ForkJoin框架
ForkJoin框架
# Java Fork Join 框架
对于简单的并行任务,你可以通过“线程池 +Future”的方案来解决;如果任务之间有聚合关系,无论是 AND 聚合还是 OR 聚合,都可以通过 CompletableFuture 来解决;而批量的并行任务,则可以通过 CompletionService 来解决。
# CompletableFuture
# runAsync 和 supplyAsync 方法
CompletableFuture 提供了四个静态方法来创建一个异步操作。
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
没有指定 Executor 的方法会使用 ForkJoinPool.commonPool() 作为它的线程池执行异步代码。如果指定线程池,则使用指定的线程池运行。以下所有的方法都类同。
- runAsync 方法不支持返回值。
- supplyAsync 可以支持返回值。
# CompletionStage
CompletionStage 接口可以清晰地描述任务之间的时序关系,如串行关系、并行关系、汇聚关系等。
# 串行关系
CompletionStage 接口里面描述串行关系,主要是 thenApply、thenAccept、thenRun 和 thenCompose 这四个系列的接口。
thenApply 系列函数里参数 fn 的类型是接口 Function<T, R>,这个接口里与 CompletionStage 相关的方法是 R apply(T t),这个方法既能接收参数也支持返回值,所以 thenApply 系列方法返回的是CompletionStage。
而 thenAccept 系列方法里参数 consumer 的类型是接口 Consumer<T>,这个接口里与 CompletionStage 相关的方法是 void accept(T t),这个方法虽然支持参数,但却不支持回值,所以 thenAccept 系列方法返回的是CompletionStage<Void>。
thenRun 系列方法里 action 的参数是 Runnable,所以 action 既不能接收参数也不支持返回值,所以 thenRun 系列方法返回的也是CompletionStage<Void>。
这些方法里面 Async 代表的是异步执行 fn、consumer 或者 action。其中,需要你注意的是 thenCompose 系列方法,这个系列的方法会新创建出一个子流程,最终结果和 thenApply 系列是相同的。
# 描述 AND 汇聚关系
CompletionStage 接口里面描述 AND 汇聚关系,主要是 thenCombine、thenAcceptBoth 和 runAfterBoth 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同。
CompletionStage<R> thenCombine(other, fn);
CompletionStage<R> thenCombineAsync(other, fn);
CompletionStage<Void> thenAcceptBoth(other, consumer);
CompletionStage<Void> thenAcceptBothAsync(other, consumer);
CompletionStage<Void> runAfterBoth(other, action);
CompletionStage<Void> runAfterBothAsync(other, action);
# 描述 OR 汇聚关系
CompletionStage 接口里面描述 OR 汇聚关系,主要是 applyToEither、acceptEither 和 runAfterEither 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同。
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
下面的示例代码展示了如何使用 applyToEither() 方法来描述一个 OR 汇聚关系。
CompletableFuture<String> f1 =
CompletableFuture.supplyAsync(()->{
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(()->{
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f3 =
f1.applyToEither(f2,s -> s);
System.out.println(f3.join());
# 异常处理
虽然上面我们提到的 fn、consumer、action 它们的核心方法都不允许抛出可检查异常,但是却无法限制它们抛出运行时异常,例如下面的代码,执行 7/0 就会出现除零错误这个运行时异常。非异步编程里面,我们可以使用 try{}catch{} 来捕获并处理异常,那在异步编程里面,异常该如何处理呢?
CompletableFuture<Integer>
f0 = CompletableFuture.
