Elasticsearch 存储
概述
本文介绍了 Elasticsearch 的逻辑存储、物理存储,以及 Elasticsearch 的倒排索引设计。
逻辑存储设计
Elasticsearch 的逻辑存储被设计为层级结构,自上而下为:
index -> type -> mapping -> document -> field
各层级结构的说明如下:
Document(文档)
Elasticsearch 是面向文档的,这意味着读写数据的最小单位是文档。Elasticsearch 以 JSON 文档的形式序列化和存储数据。文档是一组字段,这些字段是包含数据的键值对。每个文档都有一个唯一的 ID。
一个简单的 Elasticsearch 文档可能如下所示:
{
"_index": "my-first-elasticsearch-index",
"_id": "DyFpo5EBxE8fzbb95DOa",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": ["dolphins", "whales"]
},
"join_date": "2024/05/01"
}
}
Elasticsearch 中的 document 是无模式的,也就是并非所有 document 都必须拥有完全相同的字段,它们不受限于同一个模式。
Field(字段)
field 包含数据的键值对。默认情况下,Elasticsearch 对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。
document 包含数据和元数据。Metadata Field(元数据字段) 是存储有关文档信息的系统字段。在 Elasticsearch 中,元数据字段都以 _ 开头。常见的元数据字段有:
Type(类型)
在 Elasticsearch 中,type 是 document 的逻辑分类。每个 index 里可以有一个或多个 type。
不同的 type 应该有相似的结构(schema)。举例来说,id字段不能在这个组是字符串,在另一个组是数值。
注意:Elasticsearch 7.x 版已彻底移除 type。
Index(索引)
在 Elasticsearch 中,可以将 index 视为 document 的集合。每个索引存储在磁盘上的同组文件中;索引存储了所有映射类型的字段,还有一些设置。
Elasticsearch 会为所有字段建立索引,经过处理后写入一个倒排索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elasticsearch 数据管理的顶层单位就叫做 Index。它是单个数据库的同义词。每个 Index 的名字必须是小写。
Elasticsearch 概念和 RDBM 概念
Elasticsearch 概念 vs. RDBM 概念
| Elasticsearch 概念 | RDBM 概念 |
|---|---|
| 索引(index) | 数据库(database) |
| 类型(type,6.0 废弃,7.0 移除) | 数据表(table) |
| 文档(docuemnt) | 行(row) |
| 字符(field) | 列(column) |
| 映射(mapping) | 表结构(schema) |
物理存储设计
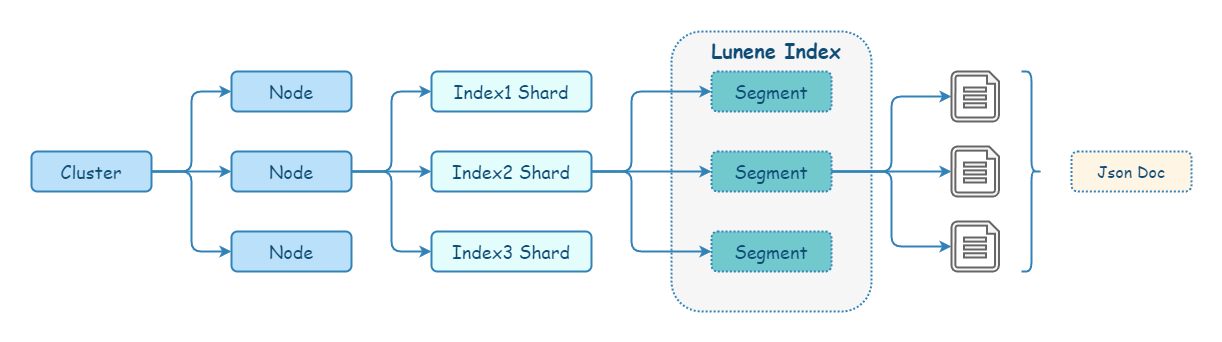
Elasticsearch 的物理存储,天然使用了分布式设计。
每个 Elasticsearch 进程都从属于一个 cluster,一个 cluster 可以有一个或多个 node(即 Elasticsearch 进程)。
