
Elasticsearch 面试
Elasticsearch 简介
扩展阅读:
【简单】什么是 ES?
Elasticsearch 是一个开源的分布式搜索和分析引擎。
Elasticsearch 基于搜索库 Lucene 开发。Elasticsearch 隐藏了 Lucene 的复杂性,提供了简单易用的 REST API / Java API 接口(另外还有其他语言的 API 接口)。
Elasticsearch 是面向文档的,它将复杂数据结构序列化为 JSON 形式存储。
Elasticsearch 提供近实时(Near Realtime,缩写 NRT)的全文搜索。近实时是指:
- 从写入数据到数据可以被搜索,存在较小的延迟(大概是 1s)。
- 基于 Elasticsearch 执行搜索和分析可以达到秒级。
【简单】ES 有哪些应用场景?
Elasticsearch 的主要功能如下:
- 海量数据的分布式存储及集群管理
- 提供丰富的近实时搜索能力
- 海量数据的近实时分析(聚合)
Elasticsearch 被广泛应用于以下场景:
- 搜索
- 全文检索 - Elasticsearch 通过快速搜索大型数据集,使复杂的搜索查询变得更加容易。它对于需要即时和相关搜索结果的网站、应用程序或企业特别有用。
- 自动补全和拼写纠正 - 可以在用户输入内容时,实时提供自动补全和拼写纠正,以增加用户体验并提高搜索效率。
- 地理空间搜索 - 使用地理空间查询搜索位置并计算空间关系。
- 近实时分析 - Elasticsearch 能够进行实时分析,使其适用于追踪实时数据的仪表板,例如用户活动、用户画像等,分析后进行推送。
- 可观测性
- 日志、指标和链路追踪 - 收集、存储和分析来自应用程序、系统和服务的日志、指标和追踪。
- 性能监控 - 监控和分析业务关键性能指标。
- OpenTelemetry - 使用 OpenTelemetry 标准,将遥测数据采集到 Elastic Stack。
【简单】ES 有哪些里程碑版本?
Elasticsearch 里程碑版本:
- 1.0(2014 年)
- 5.0(2016 年)
- Lucene 6.x
- 默认打分机制从 TD-IDF 改为 BM25
- 增加 Keyword 类型
- 6.0(2017 年)
- Lucene 7.x
- 跨集群复制
- 索引生命周期管理
- SQL 的支持
- 7.0(2019 年)
- Lucene 8.0
- 移除 Type
- ECK (用于支持 K8S)
- 集群协调
- High Level Rest Client
- Script Score 查询
- 8.0(2022 年)
- Lucene 9.0
- 向量搜索
- 支持 OpenTelemetry
【简单】什么是 Elasic Stack(ELK)?
Elastic Stack 通常被用来作为日志采集、检索、可视化的解决方案。
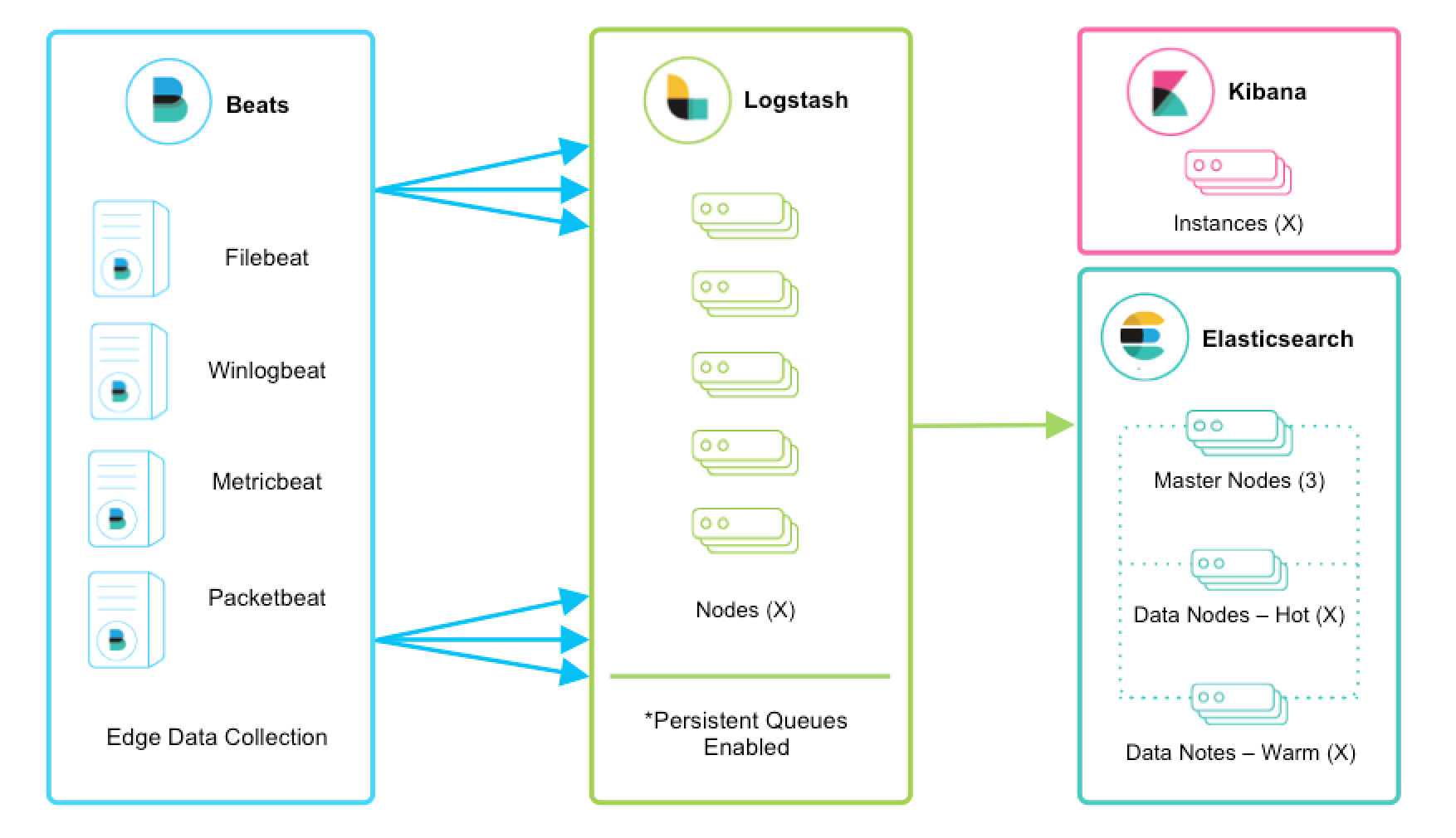
Elastic Stack 也常被称为 ELK,这是 Elastic 公司旗下三款产品 Elasticsearch 、Logstash 、Kibana 的首字母组合。
- Elasticsearch 负责存储数据,并提供对数据的检索和分析。
- Logstash 传输和处理你的日志、事务或其他数据。
- Kibana 将 Elasticsearch 的数据分析并渲染为可视化的报表。
Elastic Stack,在 ELK 的基础上扩展了一些新的产品。如:Beats,这是针对不同类型数据的轻量级采集器套件。
此外,基于 Elastic Stack,其技术生态还可以和一些主流的分布式中间件进行集成,以应对各种不同的场景。
Elasticsearch CRUD
扩展阅读:
【简单】如何在 ES 中 CRUD?
Elasticsearch 的基本 CRUD 方式如下:
- 添加索引
PUT <index>/_create/<id>- 指定 id,如果 id 已存在,报错POST <index>/_doc- 自动生成_id
- 删除索引 -
DELETE /<index>?pretty - 更新索引 -
POST <index>/_update/<id> - 查询索引 -
GET <index>/_doc/<id> - 批量更新 -
bulkAPI 支持index/create/update/delete - 批量查询 -
_mget和_msearch可以用于批量查询
扩展阅读:Quick starts
Elasticsearch Mapping
扩展阅读:
【简单】ES 支持哪些数据类型?
Elasticsearch 支持丰富的数据类型,常见的有:
- 文本类型:
text、keyword、constant_keyword、wildcard - 二进制类型:
binary - 数值类型:
long、float等 - 日期类型:
date - 布尔类型:
boolean - 对象类型:
object、nested
扩展:数据类型
【简单】ES 如何识别字段的数据类型?
