《极客时间教程 - Java 并发编程实战》笔记四
《极客时间教程 - Java 并发编程实战》笔记四
案例分析(一):高性能限流器 Guava RateLimiter
Guava 是 Google 开源的 Java 类库,提供了一个工具类 RateLimiter。
【示例】使用 RateLimiter 限流
//限流器流速:2 个请求/秒
RateLimiter limiter = RateLimiter.create(2.0);
//执行任务的线程池
ExecutorService es = Executors.newFixedThreadPool(1);
//记录上一次执行时间
prev = System.nanoTime();
//测试执行 20 次
for (int i = 0; i < 20; i++) {
//限流器限流
limiter.acquire();
//提交任务异步执行
es.execute(() -> {
long cur = System.nanoTime();
//打印时间间隔:毫秒
System.out.println((cur - prev) / 1000_000);
prev = cur;
});
}
// 输出结果:
// ...
// 500
// 499
// 500
// 499
经典限流算法:令牌桶算法
Guava 限流算法采用令牌桶算法,其核心是要想通过限流器,必须拿到令牌。也就是说,只要我们能够限制发放令牌的速率,那么就能控制流速了。令牌桶算法的详细描述如下:
- 令牌以固定的速率添加到令牌桶中,假设限流的速率是 r/秒,则令牌每 1/r 秒会添加一个;
- 假设令牌桶的容量是 b ,如果令牌桶已满,则新的令牌会被丢弃;
- 请求能够通过限流器的前提是令牌桶中有令牌。
这个算法中,限流的速率 r 还是比较容易理解的,但令牌桶的容量 b 该怎么理解呢?b 其实是 burst 的简写,意义是限流器允许的最大突发流量。比如 b=10,而且令牌桶中的令牌已满,此时限流器允许 10 个请求同时通过限流器,当然只是突发流量而已,这 10 个请求会带走 10 个令牌,所以后续的流量只能按照速率 r 通过限流器。
Guava 如何实现令牌桶算法
Guava 实现令牌桶算法,其关键是记录并动态计算下一令牌发放的时间。
假设令牌桶的容量为 b=1,限流速率 r = 1 个请求/秒,如下图所示,如果当前令牌桶中没有令牌,下一个令牌的发放时间是在第 3 秒,而在第 2 秒的时候有一个线程 T1 请求令牌,此时该如何处理呢?
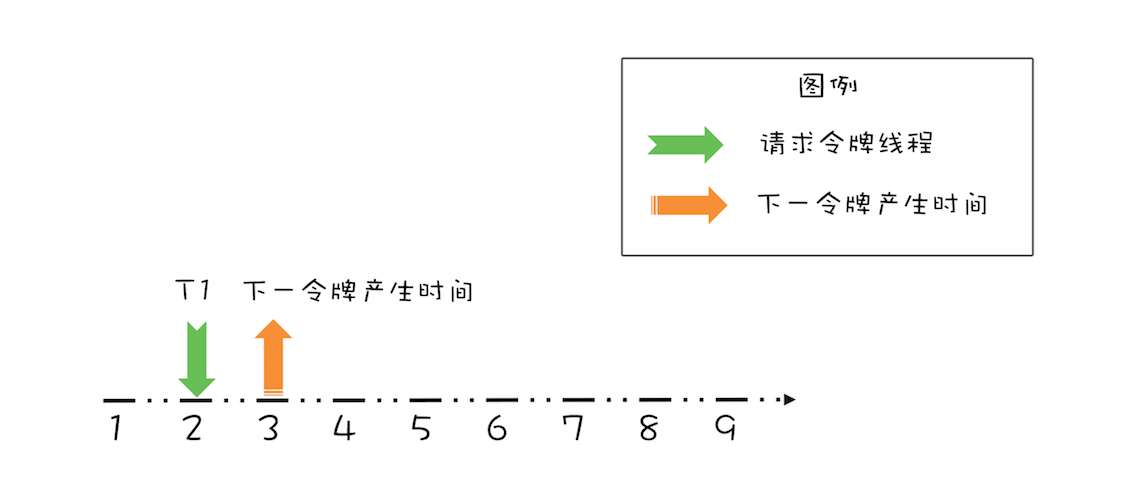
对于这个请求令牌的线程而言,很显然需要等待 1 秒,因为 1 秒以后(第 3 秒)它就能拿到令牌了。此时需要注意的是,下一个令牌发放的时间也要增加 1 秒,为什么呢?因为第 3 秒发放的令牌已经被线程 T1 预占了。处理之后如下图所示。
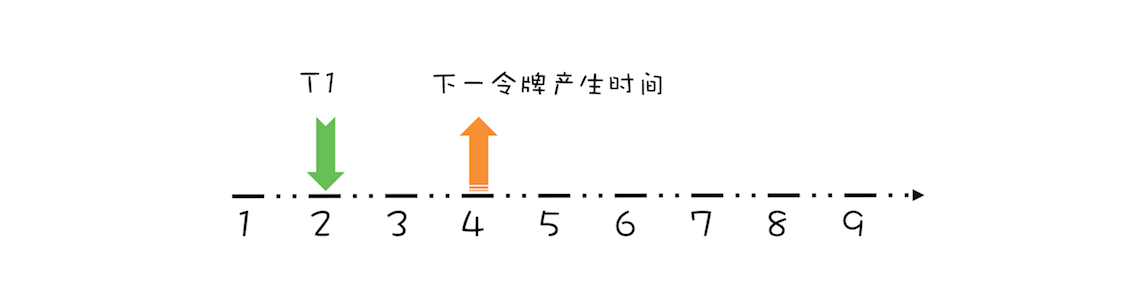
假设 T1 在预占了第 3 秒的令牌之后,马上又有一个线程 T2 请求令牌,如下图所示。
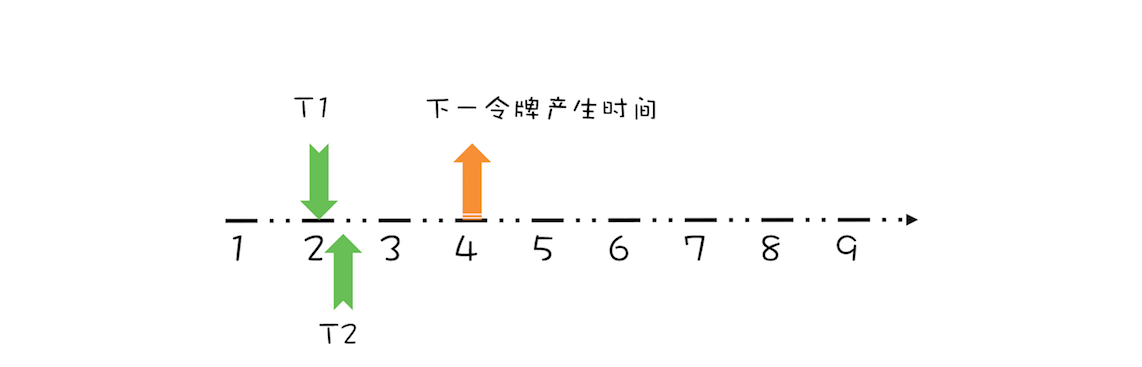
很显然,由于下一个令牌产生的时间是第 4 秒,所以线程 T2 要等待两秒的时间,才能获取到令牌,同时由于 T2 预占了第 4 秒的令牌,所以下一令牌产生时间还要增加 1 秒,完全处理之后,如下图所示。
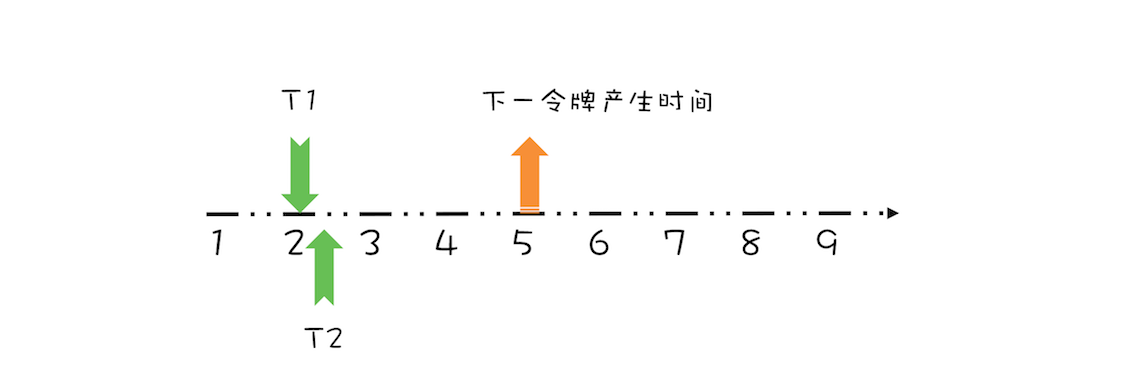
上面线程 T1、T2 都是在下一令牌产生时间之前请求令牌,如果线程在下一令牌产生时间之后请求令牌会如何呢?假设在线程 T1 请求令牌之后的 5 秒,也就是第 7 秒,线程 T3 请求令牌,如下图所示。
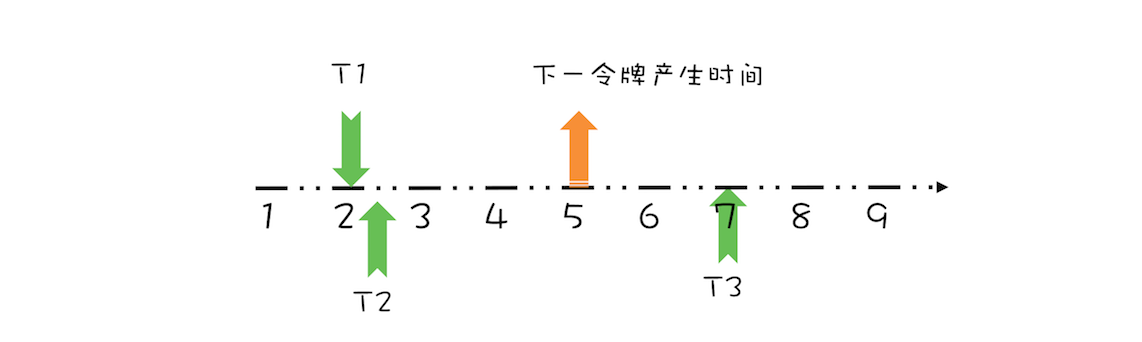
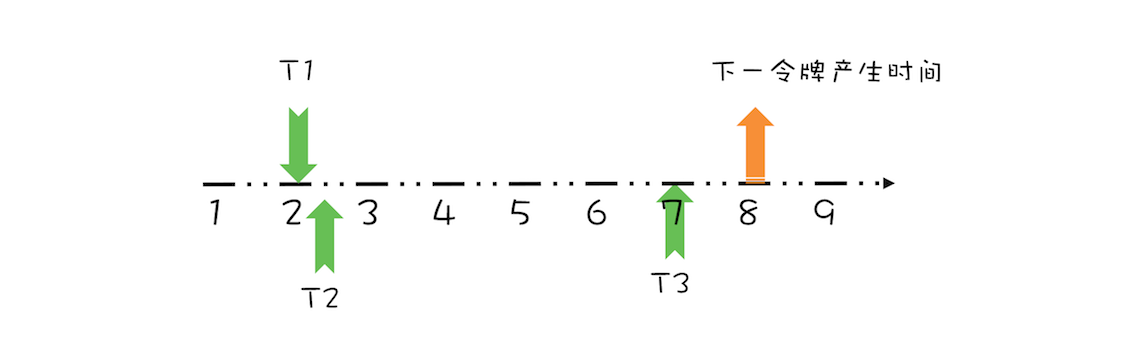
由于在第 5 秒已经产生了一个令牌,所以此时线程 T3 可以直接拿到令牌,而无需等待。在第 7 秒,实际上限流器能够产生 3 个令牌,第 5、6、7 秒各产生一个令牌。由于我们假设令牌桶的容量是 1,所以第 6、7 秒产生的令牌就丢弃了,其实等价地你也可以认为是保留的第 7 秒的令牌,丢弃的第 5、6 秒的令牌,也就是说第 7 秒的令牌被线程 T3 占有了,于是下一令牌的的产生时间应该是第 8 秒,如下图所示。
通过上面简要地分析们只需要记录一个下一令牌产生的时间,并动态更新它,就能够轻松完成限流功能。我们可以将上面的这个算法代码化,示例代码如下所示,依然假设令牌桶的容量是 1。关键是** reserve() 方法**,这个方法会为请求令牌的线程预分配令牌,同时返回该线程能够获取令牌的时间。其实现逻辑就是上面提到的:如果线程请求令牌的时间在下一令牌产生时间之后,那么该线程立刻就能够获取令牌;反之,如果请求时间在下一令牌产生时间之前,那么该线程是在下一令牌产生的时间获取令牌。由于此时下一令牌已经被该线程预占,所以下一令牌产生的时间需要加上 1 秒。
class SimpleLimiter {
//下一令牌产生时间
long next = System.nanoTime();
//发放令牌间隔:纳秒
long interval = 1000_000_000;
//预占令牌,返回能够获取令牌的时间
synchronized long reserve(long now) {
//请求时间在下一令牌产生时间之后
//重新计算下一令牌产生时间
if (now > next) {
//将下一令牌产生时间重置为当前时间
next = now;
}
//能够获取令牌的时间
long at = next;
//设置下一令牌产生时间
next += interval;
//返回线程需要等待的时间
return Math.max(at, 0L);
}
//申请令牌
void acquire() {
//申请令牌时的时间
long now = System.nanoTime();
//预占令牌
long at = reserve(now);
long waitTime = max(at - now, 0);
//按照条件等待
if (waitTime > 0) {
try {
TimeUnit.NANOSECONDS.sleep(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
如果令牌桶的容量大于 1,又该如何处理呢?按照令牌桶算法,令牌要首先从令牌桶中出,所以我们需要按需计算令牌桶中的数量,当有线程请求令牌时,先从令牌桶中出。具体的代码实现如下所示。我们增加了一个** resync() 方法**,在这个方法中,如果线程请求令牌的时间在下一令牌产生时间之后,会重新计算令牌桶中的令牌数,新产生的令牌的计算公式是:(now-next)/interval,你可对照上面的示意图来理解。reserve() 方法中,则增加了先从令牌桶中出令牌的逻辑,不过需要注意的是,如果令牌是从令牌桶中出的,那么 next 就无需增加一个 interval 了。
