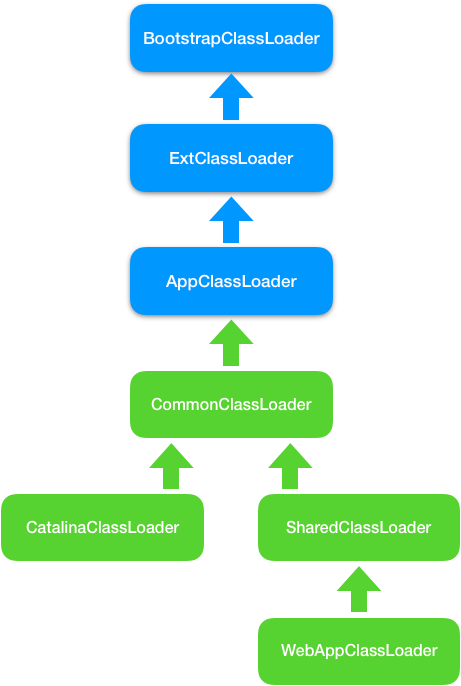
# WebAppClassLoader
针对第一个问题:
如果使用 JVM 默认 AppClassLoader 来加载 Web 应用,AppClassLoader 只能加载一个 Servlet 类,在加载第二个同名 Servlet 类时,AppClassLoader 会返回第一个 Servlet 类的 Class 实例,这是因为在 AppClassLoader 看来,同名的 Servlet 类只被加载一次。
Tomcat 的解决方案是自定义一个类加载器 WebAppClassLoader, 并且给每个 Web 应用创建一个类加载器实例。我们知道,Context 容器组件对应一个 Web 应用,因此,每个 Context 容器负责创建和维护一个 WebAppClassLoader 加载器实例。这背后的原理是,不同的加载器实例加载的类被认为是不同的类,即使它们的类名相同。这就相当于在 Java 虚拟机内部创建了一个个相互隔离的 Java 类空间,每一个 Web 应用都有自己的类空间,Web 应用之间通过各自的类加载器互相隔离。
# SharedClassLoader
针对第二个问题:
本质需求是两个 Web 应用之间怎么共享库类,并且不能重复加载相同的类。我们知道,在双亲委派机制里,各个子加载器都可以通过父加载器去加载类,那么把需要共享的类放到父加载器的加载路径下不就行了吗,应用程序也正是通过这种方式共享 JRE 的核心类。因此 Tomcat 的设计者又加了一个类加载器 SharedClassLoader,作为 WebAppClassLoader 的父加载器,专门来加载 Web 应用之间共享的类。如果 WebAppClassLoader 自己没有加载到某个类,就会委托父加载器 SharedClassLoader 去加载这个类,SharedClassLoader 会在指定目录下加载共享类,之后返回给 WebAppClassLoader,这样共享的问题就解决了。
# CatalinaClassloader
如何隔离 Tomcat 本身的类和 Web 应用的类?
要共享可以通过父子关系,要隔离那就需要兄弟关系了。兄弟关系就是指两个类加载器是平行的,它们可能拥有同一个父加载器,但是两个兄弟类加载器加载的类是隔离的。基于此 Tomcat 又设计一个类加载器 CatalinaClassloader,专门来加载 Tomcat 自身的类。这样设计有个问题,那 Tomcat 和各 Web 应用之间需要共享一些类时该怎么办呢?