在 Elasticsearch 中,Mapping(映射),用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。简言之,Mapping 定义了索引中的文档有哪些字段及其类型、这些字段是如何存储和索引的,就好像数据库的表定义一样。
Mapping 会把 json 文档映射成 Lucene 所需要的扁平格式
一个 Mapping 属于一个索引的 Type
- 每个文档都属于一个 Type
- 一个 Type 有一个 Mapping 定义
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
每个 document 都是 field 的集合,每个 field 都有自己的数据类型。映射数据时,可以创建一个 mapping,其中包含与 document 相关的 field 列表。映射定义还包括元数据 field,例如 _source ,它自定义如何处理 document 的关联元数据。
在 Elasticsearch 中,映射可分为静态映射和动态映射。在关系型数据库中写入数据之前首先要建表,在建表语句中声明字段的属性,在 Elasticsearch 中,则不必如此,Elasticsearch 最重要的功能之一就是让你尽可能快地开始探索数据,文档写入 Elasticsearch 中,它会根据字段的类型自动识别,这种机制称为动态映射,而静态映射则是写入数据之前对字段的属性进行手工设置。
静态映射
Elasticsearch 官方将静态映射称为显式映射(Explicit mapping)。静态映射是在创建索引时手工指定索引映射。静态映射和 SQL 中在建表语句中指定字段属性类似。相比动态映射,通过静态映射可以添加更详细、更精准的配置信息。
例如:
- 哪些字符串字段应被视为全文字段。
- 哪些字段包含数字、日期或地理位置。
- 日期值的格式。
- 用于控制动态添加字段的自定义规则。
【示例】创建索引时,显示指定 mapping
PUT /my-index-000001
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
【示例】在已存在的索引中,指定一个 field 的属性
PUT /my-index-000001/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
【示例】查看 mapping
GET /my-index-000001/_mapping
【示例】查看指定 field 的 mapping
GET /my-index-000001/_mapping/field/employee-id
动态映射
动态映射机制,允许用户不手动定义映射,Elasticsearch 会自动识别字段类型。在实际项目中,如果遇到的业务在导入数据之前不确定有哪些字段,也不清楚字段的类型是什么,使用动态映射非常合适。当 Elasticsearch 在文档中碰到一个以前没见过的字段时,它会利用动态映射来决定该字段的类型,并自动把该字段添加到映射中。
示例:创建一个名为 data 的索引、其 mapping 类型为 _doc,并且有一个类型为 long 的字段 count。
PUT data/_doc/1
{ "count": 5 }
Elasticsearch 存储
扩展阅读:
【简单】ES 的逻辑存储是怎样设计的?
Elasticsearch 的逻辑存储被设计为层级结构,自上而下依次为:
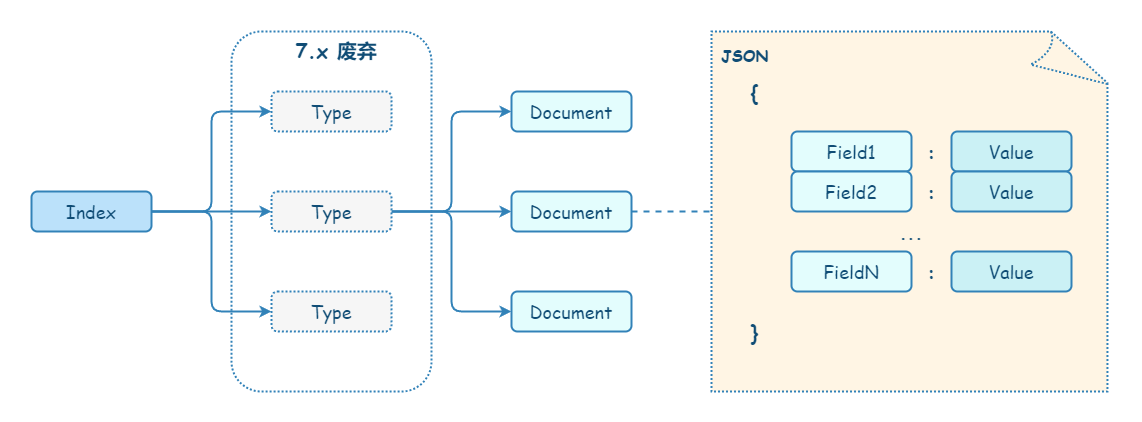
各层级结构的说明如下:
(1)Document(文档)
Elasticsearch 是面向文档的,这意味着读写数据的最小单位是文档。Elasticsearch 以 JSON 文档的形式序列化和存储数据。文档是一组字段,这些字段是包含数据的键值对。每个文档都有一个唯一的 ID。
一个简单的 Elasticsearch 文档可能如下所示:
{
"_index": "my-first-elasticsearch-index",
"_id": "DyFpo5EBxE8fzbb95DOa",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": ["dolphins", "whales"]
},
"join_date": "2024/05/01"
}
}
Elasticsearch 中的 document 是无模式的,也就是并非所有 document 都必须拥有完全相同的字段,它们不受限于同一个模式。
(2)Field(字段)
field 包含数据的键值对。默认情况下,Elasticsearch 对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。
document 包含数据和元数据。Metadata Field(元数据字段) 是存储有关文档信息的系统字段。在 Elasticsearch 中,元数据字段都以 _ 开头。常见的元数据字段有:
(3)Type(类型)
在 Elasticsearch 中,type 是 document 的逻辑分类。每个 index 里可以有一个或多个 type。
不同的 type 应该有相似的结构(schema)。举例来说,id字段不能在这个组是字符串,在另一个组是数值。
注意:Elasticsearch 7.x 版已彻底移除 type。
(4)Index(索引)
在 Elasticsearch 中,可以将 index 视为 document 的集合。
Elasticsearch 会为所有字段建立索引,经过处理后写入一个倒排索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elasticsearch 数据管理的顶层单位就叫做 Index。它是单个数据库的同义词。每个 Index 的名字必须是小写。
(5)Elasticsearch 概念和 RDBM 概念
| Elasticsearch | DB |
|---|---|
| 索引(index) | 数据库(database) |
| 类型(type,6.0 废弃,7.0 移除) | 数据表(table) |
| 文档(docuemnt) | 行(row) |
| 字符(field) | 列(column) |
| 映射(mapping) | 表结构(schema) |
【简单】ES 的物理存储是怎样设计的?
Elasticsearch 的物理存储,天然使用了分布式设计。
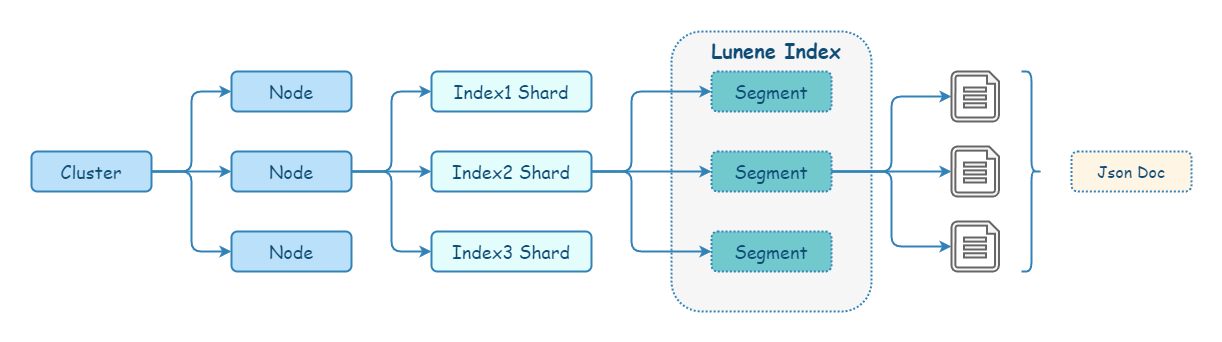
每个 Elasticsearch 进程都从属于一个 cluster,一个 cluster 可以有一个或多个 node(即 Elasticsearch 进程)。
Elasticsearch 存储会将每个 index 分为多个 shard,而 shard 可以分布在集群中不同节点上。正是由于这个机制,使得 Elasticsearch 有了水平扩展的能力。shard 也是 Elasticsearch 将数据从一个节点迁移到拎一个节点的最小单位。
Elasticsearch 的每个 shard 对应一个 Lucene index(一个包含倒排索引的文件目录)。Lucene index 又会被分解为多个 segment。segment 是索引中的内部存储元素,由于写入效率的考虑,所以被设计为不可变更的。segment 会定期 合并 较大的 segment,以保持索引大小。简单来说,Lucene 就是一个 jar 包,里面包含了封装好的构建、管理倒排索引的算法代码。
【中等】什么是倒排索引?