.supplyAsync(()->(7/0))
.thenApply(r->r*10);
System.out.println(f0.join());
CompletionStage 接口给我们提供的方案非常简单,比 try{}catch{}还要简单,下面是相关的方法,使用这些方法进行异常处理和串行操作是一样的,都支持链式编程方式。
CompletionStage exceptionally(fn);
CompletionStage<R> whenComplete(consumer);
CompletionStage<R> whenCompleteAsync(consumer);
CompletionStage<R> handle(fn);
CompletionStage<R> handleAsync(fn);
下面的示例代码展示了如何使用 exceptionally() 方法来处理异常,exceptionally() 的使用非常类似于 try{}catch{}中的 catch{},但是由于支持链式编程方式,所以相对更简单。既然有 try{}catch{},那就一定还有 try{}finally{},whenComplete() 和 handle() 系列方法就类似于 try{}finally{}中的 finally{},无论是否发生异常都会执行 whenComplete() 中的回调函数 consumer 和 handle() 中的回调函数 fn。whenComplete() 和 handle() 的区别在于 whenComplete() 不支持返回结果,而 handle() 是支持返回结果的。
CompletableFuture<Integer>
f0 = CompletableFuture
.supplyAsync(()->7/0))
.thenApply(r->r*10)
.exceptionally(e->0);
System.out.println(f0.join());
# Fork/Join
Fork/Join 是一个并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。这两部分的关系类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。ForkJoinTask 有两个子类——RecursiveAction 和 RecursiveTask,通过名字你就应该能知道,它们都是用递归的方式来处理分治任务的。这两个子类都定义了抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。这两个子类也是抽象类,在使用的时候,需要你定义子类去扩展。
# ForkJoinPool 工作原理
Fork/Join 并行计算的核心组件是 ForkJoinPool,所以下面我们就来简单介绍一下 ForkJoinPool 的工作原理。
通过专栏前面文章的学习,你应该已经知道 ThreadPoolExecutor 本质上是一个生产者 - 消费者模式的实现,内部有一个任务队列,这个任务队列是生产者和消费者通信的媒介;ThreadPoolExecutor 可以有多个工作线程,但是这些工作线程都共享一个任务队列。
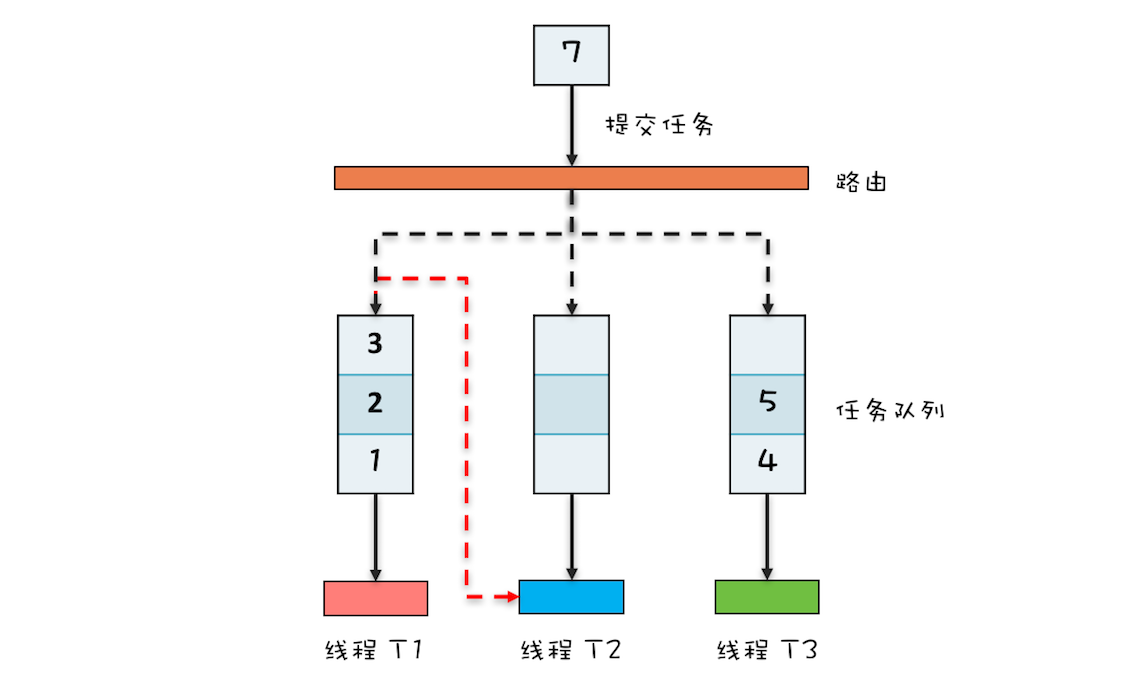
ForkJoinPool 本质上也是一个生产者 - 消费者的实现,但是更加智能,你可以参考下面的 ForkJoinPool 工作原理图来理解其原理。ThreadPoolExecutor 内部只有一个任务队列,而 ForkJoinPool 内部有多个任务队列,当我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
如果工作线程对应的任务队列空了,是不是就没活儿干了呢?不是的,ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务,例如下图中,线程 T2 对应的任务队列已经空了,它可以“窃取”线程 T1 对应的任务队列的任务。如此一来,所有的工作线程都不会闲下来了。
ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别是从任务队列不同的端消费,这样能避免很多不必要的数据竞争。我们这里介绍的仅仅是简化后的原理,ForkJoinPool 的实现远比我们这里介绍的复杂,如果你感兴趣,建议去看它的源码。