Kubernetes 面试
【中等】什么是 Kubernetes,并描述其主要组件及其作用。
Kubernetes(K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。
它解决了管理大量微服务时的核心难题:
- 自动化运维:实现自动部署、扩缩容、故障恢复(自我修复)、滚动更新。
- 高可用与弹性伸缩:保证应用持续在线,并能轻松应对流量波动。
- 资源优化:高效调度容器,充分利用基础设施资源。
核心概念
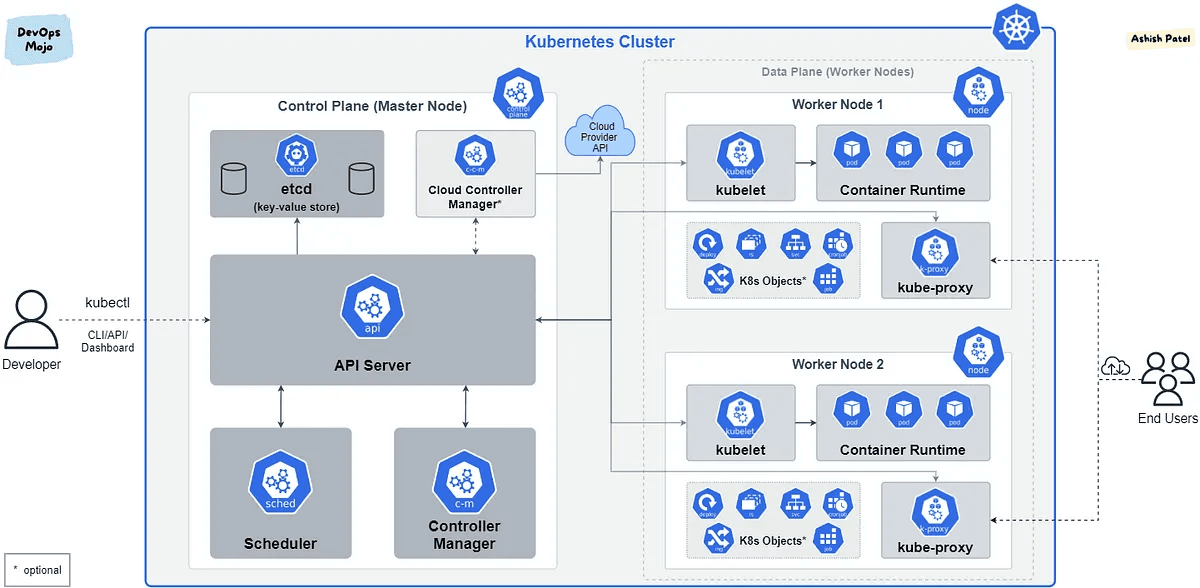
- 集群:由 Control Plane / Master Node 和 Worker Nodes 组成。
- Pod:最小部署单元,包含一个或多个紧密关联的容器。
- Deployment:定义 Pod 的期望状态(如副本数),实现滚动更新和回滚。
- Service:为动态变化的 Pod 提供稳定的网络访问和服务发现。
【中等】如何在 Kubernetes 中创建一个 Pod?
方法一、配置文件(推荐用于生产)
(1)创建 YAML 文件(示例:my-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:1.25.3
ports:
- containerPort: 80(2)应用配置
kubectl apply -f my-pod.yaml优势:可版本控制、可重复、内容清晰,是生产环境标准做法。
方法二、命令式命令(仅用于测试)
快速创建 Pod 的命令
kubectl run my-redis-pod --image=redis --restart=Never注意:必须加 --restart=Never 才会创建独立 Pod,否则会默认创建 Deployment。
优势: 快速简单,适合临时测试。
建议
- 最佳实践: 在生产中,不应直接创建 Pod,而应使用 Deployment 或 StatefulSet 等更高层级资源来管理 Pod,以实现自动恢复、扩缩容和滚动更新。
containerPort字段 仅是文档说明,实际开放端口需要通过 Service 资源来实现。
【中等】Kubernetes 中的 Service 和 Ingress 有什么区别?
