《姜承尧的 MySQL 实战宝典》笔记
00 开篇词 从业务出发,开启海量 MySQL 架构设计
课程设计:
- 模块一、表结构设计:字段类型的选型、表结构设计、访问设计、物理存储设计
- 模块二、索引设计:索引原理、索引的创建和优化、索引的设计与调优(如多表 JOIN、子查询、分区表等)
- 模块三、高可用架构设计
- 模块四、分布式架构设计:分布式架构概述、分布式表结构设计、分布式索引设计、分布式事务
- 模块五、拓展:热点更新、数据迁移
01 数字类型:避免自增踩坑
数字类型
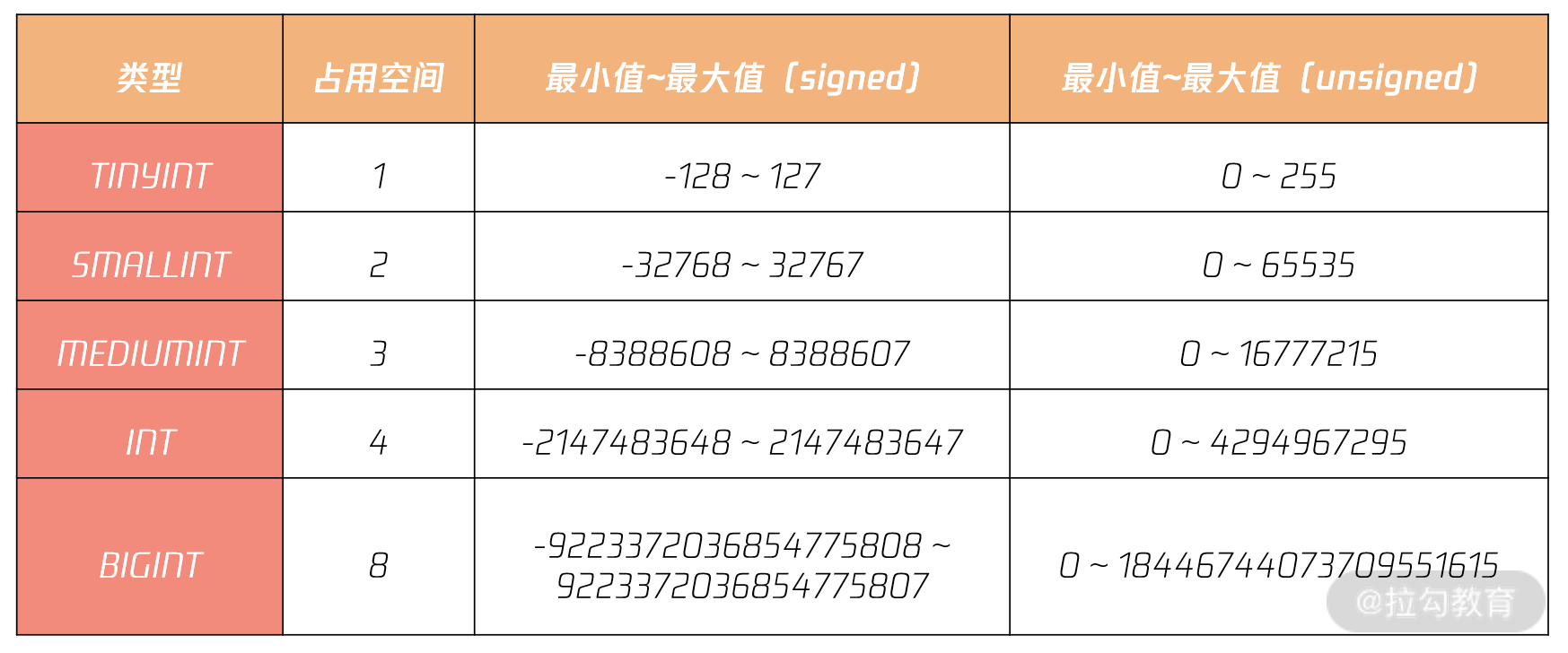
整型类型包括 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT。这些类型的存储空间和取值范围各不相同。
浮点类型包括 FLOAT 和 DOUBLE,但不推荐在生产环境中使用,因为存在精度问题。MySQL 8.0.17 版本后,使用 FLOAT 或 DOUBLE 会抛出警告,未来可能会废弃。
DECIMAL 是高精度类型,适合存储精确到小数点后的数据(如金额)。在海量并发业务中,不推荐使用 DECIMAL ,因为它的计算效率较低,更推荐使用 INT 类型。
业务表结构设计
自增主键:
- 推荐使用
BIGINT而不是INT作为自增主键,因为INT的上限(4 个字节)在海量业务中容易被突破。 - 自增主键在 MySQL 8.0 版本前存在回溯问题(自增值不持久化),可能导致主键冲突。
Unsigned 属性的问题:
- 不推荐使用
UNSIGNED属性,因为在进行减法运算时可能导致错误。 - 可以通过设置
sql_mode='NO_UNSIGNED_SUBTRACTION'来避免减法运算的错误。
不认同此观点,业务场景中未必需要使用无符号整型进行相减,且即使需要相减,大多数情况下不需要在 SQL 中执行。
资金字段的设计:
在海量并发业务中,不推荐使用 DECIMAL ,因为它的计算效率较低:
DECIMAL是变长字段,定长的整型存储更紧凑。DECIMAL是通过二进制实现的一种编码方式,计算效率远不如整型高效。
余额字段,更推荐使用 INT 类型。按单位分存储,如 1 元存储为 100,使用 BIGINT 类型。
02 字符串类型:不能忽略的 COLLATION
字符串类型
MySQL 的字符串类型有 CHAR、VARCHAR、BINARY、BLOB、TEXT、ENUM、SET。不同的类型在业务设计、数据库性能方面的表现完全不同。
CHAR(N)用于存储固定长度的字符,N 的范围是 0~255,表示字符数。VARCHAR(N)用于存储可变长度的字符,N 的范围是 0~65536,表示字符数。
字符集
- 常见的字符集有
GBK、UTF8,推荐使用UTF8MB4,因为它支持更多的字符(如 emoji)。 - 修改字符集时,需要使用
ALTER TABLE … CONVERT TO …命令,确保已有列的字符集也被修改。 - 排序规则用于字符串的比较和排序,常见的排序规则有
_ci(不区分大小写)、_cs(区分大小写)、_bin(二进制比较)。默认,MySQL 使用_ci排序规则。