既然有倒排索引,顾名思义,有与之相对的正排索引。这里,以实现一个诗词检索器为例,来说明一下正排索引和倒排索引的区别。
正排索引是 ID 到数据的映射关系。如下所示,每首诗词用一个 ID 唯一识别。如果,我们要查找诗歌内容中是否包含某个关键字,就不得不在内容的完整文本中进行检索,效率很低。即使针对文档内容创建传统 RDBM 的索引(通常为 B+ 树结构),查找效率依然低下,并且会产生较大的额外存储空间开销。
| ID | 文档标题 | 文档内容 |
|---|---|---|
| 1 | 望月怀远 | 海上生明月,天涯共此时… |
| 2 | 春江花月夜 | 春江潮水连海平,海上明月共潮生… |
| 3 | 静夜思 | 床前明月光,疑是地上霜。举头望明月,低头思故乡。 |
| 4 | 锦瑟 | 沧海月明珠有泪,蓝田日暖玉生烟… |
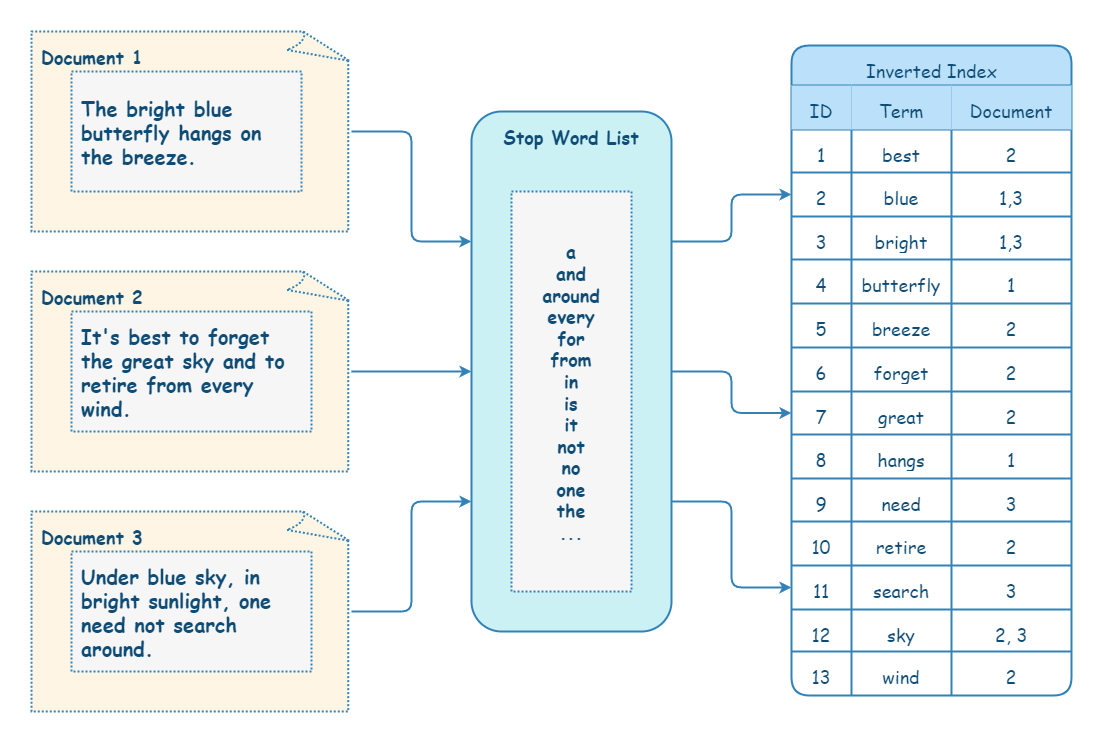
倒排索引的实现与正排索引相反。将文本分词后保存为多个词项,词项到 ID 的映射关系称为倒排索引(Inverted index)。
| 词项 | ID | 词频 |
|---|---|---|
| 月 | 1, 2, 3, 4 | 1:1 次、2:1 次、3:2 次、4:1 次 |
| 明月 | 1, 2, 3 | 1:1 次、2:1 次、3:2 次 |
| 海 | 1, 2, 4 | 1:1 次、2:1 次、4:1 次 |
除了要保存词项与 ID 的关系外,还需要保存这个词项在对应文档出现的位置、偏移量等信息,这是因为很多检索的场景中还需要判断关键词前后的内容是否符合搜索要求。
有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 明月,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
要注意倒排索引的两个重要细节:
- 倒排索引中的所有词项对应一个或多个文档;
- 倒排索引中的词项根据字典顺序升序排列
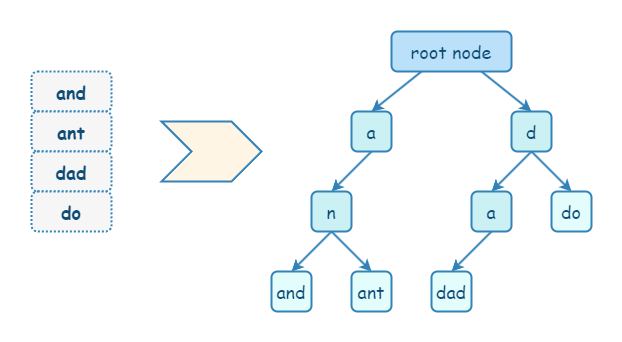
【中等】什么是字典树?
Trie(字典树),也被称为前缀树,是一种树状数据结构,用于有效检索键值对。它通常用于实现字典和自动补全功能,使其成为许多搜索算法的基本组件。
Trie 遵循一个规则:如果两个字符串有共同的前缀,那么它们在 Trie 中将具有相同的祖先。
Trie 的检索能力也可以使用 Hash 替代,但是 Trie 比 Hash 更高效。此外,Trie 有 Hash 不具备的优点:Trie 支持前缀搜索和排序。Trie 的主要缺点是:存储词项需要额外的空间,对于长文本,空间可能会变得很大。
【困难】ES 如何实现倒排索引?
在 Elasticsearch 中,数据存储、检索实际上是基于 Lucene 实现。
一个 Elasticsearch shard 对应一个 Lucene index,
Elasticsearch 的每个 shard 对应一个 Lucene index(一个包含倒排索引的文件目录)。Lucene index 又会被分解为多个 segment。segment 是索引中的内部存储元素,由于写入效率的考虑,所以被设计为不可变更的。segment 会定期 合并 较大的 segment,以保持索引大小。

倒排索引的组成主要有 3 个部分:
- Term Dictionary - Term Dictionary 用于保存 term(词项)。由于 ES 会对 document 中的每个 field 都进行分词,所以数据量可能会非常大。
- Term Dictionary 存储数据时,先将所有的 term 进行排序,然后将 Term Dictionary 中有共同前缀的 term 抽取出来进行分块存储;再对共同前缀做索引,最后通过索引就可以找到公共前缀对应的块在 Term Dictionary 文件中的偏移地址。
- 由于每个块中都有共同前缀,所以不需要再保存每个 Term 的全部内容,只需要保存其后缀即可,而且这些后缀都是排好序的。
- Term Index - Term Index 是 Term Dictionary 的索引。由于 Term Dictionary 存储的 term 可能会非常多,为了提高查询效率,从而设计了 Term Index。
- 为了提高检索效率以及节省空间,Term Index 只使用公共前缀做索引。
- Lucene 中实现 Term Index 采用了 FST 算法。FST 是一种非常复杂的结构,可以把它简单理解为一个占用空间小且高效的 KV 数据结构,有点类似于 Trie(字典树)。FST 有以下的特点:
- 通过对 Term Dictionary 数据的前缀复用,压缩了存储空间;
- 高效的查询性能,
O(len(prefix))的复杂度; - 构建后不可修改,因此 Lucene segment 也不允许修改。
- Posting List - Posting List 保存着每个 term 的映射信息。如文档 ID、词频、位置等。Lucene 把这些数据分成 3 个文件进行存储:
.doc文件,记录了文档 ID 信息和 term 的词频,还额外记录了跳表的信息,用来加速文档 ID 的查询;并且还记录了 term 在.pos和.pay文件中的位置,有助于进行快速读取。.pay文件,记录了 payload 信息和 term 在 doc 中的偏移信息;.pos文件,记录了 term 在 doc 中的位置信息。
Elasticsearch 搜索
扩展阅读:
【简单】ES 索引别名有什么用?
