数据类型
2025/9/1大约 22 分钟

“索引”是数据库为了提高查找效率的一种数据结构。
日常生活中,我们可以通过检索目录,来快速定位书本中的内容。索引和数据表,就好比目录和书,想要高效查询数据表,索引至关重要。在数据量小且负载较低时,不恰当的索引对于性能的影响可能还不明显;但随着数据量逐渐增大,性能则会急剧下降。因此,设置合理的索引是数据库查询性能优化的最有效手段。
✔️️️️️️️️ 索引的优点:
概述
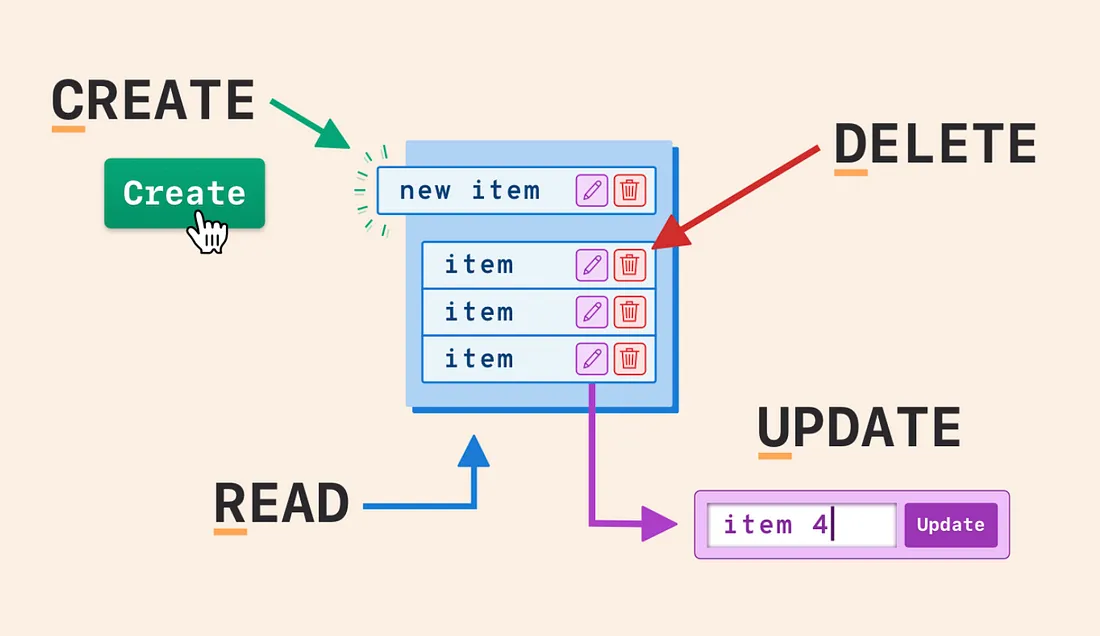
CRUD 由英文单词 Create, Read, Update, Delete 的首字母组成,即增删改查。
本文通过介绍基本的 MySQL CRUD 方法,向读者呈现如何访问 MySQL 数据。
扩展阅读:SQL 语法必知必会
概述
数据类型在 MySQL 中扮演着至关重要的角色,它定义了表中每个字段可以存储的数据种类和格式。
MySQL 支持多种类型,大致可以分为三类:数值、时间和字符串类型。

概述
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL 是最好的 RDBMS 应用软件之一。
本文简单介绍了 MySQL 的功能、特性、发行版本、简史、概念,可以让读者在短时间内对于 MySQL 有一个初步的认识。

HBase 是一个构建在 HDFS(Hadoop 文件系统)之上的列式数据库。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。
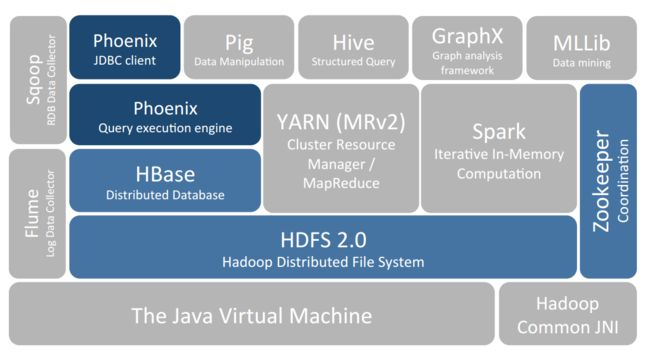
HBase 的核心特性如下:
HBase 的其他特性
ES 存储数据的流程可以从三个角度来阐述: