
MongoDB 聚合
概述
聚合操作处理多个文档并返回计算结果。可以使用聚合操作来:
- 将多个文档中的值组合在一起。
- 对分组数据执行操作,返回单一结果。
- 分析一段时间内的数据变化。
在 MongoDB 中,支持以下聚合方式:
- 聚合管道,这是执行聚合的首选方法。
- 单一目的聚合方法,这些方法很简单,但缺乏聚合管道的功能。
- Map-Reduce,从 MongoDB 5.0 开始,Map-Reduce 已被弃用。聚合管道提供的性能和可用性比 Map-Reduce 更优越。
本文将逐一介绍这三种聚合方式的要点和使用方法。
聚合管道简介
聚合管道由一个或多个处理文档的 阶段 组成:
- 每个阶段对输入文档执行一个操作。例如,某个阶段可以过滤文档、对文档进行分组并计算值。
- 从一个阶段输出的文档将传递到下一阶段。
- 一个聚合管道可以返回针对文档组的结果。例如,返回总值、平均值、最大值和最小值。
如使用 通过聚合管道更新 中显示的阶段,则可以通过聚合管道更新文档。
注意:使用
db.collection.aggregate()方法运行的聚合管道不会修改集合中的文档,除非管道包含$merge或$out阶段。
阶段 的其他要点:
- 阶段不必为每个输入文档输出一个文档。例如,某些阶段可能会产生新文档或过滤掉现有文档。
- 同一个阶段可以在管道中多次出现,但以下阶段例外:
$out、$merge和$geoNear。 - 要在阶段中计算平均值和执行其他计算,请使用指定 聚合操作符 的 聚合表达式。
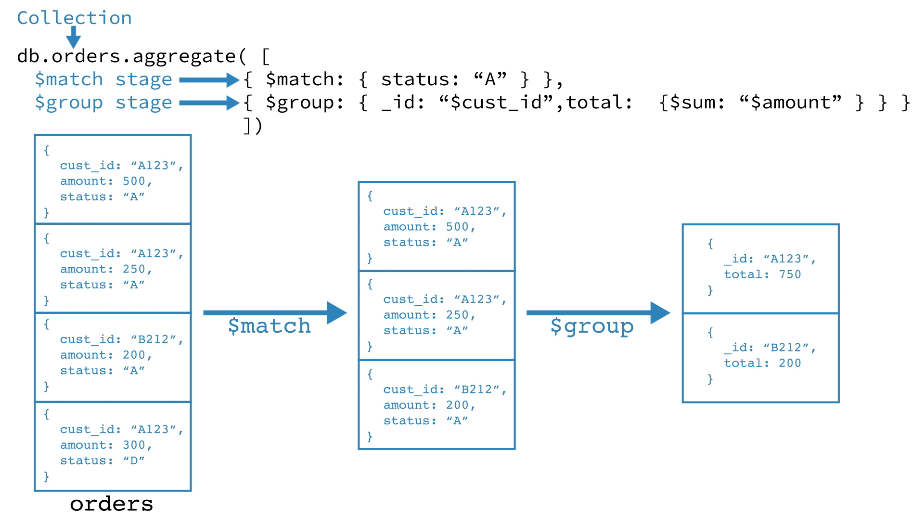
下面是一个聚合管道示例:
【示例】计算总订单数量
以下聚合管道示例包含两个 阶段,并返回按披萨名称分组后,各款中号披萨的总订单数量:
db.orders.aggregate([
// Stage 1: 根据 size 过滤订单
{
$match: { size: 'medium' }
},
// Stage 2: 按名称对剩余文档进行分组,并计算总数量
{
$group: { _id: '$name', totalQuantity: { $sum: '$quantity' } }
}
])
$match 阶段:
- 从披萨订单文档过滤出
size为medium的披萨。 - 将剩余文档传递到
$group阶段。
$group 阶段:
- 按披萨
name对剩余文档进行分组。 - 使用
$sum计算每种披萨name的总订单quantity。总数存储在聚合管道返回的totalQuantity字段中。
扩展:有关包含样本输入文档的可运行示例,请参阅 完整聚合管道示例。
字段路径
字段路径 表达式用于访问权限输入文档中的字段。要指定字段路径,请在字段名称或 虚线字段路径(如果该字段位于嵌入式文档中)前添加美元符号 $。例如,用 "$user" 指定 user 字段的字段路径,或用 "$user.name" 指定嵌入式 "user.name" 字段的字段路径。
"{0}lt;field>" 等效于 "$CURRENT.<field>",其中 CURRENT 为系统变量,而它默认为当前对象的根(除非在特定阶段另行说明)。
聚合管道优化
聚合管道操作包含一个优化阶段,该阶段会尝试重塑管道以提高性能。
要查看优化器如何转换特定的聚合管道,请在 db.collection.aggregate() 方法中添加 explain 选项。
优化可能因版本而异。
投影优化
聚合管道可确定是否只需文档中的部分字段即可获取结果。如果是,管道则仅会使用这些字段,从而减少通过管道传递的数据量。
使用 $project 阶段时,通常应该是管道的最后一个阶段,用于指定要返回给客户端的字段。在管道的开头或中间使用 $project 阶段来减少传递到后续管道阶段的字段数量不太可能提高性能,因为数据库会自动执行此优化。
管道序列优化
($project、$unset、$addFields、$set) + $match 序列优化
如果聚合管道包含投影阶段 ($addFields、$project、$set 或 $unset),且其后跟随 $match 阶段,MongoDB 会将 $match 阶段中无需使用投影阶段计算的值的所有过滤器移动到投影前的新的 $match 阶段。
如果聚合管道包含多个投影或 $match 阶段,MongoDB 会对每个 $match 阶段执行此优化,将每个 $match 过滤器移到过滤器不依赖的所有投影阶段之前。
【示例】管道序列优化示例
优化前:
{
$addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
}
},
{
$project: {
_id: 1,
name: 1,
times: 1,
maxTime: 1,
minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
}
},
{
$match: {
name: "Joe Schmoe",
maxTime: { $lt: 20 },
minTime: { $gt: 5 },
avgTime: { $gt: 7 }
}
}
优化器会将 $match 阶段分解为四个单独的过滤器,每个过滤器对应 $match 查询文档中的一个键。然后,优化器会将每个过滤器移至尽可能多的投影阶段之前,从而按需创建新的 $match 阶段。
优化后:
{ $match: { name: "Joe Schmoe" } },
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: { avgTime: { $gt: 7 } } }
