《极客时间教程 - Java 并发编程实战》笔记三
《极客时间教程 - Java 并发编程实战》笔记三
Immutability 模式:如何利用不变性解决并发问题?
解决并发问题,其实最简单的办法就是让共享变量只有读操作,而没有写操作。这个办法如此重要,以至于被上升到了一种解决并发问题的设计模式:不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦被创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值,就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。
快速实现具备不可变性的类
将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。更严格的做法是这个类本身也是 final 的,也就是不允许继承。因为子类可以覆盖父类的方法,有可能改变不可变性。
经常用到的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。它们都严格遵守不可变类的三点要求:类和属性都是 final 的,所有方法均是只读的。
Java 的 String 方法也有类似字符替换操作,怎么能说所有方法都是只读的呢?下面的示例代码源自 Java 1.8 SDK,仅保留了关键属性 value[] 和 replace() 方法,你会发现:String 这个类以及它的属性 value[] 都是 final 的;而 replace() 方法的实现,就的确没有修改 value[],而是将替换后的字符串作为返回值返回了。
public final class String {
private final char value[];
// 字符替换
String replace(char oldChar,
char newChar) {
//无需替换,直接返回 this
if (oldChar == newChar){
return this;
}
int len = value.length;
int i = -1;
/* avoid getfield opcode */
char[] val = value;
//定位到需要替换的字符位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
//未找到 oldChar,无需替换
if (i >= len) {
return this;
}
//创建一个 buf[],这是关键
//用来保存替换后的字符串
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ?
newChar : c;
i++;
}
//创建一个新的字符串返回
//原字符串不会发生任何变化
return new String(buf, true);
}
}
利用享元模式避免创建重复对象
**享元模式(Flyweight Pattern)可以减少创建对象的数量,从而减少内存占用。**Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。
享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了 [-128,127] 之间的数字,这个对象池在 JVM 启动的时候就创建好了,而且这个对象池一直都不会变化,也就是说它是静态的。之所以采用这样的设计,是因为 Long 这个对象的状态共有 2^64 种,实在太多,不宜全部缓存,而 [-128,127] 之间的数字利用率最高。
Long valueOf(long l) {
final int offset = 128;
// [-128,127] 直接的数字做了缓存
if (l >= -128 && l <= 127) {
return LongCache
.cache[(int)l + offset];
}
return new Long(l);
}
//缓存,等价于对象池
//仅缓存 [-128,127] 直接的数字
static class LongCache {
static final Long cache[]
= new Long[-(-128) + 127 + 1];
static {
for(int i=0; i<cache.length; i++)
cache[i] = new Long(i-128);
}
}
基本上所有的基础类型的包装类都不适合做锁,因为它们内部用到了享元模式,这会导致看上去私有的锁,其实是共有的。例如在下面代码中,本意是 A 用锁 al,B 用锁 bl,各自管理各自的,互不影响。但实际上 al 和 bl 是一个对象,结果 A 和 B 共用的是一把锁。
class A {
Long al=Long.valueOf(1);
public void setAX(){
synchronized (al) {
//省略代码无数
}
}
}
class B {
Long bl=Long.valueOf(1);
public void setBY(){
synchronized (bl) {
//省略代码无数
}
}
}
使用 Immutability 式的注意事项
在使用 Immutability 模式的时候,需要注意以下两点:
- 对象的所有属性都是 final 的,并不能保证不可变性;
- 不可变对象也需要正确发布。
在 Java 语言中,final 修饰的属性一旦被赋值,就不可以再修改,但是如果属性的类型是普通对象,那么这个普通对象的属性是可以被修改的。例如下面的代码中,Bar 的属性 foo 虽然是 final 的,依然可以通过 setAge() 方法来设置 foo 的属性 age。所以,在使用 Immutability 模式的时候一定要确认保持不变性的边界在哪里,是否要求属性对象也具备不可变性。
class Foo{
int age=0;
int name="abc";
}
final class Bar {
final Foo foo;
void setAge(int a){
foo.age=a;
}
}
下面我们再看看如何正确地发布不可变对象。不可变对象虽然是线程安全的,但是并不意味着引用这些不可变对象的对象就是线程安全的。例如在下面的代码中,Foo 具备不可变性,线程安全,但是类 Bar 并不是线程安全的,类 Bar 中持有对 Foo 的引用 foo,对 foo 这个引用的修改在多线程中并不能保证可见性和原子性。
//Foo 线程安全
final class Foo{
final int age=0;
final int name="abc";
}
//Bar 线程不安全
class Bar {
Foo foo;
void setFoo(Foo f){
this.foo=f;
}
}
如果你的程序仅仅需要 foo 保持可见性,无需保证原子性,那么可以将 foo 声明为 volatile 变量,这样就能保证可见性。如果你的程序需要保证原子性,那么可以通过原子类来实现。下面的示例代码是合理库存的原子化实现,你应该很熟悉了,其中就是用原子类解决了不可变对象引用的原子性问题。
public class SafeWM {
class WMRange{
final int upper;
final int lower;
WMRange(int upper,int lower){
//省略构造函数实现
}
}
final AtomicReference<WMRange>
rf = new AtomicReference<>(
new WMRange(0,0)
);
// 设置库存上限
void setUpper(int v){
while(true){
WMRange or = rf.get();
// 检查参数合法性
if(v < or.lower){
throw new IllegalArgumentException();