在 UTF8MB4 字符集下,CHAR 和 VARCHAR 的底层实现都是变长存储。
业务表结构设计
用户性别设计
问题:使用 TINYINT 存储性别(如 0 表示女,1 表示男)会导致表达不清和脏数据问题。
解决方案:使用 ENUM 类型或 CHECK 约束(MySQL 8.0.16 及以上版本)来限制字段的取值范围。
不认同使用 ENUM 类型,不利于通用和移植。
隐私数据加密
问题:隐私数据如登录密码、手机、信用卡信息等需要加密,以防泄露。
解决方案:使用动态盐+非固定加密算法来存储隐私数据。
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
regDate DATETIME NOT NULL,
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);
密码存储格式:$salt$cryption_algorithm$value,其中 $salt 是动态盐值,$cryption_algorithm 是加密算法,$value 是加密后的值。
03 日期类型:TIMESTAMP 可能是巨坑
日期类型
DATETIME
- 格式为
YYYY-MM-DD HH:MM:SS,固定占用 8 个字节。 - 从 MySQL 5.6 开始支持毫秒精度,
DATETIME(6)表示存储 6 位毫秒。 - 适合存储不需要时区转换的日期时间。
TIMESTAMP
- 存储从
1970-01-01 00:00:00到现在的毫秒数,占用 4 个字节(带毫秒时占用 7 个字节)。 - 支持时区转换,适合需要处理不同时区的业务场景。
- 最大时间上限为
2038-01-19 03:14:07,存在“2038 年问题”。
业务表结构设计
DATETIME vs TIMESTAMP vs INT
- DATETIME:推荐使用。适合大多数业务场景,不涉及时区转换,性能稳定。
- TIMESTAMP:不推荐使用。适合需要时区转换的场景,但存在 2038 年问题和潜在的性能问题。
- 如果使用默认的系统时区,每次时间转换都需要调用底层系统函数
__tz_convert(),可能导致性能抖动。 - 建议在 MySQL 配置文件中显式设置时区,避免使用系统时区。
- 如果使用默认的系统时区,每次时间转换都需要调用底层系统函数
- INT:不推荐使用。虽然存储的是毫秒数,但可读性和可维护性差。
建议业务核心表都增加一个 DATETIME 类型的 last_modify_date 字段,并设置为自动更新(ON UPDATE CURRENT_TIMESTAMP)
04 非结构存储:用好 JSON 这张牌
实际业务场景中,使用 JSON 类型非常罕见。真需要存储无模式数据,更多会考虑使用 MongoDB、Elasticsearch 等专业的 Nosql。忽略
05 表结构设计:忘记范式准则
范式准则
- 一范式:所有属性都是不可分的基本数据项。
- 二范式:解决部分依赖。
- 三范式:解决传递依赖。
一言以蔽之,范式是为了消除冗余;反范式则是冗余数据。
注:在真实业务中,不必严格遵守三范式的要求,有时为了性能和便利性,可能还需要反范式设计。
