分布式协同面试
复制
【基础】什么是复制?复制有什么作用?
要点
复制主要指通过网络在多台机器上保存相同数据的副本。
复制数据,可能出于各种各样的原因:
- 提高可用性 - 当部分组件出现位障,系统依然可以继续工作,系统依然可以继续工作。
- 降低访问延迟 - 使数据在地理位置上更接近用户。
- 提高读吞吐量 - 扩展至多台机器以同时提供数据访问服务。
...大约 72 分钟
复制主要指通过网络在多台机器上保存相同数据的副本。
复制数据,可能出于各种各样的原因:
分布式系统最重要的抽象之一就是共识(consensus):所有的节点就某一项提议达成一致。
共识问题通常形式化如下:一个或多个节点可以提议(propose) 某些值,而集群中的所有有效节点根据共识算法进行协商,最终决议(decides) 采纳某个节点的提议。
而共识算法必须满足以下性质:
v ,则 v 由某个节点所提议。分区通常是这样定义的,即每一条数据(或者每条记录,每行或每个文档)只属于某个特定分区。实际上,每个分区都可以视为一个完整的小型数据库,虽然数据库可能存在一些跨分区的操作。
在不同系统中,分区有着不同的称呼,例如它对应于 MongoDB, Elasticsearch 和 SolrCloud 中的 shard, HBase 的 region, Bigtable 中的 tablet, Cassandra 和 Riak 中的 vnode ,以及 Couch base 中的 vBucket。总体而言,分区是最普遍的术语。
复制主要指通过网络在多台机器上保存相同数据的副本。
复制数据,可能出于各种各样的原因:
复制的模式有以下几种:
从故障影响范围维度来看,分布式系统的故障可以分为三类:
ID 是 Identity 的缩写,用于唯一的标识一条数据。分布式 ID,顾名思义,是用于在分布式系统中唯一标识数据的 ID。
传统数据库基本都支持针对单表生成唯一性的自增主键。随着数据的膨胀,单机成为了性能和容量的瓶颈。为了解决这个问题,有了分库分表技术。分库分表所要面临的第一个问题是:数据分布在不同机器上,数据库无法保证多个节点上产生的主键唯一。 这就需要用到分布式 ID 了,它起到了分布式系统中全局 ID 的作用。
在数据存储环境中,可能会出现各种各样的问题:
由于 Http 是一种无状态的协议,服务器单单从网络连接上无从知道客户身份。
会话跟踪是 Web 程序中常用的技术,用来跟踪用户的整个会话。常用会话跟踪技术是 Cookie 与 Session。
由于 Http 是一种无状态的协议,服务器单从网络连接上无从知道客户身份。
所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。
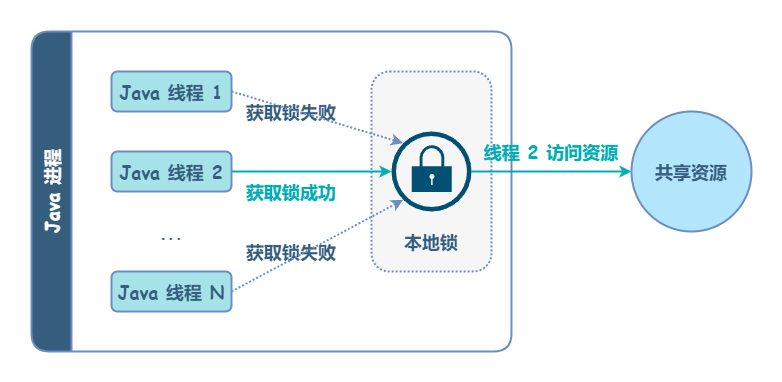
在计算机科学中,锁是在并发场景下用于强行限制资源访问的一种同步机制,即用于在并发控制中通过互斥手段来保证数据同步安全。
在 Java 进程中,可以使用 Lock、synchronized 等来支持并发锁。如果是同一台机器的不同进程,想要同时操作一个共享资源(例如修改同一个文件),可以使用操作系统提供的「文件锁」或「信号量」来做互斥。这些发生在同一台机器上的互斥操作,可以称为本地锁。