}
WMRange nr = new
WMRange(v, or.lower);
if(rf.compareAndSet(or, nr)){
return;
}
}
}
}
总结
利用 Immutability 模式解决并发问题,也许你觉得有点陌生,其实你天天都在享受它的战果。Java 语言里面的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。Immutability 模式是最简单的解决并发问题的方法,建议当你试图解决一个并发问题时,可以首先尝试一下 Immutability 模式,看是否能够快速解决。
具备不变性的对象,只有一种状态,这个状态由对象内部所有的不变属性共同决定。其实还有一种更简单的不变性对象,那就是无状态。无状态对象内部没有属性,只有方法。除了无状态的对象,你可能还听说过无状态的服务、无状态的协议等等。无状态有很多好处,最核心的一点就是性能。在多线程领域,无状态对象没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。
Copy-on-Write 模式:不是延时策略的 COW
Copy-on-Write,经常被缩写为 COW 或者 CoW,顾名思义就是写时复制。
Copy-on-Write 模式的应用领域
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器,它们背后的设计思想就是 Copy-on-Write;通过 Copy-on-Write 这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。
Copy-on-Write 最大的应用领域还是在函数式编程领域。函数式编程的基础是不可变性(Immutability),所以函数式编程里面所有的修改操作都需要 Copy-on-Write 来解决。
一个真实案例
Router 的实现代码如下所示,是一种典型 Immutability 模式的实现,需要你注意的是我们重写了 equals 方法,这样 CopyOnWriteArraySet 的 add() 和 remove() 方法才能正常工作。
//路由信息
public final class Router{
private final String ip;
private final Integer port;
private final String iface;
//构造函数
public Router(String ip,
Integer port, String iface){
this.ip = ip;
this.port = port;
this.iface = iface;
}
//重写 equals 方法
public boolean equals(Object obj){
if (obj instanceof Router) {
Router r = (Router)obj;
return iface.equals(r.iface) &&
ip.equals(r.ip) &&
port.equals(r.port);
}
return false;
}
public int hashCode() {
//省略 hashCode 相关代码
}
}
//路由表信息
public class RouterTable {
//Key: 接口名
//Value: 路由集合
ConcurrentHashMap<String, CopyOnWriteArraySet<Router>>
rt = new ConcurrentHashMap<>();
//根据接口名获取路由表
public Set<Router> get(String iface){
return rt.get(iface);
}
//删除路由
public void remove(Router router) {
Set<Router> set=rt.get(router.iface);
if (set != null) {
set.remove(router);
}
}
//增加路由
public void add(Router router) {
Set<Router> set = rt.computeIfAbsent(
route.iface, r ->
new CopyOnWriteArraySet<>());
set.add(router);
}
}
线程本地存储模式:没有共享,就没有伤害
线程封闭,其本质上就是避免共享。没有共享,自然也就没有并发安全问题。
Java 中,ThreadLocal 就可以做到线程封闭。
ThreadLocal 的使用方法
SimpleDateFormat 不是线程安全的,如果要保证并发安全,可以使用 ThreadLocal 来解决。
static class SafeDateFormat {
//定义 ThreadLocal 变量
static final ThreadLocal<DateFormat>
tl=ThreadLocal.withInitial(
()-> new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss"));
static DateFormat get(){
return tl.get();
}
}
//不同线程执行下面代码
//返回的 df 是不同的
DateFormat df = SafeDateFormat.get();
ThreadLocal 的工作原理
ThreadLocal 的目标是让不同的线程有不同的变量 V,那最直接的方法就是创建一个 Map,它的 Key 是线程,Value 是每个线程拥有的变量 V,ThreadLocal 内部持有这样的一个 Map 就可以了。
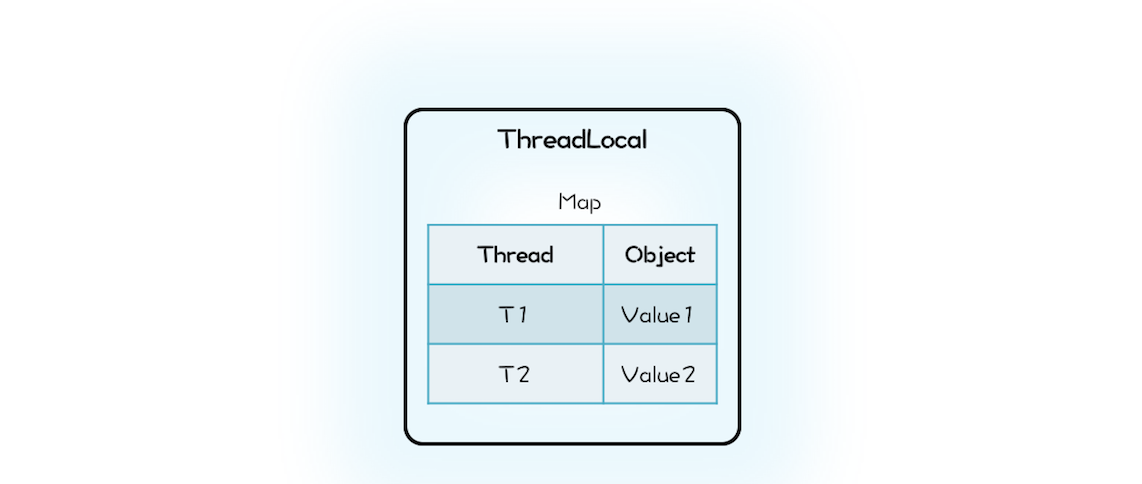
class MyThreadLocal<T> {
Map<Thread, T> locals =
new ConcurrentHashMap<>();
//获取线程变量
T get() {
return locals.get(
Thread.currentThread());
}
//设置线程变量
void set(T t) {
locals.put(
Thread.currentThread(), t);
}
}
Java 的实现里面也有一个 Map,叫做 ThreadLocalMap,不过持有 ThreadLocalMap 的不是 ThreadLocal,而是 Thread。Thread 这个类内部有一个私有属性 threadLocals,其类型就是 ThreadLocalMap,ThreadLocalMap 的 Key 是 ThreadLocal。
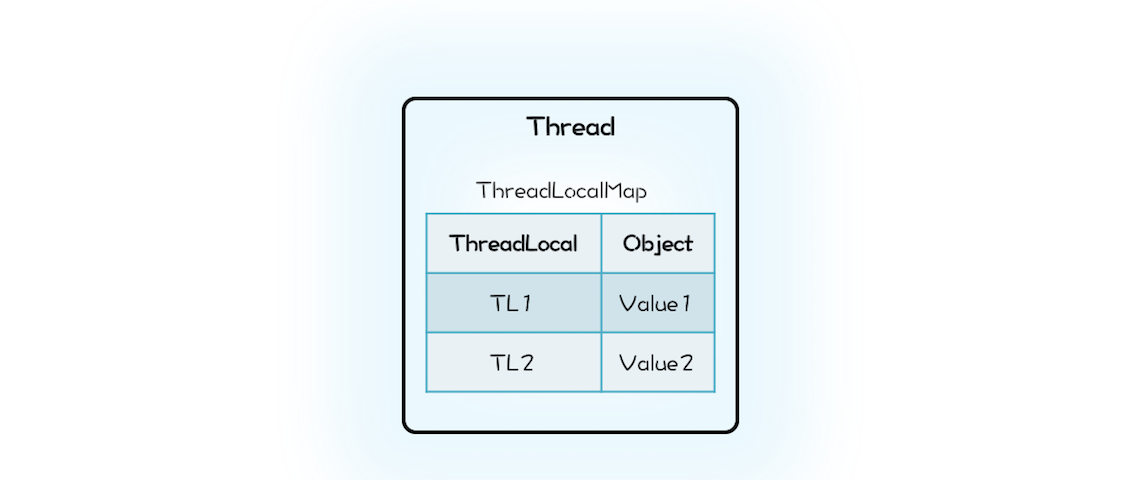
Thread 持有 ThreadLocalMap 的示意图
class Thread {
//内部持有 ThreadLocalMap
ThreadLocal.ThreadLocalMap
threadLocals;
}
class ThreadLocal<T>{
public T get() {
//首先获取线程持有的
//ThreadLocalMap
ThreadLocalMap map =
Thread.currentThread()
.threadLocals;
//在 ThreadLocalMap 中
//查找变量
Entry e =
map.getEntry(this);
return e.value;
}
static class ThreadLocalMap{
//内部是数组而不是 Map
Entry[] table;
//根据 ThreadLocal 查找 Entry
Entry getEntry(ThreadLocal key){
//省略查找逻辑
}
//Entry 定义