# CommonClassLoader
老办法,还是再增加一个 CommonClassLoader,作为 CatalinaClassloader 和 SharedClassLoader 的父加载器。CommonClassLoader 能加载的类都可以被 CatalinaClassLoader 和 SharedClassLoader 使用,而 CatalinaClassLoader 和 SharedClassLoader 能加载的类则与对方相互隔离。WebAppClassLoader 可以使用 SharedClassLoader 加载到的类,但各个 WebAppClassLoader 实例之间相互隔离。
# Tomcat 实现 Servlet 规范
Servlet 容器最重要的任务就是创建 Servlet 的实例并且调用 Servlet。
一个 Web 应用里往往有多个 Servlet,而在 Tomcat 中一个 Web 应用对应一个 Context 容器,也就是说一个 Context 容器需要管理多个 Servlet 实例。但 Context 容器并不直接持有 Servlet 实例,而是通过子容器 Wrapper 来管理 Servlet,你可以把 Wrapper 容器看作是 Servlet 的包装。
为什么需要 Wrapper 呢?Context 容器直接维护一个 Servlet 数组不就行了吗?这是因为 Servlet 不仅仅是一个类实例,它还有相关的配置信息,比如它的 URL 映射、它的初始化参数,因此设计出了一个包装器,把 Servlet 本身和它相关的数据包起来,没错,这就是面向对象的思想。
除此以外,Servlet 规范中还有两个重要特性:Listener 和 Filter,Tomcat 也需要创建它们的实例,并在合适的时机去调用它们的方法。
# Servlet 管理
Tomcat 是用 Wrapper 容器来管理 Servlet 的,那 Wrapper 容器具体长什么样子呢?我们先来看看它里面有哪些关键的成员变量:
protected volatile Servlet instance = null;
它拥有一个 Servlet 实例,并且 Wrapper 通过 loadServlet 方法来实例化 Servlet。为了方便你阅读,我简化了代码:
public synchronized Servlet loadServlet() throws ServletException {
Servlet servlet;
//1. 创建一个 Servlet 实例
servlet = (Servlet) instanceManager.newInstance(servletClass);
//2. 调用了 Servlet 的 init 方法,这是 Servlet 规范要求的
initServlet(servlet);
return servlet;
}
其实 loadServlet 主要做了两件事:创建 Servlet 的实例,并且调用 Servlet 的 init 方法,因为这是 Servlet 规范要求的。
那接下来的问题是,什么时候会调到这个 loadServlet 方法呢?为了加快系统的启动速度,我们往往会采取资源延迟加载的策略,Tomcat 也不例外,默认情况下 Tomcat 在启动时不会加载你的 Servlet,除非你把 Servlet 的loadOnStartup参数设置为true。
这里还需要你注意的是,虽然 Tomcat 在启动时不会创建 Servlet 实例,但是会创建 Wrapper 容器,就好比尽管枪里面还没有子弹,先把枪造出来。那子弹什么时候造呢?是真正需要开枪的时候,也就是说有请求来访问某个 Servlet 时,这个 Servlet 的实例才会被创建。
那 Servlet 是被谁调用的呢?我们回忆一下专栏前面提到过 Tomcat 的 Pipeline-Valve 机制,每个容器组件都有自己的 Pipeline,每个 Pipeline 中有一个 Valve 链,并且每个容器组件有一个 BasicValve(基础阀)。Wrapper 作为一个容器组件,它也有自己的 Pipeline 和 BasicValve,Wrapper 的 BasicValve 叫 StandardWrapperValve。
你可以想到,当请求到来时,Context 容器的 BasicValve 会调用 Wrapper 容器中 Pipeline 中的第一个 Valve,然后会调用到 StandardWrapperValve。我们先来看看它的 invoke 方法是如何实现的,同样为了方便你阅读,我简化了代码:
public final void invoke(Request request, Response response) {
//1. 实例化 Servlet
servlet = wrapper.allocate();
//2. 给当前请求创建一个 Filter 链
ApplicationFilterChain filterChain =
ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
//3. 调用这个 Filter 链,Filter 链中的最后一个 Filter 会调用 Servlet
filterChain.doFilter(request.getRequest(), response.getResponse());
}
StandardWrapperValve 的 invoke 方法比较复杂,去掉其他异常处理的一些细节,本质上就是三步:
- 第一步,创建 Servlet 实例;
- 第二步,给当前请求创建一个 Filter 链;
- 第三步,调用这个 Filter 链。
你可能会问,为什么需要给每个请求创建一个 Filter 链?这是因为每个请求的请求路径都不一样,而 Filter 都有相应的路径映射,因此不是所有的 Filter 都需要来处理当前的请求,我们需要根据请求的路径来选择特定的一些 Filter 来处理。
第二个问题是,为什么没有看到调到 Servlet 的 service 方法?这是因为 Filter 链的 doFilter 方法会负责调用 Servlet,具体来说就是 Filter 链中的最后一个 Filter 会负责调用 Servlet。
接下来我们来看 Filter 的实现原理。
