RabbitMQ 简介
【简单】RabbitMQ 是什么?⭐
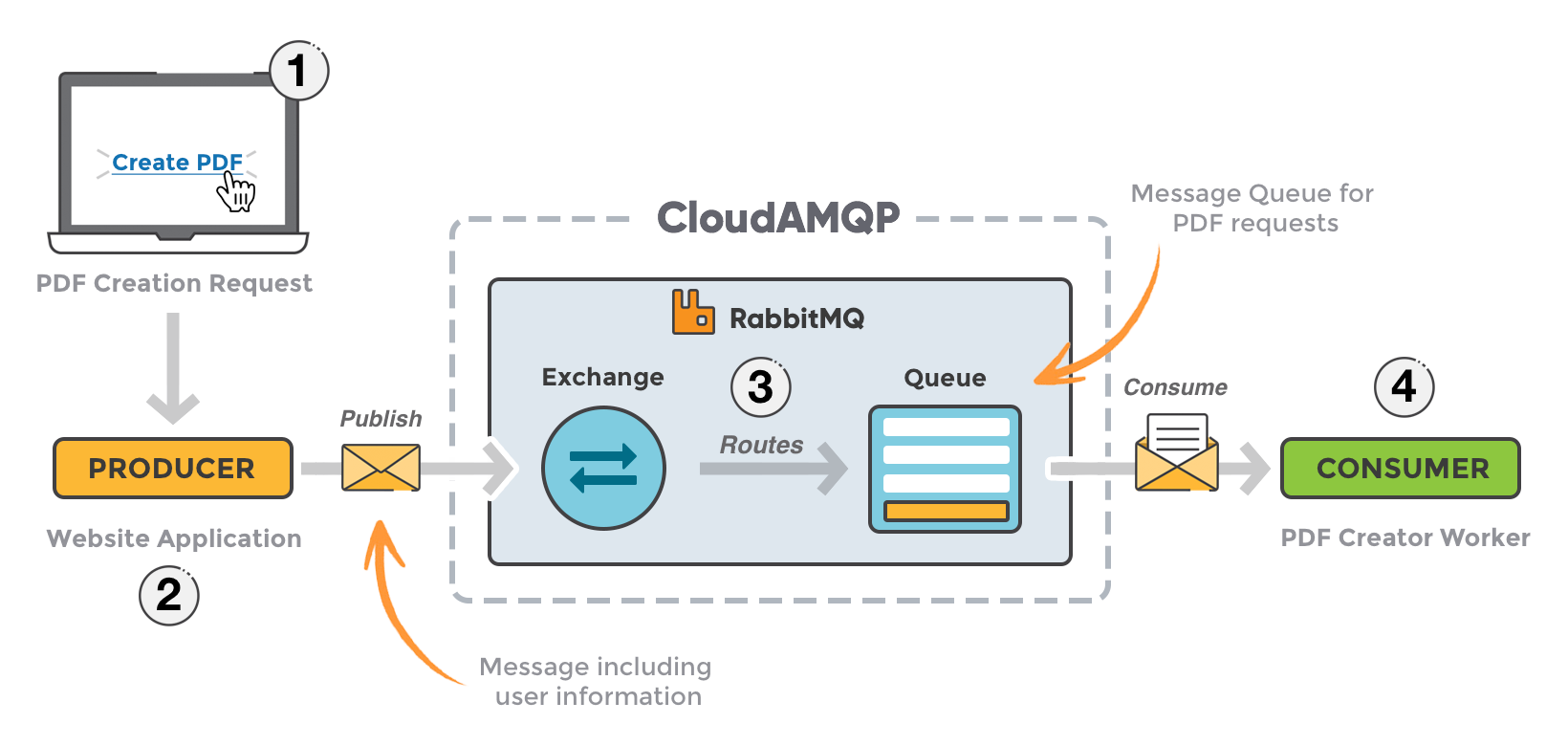
RabbitMQ 是一个开源的消息队列中间件,基于 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)标准实现。
2025/9/19大约 44 分钟