static class Entry extends
WeakReference<ThreadLocal>{
Object value;
}
}
}
在 Java 的实现方案里面,ThreadLocal 仅仅是一个代理工具类,内部并不持有任何与线程相关的数据,所有和线程相关的数据都存储在 Thread 里面,这样的设计容易理解。
当然还有一个更加深层次的原因,那就是不容易产生内存泄露。在我们的设计方案中,ThreadLocal 持有的 Map 会持有 Thread 对象的引用,这就意味着,只要 ThreadLocal 对象存在,那么 Map 中的 Thread 对象就永远不会被回收。ThreadLocal 的生命周期往往都比线程要长,所以这种设计方案很容易导致内存泄露。而 Java 的实现中 Thread 持有 ThreadLocalMap,而且 ThreadLocalMap 里对 ThreadLocal 的引用还是弱引用(WeakReference),所以只要 Thread 对象可以被回收,那么 ThreadLocalMap 就能被回收。Java 的这种实现方案虽然看上去复杂一些,但是更加安全。
ThreadLocal 与内存泄露
在线程池中使用 ThreadLocal 为什么可能导致内存泄露呢?原因就出在线程池中线程的存活时间太长,往往都是和程序同生共死的,这就意味着 Thread 持有的 ThreadLocalMap 一直都不会被回收,再加上 ThreadLocalMap 中的 Entry 对 ThreadLocal 是弱引用(WeakReference),所以只要 ThreadLocal 结束了自己的生命周期是可以被回收掉的。但是 Entry 中的 Value 却是被 Entry 强引用的,所以即便 Value 的生命周期结束了,Value 也是无法被回收的,从而导致内存泄露。
那在线程池中,我们该如何正确使用 ThreadLocal 呢?其实很简单,既然 JVM 不能做到自动释放对 Value 的强引用,那我们手动释放就可以了。如何能做到手动释放呢?估计你马上想到** try{}finally{}方案了,这个简直就是手动释放资源的利器**。
ExecutorService es;
ThreadLocal tl;
es.execute(()->{
//ThreadLocal 增加变量
tl.set(obj);
try {
// 省略业务逻辑代码
}finally {
//手动清理 ThreadLocal
tl.remove();
}
});
InheritableThreadLocal 与继承性
通过 ThreadLocal 创建的线程变量,其子线程是无法继承的。也就是说你在线程中通过 ThreadLocal 创建了线程变量 V,而后该线程创建了子线程,你在子线程中是无法通过 ThreadLocal 来访问父线程的线程变量 V 的。
如果你需要子线程继承父线程的线程变量,那该怎么办呢?其实很简单,Java 提供了 InheritableThreadLocal 来支持这种特性,InheritableThreadLocal 是 ThreadLocal 子类,所以用法和 ThreadLocal 相同。
不过,完全不建议你在线程池中使用 InheritableThreadLocal,不仅仅是因为它具有 ThreadLocal 相同的缺点——可能导致内存泄露,更重要的原因是:线程池中线程的创建是动态的,很容易导致继承关系错乱,如果你的业务逻辑依赖 InheritableThreadLocal,那么很可能导致业务逻辑计算错误,而这个错误往往比内存泄露更要命。
Guarded Suspension 模式:等待唤醒机制的规范实现
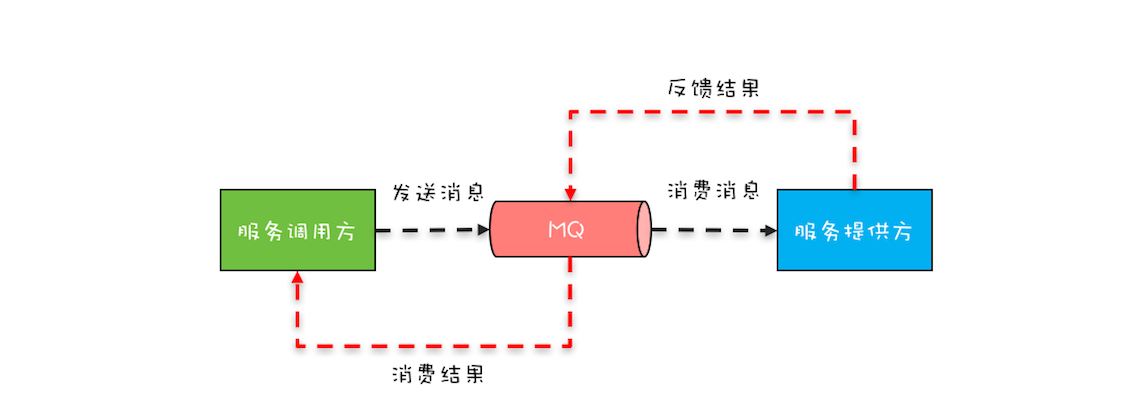
消息队列在互联网大厂中用的非常多,主要用作流量削峰和系统解耦。在这种接入方式中,发送消息和消费结果这两个操作之间是异步的。
class Message{
String id;
String content;
}
//该方法可以发送消息
void send(Message msg){
//省略相关代码
}
//MQ 消息返回后会调用该方法
//该方法的执行线程不同于
//发送消息的线程
void onMessage(Message msg){
//省略相关代码
}
//处理浏览器发来的请求
Respond handleWebReq(){
//创建一消息
Message msg1 = new
Message("1","{...}");
//发送消息
send(msg1);
//如何等待 MQ 返回的消息呢?
String result = ...;
}
Guarded Suspension 模式
Guarded Suspension 模式就是“保护性地暂停”。
一个对象 GuardedObject,内部有一个成员变量——受保护的对象,以及两个成员方法——get(Predicate<T> p)和onChanged(T obj)方法。
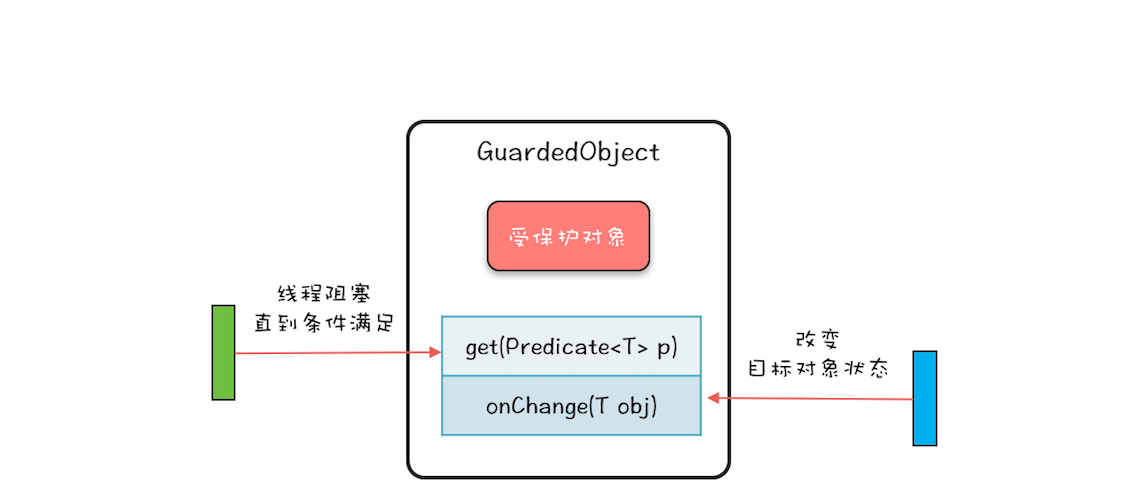
GuardedObject 的内部实现非常简单,是管程的一个经典用法,核心是:get() 方法通过条件变量的 await() 方法实现等待,onChanged() 方法通过条件变量的 signalAll() 方法实现唤醒功能。逻辑还是很简单的,所以这里就不再详细介绍了。
class GuardedObject<T>{
//受保护的对象
T obj;
final Lock lock =
new ReentrantLock();
final Condition done =
lock.newCondition();
final int timeout=1;
//获取受保护对象
T get(Predicate<T> p) {
lock.lock();
try {
//MESA 管程推荐写法
while(!p.test(obj)){
done.await(timeout,
TimeUnit.SECONDS);
}
}catch(InterruptedException e){
throw new RuntimeException(e);
}finally{
lock.unlock();
}
//返回非空的受保护对象
return obj;
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
}
扩展 Guarded Suspension 模式
Guarded Suspension 模式里 GuardedObject 有两个核心方法,一个是 get() 方法,一个是 onChanged() 方法。很显然,在处理 Web 请求的方法 handleWebReq() 中,可以调用 GuardedObject 的 get() 方法来实现等待;在 MQ 消息的消费方法 onMessage() 中,可以调用 GuardedObject 的 onChanged() 方法来实现唤醒。
//处理浏览器发来的请求
Respond handleWebReq(){
//创建一消息
Message msg1 = new
Message("1","{...}");
//发送消息
send(msg1);
//利用 GuardedObject 实现等待
GuardedObject<Message> go
=new GuardObjec<>();
Message r = go.get(
t->t != null);
}
void onMessage(Message msg){
//如何找到匹配的 go?
GuardedObject<Message> go=???
go.onChanged(msg);
}
handleWebReq() 里面创建了 GuardedObject 对象的实例 go,并调用其 get() 方等待结果,那在 onMessage() 方法中,如何才能够找到匹配的 GuardedObject 对象呢?