class SimpleLimiter {
//当前令牌桶中的令牌数量
long storedPermits = 0;
//令牌桶的容量
long maxPermits = 3;
//下一令牌产生时间
long next = System.nanoTime();
//发放令牌间隔:纳秒
long interval = 1000_000_000;
//请求时间在下一令牌产生时间之后,则
// 1. 重新计算令牌桶中的令牌数
// 2. 将下一个令牌发放时间重置为当前时间
void resync(long now) {
if (now > next) {
//新产生的令牌数
long newPermits = (now - next) / interval;
//新令牌增加到令牌桶
storedPermits = min(maxPermits, storedPermits + newPermits);
//将下一个令牌发放时间重置为当前时间
next = now;
}
}
//预占令牌,返回能够获取令牌的时间
synchronized long reserve(long now) {
resync(now);
//能够获取令牌的时间
long at = next;
//令牌桶中能提供的令牌
long fb = min(1, storedPermits);
//令牌净需求:首先减掉令牌桶中的令牌
long nr = 1 - fb;
//重新计算下一令牌产生时间
next = next + nr * interval;
//重新计算令牌桶中的令牌
this.storedPermits -= fb;
return at;
}
//申请令牌
void acquire() {
//申请令牌时的时间
long now = System.nanoTime();
//预占令牌
long at = reserve(now);
long waitTime = max(at - now, 0);
//按照条件等待
if (waitTime > 0) {
try {
TimeUnit.NANOSECONDS.sleep(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
总结
经典的限流算法有两个,一个是令牌桶算法(Token Bucket),另一个是漏桶算法(Leaky Bucket)。令牌桶算法是定时向令牌桶发送令牌,请求能够从令牌桶中拿到令牌,然后才能通过限流器;而漏桶算法里,请求就像水一样注入漏桶,漏桶会按照一定的速率自动将水漏掉,只有漏桶里还能注入水的时候,请求才能通过限流器。令牌桶算法和漏桶算法很像一个硬币的正反面,所以你可以参考令牌桶算法的实现来实现漏桶算法。
案例分析(二):高性能网络应用框架 Netty
网络编程性能的瓶颈
BIO 模型里,所有 read() 操作和 write() 操作都会阻塞当前线程的,如果客户端已经和服务端建立了一个连接,而迟迟不发送数据,那么服务端的 read() 操作会一直阻塞,所以使用 BIO 模型,一般都会为每个 socket 分配一个独立的线程,这样就不会因为线程阻塞在一个 socket 上而影响对其他 socket 的读写。BIO 的线程模型如下图所示,每一个 socket 都对应一个独立的线程;为了避免频繁创建、消耗线程,可以采用线程池,但是 socket 和线程之间的对应关系并不会变化。
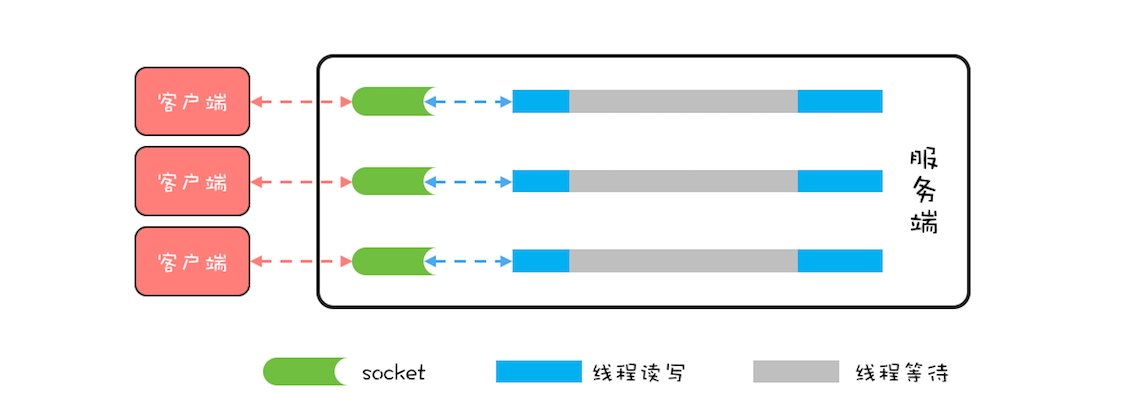
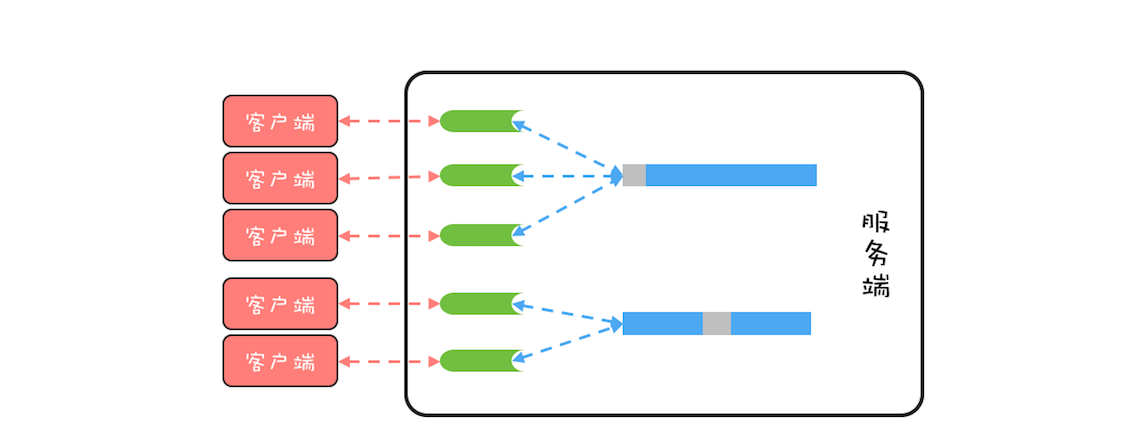
BIO 这种线程模型适用于 socket 连接不是很多的场景;但是现在的互联网场景,往往需要服务器能够支撑十万甚至百万连接,而创建十万甚至上百万个线程显然并不现实,所以 BIO 线程模型无法解决百万连接的问题。如果仔细观察,你会发现互联网场景中,虽然连接多,但是每个连接上的请求并不频繁,所以线程大部分时间都在等待 I/O 就绪。也就是说线程大部分时间都阻塞在那里,这完全是浪费,如果我们能够解决这个问题,那就不需要这么多线程了。
可以用一个线程来处理多个连接,这样线程的利用率就上来了,同时所需的线程数量也跟着降下来了。这个思路很好,可是使用 BIO 相关的 API 是无法实现的,这是为什么呢?因为 BIO 相关的 socket 读写操作都是阻塞式的,而一旦调用了阻塞式 API,在 I/O 就绪前,调用线程会一直阻塞,也就无法处理其他的 socket 连接了。
Reactor 模式
下面是 Reactor 模式的类结构图,其中 Handle 指的是 I/O 句柄,在 Java 网络编程里,它本质上就是一个网络连接。Event Handler 很容易理解,就是一个事件处理器,其中 handle_event() 方法处理 I/O 事件,也就是每个 Event Handler 处理一个 I/O Handle;get_handle() 方法可以返回这个 I/O 的 Handle。Synchronous Event Demultiplexer 可以理解为操作系统提供的 I/O 多路复用 API,例如 POSIX 标准里的 select() 以及 Linux 里面的 epoll()。
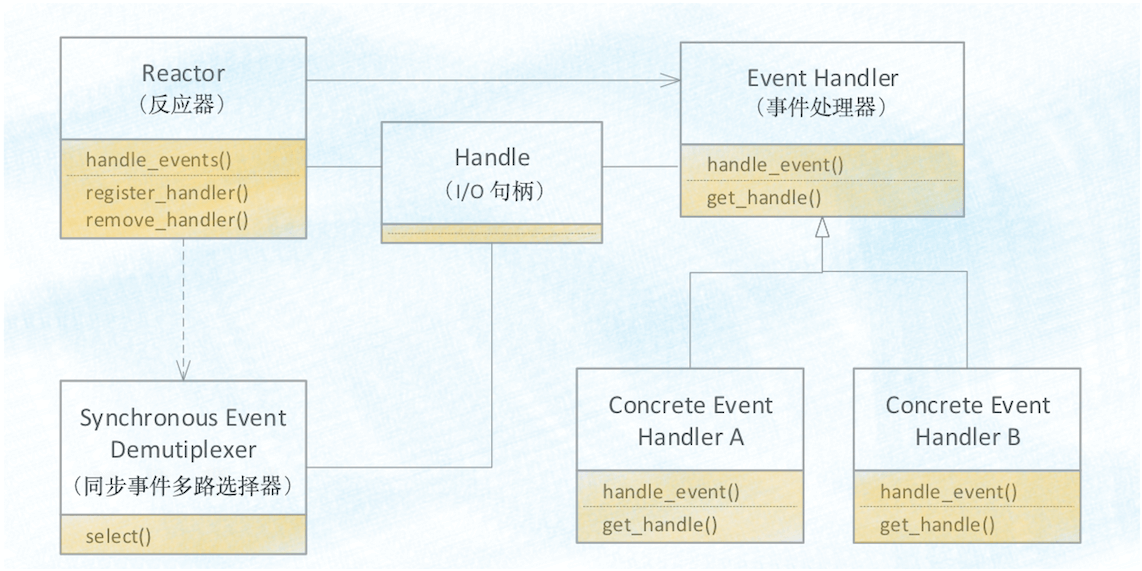
Reactor 模式的核心自然是 Reactor 这个类,其中 register_handler() 和 remove_handler() 这两个方法可以注册和删除一个事件处理器;handle_events() 方式是核心,也是 Reactor 模式的发动机,这个方法的核心逻辑如下:首先通过同步事件多路选择器提供的 select() 方法监听网络事件,当有网络事件就绪后,就遍历事件处理器来处理该网络事件。由于网络事件是源源不断的,所以在主程序中启动 Reactor 模式,需要以 while(true){} 的方式调用 handle_events() 方法。
void Reactor::handle_events(){
//通过同步事件多路选择器提供的
//select() 方法监听网络事件
select(handlers);
//处理网络事件
for(h in handlers){
h.handle_event();
}
}
// 在主程序中启动事件循环
while (true) {
handle_events();
Netty 中的线程模型
