MapReduce
MapReduce 简介
MapReduce 是 Hadoop 项目中的分布式计算框架。它降低了分布式计算的门槛,可以让用户轻松编写程序,让其以可靠、容错的方式运行在大型集群上并行处理海量数据(TB 级)。
MapReduce 的设计思路是:
- 分而治之,并行计算
- 移动计算,而非移动数据
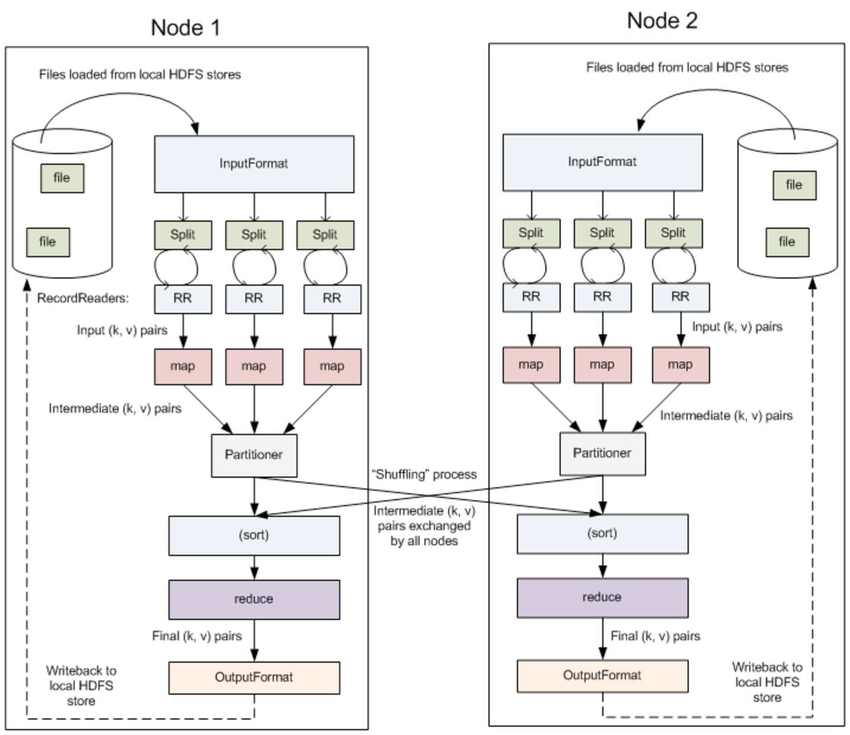
MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 任务以并行的方式处理。框架对 map 的输出进行排序,然后将其输入到 reduce 任务中。作业的输入和输出都存储在文件系统中。该框架负责调度任务、监控任务并重新执行失败的任务。
通常,计算节点和存储节点是相同的,即 MapReduce 框架和 HDFS 在同一组节点上运行。此配置允许框架在已存在数据的节点上有效地调度任务,从而在整个集群中实现非常高的聚合带宽。
MapReduce 框架由一个主 ResourceManager、每个集群节点一个工作程序 NodeManager 和每个应用程序的 MRAppMaster (YARN 组件) 组成。
MapReduce 框架仅对 <key、value> 对进行作,也就是说,框架将作业的输入视为一组 <key、value> 对,并生成一组 <key、value> 对作为作业的输出,可以想象是不同的类型。键和值类必须可由框架序列化,因此需要实现 Writable 接口。此外,关键类必须实现 WritableComparable 接口,以便于按框架进行排序。
MapReduce 作业的 Input 和 Output 类型:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
MapReduce 的特点
- 计算跟着数据走
- 良好的扩展性:计算能力随着节点数增加,近似线性递增
- 高容错
- 状态监控
- 适合海量数据的离线批处理
- 降低了分布式编程的门槛
MapReduce 应用场景
适用场景:
- 数据统计,如:网站的 PV、UV 统计
- 搜索引擎构建索引
- 海量数据查询
不适用场景:
- OLAP - 要求毫秒或秒级返回结果
- 流计算 - 流计算的输入数据集是动态的,而 MapReduce 是静态的
- DAG 计算
- 多个作业存在依赖关系,后一个的输入是前一个的输出,构成有向无环图 DAG
- 每个 MapReduce 作业的输出结果都会落盘,造成大量磁盘 IO,导致性能非常低下
MapReduce 工作流
MapReduce 编程模型:MapReduce 程序被分为 Map(映射)阶段和 Reduce(化简)阶段。
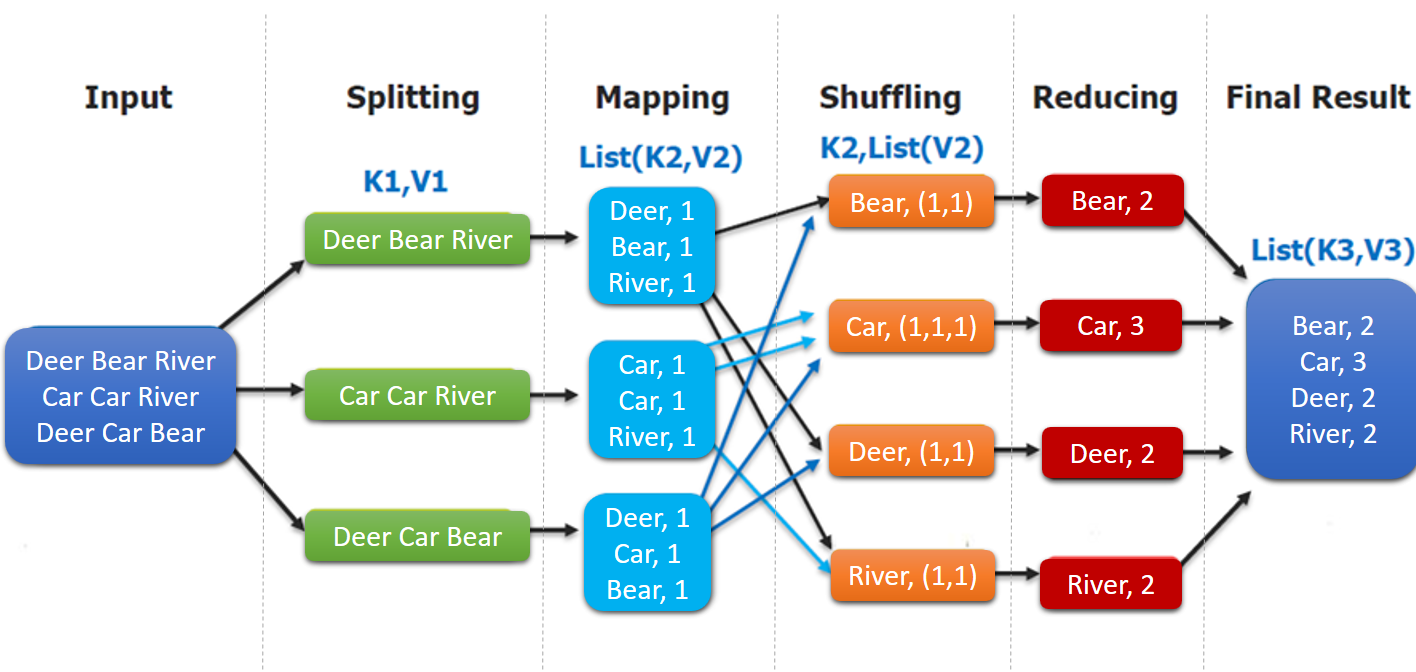
- input : 读取文本文件;
- splitting : 将文件按照行进行拆分,此时得到的
K1行数,V1表示对应行的文本内容; - mapping : 并行将每一行按照空格进行拆分,拆分得到的
List(K2,V2),其中K2代表每一个单词,由于是做词频统计,所以V2的值为 1,代表出现 1 次; - shuffling:由于