表结构设计
表必须有主键(方法有:自增主键、UUID 主键、自定义生成主键)
使用 BIGINT 的自增类型作为主键的设计仅仅适合非核心业务表,比如告警表、日志表等。真正的核心业务表,一定不要用自增键做主键,主要原因如下:
- 自增存在回溯问题(解决办法是升级到 Mysql 8.0);
- 自增值在服务器端产生,存在并发性能问题。生成主键时,会加自增锁,若此时有大量插入请求,就可能会因为自增产生瓶颈;
- 自增值做主键,只能在当前实例中保证唯一,不能保证全局唯一;
- 公开数据值,容易引发安全问题,例如知道地址 http://www.example.com/User/10/,很容猜出 User 有 11、12 依次类推的值,容易引发数据泄露;
- MGR(MySQL Group Replication) 可能引起的性能问题;
- 分布式架构设计问题。
作者推荐采用 UUID。UUID 优点是全局唯一,使用简单;缺点是无序,且长度较长,影响性能。实际的业务线上,分布式 ID 更多的是采用自定义方式,例如雪花算法生成 ID 等。
06 表压缩:不仅仅是空间压缩
- MySQL 中的压缩都是基于页的压缩;
- COMPRESS 页压缩适合用于性能要求不高的业务表,如日志、监控、告警表等;
- COMPRESS 页压缩内存缓冲池存在压缩和解压的两个页,会严重影响性能;
- 对存储有压缩需求,又希望性能不要有明显退化,推荐使用 TPC 压缩;
- 通过 ALTER TABLE 启用 TPC 压缩后,还需要执行命令 OPTIMIZE TABLE 才能立即完成空间的压缩。
07 表的访问设计:你该选择 SQL 还是 NoSQL?
MySQL 可以同时作为关系型数据库、KV 数据库和文档数据库使用,底层数据都存储在 InnoDB 引擎中。但是,
术业有专攻,MySQL 在关系型数据库以外的其他领域,并不适用。
08 索引:排序的艺术
索引是什么
索引是提升查询速度的一种数据结构。
B+ 树索引在插入时对数据进行了排序,因此它可以提升查询速度,但是会影响插入或更新的性能。
B+树索引是数据库中最常见的索引数据结构,二叉树,哈希索引、红黑树、SkipList,在海量数据基于磁盘存储效率方面远不如 B+ 树索引高效。
B+树的特点是:树的高度低(通常 3~4 层),查询效率高,能在千万甚至上亿数据中快速定位记录。
B+树由根节点、中间节点和叶子节点组成,叶子节点存放所有排序后的数据。
B+树索引结构
所有 B+ 树都是从高度为 1 的树开始,然后根据数据的插入,慢慢增加树的高度。随着插入 B+ 树索引的记录变多,1 个页(16K)无法存放这么多数据,所以会发生 B+ 树的分裂,B+ 树的高度变为 2,当 B+ 树的高度大于等于 2 时,根节点和中间节点存放的是索引键对,由(索引键、指针)组成。
索引键就是排序的列,而指针是指向下一层的地址,在 MySQL 的 InnoDB 存储引擎中占用 6 个字节。若主键是 BIGINT 类型,占 8 个字节。也即是说,这样的一个键值对需要 8+6 = 14 字节。
一个高度为 2 的 B+ 树索引,理论上最多能存放多少行记录呢?