Netty 中最核心的概念是事件循环(EventLoop),其实也就是 Reactor 模式中的 Reactor,负责监听网络事件并调用事件处理器进行处理。在 4.x 版本的 Netty 中,网络连接和 EventLoop 是稳定的多对 1 关系,而 EventLoop 和 Java 线程是 1 对 1 关系,这里的稳定指的是关系一旦确定就不再发生变化。也就是说一个网络连接只会对应唯一的一个 EventLoop,而一个 EventLoop 也只会对应到一个 Java 线程,所以一个网络连接只会对应到一个 Java 线程。
一个网络连接对应到一个 Java 线程上,最大的好处就是对于一个网络连接的事件处理是单线程的,这样就避免了各种并发问题。
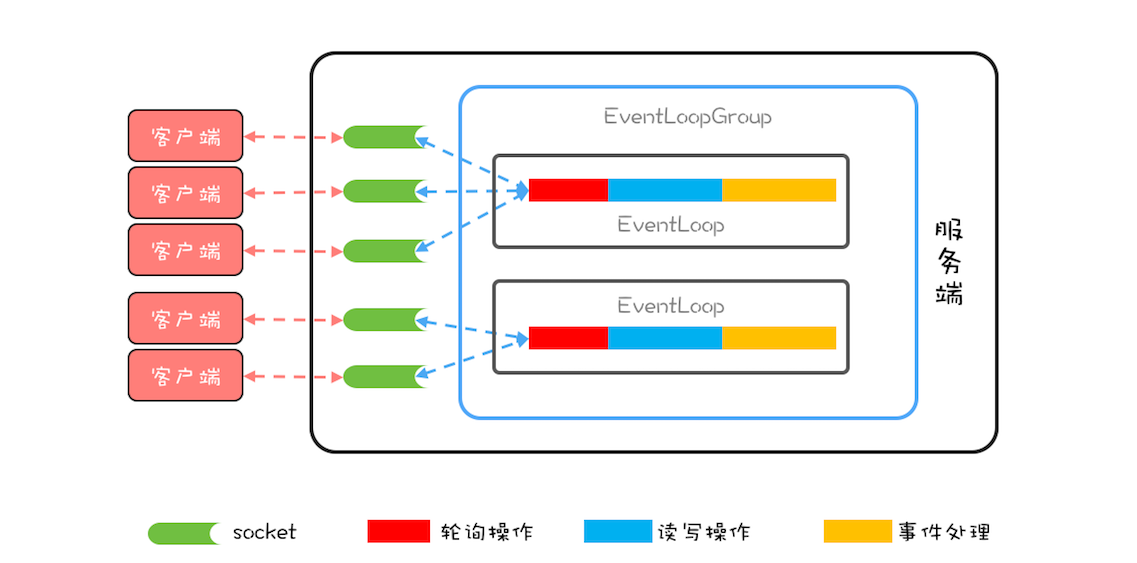
Netty 中还有一个核心概念是** EventLoopGroup**,顾名思义,一个 EventLoopGroup 由一组 EventLoop 组成。实际使用中,一般都会创建两个 EventLoopGroup,一个称为 bossGroup,一个称为 workerGroup。
这个和 socket 处理网络请求的机制有关,socket 处理 TCP 网络连接请求,是在一个独立的 socket 中,每当有一个 TCP 连接成功建立,都会创建一个新的 socket,之后对 TCP 连接的读写都是由新创建处理的 socket 完成的。也就是说处理 TCP 连接请求和读写请求是通过两个不同的 socket 完成的。
在 Netty 中,bossGroup 就用来处理连接请求的,而 workerGroup 是用来处理读写请求的。bossGroup 处理完连接请求后,会将这个连接提交给 workerGroup 来处理, workerGroup 里面有多个 EventLoop,那新的连接会交给哪个 EventLoop 来处理呢?这就需要一个负载均衡算法,Netty 中目前使用的是轮询算法。
用 Netty 实现 Echo 程序服务端
第一个,如果 NettybossGroup 只监听一个端口,那 bossGroup 只需要 1 个 EventLoop 就可以了,多了纯属浪费。
第二个,默认情况下,Netty 会创建“2*CPU 核数”个 EventLoop,由于网络连接与 EventLoop 有稳定的关系,所以事件处理器在处理网络事件的时候是不能有阻塞操作的,否则很容易导致请求大面积超时。如果实在无法避免使用阻塞操作,那可以通过线程池来异步处理。
//事件处理器
final EchoServerHandler serverHandler = new EchoServerHandler();
//boss 线程组
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
//worker 线程组
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(serverHandler);
}
});
//bind 服务端端口
ChannelFuture f = b.bind(9090).sync();
f.channel().closeFuture().sync();
} finally {
//终止工作线程组
workerGroup.shutdownGracefully();
//终止 boss 线程组
bossGroup.shutdownGracefully();
}
//socket 连接处理器
class EchoServerHandler extends ChannelInboundHandlerAdapter {
//处理读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.write(msg);
}
//处理读完成事件
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
ctx.flush();
}
//处理异常事件
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
总结
Netty 是一个款优秀的网络编程框架,性能非常好,为了实现高性能的目标,Netty 做了很多优化,例如优化了 ByteBuffer、支持零拷贝等等,和并发编程相关的就是它的线程模型了。Netty 的线程模型设计得很精巧,每个网络连接都关联到了一个线程上,这样做的好处是:对于一个网络连接,读写操作都是单线程执行的,从而避免了并发程序的各种问题。
案例分析(三):高性能队列 Disruptor
Disruptor 是一款高性能的有界内存队列,目前应用非常广泛,Log4j2、Spring Messaging、HBase、Storm 都用到了 Disruptor,那 Disruptor 的性能为什么这么高呢?Disruptor 项目团队曾经写过一篇论文,详细解释了其原因,可以总结为如下:
- 内存分配更加合理,使用 RingBuffer 数据结构,数组元素在初始化时一次性全部创建,提升缓存命中率;对象循环利用,避免频繁 GC。
- 能够避免伪共享,提升缓存利用率。
- 采用无锁算法,避免频繁加锁、解锁的性能消耗。
- 支持批量消费,消费者可以无锁方式消费多个消息。
Disruptor 的使用比 Java SDK 提供 BlockingQueue 要复杂一些,但是总体思路还是一致的,其大致情况如下:
在 Disruptor 中,生产者生产的对象(也就是消费者消费的对象)称为 Event,使用 Disruptor 必须自定义 Event,例如示例代码的自定义 Event 是 LongEvent;
构建 Disruptor 对象除了要指定队列大小外,还需要传入一个 EventFactory,示例代码中传入的是
LongEvent::new;消费 Disruptor 中的 Event 需要通过 handleEventsWith() 方法注册一个事件处理器,发布 Event 则需要通过 publishEvent() 方法。
// 自定义 Event class LongEvent { private long value; public void set(long value) { this.value = value; } } // 指定 RingBuffer 大小, // 必须是 2 的 N 次方 int bufferSize = 1024; // 构建 Disruptor Disruptor<LongEvent> disruptor = new Disruptor<>( LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE); // 注册事件处理器 disruptor.handleEventsWith( (event, sequence, endOfBatch) -> System.out.println("E: "+event)); // 启动 Disruptor disruptor.start(); // 获取 RingBuffer RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); // 生产 Event ByteBuffer bb = ByteBuffer.allocate(8); for (long l = 0; true; l++){ bb.putLong(0, l); // 生产者生产消息 ringBuffer.publishEvent( (event, sequence, buffer) -> event.set(buffer.getLong(0)), bb); Thread.sleep(1000); }
