Java 并发之分工工具
Java 并发之分工工具
对于简单的并行任务,你可以通过“线程池 + Future”的方案来解决;如果任务之间有聚合关系,无论是 AND 聚合还是 OR 聚合,都可以通过 CompletableFuture 来解决;而批量的并行任务,则可以通过 CompletionService 来解决。
FutureTask
FutureTask 有两个构造函数:
FutureTask(Callable<V> callable);
FutureTask(Runnable runnable, V result);
FutureTask 实现了 Runnable 和 Future 接口。由于实现了 Runnable 接口,所以可以将 FutureTask 对象作为任务提交给 ThreadPoolExecutor 去执行,也可以直接被 Thread 执行;又因为实现了 Future 接口,所以也能用来获得任务的执行结果。
下面,通过一组示例来展示 FutureTask 如何分别交给线程池、线程执行。
【示例】FutureTask 交给线程池执行
public class FutureTaskDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建 FutureTask
Task task = new Task();
FutureTask<String> f1 = new FutureTask<>(task);
FutureTask<String> f2 = new FutureTask<>(task);
// 创建线程池
ExecutorService executor = Executors.newCachedThreadPool();
executor.submit(f1);
executor.submit(f2);
System.out.println(f1.get());
System.out.println(f2.get());
executor.shutdown();
}
static class Task implements Callable<String> {
@Override
public String call() {
return Thread.currentThread().getName() + " 执行成功!";
}
}
}
// 输出
// pool-1-thread-1 执行成功!
// pool-1-thread-2 执行成功!
【示例】FutureTask 交给线程执行
public class FutureTaskDemo2 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建 FutureTask
Task task = new Task();
FutureTask<String> f1 = new FutureTask<>(task);
FutureTask<String> f2 = new FutureTask<>(task);
// 创建线程
new Thread(f1).start();
new Thread(f2).start();
System.out.println(f1.get());
System.out.println(f2.get());
}
static class Task implements Callable<String> {
@Override
public String call() {
return Thread.currentThread().getName() + " 执行成功!";
}
}
}
// 输出
// Thread-0 执行成功!
// Thread-1 执行成功!
【示例】用 FutureTask 完成并行计算
public class FutureTaskDemo3 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建一个线程池来执行任务
ExecutorService executor = Executors.newFixedThreadPool(2);
// 创建两个 Callable 对象
Callable<Integer> t1 = () -> {
int result = 0;
for (int i = 1; i <= 100; i++) {
result += i;
}
return result;
};
Callable<Integer> t2 = () -> {
int result = 0;
for (int i = 101; i <= 200; i++) {
result += i;
}
return result;
};
// 创建两个 FutureTask 对象
FutureTask<Integer> f1 = new FutureTask<>(t1);
FutureTask<Integer> f2 = new FutureTask<>(t2);
// 提交任务到线程池执行
executor.execute(f1);
executor.execute(f2);
// 获取任务的结果
Integer value1 = f1.get();
Integer value2 = f2.get();
System.out.println("total = " + value1 + value2);
// 关闭线程池
executor.shutdown();
}
}
CompletableFuture
JDK8 提供了 CompletableFuture 来支持异步编程。
CompletableFuture 提供了四个静态方法来创建一个异步操作。
// 使用默认线程池
public static CompletableFuture<Void> runAsync(Runnable runnable) { // 省略 }
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) { // 省略 }
// 使用自定义线程池
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) { // 省略 }
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor) { // 省略 }
