复制
【简单】什么是复制?复制有什么作用?
复制是将同一份数据存储在多台机器上,以提升系统的可用性、可靠性和性能。
复制数据,可能出于各种各样的原因:
- 提高可用性:当部分组件出现位障,系统依然可以继续工作,系统依然可以继续工作。
- 降低访问延迟:使数据在地理位置上更接近用户。
- 提高读吞吐量:扩展至多台机器以同时提供数据访问服务。
2024/12/16大约 76 分钟
复制是将同一份数据存储在多台机器上,以提升系统的可用性、可靠性和性能。
复制数据,可能出于各种各样的原因:
分布式系统最重要的抽象之一就是共识(consensus):所有的节点就某一项提议达成一致。
共识问题通常形式化如下:一个或多个节点可以提议(propose) 某些值,而集群中的所有有效节点根据共识算法进行协商,最终决议(decides) 采纳某个节点的提议。
而共识算法必须满足以下性质:
v ,则 v 由某个节点所提议。分区通常是这样定义的,即每一条数据(或者每条记录,每行或每个文档)只属于某个特定分区。实际上,每个分区都可以视为一个完整的小型数据库,虽然数据库可能存在一些跨分区的操作。
在不同系统中,分区有着不同的称呼,例如它对应于 MongoDB, Elasticsearch 和 SolrCloud 中的 shard, HBase 的 region, Bigtable 中的 tablet, Cassandra 和 Riak 中的 vnode ,以及 Couch base 中的 vBucket。总体而言,分区是最普遍的术语。
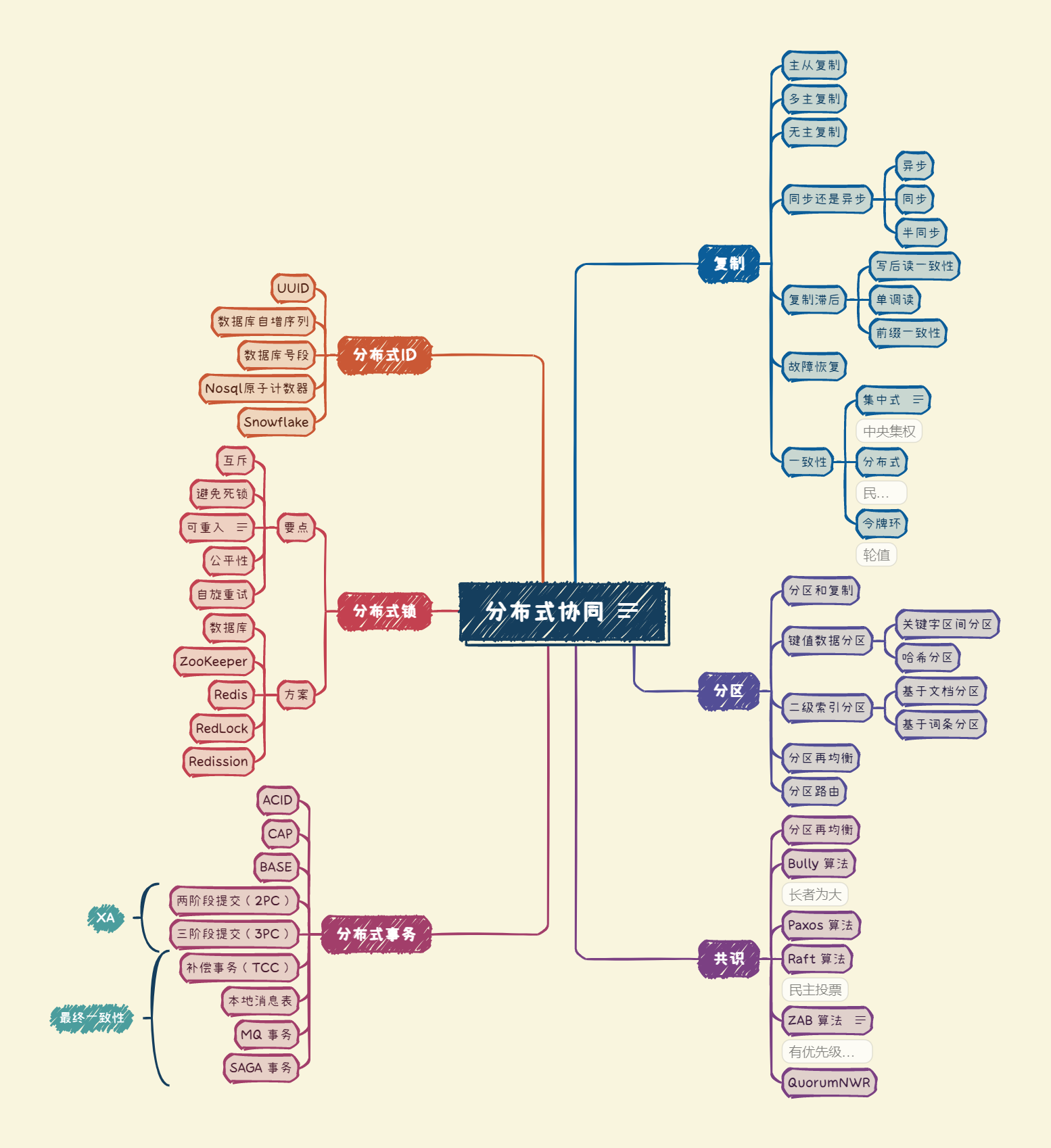
复制主要指通过网络在多台机器上保存相同数据的副本。
复制数据,可能出于各种各样的原因:
复制的模式有以下几种:
为了避免存储在 Zookeeper 上的数据被其他程序或者人为误修改,Zookeeper 提供了 ACL(Access Control Lists) 进行权限控制。
ACL 权限可以针对节点设置相关读写等权限,保障数据安全性。
ZooKeeper ACL 提供了以下几种命令行:
ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。
ZooKeeper 主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储。但是 ZooKeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控存储数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
很多大名鼎鼎的框架都基于 ZooKeeper 来实现分布式高可用,如:Dubbo、Kafka 等。
ZooKeeper 官方支持 Java 和 C 的 Client API。ZooKeeper 社区为大多数语言(.NET,python 等)提供非官方 API。
ZooKeeper 命令用于在 ZooKeeper 服务上执行操作。
# 启动服务
bin/zkServer.sh start
# 启动命令行,不指定服务地址则默认连接到localhost:2181
bin/zkCli.sh -server hadoop001:2181ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。
ZooKeeper 主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储。但是 ZooKeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控存储数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
很多大名鼎鼎的框架都基于 ZooKeeper 来实现分布式高可用,如:Dubbo、Kafka 等。
ZooKeeper 官方支持 Java 和 C 的 Client API。ZooKeeper 社区为大多数语言(.NET,python 等)提供非官方 API。
ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。
ZooKeeper 主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储。但是 ZooKeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控存储数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
很多大名鼎鼎的框架都基于 ZooKeeper 来实现分布式高可用,如:Dubbo、Kafka 等。
ZooKeeper 官方支持 Java 和 C 的 Client API。ZooKeeper 社区为大多数语言(.NET,python 等)提供非官方 API。