RingBuffer 如何提升性能
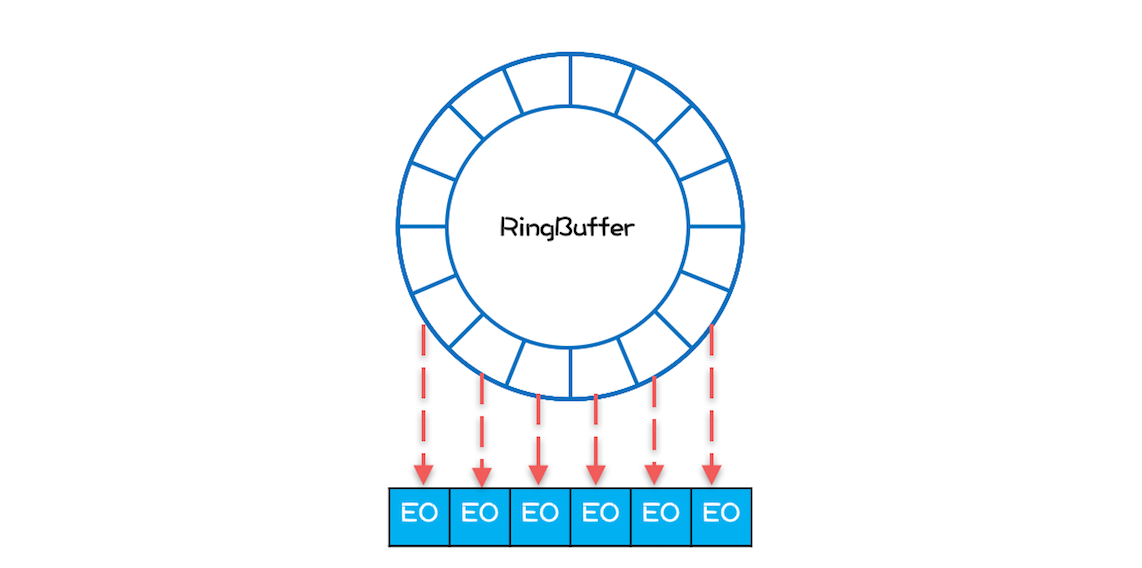
Java SDK 中 ArrayBlockingQueue 使用数组作为底层的数据存储,而 Disruptor 是使用** RingBuffer **作为数据存储。RingBuffer 本质上也是数组。
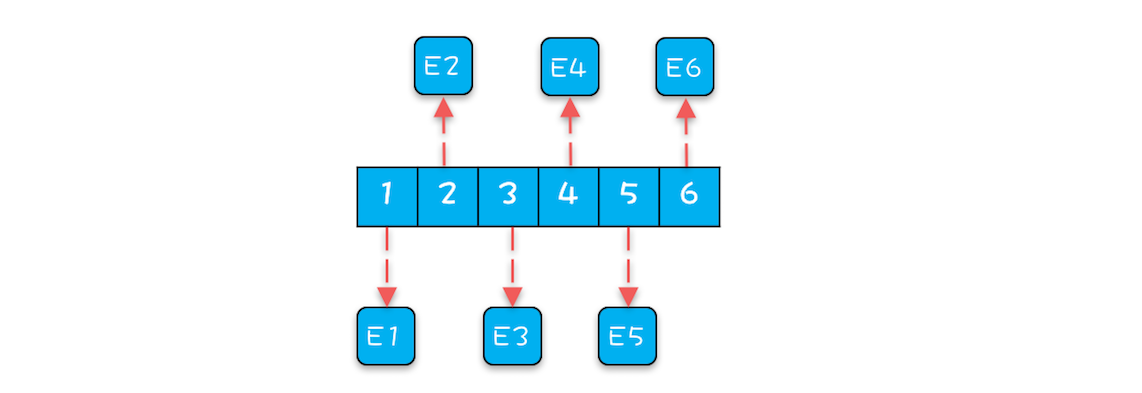
生产者线程向 ArrayBlockingQueue 增加一个元素,每次增加元素 E 之前,都需要创建一个对象 E,如下图所示,ArrayBlockingQueue 内部有 6 个元素,这 6 个元素都是由生产者线程创建的,由于创建这些元素的时间基本上是离散的,所以这些元素的内存地址大概率也不是连续的。
Disruptor 内部的 RingBuffer 也是用数组实现的,但是这个数组中的所有元素在初始化时是一次性全部创建的,所以这些元素的内存地址大概率是连续的,相关的代码如下所示。
for (int i=0; i<bufferSize; i++){
//entries[] 就是 RingBuffer 内部的数组
//eventFactory 就是前面示例代码中传入的 LongEvent::new
entries[BUFFER_PAD + i]
= eventFactory.newInstance();
}
数组中所有元素内存地址连续能提升性能。因为消费者线程在消费的时候,是遵循空间局部性原理的,消费完第 1 个元素,很快就会消费第 2 个元素;当消费第 1 个元素 E1 的时候,CPU 会把内存中 E1 后面的数据也加载进 Cache,如果 E1 和 E2 在内存中的地址是连续的,那么 E2 也就会被加载进 Cache 中,然后当消费第 2 个元素的时候,由于 E2 已经在 Cache 中了,所以就不需要从内存中加载了,这样就能大大提升性能。
除此之外,在 Disruptor 中,生产者线程通过 publishEvent() 发布 Event 的时候,并不是创建一个新的 Event,而是通过 event.set() 方法修改 Event, 也就是说 RingBuffer 创建的 Event 是可以循环利用的,这样还能避免频繁创建、删除 Event 导致的频繁 GC 问题。
如何避免“伪共享”
伪共享指的是由于共享缓存行导致缓存无效的场景。
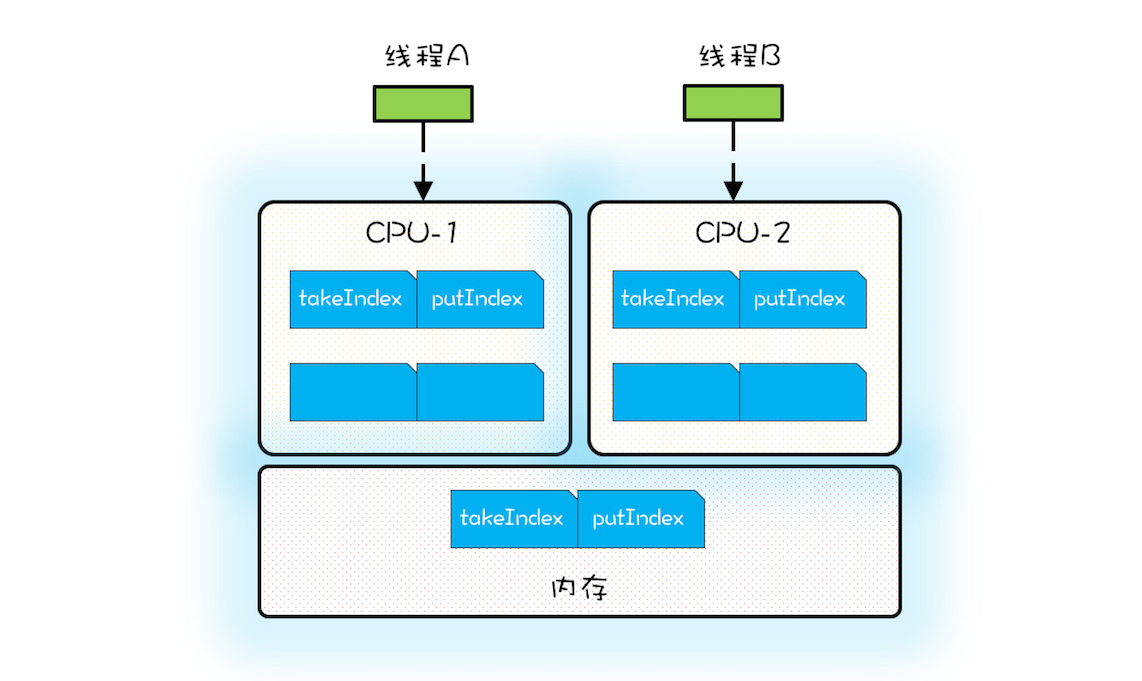
避免伪共享的方法是:
每个变量独占一个缓存行、不共享缓存行就可以了,具体技术是缓存行填充。比如想让 takeIndex 独占一个缓存行,可以在 takeIndex 的前后各填充 56 个字节,这样就一定能保证 takeIndex 独占一个缓存行。下面的示例代码出自 Disruptor,Sequence 对象中的 value 属性就能避免伪共享,因为这个属性前后都填充了 56 个字节。Disruptor 中很多对象,例如 RingBuffer、RingBuffer 内部的数组都用到了这种填充技术来避免伪共享。
//前:填充 56 字节
class LhsPadding{
long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding{
volatile long value;
}
//后:填充 56 字节
class RhsPadding extends Value{
long p9, p10, p11, p12, p13, p14, p15;
}
class Sequence extends RhsPadding{
//省略实现
}
Disruptor 中的无锁算法
Disruptor 中最复杂的是入队操作,所以我们重点来看看入队操作是如何实现的。
对于入队操作,最关键的要求是不能覆盖没有消费的元素;对于出队操作,最关键的要求是不能读取没有写入的元素,所以 Disruptor 中也一定会维护类似出队索引和入队索引这样两个关键变量。Disruptor 中的 RingBuffer 维护了入队索引,但是并没有维护出队索引,这是因为在 Disruptor 中多个消费者可以同时消费,每个消费者都会有一个出队索引,所以 RingBuffer 的出队索引是所有消费者里面最小的那一个。
下面是 Disruptor 生产者入队操作的核心代码,看上去很复杂,其实逻辑很简单:如果没有足够的空余位置,就出让 CPU 使用权,然后重新计算;反之则用 CAS 设置入队索引。
//生产者获取 n 个写入位置
do {
//cursor 类似于入队索引,指的是上次生产到这里
current = cursor.get();
//目标是在生产 n 个
next = current + n;
//减掉一个循环
long wrapPoint = next - bufferSize;
//获取上一次的最小消费位置
long cachedGatingSequence = gatingSequenceCache.get();
//没有足够的空余位置
if (wrapPoint>cachedGatingSequence || cachedGatingSequence>current){
//重新计算所有消费者里面的最小值位置
long gatingSequence = Util.getMinimumSequence(
gatingSequences, current);
//仍然没有足够的空余位置,出让 CPU 使用权,重新执行下一循环
if (wrapPoint > gatingSequence){
LockSupport.parkNanos(1);
continue;
}
//从新设置上一次的最小消费位置
gatingSequenceCache.set(gatingSequence);
} else if (cursor.compareAndSet(current, next)){
//获取写入位置成功,跳出循环
break;
}
} while (true);
案例分析(四):高性能数据库连接池 HiKariCP
业界知名的数据库连接池有不少,例如 c3p0、DBCP、Tomcat JDBC Connection Pool、Druid 等,不过最近最火的是 HiKariCP。