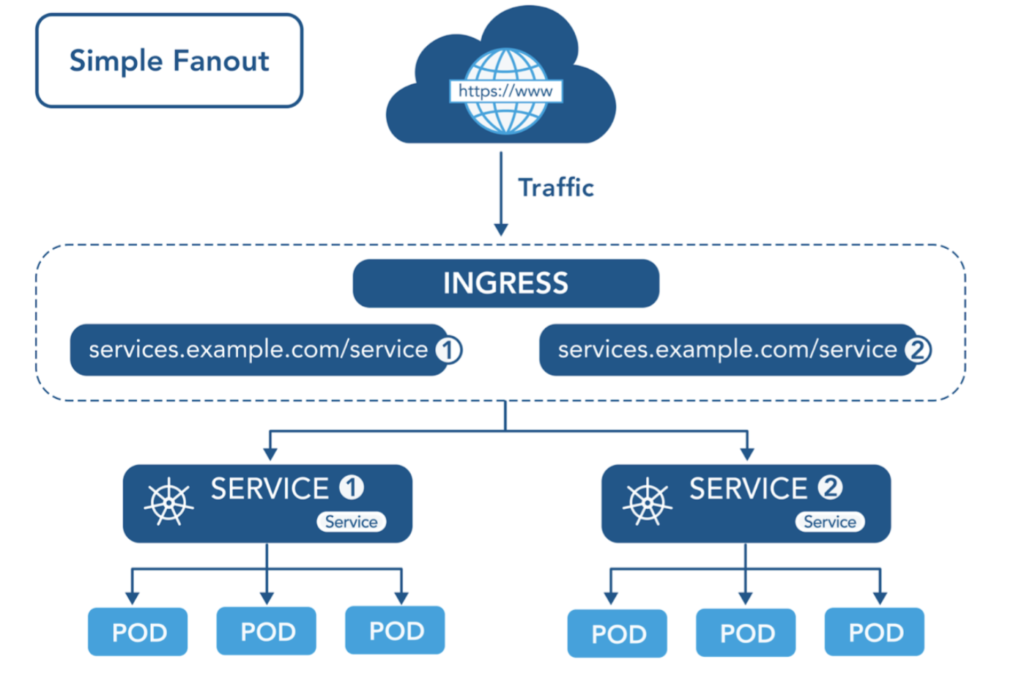
- Service:集群内部的通信与负载均衡。
- Ingress:集群外部的 HTTP(S) 流量管理与路由。
- 典型流量路径:外部用户 -> Ingress -> Service -> Pod。
核心区别对比表
| 特性 | Service | Ingress |
|---|---|---|
| 作用层面 | 传输层(L4) | 应用层(L7,HTTP/HTTPS) |
| 主要目标 | 内部通信与稳定性 | 外部访问与智能路由 |
| 依赖关系 | Kubernetes 内置功能 | 依赖 Service 作为后端,并需要部署 Ingress Controller |
| 功能 | 负载均衡、服务发现 | 域名/路径路由、SSL 终止 |
Service(服务):内部稳定端点
- 用途:为动态变化的 Pod 集合提供一个稳定的 IP 地址、DNS 名称和端口,实现服务发现和内部负载均衡。
- 核心功能:
- 服务发现:通过标签选择器动态找到后端 Pod。
- 负载均衡:将请求分发给多个 Pod 实例。
- 类型:
- ClusterIP(默认):仅限集群内部访问。
- NodePort:通过节点 IP 和静态端口暴露服务,可从外部访问。
- LoadBalancer:通过云提供商负载均衡器暴露服务到公网。
Ingress(入口):外部流量网关
- 用途:作为集群的统一入口,管理外部访问,实现基于域名和路径的高级路由。
- 核心功能:
- 基于规则的路由:根据 HTTP 请求的域名(如
api.example.com)和路径(如/api)将流量导向不同的后端 Service。 - SSL/TLS 终止:在入口处处理 HTTPS 加密/解密。
- 基于规则的路由:根据 HTTP 请求的域名(如
- 重要概念:
- Ingress Controller:必须部署的软件(如 Nginx、Traefik),用于实现 Ingress 规则。
- Ingress Resource:声明路由规则的 YAML 配置文件。
【中等】Kubernetes 中如何进行滚动更新和回滚?