可以扩展一下 Guarded Suspension 模式,从而使它能够很方便地解决小灰同学的问题。在小灰的程序中,每个发送到 MQ 的消息,都有一个唯一性的属性 id,所以我们可以维护一个 MQ 消息 id 和 GuardedObject 对象实例的关系。
class GuardedObject<T>{
//受保护的对象
T obj;
final Lock lock =
new ReentrantLock();
final Condition done =
lock.newCondition();
final int timeout=2;
//保存所有 GuardedObject
final static Map<Object, GuardedObject>
gos=new ConcurrentHashMap<>();
//静态方法创建 GuardedObject
static <K> GuardedObject
create(K key){
GuardedObject go=new GuardedObject();
gos.put(key, go);
return go;
}
static <K, T> void
fireEvent(K key, T obj){
GuardedObject go=gos.remove(key);
if (go != null){
go.onChanged(obj);
}
}
//获取受保护对象
T get(Predicate<T> p) {
lock.lock();
try {
//MESA 管程推荐写法
while(!p.test(obj)){
done.await(timeout,
TimeUnit.SECONDS);
}
}catch(InterruptedException e){
throw new RuntimeException(e);
}finally{
lock.unlock();
}
//返回非空的受保护对象
return obj;
}
//事件通知方法
void onChanged(T obj) {
lock.lock();
try {
this.obj = obj;
done.signalAll();
} finally {
lock.unlock();
}
}
}
客户端代码
//处理浏览器发来的请求
Respond handleWebReq(){
int id=序号生成器。get();
//创建一消息
Message msg1 = new
Message(id,"{...}");
//创建 GuardedObject 实例
GuardedObject<Message> go=
GuardedObject.create(id);
//发送消息
send(msg1);
//等待 MQ 消息
Message r = go.get(
t->t != null);
}
void onMessage(Message msg){
//唤醒等待的线程
GuardedObject.fireEvent(
msg.id, msg);
}
总结
Guarded Suspension 模式本质上是一种等待唤醒机制的实现,只不过 Guarded Suspension 模式将其规范化了。规范化的好处是你无需重头思考如何实现,也无需担心实现程序的可理解性问题,同时也能避免一不小心写出个 Bug 来。但 Guarded Suspension 模式在解决实际问题的时候,往往还是需要扩展的,扩展的方式有很多,本篇文章就直接对 GuardedObject 的功能进行了增强,Dubbo 中 DefaultFuture 这个类也是采用的这种方式,你可以对比着来看,相信对 DefaultFuture 的实现原理会理解得更透彻。当然,你也可以创建新的类来实现对 Guarded Suspension 模式的扩展。
Guarded Suspension 模式也常被称作 Guarded Wait 模式、Spin Lock 模式(因为使用了 while 循环去等待),这些名字都很形象,不过它还有一个更形象的非官方名字:多线程版本的 if。单线程场景中,if 语句是不需要等待的,因为在只有一个线程的条件下,如果这个线程被阻塞,那就没有其他活动线程了,这意味着 if 判断条件的结果也不会发生变化了。但是多线程场景中,等待就变得有意义了,这种场景下,if 判断条件的结果是可能发生变化的。所以,用“多线程版本的 if”来理解这个模式会更简单。
Balking 模式:再谈线程安全的单例模式
需要快速放弃的一个最常见的例子是各种编辑器提供的自动保存功能。自动保存功能的实现逻辑一般都是隔一定时间自动执行存盘操作,存盘操作的前提是文件做过修改,如果文件没有执行过修改操作,就需要快速放弃存盘操作。下面的示例代码将自动保存功能代码化了,很显然 AutoSaveEditor 这个类不是线程安全的,因为对共享变量 changed 的读写没有使用同步,那如何保证 AutoSaveEditor 的线程安全性呢?
class AutoSaveEditor {
//文件是否被修改过
boolean changed = false;
//定时任务线程池
ScheduledExecutorService ses = Executors.newSingleThreadScheduledExecutor();
//定时执行自动保存
void startAutoSave() {
ses.scheduleWithFixedDelay(() -> { autoSave(); }, 5, 5, TimeUnit.SECONDS);
}
//自动存盘操作
void autoSave() {
if (!changed) {
return;
}
changed = false;
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit() {
//省略编辑逻辑
changed = true;
}
}
解决这个问题相信你一定手到擒来了:读写共享变量 changed 的方法 autoSave() 和 edit() 都加互斥锁就可以了。这样做虽然简单,但是性能很差,原因是锁的范围太大了。那我们可以将锁的范围缩小,只在读写共享变量 changed 的地方加锁,实现代码如下所示。
//自动存盘操作
void autoSave() {
synchronized (this) {
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit() {
//省略编辑逻辑
synchronized (this) {
changed = true;
}
}
Balking 模式的经典实现
Balking 模式本质上是一种规范化地解决“多线程版本的 if”的方案,对于上面自动保存的例子,使用 Balking 模式规范化之后的写法如下所示,你会发现仅仅是将 edit() 方法中对共享变量 changed 的赋值操作抽取到了 change() 中,这样的好处是将并发处理逻辑和业务逻辑分开。
boolean changed=false;
//自动存盘操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
//执行存盘操作
//省略且实现
this.execSave();
}
//编辑操作
void edit(){
//省略编辑逻辑
......
change();
}
//改变状态
void change(){
synchronized(this){
changed = true;
}
}
用 volatile 实现 Balking 模式
前面我们用 synchronized 实现了 Balking 模式,这种实现方式最为稳妥,建议你实际工作中也使用这个方案。不过在某些特定场景下,也可以使用 volatile 来实现,但使用 volatile 的前提是对原子性没有要求。
在 RPC 框架中,本地路由表是要和注册中心进行信息同步的,应用启动的时候,会将应用依赖服务的路由表从注册中心同步到本地路由表中,如果应用重启的时候注册中心宕机,那么会导致该应用依赖的服务均不可用,因为找不到依赖服务的路由表。为了防止这种极端情况出现,RPC 框架可以将本地路由表自动保存到本地文件中,如果重启的时候注册中心宕机,那么就从本地文件中恢复重启前的路由表。这其实也是一种降级的方案。
自动保存路由表和前面介绍的编辑器自动保存原理是一样的,也可以用 Balking 模式实现,不过我们这里采用 volatile 来实现,实现的代码如下所示。之所以可以采用 volatile 来实现,是因为对共享变量 changed 和 rt 的写操作不存在原子性的要求,而且采用 scheduleWithFixedDelay() 这种调度方式能保证同一时刻只有一个线程执行 autoSave() 方法。
//路由表信息
public class RouterTable {
//Key: 接口名
//Value: 路由集合
ConcurrentHashMap<String, CopyOnWriteArraySet<Router>>
rt = new ConcurrentHashMap<>();
//路由表是否发生变化
volatile boolean changed;
//将路由表写入本地文件的线程池
ScheduledExecutorService ses=
Executors.newSingleThreadScheduledExecutor();
//启动定时任务
//将变更后的路由表写入本地文件
public void startLocalSaver(){
ses.scheduleWithFixedDelay(()->{
autoSave();
}, 1, 1, MINUTES);
}
//保存路由表到本地文件
void autoSave() {
if (!changed) {
return;
}
changed = false;
//将路由表写入本地文件
//省略其方法实现
this.save2Local();
}
//删除路由
public void remove(Router router) {
Set<Router> set=rt.get(router.iface);
if (set != null) {
set.remove(router);
//路由表已发生变化
changed = true;
}
}
//增加路由
public void add(Router router) {
Set<Router> set = rt.computeIfAbsent(
route.iface, r ->
new CopyOnWriteArraySet<>());
set.add(router);
//路由表已发生变化
changed = true;
}
}
Balking 模式有一个非常典型的应用场景就是单次初始化,下面的示例代码是它的实现。这个实现方案中,我们将 init() 声明为一个同步方法,这样同一个时刻就只有一个线程能够执行 init() 方法;init() 方法在第一次执行完时会将 inited 设置为 true,这样后续执行 init() 方法的线程就不会再执行 doInit() 了。
class InitTest{
boolean inited = false;
synchronized void init(){
if(inited){
return;
}
//省略 doInit 的实现
doInit();
inited=true;
}
}
线程安全的单例模式本质上其实也是单次初始化,所以可以用 Balking 模式来实现线程安全的单例模式,下面的示例代码是其实现。这个实现虽然功能上没有问题,但是性能却很差,因为互斥锁 synchronized 将 getInstance() 方法串行化了,那有没有办法可以优化一下它的性能呢?