HiKariCP 号称是业界跑得最快的数据库连接池,这两年发展得顺风顺水,尤其是 Springboot 2.0 将其作为默认数据库连接池。
什么是数据库连接池
数据库连接池和线程池一样,都属于池化资源,作用都是避免重量级资源的频繁创建和销毁,对于数据库连接池来说,也就是避免数据库连接频繁创建和销毁。如下图所示,服务端会在运行期持有一定数量的数据库连接,当需要执行 SQL 时,并不是直接创建一个数据库连接,而是从连接池中获取一个;当 SQL 执行完,也并不是将数据库连接真的关掉,而是将其归还到连接池中。
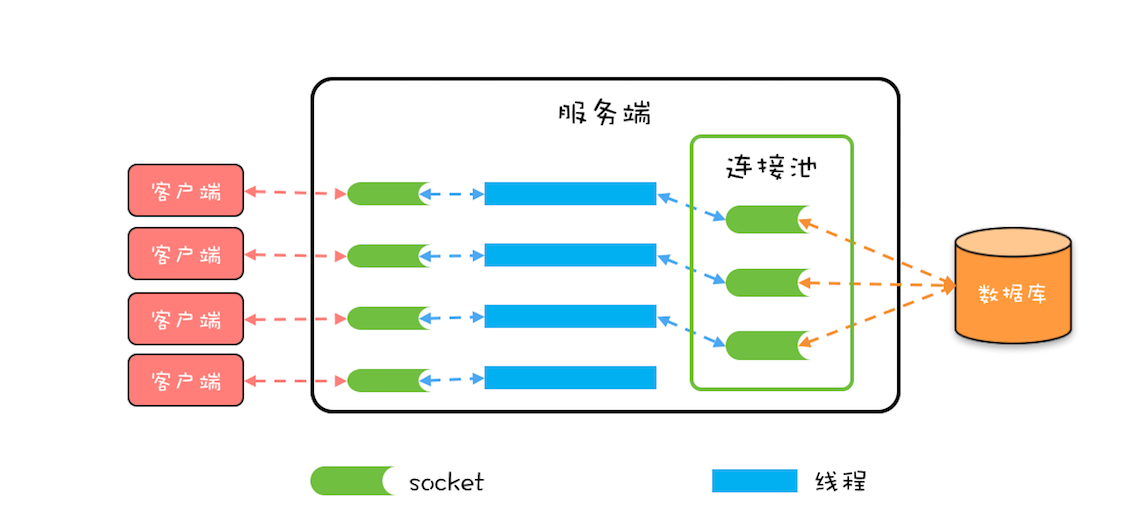
执行数据库操作基本上是一系列规范化的步骤:
- 通过数据源获取一个数据库连接;
- 创建 Statement;
- 执行 SQL;
- 通过 ResultSet 获取 SQL 执行结果;
- 释放 ResultSet;
- 释放 Statement;
- 释放数据库连接。
下面的示例代码,通过 ds.getConnection() 获取一个数据库连接时,其实是向数据库连接池申请一个数据库连接,而不是创建一个新的数据库连接。同样,通过 conn.close() 释放一个数据库连接时,也不是直接将连接关闭,而是将连接归还给数据库连接池。
//数据库连接池配置
HikariConfig config = new HikariConfig();
config.setMinimumIdle(1);
config.setMaximumPoolSize(2);
config.setConnectionTestQuery("SELECT 1");
config.setDataSourceClassName("org.h2.jdbcx.JdbcDataSource");
config.addDataSourceProperty("url", "jdbc:h2:mem:test");
// 创建数据源
DataSource ds = new HikariDataSource(config);
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 获取数据库连接
conn = ds.getConnection();
// 创建 Statement
stmt = conn.createStatement();
// 执行 SQL
rs = stmt.executeQuery("select * from abc");
// 获取结果
while (rs.next()) {
int id = rs.getInt(1);
......
}
} catch(Exception e) {
e.printStackTrace();
} finally {
//关闭 ResultSet
close(rs);
//关闭 Statement
close(stmt);
//关闭 Connection
close(conn);
}
//关闭资源
void close(AutoCloseable rs) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
HiKariCP 官方网站 解释了其性能之所以如此之高的秘密。微观上 HiKariCP 程序编译出的字节码执行效率更高,站在字节码的角度去优化 Java 代码,HiKariCP 的作者对性能的执着可见一斑,不过遗憾的是他并没有详细解释都做了哪些优化。而宏观上主要是和两个数据结构有关,一个是 FastList,另一个是 ConcurrentBag。下面我们来看看它们是如何提升 HiKariCP 的性能的。
FastList 解决了哪些性能问题
按照规范步骤,执行完数据库操作之后,需要依次关闭 ResultSet、Statement、Connection,但是总有粗心的同学只是关闭了 Connection,而忘了关闭 ResultSet 和 Statement。为了解决这种问题,最好的办法是当关闭 Connection 时,能够自动关闭 Statement。为了达到这个目标,Connection 就需要跟踪创建的 Statement,最简单的办法就是将创建的 Statement 保存在数组 ArrayList 里,这样当关闭 Connection 的时候,就可以依次将数组中的所有 Statement 关闭。
HiKariCP 觉得用 ArrayList 还是太慢,当通过 conn.createStatement() 创建一个 Statement 时,需要调用 ArrayList 的 add() 方法加入到 ArrayList 中,这个是没有问题的;但是当通过 stmt.close() 关闭 Statement 的时候,需要调用 ArrayList 的 remove() 方法来将其从 ArrayList 中删除,这里是有优化余地的。
假设一个 Connection 依次创建 6 个 Statement,分别是 S1、S2、S3、S4、S5、S6,按照正常的编码习惯,关闭 Statement 的顺序一般是逆序的,关闭的顺序是:S6、S5、S4、S3、S2、S1,而 ArrayList 的 remove(Object o) 方法是顺序遍历查找,逆序删除而顺序查找,这样的查找效率就太慢了。如何优化呢?很简单,优化成逆序查找就可以了。
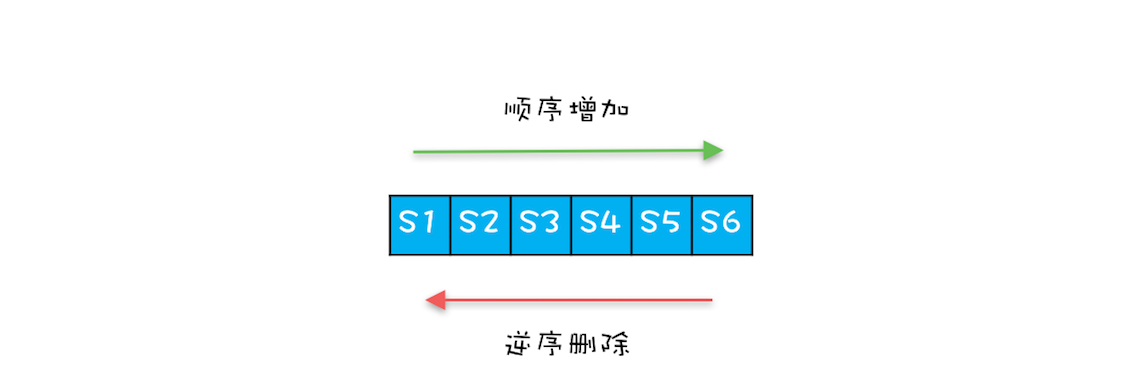
HiKariCP 中的 FastList 相对于 ArrayList 的一个优化点就是将 remove(Object element) 方法的查找顺序变成了逆序查找。除此之外,FastList 还有另一个优化点,是 get(int index) 方法没有对 index 参数进行越界检查,HiKariCP 能保证不会越界,所以不用每次都进行越界检查。
ConcurrentBag 解决了哪些性能问题
如果让我们自己来实现一个数据库连接池,最简单的办法就是用两个阻塞队列来实现,一个用于保存空闲数据库连接的队列 idle,另一个用于保存忙碌数据库连接的队列 busy;获取连接时将空闲的数据库连接从 idle 队列移动到 busy 队列,而关闭连接时将数据库连接从 busy 移动到 idle。这种方案将并发问题委托给了阻塞队列,实现简单,但是性能并不是很理想。因为 Java SDK 中的阻塞队列是用锁实现的,而高并发场景下锁的争用对性能影响很大。
//忙碌队列
BlockingQueue<Connection> busy;
//空闲队列
BlockingQueue<Connection> idle;
HiKariCP 并没有使用 Java SDK 中的阻塞队列,而是自己实现了一个叫做 ConcurrentBag 的并发容器。ConcurrentBag 的设计最初源自 C#,它的一个核心设计是使用 ThreadLocal 避免部分并发问题,不过 HiKariCP 中的 ConcurrentBag 并没有完全参考 C#的实现,下面我们来看看它是如何实现的。