滚动更新和回滚是 Deployment 资源的核心功能。Deployment 通过控制 ReplicaSet 来管理 Pod,通过改变 Pod 模板的“期望状态”来实现无缝更新。
| 操作 | 核心命令 | 本质 |
|---|---|---|
| 滚动更新 | kubectl set image... 或 kubectl apply -f | 通过创建新 ReplicaSet,逐步替换 Pod。 |
| 回滚 | kubectl rollout undo | 将 Pod 模板重置为历史版本,并再次触发更新。 |
滚动更新
目标:逐步用新版本 Pod 替换旧版本 Pod,实现零停机部署。
操作方式:
(1)命令式(快速测试)
kubectl set image deployment/my-app my-container=my-app:v2.0(2)声明式(生产推荐)
kubectl apply -f deployment.yaml # 修改 yaml 文件中的镜像版本后应用关键配置参数(在 Deployment YAML 的 spec.strategy.rollingUpdate 中):
maxSurge:允许临时超过期望副本数的 Pod 数量(如 25%),用于平滑更新。maxUnavailable:更新过程中允许不可用的 Pod 最大数量(如 25%),保证服务最低可用性。
监控命令:
kubectl rollout status deployment/my-app # 查看实时状态回滚操作
目标:当新版本出现问题时,快速恢复到之前的稳定版本。
操作流程:
(1)查看修订历史
kubectl rollout history deployment/my-app(2)执行回滚
回滚到上一个版本(最常用)
kubectl rollout undo deployment/my-app回滚到指定版本
kubectl rollout undo deployment/my-app --to-revision=1关键配置:
revisionHistoryLimit:指定保留的旧 ReplicaSet 历史记录数量,默认为 10,供回滚使用。
【中等】Kubernetes 中的 ConfigMap 和 Secret 有什么作用?
用 ConfigMap 管理应用配置,用 Secret 管理所有密码密钥。
核心区别与总结
| 特性 | ConfigMap | Secret |
|---|---|---|
| 数据性质 | 非敏感配置 | 敏感信息 |
| 安全性 | 低,明文 | 较高(但默认不加密,需配合 RBAC 和 ETCD 加密) |
| 关键建议 | 存放应用配置 | 永远不要用 ConfigMap 存密码 |
ConfigMap(配置映射)
- 用途:存储非敏感数据。
- 数据类型:环境变量(如
LOG_LEVEL=info)、配置文件(如nginx.conf)、命令行参数。 - 存储形式:明文存储。
- 使用方式:
- 作为环境变量注入到容器中。
- 作为配置文件挂载到容器的指定目录(最常用)。
Secret(密钥)
- 用途:存储敏感信息。
- 数据类型:密码、API 密钥、TLS 证书、镜像仓库拉取凭证。
- 存储形式:Base64 编码(注意:这是编码,不是加密)。
- 使用方式:
- 作为环境变量注入(不推荐用于高敏感数据,有日志泄露风险)。
- 作为只读文件挂载(推荐方式,更安全)。
- 特殊类型
imagePullSecrets用于拉取私有镜像。
【中等】Kubernetes 中如何配置资源配额?
Kubernetes 中通过在命名空间创建 ResourceQuota 对象来配置资源配额。
配置方式:
- 用 YAML 定义
ResourceQuota对象,指定namespace(仅作用于目标命名空间) - 配置项含两类:计算资源(
requests.cpu/limits.memory等总量上限)、对象数量(pods/services等最大数量) - 应用命令:
kubectl apply -f quota.yaml
核心作用:
- 防资源滥用:限制命名空间资源总用量,避免单个应用占用过多资源
- 公平分配:按业务需求为不同命名空间(如开发 / 生产)分配配额
- 成本控制:避免超预期资源消耗,降低运维成本
- 保障核心业务:为关键业务预留资源,防止被抢占
注意:需与 Pod 的 requests/limits 配合;超配额时资源创建会被拒绝。
【中等】Kubernetes 中的 Namespace 有什么作用?