Elasticsearch 存储会将每个 index 分为多个 shard,而 shard 可以分布在集群中不同节点上。正是由于这个机制,使得 Elasticsearch 有了水平扩展的能力。shard 也是 Elasticsearch 将数据从一个节点迁移到拎一个节点的最小单位。
Elasticsearch 的每个 shard 对应一个 Lucene index(一个包含倒排索引的文件目录)。Lucene index 又会被分解为多个 segment。segment 是索引中的内部存储元素,由于写入效率的考虑,所以被设计为不可变更的。segment 会定期 合并 较大的 segment,以保持索引大小。简单来说,Lucene 就是一个 jar 包,里面包含了封装好的构建、管理倒排索引的算法代码。
倒排索引
既然有倒排索引,顾名思义,有与之相对的正排索引。这里,以实现一个诗词检索器为例,来说明一下正排索引和倒排索引的区别。
正排索引是 ID 到数据的映射关系。如下所示,每首诗词用一个 ID 唯一识别。如果,我们要查找诗歌内容中是否包含某个关键字,就不得不在内容的完整文本中进行检索,效率很低。即使针对文档内容创建传统 RDBM 的索引(通常为 B+ 树结构),查找效率依然低下,并且会产生较大的额外存储空间开销。
| ID | 文档标题 | 文档内容 |
|---|---|---|
| 1 | 望月怀远 | 海上生明月,天涯共此时… |
| 2 | 春江花月夜 | 春江潮水连海平,海上明月共潮生… |
| 3 | 静夜思 | 床前明月光,疑是地上霜。举头望明月,低头思故乡。 |
| 4 | 锦瑟 | 沧海月明珠有泪,蓝田日暖玉生烟… |
倒排索引的实现与正排索引相反。将文本分词后保存为多个词项,词项到 ID 的映射关系称为倒排索引(Inverted index)。
| 词项 | ID | 词频 |
|---|---|---|
| 月 | 1, 2, 3, 4 | 1:1 次、2:1 次、3:2 次、4:1 次 |
| 明月 | 1, 2, 3 | 1:1 次、2:1 次、3:2 次 |
| 海 | 1, 2, 4 | 1:1 次、2:1 次、4:1 次 |
除了要保存词项与 ID 的关系外,还需要保存这个词项在对应文档出现的位置、偏移量等信息,这是因为很多检索的场景中还需要判断关键词前后的内容是否符合搜索要求。
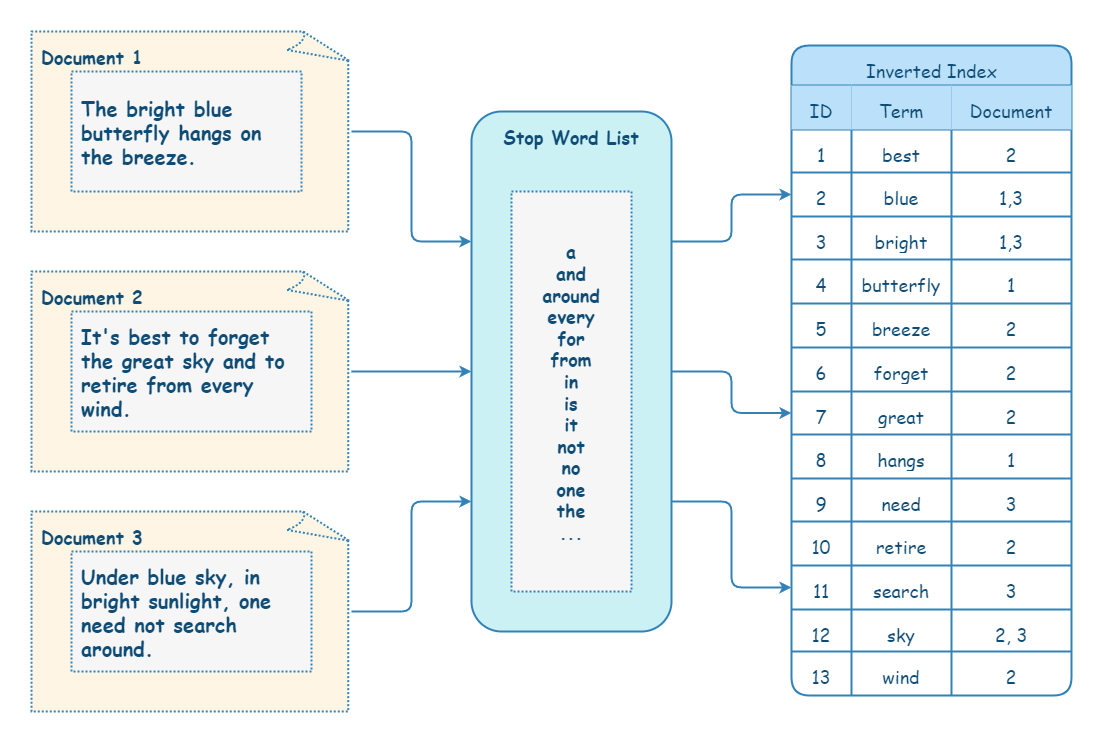

有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 明月,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
要注意倒排索引的两个重要细节:
- 倒排索引中的所有词项对应一个或多个文档;
- 倒排索引中的词项根据字典顺序升序排列
Setting
Elasticsearch 索引的配置项主要分为静态配置属性和动态配置属性,静态配置属性是索引创建后不能修改,而动态配置属性则可以随时修改。
Elasticsearch 索引设置的 api 为 settings,完整的示例如下:
PUT /my_index
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1",
"refresh_interval": "60s",
"analysis": {
"filter": {
"tsconvert": {
"type": "stconvert",
"convert_type": "t2s",
"delimiter": ","
},
"synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
}
},
"analyzer": {
"ik_max_word_synonym": {