在 MySQL InnoDB 存储引擎中,一个页的大小为 16K。
根结点可以存储的记录数 = 页大小(16K) / 键值对大小(14) ≈ 1100
假设记录的平均大小为 1000 字节,则
叶子节点能存放的最多记录为 = 页大小(16K) / 记录平均大小(1000) ≈ 16
综上所述,树高度为 2 的 B+ 树索引,最多能存放的记录数为:
总记录数 = 1100 * 16 = 16,100
由此,可以推算出:
- 高度为 2 的 B+树索引最多能存放约 16,100 条记录,查询时只需 2 次 I/O。
- 高度为 3 的 B+树索引最多能存放约 19,360,000 条记录,查询时只需 3 次 I/O。
- 高度为 4 的 B+树索引最多能存放约 25 亿条记录,查询时只需 4 次 I/O。
优化 B+ 树索引的插入性能
- 顺序插入(如自增 ID 或时间列)的维护代价小,性能较好。
- 无序插入(如用户昵称)会导致页分裂、旋转等开销较大的操作,影响性能。
- 主键设计应尽量使用顺序值(如自增 ID),以保证高并发场景下的性能。
MySQL 中 B+树索引的管理
- 可以通过
mysql.innodb_index_stats表查看索引的统计信息,如记录数、叶子节点数等。 - 通过
sys.schema_unused_indexes表可以查看哪些索引未被使用,考虑删除这些无效索引。 - MySQL 8.0 支持索引不可见功能,可以在删除索引前将其设置为不可见,观察业务是否有影响。
总结
- 索引是加快查询的一种数据结构,其原理是插入时对数据排序,缺点是会影响插入的性能;
- MySQL 当前支持 B+树索引、全文索引、R 树索引;
- B+ 树索引的高度通常为 3~4 层,高度为 4 的 B+ 树能存放 25 亿左右的数据,只需要 4 次查询 I/O。
- MySQL 单表的索引没有个数限制,业务查询有具体需要,创建即可,不要迷信个数限制;
- 可以通过表 sys.schema_unused_indexes 和索引不可见特性,删除无用的索引。
09 索引组织表:万物皆索引
索引组织表
数据存储有堆表和索引组织表两种方式。
堆表 - 堆表中的数据无序存放, 数据的排序完全依赖于索引。索引的叶子节点存放数据在堆表中的地址。堆表在数据变更时性能较差,不适合高并发场景。
索引组织表:数据根据主键排序存放在索引中,主键索引也叫聚集索引(Clustered Index)。在索引组织表中,数据即索引,索引即数据。
二级索引(非聚集索引)
InnoDB 的数据是根据主键索引排序存储的,除了主键索引外,其他的索引都称之为二级索引(Secondeary Index), 或非聚集索引(None Clustered Index)。二级索引也是一颗 B+ 树索引。
- 二级索引的叶子节点存放索引键值和主键值,查询时需要通过主键值进行“回表”操作,才能获取完整记录。
- 二级索引的设计需要考虑插入的顺序性,顺序插入的性能较好,随机插入的性能较差。
- 二级索引的更新频率较高时(如
last_modify_date),可能会影响性能。
二级索引的性能评估
- 主键索引通常设计为顺序插入,性能较好。
- 二级索引的插入顺序性影响性能,如
name字段的索引插入是随机的,性能开销较大;而register_date字段的索引插入是顺序的,性能开销较小。 - 主键设计应尽量紧凑,以提升二级索引的性能和存储效率。
函数索引
- MySQL 5.7 版本开始支持函数索引,索引键可以是函数表达式。
- 函数索引可以优化业务 SQL 性能,特别是在查询条件中使用函数时。
- 函数索引还可以与虚拟列(Generated Column)结合使用,虚拟列不占用存储空间,索引本质上是函数索引。
- 虚拟列是通过函数表达式计算得出的列,不占用实际存储空间。
- 在虚拟列上创建索引可以简化 SQL 查询,提升查询性能。
总结
- 索引组织表主键是聚集索引,索引的叶子节点存放表中一整行完整记录;
- 除主键索引外的索引都是二级索引,索引的叶子节点存放的是(索引键值,主键值);
- 由于二级索引不存放完整记录,因此需要通过主键值再进行一次回表才能定位到完整数据;
- 索引组织表对比堆表,在海量并发的 OLTP 业务中能有更好的性能表现;
- 每种不同数据,对二级索引的性能开销影响是不一样的;
- 有时通过函数索引可以快速解决线上 SQL 的性能问题;
- 虚拟列不占用实际存储空间,在虚拟列上创建索引本质就是函数索引。
10 组合索引:用好,性能提升 10 倍!