Namespace(命名空间) 是 Kubernetes 集群的虚拟分区,用于在同一个物理集群中创建多个逻辑隔离的工作空间。
- 资源与对象隔离:不同 Namespace 中的资源(如 Pod、Service)可以重名。
- 资源配额管理:可以为每个 Namespace 设置独立的 CPU、内存等资源使用上限。
- 访问权限控制:结合 RBAC,可限制不同团队或用户只能访问指定的 Namespace。
主要使用场景
| 场景 | 目的 | 示例 |
|---|---|---|
| 环境隔离 (最常用) | 将开发、测试、生产环境完全分离,避免相互干扰。 | dev, test, prod |
| 团队/项目隔离 | 在共享集群中,为不同团队或项目提供独立的工作空间。 | team-a, project-x |
| 系统组件隔离 | 将 Kubernetes 核心系统组件与用户应用分开管理。 | kube-system (存放核心组件) |
关键要点与注意事项
- 并非完全隔离:是逻辑隔离,非物理隔离。异常应用仍可能影响底层节点。
- 部分资源不归属:Node、PersistentVolume 等集群级资源不属于任何 Namespace。
- 删除后果严重:删除 Namespace 会同步删除其内所有资源,且不可逆。
- 默认空间:未指定时,操作默认在
default命名空间进行。
【中等】Kubernetes 中如何进行日志管理?
Kubernetes 本身不提供内置的集中式日志解决方案,但其基础机制是:应用应将日志输出到标准输出(stdout)和标准错误(stderr),而非文件。
| 场景 | 方案 | 特点 |
|---|---|---|
| 开发/调试 | kubectl logs | 简单快捷,但日志易失、分散。 |
| 生产环境 | 集群级日志架构 | 必备方案。实现日志的集中、持久化、搜索和告警。 |
基础查看(用于开发调试)
- 命令:使用
kubectl logs <pod-name>直接查看 Pod 的日志。 - 原理:日志由节点上的容器运行时捕获并存储在本地文件中。
- 缺点:日志分散在各节点,随 Pod 删除或节点故障而丢失,无法集中分析。
集群级方案(用于生产环境)
这是必须采用的架构,核心是增加一个日志代理,将日志收集到中心化后端。
核心组件:
- 日志代理:以 DaemonSet 形式运行在每个节点上(如 Fluentd 或 Fluent Bit),负责收集和转发该节点上所有容器的日志。
- 日志后端:集中存储和索引日志的系统(如 Elasticsearch、Grafana Loki 或云厂商服务)。
- 可视化界面:用于查询和展示日志的 Web UI(如 Kibana、Grafana)。
经典架构(EFK):
应用 stdout -> 节点文件 -> Fluentd -> Elasticsearch -> Kibana
关键实践与要点
- 日志上下文:日志代理会自动为每条日志添加丰富的元数据(如 Pod 名称、命名空间、标签),极大方便问题排查。
- 处理文件日志:若应用必须写文件到磁盘,可采用 Sidecar 容器模式,由 Sidecar 读取日志文件并输出到其 stdout,从而纳入标准收集流程。
- 云服务:在公有云上,直接使用托管的日志服务(如 AWS CloudWatch)是最简单省心的选择。
【中等】Kubernetes 中如何实现持久化存储?