上面的 4 个静态方法中,有 2 个 runAsync 方法,2 个 supplyAsync 方法,它们的区别是:
runAsync方法没有返回值。supplyAsync方法有返回值。
默认情况下 CompletableFuture 会使用公共的 ForkJoinPool 线程池,这个线程池默认创建的线程数是 CPU 的核数(也可以通过 JVM option: -Djava.util.concurrent.ForkJoinPool.common.parallelism 来设置 ForkJoinPool 线程池的线程数)。如果所有 CompletableFuture 共享一个线程池,那么一旦有任务执行一些很慢的 I/O 操作,就会导致线程池中所有线程都阻塞在 I/O 操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰。
CompletionStage
CompletionStage 接口可以清晰地描述任务之间的时序关系,如串行关系、并行关系、汇聚关系等。
串行关系
CompletionStage 接口里面描述串行关系,主要是 thenApply、thenAccept、thenRun 和 thenCompose 这四个系列的接口。
thenApply 系列函数里参数 fn 的类型是接口 Function<T, R>,这个接口里与 CompletionStage 相关的方法是 R apply(T t),这个方法既能接收参数也支持返回值,所以 thenApply 系列方法返回的是CompletionStage<R>。
thenAccept 系列方法里参数 consumer 的类型是接口 Consumer<T>,这个接口里与 CompletionStage 相关的方法是 void accept(T t),这个方法虽然支持参数,但却不支持回值,所以 thenAccept 系列方法返回的是CompletionStage<Void>。
thenRun 系列方法里 action 的参数是 Runnable,所以 action 既不能接收参数也不支持返回值,所以 thenRun 系列方法返回的也是 CompletionStage<Void>。
这些方法里面 Async 代表的是异步执行 fn、consumer 或者 action。其中,需要你注意的是 thenCompose 系列方法,这个系列的方法会新创建出一个子流程,最终结果和 thenApply 系列是相同的。
CompletionStage<R> thenApply(fn);
CompletionStage<R> thenApplyAsync(fn);
CompletionStage<Void> thenAccept(consumer);
CompletionStage<Void> thenAcceptAsync(consumer);
CompletionStage<Void> thenRun(action);
CompletionStage<Void> thenRunAsync(action);
CompletionStage<R> thenCompose(fn);
CompletionStage<R> thenComposeAsync(fn);
描述 AND 汇聚关系
CompletionStage 接口里面描述 AND 汇聚关系,主要是 thenCombine、thenAcceptBoth 和 runAfterBoth 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同。
CompletionStage<R> thenCombine(other, fn);
CompletionStage<R> thenCombineAsync(other, fn);
CompletionStage<Void> thenAcceptBoth(other, consumer);
CompletionStage<Void> thenAcceptBothAsync(other, consumer);
CompletionStage<Void> runAfterBoth(other, action);
CompletionStage<Void> runAfterBothAsync(other, action);
描述 OR 汇聚关系
CompletionStage 接口里面描述 OR 汇聚关系,主要是 applyToEither、acceptEither 和 runAfterEither 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同。
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
下面的示例代码展示了如何使用 applyToEither() 方法来描述一个 OR 汇聚关系。
CompletableFuture<String> f1 = CompletableFuture.supplyAsync(() -> {
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f2 = CompletableFuture.supplyAsync(() -> {
int t = getRandom(5, 10);
sleep(t, TimeUnit.SECONDS);
return String.valueOf(t);
});
CompletableFuture<String> f3 = f1.applyToEither(f2, s -> s);
System.out.println(f3.join());
异常处理
虽然上面我们提到的 fn、consumer、action 它们的核心方法都不允许抛出可检查异常,但是却无法限制它们抛出运行时异常,例如下面的代码,执行 7/0 就会出现除零错误这个运行时异常。非异步编程里面,我们可以使用 try {} catch {} 来捕获并处理异常,那在异步编程里面,异常该如何处理呢?
CompletableFuture<Integer> f = CompletableFuture.supplyAsync(() -> (7 / 0))
.thenApply(r -> r * 10);