组合索引的定义
- 组合索引是由多个列组成的 B+树索引,排序依据是多个列的组合。
- 组合索引既可以是主键索引,也可以是二级索引。
组合索引的排序与查询
- 组合索引的排序顺序决定了查询的效率。例如,组合索引(a, b)可以优化
a = ?和a = ? AND b = ?的查询,但不能优化b = ?的查询。 - 组合索引的顺序非常重要,(a, b)和(b, a)的索引排序结果完全不同。
组合索引的业务应用
- 避免额外排序:在业务中,常见的需求是根据某个列查询并按时间排序。通过创建合适的组合索引(如
(o_custkey, o_orderdate)),可以避免额外的排序操作,提升查询性能。 - 避免回表(覆盖索引):组合索引的叶子节点包含索引键值和主键值。如果查询的字段都在组合索引中,可以直接返回结果,无需回表,这种技术称为覆盖索引(Covering Index),能显著提升查询性能。
组合索引的三大优势
- 覆盖多个查询条件:组合索引可以覆盖多个查询条件,提升查询效率。
- 避免额外排序:通过组合索引可以避免 SQL 查询中的额外排序操作。
- 利用覆盖索引技术:组合索引可以包含多个列,利用索引覆盖技术可以避免回表,提升查询性能。
11 索引出错:请理解 CBO 的工作原理
- MySQL 优化器是 CBO(Cost-based Optimizer,基于成本的优化器)的;
- MySQL 会选择成本最低的执行计划,可以通过 EXPLAIN 命令查看每个 SQL 的成本;
- 一般只对高选择度的字段和字段组合创建索引,低选择度的字段如性别,不创建索引;
- 低选择性,但是数据存在倾斜,通过索引找出少部分数据,可以考虑创建索引;
- 若数据存在倾斜,可以创建直方图,让优化器知道索引中数据的分布,进一步校准执行计划。
12 JOIN 连接:到底能不能写 JOIN?
- MySQL 支持 Nested Loop Join 和 Hash Join 两种 JOIN 算法,前者通常用于 OLTP 业务,后者用于 OLAP 业务。
- 在 OLTP 业务中,JOIN 操作是高效的,尤其是在通过主键或索引进行过滤的情况下。
- 优化器会自动选择最优的执行计划,开发人员不必手动拆分 JOIN 语句。
- 索引设计是确保 JOIN 性能的关键,DBA 需要在业务上线前进行 SQL Review,确保索引的正确性。
13 子查询:放心地使用子查询功能吧!
- 子查询相比 JOIN 更易于人类理解,所以受众更广,使用更多;
- 当前 MySQL 8.0 版本可以“毫无顾忌”地写子查询,对于子查询的优化已经相当完备;
- 对于老版本的 MySQL,请 Review 所有子查询的 SQL 执行计划, 对于出现 DEPENDENT SUBQUERY 的提示,请务必即使进行优化,否则对业务将造成重大的性能影响;
- DEPENDENT SUBQUERY 的优化,一般是重写为派生表进行表连接。表连接的优化就是我们 12 讲所讲述的内容。
14 分区表:哪些场景我不建议用分区表?