在 Kubernetes 中配置持久化存储需通过 PV(PersistentVolume,持久卷) 和 PVC(PersistentVolumeClaim,持久卷声明) 实现,核心步骤如下:
(1)定义 PV(集群级存储资源)
PV 由管理员配置,代表集群中的实际存储资源(如本地磁盘、NFS、云存储等),示例(NFS 类型):
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 10Gi # 存储容量
accessModes:
- ReadWriteMany # 多节点读写
nfs:
path: /data/nfs # NFS 共享路径
server: 192.168.1.100 # NFS 服务器地址
persistentVolumeReclaimPolicy: Retain # 回收策略(Retain/Delete/Recycle)应用:kubectl apply -f pv.yaml
(2)定义 PVC(用户申请存储)
PVC 由用户创建,用于申请 PV 资源,无需关心底层存储细节:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: app-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi # 申请 5Gi 存储
# 可选:通过 storageClassName 指定存储类
# storageClassName: "fast"应用:kubectl apply -f pvc.yaml
(3)Pod 挂载 PVC
在 Pod 中引用 PVC,实现数据持久化:
apiVersion: v1
kind: Pod
metadata:
name: app-pod
spec:
containers:
- name: app
image: nginx
volumeMounts:
- name: data-volume
mountPath: /usr/share/nginx/html # 容器内挂载路径
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: app-pvc # 关联 PVC(4)进阶:使用 StorageClass 动态供应
通过 StorageClass 实现 PV 自动创建,无需手动配置 PV:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/aws-ebs # 存储插件(如 AWS EBS、Ceph 等)
parameters:
type: gp2 # 存储类型
reclaimPolicy: DeletePVC 引用 StorageClass 即可动态获取存储。
核心作用
- 解耦存储与应用:管理员管理 PV,用户通过 PVC 申请,无需关注底层存储细节
- 数据持久化:容器销毁后,数据仍保存在 PV 中,支持跨 Pod 复用
- 灵活适配:支持多种存储后端(本地磁盘、NFS、云存储等)
通过 PV/PVC 机制,Kubernetes 实现了存储资源的标准化管理,满足状态应用(如数据库)的数据持久化需求。
【中等】Kubernetes 中的 Helm 有什么作用?
Helm 作为 Kubernetes 包管理工具的核心作用:
- 应用打包:将 Deployment、Service 等资源打包为「Chart」,便于分发复用
- 简化部署:通过
helm install一键部署,支持动态配置(--set或 values 文件) - 版本管理:记录应用版本(Release),支持
upgrade升级和rollback回滚 - 依赖管理:自动处理应用间依赖,一键部署完整应用栈
- 模板化配置:用 Go 模板分离配置与代码,适配多环境部署
适用于简化复杂 K8s 应用的管理,提升部署效率和可维护性。
【中等】如何在 Kubernetes 中使用 Helm 部署应用?
使用 Helm 在 Kubernetes 中部署应用的核心要点:
- 准备工作:安装 Helm 客户端,添加并更新 Chart 仓库(如
helm repo add) - 部署流程:
- 搜索 Chart(
helm search repo)并查看配置(helm show values) - 自定义配置(通过
values.yaml或--set参数覆盖默认值) - 部署应用(
helm install <release 名> <chart 名>)
- 搜索 Chart(
- 管理操作:
- 升级(
helm upgrade):更新配置或 Chart 版本 - 回滚(
helm rollback):基于历史版本(helm history查看)恢复 - 卸载(
helm uninstall):删除 Release 及相关资源
- 升级(
- 自定义应用:通过
helm create生成 Chart 结构,编写模板和配置后部署本地 Chart
优势:简化多资源部署,支持配置分离、版本控制和一键回滚,提升管理效率。
【中等】Kubernetes 中如何进行安全配置?
- 集群级防护:API Server 启用 TLS 加密 + IP 限制 + RBAC;kubelet 最小权限配置;用 Secrets / 外部工具(Vault)管理敏感信息
- 资源安全配置:
- Pod 安全上下文(禁止 root 运行、禁用权限提升等)
- 用 Pod 安全标准 / 策略定义运行规则,设资源限制防耗尽
- 网络安全:通过 NetworkPolicy 限制 Pod 间通信;服务网格(如 Istio)实现 mTLS 加密
- 镜像与供应链:扫描镜像漏洞,用私有仓库 + 拉取密钥,禁止
latest标签 - 审计与监控:启用 API Server 审计日志,监控异常行为(如特权容器创建)
【中等】Kubernetes 中的 Pod 是什么?其作用是什么?