Elasticsearch 中的别名可用于更轻松地管理和使用索引。别名允许同时对多个索引执行操作,或者通过隐藏底层索引结构的复杂性来简化索引管理。
扩展阅读:https://www.elastic.co/guide/en/elasticsearch/reference/current/aliases.html
【简单】ES 中有哪些全文搜索 API?
ES 支持全文搜索的 API 主要有以下几个:
- intervals - 根据匹配词的顺序和近似度返回文档。
- match - 匹配查询,用于执行全文搜索的标准查询,包括模糊匹配和短语或邻近查询。
- match_bool_prefix - 对检索文本分词,并根据这些分词构造一个布尔查询。除了最后一个分词之外的每个分词都进行 term 查询。最后一个分词用于
prefix查询;其他分词都进行term查询。 - match_phrase - 短语匹配查询,短语匹配会将检索内容分词,这些词语必须全部出现在被检索内容中,并且顺序必须一致,默认情况下这些词都必须连续。
- match_phrase_prefix - 与
match_phrase查询类似,但对最后一个单词执行通配符搜索。 - multi_match 支持多字段 match 查询
- combined_fields - 匹配多个字段,就像它们已索引到一个组合字段中一样。
- query_string - 支持紧凑的 Lucene query string(查询字符串)语法,允许指定
AND|OR|NOT条件和单个查询字符串中的多字段搜索。仅适用于专家用户。 - simple_query_string - 更简单、更健壮的
query_string语法版本,适合直接向用户公开。
【简单】ES 中有哪些词项搜索 API?
Term(词项)是表达语意的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理 Term。
全文查询在执行查询之前会分析查询字符串。与全文查询不同,词项级别查询不会分词,而是将输入作为一个整体,在倒排索引中查找准确的词项。并且使用相关度计算公式为每个包含该词项的文档进行相关度计算。一言以概之:词项查询是对词项进行精确匹配。词项查询通常用于结构化数据,如数字、日期和枚举类型。
ES 支持词项搜索的 API 主要有以下几个:
- exists - 返回在指定字段上有值的文档。
- fuzzy - 模糊查询,返回包含与搜索词相似的词的文档。
- ids - 根据 ID 返回文档。此查询使用存储在
_id字段中的文档 ID。 - prefix - 前缀查询,用于查询某个字段中包含指定前缀的文档。
- range - 范围查询,用于匹配在某一范围内的数值型、日期类型或者字符串型字段的文档。
- regexp - 正则匹配查询,返回与正则表达式相匹配的词项所属的文档。
- term - 用来查找指定字段中包含给定单词的文档。
- terms - 与
term相似,但可以搜索多个值。 - terms set - 与
term相似,但可以定义返回文档所需的匹配词数。 - wildcard - 通配符查询,返回与通配符模式匹配的文档。
【简单】ES 支持哪些组合查询?
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外,复合查询还可以控制另外一个查询的行为。
复合查询有以下类型:
bool- 布尔查询,可以组合多个过滤语句来过滤文档。boosting- 提供调整相关性打分的能力,在positive块中指定匹配文档的语句,同时降低在negative块中也匹配的文档的得分。constant_score- 使用constant_score可以将query转化为filter,filter 可以忽略相关性算分的环节,并且 filter 可以有效利用缓存,从而提高查询的性能。dis_max- 返回匹配了一个或者多个查询语句的文档,但只将最佳匹配的评分作为相关性算分返回。function_score- 支持使用函数来修改查询返回的分数。
【简单】ES 中的 query 和 filter 有什么区别?
在 Elasticsearch 中,可以在两个不同的上下文中执行查询:
querycontext - 有相关性计算,采用相关性算法,计算文档与查询关键词之间的相关度,并根据评分(_score)大小排序。filtercontext - 无相关性计算,可以利用缓存,性能更好。
【中等】ES 支持哪些推荐查询?
ES 通过 Suggester 提供了推荐搜索能力,可以用于文本纠错,文本自动补全等场景。
根据使用场景的不同,ES 提供了以下 4 种 Suggester:
- Term Suggester - 基于词项的纠错补全。
- Phrase Suggester - 基于短语的纠错补全。
- Completion Suggester - 自动补全单词,输入词语的前半部分,自动补全单词。
- Context Suggester - 基于上下文的补全提示,可以实现上下文感知推荐。
【困难】ES 为什么会有深分页问题?
在 Elasticsearch 中,支持三种分页查询方式:
- from + size - 可以使用
from和size参数分别指定查询的起始页和每页记录数。 search_after- 不支持指定页数,只能向下翻页;并且需要指定 sort,并保证值是唯一的。然后,可以反复使用上次结果中最后一个文档的 sort 值进行查询。- scroll - 类似于 RDBMS 中的游标,只允许向下翻页。每次下一页查询后,使用返回结果的 scroll id 来作为下一次翻页的标记。scroll 查询会在搜索初始化阶段会生成快照,后续数据的变化无法及时体现在查询结果,因此更加适合一次性批量查询或非实时数据的分页查询。
前文中,我们已经了解了 ES 两阶段搜索流程(Query 和 Fetch)。从中不难发现,这种搜索方式在分页查询时会出现以下情况:
- 每个 shard 要扫描
from + size条数据; - coordinate node 需要接收并处理
(from + size) * primary_shard_num条数据。
如果 from 或 size 很大,需要处理的数据量也会很大,代价很高,这就是深分页产生的原因。为了避免深分页,ES 默认限制 from + size 不能超过 10000,可以通过 index.max_result_window 设置。
如何解决 Elasticsearch 深分页问题?
ES 官方提供了另外两种分页查询方式 search_after + PIT 和 scroll(注意:官方已不再推荐) 来避免深分页问题。
Elasticsearch 聚合
扩展阅读:
【简单】什么是聚合?ES 中有哪些聚合?
在数据库中,聚合是指将数据进行分组统计,得到一个汇总的结果。例如,计算总和、平均值、最大值或最小值等操作。
Elasticsearch 将聚合分为三类:
| 类型 | 说明 |
|---|---|
| Metric(指标聚合) | 根据字段值进行统计计算 |
| Bucket(桶聚合) | 根据字段值、范围或其他条件进行分组 |
| Pipeline(管道聚合) | 对其他聚合输出的结果进行再次聚合 |
【中等】ES 如何对海量数据(过亿)进行聚合计算?
Elasticsearch 支持 cardinality(近似计算非重复值) 。它提供一个字段的基数,即该字段的 distinct 或者 unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
Elasticsearch 分析
【简单】什么是文本分析?为什么需要文本分析?
Elasticsearch 中存储的数据可以粗略分为:
- 词项数据 - 采用精确查询。比较两条词项数据是否相对,实际是比较二者的二进制数据,结果只有相等或不相等。
- 文本数据 - 采用全文搜索。比较两个文本数据是否相等,没有太大意义,一般只会比较二者是否相似。相似性比较,是通过相关性评分来评估的。而计算相关性评分,需要对全文先分词处理,然后对分词后的词项进行统计才能进行相似性评估。
Elasticsearch 文本分析是将非结构化文本转换为一组词项(term)的过程。
文本分析可以分为两个方面:
- Tokenization(分词化) - 分词化将文本分解成更小的块,称为分词。在大多数情况下,这些分词是单独的 term(词项)。
- Normalization(标准化) - 经过分词后的文本只能进行词项匹配,但是无法进行同义词匹配。为解决这个问题,可以将文本进行标准化处理。例如:将
foxes标准化为fox。
【简单】ES 中的分析器是什么?