"filter": [
"synonym",
"tsconvert",
"standard",
"lowercase",
"stop"
],
"tokenizer": "ik_max_word"
},
"ik_smart_synonym": {
"filter": [
"synonym",
"standard",
"lowercase",
"stop"
],
"tokenizer": "ik_smart"
}
},
"mapping": {
"coerce": "false",
"ignore_malformed": "false"
},
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "2s",
"info": "1s"
}
}
}
},
"provided_name": "hospital_202101070533",
"query": {
"default_field": "timestamp",
"parse": {
"allow_unmapped_fields": "false"
}
},
"requests": {
"cache": {
"enable": "true"
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"warn": "1s",
"info": "200ms"
},
"query": {
"warn": "1s",
"info": "500ms"
}
}
}
}
}
}
}
固定属性
index.creation_date:顾名思义索引的创建时间戳。index.uuid:索引的 uuid 信息。index.version.created:索引的版本号。
索引静态配置
index.number_of_shards:索引的主分片数,默认值是5。这个配置在索引创建后不能修改;在 Elasticsearch 层面,可以通过es.index.max_number_of_shards属性设置索引最大的分片数,默认为1024。index.codec:数据存储的压缩算法,默认值为LZ4,可选择值还有best_compression,它比 LZ4 可以获得更好的压缩比(即占据较小的磁盘空间,但存储性能比 LZ4 低)。index.routing_partition_size:路由分区数,如果设置了该参数,其路由算法为:( hash(_routing) + hash(_id) % index.routing_parttion_size ) % number_of_shards。如果该值不设置,则路由算法为hash(_routing) % number_of_shardings,_routing默认值为_id。
静态配置里,有重要的部分是配置分析器(config analyzers)。
index.analysis:分析器最外层的配置项,内部主要分为 char_filter、tokenizer、filter 和 analyzer。
char_filter:定义新的字符过滤器件。tokenizer:定义新的分词器。filter:定义新的 token filter,如同义词 filter。analyzer:配置新的分析器,一般是 char_filter、tokenizer 和一些 token filter 的组合。
索引动态配置
index.number_of_replicas:索引主分片的副本数,默认值是1,该值必须大于等于 0,这个配置可以随时修改。index.refresh_interval:执行新索引数据的刷新操作频率,该操作使对索引的最新更改对搜索可见,默认为1s。也可以设置为-1以禁用刷新。更详细信息参考 Elasticsearch 动态修改 refresh_interval 刷新间隔设置。