Kubernetes 中的 Pod 是集群中最小的部署和管理单元,是容器的封装集合。
核心构成:
- 包含一个或多个紧密关联的容器(如应用容器 + 日志收集容器)
- 共享网络命名空间(同一 Pod 内容器共享 IP 和端口)
- 共享存储卷(可通过 Volume 实现容器间数据共享)
主要作用:
- 作为应用部署的基本单位,封装应用运行所需的容器、网络和存储资源
- 提供容器间协同工作的环境(如前后端容器同 Pod 部署,通过 localhost 通信)
- 作为 Kubernetes 调度、扩展、自愈的最小单元(如调度到节点、副本集扩缩容均以 Pod 为单位)
- 抽象底层容器运行时,统一管理容器生命周期
Pod 具有临时性,生命周期结束后会被销毁重建,其 IP 可能变化,通常通过 Service 提供稳定访问入口。
【中等】如何在 Kubernetes 中实现服务的自动伸缩?
Kubernetes 中服务自动伸缩的核心要点:
- 核心实现:通过 HPA(Horizontal Pod Autoscaler)实现,根据指标动态调整 Pod 副本数
- 配置要点:
- 关联目标控制器(Deployment/StatefulSet 等)
- 设定副本数范围(minReplicas/maxReplicas)
- 基于指标触发伸缩(CPU / 内存使用率或自定义指标)
- 依赖条件:需部署 Metrics Server 收集指标,目标 Pod 需定义 resources.requests
- 作用:动态适配负载变化,高峰扩容提升能力,低谷缩容节约资源,保障服务稳定性
- 扩展场景:结合 Prometheus 等工具支持自定义指标(如每秒请求数)伸缩
【中等】Kubernetes 中的 Deployment 和 StatefulSet 有什么区别?
Kubernetes 中 Deployment 与 StatefulSet 的核心区别:
- 适用场景:
- Deployment:适用于无状态应用(如 Web 服务),副本完全等价
- StatefulSet:适用于有状态应用(如数据库),需稳定身份和存储
- 核心差异:
- 命名:Deployment 随机命名,StatefulSet 固定序号命名(如 db-0、db-1)
- 网络:Deployment 共享 Service IP,StatefulSet 每个 Pod 有稳定 DNS
- 存储:Deployment 共享存储,StatefulSet 每个 Pod 绑定独立 PVC
- 更新 / 扩缩容:Deployment 无序操作,StatefulSet 按序号严格执行
- 自愈:Deployment 重建后身份变化,StatefulSet 保持原身份
选择依据:应用是否依赖稳定身份、存储或有序部署 / 更新。
【中等】Kubernetes 中的 Ingress 资源有什么作用?如何配置?
Kubernetes 中 Ingress 资源的核心要点:
- 核心作用:
- 作为集群入口网关,统一管理外部对集群内服务的访问
- 支持基于域名、路径的 HTTP/HTTPS 请求路由(如将不同域名请求转发到对应服务)
- 实现 SSL 终结(集中管理 HTTPS 证书)和负载均衡
- 配置前提:需部署 Ingress 控制器(如 Nginx Ingress Controller),否则规则不生效
- 关键配置:
ingressClassName:指定使用的控制器rules:定义路由规则(host域名 +paths路径,关联目标 Service)tls:配置 HTTPS,通过secretName关联存储证书的 SecretpathType:路径匹配类型(Prefix 前缀 / Exact 精确等)
- 示例场景:基于域名(
web.example.com到 Web 服务)、路径(/v1到 API v1 服务)的路由,或配置 HTTPS 加密访问
【中等】Kubernetes 中的 DaemonSet 有什么作用?
Kubernetes 中 DaemonSet 的核心要点:
- 核心作用:确保集群中(或指定标签的)所有节点上都运行且仅运行一个相同的 Pod 副本,专为节点级服务设计。
- 典型场景:
- 节点监控(如 Prometheus Node Exporter)
- 日志收集(如 Fluentd)
- 网络 / 存储插件的节点代理(如 Calico、Ceph 代理)
- 关键特性:
- 自动适配节点变化(新节点加入时自动部署,节点移除时自动清理)
- 无需手动配置副本数(由符合条件的节点数量决定)
- 支持通过
nodeSelector等指定部署节点范围
适用于需要在每个节点上部署的系统级服务,简化底层支撑能力的统一管理。
【中等】Kubernetes 中的 ReplicaSet 和 ReplicationController 有什么区别?