class Singleton{
private static
Singleton singleton;
//构造方法私有化
private Singleton(){}
//获取实例(单例)
public synchronized static
Singleton getInstance(){
if(singleton == null){
singleton=new Singleton();
}
return singleton;
}
}
办法当然是有的,那就是经典的双重检查(Double Check)方案,下面的示例代码是其详细实现。在双重检查方案中,一旦 Singleton 对象被成功创建之后,就不会执行 synchronized(Singleton.class){}相关的代码,也就是说,此时 getInstance() 方法的执行路径是无锁的,从而解决了性能问题。不过需要你注意的是,这个方案中使用了 volatile 来禁止编译优化。至于获取锁后的二次检查,则是出于对安全性负责。
class Singleton{
private static volatile
Singleton singleton;
//构造方法私有化
private Singleton() {}
//获取实例(单例)
public static Singleton
getInstance() {
//第一次检查
if(singleton==null){
synchronize(Singleton.class){
//获取锁后二次检查
if(singleton==null){
singleton=new Singleton();
}
}
}
return singleton;
}
}
总结
Balking 模式和 Guarded Suspension 模式从实现上看似乎没有多大的关系,Balking 模式只需要用互斥锁就能解决,而 Guarded Suspension 模式则要用到管程这种高级的并发原语;但是从应用的角度来看,它们解决的都是“线程安全的 if”语义,不同之处在于,Guarded Suspension 模式会等待 if 条件为真,而 Balking 模式不会等待。
Balking 模式的经典实现是使用互斥锁,你可以使用 Java 语言内置 synchronized,也可以使用 SDK 提供 Lock;如果你对互斥锁的性能不满意,可以尝试采用 volatile 方案,不过使用 volatile 方案需要你更加谨慎。
Thread-Per-Message 模式:最简单实用的分工方法
并发编程领域里,解决分工问题也有一系列的设计模式,比较常用的主要有 Thread-Per-Message 模式、Worker Thread 模式、生产者-消费者模式等等。
如何理解 Thread-Per-Message 模式
现实世界里,很多事情我们都需要委托他人办理,委托他人代办有一个非常大的好处,那就是可以专心做自己的事了。
在编程领域也有很多类似的需求,比如写一个 HTTP Server,创建一个子线程,委托子线程去处理 HTTP 请求。
这种委托他人办理的方式,在并发编程领域被总结为一种设计模式,叫做** Thread-Per-Message 模式**,简言之就是为每个任务分配一个独立的线程。
用 Thread 实现 Thread-Per-Message 模式
Thread-Per-Message 模式的一个最经典的应用场景是网络编程里服务端的实现,服务端为每个客户端请求创建一个独立的线程,当线程处理完请求后,自动销毁,这是一种最简单的并发处理网络请求的方法。
网络编程里最简单的程序当数 echo 程序了,echo 程序的服务端会原封不动地将客户端的请求发送回客户端。例如,客户端发送 TCP 请求”Hello World”,那么服务端也会返回”Hello World”。
final ServerSocketChannel ssc =
ServerSocketChannel.open().bind(new InetSocketAddress(8080));
//处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 每个请求都创建一个线程
new Thread(() -> {
try {
// 读 Socket
ByteBuffer rb = ByteBuffer.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
Thread.sleep(2000);
// 写 Socket
ByteBuffer wb = (ByteBuffer) rb.flip();
sc.write(wb);
// 关闭 Socket
sc.close();
} catch (Exception e) {
throw new UncheckedIOException(e);
}
}).start();
}
} finally {
ssc.close();
}
上面这个 echo 服务的实现方案是不具备可行性的。原因在于 Java 中的线程是一个重量级的对象,创建成本很高,一方面创建线程比较耗时,另一方面线程占用的内存也比较大。所以,为每个请求创建一个新的线程并不适合高并发场景。
Java 语言里,Java 线程是和操作系统线程一一对应的,这种做法本质上是将 Java 线程的调度权完全委托给操作系统,而操作系统在这方面非常成熟,所以这种做法的好处是稳定、可靠,但是也继承了操作系统线程的缺点:创建成本高。为了解决这个缺点,Java 并发包里提供了线程池等工具类。这个思路在很长一段时间里都是很稳妥的方案,但是这个方案并不是唯一的方案。
业界还有另外一种方案,叫做轻量级线程。这个方案在 Java 领域知名度并不高,但是在其他编程语言里却叫得很响,例如 Go 语言、Lua 语言里的协程,本质上就是一种轻量级的线程。轻量级的线程,创建的成本很低,基本上和创建一个普通对象的成本相似;并且创建的速度和内存占用相比操作系统线程至少有一个数量级的提升,所以基于轻量级线程实现 Thread-Per-Message 模式就完全没有问题了。
Java 语言目前也已经意识到轻量级线程的重要性了,OpenJDK 有个 Loom 项目,就是要解决 Java 语言的轻量级线程问题,在这个项目中,轻量级线程被叫做** Fiber**。
用 Fiber 实现 Thread-Per-Message 模式
Loom 项目在设计轻量级线程时,充分考量了当前 Java 线程的使用方式,采取的是尽量兼容的态度,所以使用上还是挺简单的。用 Fiber 实现 echo 服务的示例代码如下所示,对比 Thread 的实现,你会发现改动量非常小,只需要把 new Thread(()->{…}).start() 换成 Fiber.schedule(()->{}) 就可以了。
final ServerSocketChannel ssc =
ServerSocketChannel.open().bind(new InetSocketAddress(8080));
//处理请求
try {
while (true) {
// 接收请求
final SocketChannel sc = ssc.accept();
Fiber.schedule(() -> {
try {
// 读 Socket
ByteBuffer rb = ByteBuffer.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
LockSupport.parkNanos(2000 * 1000000);
// 写 Socket
ByteBuffer wb =
(ByteBuffer) rb.flip()
sc.write(wb);
// 关闭 Socket
sc.close();
} catch (Exception e) {
throw new UncheckedIOException(e);
}
});
}//while
} finally {
ssc.close();
}
通过压测,可以发现协程方式相比与线程方式,会大大减少线程数。
Worker Thread 模式:如何避免重复创建线程?