RabbitMQ 是一个开源的消息队列中间件,基于 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)标准实现。
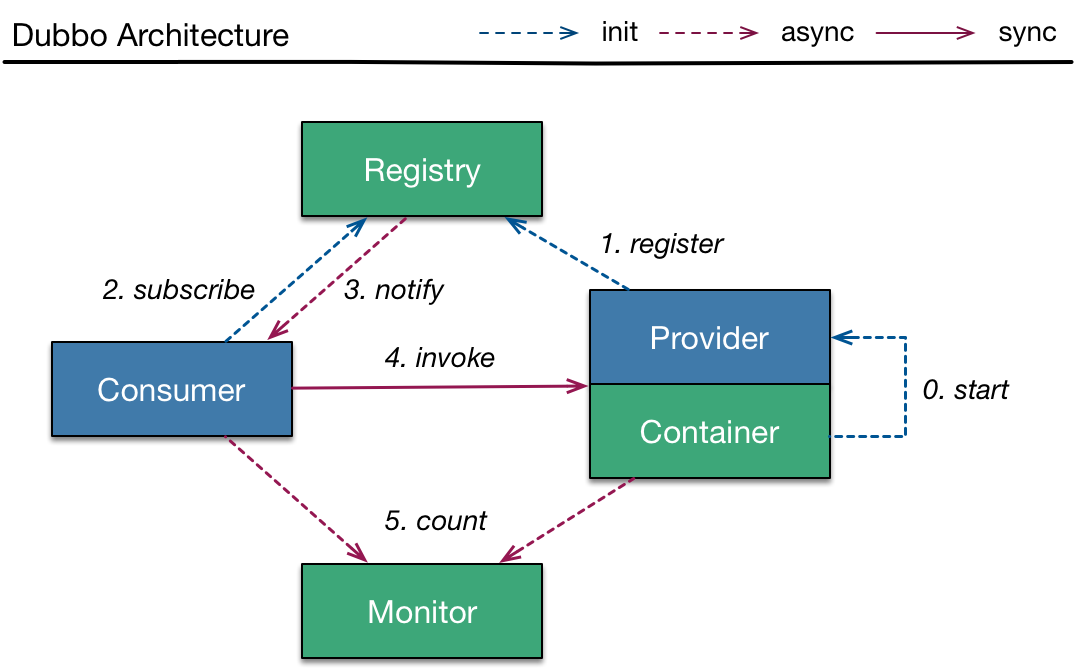
Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。