文本分析由 analyzer(分析器) 执行,分析器是一组控制整个过程的规则。无论是索引还是搜索,都需要使用分析器。
analyzer(分析器) 由三个组件组成:零个或多个 Character Filters(字符过滤器)、有且仅有一个 Tokenizer(分词器)、零个或多个 Token Filters(分词过滤器)。分析的执行顺序为:character filters -> tokenizer -> token filters。

Elasticsearch 内置的分析器:
standard- 根据单词边界将文本划分为多个 term,如 Unicode 文本分割算法所定义。它删除了大多数标点符号、小写 term,并支持删除停用词。simple- 遇到非字母字符时将文本划分为多个 term,并将其转为小写。whitespace- 遇到任何空格时将文本划分为多个 term,不转换为小写。stop- 与simple相似,同时支持删除停用词(如:the、a、is)。keyword- 部分词,直接将输入当做输出。pattern- 使用正则表达式将文本拆分为 term。它支持小写和非索引字。fingerprint- 可创建用于重复检测的指纹。- 语言分析器 - 提供了 30 多种常见语言的分词器。
默认情况下,Elasticsearch 使用 standard analyzer(标准分析器),它开箱即用,适用于大多数使用场景。Elasticsearch 也允许定制分析器。
Character Filters(字符过滤器)
Character Filters(字符过滤器) 将原始文本作为字符流接收,并可以通过添加、删除或更改字符来转换文本。分析器可以有零个或多个 Character Filters(字符过滤器),如果配置了多个,它会按照配置的顺序执行。
Elasticsearch 内置的字符过滤器:
html_strip-html_strip字符过滤器用于去除 HTML 元素(如<b>)并转义 HTML 实体(如&)。mapping-mapping字符过滤器用于将指定字符串的任何匹配项替换为指定的替换项。pattern_replace-pattern_replace字符筛选器将匹配正则表达式的任何字符替换为指定的替换。
Tokenizer(分词器)
Tokenizer(分词器) 接收字符流,将其分解为分词(通常是单个单词),并输出一个分词流。分词器还负责记录每个 term 的顺序或位置,以及该 term 所代表的原始单词的开始和结束字符偏移量。分析器有且仅有一个 Tokenizer(分词器)。
Elasticsearch 内置的分词器:
- 面向单词的分词器
standard- 将文本划分为单词边界上的 term,如 Unicode 文本分割算法所定义。它会删除大多数标点符号。它是大多数语言的最佳选择。letter- 遇到非字母字符时将文本划分为多个 term。lowercase- 到非字母字符时将文本划分为多个 term,并将其转为小写。whitespace- 遇到任何空格时将文本划分为多个 term。uax_url_email- 与standard相似,不同之处在于它将 URL 和电子邮件地址识别为单个分词。classic- 基于语法的英语分词器。thai- 将泰语文本分割为单词。
- 部分单词分词器
n-gram- 遇到指定字符列表(例如空格或标点符号)中的任何一个时,将文本分解为单词,然后返回每个单词的 n-gram:一个连续字母的滑动窗口,例如quick→[qu, ui, ic, ck]。edge_n-gram- 遇到指定字符列表(例如空格或标点符号)中的任何一个时,将文本分解为单词,然后返回锚定到单词开头的每个单词的 n 元语法,例如quick→[q, qu, qui, quic, quick]。
- 结构化文本分词器
keyword- 接受给定的任何文本,并输出与单个 term 完全相同的文本。它可以与lowercase等分词过滤器结合使用,以规范化分析的 term。pattern- 使用正则表达式在文本与单词分隔符匹配时将文本拆分为 term,或者将匹配的文本捕获为 term。simple_pattern- 使用正则表达式将匹配的文本捕获为 term。它使用正则表达式特征的受限子集,并且通常比pattern更快。char_group- 可以通过要拆分的字符集进行配置,这通常比运行正则表达式代价更小。simple_pattern_split- 使用与simple_pattern分词器相同的受限正则表达式子集,但在匹配项处拆分输入,而不是将匹配项作为 term 返回。path_hierarchy- 基于文件系统的路径分隔符,进行拆分,例如/foo/bar/baz→[/foo, /foo/bar, /foo/bar/baz ]。
Token Filters(分词过滤器)
Token Filters(分词过滤器) 接收分词流,并可以添加、删除或更改分词。常用的分词过滤器有: lowercase(小写转换)、stop(停用词处理)、synonym(同义词处理) 等等。分析器可以有零个或多个 Token Filters(分词过滤器),如果配置了多个,它会按照配置的顺序执行。
Elasticsearch 内置了很多分词过滤器,这里列举几个常见的:
classic- 从单词末尾删除英语所有格 ('s),并删除首字母缩略词中的点。它使用 Lucene 的 ClassicFilter。lowercase- 将分词转为小写。stop- 从分词中删除 stop word(停用词)。synonym- 允许在分析过程中轻松处理 近义词。
【中等】如果需要中文分词怎么办?
在英文中,单词有自然的空格作为分隔。
在中文中,分词有以下难点:
- 中文不能根据一个个汉字进行分词
- 不同于英文可以根据自然的空格进行分词;中文中一般不会有空格。
- 同一句话,在不同的上下文中,有不同个理解。例如:这个苹果,不大好吃;这个苹果,不大,好吃!
可以使用一些插件来获得对中文更好的分析能力:
- analysis-icu - 添加了扩展的 Unicode 支持,包括更好地分析亚洲语言、Unicode 规范化、Unicode 感知大小写折叠、排序规则支持和音译。
- elasticsearch-analysis-ik - 支持自定义词库,支持热更新分词字典
- elasticsearch-thulac-plugin - 清华大学自然语言处理和社会人文计算实验室的一套中文分词器。
Elasticsearch 复制
【中等】ES 如何保证高可用?
ES 通过副本机制实现高可用。ES 的数据副本模型参考了 PacificA 算法。
ES 必须满足以下条件才能运行:
默认的情况下,ES 的数据写入只需要保证主副本写入了即可,ES 在写上选择的是可用性优先,而并不是像 PacificA 协议那样的强一致性。而数据读取方面,ES 可能会读取到没有 commit 的数据,所以 ES 的数据读取可能产生不一致的情况。
在数据恢复方面,系统可以借助 GlobalCheckpoint 和 LocalCheckpoint 来加速数据恢复的过程。如果集群中只有旧的副本可用,那么可以使用 allocate_stale_primary 将一个指定的旧分片分配为主分片,但会造成数据丢失,慎用!
扩展:
【中等】ES 是如何实现选主的?
发起选主流程的条件:
- 只有 master-eligible 节点(通过
node.master: true设置)才能发起选主流程。 - 该 master-eligible 节点的当前状态不是 master。
- 该 master-eligible 节点通过 ZenDiscovery 模块的 ping 操作询问其已知的集群其他节点是否连接到 master。
- 包括本节点在内,当前已有超过
discovery.zen.minimum_master_nodes个节点没有连接到 master。
一般,应设置
discovery.zen.minimum_master_nodes为N / 2 + 1,以保证各种分布式决议能得到大多数节点认可。当集群由于故障(如:通信失联)被分割成多个子集群时,节点数未达到半数以上的子集群,不允许进行选主。以此,来避免出现脑裂问题。
选主流程:
- Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块,包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
- 对所有 master-eligible 节点根据 nodeId 字典排序:每次选举时,每个节点都把自己所知道的节点排一次序,然后选出 id 最小的节点,投票该节点为 master 节点。
- 如果对某个节点的投票数达到一定的值(
投票数 > N / 2 + 1),并且该节点自己也投票自己,那这个节点就当选 master;否则,重新发起选举,直到满足上述条件。
【中等】ES 如何避免脑裂问题?
ES 集群采用主从架构模式,集群中有且只能有一个 Master 存在。
现在假设这样一种场景,ES 集群部署在 2 个不同的机房。若两个机房网络断连,其中没有主节点的机房进行选主,产生了一个新的主节点。这时,就同时存在了两个主节点,它们各自负责处理接收的请求,会存在数据不一致。一旦,两个机房恢复通信,又将以哪个主节点为主,数据不一致问题怎么办,这就是脑裂问题。
那如何避免产生脑裂呢?ES 使用了 Quorum 机制来避免脑裂,在进行选主的时候,需要超过半数 Master 候选节点参与选主才行。假如有 5 个 Master 候选节点,如果要成功选举出 Master,必须有 (5 / 2) + 1 = 3 个 Master 候选节点参与选主才行。
在 6.x 及之前的版本使用 Zen Discovery 的集群协调子系统,Zen Discovery 允许用户通过使用 discovery.zen.minimum_master_nodes 设置来决定多少个符合主节点条件的节点可以选举出主节点。通常,只有 Master Eligible 节点(Master 候选节点)数大于 Quorum 的时候才能进行选主。计算公式如下:
Quorum = (Master 候选节点数 / 2) + 1
Elasticsearch 7.0 中,重新设计并重建了集群协调子系统:
- 移除了
discovery.zen.minimum_master_nodes设置,让 Elasticsearch 自己选择可以形成法定数量的节点。 - 典型的主节点选举只需很短时间就能完成。
- 集群的扩充和缩减变得更加安全和简单,并且大幅降低了因系统配置不当而可能造成数据丢失的风险。
- 节点状态记录比以往清晰很多,有助于诊断它们不能加入集群的原因,或者为何不能选举出主节点。
【中等】Elasticsearch 集群中有哪些不同类型的节点?
