HBase 简介
【简单】什么是 HBase?
要点
HBase 是一个构建在 HDFS(Hadoop 文件系统)之上的列式数据库。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。
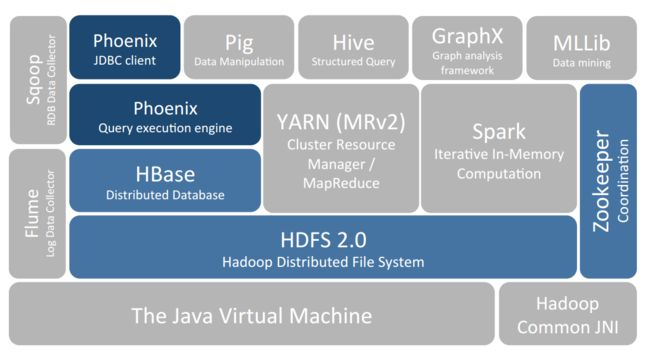
HBase 的核心特性如下:
- 分布式
- 伸缩性:支持通过增减机器进行水平扩展,以提升整体容量和性能
- 高可用:支持 RegionServers 之间的自动故障转移
- 自动分区:Region 分散在集群中,当行数增长的时候,Region 也会自动的分区再均衡
- 超大数据集:HBase 被设计用来读写超大规模的数据集(数十亿行至数百亿行的表)
- 支持结构化、半结构化和非结构化的数据:由于 HBase 基于 HDFS 构建,所以和 HDFS 一样,支持结构化、半结构化和非结构化的数据
- 非关系型数据库
- 不支持标准 SQL 语法
- 没有真正的索引
- 不支持复杂的事务:只支持行级事务,即单行数据的读写都是原子性的
HBase 的其他特性
- 读写操作遵循强一致性
- 过滤器支持谓词下推
- 易于使用的 Java 客户端 API
- 它支持线性和模块化可扩展性。
- HBase 表支持 Hadoop MapReduce 作业的便捷基类
- 很容易使用 Java API 进行客户端访问
- 为实时查询提供块缓存 BlockCache 和布隆过滤器
- 它通过服务器端过滤器提供查询谓词下推
2025/3/4大约 13 分钟