$match 筛选器 { avgTime: { $gt: 7 } } 依赖 $project 阶段来计算 avgTime 字段。$project 阶段是该管道中的最后一个投影阶段,因此 avgTime 上的 $match 筛选器无法移动。
maxTime 和 minTime 字段在 $addFields 阶段计算,但不依赖 $project 阶段。优化器已为这些字段上的筛选器创建一个新的 $match 阶段,并将其置于 $project 阶段之前。
$match 筛选器 { name: "Joe Schmoe" } 不使用在 $project 或 $addFields 阶段计算的任何值,因此它在这两个投影阶段之前移到了新的 $match 阶段。
优化后,筛选器 { name: "Joe Schmoe" } 在管道开始时会处于 $match 阶段。此举还允许聚合在最初查询该集合时使用针对 name 字段的索引。
$sort + $match 序列优化
当序列中的 $sort 后面是 $match 时,$match 会在 $sort 之前移动,以最大限度地减少要排序的对象数量。例如,如果管道由以下阶段组成:
{ $sort: { age : -1 } },
{ $match: { status: 'A' } }
在优化阶段,优化器会将序列转换为以下内容:
{ $match: { status: 'A' } },
{ $sort: { age : -1 } }
$redact + $match 序列优化
如果可能,当管道有 $redact 阶段紧接着 $match 阶段时,聚合有时可以在 $redact 阶段之前添加 $match 阶段的一部分。如果添加的 $match 阶段位于管道的开头,则聚合可以使用索引并查询集合以限制进入管道的文档数量。有关更多信息,请参阅 使用索引和文档过滤器提高性能。
例如,如果管道由以下阶段组成:
{ $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } },
{ $match: { year: 2014, category: { $ne: "Z" } } }
优化器可以在 $redact 阶段之前添加相同的 $match 阶段:
{ $match: { year: 2014 } },
{ $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } },
{ $match: { year: 2014, category: { $ne: "Z" } } }
$project/$unset + $skip 序列优化
如果序列中的 $project 或 $unset 后面是 $skip,则 $skip 在 $project 之前移动。例如,如果管道由以下阶段组成:
{ $sort: { age : -1 } },
{ $project: { status: 1, name: 1 } },
{ $skip: 5 }
在优化阶段,优化器会将序列转换为以下内容:
{ $sort: { age : -1 } },
{ $skip: 5 },
{ $project: { status: 1, name: 1 } }
管道合并优化
在可能的情况下,优化阶段将管道阶段合并到其前置阶段中。通常,合并发生在任何序列重新排序优化之后。
$sort + $limit 合并
当 $sort 在 $limit 之前时,如果没有干预阶段(例如 $unwind、$group)修改文档的数量,则优化器可以将 $limit 阶段合并到 $sort。如果有管道阶段更改了 $sort 和 $limit 阶段之间的文档数量,则 MongoDB 不会将 $limit 合并到 $sort 中。
例如,如果管道由以下阶段组成:
{ $sort : { age : -1 } },
{ $project : { age : 1, status : 1, name : 1 } },
{ $limit: 5 }
在优化阶段,优化器会将此序列合并为以下内容:
{
"$sort" : {
"sortKey" : {
"age" : -1
},
"limit" : NumberLong(5)
}
},
{ "$project" : {
"age" : 1,
"status" : 1,
"name" : 1
}
}
此操作可让排序操作在推进时仅维护前 n 个结果,其中 n 为指定的限制,而 MongoDB 仅需要在内存中存储 n 个项目 [1]。有关更多信息,请参阅 $sort 操作符和内存。
$limit + $limit 合并
当 $limit 紧随另一个 $limit 时,这两个阶段可以合并为一个 $limit,以两个初始限额中较小的为合并后的限额。例如,一个管道包含以下序列:
{ $limit: 100 },
{ $limit: 10 }
然后第二个 $limit 阶段可以合并到第一个 $limit 阶段,形成一个 $limit 阶段,新阶段的限额 10 是两个初始限额 100 和 10 中的较小者。
{
$limit: 10
}
$skip + $skip 合并
当 $skip 紧随在另一个 $skip 之后时,这两个阶段可以合并为一个 $skip,其中的跳过数量是两个初始跳过数量的总和。例如,一个管道包含以下序列:
{ $skip: 5 },
{ $skip: 2 }
然后第二个 $skip 阶段可以合并到第一个 $skip 阶段,形成一个 $skip 阶段,新阶段的跳过数量 7 是两个初始限额 5 和 2 的总和。