Dubbo 提供了三大核心能力:
什么是服务注册与发现?
服务注册与发现是微服务的核心基础设施,通过解耦服务地址硬编码,实现动态扩缩容和故障自动恢复。
订单服务启动后,向注册中心注册:"order-service: 192.168.1.100:8080"。支付服务需要调用订单服务时,从注册中心获取所有可用的order-service节点列表。
设计消息引擎的关键点:
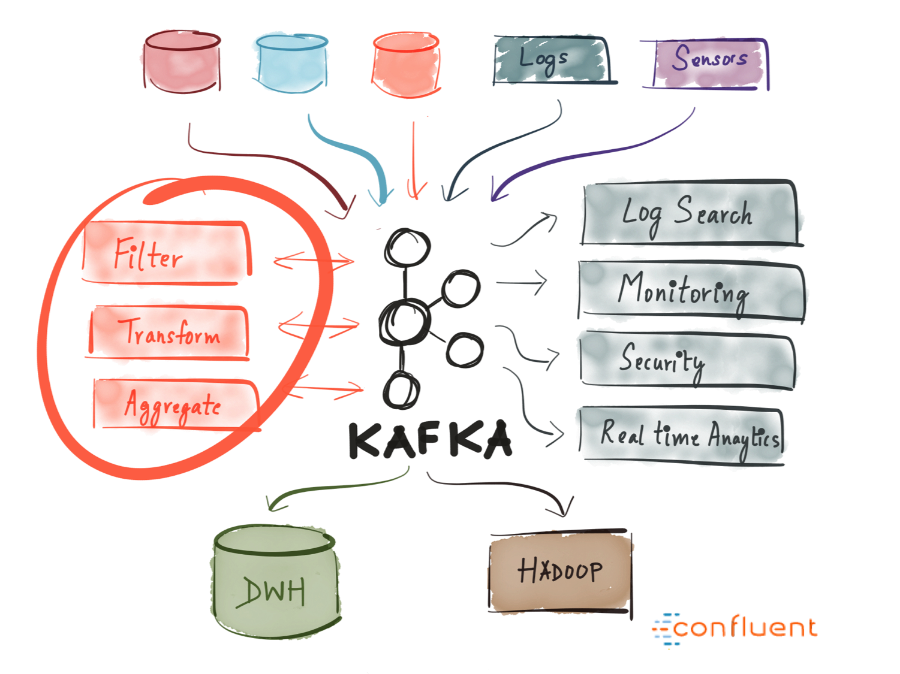
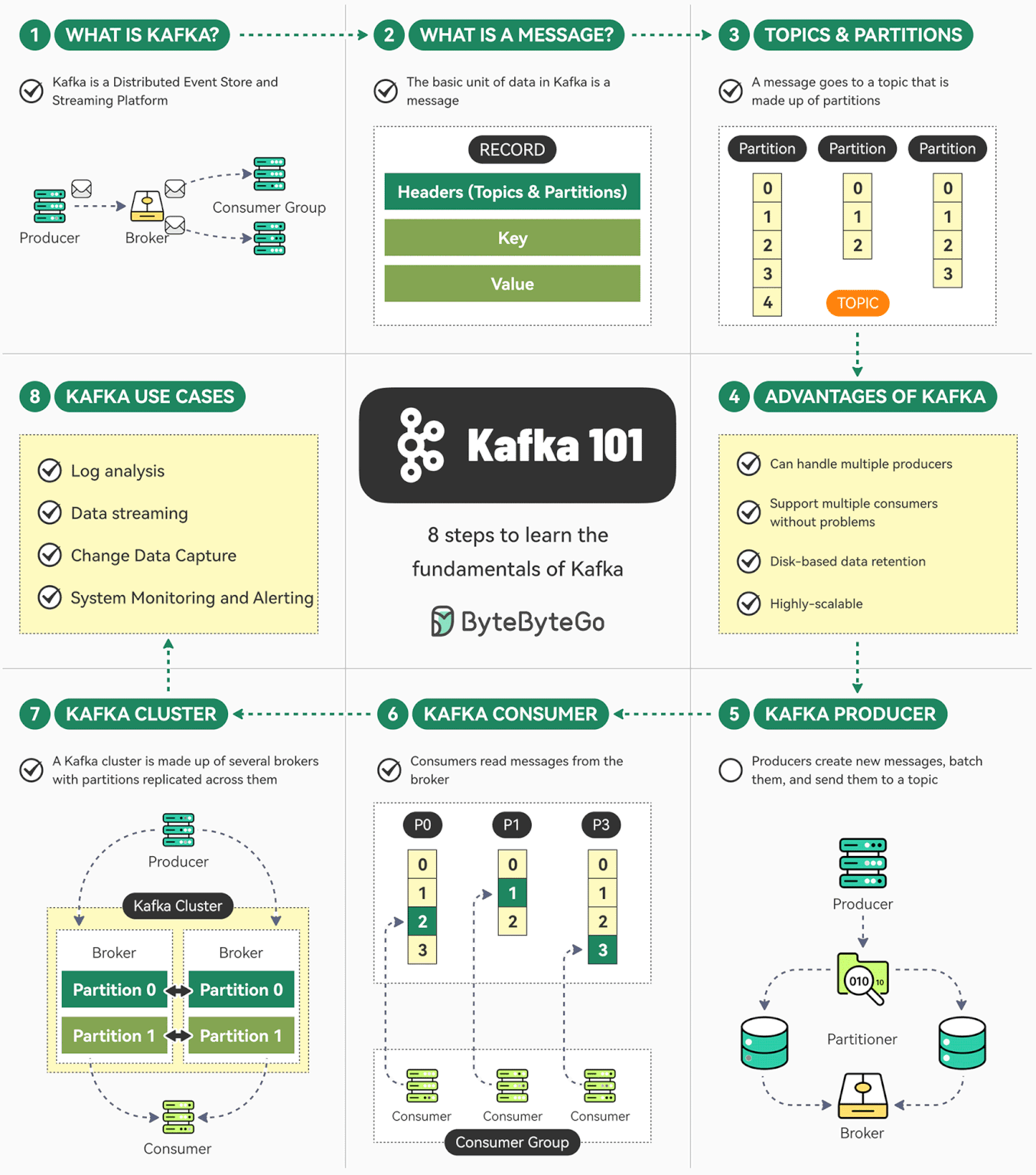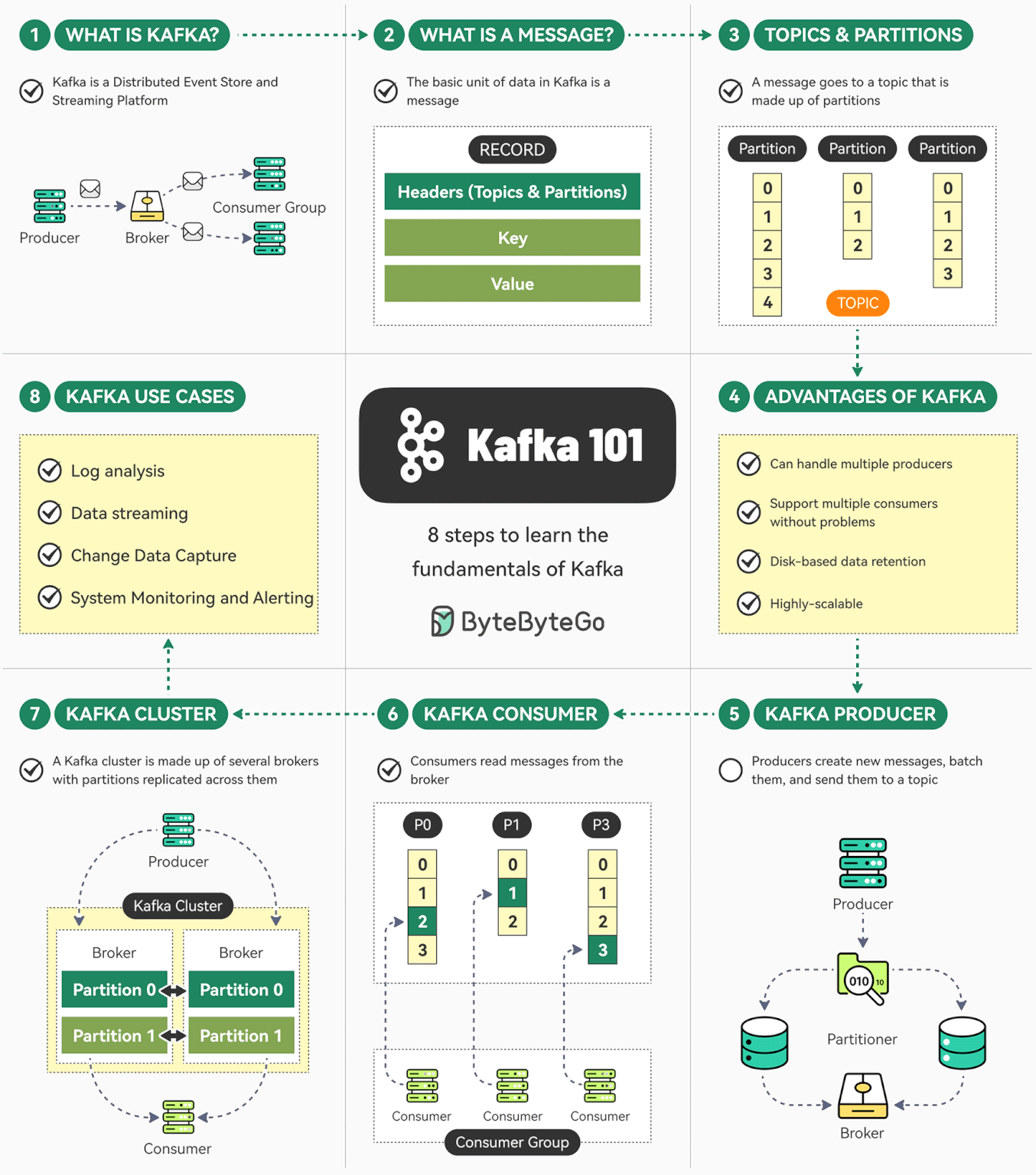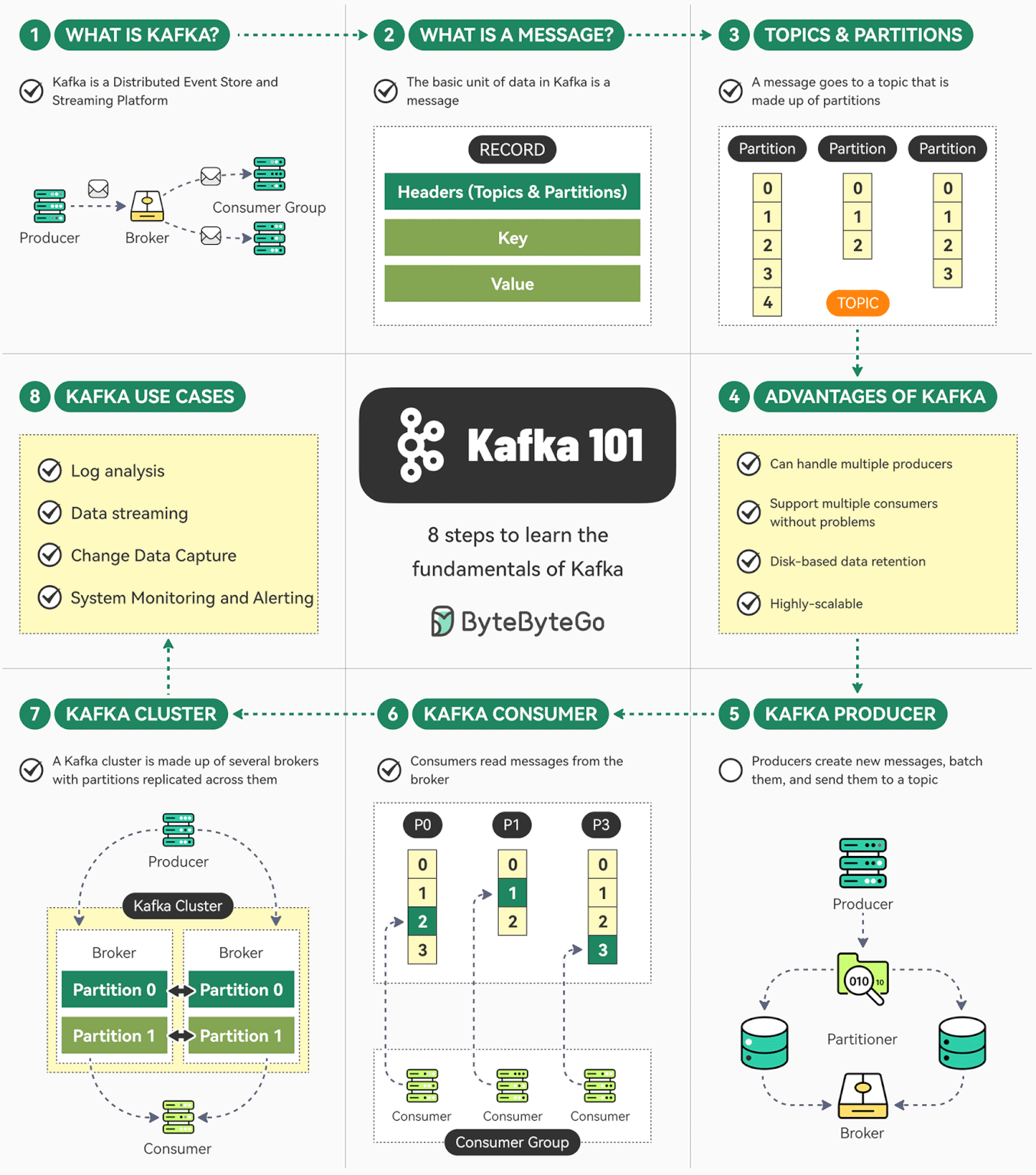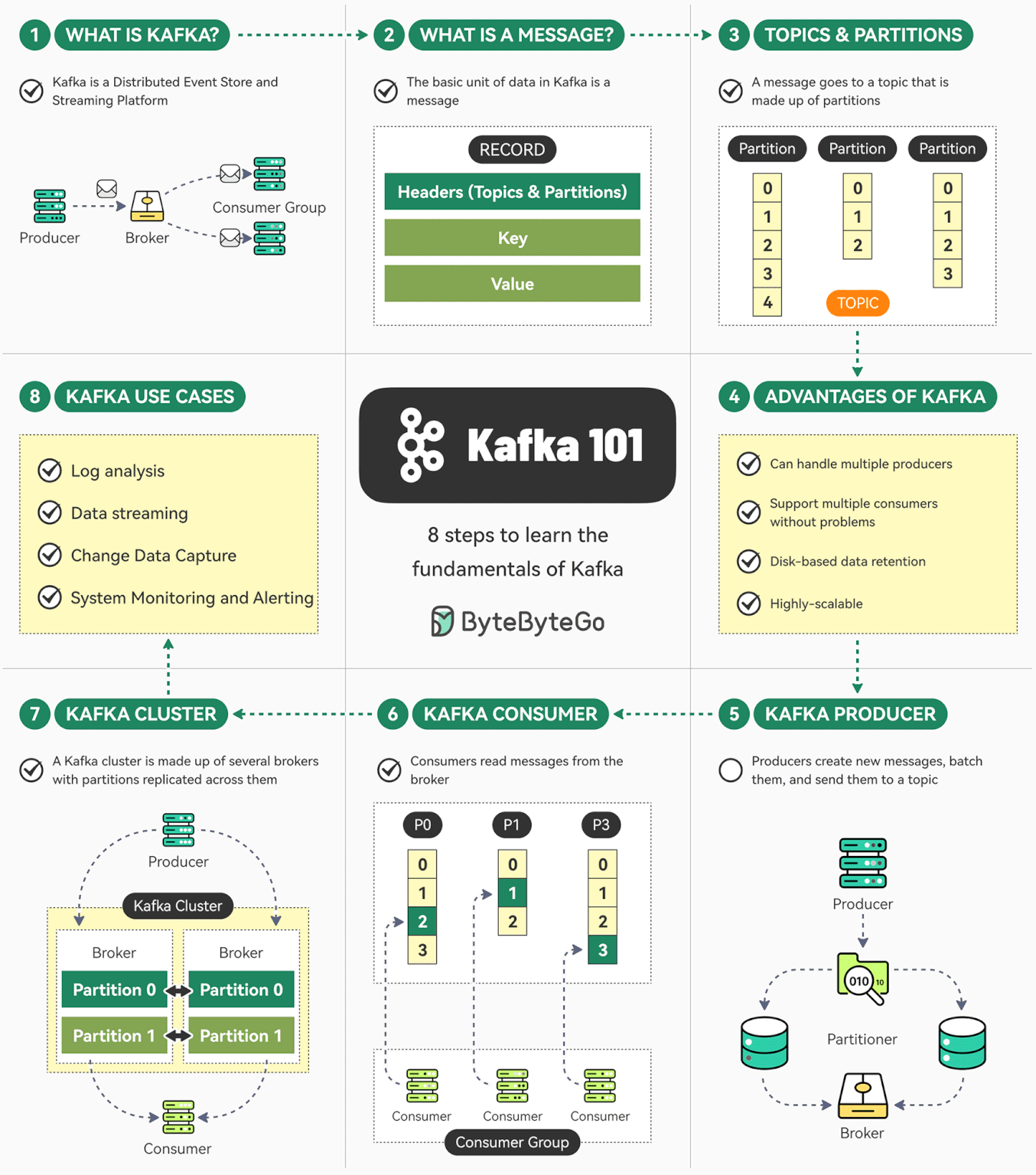
Kafka 是一个开源分布式事件流平台。最初由 LinkedIn 开发,现在是 Apache 顶级项目。
RPC 的全称是 Remote Procedure Call,即远程过程调用。
RPC 的主要作用是:
RPC 是微服务架构的基石,它提供了一种应用间通信的方式。
broker:Broker 模块(Broker 启动进程)client:消息客户端(生产者、消费者)common:公共包namesrv:NameServer 实现(NameServer 启动进程)remoting:远程通信模块(基于 Netty)store:消息存储实现tools:工具类、监控命令RocketMQ 是一个开源分布式消息中间件。最初由阿里巴巴开发,现在是 Apache 顶级项目。
RocketMQ 的核心概念