Elasticsearch 中的节点是指集群中的单个 Elasticsearch 进程实例。节点用于存储数据并参与集群的索引和搜索功能。
节点间会相互通信以分配数据和工作负载,从而确保集群的平衡和高性能。节点可以配置不同的角色,这些角色决定了它们在集群中的职责。
可以通过在 elasticsearch.yml 中设置 node.roles 来为节点分配角色。
ES 中主要有以下节点类型:
| 节点类型 | 说明 | 配置 |
|---|---|---|
| master eligible node | 候选主节点。一旦成为主节点,可以管理整个集群:创建、更新、删除索引;添加或删除节点;为节点分配分片。 | 低配置的 CPU、内存、磁盘 |
| data node | 数据节点。负责数据的存储和读取。 | 高配置的 CPU、内存、磁盘 |
| coordinating node | 协调节点。负责请求的分发,结果的汇总。 | 高配置的 CPU、中等配置的内存、低配置的磁盘 |
| ingest node | 预处理节点。负责处理数据、数据转换。 | 高配置的 CPU、中等配置的内存、低配置的磁盘 |
| warm & hot node | 存储冷、热数据的数据节点。 | Hot 类型的节点,都是高配配置,Warm 都是中低配即可 |
Elasticsearch 分片
【中等】ES 是如何实现水平扩展的?
Elasticsearch 通过分片来实现水平扩展。在 Elasticsearch 中,分片是索引的逻辑划分。索引可以有一个或多个分片,并且每个分片可以存储在集群中的不同节点上。分片用于在多个节点之间分配数据,从而提高性能和可扩展性。
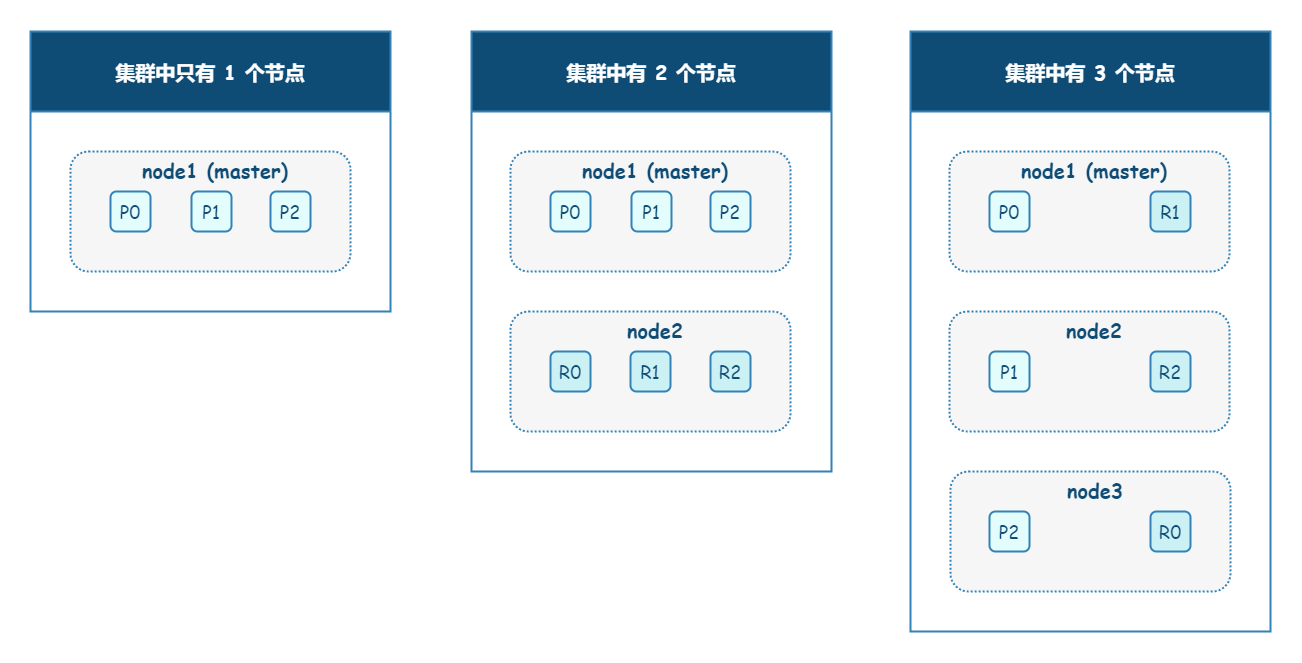
Elasticsearch 中有两种类型的分片:
- primary shard(主分片) - 用于存储原始数据。适当增加主分片数,可以提升 Elasticsearch 集群的吞吐量和整体容量。
- replica shard(副本分片) - 用于存储数据备份。
默认情况下,每个索引都有 1 个主分片(早期版本,默认每个索引有 5 个主分片)。
【中等】ES 如何选择读写数据映射到哪个分片上?
为了避免出现数据倾斜,系统需要一种高效的方式把数据均匀分散到各个节点上存储,并且在检索的时候可以快速找到文档所在的节点与分片。这就需要确立路由算法,使得数据可以映射到指定的节点上。
常见的路由方式如下:
| 算法 | 描述 |
|---|---|
| 随机算法 | 写数据时,随机写入到一个节点中;读数据时,由于不知道查询数据存在于哪个节点,所以需要遍历所有节点。 |
| 路由表 | 由中心节点统一维护数据的路由表,以保证唯一性;但是,中心化产生了新的问题:单点故障、数据越大,路由表越大、单点容易称为性能瓶颈、数据迁移复杂等。 |
| 哈希取模 | 对 key 值进行哈希计算,然后根据节点数取模,以确定节点。 |
ES 的数据路由算法是根据文档 ID 和 routing key 来确定 Shard ID 的过程。默认的情况下 routing key 为文档 ID,路由算法一般情况下的计算公式如下:
shard_number = hash(_routing) % numer_of_primary_shards
也可以在请求中指定 routing key,下面是新增数据的时候指定 routing 的方式:
PUT <index>/_doc/<id>?routing=routing_key
{
"field1": "xxx",
"field2": "xxx"
}
添加数据时,如果不指定文档 ID,ES 会自动分片一个随机 ID。这种情况下,结合 Hash 算法,可以保证数据被均匀分布到各个分片中。如果指定文档 ID,或指定 routing key,Hash 计算得出的值可能会不够随机,从而导致数据倾斜。
index 一旦设置了主分片数就不能修改,如果要修改就需要 reindex(即数据迁移)。之所以如此,就是因为:一旦修改了主分片数,即等于修改了原 Hash 计算中的变量,无法再通过 Hash 计算正确路由到数据存储的分片。
【中等】如何合理设置 ES 分片?
ES 索引设置多分片有以下好处:
- 多分片如果分布在不同的节点,查询可以在不同分片上并行执行,提升查询速度;
- 数据写入时,会分散在不同节点存储,避免数据倾斜。
设置多少分片合适:
一般,分片数要大于节点数,这样可以保证:一旦集群中有新的数据节点加入,ES 会自动对分片数进行再均衡,使得分片尽量在集群中分布均匀。
分片数也不宜设置过多,这会带来一些问题:
- 每一个 ES 分片对应一个 Lucene 索引,Lucene 索引存储在一个文件系统的目录中,它又可以分为多个 Segment,每个存储在一个文件中。因此,过多的分片意味着过多的文件,这会导致较大的读写性能开销。
- 此外,分片的元数据信息由 Master 节点维护,分片过多,会增加管理负担。建议,集群的总分片数控制在 10w 以内。
单数据节点分片限制:
- 每个非冻结数据节点 1000 个分片,通过
cluster.max_shards_per_node控制 - 每个冻结数据节点 3000 个分片,通过
cluster.max_shards_per_node.frozen控制
此外,分片大小也要有所限制:
- 理论上,一个分片最多包含约 20 亿个文档(
Integer.MAX_VALUE - 128)。但是,经验表明,每个分片的文档数量最好保持在 2 亿以下。 - 非日志型(搜索型、线上业务型) ES 的单分片容量最好在 [10GB, 30GB] 范围内;
- 日志型 ES 的单分片容量最好在 [30GB, 50GB] 范围内;
分片大小的上下限可以分别通过 max_primary_shard_size 和 min_primary_shard_size 来控制。
扩展:
Elasticsearch 架构
【困难】ES 搜索数据的流程是怎样的?