System.out.println(f.join());
CompletionStage 接口给我们提供的方案非常简单,比 try {} catch {} 还要简单,下面是相关的方法,使用这些方法进行异常处理和串行操作是一样的,都支持链式编程方式。
CompletionStage exceptionally(fn);
CompletionStage<R> whenComplete(consumer);
CompletionStage<R> whenCompleteAsync(consumer);
CompletionStage<R> handle(fn);
CompletionStage<R> handleAsync(fn);
下面的示例代码展示了如何使用 exceptionally() 方法来处理异常,exceptionally() 的使用非常类似于 try {} catch {} 中的 catch {},但是由于支持链式编程方式,所以相对更简单。既然有 try {} catch {},那就一定还有 try {} catch {},whenComplete() 和 handle() 系列方法就类似于 try {} catch {} 中的 finally {},无论是否发生异常都会执行 whenComplete() 中的回调函数 consumer 和 handle() 中的回调函数 fn。whenComplete() 和 handle() 的区别在于 whenComplete() 不支持返回结果,而 handle() 是支持返回结果的。
CompletableFuture<Integer> f = CompletableFuture.supplyAsync(() -> 7 / 0)
.thenApply(r -> r * 10)
.exceptionally(e -> 0);
System.out.println(f.join());
CompletionService
CompletionService 接口的实现类是 ExecutorCompletionService,这个实现类的构造方法有两个,分别是:
ExecutorCompletionService(Executor executor);ExecutorCompletionService(Executor executor, BlockingQueue<Future<V>> completionQueue)。
这两个构造方法都需要传入一个线程池,如果不指定 completionQueue,那么默认会使用无界的 LinkedBlockingQueue。任务执行结果的 Future 对象就是加入到 completionQueue 中。
下面的示例代码完整地展示了如何利用 CompletionService 来实现高性能的询价系统。其中,我们没有指定 completionQueue,因此默认使用无界的 LinkedBlockingQueue。之后通过 CompletionService 接口提供的 submit() 方法提交了三个询价操作,这三个询价操作将会被 CompletionService 异步执行。最后,我们通过 CompletionService 接口提供的 take() 方法获取一个 Future 对象(前面我们提到过,加入到阻塞队列中的是任务执行结果的 Future 对象),调用 Future 对象的 get() 方法就能返回询价操作的执行结果了。
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 创建 CompletionService
CompletionService<Integer> cs = new ExecutorCompletionService<>(executor);
// 异步向电商 S1 询价
cs.submit(()->getPriceByS1());
// 异步向电商 S2 询价
cs.submit(()->getPriceByS2());
// 异步向电商 S3 询价
cs.submit(()->getPriceByS3());
// 将询价结果异步保存到数据库
for (int i=0; i<3; i++) {
Integer r = cs.take().get();
executor.execute(()->save(r));
}
CompletionService 接口提供的方法有 5 个,这 5 个方法的方法签名如下所示。
其中,submit() 相关的方法有两个。一个方法参数是Callable<V> task,前面利用 CompletionService 实现询价系统的示例代码中,我们提交任务就是用的它。另外一个方法有两个参数,分别是Runnable task和V result,这个方法类似于 ThreadPoolExecutor 的 <T> Future<T> submit(Runnable task, T result) ,这个方法在 《23 | Future:如何用多线程实现最优的“烧水泡茶”程序?》 中我们已详细介绍过,这里不再赘述。
CompletionService 接口其余的 3 个方法,都是和阻塞队列相关的,take()、poll() 都是从阻塞队列中获取并移除一个元素;它们的区别在于如果阻塞队列是空的,那么调用 take() 方法的线程会被阻塞,而 poll() 方法会返回 null 值。 poll(long timeout, TimeUnit unit) 方法支持以超时的方式获取并移除阻塞队列头部的一个元素,如果等待了 timeout unit 时间,阻塞队列还是空的,那么该方法会返回 null 值。
Future<V> submit(Callable<V> task);
Future<V> submit(Runnable task, V result);
Future<V> take() throws InterruptedException;
Future<V> poll();
Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException;