Kubernetes 中 ReplicaSet 与 ReplicationController 的核心区别:
- 核心差异:标签选择器
- ReplicationController:仅支持等值选择器(
matchLabels),只能匹配标签完全一致的 Pod,灵活性低。 - ReplicaSet:支持等值选择器(
matchLabels)和集合选择器(matchExpressions),可通过表达式(如app in (nginx,web))实现复杂匹配,灵活性更高。
- ReplicationController:仅支持等值选择器(
- 其他区别
- API 版本:ReplicationController 使用
v1(老旧),ReplicaSet 使用apps/v1(标准稳定版)。 - 定位:ReplicaSet 是 ReplicationController 的升级替代方案,是 Deployment 的底层依赖,目前为推荐使用的副本管理组件;ReplicationController 已逐步淘汰。
- API 版本:ReplicationController 使用
选择建议:优先使用 ReplicaSet,仅在维护旧集群时考虑 ReplicationController。
【中等】Kubernetes 中的 Service 有哪几种类型?
- ClusterIP(默认):仅集群内访问,分配内部虚拟 IP;用于集群内服务通信(如前端调后端)。
- NodePort:每个节点开放静态端口(30000-32767),外部通过
节点 IP:NodePort访问;含 ClusterIP 功能,适合临时外部测试。 - LoadBalancer:依赖云服务商负载均衡器,分配外部 IP;用于生产环境公网访问(需云环境支持)。
- ExternalName:将 Service 映射到外部域名(如 example.com),无 Pod 关联;用于访问集群外固定服务(如外部数据库)。
- Headless Service(无头服务):不分配 ClusterIP,DNS 直接返回匹配 Pod IP 列表;适用于 StatefulSet 有状态应用(如数据库主从,需访问特定 Pod)。
核心作用:抽象 Pod 动态变化,提供稳定访问入口,适配不同内外网访问场景。
【中等】Kubernetes 的 Helm Charts 如何实现应用的版本控制?
Helm Charts 实现应用版本控制的核心机制:
- Chart 版本管理:通过
Chart.yaml的version字段(语义化版本)标识模板本身版本,内容变更时同步更新版本号。 - Release 版本控制:
- 每个部署实例(Release)有独立版本号(自动递增),记录当前 Chart 版本、配置参数和资源状态。
- 可通过
helm history查看所有版本记录,用helm rollback回滚到指定版本。
- 配置与依赖管理
- 配置(
values.yaml)与模板分离,不同环境配置独立管理,变更随 Release 版本记录。 - 依赖通过
Chart.yaml声明版本范围,Chart.lock锁定实际安装版本,确保部署一致性。
- 配置(
核心价值:实现从应用模板到部署实例的全链路版本追踪,支持安全升级与快速回滚,简化 Kubernetes 应用的版本管理。
【中等】Kubernetes 中的 Job 和 CronJob 有什么区别?
Kubernetes 中 Job 和 CronJob 均用于管理短期运行的任务型工作负载,核心区别在于执行时机和调度方式:
- Job 适用于单次运行的任务,强调任务的成功完成;
- CronJob 适用于周期性重复的任务,通过时间规则自动触发 Job,本质是 Job 的定时调度器。
两者均专注于短期任务(区别于长期运行的 Deployment),但在执行时机和周期上有明确分工。
关键特性差异
| 特性 | Job | CronJob |
|---|---|---|
| 执行方式 | 手动触发或部署后立即执行 | 按 cron 表达式自动定时触发(如 0 3 * * * 表示每天凌晨 3 点) |
| 任务周期 | 一次性完成,执行结束后终止 | 周期性重复执行,按调度规则循环触发新 Job |
| 核心配置 | 指定完成的 Pod 数量(completions)、并行数(parallelism) | 包含 cron 表达式(schedule)、任务模板(jobTemplate)、历史任务保留策略等 |
apiVersion: batch/v1
kind: Job
metadata:
name: backup-job
spec:
completions: 1 # 需成功完成 1 个 Pod
parallelism: 1 # 并行执行 1 个 Pod
template:
spec:
containers:
- name: backup
image: backup-tool:v1
command: ['backup', '/data']
restartPolicy: Never # 失败后不重启,由 Job 重新创建 PodapiVersion: batch/v1
kind: CronJob
metadata:
name: log-cleanup-cronjob
spec:
schedule: '0 3 * * *' # 每天凌晨 3 点执行
jobTemplate: # 嵌套 Job 配置
spec:
template:
spec:
containers:
- name: cleaner
image: cleanup-tool:v1
command: ['clean', '/logs']
restartPolicy: Never
successfulJobsHistoryLimit: 3 # 保留 3 个成功历史任务
failedJobsHistoryLimit: 1 # 保留 1 个失败历史任务【中等】Kubernetes 中的 Persistent Volume 和 Persistent Volume Claim 有什么区别?