在 Elasticsearch 中,搜索一般分为两个阶段,query 和 fetch 阶段。可以简单的理解,query 阶段确定要取哪些 doc,fetch 阶段取出具体的 doc。
Query 阶段会根据搜索条件遍历每个分片(主分片或者副分片中的其一)中的数据,返回符合条件的前 N 条数据的 ID 和排序值,然后在协调节点中对所有分片的数据进行排序,获取前 N 条数据的 ID。
Query 阶段的流程如下:
- 客户端发送请求到任意一个节点,这个 node 成为 coordinate node(协调节点)。coordinate node 创建一个大小为 from + size 的优先级队列用来存放结果。
- coordinate node 对 document 进行路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 每个分片在本地执行搜索请求,并将查询结果打分排序,然后将结果保存到 from + size 大小的有序队列中。
- 接着,每个分片将结果返回给 coordinate node,coordinate node 对数据进行汇总处理:合并、排序、分页,将汇总数据存到一个大小为 from + size 的全局有序队列。
需要注意的是,在协调节点转发搜索请求的时候,如果有 N 个 Shard 位于同一个节点时,并不会合并这些请求,而是发生 N 次请求!
在 Fetch 阶段,协调节点会从 Query 阶段产生的全局排序列表中确定需要取回的文档 ID 列表,然后通过路由算法计算出各个文档对应的分片,并且用 multi get 的方式到对应的分片上获取文档数据。
Fetch 阶段的流程如下:
- coordinate node 确定需要获取哪些文档,然后向相关节点发起 multi get 请求;
- 分片所在节点读取文档数据,并且进行
_source字段过滤、处理高亮参数等,然后把处理后的文档数据返回给协调节点; - coordinate node 汇总所有数据后,返回给客户端。
【困难】ES 存储数据的流程是怎样的?
扩展阅读
关键点
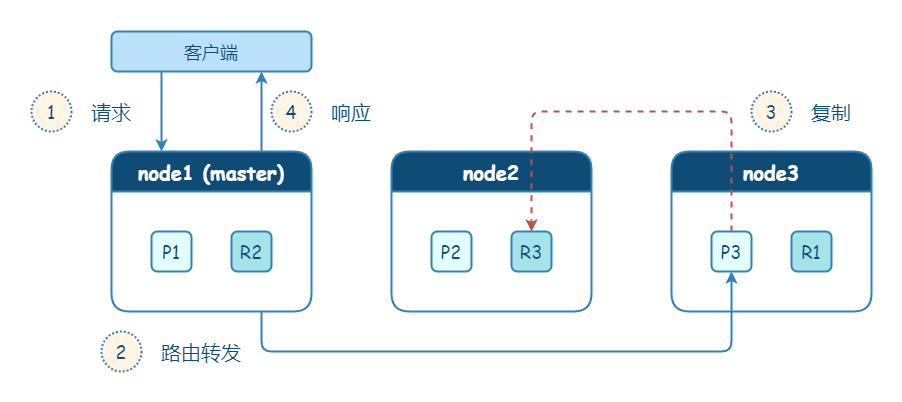
- 集群角度:请求任意节点,路由转发到主分片;主分片写入本地,然后复制数据到副本分片;最后响应客户端
- 分片角度:对内容做格式校验、分词
- 节点角度:持久化、refresh Lucene Segment,flush(fsync) Translog

ES 存储数据的流程可以从三个角度来阐述:
从集群的角度来看,数据写入会先路由到主分片,在主分片上写入成功后,会并发写副本分片,最后响应给客户端。
从分片的角度来看,数据到达分片后,需要对内容进行格式校验、分词处理然后再索引数据。
从节点的角度来看,ES 数据持久化的步骤可归纳为:Refresh、写 Translog、Flush、Merge。
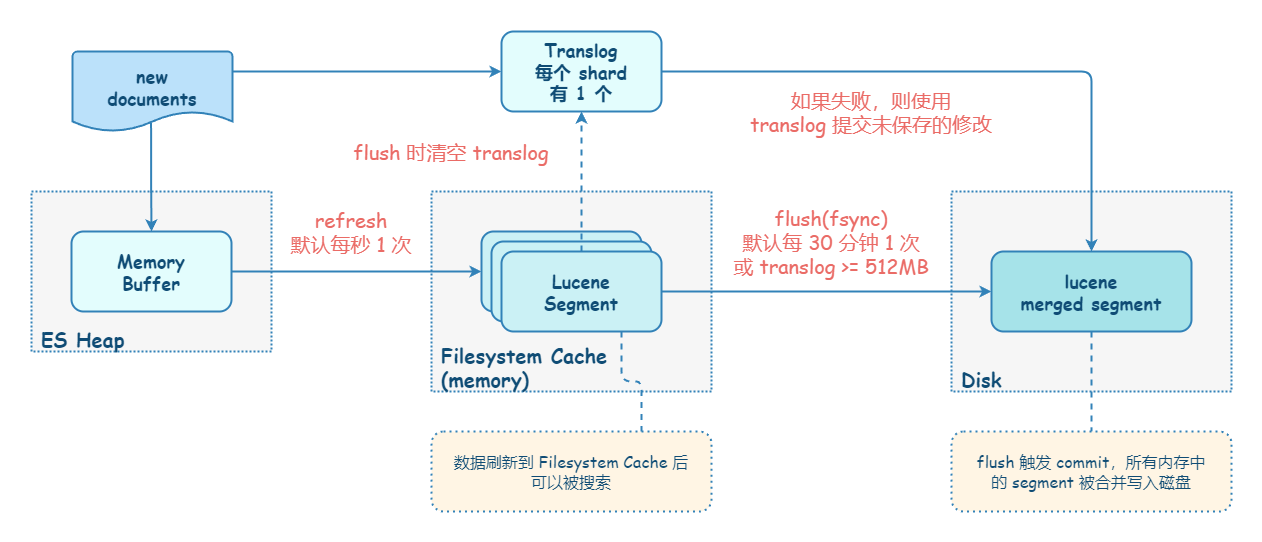
- 默认,ES 会每秒执行一次 Refresh 操作,把 Index Buffer 的数据写入磁盘中,但不会调用 fsync 刷盘。ES 提供近实时搜索的原因是因为数据被 Refresh 后才能被检索出来 。
- 为了保证数据不丢失,在写完 Index Buffer 后,ES 还要写 Translog。Translog 是追加写入的,并且默认是调用 fsync 进行刷盘的。
- Flush 操作会将 Filesystem Cache 中的数据持久化到磁盘中,默认 30 分钟或者在 Translog 写满时(默认 512 MB)触发执行。Flush 将磁盘缓存持久化到磁盘后,会清空 Translog。
- 最后,ES 和 Lucene 会自动执行 Merge 操作,清理过多的 Segment 文件,这个时候被标记为删除的文档会正式被物理删除。
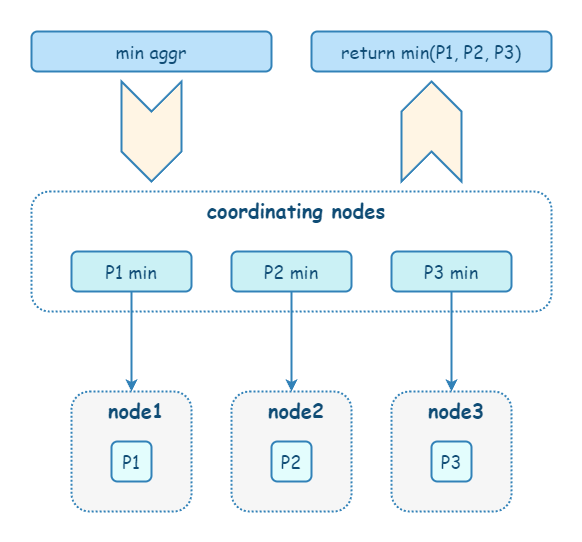
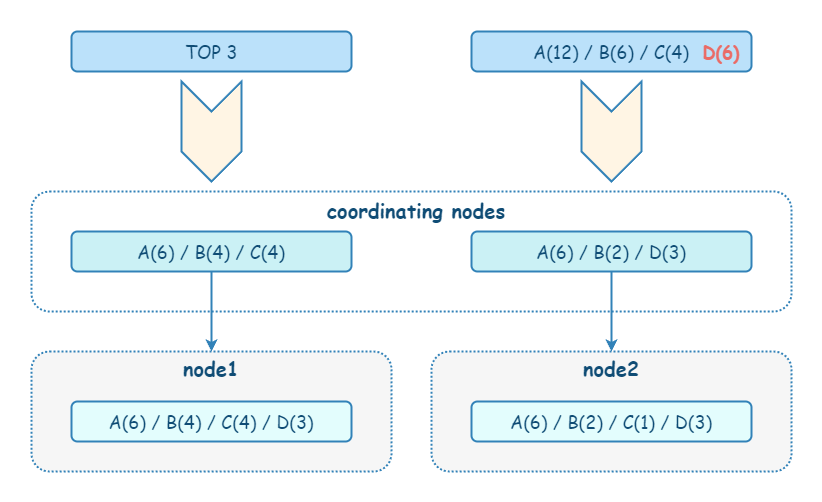
【中等】ES 相关性计算和聚合计算为什么会有计算偏差?