当需要批量提交异步任务的时候建议你使用 CompletionService。CompletionService 将线程池 Executor 和阻塞队列 BlockingQueue 的功能融合在了一起,能够让批量异步任务的管理更简单。除此之外,CompletionService 能够让异步任务的执行结果有序化,先执行完的先进入阻塞队列,利用这个特性,你可以轻松实现后续处理的有序性,避免无谓的等待,同时还可以快速实现诸如 Forking Cluster 这样的需求。
CompletionService 的实现类 ExecutorCompletionService,需要你自己创建线程池,虽看上去有些啰嗦,但好处是你可以让多个 ExecutorCompletionService 的线程池隔离,这种隔离性能避免几个特别耗时的任务拖垮整个应用的风险。
ForkJoinPool
Fork/Join 是一个并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的** Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并**。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。这两部分的关系类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。ForkJoinTask 有两个子类——RecursiveAction 和 RecursiveTask,通过名字你就应该能知道,它们都是用递归的方式来处理分治任务的。这两个子类都定义了抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。这两个子类也是抽象类,在使用的时候,需要你定义子类去扩展。
Fork/Join 并行计算的核心组件是 ForkJoinPool,所以下面我们就来简单介绍一下 ForkJoinPool 的工作原理。
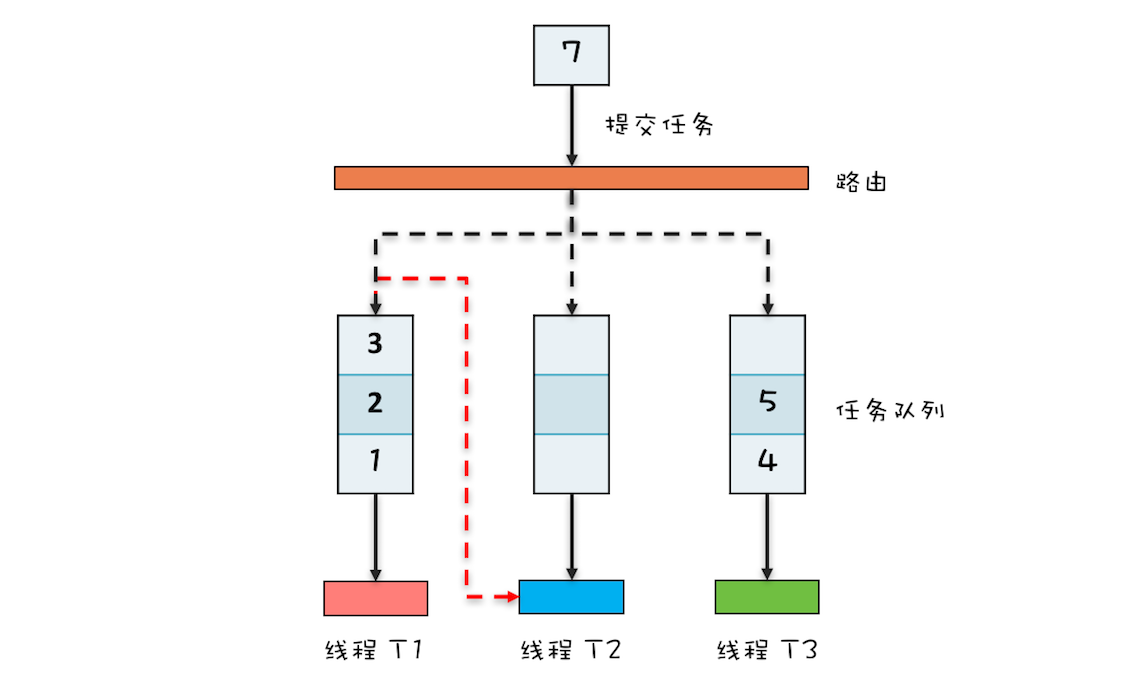
ForkJoinPool 本质上也是一个生产者 - 消费者的实现,但是更加智能,你可以参考下面的 ForkJoinPool 工作原理图来理解其原理。ThreadPoolExecutor 内部只有一个任务队列,而 ForkJoinPool 内部有多个任务队列,当我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
如果工作线程对应的任务队列空了,是不是就没活儿干了呢?不是的,ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务,例如下图中,线程 T2 对应的任务队列已经空了,它可以“窃取”线程 T1 对应的任务队列的任务。如此一来,所有的工作线程都不会闲下来了。
ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别是从任务队列不同的端消费,这样能避免很多不必要的数据竞争。我们这里介绍的仅仅是简化后的原理,ForkJoinPool 的实现远比我们这里介绍的复杂,如果你感兴趣,建议去看它的源码。
【示例】模拟 MapReduce 统计单词数量
static void main(String[] args) {
String[] fc = { "hello world",
"hello me",
"hello fork",
"hello join",
"fork join in world" };
//创建 ForkJoin 线程池
ForkJoinPool fjp = new ForkJoinPool(3);
//创建任务
MR mr = new MR(fc, 0, fc.length);
//启动任务
Map<String, Long> result = fjp.invoke(mr);
//输出结果
result.forEach((k, v) -> System.out.println(k + ":" + v));
}
//MR 模拟类
static class MR extends RecursiveTask<Map<String, Long>> {
private String[] fc;
private int start, end;
//构造函数
MR(String[] fc, int fr, int to) {
this.fc = fc;
this.start = fr;
this.end = to;
}
@Override
protected Map<String, Long> compute() {
if (end - start == 1) {
return calc(fc[start]);
} else {
int mid = (start + end) / 2;
MR mr1 = new MR(fc, start, mid);
mr1.fork();
MR mr2 = new MR(fc, mid, end);
//计算子任务,并返回合并的结果
return merge(mr2.compute(),
mr1.join());
}
}
//合并结果
private Map<String, Long> merge(Map<String, Long> r1, Map<String, Long> r2) {
Map<String, Long> result = new HashMap<>();
result.putAll(r1);
//合并结果
r2.forEach((k, v) -> {
Long c = result.get(k);
if (c != null) { result.put(k, c + v); } else { result.put(k, v); }
});
return result;
}
//统计单词数量
private Map<String, Long> calc(String line) {
Map<String, Long> result = new HashMap<>();
//分割单词
String[] words = line.split("\\s+");
//统计单词数量
for (String w : words) {
Long v = result.get(w);
if (v != null) { result.put(w, v + 1); } else { result.put(w, 1L); }
}
return result;
}
}