# Filter 管理
我们知道,跟 Servlet 一样,Filter 也可以在web.xml文件里进行配置,不同的是,Filter 的作用域是整个 Web 应用,因此 Filter 的实例是在 Context 容器中进行管理的,Context 容器用 Map 集合来保存 Filter。
private Map<String, FilterDef> filterDefs = new HashMap<>();
那上面提到的 Filter 链又是什么呢?Filter 链的存活期很短,它是跟每个请求对应的。一个新的请求来了,就动态创建一个 FIlter 链,请求处理完了,Filter 链也就被回收了。理解它的原理也非常关键,我们还是来看看源码:
public final class ApplicationFilterChain implements FilterChain {
//Filter 链中有 Filter 数组,这个好理解
private ApplicationFilterConfig[] filters = new ApplicationFilterConfig[0];
//Filter 链中的当前的调用位置
private int pos = 0;
// 总共有多少了 Filter
private int n = 0;
// 每个 Filter 链对应一个 Servlet,也就是它要调用的 Servlet
private Servlet servlet = null;
public void doFilter(ServletRequest req, ServletResponse res) {
internalDoFilter(request,response);
}
private void internalDoFilter(ServletRequest req,
ServletResponse res){
// 每个 Filter 链在内部维护了一个 Filter 数组
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
return;
}
servlet.service(request, response);
}
从 ApplicationFilterChain 的源码我们可以看到几个关键信息:
- Filter 链中除了有 Filter 对象的数组,还有一个整数变量 pos,这个变量用来记录当前被调用的 Filter 在数组中的位置。
- Filter 链中有个 Servlet 实例,这个好理解,因为上面提到了,每个 Filter 链最后都会调到一个 Servlet。
- Filter 链本身也实现了 doFilter 方法,直接调用了一个内部方法 internalDoFilter。
- internalDoFilter 方法的实现比较有意思,它做了一个判断,如果当前 Filter 的位置小于 Filter 数组的长度,也就是说 Filter 还没调完,就从 Filter 数组拿下一个 Filter,调用它的 doFilter 方法。否则,意味着所有 Filter 都调到了,就调用 Servlet 的 service 方法。
但问题是,方法体里没看到循环,谁在不停地调用 Filter 链的 doFIlter 方法呢?Filter 是怎么依次调到的呢?
答案是Filter 本身的 doFilter 方法会调用 Filter 链的 doFilter 方法,我们还是来看看代码就明白了:
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain){
...
// 调用 Filter 的方法
chain.doFilter(request, response);
}
注意 Filter 的 doFilter 方法有个关键参数 FilterChain,就是 Filter 链。并且每个 Filter 在实现 doFilter 时,必须要调用 Filter 链的 doFilter 方法,而 Filter 链中保存当前 FIlter 的位置,会调用下一个 FIlter 的 doFilter 方法,这样链式调用就完成了。
Filter 链跟 Tomcat 的 Pipeline-Valve 本质都是责任链模式,但是在具体实现上稍有不同,你可以细细体会一下。
# Listener 管理
我们接着聊 Servlet 规范里 Listener。跟 Filter 一样,Listener 也是一种扩展机制,你可以监听容器内部发生的事件,主要有两类事件:
- 第一类是生命状态的变化,比如 Context 容器启动和停止、Session 的创建和销毁。
- 第二类是属性的变化,比如 Context 容器某个属性值变了、Session 的某个属性值变了以及新的请求来了等。
我们可以在web.xml配置或者通过注解的方式来添加监听器,在监听器里实现我们的业务逻辑。对于 Tomcat 来说,它需要读取配置文件,拿到监听器类的名字,实例化这些类,并且在合适的时机调用这些监听器的方法。
Tomcat 是通过 Context 容器来管理这些监听器的。Context 容器将两类事件分开来管理,分别用不同的集合来存放不同类型事件的监听器:
// 监听属性值变化的监听器
private List<Object> applicationEventListenersList = new CopyOnWriteArrayList<>();
// 监听生命事件的监听器
private Object applicationLifecycleListenersObjects[] = new Object[0];
剩下的事情就是触发监听器了,比如在 Context 容器的启动方法里,就触发了所有的 ServletContextListener:
//1. 拿到所有的生命周期监听器
Object instances[] = getApplicationLifecycleListeners();
for (int i = 0; i < instances.length; i++) {
//2. 判断 Listener 的类型是不是 ServletContextListener
if (!(instances[i] instanceof ServletContextListener))
continue;