在 ES 中,不仅仅是普通搜索,相关性计算(评分)和聚合计算也是先在每个 shard 的本地进行计算,再由 coordinate node 进行汇总。由于分片的本地计算是独立的,只能基于数据子集来进行计算,所以难免出现数据偏差。
解决这个问题的方式也有多种:
- 当数据量不大的情况下,设置主分片数为 1,这意味着在数据全集上进行聚合。 但这种方案不太现实。
- 设置
shard_size参数,将计算数据范围变大,牺牲整体性能,提高精准度。shard_size 的默认值是size * 1.5 + 10。 - 使用 DFS Query Then Fetch, 在 URL 参数中指定:
_search?search_type=dfs_query_then_fetch。这样设定之后,ES 先会把每个分片的词频和文档频率的数据汇总到协调节点进行处理,然后再进行相关性算分。这样的话会消耗更多的 CPU 和内存资源,效率低下! - 尽量保证数据均匀地分布在各个分片中。
【困难】ES 如何保证读写一致?
乐观锁机制 - 可以通过版本号使用乐观锁并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置 replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置 replication 为 async 时,也可以通过设置搜索请求参数、_preference 为 primary 来查询主分片,确保文档是最新版本。
【困难】ES 查询速度为什么快?
- 倒排索引 - Elasticsearch 查询速度快最核心的点在于使用倒排索引。
- 在 Elasticsearch 中,为了提高查询效率,它对存储的文档进行了分词处理。分词是将连续的文本切分成一个个独立的词项的过程。对文本进行分词后,Elasticsearch 会为每个词项创建一个倒排索引。这样,当用户进行查询时,Elasticsearch 只需要在倒排索引中查找匹配的词项,从而快速地定位到相关的文档。
- 正向索引的结构是每个文档和关键字做关联,每个文档都有与之对应的关键字,记录关键字在文档中出现的位置和次数;而倒排索引则是将文档中的词项和文档的 ID 进行关联,这样就可以通过词项快速找到包含它的文档。
- 分片 - Elasticsearch 通过分片,支持分布式存储和搜索,可以实现搜索的并行处理和负载均衡。
【中等】ES 生产环境部署情况是怎样的?
典型问题
- 你们的 Elasticsearch 生产环境部署情况是怎样的?
- 你们的 Elasticsearch 生产环境集群规模有多大?
- 你们的 Elasticsearch 生产环境中有多少索引,每个索引大概有多少个分片?
知识点
根据实际 Elasticsearch 集群情况描述,以下是一个案例:
- 版本:6.3.2
- 集群规模:21 个节点,8 核 16G 内存,400G 磁盘
- 容量:6600GB/8400GB,900+ 索引、1.3 万分片、150 亿+ 文档
- 增量:日增 4 百万文档,5 GB
Elasticsearch 优化
【中等】使用 ES 有哪些最佳实践?
- 索引
- 大索引应拆分,增强性能,减少风险
- index 可以按日期拆分为
index_yyyyMMdd,然后用 alias 映射
- 分片:分片太大会导致查询慢、数据迁移和恢复时间长
- 非日志型业务分片不超过 30 GB
- 日志型业务分片不超过 50 GB
- 单分片文档数不超过 21 亿
- 单节点分片数不要超过 600 个
- 文档
- 单个文档大小不能超过 100MB
- 字段
- 一个索引中的字段数默认最大为 1000,但是不建议超过 100
- text 和 keyword 必须理清楚,keyword 是不会进行分词。
- 对于
keyword类型,默认只索引前 256 个字符。超过此长度的字符串将不会被索引(即无法被term查询、聚合)。可以通过ignore_above参数调整。
- Settings 设置
- 分片数设置后,不可修改
- 副本数默认 1 个
- Mapping 设置
- text 数据类型默认是关闭 fielddate
- 关闭
_source会导致无法使用 reindex copy_to虽然方便,但会显著增加索引大小和写入开销。只在明确需要跨字段搜索时才使用。
- Refresh
- 写入时,尽量不要执行 refresh,在并发较大的情况下,ES 负载可能会被打满。
- 索引别名
- 尽量使用索引的别名,在类似于进行索引字段类型变更需要进行索引重建的时候会减少很多的问题。
- 别名的下面可以挂载多个索引,若是索引拆分之后业务验证允许可以这么使用。
- alias 下面可以挂多个索引,但是需要注意的是每次请求很容易放大,比如说 alias 挂了 50 个索引,每个索引有 5 个分片,那么从集群的维度来看一共就是 50*5=250 次 query 和 fetch,很容易导致读放大的情况。
【中等】ES JVM 设置需要注意什么?
扩展阅读
关键点
-Xms 和 -Xmx 设置 JVM,JVM 内存不超过 32GB
ES 实际上是一个 Java 进程,因此也需要考虑 JVM 设置。关于 ES JVM 的设置,有以下几点建议:
- 从 ES6 开始,支持 64 位的 JVM
- 将内存
Xms和Xmx设置一样,需要注意过多的堆可能会使垃圾回收停顿时间过长 - 一般,将 50% 的可用内存分配给 ES
- ES 内存不要超过 32 GB
实际上,一般而言,绝大部分 JVM 内存最好都不要超过 32 GB,不仅仅是 ES 内存。
对于 32 位系统来说,JVM 的对象指针占用 32 位(4 byte),可以表示 2^32 个内存地址。由于,CPU 寻址的最小单位是 byte,2^32 byte 即 4GB,也就是说 JVM 最大可以支持 4GB。对于 64 位系统来说,如果直接引用,就需要使用 64 位的指针,相比 32 位 指针,多使用了一倍的内存。并且,指针在主内存和各级缓存间移动数据时,会占用更大的带宽。
Java 使用了一种叫做 Compressed oops 的技术来进行优化。该技术利用 Java 对象按照 8 字节对齐的机制,让 Java 对象指针指向一个映射地址偏移量(非真实 64 位 地址)。这种方式可以寻址最大位 32 GB 的内存空间。一旦超出 32 GB,就无法利用压缩指针技术,对象指针只能指向真实内存地址,这会造成空间的浪费。
【中等】ES 主机有哪些优化点?
- 关闭缓存 swap;
- 堆内存设置为:Min(节点内存/2, 32GB);
- 设置最大文件句柄数;
- 线程池+队列大小根据业务需要做调整;
- 磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单节点存储故障。
【中等】ES 索引数据多,如何优化?
- 动态索引 - 如果单索引数据量过大,可以创建索引模板,并周期性创建新索引(举例来说,索引名为 blog_yyyyMMdd),实现数据的分解。
- 冷热数据分离 - 将一定范围(如:一周、一月等)的数据作为热数据,其他数据作为冷数据。针对冷数据,可以考虑定期 force_merge + shrink 进行压缩,以节省存储空间和检索效率。
- 分区再均衡 - Elasticsearch 集群可以动态根据节点数的变化,调整索引分片在集群上的分布。但需要注意的是,要提前合理规划好索引的分片数:分片数过少,则增加节点也无法水平扩展;分片数过多,影响 Elasticsearch 读写效率。