ConcurrentBag 中最关键的属性有 4 个,分别是:用于存储所有的数据库连接的共享队列 sharedList、线程本地存储 threadList、等待数据库连接的线程数 waiters 以及分配数据库连接的工具 handoffQueue。其中,handoffQueue 用的是 Java SDK 提供的 SynchronousQueue,SynchronousQueue 主要用于线程之间传递数据。
//用于存储所有的数据库连接
CopyOnWriteArrayList<T> sharedList;
//线程本地存储中的数据库连接
ThreadLocal<List<Object>> threadList;
//等待数据库连接的线程数
AtomicInteger waiters;
//分配数据库连接的工具
SynchronousQueue<T> handoffQueue;
当线程池创建了一个数据库连接时,通过调用 ConcurrentBag 的 add() 方法加入到 ConcurrentBag 中,下面是 add() 方法的具体实现,逻辑很简单,就是将这个连接加入到共享队列 sharedList 中,如果此时有线程在等待数据库连接,那么就通过 handoffQueue 将这个连接分配给等待的线程。
//将空闲连接添加到队列
void add(final T bagEntry){
//加入共享队列
sharedList.add(bagEntry);
//如果有等待连接的线程,
//则通过 handoffQueue 直接分配给等待的线程
while (waiters.get() > 0
&& bagEntry.getState() == STATE_NOT_IN_USE
&& !handoffQueue.offer(bagEntry)) {
yield();
}
}
通过 ConcurrentBag 提供的 borrow() 方法,可以获取一个空闲的数据库连接,borrow() 的主要逻辑是:
- 首先查看线程本地存储是否有空闲连接,如果有,则返回一个空闲的连接;
- 如果线程本地存储中无空闲连接,则从共享队列中获取。
- 如果共享队列中也没有空闲的连接,则请求线程需要等待。
需要注意的是,线程本地存储中的连接是可以被其他线程窃取的,所以需要用 CAS 方法防止重复分配。在共享队列中获取空闲连接,也采用了 CAS 方法防止重复分配。
T borrow(long timeout, final TimeUnit timeUnit){
// 先查看线程本地存储是否有空闲连接
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
final T bagEntry = weakThreadLocals
? ((WeakReference<T>) entry).get()
: (T) entry;
//线程本地存储中的连接也可以被窃取,
//所以需要用 CAS 方法防止重复分配
if (bagEntry != null
&& bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 线程本地存储中无空闲连接,则从共享队列中获取
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
//如果共享队列中有空闲连接,则返回
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
//共享队列中没有连接,则需要等待
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null
|| bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
//重新计算等待时间
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
//超时没有获取到连接,返回 null
return null;
} finally {
waiters.decrementAndGet();
}
}
释放连接需要调用 ConcurrentBag 提供的 requite() 方法,该方法的逻辑很简单,首先将数据库连接状态更改为 STATE_NOT_IN_USE,之后查看是否存在等待线程,如果有,则分配给等待线程;如果没有,则将该数据库连接保存到线程本地存储里。
//释放连接
void requite(final T bagEntry){
//更新连接状态
bagEntry.setState(STATE_NOT_IN_USE);
//如果有等待的线程,则直接分配给线程,无需进入任何队列
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE
|| handoffQueue.offer(bagEntry)) {
return;
} else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
} else {
yield();
}
}
//如果没有等待的线程,则进入线程本地存储
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals
? new WeakReference<>(bagEntry)
: bagEntry);
}
}
Actor 模型:面向对象原生的并发模型
Hello Actor 模型
Actor 模型本质上是一种计算模型,基本的计算单元称为 Actor,换言之,在 Actor 模型中,所有的计算都是在 Actor 中执行的。在面向对象编程里面,一切都是对象;在 Actor 模型里,一切都是 Actor,并且 Actor 之间是完全隔离的,不会共享任何变量。
并发问题的根源就在于共享变量,而 Actor 模型中 Actor 之间不共享变量,所以很多人就把 Actor 模型定义为一种并发计算模型。
Java 语言本身并不支持 Actor 模型,所以如果你想在 Java 语言里使用 Actor 模型,就需要借助第三方类库,目前能完备地支持 Actor 模型而且比较成熟的类库就是** Akka **了。
在下面的示例代码中,我们首先创建了一个 ActorSystem(Actor 不能脱离 ActorSystem 存在);之后创建了一个 HelloActor,Akka 中创建 Actor 并不是 new 一个对象出来,而是通过调用 system.actorOf() 方法创建的,该方法返回的是 ActorRef,而不是 HelloActor;最后通过调用 ActorRef 的 tell() 方法给 HelloActor 发送了一条消息 “Actor” 。
//该 Actor 当收到消息 message 后,