- PV 是具体的存储资源,如一块云硬盘或 NFS 目录。相当于一个仓库。
- PVC 是用户对存储的抽象请求,如“我需要 10Gi 可读写的存储”。相当于一份仓储申请单。
Kubernetes 的作用是将 PVC(申请单)与合适的 PV(仓库)进行绑定,供 Pod(用户)使用。
核心区别对比
| 特性 | Persistent Volume (PV) | Persistent Volume Claim (PVC) |
|---|---|---|
| 本质 | 存储资源本身 | 对存储的请求 |
| 创建者 | 集群管理员(或由系统自动创建) | 应用开发者 |
| 作用范围 | 集群级别资源,不属于任何命名空间 | 命名空间级别资源 |
| 关注点 | “如何提供”(如 NFS、云硬盘、容量) | “需要什么”(如容量、访问模式) |
两种供给模式
- 静态供给:管理员预先创建好一批 PV,PVC 从现有 PV 池中申请绑定。
- 动态供给(推荐):管理员创建 StorageClass(存储类)。当用户创建 PVC 并指定
storageClassName时,系统自动按需创建对应的 PV。这是云环境中的标准做法。
核心价值:职责分离
- 管理员:负责底层存储基础设施(PV/StorageClass)。
- 开发者:只需通过 PVC 声明存储需求,无需关心后端细节。
【中等】Kubernetes 中的网络策略如何实现?
网络策略是一种基于规则的防火墙,用于控制 Pod 之间的网络流量。它采用 “默认允许,有策则拒” 的白名单模型。
- 前提:集群的网络插件必须支持 NetworkPolicy(如 Calico、Cilium),否则策略不生效。
- 本质:基于标签的 Pod 级防火墙。
- 模型:白名单。规则之外的流量被拒绝。
- 价值:实现网络微隔离,是 Kubernetes 安全的重要基石。
核心规则模型
- 无策略状态:Pod 未被任何 NetworkPolicy 选中时,允许所有入站和出站流量。
- 有策略状态:一旦 Pod 被某个策略选中,则:
- 入站流量:默认被拒绝,除非在
ingress规则中明确允许。 - 出站流量:默认仍被允许,除非在
egress规则中明确限制。
- 入站流量:默认被拒绝,除非在
NetworkPolicy 关键组成部分
一个策略主要定义四部分:
podSelector:此策略应用于哪些 Pod(通过标签选择)。policyTypes:策略类型(Ingress,Egress,或两者)。ingress:允许的入站流量来源(from)和端口(ports)。egress:允许的出站流量目标(to)和端口(ports)。
流量来源/目标可以是
podSelector:同一命名空间内的其他 Pod。namespaceSelector:特定命名空间下的 Pod。ipBlock:外部 IP 地址段(CIDR)。
最基础的安全加固
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {} # 选择本命名空间所有 Pod
policyTypes:
- Ingress
# ingress 规则为空,表示拒绝所有入站连接---
spec:
podSelector:
matchLabels:
app: backend # 策略作用于后端 Pod
ingress:
- from:
- podSelector:
matchLabels:
app: frontend # 只允许来自前端 Pod 的流量
ports:
- port: 8080 # 只开放 8080 端口