Mapping操作可能是在不同的机器上并行处理的,所以需要通过shuffling将相同key值的数据分发到同一个节点上去合并,这样才能统计出最终的结果,此时得到K2为每一个单词,List(V2)为可迭代集合,V2就是 Mapping 中的 V2; - Reducing : 这里的案例是统计单词出现的总次数,所以
Reducing对List(V2)进行归约求和操作,最终输出。
MapReduce 编程模型中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
MapReduce 组件
MapReduce 有以下核心组件:
- Job - Job 表示 MapReduce 作业配置。
Job通常用于指定Mapper、combiner(如果有)、Partitioner、Reducer、InputFormat、OutputFormat实现。 - Mapper - Mapper 负责将输入键值对映射到一组中间键值对。转换的中间记录不需要与输入记录具有相同的类型。一个给定的输入键值对可能映射到零个或多个输出键值对。
- Combiner -
combiner是map运算后的可选操作,它实际上是一个本地化的reduce操作。它执行中间输出的本地聚合,这有助于减少从Mapper传输到Reducer的数据量。 - Reducer - Reducer 将共享一个 key 的一组中间值归并为一个小的数值集。Reducer 有 3 个主要子阶段:shuffle,sort 和 reduce。
- shuffle - Reducer 的输入就是 mapper 的排序输出。在这个阶段,框架通过 HTTP 获取所有 mapper 输出的相关分区。
- sort - 在这个阶段中,框架将按照 key (因为不同 mapper 的输出中可能会有相同的 key) 对 Reducer 的输入进行分组。shuffle 和 sort 两个阶段是同时发生的。
- reduce - 对按键分组的数据进行聚合统计。
- Partitioner - Partitioner 负责控制 map 中间输出结果的键的分区。
- 键(或者键的子集)用于产生分区,通常通过一个散列函数。
- 分区总数与作业的 reduce 任务数是一样的。因此,它控制中间输出结果(也就是这条记录)的键发送给 m 个 reduce 任务中的哪一个来进行 reduce 操作。
- InputFormat - InputFormat 描述 MapReduce 作业的输入规范。MapReduce 框架依赖作业的 InputFormat 来完成以下工作:
- 确认作业的输入规范。
- 把输入文件分割成多个逻辑的 InputSplit 实例,然后将每个实例分配给一个单独的 Mapper。InputSplit 表示要由单个
Mapper处理的数据。 - 提供 RecordReader 的实现。RecordReader 从
InputSplit中读取<key, value>对,并提供给Mapper实现进行处理。
- OutputFormat - OutputFormat 描述 MapReduce 作业的输出规范。MapReduce 框架依赖作业的 OutputFormat 来完成以下工作:
- 确认作业的输出规范,例如检查输出路径是否已经存在。
- 提供 RecordWriter 实现。RecordWriter 将输出
<key, value>对到文件系统。