//会打印 Hello message
static class HelloActor
extends UntypedActor {
@Override
public void onReceive(Object message) {
System.out.println("Hello " + message);
}
}
public static void main(String[] args) {
//创建 Actor 系统
ActorSystem system = ActorSystem.create("HelloSystem");
//创建 HelloActor
ActorRef helloActor =
system.actorOf(Props.create(HelloActor.class));
//发送消息给 HelloActor
helloActor.tell("Actor", ActorRef.noSender());
}
消息和对象方法的区别
Actor 中的消息机制,就可以类比这现实世界里的写信。Actor 内部有一个邮箱(Mailbox),接收到的消息都是先放到邮箱里,如果邮箱里有积压的消息,那么新收到的消息就不会马上得到处理,也正是因为 Actor 使用单线程处理消息,所以不会出现并发问题。你可以把 Actor 内部的工作模式想象成只有一个消费者线程的生产者-消费者模式。
在 Actor 模型里,发送消息仅仅是把消息发出去而已,接收消息的 Actor 在接收到消息后,也不一定会立即处理,也就是说** Actor 中的消息机制完全是异步的**。而调用对象方法,实际上是同步的,对象方法 return 之前,调用方会一直等待。
除此之外,调用对象方法,需要持有对象的引用,所有的对象必须在同一个进程中。而在 Actor 中发送消息,类似于现实中的写信,只需要知道对方的地址就可以,发送消息和接收消息的 Actor 可以不在一个进程中,也可以不在同一台机器上。因此,Actor 模型不但适用于并发计算,还适用于分布式计算。
Actor 的规范化定义
Actor 是一种基础的计算单元,具体来讲包括三部分能力,分别是:
- 处理能力,处理接收到的消息。
- 存储能力,Actor 可以存储自己的内部状态,并且内部状态在不同 Actor 之间是绝对隔离的。
- 通信能力,Actor 可以和其他 Actor 之间通信。
当一个 Actor 接收的一条消息之后,这个 Actor 可以做以下三件事:
- 创建更多的 Actor;
- 发消息给其他 Actor;
- 确定如何处理下一条消息。
用 Actor 实现累加器
在下面的示例代码中,CounterActor 内部持有累计值 counter,当 CounterActor 接收到一个数值型的消息 message 时,就将累计值 counter += message;但如果是其他类型的消息,则打印当前累计值 counter。在 main() 方法中,我们启动了 4 个线程来执行累加操作。整个程序没有锁,也没有 CAS,但是程序是线程安全的。
//累加器
static class CounterActor extends UntypedActor {
private int counter = 0;
@Override
public void onReceive(Object message){
//如果接收到的消息是数字类型,执行累加操作,
//否则打印 counter 的值
if (message instanceof Number) {
counter += ((Number) message).intValue();
} else {
System.out.println(counter);
}
}
}
public static void main(String[] args) throws InterruptedException {
//创建 Actor 系统
ActorSystem system = ActorSystem.create("HelloSystem");
//4 个线程生产消息
ExecutorService es = Executors.newFixedThreadPool(4);
//创建 CounterActor
ActorRef counterActor =
system.actorOf(Props.create(CounterActor.class));
//生产 4*100000 个消息
for (int i=0; i<4; i++) {
es.execute(()->{
for (int j=0; j<100000; j++) {
counterActor.tell(1, ActorRef.noSender());
}
});
}
//关闭线程池
es.shutdown();
//等待 CounterActor 处理完所有消息
Thread.sleep(1000);
//打印结果
counterActor.tell("", ActorRef.noSender());
//关闭 Actor 系统
system.shutdown();
}
软件事务内存:借鉴数据库的并发经验
软件事务内存(Software Transactional Memory,简称 STM)。传统的数据库事务,支持 4 个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),也就是大家常说的 ACID,STM 由于不涉及到持久化,所以只支持 ACI。
用 STM 实现转账
并发转账可以简单地使用 synchronized 将 transfer() 方法变成同步方法,但并不能解决并发问题,因为还存在死锁问题。
class UnsafeAccount {
//余额
private long balance;
//构造函数
public UnsafeAccount(long balance) {
this.balance = balance;
}
//转账
void transfer(UnsafeAccount target, long amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
该转账操作若使用数据库事务就会非常简单,如下面的示例代码所示。如果所有 SQL 都正常执行,则通过 commit() 方法提交事务;如果 SQL 在执行过程中有异常,则通过 rollback() 方法回滚事务。数据库保证在并发情况下不会有死锁,而且还能保证前面我们说的原子性、一致性、隔离性和持久性,也就是 ACID。
Connection conn = null;
try{
//获取数据库连接
conn = DriverManager.getConnection();
//设置手动提交事务
conn.setAutoCommit(false);
//执行转账 SQL
......