{
$skip: 7
}
$match + $match 合并
当 $match 紧随另一个 $match 之后时,这两个阶段可以合并为一个 $match,用 $and 将条件组合在一起。例如,一个管道包含以下序列:
{ $match: { year: 2014 } },
{ $match: { status: "A" } }
然后第二个 $match 阶段可合并到第一个 $match 阶段并形成一个 $match 阶段
{
$match: {
$and: [{ year: 2014 }, { status: 'A' }]
}
}
$lookup、$unwind 和 $match Coalescence
当 $unwind 紧随 $lookup,且 $unwind 在 $lookup 的 as 字段上运行时,优化器将 $unwind 合并到 $lookup 阶段。这样可以避免创建大型中间文档。此外,如果 $unwind 后接 $lookup 的任意 as 子字段上的 $match,则优化器也会合并 $match。
例如,一个管道包含以下序列:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y"
}
},
{ $unwind: "$resultingArray" },
{ $match: {
"resultingArray.foo": "bar"
}
}
优化器将 $unwind 和 $match 阶段合并到 $lookup 阶段。如果使用 explain 选项运行聚合,explain 输出将显示合并阶段:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y",
let: {},
pipeline: [
{
$match: {
"foo": {
"$eq": "bar"
}
}
}
],
unwinding: {
"preserveNullAndEmptyArrays": false
}
}
}
您可以在 解释计划 中查看此优化后的管道。
聚合管道限制
- 结果大小限制 -
aggregate命令既可以返回一个游标,也可以将结果存储在集合中。结果集中的每个文档存在 16 MB 的 BSON 文档大小限制。如果任何单个文档超过 BSON 文档大小限制,则聚合会产生错误。该限制仅适用于返回的文档。在管道处理过程中,文档可能会超过此大小。db.collection.aggregate()方法默认返回一个游标。 - 阶段数量限制 - MongoDB 5.0 将单个管道中允许的 聚合管道阶段 限制为 1000 个。如果聚合管道在解析之前或之后超过阶段限制,会收到错误消息。
- 内存限制 - 从 MongoDB 6.0 开始,
allowDiskUseByDefault参数可控制需要 100 MB 以上内存容量来执行的管道阶段是否默认会将临时文件写入磁盘。- 如果将
allowDiskUseByDefault设为true,则默认情况下,需要 100 MB 以上内存容量的管道阶段会将临时文件写入磁盘。您可以使用{ allowDiskUse: false }选项来为特定的find或aggregate命令禁用将临时文件写入磁盘的功能。 - 如果
allowDiskUseByDefault设置为false,则默认情况下,需要超过 100 MB 的内存才能执行的管道阶段会引发错误。您可以使用{ allowDiskUse: true }选项来为特定find或aggregate启用向磁盘写入临时文件的功能。
- 如果将
聚合管道和分片集合
聚合管道支持针对 分片 集合的操作。
如果管道严格以 $match 开头(位于 分片键 上),并且管道不包含 $out 或 $lookup 阶段,则整个管道都只在匹配的分片上运行。
当聚合操作在多个分片上运行时,结果会被路由到 mongos 进行合并,以下情况除外:
- 如果管道集合
$out阶段,则合并在输出分片所在的分片上运行。 - 如果管道集合引用未分片集合的
$lookup阶段,则合并将在未分片分片所在的分片上运行。 - 如果管道包含排序或分组阶段,且启用了 allowDiskUse 设置,则合并会在随机选择的分片上运行。
单一目的聚合方法
MongoDB 支持以下单一目的的聚合操作:
db.collection.estimatedDocumentCount()- 返回集合或视图中文档的近似数量db.collection.count()- 返回集合或视图中文档的数量db.collection.distinct()- 返回具有指定字段的不同值的文档数组
所有这些操作都汇总了单个 collection 中的 document。尽管这些操作提供了对常见聚合过程的简单访问,但是它们相比聚合 pipeline 和 Map-Reduce,缺少灵活性和丰富的功能性。

RDBM 聚合 vs. MongoDB 聚合
MongoDB pipeline 提供了许多等价于 SQL 中常见聚合语句的操作。 下表概述了常见的 SQL 聚合语句或函数和 MongoDB 聚合操作的映射表:
| RDBM 操作 | MongoDB 聚合操作 |
|---|---|
WHERE | $match |
GROUP BY | $group |
HAVING | $match |
SELECT | $project |
ORDER BY | $sort |
LIMIT | $limit |
SUM() | $sum |
COUNT() | $sum$sortByCount |