//3. 触发 Listener 的方法
ServletContextListener lr = (ServletContextListener) instances[i];
lr.contextInitialized(event);
}
需要注意的是,这里的 ServletContextListener 接口是一种留给用户的扩展机制,用户可以实现这个接口来定义自己的监听器,监听 Context 容器的启停事件。Spring 就是这么做的。ServletContextListener 跟 Tomcat 自己的生命周期事件 LifecycleListener 是不同的。LifecycleListener 定义在生命周期管理组件中,由基类 LifeCycleBase 统一管理。
# Tomcat 支持异步 Servlet
# 异步示例
@WebServlet(urlPatterns = {"/async"}, asyncSupported = true)
public class AsyncServlet extends HttpServlet {
//Web 应用线程池,用来处理异步 Servlet
ExecutorService executor = Executors.newSingleThreadExecutor();
public void service(HttpServletRequest req, HttpServletResponse resp) {
//1. 调用 startAsync 或者异步上下文
final AsyncContext ctx = req.startAsync();
// 用线程池来执行耗时操作
executor.execute(new Runnable() {
@Override
public void run() {
// 在这里做耗时的操作
try {
ctx.getResponse().getWriter().println("Handling Async Servlet");
} catch (IOException e) {}
//3. 异步 Servlet 处理完了调用异步上下文的 complete 方法
ctx.complete();
}
});
}
}
有三个要点:
- 通过注解的方式来注册 Servlet,除了 @WebServlet 注解,还需要加上 asyncSupported=true 的属性,表明当前的 Servlet 是一个异步 Servlet。
- Web 应用程序需要调用 Request 对象的 startAsync 方法来拿到一个异步上下文 AsyncContext。这个上下文保存了请求和响应对象。
- Web 应用需要开启一个新线程来处理耗时的操作,处理完成后需要调用 AsyncContext 的 complete 方法。目的是告诉 Tomcat,请求已经处理完成。
这里请你注意,虽然异步 Servlet 允许用更长的时间来处理请求,但是也有超时限制的,默认是 30 秒,如果 30 秒内请求还没处理完,Tomcat 会触发超时机制,向浏览器返回超时错误,如果这个时候你的 Web 应用再调用ctx.complete方法,会得到一个 IllegalStateException 异常。
# 异步 Servlet 原理
通过上面的例子,相信你对 Servlet 的异步实现有了基本的理解。要理解 Tomcat 在这个过程都做了什么事情,关键就是要弄清楚req.startAsync方法和ctx.complete方法都做了什么。
# startAsync 方法
startAsync 方法其实就是创建了一个异步上下文 AsyncContext 对象,AsyncContext 对象的作用是保存请求的中间信息,比如 Request 和 Response 对象等上下文信息。你来思考一下为什么需要保存这些信息呢?
这是因为 Tomcat 的工作线程在Request.startAsync调用之后,就直接结束回到线程池中了,线程本身不会保存任何信息。也就是说一个请求到服务端,执行到一半,你的 Web 应用正在处理,这个时候 Tomcat 的工作线程没了,这就需要有个缓存能够保存原始的 Request 和 Response 对象,而这个缓存就是 AsyncContext。
有了 AsyncContext,你的 Web 应用通过它拿到 request 和 response 对象,拿到 Request 对象后就可以读取请求信息,请求处理完了还需要通过 Response 对象将 HTTP 响应发送给浏览器。
除了创建 AsyncContext 对象,startAsync 还需要完成一个关键任务,那就是告诉 Tomcat 当前的 Servlet 处理方法返回时,不要把响应发到浏览器,因为这个时候,响应还没生成呢;并且不能把 Request 对象和 Response 对象销毁,因为后面 Web 应用还要用呢。
在 Tomcat 中,负责 flush 响应数据的是 CoyoteAdaptor,它还会销毁 Request 对象和 Response 对象,因此需要通过某种机制通知 CoyoteAdaptor,具体来说是通过下面这行代码:
this.request.getCoyoteRequest().action(ActionCode.ASYNC_START, this);
你可以把它理解为一个 Callback,在这个 action 方法里设置了 Request 对象的状态,设置它为一个异步 Servlet 请求。
我们知道连接器是调用 CoyoteAdapter 的 service 方法来处理请求的,而 CoyoteAdapter 会调用容器的 service 方法,当容器的 service 方法返回时,CoyoteAdapter 判断当前的请求是不是异步 Servlet 请求,如果是,就不会销毁 Request 和 Response 对象,也不会把响应信息发到浏览器。你可以通过下面的代码理解一下,这是 CoyoteAdapter 的 service 方法,我对它进行了简化:
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) {
// 调用容器的 service 方法处理请求
connector.getService().getContainer().getPipeline().