- 当前 MySQL 的分区表支持 RANGE、LIST、HASH、KEY、COLUMNS 的分区算法;
- 分区表的创建需要主键包含分区列;
- 在分区表中唯一索引仅在当前分区文件唯一,而不是全局唯一;
- 分区表唯一索引推荐使用类似 UUID 的全局唯一实现;
- 分区表不解决性能问题,如果使用非分区列查询,性能反而会更差;
- 推荐分区表用于数据管理、速度快、日志小。
15 MySQL 复制:最简单也最容易配置出错
- binlog 记录了所有对于 MySQL 变更的操作;
- 可以通过命令 SHOW BINLOG EVENTS IN … FROM … 查看二进制日志的基本信息;
- 可以通过工具 mysqlbinlog 查看二进制日志的详细内容;
- 复制搭建虽然简单,但别忘记配置 crash safe 相关参数,否则可能导致主从数据不一致;
- 异步复制用于非核心业务场景,不要求数据一致性;
- 无损半同步复制用于核心业务场景,如银行、保险、证券等核心业务,需要严格保障数据一致性;
- 多源复制可将多个 Master 数据汇总到一个数据库示例进行分析;
- 延迟复制主要用于误操作防范,金融行业要特别考虑这样的场景。
16 读写分离设计:复制延迟?其实是你用错了
- MySQL 二进制日志是一种逻辑日志,便于将数据同步到异构的数据平台;
- 逻辑日志在事务提交时才写入,若存在大事务,则提交速度很慢,也会影响主从数据之间的同步;