Worker Thread 模式及其实现
Worker Thread 模式可以类比现实世界里车间的工作模式:车间里的工人,有活儿了,大家一起干,没活儿了就聊聊天等着。
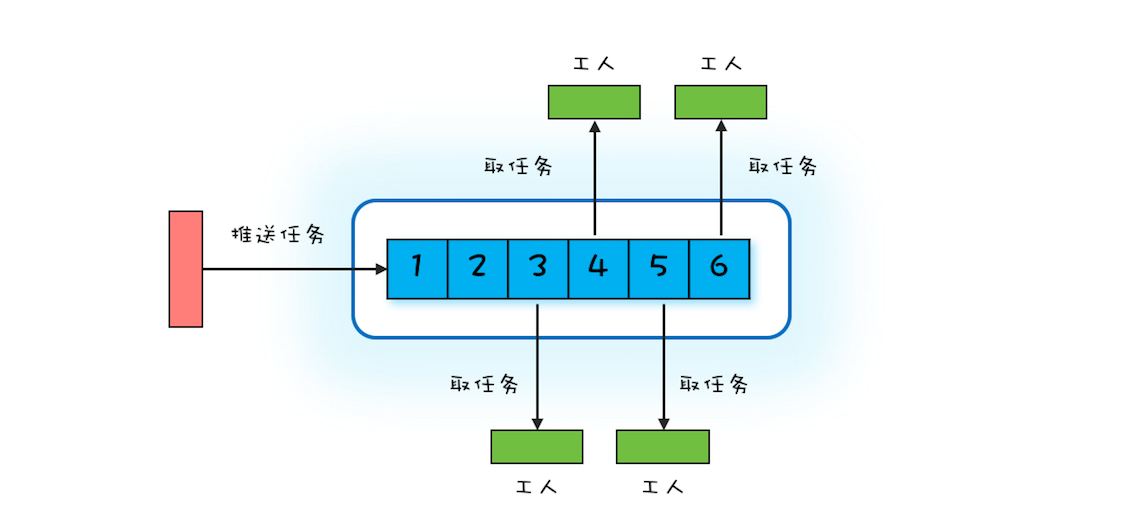
这个模式,在 Java 中的方案就是线程池。
下面的示例代码是用线程池实现的 echo 服务端。
ExecutorService es = Executors.newFixedThreadPool(500);
final ServerSocketChannel ssc =
ServerSocketChannel.open().bind(new InetSocketAddress(8080));
//处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 将请求处理任务提交给线程池
es.execute(() -> {
try {
// 读 Socket
ByteBuffer rb = ByteBuffer.allocateDirect(1024);
sc.read(rb);
//模拟处理请求
Thread.sleep(2000);
// 写 Socket
ByteBuffer wb = (ByteBuffer) rb.flip();
sc.write(wb);
// 关闭 Socket
sc.close();
} catch (Exception e) {
throw new UncheckedIOException(e);
}
});
}
} finally {
ssc.close();
es.shutdown();
}
正确地创建线程池
Java 的线程池既能够避免无限制地创建线程导致 OOM,也能避免无限制地接收任务导致 OOM。只不过后者经常容易被我们忽略,例如在上面的实现中,就被我们忽略了。所以强烈建议你用创建有界的队列来接收任务。
当请求量大于有界队列的容量时,就需要合理地拒绝请求。如何合理地拒绝呢?这需要你结合具体的业务场景来制定,即便线程池默认的拒绝策略能够满足你的需求,也同样建议你在创建线程池时,清晰地指明拒绝策略。
同时,为了便于调试和诊断问题,我也强烈建议你在实际工作中给线程赋予一个业务相关的名字。
综合以上,创建线程池的示例:
ExecutorService es = new ThreadPoolExecutor(50, 500, 60L, TimeUnit.SECONDS,
//注意要创建有界队列
new LinkedBlockingQueue<Runnable>(2000),
//建议根据业务需求实现 ThreadFactory
r -> {
return new Thread(r, "echo-" + r.hashCode());
},
//建议根据业务需求实现 RejectedExecutionHandler
new ThreadPoolExecutor.CallerRunsPolicy());
避免线程死锁
使用线程池过程中,还要注意一种线程死锁的场景。如果提交到相同线程池的任务不是相互独立的,而是有依赖关系的,那么就有可能导致线程死锁。具体现象是应用每运行一段时间偶尔就会处于无响应的状态,监控数据看上去一切都正常,但是实际上已经不能正常工作了。
这个出问题的应用,相关的逻辑精简之后,如下图所示,该应用将一个大型的计算任务分成两个阶段,第一个阶段的任务会等待第二阶段的子任务完成。在这个应用里,每一个阶段都使用了线程池,而且两个阶段使用的还是同一个线程池。
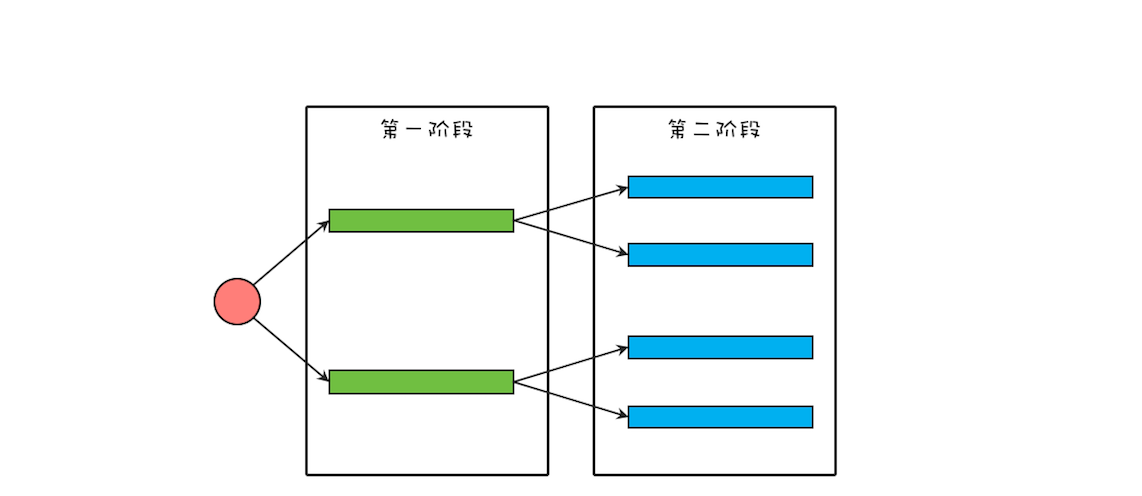
我们可以用下面的示例代码来模拟该应用,如果你执行下面的这段代码,会发现它永远执行不到最后一行。执行过程中没有任何异常,但是应用已经停止响应了。
//L1、L2 阶段共用的线程池
ExecutorService es = Executors.newFixedThreadPool(2);
//L1 阶段的闭锁
CountDownLatch l1 = new CountDownLatch(2);
for (int i = 0; i < 2; i++) {
System.out.println("L1");
//执行 L1 阶段任务
es.execute(() -> {
//L2 阶段的闭锁
CountDownLatch l2 = new CountDownLatch(2);
//执行 L2 阶段子任务
for (int j = 0; j < 2; j++) {
es.execute(() -> {
System.out.println("L2");
l2.countDown();
});
}
//等待 L2 阶段任务执行完
l2.await();
l1.countDown();
});
}
//等着 L1 阶段任务执行完
l1.await();
System.out.println("end");
当应用出现类似问题时,首选的诊断方法是查看线程栈。下图是上面示例代码停止响应后的线程栈,你会发现线程池中的两个线程全部都阻塞在 l2.await(); 这行代码上了,也就是说,线程池里所有的线程都在等待 L2 阶段的任务执行完,那 L2 阶段的子任务什么时候能够执行完呢?永远都没那一天了,为什么呢?因为线程池里的线程都阻塞了,没有空闲的线程执行 L2 阶段的任务了。
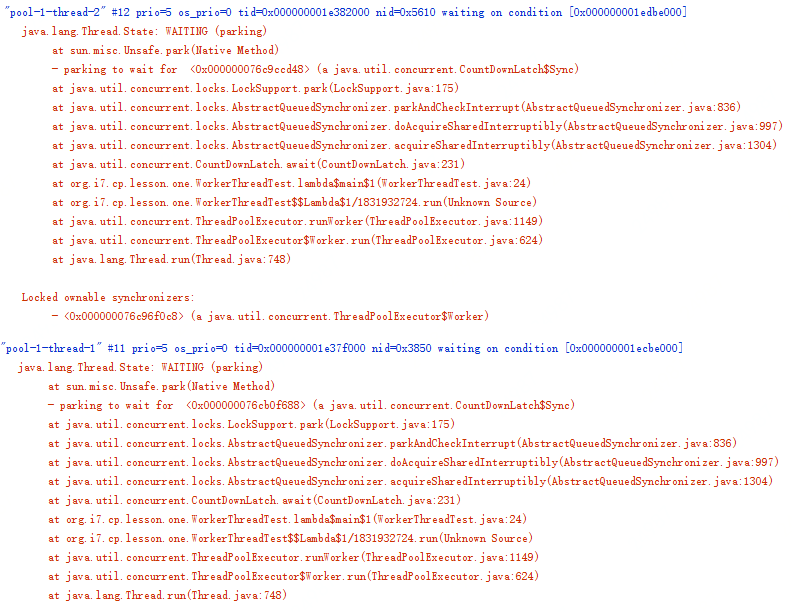
原因找到了,那如何解决就简单了,最简单粗暴的办法就是将线程池的最大线程数调大,如果能够确定任务的数量不是非常多的话,这个办法也是可行的,否则这个办法就行不通了。其实这种问题通用的解决方案是为不同的任务创建不同的线程池。对于上面的这个应用,L1 阶段的任务和 L2 阶段的任务如果各自都有自己的线程池,就不会出现这种问题了。
最后再次强调一下:提交到相同线程池中的任务一定是相互独立的,否则就一定要慎重。
两阶段终止模式:如何优雅地终止线程?