getFirst().invoke(request, response);
// 如果是异步 Servlet 请求,仅仅设置一个标志,
// 否则说明是同步 Servlet 请求,就将响应数据刷到浏览器
if (request.isAsync()) {
async = true;
} else {
request.finishRequest();
response.finishResponse();
}
// 如果不是异步 Servlet 请求,就销毁 Request 对象和 Response 对象
if (!async) {
request.recycle();
response.recycle();
}
}
接下来,当 CoyoteAdaptor 的 service 方法返回到 ProtocolHandler 组件时,ProtocolHandler 判断返回值,如果当前请求是一个异步 Servlet 请求,它会把当前 Socket 的协议处理者 Processor 缓存起来,将 SocketWrapper 对象和相应的 Processor 存到一个 Map 数据结构里。
private final Map<S,Processor> connections = new ConcurrentHashMap<>();
之所以要缓存是因为这个请求接下来还要接着处理,还是由原来的 Processor 来处理,通过 SocketWrapper 就能从 Map 里找到相应的 Processor。
# complete 方法
接着我们再来看关键的ctx.complete方法,当请求处理完成时,Web 应用调用这个方法。那么这个方法做了些什么事情呢?最重要的就是把响应数据发送到浏览器。
这件事情不能由 Web 应用线程来做,也就是说ctx.complete方法不能直接把响应数据发送到浏览器,因为这件事情应该由 Tomcat 线程来做,但具体怎么做呢?
我们知道,连接器中的 Endpoint 组件检测到有请求数据达到时,会创建一个 SocketProcessor 对象交给线程池去处理,因此 Endpoint 的通信处理和具体请求处理在两个线程里运行。
在异步 Servlet 的场景里,Web 应用通过调用ctx.complete方法时,也可以生成一个新的 SocketProcessor 任务类,交给线程池处理。对于异步 Servlet 请求来说,相应的 Socket 和协议处理组件 Processor 都被缓存起来了,并且这些对象都可以通过 Request 对象拿到。
讲到这里,你可能已经猜到ctx.complete是如何实现的了:
public void complete() {
// 检查状态合法性,我们先忽略这句
check();
// 调用 Request 对象的 action 方法,其实就是通知连接器,这个异步请求处理完了
request.getCoyoteRequest().action(ActionCode.ASYNC_COMPLETE, null);
}
我们可以看到 complete 方法调用了 Request 对象的 action 方法。而在 action 方法里,则是调用了 Processor 的 processSocketEvent 方法,并且传入了操作码 OPEN_READ。
case ASYNC_COMPLETE: {
clearDispatches();
if (asyncStateMachine.asyncComplete()) {
processSocketEvent(SocketEvent.OPEN_READ, true);
}
break;
}
我们接着看 processSocketEvent 方法,它调用 SocketWrapper 的 processSocket 方法:
protected void processSocketEvent(SocketEvent event, boolean dispatch) {
SocketWrapperBase<?> socketWrapper = getSocketWrapper();
if (socketWrapper != null) {
socketWrapper.processSocket(event, dispatch);
}
}
而 SocketWrapper 的 processSocket 方法会创建 SocketProcessor 任务类,并通过 Tomcat 线程池来处理:
public boolean processSocket(SocketWrapperBase<S> socketWrapper,
SocketEvent event, boolean dispatch) {
if (socketWrapper == null) {
return false;
}
SocketProcessorBase<S> sc = processorCache.pop();
if (sc == null) {
sc = createSocketProcessor(socketWrapper, event);
} else {
sc.reset(socketWrapper, event);
}
// 线程池运行
Executor executor = getExecutor();
if (dispatch && executor != null) {
executor.execute(sc);
} else {
sc.run();
}
}
请你注意 createSocketProcessor 函数的第二个参数是 SocketEvent,这里我们传入的是 OPEN_READ。通过这个参数,我们就能控制 SocketProcessor 的行为,因为我们不需要再把请求发送到容器进行处理,只需要向浏览器端发送数据,并且重新在这个 Socket 上监听新的请求就行了。