- 在 MySQL 中务必将大事务拆分成小事务处理,这样才能避免主从数据延迟的问题;
- 通过配置 MTS 并行复制机制,可以进一步缩短主从数据延迟的问题,推荐使用 MySQL 5.7 版本,并配置成基于 WRITESET 的复制;
- 主从复制延迟监控不能依赖 Seconds_Behind_Master 的值,最好的方法是额外配置一张心跳表;
17 高可用设计:你怎么活用三大架构方案?
- 高可用是系统所能提供无故障服务的一种能力,度量单位是几个 9;
- 高可用实现基础是:冗余 + 故障转移;
18 金融级高可用架构:必不可少的数据核对
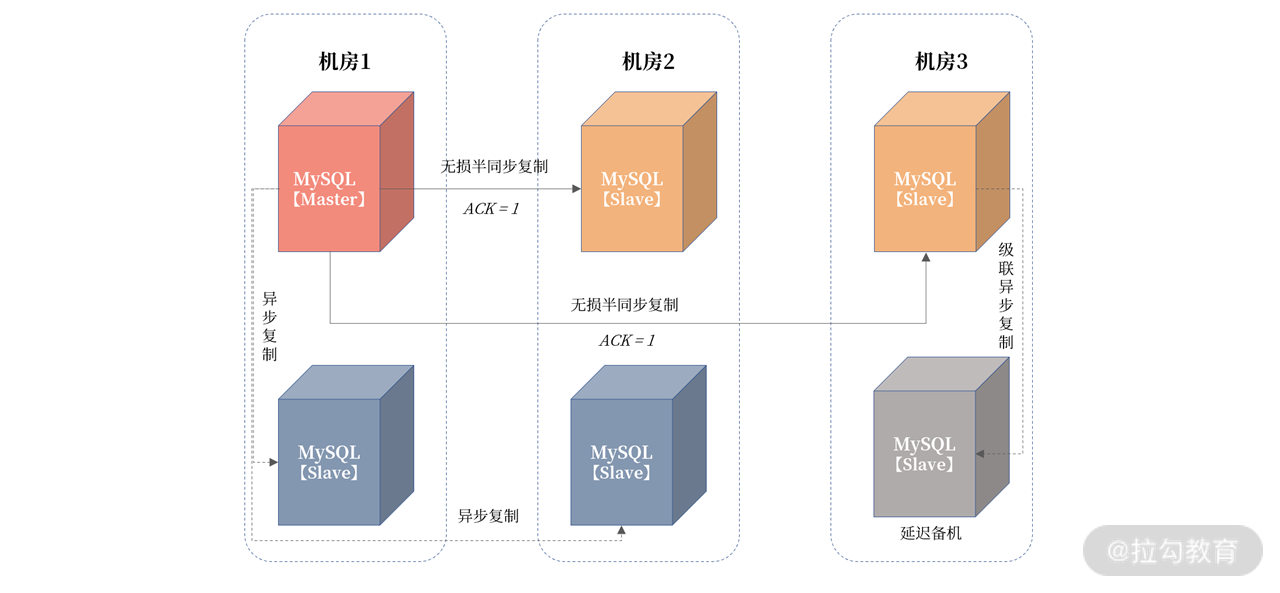
- 核心业务复制务必设置为无损半同步复制;
- 同城容灾使用三园区架构,一地三中心,或者两地三中心,机房见网络延迟不超过 5ms;
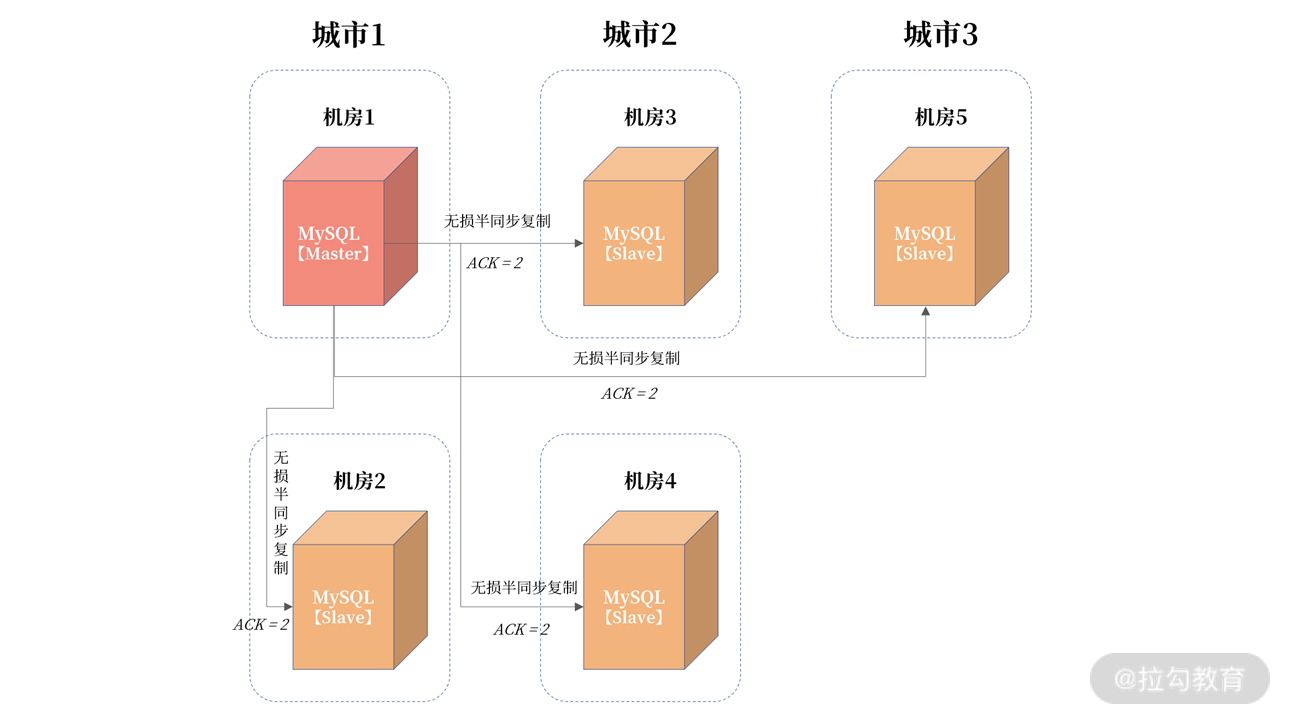
- 跨城容灾使用“三地五中心”,跨城机房距离超过 200KM,延迟超过 25ms;
- 跨城容灾架构由于网络耗时高,因此一般仅用于读多写少的业务,例如用户中心;
- 除了复制进行数据同步外,还需要额外的核对程序进行逻辑核对;
- 数据库层的逻辑核对,可以使用 last_modify_date 字段,取出最近修改的记录。
一地三中心架构
三地五中心
19 高可用套件:选择这么多,你该如何选?