如何理解两阶段终止模式
两阶段终止模式,顾名思义,就是将终止过程分成两个阶段:第一个阶段主要是线程 T1 向线程 T2 发送终止指令,而第二阶段则是线程 T2 响应终止指令。
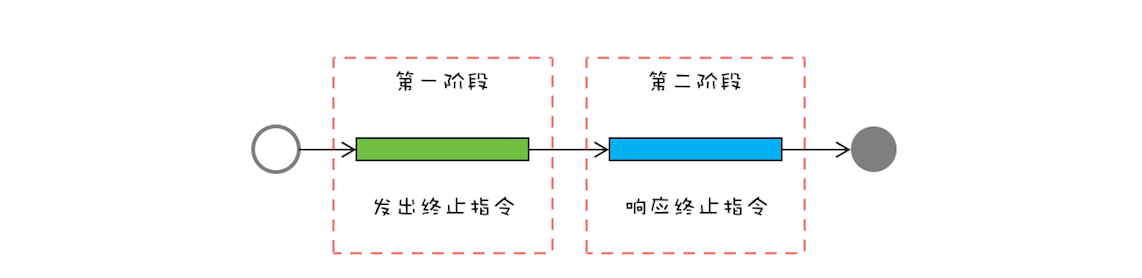
终止指令,其实包括两方面内容:interrupt() 方法和线程终止的标志位。
用两阶段终止模式终止监控操作
实际工作中,有些监控系统需要动态地采集一些数据,一般都是监控系统发送采集指令给被监控系统的监控代理,监控代理接收到指令之后,从监控目标收集数据,然后回传给监控系统,详细过程如下图所示。出于对性能的考虑(有些监控项对系统性能影响很大,所以不能一直持续监控),动态采集功能一般都会有终止操作。
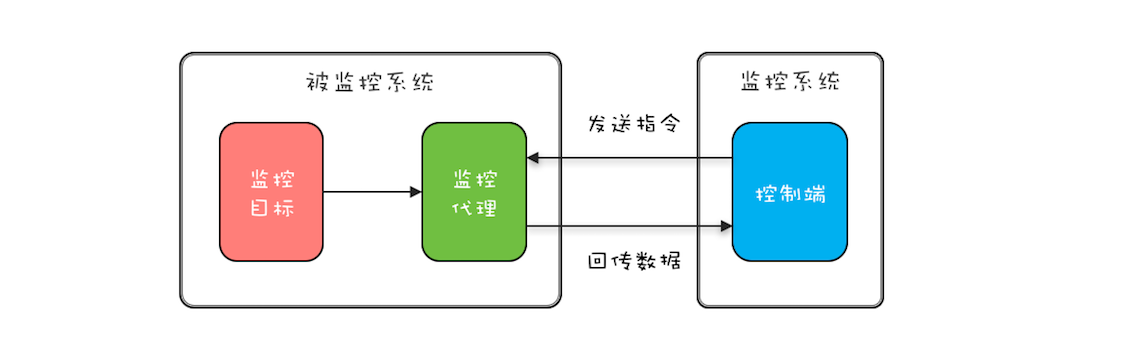
下面的示例代码是监控代理简化之后的实现,start() 方法会启动一个新的线程 rptThread 来执行监控数据采集和回传的功能,stop() 方法需要优雅地终止线程 rptThread,那 stop() 相关功能该如何实现呢?
class Proxy {
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
rptThread = new Thread(()->{
while (true) {
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
//如何实现?
}
}
按照两阶段终止模式,我们首先需要做的就是将线程 rptThread 状态转换到 RUNNABLE,做法很简单,只需要在调用 rptThread.interrupt() 就可以了。线程 rptThread 的状态转换到 RUNNABLE 之后,如何优雅地终止呢?下面的示例代码中,我们选择的标志位是线程的中断状态:Thread.currentThread().isInterrupted() ,需要注意的是,我们在捕获 Thread.sleep() 的中断异常之后,通过 Thread.currentThread().interrupt() 重新设置了线程的中断状态,因为 JVM 的异常处理会清除线程的中断状态。
class Proxy {
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
rptThread = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e){
//重新设置线程中断状态
Thread.currentThread().interrupt();
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
rptThread.interrupt();
}
}
上面的示例代码的确能够解决当前的问题,但是建议你在实际工作中谨慎使用。原因在于我们很可能在线程的 run() 方法中调用第三方类库提供的方法,而我们没有办法保证第三方类库正确处理了线程的中断异常,例如第三方类库在捕获到 Thread.sleep() 方法抛出的中断异常后,没有重新设置线程的中断状态,那么就会导致线程不能够正常终止。所以强烈建议你设置自己的线程终止标志位,例如在下面的代码中,使用 isTerminated 作为线程终止标志位,此时无论是否正确处理了线程的中断异常,都不会影响线程优雅地终止。
class Proxy {
//线程终止标志位
volatile boolean terminated = false;
boolean started = false;
//采集线程
Thread rptThread;
//启动采集功能
synchronized void start(){
//不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
terminated = false;
rptThread = new Thread(()->{
while (!terminated){
//省略采集、回传实现
report();
//每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e){
//重新设置线程中断状态
Thread.currentThread().interrupt();
}
}
//执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
//终止采集功能
synchronized void stop(){
//设置中断标志位
terminated = true;
//中断线程 rptThread
rptThread.interrupt();
}
}
如何优雅地终止线程池
Java 领域用的最多的还是线程池,而不是手动地创建线程。那我们该如何优雅地终止线程池呢?