//提交事务
conn.commit();
} catch (Exception e) {
//出现异常回滚事务
conn.rollback();
}
那如果用 STM 又该如何实现呢?Java 语言并不支持 STM,不过可以借助第三方的类库来支持,Multiverse 就是个不错的选择。下面的示例代码就是借助 Multiverse 实现了线程安全的转账操作,相比较上面线程不安全的 UnsafeAccount,其改动并不大,仅仅是将余额的类型从 long 变成了 TxnLong ,将转账的操作放到了 atomic(()->{}) 中。
class Account{
//余额
private TxnLong balance;
//构造函数
public Account(long balance){
this.balance = StmUtils.newTxnLong(balance);
}
//转账
public void transfer(Account to, int amt){
//原子化操作
atomic(()->{
if (this.balance.get() > amt) {
this.balance.decrement(amt);
to.balance.increment(amt);
}
});
}
}
一个关键的 atomic() 方法就把并发问题解决了,这个方案看上去比传统的方案的确简单了很多,那它是如何实现的呢?数据库事务发展了几十年了,目前被广泛使用的是** MVCC**(全称是 Multi-Version Concurrency Control),也就是多版本并发控制。
MVCC 可以简单地理解为数据库事务在开启的时候,会给数据库打一个快照,以后所有的读写都是基于这个快照的。当提交事务的时候,如果所有读写过的数据在该事务执行期间没有发生过变化,那么就可以提交;如果发生了变化,说明该事务和有其他事务读写的数据冲突了,这个时候是不可以提交的。
为了记录数据是否发生了变化,可以给每条数据增加一个版本号,这样每次成功修改数据都会增加版本号的值。MVCC 的工作原理和乐观锁非常相似。有不少 STM 的实现方案都是基于 MVCC 的,例如知名的 Clojure STM。
下面我们就用最简单的代码基于 MVCC 实现一个简版的 STM,这样你会对 STM 以及 MVCC 的工作原理有更深入的认识。
自己实现 STM
我们首先要做的,就是让 Java 中的对象有版本号,在下面的示例代码中,VersionedRef 这个类的作用就是将对象 value 包装成带版本号的对象。按照 MVCC 理论,数据的每一次修改都对应着一个唯一的版本号,所以不存在仅仅改变 value 或者 version 的情况,用不变性模式就可以很好地解决这个问题,所以 VersionedRef 这个类被我们设计成了不可变的。
所有对数据的读写操作,一定是在一个事务里面,TxnRef 这个类负责完成事务内的读写操作,读写操作委托给了接口 Txn,Txn 代表的是读写操作所在的当前事务, 内部持有的 curRef 代表的是系统中的最新值。
//带版本号的对象引用
public final class VersionedRef<T> {
final T value;
final long version;
//构造方法
public VersionedRef(T value, long version) {
this.value = value;
this.version = version;
}
}
//支持事务的引用
public class TxnRef<T> {
//当前数据,带版本号
volatile VersionedRef curRef;
//构造方法
public TxnRef(T value) {
this.curRef = new VersionedRef(value, 0L);
}
//获取当前事务中的数据
public T getValue(Txn txn) {
return txn.get(this);
}
//在当前事务中设置数据
public void setValue(T value, Txn txn) {
txn.set(this, value);
}
}
STMTxn 是 Txn 最关键的一个实现类,事务内对于数据的读写,都是通过它来完成的。STMTxn 内部有两个 Map:inTxnMap,用于保存当前事务中所有读写的数据的快照;writeMap,用于保存当前事务需要写入的数据。每个事务都有一个唯一的事务 ID txnId,这个 txnId 是全局递增的。
STMTxn 有三个核心方法,分别是读数据的 get() 方法、写数据的 set() 方法和提交事务的 commit() 方法。其中,get() 方法将要读取数据作为快照放入 inTxnMap,同时保证每次读取的数据都是一个版本。set() 方法会将要写入的数据放入 writeMap,但如果写入的数据没被读取过,也会将其放入 inTxnMap。
至于 commit() 方法,我们为了简化实现,使用了互斥锁,所以事务的提交是串行的。commit() 方法的实现很简单,首先检查 inTxnMap 中的数据是否发生过变化,如果没有发生变化,那么就将 writeMap 中的数据写入(这里的写入其实就是 TxnRef 内部持有的 curRef);如果发生过变化,那么就不能将 writeMap 中的数据写入了。
//事务接口
public interface Txn {
<T> T get(TxnRef<T> ref);
<T> void set(TxnRef<T> ref, T value);
}
//STM 事务实现类
public final class STMTxn implements Txn {
//事务 ID 生成器
private static AtomicLong txnSeq = new AtomicLong(0);
//当前事务所有的相关数据
private Map<TxnRef, VersionedRef> inTxnMap = new HashMap<>();
//当前事务所有需要修改的数据
private Map<TxnRef, Object> writeMap = new HashMap<>();
//当前事务 ID
private long txnId;
//构造函数,自动生成当前事务 ID
STMTxn() {
txnId = txnSeq.incrementAndGet();
}
//获取当前事务中的数据
@Override
public <T> T get(TxnRef<T> ref) {
//将需要读取的数据,加入 inTxnMap
if (!inTxnMap.containsKey(ref)) {
inTxnMap.put(ref, ref.curRef);
}
return (T) inTxnMap.get(ref).value;
}
//在当前事务中修改数据
@Override
public <T> void set(TxnRef<T> ref, T value) {
//将需要修改的数据,加入 inTxnMap
if (!inTxnMap.containsKey(ref)) {
inTxnMap.put(ref, ref.curRef);
}
writeMap.put(ref, value);
}
//提交事务
boolean commit() {
synchronized (STM.commitLock) {
//是否校验通过
boolean isValid = true;
//校验所有读过的数据是否发生过变化
for(Map.Entry<TxnRef, VersionedRef> entry : inTxnMap.entrySet()){
VersionedRef curRef = entry.getKey().curRef;
VersionedRef readRef = entry.getValue();
//通过版本号来验证数据是否发生过变化
if (curRef.version != readRef.version) {
isValid = false;
break;
}
}
//如果校验通过,则所有更改生效
if (isValid) {
writeMap.forEach((k, v) -> {
k.curRef = new VersionedRef(v, txnId);
});
}
return isValid;
}
}
下面我们来模拟实现 Multiverse 中的原子化操作 atomic()。atomic() 方法中使用了类似于 CAS 的操作,如果事务提交失败,那么就重新创建一个新的事务,重新执行。
@FunctionalInterface
public interface TxnRunnable {
void run(Txn txn);
}
//STM
public final class STM {
//私有化构造方法
private STM() {
//提交数据需要用到的全局锁
static final Object commitLock = new Object();
//原子化提交方法
public static void atomic(TxnRunnable action) {
boolean committed = false;
//如果没有提交成功,则一直重试
while (!committed) {
//创建新的事务
STMTxn txn = new STMTxn();
//执行业务逻辑
action.run(txn);
//提交事务
committed = txn.commit();
}
}
}}
就这样,我们自己实现了 STM,并完成了线程安全的转账操作,使用方法和 Multiverse 差不多,这里就不赘述了,具体代码如下面所示。
class Account {
//余额
private TxnRef<Integer> balance;
//构造方法
public Account(int balance) {
this.balance = new TxnRef<Integer>(balance);
}
//转账操作
public void transfer(Account target, int amt){
STM.atomic((txn)->{
Integer from = balance.getValue(txn);
balance.setValue(from-amt, txn);
Integer to = target.balance.getValue(txn);
target.balance.setValue(to+amt, txn);
});
}
}
协程:更轻量级的线程
协程可以理解为一种轻量级的线程。从操作系统的角度来看,线程是在内核态中调度的,而协程是在用户态调度的,所以相对于线程来说,协程切换的成本更低。协程虽然也有自己的栈,但是相比线程栈要小得多,典型的线程栈大小差不多有 1M,而协程栈的大小往往只有几 K 或者几十 K。所以,无论是从时间维度还是空间维度来看,协程都比线程轻量得多。
支持协程的语言还是挺多的,例如 Golang、Python、Lua、Kotlin 等都支持协程。
CSP 模型:Golang 的主力队员
Golang 是一门号称从语言层面支持并发的编程语言,支持并发是 Golang 一个非常重要的特性。
Golang 支持协程,协程可以类比 Java 中的线程,解决并发问题的难点就在于线程(协程)之间的协作。那 Golang 是如何解决协作问题的呢?
总的来说,Golang 提供了两种不同的方案:一种方案支持协程之间以共享内存的方式通信,Golang 提供了管程和原子类来对协程进行同步控制,这个方案与 Java 语言类似;另一种方案支持协程之间以消息传递(Message-Passing)的方式通信,本质上是要避免共享,Golang 的这个方案是基于** CSP**(Communicating Sequential Processes)模型实现的。Golang 比较推荐的方案是后者。