JOIN | $lookup |
SELECT INTO NEW_TABLE | $out |
MERGE INTO TABLE | $merge (Available starting in MongoDB 4.2) |
UNION ALL | $unionWith (Available starting in MongoDB 4.4) |
RDBM 聚合 vs. MongoDB 聚合:

【示例】
db.orders.insertMany([
{
_id: 1,
cust_id: 'Ant O. Knee',
ord_date: new Date('2020-03-01'),
price: 25,
items: [
{ sku: 'oranges', qty: 5, price: 2.5 },
{ sku: 'apples', qty: 5, price: 2.5 }
],
status: 'A'
},
{
_id: 2,
cust_id: 'Ant O. Knee',
ord_date: new Date('2020-03-08'),
price: 70,
items: [
{ sku: 'oranges', qty: 8, price: 2.5 },
{ sku: 'chocolates', qty: 5, price: 10 }
],
status: 'A'
},
{
_id: 3,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-08'),
price: 50,
items: [
{ sku: 'oranges', qty: 10, price: 2.5 },
{ sku: 'pears', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 4,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-18'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
},
{
_id: 5,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-19'),
price: 50,
items: [{ sku: 'chocolates', qty: 5, price: 10 }],
status: 'A'
},
{
_id: 6,
cust_id: 'Cam Elot',
ord_date: new Date('2020-03-19'),
price: 35,
items: [
{ sku: 'carrots', qty: 10, price: 1.0 },
{ sku: 'apples', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 7,
cust_id: 'Cam Elot',
ord_date: new Date('2020-03-20'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
},
{
_id: 8,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-20'),
price: 75,
items: [
{ sku: 'chocolates', qty: 5, price: 10 },
{ sku: 'apples', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 9,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-20'),
price: 55,
items: [
{ sku: 'carrots', qty: 5, price: 1.0 },
{ sku: 'apples', qty: 10, price: 2.5 },
{ sku: 'oranges', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 10,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-23'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
}
])
Map-Reduce
相比于 Map-Reduce,聚合 pipeline 提供了更好的性能和更一致的接口。
Map-Reduce 是一种数据处理范式,用于将大量数据汇总为有用的聚合结果。为了执行 Map-Reduce 操作,MongoDB 提供了 mapReduce 数据库命令。

在此 Map-Reduce 操作中,MongoDB 将 map 阶段应用于每个输入文档(即集合中与查询条件匹配的文档)。map 函数发出键值对。对于具有多个值的键,MongoDB 会应用 reduce 阶段,此阶段将收集并压缩聚合数据。然后,MongoDB 将结果存储在一个集合中。(可选)reduce 函数的输出可以通过 finalize 函数来进一步压缩或处理聚合的结果。
MongoDB 中的所有 Map-Reduce 函数都是 JavaScript,并在 mongod 进程中运行。Map-Reduce 操作将单个 集合 的文档作为输入,并且可以在开始映射阶段之前执行任意排序和限制。mapReduce 可以将 Map-Reduce 操作的结果作为文档返回,也可以将结果写入集合。