线程池提供了两个方法:shutdown() 和 shutdownNow()。这两个方法有什么区别呢?要了解它们的区别,就先需要了解线程池的实现原理。
我们曾经讲过,Java 线程池是生产者-消费者模式的一种实现,提交给线程池的任务,首先是进入一个阻塞队列中,之后线程池中的线程从阻塞队列中取出任务执行。
shutdown() 方法是一种很保守的关闭线程池的方法。线程池执行 shutdown() 后,就会拒绝接收新的任务,但是会等待线程池中正在执行的任务和已经进入阻塞队列的任务都执行完之后才最终关闭线程池。
而 shutdownNow() 方法,相对就激进一些了,线程池执行 shutdownNow() 后,会拒绝接收新的任务,同时还会中断线程池中正在执行的任务,已经进入阻塞队列的任务也被剥夺了执行的机会,不过这些被剥夺执行机会的任务会作为 shutdownNow() 方法的返回值返回。因为 shutdownNow() 方法会中断正在执行的线程,所以提交到线程池的任务,如果需要优雅地结束,就需要正确地处理线程中断。
如果提交到线程池的任务不允许取消,那就不能使用 shutdownNow() 方法终止线程池。不过,如果提交到线程池的任务允许后续以补偿的方式重新执行,也是可以使用 shutdownNow() 方法终止线程池的。《极客时间教程 - Java 并发编程实战》 这本书第 7 章《取消与关闭》的“shutdownNow 的局限性”一节中,提到一种将已提交但尚未开始执行的任务以及已经取消的正在执行的任务保存起来,以便后续重新执行的方案。
其实分析完 shutdown() 和 shutdownNow() 方法你会发现,它们实质上使用的也是两阶段终止模式,只是终止指令的范围不同而已,前者只影响阻塞队列接收任务,后者范围扩大到线程池中所有的任务。
生产者-消费者模式:用流水线思想提高效率
生产者-消费者模式的优点
生产者-消费者模式的核心是一个任务队列,生产者线程生产任务,并将任务添加到任务队列中,而消费者线程从任务队列中获取任务并执行。
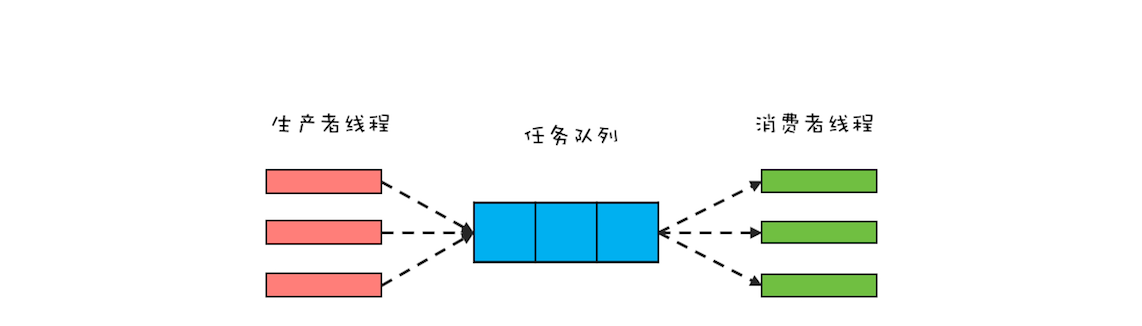
生产者和消费者没有任何依赖关系,它们彼此之间的通信只能通过任务队列,所以生产者-消费者模式是一个不错的解耦方案。
生产者-消费者模式支持异步,并且能够平衡生产者和消费者的速度差异。
支持批量执行以提升性能
监控系统动态采集的案例,其实最终回传的监控数据还是要存入数据库的(如下图)。但被监控系统往往有很多,如果每一条回传数据都直接 INSERT 到数据库,那么这个方案就是上面提到的第一种方案:每个线程 INSERT 一条数据。很显然,更好的方案是批量执行 SQL,那如何实现呢?这就要用到生产者-消费者模式了。
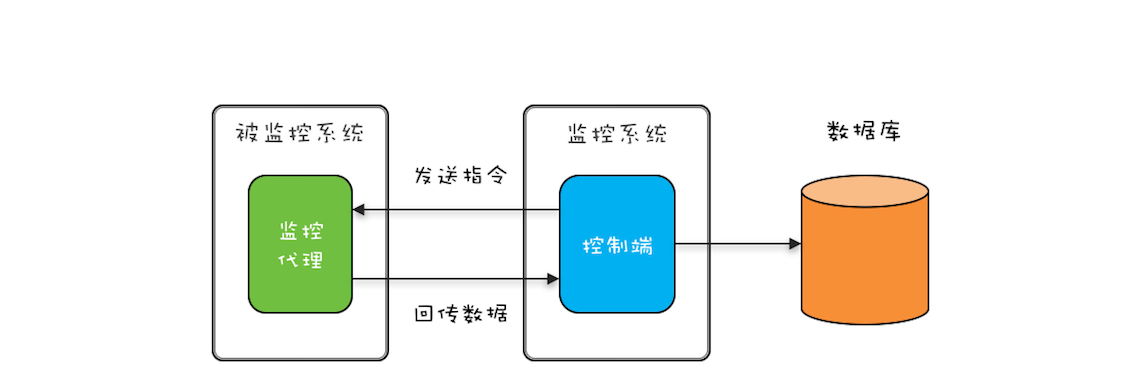
利用生产者-消费者模式实现批量执行 SQL 非常简单:将原来直接 INSERT 数据到数据库的线程作为生产者线程,生产者线程只需将数据添加到任务队列,然后消费者线程负责将任务从任务队列中批量取出并批量执行。
在下面的示例代码中,我们创建了 5 个消费者线程负责批量执行 SQL,这 5 个消费者线程以 while(true){} 循环方式批量地获取任务并批量地执行。需要注意的是,从任务队列中获取批量任务的方法 pollTasks() 中,首先是以阻塞方式获取任务队列中的一条任务,而后则是以非阻塞的方式获取任务;之所以首先采用阻塞方式,是因为如果任务队列中没有任务,这样的方式能够避免无谓的循环。
//任务队列
BlockingQueue<Task> bq=new
LinkedBlockingQueue<>(2000);
//启动 5 个消费者线程
//执行批量任务
void start() {
ExecutorService es=executors
.newFixedThreadPool(5);
for (int i=0; i<5; i++) {
es.execute(()->{
try {
while (true) {
//获取批量任务
List<Task> ts=pollTasks();
//执行批量任务
execTasks(ts);
}
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
//从任务队列中获取批量任务
List<Task> pollTasks()
throws InterruptedException{
List<Task> ts=new LinkedList<>();
//阻塞式获取一条任务
Task t = bq.take();
while (t != null) {
ts.add(t);
//非阻塞式获取一条任务
t = bq.poll();
}
return ts;
}
//批量执行任务
execTasks(List<Task> ts) {
//省略具体代码无数
}
支持分阶段提交以提升性能
利用生产者-消费者模式还可以轻松地支持一种分阶段提交的应用场景。我们知道写文件如果同步刷盘性能会很慢,所以对于不是很重要的数据,我们往往采用异步刷盘的方式。
这个日志组件的异步刷盘操作本质上其实就是一种分阶段提交。下面我们具体看看用生产者-消费者模式如何实现。在下面的示例代码中,可以通过调用 info()和error() 方法写入日志,这两个方法都是创建了一个日志任务 LogMsg,并添加到阻塞队列中,调用 info()和error() 方法的线程是生产者;而真正将日志写入文件的是消费者线程,在 Logger 这个类中,我们只创建了 1 个消费者线程,在这个消费者线程中,会根据刷盘规则执行刷盘操作,逻辑很简单,这里就不赘述了。
class Logger {
//任务队列
final BlockingQueue<LogMsg> bq = new BlockingQueue<>();
//flush 批量
static final int batchSize = 500;
//只需要一个线程写日志
ExecutorService es = Executors.newFixedThreadPool(1);
//启动写日志线程
void start() {
File file = File.createTempFile("foo", ".log");
final FileWriter writer = new FileWriter(file);
this.es.execute(() -> {
try {
//未刷盘日志数量
int curIdx = 0;
long preFT = System.currentTimeMillis();
while (true) {
LogMsg log = bq.poll(5, TimeUnit.SECONDS);
//写日志
if (log != null) {
writer.write(log.toString());
++curIdx;
}
//如果不存在未刷盘数据,则无需刷盘
if (curIdx <= 0) {
continue;
}
//根据规则刷盘
if (log != null && log.level == LEVEL.ERROR
|| curIdx == batchSize
|| System.currentTimeMillis() - preFT > 5000) {
writer.flush();
curIdx = 0;
preFT = System.currentTimeMillis();
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//写 INFO 级别日志
void info(String msg) {
bq.put(new LogMsg(
LEVEL.INFO, msg));
}
//写 ERROR 级别日志
void error(String msg) {
bq.put(new LogMsg(
LEVEL.ERROR, msg));
}
}
//日志级别
enum LEVEL {
INFO,
ERROR
}
class LogMsg {
LEVEL level;
String msg;
//省略构造函数实现
LogMsg(LEVEL lvl, String msg) { }
//省略 toString() 实现
String toString() { }
}
设计模式模块热点问题答疑
略