MySQL 复制技术本身不能实现 failover 的功能。
为了实现数据切换的透明性,可以采用 VIP 和名字服务机制。VIP 仅用于同机房同网段,名字服务器,比如域名可以跨机房进行切换。
MySQL 常用的高可用套件有 MHA 和 Orchestrator,它们都能完成 failover 的工作。但是由于管理节点与 MySQL 通信采用 ssh 协议,所以安全性不高,性能也很一般,一般建议用在不超过 20 台数据库节点的环境中。
20 InnoDB Cluster:改变历史的新产品
从未在业务场景中见过,忽略
21 数据库备份:备份文件也要检查!
全量备份:备份当前时间点数据库中的所有数据,分为逻辑备份和物理备份。
- 逻辑备份:通过 SQL 语句备份数据,常用工具有
mysqldump、mysqlpump和mydumper。mysqldump:简单易用,但速度较慢。mysqlpump:支持多线程备份,但不保证一致性。mydumper:支持一致性备份和多线程恢复,是推荐的逻辑备份工具。
- 物理备份:直接备份数据库的物理文件,速度较快,常用工具有 MySQL 8.0 的
Clone Plugin和第三方工具Xtrabackup。
增量备份:备份二进制日志文件,结合全量备份可以实现基于时间点的恢复。
- 使用
mysqlbinlog工具进行增量备份和恢复。
22 分布式数据库架构:彻底理解什么叫分布式数据库
略
23 分布式数据库表结构设计:如何正确地将数据分片?
- 分布式数据库数据分片要先选择一个或多个字段作为分片键;
- 分片键的要求是业务经常访问的字段,且业务之间的表大多能根据这个分片键进行单元化;
- 如果选不出分片键,业务就无法进行分布式数据库的改造;
- 选择完分片键后,就要选择分片算法,通常是 RANGE 或 HASH 算法;
- 海量 OLTP 业务推荐使用 HASH 算法,强烈不推荐使用 RANGE 算法;
- 分片键和分片算法选择完后,就要进行分库分表设计,推荐不同库名表名的设计,这样能方便后续对分片数据进行扩缩容;
- 实际进行扩容时,可以使用过滤复制,仅复制需要的分片数据。
24 分布式数据库索引设计:二级索引、全局索引的最佳设计实践
忽略
25 分布式数据库架构选型:分库分表 or 中间件 ?
业界比较知名的 MySQL 分布式数据库中间件产品有:ShardingShpere、DBLE、TDSQL 等。
ShardingSphere 于 2020 年 4 月 16 日成为 Apache 软件基金会的顶级项目、社区熟度、功能支持较多,特别是对于分布式事务的支持,有多种选择(ShardingSphere 官网地址)。
DBLE 是由知名 MySQL 服务商爱可生公司开源的 MySQL 中间件产品,已用于四大行核心业务,完美支撑传统银行去 IOE,转型分布式架构的探索。除了中间件技术外,爱可生公司还有很多关于 MySQL 数据库、分布式数据库设计等方面的综合经验。
TDSQL MySQL 版(TDSQL for MySQL)是腾讯打造的一款分布式数据库产品,具备强一致高可用、全球部署架构、分布式水平扩展、高性能、企业级安全等特性,同时提供智能 DBA、自动化运营、监控告警等配套设施,为客户提供完整的分布式数据库解决方案。
26 分布式设计之禅:全链路的条带化设计
忽略
27 分布式事务:我们到底要不要使用 2PC?
忽略